Несколько инструкций, несколько данных
| Таксономия Флинна |
|---|
| Одиночный поток данных |
| Несколько потоков данных |
| SIMD подкатегории [ 1 ] |
| Смотрите также |
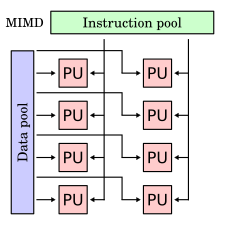
В вычислениях . множественные инструкции несколько данных ( MIMD ) - это метод, используемый для достижения параллелизма Машины, использующие MIMD, имеют несколько процессоров , которые функционируют асинхронно и независимо. В любое время разные процессоры могут выполнять различные инструкции по разным частям данных.
Архитектуры MIMD могут использоваться в ряде областей применения, таких как компьютерный дизайн / компьютерное производство , моделирование , моделирование и в качестве коммуникационных переключателей . Машины MIMD могут быть либо из общей памяти , либо распределенной категорий памяти . Эти классификации основаны на том, как процессоры MIMD получают доступ к памяти. Общие машины памяти могут быть на основе шины , расширенного или иерархического типа. Распределенные машины для памяти могут иметь гиперкуб или сетки схемы взаимосвязанного соединения .
Примеры
[ редактировать ]Примером системы MIMD является Intel Xeon Phi , произошедший от микроархитектуры Larrabee . [ 2 ] Эти процессоры имеют несколько ядер обработки (до 61 по состоянию на 2015 год), которые могут выполнять различные инструкции по разным данным.
Большинство параллельных компьютеров по состоянию на 2013 год являются системами MIMD. [ 3 ]
Общая модель памяти
[ редактировать ]В модели общей памяти все процессоры подключены к «глобально доступной» памяти, через программное или аппаратное средство. обычно Операционная система поддерживает согласованность памяти . [ 4 ]
С точки зрения программиста эта модель памяти лучше понята, чем модель распределенной памяти. Еще одним преимуществом является то, что согласованностью памяти управляется операционной системой, а не письменной программой. Два известных недостатка: масштабируемость за пределами тридцати двух процессоров сложно, а модель общей памяти менее гибкая, чем модель распределенной памяти. [ 4 ]
Существует много примеров общей памяти (многопроцессоры): UMA ( Единый доступ к памяти ), COMA ( доступ к памяти только кэш ). [ 5 ]
Автобус на основе
[ редактировать ]Машины MIMD с общей памятью имеют процессоры, которые имеют общую центральную память. В простейшей форме все процессоры прикреплены к шине, которая соединяет их к памяти. Это означает, что каждая машина с общей памятью разделяет конкретную CM, общую систему шины для всех клиентов.
Например, если мы рассмотрим автобус с клиентами A, B, C, подключенные с одной стороны и P, Q, R подключен на противоположной стороне, Любой из клиентов будет общаться с другим посредством интерфейса шины между ними.
Иерархический
[ редактировать ]Машины MIMD с иерархической общей памятью используют иерархию шин (как, например, в « жирном дереве »), чтобы дать процессорам доступ к памяти друг друга. Процессоры на разных досках могут общаться через междодальные автобусы. Автобусы поддерживают связь между досками. С этим типом архитектуры машина может поддерживать более девяти тысяч процессоров.
Распределенная память
[ редактировать ]В машинах распределенной памяти MIMD (множественные инструкции, несколько данных) каждый процессор имеет свое отдельное местоположение памяти. Каждый процессор не имеет прямого знания о памяти другого процессора. Для обмена данными они должны передаваться из одного процессора в другой в качестве сообщения. Поскольку общей памяти нет, споры не такая большая проблема с этими машинами. Экономически невозможно подключить большое количество процессоров непосредственно друг к другу. Способ избежать этого множества прямых соединений - подключить каждый процессор к нескольким другим. Этот тип дизайна может быть неэффективным из -за дополнительного времени, необходимого для передачи сообщения от одного процессора другому по пути сообщения. Количество времени, необходимое для процессов для выполнения простой маршрутизации сообщений, может быть существенным. Системы были разработаны, чтобы уменьшить потерю времени, а гиперкуб и сетка - одни из двух популярных схем взаимосвязи.
Примеры распределенной памяти (несколько компьютеров) включают MPP (массивно параллельные процессоры) , корову (кластеры рабочих станций) и NUMA ( неравномерный доступ к памяти ). Первый сложный и дорогой: многие суперкомпьютеры в сочетании с широкополосными сетями. Примеры включают в себя гиперкуб и сетку. Корова-это «домашняя» версия за часть цены. [ 5 ]
Гиперкубная взаимосвязанная сеть
[ редактировать ]В распределенной машине памяти MIMD с сетью взаимодействия гиперкубе , содержащей четыре процессора, процессор и модуль памяти размещены на каждой вершине квадрата. Диаметр системы - это минимальное количество шагов, необходимых для одного процессора, чтобы отправить сообщение в процессор, который находится в дальнейшем. Так, например, диаметр 2-куба составляет 2. В системе гиперкубе с восемью процессорами, а каждый процессор и модуль памяти размещены в вершине куба, диаметр-3. В целом, система, которая содержит 2 ^N процессоров с каждым процессором, непосредственно подключенным к другим процессорам, диаметр системы - это N. Одним из недостатков системы гиперкуб. Процессоры, чем действительно необходимы для приложения.
Сетчатая взаимосвязанная сеть
[ редактировать ]В MIMD-распределенной памятью машины с сетью соединения сетки процессоры помещаются в двумерную сетку. Каждый процессор связан с четырьмя непосредственными соседями. Обертка вокруг соединений может быть предусмотрена по краям сетки. Одним из преимуществ сети сетчатой взаимосвязи над гиперкубом является то, что система сетки не должна быть настроена на два. Недостатком является то, что диаметр сети сетки больше, чем гиперкуб для систем с более чем четырех процессорами.
Смотрите также
[ редактировать ]- Младшая средняя школа
- В
- Torus Interconnect
- Таксономия Флинна
- SPMD
- Суперкалар
- Очень длинное инструкционное слово
Ссылки
[ редактировать ]- ^ Флинн, Майкл Дж. (Сентябрь 1972). «Некоторые компьютерные организации и их эффективность» (PDF) . IEEE транзакции на компьютерах . C-21 (9): 948–960. doi : 10.1109/tc.1972.5009071 .
- ^ «Опасности параллели: Ларраби против Нвидии, Мимд против Симда» . 19 сентября 2008 г.
- ^ "Mimd | Intel® Developer Zone" . Архивировано из оригинала 2013-10-16 . Получено 2013-10-16 .
- ^ Jump up to: а беременный Ибаруден, Джаффер. «Параллельная обработка, EG6370G: Глава 1, Мотивация и история». Лекции слайды. Университет Святой Марии , Сан -Антонио, Техас . Весна 2008.
- ^ Jump up to: а беременный Эндрю С. Таненбаум (1997). Структурированная компьютерная организация (4 изд.). Прентис-Холл. С. 559–585. ISBN 978-0130959904 Полем Архивировано из оригинала 2013-12-01 . Получено 2013-03-15 .
| Базы данных управления авторитетом : национальный |
|---|