Центральный процессор


Центральный процессор ( ЦП ), также называемый центральным процессором , основным процессором или просто процессором , является наиболее важным процессором в данном компьютере . [1] [2] Его электронная схема выполняет инструкции , компьютерной программы такие как арифметические , логические, управляющие операции и операции ввода/вывода (I/O). [3] [4] [5] Эта роль контрастирует с ролью внешних компонентов, таких как основная память и схемы ввода-вывода. [6] и специализированные сопроцессоры , такие как графические процессоры (GPU).
Форма, конструкция и реализация процессоров со временем изменились, но их основные принципы работы остались практически неизменными. [7] Основные компоненты ЦП включают арифметико-логическое устройство (АЛУ), выполняющее арифметические и логические операции , регистры процессора , которые передают операнды в АЛУ и сохраняют результаты операций АЛУ, а также блок управления , который организует выборку (из памяти) . декодирование и выполнение (инструкций) путем управления согласованными операциями АЛУ, регистров и других компонентов. В современных процессорах большая часть полупроводниковой памяти отводится кэшам и параллелизму на уровне команд для повышения производительности, а также режимам процессора для поддержки операционных систем и виртуализации .
Most modern CPUs are implemented on integrated circuit (IC) microprocessors, with one or more CPUs on a single IC chip. Microprocessor chips with multiple CPUs are called multi-core processors.[8] The individual physical CPUs, called processor cores, can also be multithreaded to support CPU-level multithreading.[9]
An IC that contains a CPU may also contain memory, peripheral interfaces, and other components of a computer;[10] such integrated devices are variously called microcontrollers or systems on a chip (SoC).
History[edit]

Early computers such as the ENIAC had to be physically rewired to perform different tasks, which caused these machines to be called "fixed-program computers".[11] The "central processing unit" term has been in use since as early as 1955.[12][13] Since the term "CPU" is generally defined as a device for software (computer program) execution, the earliest devices that could rightly be called CPUs came with the advent of the stored-program computer.
The idea of a stored-program computer had been already present in the design of J. Presper Eckert and John William Mauchly's ENIAC, but was initially omitted so that ENIAC could be finished sooner.[14] On June 30, 1945, before ENIAC was made, mathematician John von Neumann distributed a paper entitled First Draft of a Report on the EDVAC. It was the outline of a stored-program computer that would eventually be completed in August 1949.[15] EDVAC was designed to perform a certain number of instructions (or operations) of various types. Significantly, the programs written for EDVAC were to be stored in high-speed computer memory rather than specified by the physical wiring of the computer.[16] This overcame a severe limitation of ENIAC, which was the considerable time and effort required to reconfigure the computer to perform a new task.[17] With von Neumann's design, the program that EDVAC ran could be changed simply by changing the contents of the memory. EDVAC was not the first stored-program computer; the Manchester Baby, which was a small-scale experimental stored-program computer, ran its first program on 21 June 1948[18] and the Manchester Mark 1 ran its first program during the night of 16–17 June 1949.[19]
Early CPUs were custom designs used as part of a larger and sometimes distinctive computer.[20] However, this method of designing custom CPUs for a particular application has largely given way to the development of multi-purpose processors produced in large quantities. This standardization began in the era of discrete transistor mainframes and minicomputers, and has rapidly accelerated with the popularization of the integrated circuit (IC). The IC has allowed increasingly complex CPUs to be designed and manufactured to tolerances on the order of nanometers.[21] Both the miniaturization and standardization of CPUs have increased the presence of digital devices in modern life far beyond the limited application of dedicated computing machines. Modern microprocessors appear in electronic devices ranging from automobiles[22] to cellphones,[23] and sometimes even in toys.[24][25]
While von Neumann is most often credited with the design of the stored-program computer because of his design of EDVAC, and the design became known as the von Neumann architecture, others before him, such as Konrad Zuse, had suggested and implemented similar ideas.[26] The so-called Harvard architecture of the Harvard Mark I, which was completed before EDVAC,[27][28] also used a stored-program design using punched paper tape rather than electronic memory.[29] The key difference between the von Neumann and Harvard architectures is that the latter separates the storage and treatment of CPU instructions and data, while the former uses the same memory space for both.[30] Most modern CPUs are primarily von Neumann in design, but CPUs with the Harvard architecture are seen as well, especially in embedded applications; for instance, the Atmel AVR microcontrollers are Harvard-architecture processors.[31]
Relays and vacuum tubes (thermionic tubes) were commonly used as switching elements;[32][33] a useful computer requires thousands or tens of thousands of switching devices. The overall speed of a system is dependent on the speed of the switches. Vacuum-tube computers such as EDVAC tended to average eight hours between failures, whereas relay computers—such as the slower but earlier Harvard Mark I—failed very rarely.[13] In the end, tube-based CPUs became dominant because the significant speed advantages afforded generally outweighed the reliability problems. Most of these early synchronous CPUs ran at low clock rates compared to modern microelectronic designs. Clock signal frequencies ranging from 100 kHz to 4 MHz were very common at this time, limited largely by the speed of the switching devices they were built with.[34]
Transistor CPUs[edit]

The design complexity of CPUs increased as various technologies facilitated the building of smaller and more reliable electronic devices. The first such improvement came with the advent of the transistor. Transistorized CPUs during the 1950s and 1960s no longer had to be built out of bulky, unreliable, and fragile switching elements, like vacuum tubes and relays.[35] With this improvement, more complex and reliable CPUs were built onto one or several printed circuit boards containing discrete (individual) components.
In 1964, IBM introduced its IBM System/360 computer architecture that was used in a series of computers capable of running the same programs with different speeds and performances.[36] This was significant at a time when most electronic computers were incompatible with one another, even those made by the same manufacturer. To facilitate this improvement, IBM used the concept of a microprogram (often called "microcode"), which still sees widespread use in modern CPUs.[37] The System/360 architecture was so popular that it dominated the mainframe computer market for decades and left a legacy that is continued by similar modern computers like the IBM zSeries.[38][39] In 1965, Digital Equipment Corporation (DEC) introduced another influential computer aimed at the scientific and research markets—the PDP-8.[40]

Transistor-based computers had several distinct advantages over their predecessors. Aside from facilitating increased reliability and lower power consumption, transistors also allowed CPUs to operate at much higher speeds because of the short switching time of a transistor in comparison to a tube or relay.[41] The increased reliability and dramatically increased speed of the switching elements, which were almost exclusively transistors by this time; CPU clock rates in the tens of megahertz were easily obtained during this period.[42] Additionally, while discrete transistor and IC CPUs were in heavy usage, new high-performance designs like single instruction, multiple data (SIMD) vector processors began to appear.[43] These early experimental designs later gave rise to the era of specialized supercomputers like those made by Cray Inc and Fujitsu Ltd.[43]
Small-scale integration CPUs[edit]

During this period, a method of manufacturing many interconnected transistors in a compact space was developed. The integrated circuit (IC) allowed a large number of transistors to be manufactured on a single semiconductor-based die, or "chip". At first, only very basic non-specialized digital circuits such as NOR gates were miniaturized into ICs.[44] CPUs based on these "building block" ICs are generally referred to as "small-scale integration" (SSI) devices. SSI ICs, such as the ones used in the Apollo Guidance Computer, usually contained up to a few dozen transistors. To build an entire CPU out of SSI ICs required thousands of individual chips, but still consumed much less space and power than earlier discrete transistor designs.[45]
IBM's System/370, follow-on to the System/360, used SSI ICs rather than Solid Logic Technology discrete-transistor modules.[46][47] DEC's PDP-8/I and KI10 PDP-10 also switched from the individual transistors used by the PDP-8 and PDP-10 to SSI ICs,[48] and their extremely popular PDP-11 line was originally built with SSI ICs, but was eventually implemented with LSI components once these became practical.
Large-scale integration CPUs[edit]
Lee Boysel published influential articles, including a 1967 "manifesto", which described how to build the equivalent of a 32-bit mainframe computer from a relatively small number of large-scale integration circuits (LSI).[49][50] The only way to build LSI chips, which are chips with a hundred or more gates, was to build them using a metal–oxide–semiconductor (MOS) semiconductor manufacturing process (either PMOS logic, NMOS logic, or CMOS logic). However, some companies continued to build processors out of bipolar transistor–transistor logic (TTL) chips because bipolar junction transistors were faster than MOS chips up until the 1970s (a few companies such as Datapoint continued to build processors out of TTL chips until the early 1980s).[50] In the 1960s, MOS ICs were slower and initially considered useful only in applications that required low power.[51][52] Following the development of silicon-gate MOS technology by Federico Faggin at Fairchild Semiconductor in 1968, MOS ICs largely replaced bipolar TTL as the standard chip technology in the early 1970s.[53]
As the microelectronic technology advanced, an increasing number of transistors were placed on ICs, decreasing the number of individual ICs needed for a complete CPU. MSI and LSI ICs increased transistor counts to hundreds, and then thousands. By 1968, the number of ICs required to build a complete CPU had been reduced to 24 ICs of eight different types, with each IC containing roughly 1000 MOSFETs.[54] In stark contrast with its SSI and MSI predecessors, the first LSI implementation of the PDP-11 contained a CPU composed of only four LSI integrated circuits.[55]
Microprocessors[edit]



Since microprocessors were first introduced they have almost completely overtaken all other central processing unit implementation methods. The first commercially available microprocessor, made in 1971, was the Intel 4004, and the first widely used microprocessor, made in 1974, was the Intel 8080. Mainframe and minicomputer manufacturers of the time launched proprietary IC development programs to upgrade their older computer architectures, and eventually produced instruction set compatible microprocessors that were backward-compatible with their older hardware and software. Combined with the advent and eventual success of the ubiquitous personal computer, the term CPU is now applied almost exclusively[a] to microprocessors. Several CPUs (denoted cores) can be combined in a single processing chip.[56]
Previous generations of CPUs were implemented as discrete components and numerous small integrated circuits (ICs) on one or more circuit boards.[57] Microprocessors, on the other hand, are CPUs manufactured on a very small number of ICs; usually just one.[58] The overall smaller CPU size, as a result of being implemented on a single die, means faster switching time because of physical factors like decreased gate parasitic capacitance.[59][60] This has allowed synchronous microprocessors to have clock rates ranging from tens of megahertz to several gigahertz. Additionally, the ability to construct exceedingly small transistors on an IC has increased the complexity and number of transistors in a single CPU many fold. This widely observed trend is described by Moore's law, which had proven to be a fairly accurate predictor of the growth of CPU (and other IC) complexity until 2016.[61][62]
While the complexity, size, construction and general form of CPUs have changed enormously since 1950,[63] the basic design and function has not changed much at all. Almost all common CPUs today can be very accurately described as von Neumann stored-program machines.[64][b] As Moore's law no longer holds, concerns have arisen about the limits of integrated circuit transistor technology. Extreme miniaturization of electronic gates is causing the effects of phenomena like electromigration and subthreshold leakage to become much more significant.[66][67] These newer concerns are among the many factors causing researchers to investigate new methods of computing such as the quantum computer, as well as to expand the use of parallelism and other methods that extend the usefulness of the classical von Neumann model.
Operation[edit]
The fundamental operation of most CPUs, regardless of the physical form they take, is to execute a sequence of stored instructions that is called a program. The instructions to be executed are kept in some kind of computer memory. Nearly all CPUs follow the fetch, decode and execute steps in their operation, which are collectively known as the instruction cycle.
After the execution of an instruction, the entire process repeats, with the next instruction cycle normally fetching the next-in-sequence instruction because of the incremented value in the program counter. If a jump instruction was executed, the program counter will be modified to contain the address of the instruction that was jumped to and program execution continues normally. In more complex CPUs, multiple instructions can be fetched, decoded and executed simultaneously. This section describes what is generally referred to as the "classic RISC pipeline", which is quite common among the simple CPUs used in many electronic devices (often called microcontrollers). It largely ignores the important role of CPU cache, and therefore the access stage of the pipeline.
Some instructions manipulate the program counter rather than producing result data directly; such instructions are generally called "jumps" and facilitate program behavior like loops, conditional program execution (through the use of a conditional jump), and existence of functions.[c] In some processors, some other instructions change the state of bits in a "flags" register. These flags can be used to influence how a program behaves, since they often indicate the outcome of various operations. For example, in such processors a "compare" instruction evaluates two values and sets or clears bits in the flags register to indicate which one is greater or whether they are equal; one of these flags could then be used by a later jump instruction to determine program flow.
Fetch[edit]
Fetch involves retrieving an instruction (which is represented by a number or sequence of numbers) from program memory. The instruction's location (address) in program memory is determined by the program counter (PC; called the "instruction pointer" in Intel x86 microprocessors), which stores a number that identifies the address of the next instruction to be fetched. After an instruction is fetched, the PC is incremented by the length of the instruction so that it will contain the address of the next instruction in the sequence.[d] Often, the instruction to be fetched must be retrieved from relatively slow memory, causing the CPU to stall while waiting for the instruction to be returned. This issue is largely addressed in modern processors by caches and pipeline architectures (see below).
Decode[edit]
The instruction that the CPU fetches from memory determines what the CPU will do. In the decode step, performed by binary decoder circuitry known as the instruction decoder, the instruction is converted into signals that control other parts of the CPU.
The way in which the instruction is interpreted is defined by the CPU's instruction set architecture (ISA).[e] Often, one group of bits (that is, a "field") within the instruction, called the opcode, indicates which operation is to be performed, while the remaining fields usually provide supplemental information required for the operation, such as the operands. Those operands may be specified as a constant value (called an immediate value), or as the location of a value that may be a processor register or a memory address, as determined by some addressing mode.
In some CPU designs the instruction decoder is implemented as a hardwired, unchangeable binary decoder circuit. In others, a microprogram is used to translate instructions into sets of CPU configuration signals that are applied sequentially over multiple clock pulses. In some cases the memory that stores the microprogram is rewritable, making it possible to change the way in which the CPU decodes instructions.
Execute[edit]
After the fetch and decode steps, the execute step is performed. Depending on the CPU architecture, this may consist of a single action or a sequence of actions. During each action, control signals electrically enable or disable various parts of the CPU so they can perform all or part of the desired operation. The action is then completed, typically in response to a clock pulse. Very often the results are written to an internal CPU register for quick access by subsequent instructions. In other cases results may be written to slower, but less expensive and higher capacity main memory.
For example, if an instruction that performs addition is to be executed, registers containing operands (numbers to be summed) are activated, as are the parts of the arithmetic logic unit (ALU) that perform addition. When the clock pulse occurs, the operands flow from the source registers into the ALU, and the sum appears at its output. On subsequent clock pulses, other components are enabled (and disabled) to move the output (the sum of the operation) to storage (e.g., a register or memory). If the resulting sum is too large (i.e., it is larger than the ALU's output word size), an arithmetic overflow flag will be set, influencing the next operation.
Structure and implementation[edit]

Hardwired into a CPU's circuitry is a set of basic operations it can perform, called an instruction set. Such operations may involve, for example, adding or subtracting two numbers, comparing two numbers, or jumping to a different part of a program. Each instruction is represented by a unique combination of bits, known as the machine language opcode. While processing an instruction, the CPU decodes the opcode (via a binary decoder) into control signals, which orchestrate the behavior of the CPU. A complete machine language instruction consists of an opcode and, in many cases, additional bits that specify arguments for the operation (for example, the numbers to be summed in the case of an addition operation). Going up the complexity scale, a machine language program is a collection of machine language instructions that the CPU executes.
The actual mathematical operation for each instruction is performed by a combinational logic circuit within the CPU's processor known as the arithmetic–logic unit or ALU. In general, a CPU executes an instruction by fetching it from memory, using its ALU to perform an operation, and then storing the result to memory. Besides the instructions for integer mathematics and logic operations, various other machine instructions exist, such as those for loading data from memory and storing it back, branching operations, and mathematical operations on floating-point numbers performed by the CPU's floating-point unit (FPU).[68]
Control unit[edit]
The control unit (CU) is a component of the CPU that directs the operation of the processor. It tells the computer's memory, arithmetic and logic unit and input and output devices how to respond to the instructions that have been sent to the processor.
It directs the operation of the other units by providing timing and control signals. Most computer resources are managed by the CU. It directs the flow of data between the CPU and the other devices. John von Neumann included the control unit as part of the von Neumann architecture. In modern computer designs, the control unit is typically an internal part of the CPU with its overall role and operation unchanged since its introduction.[69]
Arithmetic logic unit[edit]

The arithmetic logic unit (ALU) is a digital circuit within the processor that performs integer arithmetic and bitwise logic operations. The inputs to the ALU are the data words to be operated on (called operands), status information from previous operations, and a code from the control unit indicating which operation to perform. Depending on the instruction being executed, the operands may come from internal CPU registers, external memory, or constants generated by the ALU itself.
When all input signals have settled and propagated through the ALU circuitry, the result of the performed operation appears at the ALU's outputs. The result consists of both a data word, which may be stored in a register or memory, and status information that is typically stored in a special, internal CPU register reserved for this purpose.
Modern CPUs typically contain more than one ALU to improve performance.
Address generation unit[edit]
Блок генерации адреса (AGU), иногда также называемый блоком вычисления адреса (ACU), [70] is an execution unit inside the CPU that calculates addresses used by the CPU to access main memory. By having address calculations handled by separate circuitry that operates in parallel with the rest of the CPU, the number of CPU cycles required for executing various machine instructions can be reduced, bringing performance improvements.
При выполнении различных операций процессорам необходимо вычислять адреса памяти, необходимые для извлечения данных из памяти; например, позиции элементов массива в памяти должны быть рассчитаны до того, как ЦП сможет извлечь данные из реальных ячеек памяти. Эти вычисления по генерации адреса включают в себя различные арифметические операции с целыми числами , такие как сложение, вычитание, операции по модулю или сдвиг битов . Часто вычисление адреса памяти включает в себя более одной машинной инструкции общего назначения, которые не обязательно декодируются и выполняются быстро. Путем включения AGU в конструкцию ЦП, а также введения специализированных инструкций, использующих AGU, различные вычисления по генерации адреса могут быть разгружены от остальной части ЦП и часто могут выполняться быстро за один цикл ЦП.
Возможности AGU зависят от конкретного процессора и его архитектуры . Таким образом, некоторые AGU реализуют и предоставляют больше операций вычисления адреса, а некоторые также включают более сложные специализированные инструкции, которые могут работать с несколькими операндами одновременно. Некоторые архитектуры ЦП включают несколько AGU, поэтому одновременно может выполняться более одной операции вычисления адреса, что приводит к дальнейшему повышению производительности благодаря суперскалярной природе усовершенствованных конструкций ЦП. Например, Intel включает несколько AGU в свои Sandy Bridge и Haswell микроархитектуры , которые увеличивают пропускную способность подсистемы памяти ЦП, позволяя параллельно выполнять несколько инструкций доступа к памяти.
Блок управления памятью (MMU) [ править ]
Многие микропроцессоры (в смартфонах и настольных компьютерах, ноутбуках, серверных компьютерах) имеют блок управления памятью, преобразующий логические адреса в адреса физического ОЗУ, обеспечивающий защиту памяти и возможности подкачки , полезные для виртуальной памяти . Более простые процессоры, особенно микроконтроллеры , обычно не содержат MMU.
Кэш [ править ]
процессора Кэш [71] — это аппаратный кэш, используемый центральным процессором (ЦП) компьютера для снижения средних затрат (времени или энергии) на доступ к данным из основной памяти . Кэш — это меньшая по размеру и более быстрая память, расположенная ближе к ядру процессора , в которой хранятся копии данных из часто используемых ячеек основной памяти . Большинство процессоров имеют различные независимые кэши, включая кэши инструкций и данных , где кэш данных обычно организован в виде иерархии большего количества уровней кэша (L1, L2, L3, L4 и т. д.).
Все современные (быстрые) процессоры (за некоторыми специализированными исключениями) [ф] ) имеют несколько уровней кэша ЦП. Первые процессоры, использовавшие кеш, имели только один уровень кеша; в отличие от более поздних кэшей уровня 1, он не был разделен на L1d (для данных) и L1i (для инструкций). Почти все современные процессоры с кешами имеют разделенный кеш L1. У них также есть кэши L2, а для более крупных процессоров — кэши L3. Кэш L2 обычно не разделен и действует как общий репозиторий для уже разделенного кеша L1. Каждое ядро многоядерного процессора имеет выделенный кэш L2, который обычно не используется совместно ядрами. Кэш L3 и кэши более высокого уровня распределяются между ядрами и не разделяются. Кэш L4 в настоящее время встречается редко и обычно находится в динамической памяти с произвольным доступом (DRAM), а не в статической памяти с произвольным доступом (SRAM), на отдельном кристалле или кристалле. Исторически так же было и с L1, хотя более крупные чипы позволяли интегрировать его и вообще все уровни кэша, за возможным исключением последнего уровня. Каждый дополнительный уровень кэша имеет тенденцию быть больше и оптимизирован по-разному.
Существуют и другие типы кешей (которые не учитываются в «размере кеша» наиболее важных кешей, упомянутых выше), например, резервный буфер трансляции (TLB), который является частью блока управления памятью (MMU), который имеется у большинства процессоров.
Размер кэшей обычно определяется степенями двойки: 2, 8, 16 и т. д. КиБ или МиБ (для больших размеров, не относящихся к L1), хотя IBM z13 имеет кэш инструкций L1 объемом 96 КиБ. [72]
Тактовая частота [ править ]
Большинство процессоров представляют собой синхронные схемы , что означает, что они используют тактовый сигнал для управления своими последовательными операциями. Тактовый сигнал генерируется внешним генератором , который каждую секунду генерирует постоянное количество импульсов в форме периодической прямоугольной волны . Частота тактовых импульсов определяет скорость, с которой ЦП выполняет инструкции, и, следовательно, чем быстрее такт, тем больше инструкций ЦП будет выполнять каждую секунду.
Чтобы обеспечить правильную работу ЦП, период тактирования превышает максимальное время, необходимое для распространения (перемещения) всех сигналов через ЦП. Установив период тактового сигнала на значение, значительно превышающее задержку распространения в наихудшем случае , можно спроектировать весь ЦП и способ его перемещения данных по «краям» нарастающего и падающего тактового сигнала. Преимущество этого заключается в значительном упрощении ЦП как с точки зрения дизайна, так и с точки зрения количества компонентов. Однако у него также есть тот недостаток, что весь ЦП должен ожидать обработки своих самых медленных элементов, хотя некоторые его части работают намного быстрее. Это ограничение в значительной степени компенсируется различными методами увеличения параллелизма ЦП (см. Ниже).
Однако одни лишь архитектурные улучшения не решают всех недостатков глобально синхронных процессоров. Например, тактовый сигнал подвержен задержкам любого другого электрического сигнала. Более высокие тактовые частоты во все более сложных процессорах затрудняют поддержание синфазности (синхронизации) тактового сигнала во всем устройстве. Это привело к тому, что многие современные процессоры требуют подачи нескольких одинаковых тактовых сигналов, чтобы избежать значительной задержки одного сигнала, которая может привести к неисправности процессора. Еще одной серьезной проблемой, связанной с резким увеличением тактовой частоты, является количество тепла, рассеиваемого процессором . Постоянно меняющиеся часы заставляют многие компоненты переключаться независимо от того, используются ли они в данный момент. Как правило, переключающийся компонент потребляет больше энергии, чем элемент в статическом состоянии. Таким образом, по мере увеличения тактовой частоты увеличивается и потребление энергии, в результате чего процессору требуется больше рассеивания тепла в виде решений для охлаждения процессора .
Один из методов борьбы с переключением ненужных компонентов называется тактовым стробированием , который предполагает отключение тактового сигнала на ненужные компоненты (фактически их отключение). Однако это часто считается трудным для реализации и поэтому не находит широкого применения за пределами конструкций с очень низким энергопотреблением. IBM PowerPC, на базе Одним из примечательных недавних проектов ЦП, в котором используется обширное стробирование тактовой частоты, является Xenon используемый в Xbox 360 ; это снижает требования к питанию Xbox 360. [73]
Безтактовые процессоры [ править ]
Другим методом решения некоторых проблем с глобальным тактовым сигналом является полное удаление тактового сигнала. Хотя удаление глобального тактового сигнала значительно усложняет процесс проектирования во многих отношениях, асинхронные (или безтактовые) конструкции имеют заметные преимущества в энергопотреблении и рассеивании тепла по сравнению с аналогичными синхронными конструкциями. Хотя это и необычно, но целые асинхронные процессоры создаются без использования глобального тактового сигнала. Двумя яркими примерами этого являются ARM совместимый с AMULET, , и MiniMIPS, совместимый с MIPS R3000. [74]
Вместо полного удаления тактового сигнала некоторые конструкции ЦП позволяют определенным частям устройства работать асинхронно, например, используя асинхронные ALU в сочетании с суперскалярной конвейерной обработкой для достижения некоторого повышения производительности арифметических операций. Хотя не совсем ясно, могут ли полностью асинхронные проекты работать на сопоставимом или лучшем уровне, чем их синхронные аналоги, очевидно, что они, по крайней мере, преуспевают в более простых математических операциях. Это, в сочетании с отличными характеристиками энергопотребления и рассеивания тепла, делает их очень подходящими для встраиваемых компьютеров . [75]
Модуль регулятора напряжения [ править ]
Многие современные процессоры имеют встроенный в кристалл модуль управления питанием, который по требованию регулирует подачу напряжения на схему процессора, позволяя поддерживать баланс между производительностью и энергопотреблением.
Целочисленный диапазон [ править ]
Каждый процессор представляет числовые значения определенным образом. Например, некоторые ранние цифровые компьютеры представляли числа в виде знакомой десятичной (по основанию 10) значений системы счисления , а другие использовали более необычные представления, такие как троичная (по основанию три). Почти все современные процессоры представляют числа в двоичной форме, где каждая цифра представлена некоторой двузначной физической величиной, такой как «высокое» или «низкое» напряжение . [г]

С числовым представлением связан размер и точность целых чисел, которые может представлять ЦП. В случае двоичного ЦП это измеряется количеством битов (значащих цифр двоичного целого числа), которые ЦП может обработать за одну операцию, которую обычно называют размером слова , разрядностью , шириной пути данных , целочисленной точностью. или целочисленный размер . Целочисленный размер ЦП определяет диапазон целочисленных значений, с которыми он может напрямую работать. [час] Например, 8-битный процессор может напрямую манипулировать целыми числами, представленными восемью битами, которые имеют диапазон 256 (2 8 ) дискретные целочисленные значения.
Целочисленный диапазон также может влиять на количество ячеек памяти, к которым процессор может напрямую обращаться (адрес — это целое значение, представляющее определенную ячейку памяти). Например, если двоичный процессор использует 32 бита для представления адреса памяти, то он может напрямую адресовать 2. 32 места памяти. Чтобы обойти это ограничение и по ряду других причин, некоторые ЦП используют механизмы (например, переключение банков ), которые позволяют адресовать дополнительную память.
Процессоры с большими размерами слов требуют больше схем и, следовательно, физически больше, стоят дороже и потребляют больше энергии (и, следовательно, выделяют больше тепла). В результате в современных приложениях обычно используются 4- или 8-битные микроконтроллеры меньшего размера , хотя доступны процессоры с гораздо большими размерами слов (например, 16, 32, 64 и даже 128-битные). Однако когда требуется более высокая производительность, преимущества большего размера слова (большие диапазоны данных и адресные пространства) могут перевесить недостатки. ЦП может иметь внутренние пути данных короче размера слова, чтобы уменьшить размер и стоимость. Например, хотя IBM System/360 архитектура набора команд представляла собой 32-битный набор команд, модели System/360 Model 30 и Model 40 имели 8-битные пути данных в арифметико-логическом блоке, так что требовалось 32-битное сложение. четыре цикла, по одному на каждые 8 бит операндов, и, хотя набор команд серии Motorola 68000 был 32-битным, у Motorola 68000 и Motorola 68010 были 16-битные пути данных в арифметико-логическом блоке, так что 32-битное сложение потребовало двух циклов.
Чтобы получить некоторые преимущества, предоставляемые как меньшей, так и большей длиной битов, многие наборы команд имеют разную разрядность для целочисленных данных и данных с плавающей запятой, что позволяет процессорам, реализующим этот набор команд, иметь разную разрядность для разных частей устройства. Например, набор инструкций IBM System/360 в основном был 32-битным, но поддерживал 64-битные значения с плавающей запятой , чтобы обеспечить большую точность и диапазон чисел с плавающей запятой. [37] Модель System/360 Model 65 имела 8-битный сумматор для десятичной и двоичной арифметики с фиксированной запятой и 60-битный сумматор для арифметики с плавающей запятой. [76] Многие более поздние конструкции ЦП используют аналогичную смешанную разрядность, особенно когда процессор предназначен для использования общего назначения, где требуется разумный баланс возможностей целых чисел и операций с плавающей запятой.
Параллелизм [ править ]
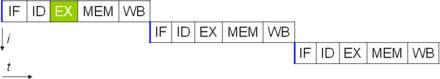
Описание основных операций ЦП, предложенное в предыдущем разделе, описывает простейшую форму, которую может принимать ЦП. Этот тип ЦП, обычно называемый субскалярным , работает и выполняет одну инструкцию с одним или двумя фрагментами данных одновременно, что составляет менее одной инструкции за такт ( IPC < 1 ).
Этот процесс приводит к присущей субскалярным процессорам неэффективности. Поскольку одновременно выполняется только одна инструкция, весь процессор должен дождаться завершения этой инструкции, прежде чем перейти к следующей инструкции. В результате субскалярный ЦП «зависает» на инструкциях, выполнение которых занимает более одного такта. Даже добавление второго исполнительного блока (см. ниже) не сильно повышает производительность; вместо того, чтобы подвешивать один канал, теперь подвешиваются два канала и увеличивается количество неиспользуемых транзисторов. Эта конструкция, в которой исполнительные ресурсы ЦП могут работать только с одной инструкцией за раз, может достигать только скалярной производительности (одна инструкция за такт, IPC = 1 ). Однако производительность почти всегда субскалярная (менее одной инструкции за такт, IPC < 1 ).
Попытки добиться скалярности и повышения производительности привели к появлению множества методологий проектирования, которые заставляют ЦП вести себя менее линейно и более параллельно. Говоря о параллелизме в процессорах, для классификации этих методов проектирования обычно используются два термина:
- параллелизм на уровне инструкций (ILP), целью которого является увеличение скорости выполнения инструкций внутри ЦП (то есть увеличение использования внутренних ресурсов выполнения);
- параллелизм на уровне задач (TLP), целью которого является увеличение количества потоков или процессов , которые ЦП может выполнять одновременно.
Каждая методология отличается как способами их реализации, так и относительной эффективностью, которую они обеспечивают в увеличении производительности ЦП для приложения. [я]
Параллелизм на уровне инструкций [ править ]

Один из самых простых способов повышения параллелизма — начать первые шаги выборки и декодирования инструкций до того, как закончится выполнение предыдущей инструкции. Это метод, известный как конвейерная обработка инструкций , и он используется почти во всех современных процессорах общего назначения. Конвейерная обработка позволяет одновременно выполнять несколько инструкций, разбивая путь выполнения на дискретные этапы. Это разделение можно сравнить со сборочной линией, на которой инструкция становится более полной на каждом этапе, пока она не выйдет из конвейера выполнения и не будет удалена.
Однако конвейерная обработка создает возможность ситуации, когда результат предыдущей операции необходим для завершения следующей операции; состояние, которое часто называют конфликтом зависимости данных. Следовательно, конвейерные процессоры должны проверять подобные условия и при необходимости задерживать часть конвейера. Конвейерный процессор может стать почти скалярным, чему препятствуют только остановки конвейера (инструкция, затрачивающая более одного тактового цикла на этап).

Улучшения в конвейерной обработке инструкций привели к дальнейшему сокращению времени простоя компонентов ЦП. Конструкции, которые называются суперскалярными, включают длинный конвейер команд и несколько идентичных исполнительных блоков , таких как блоки загрузки-сохранения , арифметико-логические блоки , блоки с плавающей запятой и блоки генерации адреса . [77] В суперскалярном конвейере инструкции считываются и передаются диспетчеру, который решает, могут ли инструкции выполняться параллельно (одновременно). Если это так, они передаются исполнительным модулям, что приводит к их одновременному выполнению. В общем, количество инструкций, которые суперскалярный ЦП выполнит за цикл, зависит от количества инструкций, которые он может одновременно отправить исполнительным модулям.
Основная сложность проектирования суперскалярной архитектуры ЦП заключается в создании эффективного диспетчера. Диспетчер должен иметь возможность быстро определять, могут ли инструкции выполняться параллельно, а также распределять их таким образом, чтобы задействовать как можно больше исполнительных блоков. Это требует, чтобы конвейер инструкций заполнялся как можно чаще, и требует значительных объемов кэша ЦП . Это также делает опасностей такие методы предотвращения , как предсказание ветвей , спекулятивное выполнение , переименование регистров , выполнение вне очереди и транзакционную память, решающими для поддержания высокого уровня производительности. Пытаясь предсказать, по какой ветке (или пути) пойдет условная инструкция, ЦП может минимизировать количество раз, которое весь конвейер должен ждать до завершения условной инструкции. Спекулятивное выполнение часто обеспечивает небольшое увеличение производительности за счет выполнения частей кода, которые могут оказаться ненужными после завершения условной операции. Выполнение вне порядка несколько меняет порядок выполнения инструкций, чтобы уменьшить задержки из-за зависимостей данных. Также в случае один поток инструкций, множественный поток данных , случай, когда необходимо обработать много данных одного типа, современные процессоры могут отключать части конвейера, так что при многократном выполнении одной инструкции ЦП пропускает выборку и декодирование фаз и, таким образом, в определенных случаях значительно увеличивает производительность, особенно в очень монотонных программных движках, таких как программное обеспечение для создания видео и обработки фотографий.
Когда часть ЦП является суперскалярной, та часть, которая не является суперскалярной, испытывает снижение производительности из-за остановок планирования. Intel P5 Pentium имел два суперскалярных ALU, каждый из которых мог принимать одну инструкцию за такт, а его FPU - нет. Таким образом, P5 был целочисленным суперскаляром, но не суперскаляром с плавающей запятой. Преемник архитектуры P5 от Intel, P6 , добавил суперскалярные возможности к своим функциям с плавающей запятой.
Простая конвейерная обработка и суперскалярная конструкция увеличивают ILP процессора, позволяя ему выполнять инструкции со скоростью, превышающей одну инструкцию за такт. Большинство современных процессоров являются, по крайней мере, в некоторой степени суперскалярными, и почти все процессоры общего назначения, разработанные за последнее десятилетие, являются суперскалярными. В последующие годы часть внимания при разработке компьютеров с высоким ILP была перенесена с аппаратного обеспечения ЦП на его программный интерфейс или архитектуру набора команд (ISA). Стратегия очень длинного командного слова (VLIW) приводит к тому, что часть ILP становится подразумеваемой непосредственно программным обеспечением, что сокращает работу ЦП по усилению ILP и тем самым снижает сложность конструкции.
Параллелизм на уровне задач [ править ]
Другая стратегия достижения производительности — выполнение нескольких потоков или процессов параллельное . Эта область исследований известна как параллельные вычисления . [78] В таксономии Флинна эта стратегия известна как множественный поток инструкций, множественный поток данных (MIMD). [79]
Одной из технологий, используемых для этой цели, является многопроцессорная обработка (MP). [80] Первоначальный тип этой технологии известен как симметричная многопроцессорная обработка (SMP), при которой небольшое количество процессоров совместно используют согласованное представление своей системы памяти. В этой схеме каждый ЦП имеет дополнительное оборудование для постоянного поддержания актуального состояния памяти. Избегая устаревшего представления памяти, процессоры могут совместно работать над одной и той же программой, а программы могут мигрировать с одного процессора на другой. Чтобы увеличить количество взаимодействующих процессоров сверх горстки, такие схемы, как неоднородный доступ к памяти (NUMA) и протоколы согласованности на основе каталогов в 1990-х годах были введены . Системы SMP ограничены небольшим количеством процессоров, тогда как системы NUMA построены на тысячах процессоров. Первоначально многопроцессорная обработка была построена с использованием нескольких дискретных процессоров и плат для реализации взаимодействия между процессорами. Когда все процессоры и их соединения реализованы на одном кристалле, эта технология называется многопроцессорной обработкой на уровне чипа (CMP), а один чип — многоядерным процессором .
Позже было признано, что более тонкий параллелизм существует в одной программе. Одна программа может иметь несколько потоков (или функций), которые могут выполняться отдельно или параллельно. Некоторые из самых ранних примеров этой технологии реализовывали обработку ввода/вывода , такую как прямой доступ к памяти, в виде отдельного потока от потока вычислений. Более общий подход к этой технологии был представлен в 1970-х годах, когда системы были спроектированы для параллельного выполнения нескольких вычислительных потоков. Эта технология известна как многопоточность (MT). Этот подход считается более экономичным, чем многопроцессорная обработка, поскольку для поддержки MT реплицируется лишь небольшое количество компонентов внутри ЦП, а не весь ЦП в случае MP. В MT исполнительные блоки и система памяти, включая кэши, совместно используются несколькими потоками. Обратной стороной MT является то, что аппаратная поддержка многопоточности более заметна для программного обеспечения, чем поддержка MP, и поэтому программное обеспечение супервизора, такое как операционные системы, должно претерпевать большие изменения для поддержки MT. Один из реализованных типов MT известен как временная многопоточность , при которой один поток выполняется до тех пор, пока он не остановится в ожидании возврата данных из внешней памяти. В этой схеме ЦП затем быстро переключается на другой поток, который готов к работе, причем переключение часто выполняется за один такт ЦП, например, UltraSPARC T1 . Другой тип MT — одновременная многопоточность , при которой инструкции из нескольких потоков выполняются параллельно в течение одного такта процессора.
В течение нескольких десятилетий, с 1970-х по начало 2000-х годов, основное внимание при разработке высокопроизводительных процессоров общего назначения уделялось в основном достижению высокого уровня ILP за счет таких технологий, как конвейерная обработка, кэширование, суперскалярное выполнение, выполнение вне очереди и т. д. Кульминацией этой тенденции стали крупные , энергоемкие процессоры, такие как Intel Pentium 4 . К началу 2000-х годов разработчики ЦП не смогли добиться более высокой производительности с помощью методов ILP из-за растущего несоответствия между рабочими частотами ЦП и рабочими частотами основной памяти, а также из-за увеличения рассеиваемой мощности ЦП из-за более эзотерических методов ILP.
Затем разработчики процессоров позаимствовали идеи с рынков коммерческих вычислений, таких как обработка транзакций , где совокупная производительность нескольких программ, также известная как пропускная способность вычислений, была более важной, чем производительность одного потока или процесса.
Об этом изменении акцентов свидетельствует распространение двухъядерных и более ядерных процессоров и, в частности, новые разработки Intel, напоминающие менее суперскалярную архитектуру P6 . Поздние разработки в нескольких семействах процессоров демонстрируют CMP, включая x86-64 Opteron и Athlon 64 X2 , SPARC UltraSPARC T1 , IBM POWER4 и POWER5 , а также несколько для игровых консолей, процессоров 360 таких как трехъядерный PowerPC Xbox . и PlayStation 3 7-ядерный микропроцессор Cell .
Параллелизм данных [ править ]
Менее распространенная, но все более важная парадигма процессоров (да и вычислений в целом) связана с параллелизмом данных. Все процессоры, обсуждавшиеся ранее, называются скалярными устройствами определенного типа. [Дж] Как следует из названия, векторные процессоры обрабатывают несколько фрагментов данных в контексте одной инструкции. В этом отличие от скалярных процессоров, которые обрабатывают один фрагмент данных для каждой инструкции. Используя таксономию Флинна , эти две схемы работы с данными обычно называются команд «один поток , множественный поток данных» ( SIMD ) и инструкций «один поток , один поток данных » ( SISD ) соответственно. одной и той же операции (например, суммирования или скалярного произведения Большая полезность создания процессоров, работающих с векторами данных, заключается в оптимизации задач, которые, как правило, требуют выполнения ) над большим набором данных. Некоторые классические примеры задач такого типа включают мультимедийные приложения (изображения, видео и звук), а также многие типы научных и инженерных задач. В то время как скалярный процессор должен завершить весь процесс выборки, декодирования и выполнения каждой инструкции и значения в наборе данных, векторный процессор может выполнить одну операцию над сравнительно большим набором данных с помощью одной инструкции. Это возможно только в том случае, если приложению требуется много шагов, которые применяют одну операцию к большому набору данных.
Большинство ранних векторных процессоров, таких как Cray-1 , были связаны почти исключительно с научными исследованиями и криптографическими приложениями. Однако, поскольку мультимедиа в значительной степени перешла на цифровые носители, потребность в той или иной форме SIMD в процессорах общего назначения стала значительной. Вскоре после того, как включение модулей с плавающей запятой стало обычным явлением в процессорах общего назначения, спецификации и реализации исполнительных блоков SIMD также начали появляться для процессоров общего назначения. [ когда? ] Некоторые из этих ранних спецификаций SIMD, например, HP Multimedia Acceleration eXtensions (MAX) и Intel MMX , были только целочисленными. Это оказалось серьезным препятствием для некоторых разработчиков программного обеспечения, поскольку многие приложения, использующие SIMD, в основном работают с числами с плавающей запятой . Постепенно разработчики усовершенствовали и переделали эти ранние конструкции в некоторые из распространенных современных спецификаций SIMD, которые обычно связаны с архитектурой одного набора команд (ISA). Некоторые известные современные примеры включают Intel Streaming SIMD Extensions связанный с PowerPC (SSE) и AltiVec, (также известный как VMX). [к]
Аппаратный счетчик производительности [ править ]
Многие современные архитектуры (в том числе встроенные) часто включают в себя аппаратные счетчики производительности (HPC), которые позволяют осуществлять низкоуровневый (на уровне инструкций) сбор, тестирование производительности , отладку или анализ показателей запущенного программного обеспечения. [81] [82] HPC также может использоваться для обнаружения и анализа необычной или подозрительной активности программного обеспечения, такой как возвратно-ориентированного программирования (ROP) или sigreturn-ориентированного программирования (SROP) и т. д. эксплойты [83] Обычно это делают группы по безопасности программного обеспечения для оценки и обнаружения вредоносных двоичных программ. [84]
Многие крупные поставщики (такие как IBM , Intel , AMD и Arm ЦП ) предоставляют программные интерфейсы (обычно написанные на C/C++), которые можно использовать для сбора данных из регистров с целью получения показателей. [85] Поставщики операционных систем также предоставляют такое программное обеспечение, как perf (Linux) для записи, тестирования или отслеживания событий ЦП, запускающих ядра и приложения.
Аппаратные счетчики обеспечивают малозатратный метод сбора комплексных показателей производительности, связанных с основными элементами ЦП (функциональными блоками, кэшами, основной памятью и т. д.), что является значительным преимуществом перед программными профилировщиками. [86] Кроме того, они обычно устраняют необходимость изменять исходный код программы. [87] [88] Поскольку конструкции аппаратного обеспечения различаются в зависимости от архитектуры, конкретные типы и интерпретации аппаратных счетчиков также изменятся.
Привилегированные режимы [ править ]
Большинство современных процессоров имеют привилегированные режимы для поддержки операционных систем и виртуализации.
Облачные вычисления могут использовать виртуализацию для предоставления виртуальных центральных процессоров. [89] ( vCPU ) для отдельных пользователей. [90]
Хост — это виртуальный эквивалент физической машины, на которой работает виртуальная система. [91] Когда несколько физических машин работают в тандеме и управляются как единое целое, сгруппированные вычислительные ресурсы и ресурсы памяти образуют кластер . В некоторых системах можно динамически добавлять и удалять кластер. Ресурсы, доступные на уровне хоста и кластера, можно разделить на пулы ресурсов с высокой степенью детализации .
Производительность [ править ]
Производительность скорость или ) и количества инструкций за такт ( IPC процессора зависит, среди многих других факторов, от тактовой частоты (обычно измеряемой в герцах ), которые вместе являются факторами для количества инструкций в секунду (IPS), которые ЦП может работать. [92] Многие заявленные значения IPS представляют собой «пиковую» скорость выполнения искусственных последовательностей инструкций с небольшим количеством ветвей, тогда как реальные рабочие нагрузки состоят из смеси инструкций и приложений, выполнение некоторых из которых занимает больше времени, чем других. Производительность иерархии памяти также сильно влияет на производительность процессора, и эта проблема почти не учитывается при расчетах IPS. Из-за этих проблем были разработаны различные стандартизированные тесты, часто называемые для этой цели «эталонными тестами» , такие как SPECint , чтобы попытаться измерить реальную эффективную производительность в часто используемых приложениях.
Производительность обработки компьютеров увеличивается за счет использования многоядерных процессоров , что по сути означает подключение двух или более отдельных процессоров ( называемых ядрами ) в одну интегральную схему. в этом смысле [93] В идеале двухъядерный процессор должен быть почти в два раза мощнее одноядерного. На практике прирост производительности гораздо меньше, всего около 50%, из-за несовершенства программных алгоритмов и реализации. [94] Увеличение количества ядер в процессоре (т. е. двухъядерных, четырехъядерных и т. д.) увеличивает рабочую нагрузку, с которой можно справиться. Это означает, что процессор теперь может обрабатывать многочисленные асинхронные события, прерывания и т. д., которые могут нанести ущерб процессору при перегрузке. Эти ядра можно рассматривать как разные этажи перерабатывающего завода, где каждый этаж выполняет свою задачу. Иногда эти ядра будут выполнять те же задачи, что и соседние с ними ядра, если одного ядра недостаточно для обработки информации. Многоядерные процессоры расширяют возможности компьютера одновременно выполнять несколько задач, обеспечивая дополнительную вычислительную мощность. Однако прирост скорости не прямо пропорционален количеству добавленных ядер. Это связано с тем, что ядрам необходимо взаимодействовать через определенные каналы, и эта связь между ядрами потребляет часть доступной скорости обработки. [95]
Из-за специфических возможностей современных процессоров, таких как одновременная многопоточность и uncore , которые предполагают совместное использование реальных ресурсов процессора с целью повышения их использования, мониторинг уровней производительности и использования оборудования постепенно стал более сложной задачей. [96] В ответ некоторые ЦП реализуют дополнительную аппаратную логику, которая отслеживает фактическое использование различных частей ЦП и предоставляет различные счетчики, доступные программному обеспечению; примером является технология Intel Performance Counter Monitor . [9]
См. также [ править ]
- Режим адресации
- Ускоренный процессор AMD
- Компьютер со сложным набором команд
- Компьютерный автобус
- Компьютерная инженерия
- Напряжение ядра процессора
- разъем процессора
- Блок обработки данных
- Цифровой сигнальный процессор
- Графический процессор
- Сравнение архитектур наборов команд
- Защитное кольцо
- Компьютер с сокращенным набором команд
- Потоковая обработка
- Истинный индекс производительности
- Тензорный процессор
- Состояние ожидания
Примечания [ править ]
- ^ Интегральные схемы теперь используются для реализации всех процессоров, за исключением нескольких машин, предназначенных для выдерживания сильных электромагнитных импульсов, например, от ядерного оружия.
- ↑ В так называемой записке «фон Неймана» изложена идея хранимых программ. [65] которые, например, могут храниться на перфокартах , бумажной или магнитной ленте.
- ^ Некоторые ранние компьютеры, такие как Harvard Mark I, не поддерживали никаких инструкций «перехода», что эффективно ограничивало сложность программ, которые они могли запускать. Во многом по этой причине часто считается, что эти компьютеры не содержат полноценного ЦП, несмотря на их близкое сходство с компьютерами с хранимыми программами.
- ^ Поскольку счетчик программ считает адреса памяти , а не инструкции , он увеличивается на количество единиц памяти, содержащихся в командном слове. В случае простых командных слов фиксированной длины ISA это всегда один и тот же номер. Например, 32-битное командное слово ISA фиксированной длины, использующее 8-битные слова памяти, всегда будет увеличивать PC на четыре (за исключением случаев переходов). ISA, которые используют командные слова переменной длины, увеличивают ПК на количество слов памяти, соответствующее длине последней инструкции.
- ^ Поскольку архитектура набора команд ЦП имеет основополагающее значение для его интерфейса и использования, она часто используется для классификации «типа» ЦП. Например, «ЦП PowerPC» использует некоторый вариант PowerPC ISA. Система может выполнять другую ISA, запустив эмулятор.
- ^ Некоторые специализированные процессоры, ускорители или микроконтроллеры не имеют кэша. Чтобы быть быстрыми, если это необходимо/желательно, у них все еще есть встроенная блокнотная память, которая имеет аналогичную функцию, хотя и управляется программным обеспечением. Например, в микроконтроллерах для жесткого использования в режиме реального времени может быть лучше иметь такой кэш или, по крайней мере, не иметь его, поскольку при одном уровне памяти задержки при загрузке предсказуемы.
- ^ Физическая концепция напряжения по своей природе является аналоговой и практически имеет бесконечный диапазон возможных значений. Для физического представления двоичных чисел определены два конкретных диапазона напряжений: один для логического «0», а другой для логической «1». Эти диапазоны продиктованы конструктивными соображениями, такими как запас шума и характеристики устройств, используемых для создания ЦП.
- ^ Хотя целочисленный размер ЦП устанавливает ограничение на целочисленные диапазоны, это можно (и часто) преодолеть с помощью комбинации программных и аппаратных методов. Используя дополнительную память, программное обеспечение может представлять целые числа, во много раз превышающие возможности ЦП. ЦП Иногда набор инструкций даже облегчает операции с целыми числами, большими, чем он может представить изначально, предоставляя инструкции для относительно быстрого выполнения арифметических операций с большими целыми числами. Этот метод работы с большими целыми числами медленнее, чем использование ЦП с большим размером целых чисел, но является разумным компромиссом в тех случаях, когда нативная поддержка полного необходимого диапазона целых чисел была бы непомерно затратной. см. в разделе Арифметика произвольной точности . Дополнительные сведения о целых числах произвольного размера, поддерживаемых программным обеспечением,
- ^ Ни ILP , ни TLP по своей сути не превосходят друг друга; это просто разные средства повышения параллелизма ЦП. Таким образом, у них обоих есть преимущества и недостатки, которые часто определяются типом программного обеспечения, для работы которого предназначен процессор. Процессоры с высоким уровнем TLP часто используются в приложениях, которые хорошо поддаются разбиению на множество более мелких приложений, в так называемых « затруднительно параллельных задачах». Часто вычислительная задача, которую можно быстро решить с помощью стратегий проектирования с высоким уровнем TLP, таких как симметричная многопроцессорная обработка, требует значительно больше времени на устройствах с высоким уровнем ILP, таких как суперскалярные процессоры, и наоборот.
- ^ Ранее термин скаляр использовался для сравнения количества IPC, полученного различными методами ILP. Здесь этот термин используется в строго математическом смысле, в отличие от векторов. См. скаляр (математика) и вектор (геометрический) .
- ^ Хотя SSE/SSE2/SSE3 заменили MMX в процессорах Intel общего назначения, более поздние конструкции IA-32 по-прежнему поддерживают MMX. Обычно это достигается путем предоставления большей части функций MMX на том же оборудовании, которое поддерживает гораздо более обширные наборы инструкций SSE.
Ссылки [ править ]
- ^ Команда, Эксперт YCT. Инженерный чертеж и фундаментальная наука . Время молодежных соревнований. п. 425.
- ^ Нагпал, ДП (2008). Основы компьютера . Издательство С. Чанд. п. 33. ISBN 978-81-219-2388-0 .
- ^ «Что такое процессор (ЦП)? Определение с сайта WhatIs.com» . Что такое . Проверено 15 марта 2024 г.
- ^ Чесалов, Александр (12 апреля 2023 г.). Глоссарий четвертой промышленной революции: более 1500 самых популярных терминов, которые вы будете использовать, чтобы создавать будущее . Литры. ISBN 978-5-04-541163-9 .
- ^ Джагаре, Ульрика (19 апреля 2022 г.). Управление искусственным интеллектом: преодоление разрыва между технологиями и бизнесом . Джон Уайли и сыновья. ISBN 978-1-119-83321-5 .
- ^ Кук, Дэвид (1978). Компьютеры и вычисления, Том 1 . John Wiley & Sons, Inc. с. 12. ISBN 978-0471027164 .
- ^ Прабхат, команда (13 апреля 2023 г.). Полное руководство по комбинированным предварительным и основным экзаменам SSC CGL для выпускников уровней Tier-I и Tier II (с последними решенными вопросами) Путеводитель на английском языке: книга-бестселлер от Team Prabhat: Полное руководство по комбинированным отборочным экзаменам SSC CGL для выпускников уровней Tier-I и Tier II и Сетевой путеводитель (с последними решенными вопросами) на английском языке . Прабхат Пракашан. п. 95. ИСБН 978-93-5488-527-3 .
- ^ «Что такое многоядерный процессор и как он работает?» . Дата-центр . Проверено 15 марта 2024 г.
- ↑ Перейти обратно: Перейти обратно: а б Уиллхальм, Томас; Дементьев Роман; Фэй, Патрик (18 декабря 2014 г.). «Intel Performance Counter Monitor — лучший способ измерения загрузки ЦП» . программное обеспечение.intel.com . Архивировано из оригинала 22 февраля 2017 года . Проверено 17 февраля 2015 г.
- ^ Херрес, Дэвид (06 октября 2020 г.). Осциллографы: Руководство для студентов, инженеров и ученых . Спрингер Природа. п. 130. ИСБН 978-3-030-53885-9 .
- ^ Риган, Джерард (2008). Краткая история вычислений . Спрингер. п. 66. ИСБН 978-1848000834 . Проверено 26 ноября 2014 г.
- ^ Вейк, Мартин Х. (1955). «Обзор отечественных электронных цифровых вычислительных систем» . Лаборатория баллистических исследований . Архивировано из оригинала 26 января 2021 г. Проверено 15 ноября 2020 г.
- ↑ Перейти обратно: Перейти обратно: а б Вейк, Мартин Х. (1961). «Третий обзор отечественных электронных цифровых вычислительных систем» . Веб-сайт Nike Missile Эда Телена . Лаборатория баллистических исследований . Архивировано из оригинала 11 сентября 2017 г. Проверено 16 декабря 2005 г.
- ^ «По крупицам» . Хаверфордский колледж. Архивировано из оригинала 13 октября 2012 года . Проверено 1 августа 2015 г.
- ^ Первый проект отчета о EDVAC (PDF) (Технический отчет). электротехники Мура Школа Пенсильванского университета . 1945. Архивировано (PDF) из оригинала 9 марта 2021 г. Проверено 31 марта 2018 г.
- ^ Стэнфордский университет. «Современная история вычислительной техники» . Стэнфордская энциклопедия философии . Проверено 25 сентября 2015 г.
- ^ «День рождения ЭНИАКа» . Массачусетский технологический институт Пресс. 9 февраля 2016. Архивировано из оригинала 17 октября 2018 года . Проверено 17 октября 2018 г.
- ^ Энтикнап, Николас (лето 1998 г.), «Золотой юбилей компьютеров» , Resurrection (20), The Computer Conservation Society, ISSN 0958-7403 , заархивировано из оригинала 17 марта 2019 г. , получено 26 июня 2019 г.
- ^ «Манчестер Марк 1» . Манчестерский университет . Архивировано из оригинала 25 января 2015 года . Проверено 25 сентября 2015 г.
- ^ «Первое поколение» . Музей истории компьютеров. Архивировано из оригинала 22 ноября 2016 года . Проверено 29 сентября 2015 г.
- ^ «История интегральной схемы» . Нобелевская премия.org . Архивировано из оригинала 22 мая 2022 года . Проверено 17 июля 2022 г.
- ^ Терли, Джим (11 августа 2003 г.). «Автомобилестроение с микропроцессорами» . Встроенный. Архивировано из оригинала 14 октября 2022 года . Проверено 26 декабря 2022 г.
- ^ «Руководство по мобильным процессорам – лето 2013 г.» . Android-авторитет. 25 июня 2013 г. Архивировано из оригинала 17 ноября 2015 г. Проверено 15 ноября 2015 г.
- ^ «Раздел 250: Микропроцессоры и игрушки: введение в вычислительные системы» . Мичиганский университет. Архивировано из оригинала 13 апреля 2021 года . Проверено 9 октября 2018 г.
- ^ «Процессор ARM946» . РУКА. Архивировано из оригинала 17 ноября 2015 года.
- ^ «Конрад Цузе» . Музей истории компьютеров. Архивировано из оригинала 3 октября 2016 года . Проверено 29 сентября 2015 г.
- ^ «Хронология компьютерной истории: компьютеры» . Музей истории компьютеров. Архивировано из оригинала 29 декабря 2017 года . Проверено 21 ноября 2015 г.
- ^ Уайт, Стивен. «Краткая история вычислительной техники – компьютеры первого поколения» . Архивировано из оригинала 2 января 2018 года . Проверено 21 ноября 2015 г.
- ^ «Дырокол для бумажной ленты Mark I Гарвардского университета» . Музей истории компьютеров. Архивировано из оригинала 22 ноября 2015 года . Проверено 21 ноября 2015 г.
- ^ «В чем разница между архитектурой фон Неймана и архитектурой Гарварда?» . РУКА. Архивировано из оригинала 18 ноября 2015 года . Проверено 22 ноября 2015 г.
- ^ «Передовая архитектура оптимизирует процессор Atmel AVR» . Атмел. Архивировано из оригинала 14 ноября 2015 года . Проверено 22 ноября 2015 г.
- ^ «Переключатели, транзисторы и реле» . Би-би-си. Архивировано из оригинала 5 декабря 2016 года.
- ^ «Представляем вакуумный транзистор: устройство, сделанное из ничего» . IEEE-спектр . 23 июня 2014 г. Архивировано из оригинала 23 марта 2018 г. Проверено 27 января 2019 г.
- ^ Что такое производительность компьютера? . Пресса национальных академий. 2011. дои : 10.17226/12980 . ISBN 978-0-309-15951-7 . Архивировано из оригинала 5 июня 2016 года . Проверено 16 мая 2016 г.
- ^ «1953: Появление транзисторных компьютеров» . Музей истории компьютеров . Архивировано из оригинала 1 июня 2016 года . Проверено 3 июня 2016 г.
- ^ «Даты и характеристики IBM System/360» . ИБМ. 23 января 2003 г. Архивировано из оригинала 21 ноября 2017 г. Проверено 13 января 2016 г.
- ↑ Перейти обратно: Перейти обратно: а б Амдал, генеральный директор ; Блаув, Джорджия ; Брукс, Ф.П. младший (апрель 1964 г.). «Архитектура IBM System/360». Журнал исследований и разработок IBM . 8 (2). ИБМ : 87–101. дои : 10.1147/rd.82.0087 . ISSN 0018-8646 .
- ^ Бродкин, Джон (7 апреля 2014 г.). «50 лет назад IBM создала мэйнфрейм, который помог отправить людей на Луну» . Арс Техника . Архивировано из оригинала 8 апреля 2016 года . Проверено 9 апреля 2016 г.
- ^ Кларк, Гэвин. «Почему вы не умрете? IBM S/360 и ее наследие в 50 лет» . Регистр . Архивировано из оригинала 24 апреля 2016 года . Проверено 9 апреля 2016 г.
- ^ «Интернет-домашняя страница PDP-8, запуск PDP-8» . ПРП8 . Архивировано из оригинала 11 августа 2015 года . Проверено 25 сентября 2015 г.
- ^ «Транзисторы, реле и управление сильноточными нагрузками» . Нью-Йоркский университет . ITP Физические вычисления. Архивировано из оригинала 21 апреля 2016 года . Проверено 9 апреля 2016 г.
- ^ Лилли, Пол (14 апреля 2009 г.). «Краткая история процессоров: 31 потрясающий год x86» . ПК-геймер . Архивировано из оригинала 13 июня 2016 г. Проверено 15 июня 2016 г.
- ↑ Перейти обратно: Перейти обратно: а б Паттерсон, Дэвид А.; Хеннесси, Джон Л.; Ларус, Джеймс Р. (1999). Компьютерная организация и дизайн: аппаратно-программный интерфейс (3-е издание 2-го изд.). Сан-Франциско, Калифорния: Кауфманн. п. 751 . ISBN 978-1558604285 .
- ^ «1962: Аэрокосмические системы — первые приложения для микросхем в компьютерах» . Музей истории компьютеров . Архивировано из оригинала 5 октября 2018 года . Проверено 9 октября 2018 г.
- ^ «Интегральные схемы в программе пилотируемой посадки на Луну «Аполлон»» . Национальное управление по аэронавтике и исследованию космического пространства. Архивировано из оригинала 21 июля 2019 года . Проверено 9 октября 2018 г.
- ^ «Объявление системы/370» . Архивы IBM . 23 января 2003 г. Архивировано из оригинала 20 августа 2018 г. Проверено 25 октября 2017 г.
- ^ «Система/370, модель 155 (продолжение)» . Архивы IBM . 23 января 2003 г. Архивировано из оригинала 20 июля 2016 г. Проверено 25 октября 2017 г.
- ^ «Модели и опции» . Корпорация цифрового оборудования PDP-8. Архивировано из оригинала 26 июня 2018 года . Проверено 15 июня 2018 г.
- ^ Бассетт, Росс Нокс (2007). В эпоху цифровых технологий: исследовательские лаборатории, стартапы и развитие MOS-технологий . Издательство Университета Джонса Хопкинса . стр. 127–128, 256 и 314. ISBN. 978-0-8018-6809-2 .
- ↑ Перейти обратно: Перейти обратно: а б Ширрифф, Кен. «Texas Instruments TMX 1795: первый, забытый микропроцессор» . Архивировано из оригинала 26 января 2021 г.
- ^ «Скорость и мощность в логических семействах» . Архивировано из оригинала 26 июля 2017 г. Проверено 2 августа 2017 г. .
- ^ Стонхэм, Ти Джей (1996). Методы цифровой логики: принципы и практика . Тейлор и Фрэнсис. п. 174. ИСБН 9780412549700 .
- ^ «1968: Разработана технология кремниевых затворов для микросхем» . Музей истории компьютеров . Архивировано из оригинала 29 июля 2020 г. Проверено 16 августа 2019 г.
- ^ Бухер, РК (1968). Компьютер MOS GP (PDF) . Международный семинар по управлению знаниями в области требований. АФИПС . п. 877. дои : 10.1109/AFIPS.1968.126 . Архивировано (PDF) из оригинала 14 июля 2017 г.
- ^ «Описание модуля LSI-11». Руководство пользователя LSI-11, PDP-11/03 (PDF) (2-е изд.). Мейнард, Массачусетс: Корпорация цифрового оборудования . Ноябрь 1975 г. с. 4-3. Архивировано (PDF) из оригинала 10 октября 2021 г. Проверено 20 февраля 2015 г.
- ^ Бигелоу, Стивен Дж. (март 2022 г.). «Что такое многоядерный процессор и как он работает?» . ТехТаржет. Архивировано из оригинала 11 июля 2022 года . Проверено 17 июля 2022 г.
- ^ Биркби, Ричард. «Краткая история микропроцессора» . www.computermuseum.li . Архивировано из оригинала 23 сентября 2015 года . Проверено 13 октября 2015 г.
- ^ Осборн, Адам (1980). Введение в микрокомпьютеры . Том. 1: Основные понятия (2-е изд.). Беркли, Калифорния: Осборн-МакГроу Хилл. ISBN 978-0-931988-34-9 .
- ^ Жислина, Виктория (19 февраля 2014 г.). «Почему частота процессора перестала расти?» . Интел. Архивировано из оригинала 21 июня 2017 г. Проверено 14 октября 2015 г.
- ^ «МОП-транзистор – электротехника и информатика» (PDF) . Калифорнийский университет. Архивировано (PDF) из оригинала 9 октября 2022 г. Проверено 14 октября 2015 г.
- ^ Симонит, Том. «Закон Мура мертв. Что теперь?» . Обзор технологий Массачусетского технологического института . Архивировано из оригинала 22 августа 2018 г. Проверено 24 августа 2018 г.
- ^ Мур, Гордон (2005). «Отрывки из разговора с Гордоном Муром: закон Мура» (PDF) (интервью). Интел. Архивировано из оригинала (PDF) 29 октября 2012 г. Проверено 25 июля 2012 г.
- ^ «Подробная история процессора» . Технический наркоман. 15 декабря 2016 года. Архивировано из оригинала 14 августа 2019 года . Проверено 14 августа 2019 г.
- ^ Эйгенманн, Рудольф; Лилья, Дэвид (1998). «Компьютеры фон Неймана». Энциклопедия электротехники и электроники Wiley . дои : 10.1002/047134608X.W1704 . ISBN 047134608X . S2CID 8197337 .
- ^ Эспрей, Уильям (сентябрь 1990 г.). «Концепция хранимой программы». IEEE-спектр . Том. 27, нет. 9. с. 51. дои : 10.1109/6.58457 .
- ^ Сарасват, Кришна. «Тенденции в технологии интегральных микросхем» (PDF) . Архивировано из оригинала (PDF) 24 июля 2015 г. Проверено 15 июня 2018 г.
- ^ «Электромиграция» . Ближневосточный технический университет. Архивировано из оригинала 31 июля 2017 года . Проверено 15 июня 2018 г.
- ^ Винанд, Ян (3 сентября 2013 г.). «Информатика снизу вверх, Глава 3. Компьютерная архитектура» (PDF) . Botuppcs.com . Архивировано (PDF) из оригинала 6 февраля 2016 г. Проверено 7 января 2015 г.
- ^ «Введение в блок управления и его конструкция» . Гики для Гиков . 24 сентября 2018 г. Архивировано из оригинала 15 января 2021 г. Проверено 12 января 2021 г.
- ^ Ван Беркель, Корнелис; Мейвиссен, Патрик (12 января 2006 г.). «Блок генерации адреса для процессора (заявка на патент США 2006010255 А1)» . гугл.com . Архивировано из оригинала 18 апреля 2016 года . Проверено 8 декабря 2014 г. [ нужна проверка ]
- ^ Торрес, Габриэль (12 сентября 2007 г.). «Как работает кэш-память» . Аппаратные секреты . Проверено 29 января 2023 г.
- ^ «Техническое введение IBM z13 и IBM z13s» (PDF) . ИБМ . Март 2016. с. 20. Архивировано (PDF) из оригинала 9 октября 2022 г. [ нужна проверка ]
- ^ Браун, Джеффри (2005). «Разработка процессора, адаптированная к приложениям» . IBM DeveloperWorks. Архивировано из оригинала 12 февраля 2006 г. Проверено 17 декабря 2005 г.
- ^ Мартин, Эй Джей; Нистром, М.; Вонг, CG (ноябрь 2003 г.). «Три поколения асинхронных микропроцессоров» . IEEE Проектирование и тестирование компьютеров . 20 (6): 9–17. дои : 10.1109/MDT.2003.1246159 . ISSN 0740-7475 . S2CID 15164301 . Архивировано из оригинала 3 декабря 2021 г. Проверено 5 января 2022 г.
- ^ Гарсайд, доктор медицинских наук; Фурбер, С.Б.; Чунг, С.Х. (1999). «Раскрытие AMULET3» . Труды Пятого международного симпозиума по перспективным исследованиям в области асинхронных цепей и систем . Манчестерского университета Факультет компьютерных наук . дои : 10.1109/ASYNC.1999.761522 . Архивировано из оригинала 10 декабря 2005 года.
- ^ Функциональные характеристики IBM System/360 Model 65 (PDF) . ИБМ . Сентябрь 1968. стр. 8–9. А22-6884-3. Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Хьюнь, Джек (2003). «Процессор AMD Athlon XP с кэшем второго уровня объемом 512 КБ» (PDF) . Урбана-Шампейн, Иллинойс: Университет Иллинойса. стр. 6–11. Архивировано из оригинала (PDF) 28 ноября 2007 г. Проверено 6 октября 2007 г.
- ^ Готлиб, Аллан; Алмаси, Джордж С. (1989). Высокопараллельные вычисления . Редвуд-Сити, Калифорния: Бенджамин/Каммингс. ISBN 978-0-8053-0177-9 . Архивировано из оригинала 07.11.2018 . Проверено 25 апреля 2016 г.
- ^ Флинн, MJ (сентябрь 1972 г.). «Некоторые компьютерные организации и их эффективность». Транзакции IEEE на компьютерах . С-21 (9): 948–960. дои : 10.1109/TC.1972.5009071 . S2CID 18573685 .
- ^ Лу, Н.-П.; Чунг, К.-П. (1998). «Использование параллелизма в суперскалярной многопроцессорной обработке». Труды IEE - Компьютеры и цифровая техника . 145 (4): 255. doi : 10.1049/ip-cdt:19981955 .
- ^ Усадел, Лейф; Жорж, Энди; Вербауведе, Ингрид (август 2008 г.). Использование аппаратных счетчиков производительности . 2008 г. 5-й семинар по диагностике ошибок и устойчивости в криптографии. стр. 59–67. дои : 10.1109/FDTC.2008.19 . ISBN 978-0-7695-3314-8 . S2CID 1897883 . Архивировано из оригинала 30 декабря 2021 г. Проверено 30 декабря 2021 г.
- ^ Роху, Эрвен (сентябрь 2012 г.). Tiptop: счетчики производительности оборудования для масс . 2012 г. 41-я Международная конференция по параллельной обработке. стр. 404–413. дои : 10.1109/ICPPW.2012.58 . ISBN 978-1-4673-2509-7 . S2CID 16160098 . Архивировано из оригинала 30 декабря 2021 г. Проверено 30 декабря 2021 г.
- ^ Герат, Нишад; Фог, Андерс (2015). «Счетчики производительности оборудования ЦП для обеспечения безопасности» (PDF) . США: Блэк Хэт. Архивировано (PDF) из оригинала 5 сентября 2015 г.
- ^ Ёсанг, Аудун (21 июня 2018 г.). ECCWS 2018 17-я Европейская конференция по кибервойне и безопасности V2 . Научные конференции и публикации ограничены. ISBN 978-1-911218-86-9 .
- ^ ДеРоуз, Луис А. (2001), Сакеллариу, Ризос; Гурд, Джон; Фриман, Лен; Кин, Джон (ред.), «Набор инструментов для мониторинга производительности оборудования» , Параллельная обработка Euro-Par 2001 , Конспекты лекций по информатике, том. 2150, Берлин, Гейдельберг: Springer Berlin Heidelberg, стр. 122–132, doi : 10.1007/3-540-44681-8_19 , ISBN 978-3-540-42495-6 , заархивировано из оригинала 01 марта 2023 г. , получено 30 декабря 2021 г.
- ^ «К ЭТАЛОНУ ДЛЯ ОЦЕНКИ ПРОИЗВОДИТЕЛЬНОСТИ И ЭНЕРГОПОТРЕБЛЕНИЯ ИНТЕРФЕЙСОВ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ» (PDF) (на вьетнамском языке) . Проверено 15 марта 2024 г.
- ^ «Открытый исходный код: что это значит, как это работает, пример» . Инвестопедия . Проверено 15 марта 2024 г.
- ^ Чаудхури, Тарун Кумар; Банерджи, Джоянта; Гупта, Випул; Поддар, Дебопам (04 марта 2024 г.). Освоение безопасных приложений Java: управление безопасностью в облаке и микросервисах для Java (английское издание). Публикации БПБ. п. 117. ИСБН 978-93-5551-884-2 .
- ^ Анджум, Бушра; Перрос, Гарри Г. (2015). «1: Разделение бюджета сквозного QoS на домены» . Распределение полосы пропускания для видео при ограничениях качества обслуживания . Серия «Фокус». Джон Уайли и сыновья. п. 3. ISBN 9781848217461 . Проверено 21 сентября 2016 г.
[...] в облачных вычислениях, где несколько программных компонентов работают в виртуальной среде на одном и том же блейде, по одному компоненту на виртуальную машину (ВМ). Каждой виртуальной машине выделяется виртуальный центральный процессор [...], который составляет часть ЦП блейда.
- ^ Файфилд, Том; Флеминг, Дайан; Нежно, Энн; Хохштейн, Лорин; Пру, Джонатан; Тэйвс, Эверетт; Топджиан, Джо (2014). «Глоссарий» . Руководство по работе с OpenStack . Пекин: O'Reilly Media, Inc., с. 286. ИСБН 9781491906309 . Проверено 20 сентября 2016 г.
Виртуальный центральный процессор (vCPU)[:] Разделяет физические процессоры. Затем экземпляры могут использовать эти подразделения.
- ^ «Обзор архитектуры инфраструктуры VMware — технический документ» (PDF) . ВМваре . 2006. Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ «Частота процессора» . Мировой глоссарий процессоров . Мир процессоров. 25 марта 2008 г. Архивировано из оригинала 9 февраля 2010 г. Проверено 1 января 2010 г.
- ^ «Что такое многоядерный процессор?» . Определения центров обработки данных . SearchDataCenter.com. Архивировано из оригинала 5 августа 2010 года . Проверено 8 августа 2016 г.
- ^ Мблевинс (8 апреля 2010 г.). «Четырехъядерный против двухъядерного» . Технический дух . Архивировано из оригинала 4 июля 2019 года . Проверено 7 ноября 2019 г.
- ^ Марцин, Вецлав (12 января 2022 г.). «Факторы, влияющие на производительность многоядерных процессоров» . ПКСайт .
- ^ Тегтмайер, Мартин. «Объяснение использования ЦП в многопоточных архитектурах» . Оракул. Архивировано из оригинала 18 июля 2022 года . Проверено 17 июля 2022 г.