Большие данные

Большие данные в первую очередь относятся к наборам данных , которые слишком велики или сложны, чтобы с ними можно было справиться с помощью традиционного для обработки данных прикладного программного обеспечения . Данные с большим количеством записей (строк) обеспечивают большую статистическую мощность , тогда как данные с более высокой сложностью (больше атрибутов или столбцов) могут привести к более высокому уровню ложного обнаружения . [2] Несмотря на то, что термин иногда используется небрежно, отчасти из-за отсутствия формального определения, лучшая интерпретация состоит в том, что это большой объем информации, который невозможно понять, если использовать его только в небольших количествах. [3]
Задачи анализа больших данных включают сбор данных , хранение данных , анализ данных , поиск, совместное использование , передачу , визуализацию , запросы , обновление, конфиденциальность информации и источник данных. Первоначально большие данные ассоциировались с тремя ключевыми понятиями: объем , разнообразие и скорость . [4] При анализе больших данных возникают проблемы с выборкой, поэтому раньше можно было использовать только наблюдения и выборку. Таким образом, четвертое понятие, достоверность, относится к качеству или полноте данных. [5] Без достаточных инвестиций в экспертные знания, необходимые для обеспечения достоверности больших данных, объем и разнообразие данных могут привести к затратам и рискам, которые превышают возможности организации по созданию и извлечению ценности из больших данных . [6]
Текущее использование термина « большие данные» , как правило, относится к использованию прогнозной аналитики , анализа поведения пользователей или некоторых других передовых методов анализа данных, которые извлекают ценность из больших данных и редко из набора данных определенного размера. «Нет никаких сомнений в том, что объемы доступных сейчас данных действительно велики, но это не самая важная характеристика этой новой экосистемы данных». [7] Анализ наборов данных может найти новые корреляции для «выявления бизнес-тенденций, предотвращения заболеваний, борьбы с преступностью и так далее». [8] Ученые, руководители предприятий, практикующие врачи, рекламщики и правительства регулярно сталкиваются с трудностями при работе с большими наборами данных в таких областях, как поиск в Интернете , финансовые технологии , медицинская аналитика, географические информационные системы, городская информатика и бизнес-информатика . Ученые сталкиваются с ограничениями в работе в области электронных наук , включая метеорологию , геномику , [9] коннектомика , сложное физическое моделирование, биология и исследования окружающей среды. [10]
Размер и количество доступных наборов данных быстро растут, поскольку данные собираются с помощью таких устройств, как мобильные устройства , воспринимающие информацию , дешевые и многочисленные устройства Интернета вещей , воздушное оборудование ( дистанционного зондирования ), журналы программного обеспечения, камеры , микрофоны, радиочастоты. считыватели идентификации (RFID) и беспроводные сенсорные сети . [11] [12] С 1980-х годов мировая технологическая способность хранить информацию на душу населения примерно удваивалась каждые 40 месяцев; [13] по состоянию на 2012 год [update], каждый день 2,5 экзабайта (2,17×2 60 байт) данных. [14] Согласно прогнозу отчета IDC , глобальный объем данных будет расти экспоненциально с 4,4 зеттабайта до 44 зеттабайт в период с 2013 по 2020 год. По прогнозам IDC, к 2025 году объем данных составит 163 зеттабайта. [15] По данным IDC, глобальные расходы на решения для больших данных и бизнес-аналитики (BDA) в 2021 году достигнут $215,7 млрд. [16] [17] По данным Statista , к 2027 году мировой рынок больших данных вырастет до 103 миллиардов долларов. [18] В 2011 году компания McKinsey & Company сообщила, что если бы здравоохранение США творчески и эффективно использовало большие данные для повышения эффективности и качества, этот сектор мог бы приносить более 300 миллиардов долларов прибыли каждый год. [19] В развитых странах Европы государственные администраторы могли бы сэкономить более 100 миллиардов евро (149 миллиардов долларов США) только на повышении операционной эффективности за счет использования больших данных. [19] А пользователи услуг, основанных на данных о личном местоположении, могут получить потребительский излишек в размере 600 миллиардов долларов. [19] Одним из вопросов для крупных предприятий является определение того, кому следует принадлежать инициативы в области больших данных, которые влияют на всю организацию. [20]
Системы управления реляционными базами данных и пакеты настольного статистического программного обеспечения, используемые для визуализации данных, часто сталкиваются с трудностями при обработке и анализе больших данных. Обработка и анализ больших данных может потребовать «массово параллельного программного обеспечения, работающего на десятках, сотнях или даже тысячах серверов». [21] То, что квалифицируется как «большие данные», варьируется в зависимости от возможностей тех, кто их анализирует, и их инструментов. Более того, расширяющиеся возможности делают большие данные движущейся целью. столкнувшихся с сотнями гигабайт данных, может возникнуть необходимость пересмотреть варианты управления данными. Для других могут пройти десятки или сотни терабайт, прежде чем размер данных станет значимым фактором». «Для некоторых организаций, впервые [22]
Определение
[ редактировать ]Термин « большие данные» используется с 1990-х годов, причем некоторые отдают должное Джону Мэши за популяризацию этого термина. [23] [24] Большие данные обычно включают наборы данных, размер которых превышает возможности широко используемых программных инструментов для сбора , хранения , управления и обработки данных в течение приемлемого прошедшего времени. [25] [ нужна страница ] Философия больших данных включает в себя неструктурированные, полуструктурированные и структурированные данные; однако основное внимание уделяется неструктурированным данным. [26] «Размер» больших данных — это постоянно меняющаяся цель; по состоянию на 2012 год [update] от нескольких десятков терабайт до многих зеттабайт данных. [27] Большие данные требуют набора методов и технологий с новыми формами интеграции, позволяющими получать ценную информацию из наборов данных , которые разнообразны, сложны и имеют огромные масштабы. [28]
«Объем», «разнообразие», «скорость» и различные другие буквы «V» добавляются некоторыми организациями для описания этого изменения, которое оспаривается некоторыми отраслевыми властями. [29] Против больших данных часто называют «три против», «четыре против» и «пять против». Они отражали качества больших данных по объему, разнообразию, скорости, достоверности и ценности. [5] Вариативность часто рассматривается как дополнительное качество больших данных.
В определении 2018 года говорится: «Большие данные — это то место, где для обработки данных необходимы инструменты параллельных вычислений », и отмечается: «Это представляет собой отчетливое и четко определенное изменение в используемой информатике за счет теорий параллельного программирования и потери некоторых гарантий и возможности, созданные реляционной моделью Кодда ». [30]
В сравнительном исследовании больших наборов данных Китчин и МакАрдл обнаружили, что ни одна из обычно рассматриваемых характеристик больших данных не проявляется последовательно во всех проанализированных случаях. [31] По этой причине другие исследования определили переопределение динамики власти в открытии знаний как определяющую черту. [32] Вместо того, чтобы сосредотачиваться на внутренних характеристиках больших данных, эта альтернативная точка зрения продвигает реляционное понимание объекта, утверждая, что важно то, как данные собираются, хранятся, становятся доступными и анализируются.
Большие данные против бизнес-аналитики
[ редактировать ]Растущая зрелость концепции более четко определяет разницу между «большими данными» и « бизнес-аналитикой »: [33]
- Бизнес-аналитика использует инструменты прикладной математики и описательную статистику с данными с высокой плотностью информации для измерения показателей, выявления тенденций и т. д.
- Большие данные используют математический анализ, оптимизацию, индуктивную статистику и концепции идентификации нелинейных систем. [34] выводить законы (регрессии, нелинейные связи и причинно-следственные связи) на основе больших наборов данных с низкой плотностью информации. [35] для выявления взаимосвязей и зависимостей или для прогнозирования результатов и поведения. [34] [36] [ рекламный источник? ]
Характеристики
[ редактировать ]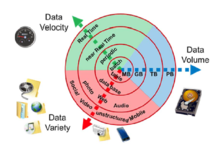
Большие данные можно описать следующими характеристиками:
- Объем
- Количество сгенерированных и сохраненных данных. Размер данных определяет ценность и потенциальную ценность, а также то, можно ли их считать большими данными или нет. Размер больших данных обычно превышает терабайты и петабайты. [37]
- Разнообразие
- Тип и характер данных. Более ранние технологии, такие как СУБД, были способны эффективно и результативно обрабатывать структурированные данные. Однако изменение типа и характера от структурированного к полуструктурированному или неструктурированному бросило вызов существующим инструментам и технологиям. Технологии больших данных развивались с основной целью сбора, хранения и обработки полуструктурированных и неструктурированных (разнообразных) данных, генерируемых с высокой скоростью (скоростью) и огромными по размеру (объему). Позже эти инструменты и технологии были изучены и использованы для обработки структурированных данных, но предпочтительно для хранения. В конце концов, обработка структурированных данных по-прежнему оставалась необязательной: либо с использованием больших данных, либо с использованием традиционных СУБД. Это помогает анализировать данные для эффективного использования скрытой информации, полученной из данных, собранных через социальные сети, файлы журналов, датчики и т. д. Большие данные извлекаются из текста, изображений, аудио, видео; плюс он дополняет недостающие части посредством объединения данных .
- Скорость
- Скорость, с которой данные генерируются и обрабатываются для удовлетворения потребностей и задач, стоящих на пути роста и развития. Большие данные часто доступны в режиме реального времени. По сравнению с небольшими данными , большие данные создаются более непрерывно. Два типа скорости, связанные с большими данными, — это частота генерации и частота обработки, записи и публикации. [38]
- Правдивость
- Правдивость или надежность данных, которая относится к качеству и ценности данных. [39] Большие данные должны быть не только большими по размеру, но и надежными, чтобы их анализ мог принести пользу. Качество . собранных данных может сильно различаться, что влияет на точность анализа [40]
- Ценить
- Ценность информации, которую можно получить путем обработки и анализа больших наборов данных. Ценность также можно измерить путем оценки других качеств больших данных. [41] Ценность также может отражать прибыльность информации, полученной в результате анализа больших данных.
- Вариативность
- Характеристика меняющихся форматов, структуры или источников больших данных. Большие данные могут включать структурированные, неструктурированные данные или комбинации структурированных и неструктурированных данных. Анализ больших данных может объединять необработанные данные из нескольких источников. Обработка необработанных данных может также включать преобразование неструктурированных данных в структурированные.
Другими возможными характеристиками больших данных являются: [42]
- исчерпывающий
- Будет ли вся система (т. е. =все) захватывается или записывается или нет. Большие данные могут включать или не включать все доступные данные из источников.

- Детализированный и уникальный лексический состав
- Соответственно, доля конкретных данных каждого элемента на каждый собранный элемент, а также правильность индексации или идентификации элемента и его характеристик.
- Реляционный
- Если собранные данные содержат общие поля, которые позволят объединить или метаанализировать различные наборы данных.
- Экстенсиональный
- Если новые поля в каждом элементе собранных данных могут быть легко добавлены или изменены.
- Масштабируемость
- Если размер системы хранения больших данных может быстро расширяться.
Архитектура
[ редактировать ]Репозитории больших данных существовали во многих формах и часто создавались корпорациями с особыми потребностями. Коммерческие поставщики исторически предлагали параллельные системы управления базами данных для больших данных, начиная с 1990-х годов. В течение многих лет WinterCorp публиковала самый крупный отчет по базе данных. [43] [ рекламный источник? ]
Корпорация Teradata в 1984 году выпустила на рынок систему параллельной обработки DBC 1012 . Системы Teradata были первыми, кто смог хранить и анализировать 1 терабайт данных в 1992 году. В 1991 году жесткие диски имели емкость 2,5 ГБ, поэтому определение больших данных постоянно развивается. Teradata установила первую систему на базе СУБД петабайтного класса в 2007 году. По состоянию на 2017 год [update]Установлено несколько десятков реляционных баз данных Teradata петабайтного класса, размер крупнейшей из которых превышает 50 ПБ. Системы до 2008 года представляли собой 100% структурированные реляционные данные. С тех пор Teradata добавила неструктурированные типы данных, включая XML , JSON и Avro.
В 2000 году компания Seisint Inc. (теперь LexisNexis Risk Solutions ) разработала основанную на C++ распределенную платформу для обработки данных и выполнения запросов, известную как платформа HPCC Systems . Эта система автоматически разделяет, распределяет, хранит и доставляет структурированные, полуструктурированные и неструктурированные данные на несколько обычных серверов. Пользователи могут писать конвейеры обработки данных и запросы на декларативном языке программирования потоков данных, называемом ECL. Аналитикам данных, работающим в ECL, не требуется заранее определять схемы данных, они могут сосредоточиться на конкретной проблеме, изменяя данные наилучшим образом по мере разработки решения. В 2004 году LexisNexis приобрела Seisint Inc. [44] и их высокоскоростную платформу параллельной обработки и успешно использовали эту платформу для интеграции систем данных Choicepoint Inc., когда они приобрели эту компанию в 2008 году. [45] В 2011 году системная платформа HPCC была открыта под лицензией Apache v2.0.
ЦЕРН и другие физические эксперименты собирали большие наборы данных на протяжении многих десятилетий, обычно анализируя их с помощью высокопроизводительных вычислений , а не с помощью архитектур сокращения карт, обычно подразумеваемых нынешним движением «больших данных».
В 2004 году Google опубликовал статью о процессе MapReduce , использующем аналогичную архитектуру. Концепция MapReduce предоставляет модель параллельной обработки, и была выпущена соответствующая реализация для обработки огромных объемов данных. С помощью MapReduce запросы разбиваются, распределяются по параллельным узлам и обрабатываются параллельно (шаг «карта»). Затем результаты собираются и доставляются (этап «сокращение»). Рамочная программа оказалась очень успешной, [46] поэтому другие захотели повторить алгоритм. Поэтому реализация платформы MapReduce была принята проектом Apache с открытым исходным кодом под названием Hadoop . [47] Apache Spark был разработан в 2012 году в ответ на ограничения парадигмы MapReduce, поскольку он добавляет обработку в памяти и возможность настройки множества операций (а не только сопоставления с последующим сокращением).
MIKE2.0 — это открытый подход к управлению информацией, который признает необходимость внесения изменений в связи с последствиями для больших данных, указанными в статье под названием «Предложение решений для больших данных». [48] Методология рассматривает обработку больших данных с точки зрения полезных перестановок источников данных, сложности взаимосвязей и трудностей удаления (или изменения) отдельных записей. [49]
Исследования 2012 года показали, что многоуровневая архитектура является одним из вариантов решения проблем, связанных с большими данными. Распределенная параллельная архитектура распределяет данные по нескольким серверам; эти среды параллельного выполнения могут значительно повысить скорость обработки данных. Этот тип архитектуры вставляет данные в параллельную СУБД, которая реализует использование фреймворков MapReduce и Hadoop. Этот тип инфраструктуры призван сделать вычислительную мощность прозрачной для конечного пользователя за счет использования интерфейсного сервера приложений. [50]
Озеро данных позволяет организации переключить свое внимание с централизованного управления на общую модель, чтобы реагировать на меняющуюся динамику управления информацией. Это позволяет быстро разделить данные в озере данных, тем самым сокращая накладные расходы. [51] [52]
Технологии
[ редактировать ]за 2011 год В отчете Глобального института McKinsey основные компоненты и экосистема больших данных характеризуются следующим образом: [53]
- Методы анализа данных, такие как A/B-тестирование , машинное обучение и обработка естественного языка.
- Технологии больших данных, такие как бизнес-аналитика , облачные вычисления и базы данных.
- Визуализация, например диаграммы, графики и другие виды отображения данных.
Многомерные большие данные также можно представить в виде OLAP кубов данных или, математически, тензоров . Системы баз данных с массивами призваны обеспечить хранение и поддержку запросов высокого уровня для этого типа данных.Дополнительные технологии, применяемые к большим данным, включают эффективные тензорные вычисления, [54] такие как мультилинейное обучение подпространству , [55] базы данных с массовой параллельной обработкой ( MPP ), приложения для поиска , интеллектуальный анализ данных , [56] распределенные файловые системы , распределенный кэш (например, пакетный буфер и Memcached ), распределенные базы данных , облачная инфраструктура и инфраструктура на базе HPC (приложения, хранилища и вычислительные ресурсы), [57] и Интернет. [ нужна ссылка ] Несмотря на то, что было разработано множество подходов и технологий, осуществлять машинное обучение с большими данными по-прежнему сложно. [58]
Некоторые реляционные базы данных MPP могут хранить петабайты данных и управлять ими. Неявной является возможность загрузки, мониторинга, резервного копирования и оптимизации использования больших таблиц данных в СУБД . [59] [ рекламный источник? ]
DARPA Программа топологического анализа данных направлена на изучение фундаментальной структуры огромных наборов данных, и в 2008 году эта технология стала достоянием общественности с запуском компании под названием «Ayasdi». [60] [ нужен сторонний источник ]
Специалисты по аналитике больших данных, как правило, враждебно относятся к более медленному общему хранилищу. [61] отдавая предпочтение хранилищам с прямым подключением ( DAS ) в различных формах: от твердотельных накопителей ( SSD большой емкости ) до дисков SATA , скрытых внутри узлов параллельной обработки. Архитектуры общего хранения данных — сеть хранения данных (SAN) и сетевое хранилище (NAS) — воспринимаются как относительно медленные, сложные и дорогие. Эти качества несовместимы с системами анализа больших данных, которые преуспевают за счет производительности системы, стандартной инфраструктуры и низкой стоимости.
Доставка информации в режиме реального или близкого к реальному времени является одной из определяющих характеристик анализа больших данных. Поэтому задержки избегаются всегда и везде, где это возможно. Данные в памяти или на диске с прямым подключением — в порядке, а данные в памяти или на диске на другом конце соединения FC SAN — нет. Стоимость SAN в масштабе, необходимом для аналитических приложений, намного выше, чем у других методов хранения.
Приложения
[ редактировать ]
Большие данные настолько увеличили спрос на специалистов по управлению информацией, что Software AG , Oracle Corporation , IBM , Microsoft , SAP , EMC , HP и Dell потратили более 15 миллиардов долларов на компании-разработчики программного обеспечения, специализирующиеся на управлении данными и аналитике. В 2010 году эта отрасль стоила более 100 миллиардов долларов и росла почти на 10 процентов в год, что примерно в два раза быстрее, чем бизнес программного обеспечения в целом. [8]
Развитые страны все чаще используют технологии, требующие больших объемов данных. Во всем мире насчитывается 4,6 миллиарда абонентов мобильных телефонов, а доступ к Интернету имеют от 1 до 2 миллиардов человек. [8] В период с 1990 по 2005 год более 1 миллиарда человек во всем мире вошли в средний класс, а это означает, что больше людей стали более грамотными, что, в свою очередь, привело к росту информации. Эффективная емкость мира для обмена информацией через телекоммуникационные сети составляла 281 петабайт в 1986 году, 471 петабайт в 1993 году, 2,2 эксабайта в 2000 году, 65 эксабайт в 2007 году. [13] По прогнозам, к 2014 году объем интернет-трафика составит 667 эксабайт в год. [8] По одной из оценок, треть глобально хранящейся информации находится в форме буквенно-цифрового текста и данных неподвижных изображений. [62] этот формат наиболее полезен для большинства приложений, работающих с большими данными. Это также показывает потенциал еще неиспользованных данных (т.е. в виде видео- и аудиоконтента).
В то время как многие вендоры предлагают готовые продукты для больших данных, эксперты поощряют разработку собственных систем, адаптированных под нужды компании, если у компании есть достаточные технические возможности. [63]
Правительство
[ редактировать ]Этот раздел нуждается в дополнительных цитатах для проверки . ( сентябрь 2023 г. ) |
Использование и внедрение больших данных в правительственные процессы позволяют повысить эффективность с точки зрения затрат, производительности и инноваций. [64] но не обходится без недостатков. Анализ данных часто требует совместной работы нескольких органов власти (центральных и местных) и создания новых и инновационных процессов для достижения желаемого результата. Обычной правительственной организацией, использующей большие данные, является Управление национальной безопасности ( АНБ ), которое постоянно отслеживает деятельность Интернета в поисках потенциальных моделей подозрительной или незаконной деятельности, которые может обнаружить их система.
Служба регистрации актов гражданского состояния и статистики естественного движения населения (CRVS) собирает все свидетельства о статусе от рождения до смерти. CRVS является источником больших данных для правительств.
Международное развитие
[ редактировать ]Исследования по эффективному использованию информационных и коммуникационных технологий в целях развития (также известные как «ICT4D») показывают, что технологии больших данных могут внести важный вклад, но также создают уникальные проблемы для международного развития . [65] [66] Достижения в области анализа больших данных открывают экономически эффективные возможности для улучшения процесса принятия решений в важнейших областях развития, таких как здравоохранение, занятость, экономическая производительность , преступность, безопасность, стихийные бедствия и управление ресурсами. [67] [ нужна страница ] [68] [69] Кроме того, данные, генерируемые пользователями, открывают новые возможности дать возможность высказаться тем, кто не услышан. [70] Однако давние проблемы развивающихся регионов, такие как неадекватная технологическая инфраструктура, а также нехватка экономических и человеческих ресурсов, усугубляют существующие проблемы с большими данными, такие как конфиденциальность, несовершенство методологии и проблемы совместимости. [67] [ нужна страница ] Задача «больших данных для развития» [67] [ нужна страница ] в настоящее время развивается в направлении применения этих данных посредством машинного обучения, известного как «искусственный интеллект для развития» (AI4D). [71]
Преимущества
[ редактировать ]Основным практическим применением больших данных в целях развития стала «борьба с бедностью с помощью данных». [72] В 2015 году Блюменшток и его коллеги оценили прогнозируемую бедность и богатство на основе метаданных мобильных телефонов. [73] а в 2016 году Джин и его коллеги объединили спутниковые снимки и машинное обучение, чтобы предсказать бедность. [74] Использование данных цифровых трасс для изучения рынка труда и цифровой экономики в Латинской Америке, Хилберт и коллеги. [75] [76] утверждают, что цифровые данные трассировки имеют ряд преимуществ, таких как:
- Тематический охват: включая области, которые ранее было трудно или невозможно измерить.
- Географический охват: предоставление крупных и сопоставимых данных почти по всем странам, включая множество небольших стран, которые обычно не включаются в международные реестры.
- Уровень детализации: предоставление детальных данных со многими взаимосвязанными переменными и новыми аспектами, такими как сетевые подключения.
- Своевременность и временные ряды: графики могут быть построены в течение нескольких дней после их сбора.
Проблемы
[ редактировать ]В то же время работа с данными цифровых трасс вместо традиционных данных обследований не устраняет традиционных проблем, возникающих при работе в области международного количественного анализа. Приоритеты меняются, но основные дискуссии остаются прежними. Среди основных задач можно назвать:
- Репрезентативность. В то время как традиционная статистика развития в основном занимается репрезентативностью выборок случайных обследований, данные цифровых трассировок никогда не являются случайной выборкой. [77]
- Обобщаемость. Хотя данные наблюдений всегда очень хорошо представляют этот источник, они представляют только то, что представляют, и не более того. Хотя возникает соблазн обобщить конкретные наблюдения одной платформы на более широкие условия, это часто очень обманчиво.
- Гармонизация. Данные цифровых трассировок по-прежнему требуют международной гармонизации показателей. Это добавляет проблему так называемого «объединения данных», гармонизации различных источников.
- Перегрузка данных. Аналитики и учреждения не привыкли эффективно работать с большим количеством переменных, что эффективно достигается с помощью интерактивных информационных панелей. Практикам до сих пор не хватает стандартного рабочего процесса, который позволил бы исследователям, пользователям и политикам эффективно и результативно работать с данными. [75]
Финансы
[ редактировать ]Большие данные быстро внедряются в финансах для 1) ускорения обработки и 2) предоставления более качественных и обоснованных выводов как внутри самих финансовых учреждений, так и для клиентов финансовых учреждений. [78] Финансовые применения больших данных варьируются от инвестиционных решений и торговли (одновременная обработка объемов доступных ценовых данных, книг лимитных заказов, экономических данных и т. д.) до управления портфелем (оптимизация все большего количества финансовых инструментов, потенциально выбранных из разных классов активов), управление рисками (кредитный рейтинг на основе расширенной информации) и любой другой аспект, в котором объем входных данных велик. [79] Большие данные также являются типичной концепцией в сфере альтернативных финансовых услуг . Некоторые из основных областей включают краудфандинговые платформы и биржи криптовалют. [80]
Здравоохранение
[ редактировать ]Аналитика больших данных используется в здравоохранении для обеспечения персонализированной медицины и предписывающей аналитики , вмешательства в клинические риски и прогнозной аналитики, сокращения отходов и изменчивости ухода, автоматизированной внешней и внутренней отчетности данных пациентов, стандартизированных медицинских терминов и регистров пациентов. [81] [82] [83] [84] Некоторые области улучшений являются более амбициозными, чем фактически реализованными. Уровень данных, генерируемых в системах здравоохранения , нетривиален. С дальнейшим внедрением мобильного здравоохранения, электронного здравоохранения и носимых технологий объем данных будет продолжать расти. Сюда входят данные электронных медицинских карт , данные визуализации, данные, созданные пациентами, данные датчиков и другие формы данных, которые трудно обрабатывать. В настоящее время существует еще большая потребность в таких средах уделять больше внимания качеству данных и информации. [85] «Большие данные очень часто означают « грязные данные », и доля неточностей в данных увеличивается с ростом объема данных». Человеческий контроль в масштабе больших данных невозможен, и существует острая потребность в службах здравоохранения в интеллектуальных инструментах для контроля точности и правдоподобности и обработки пропущенной информации. [86] Хотя обширная информация в здравоохранении теперь доступна в электронном виде, она вписывается в категорию больших данных, поскольку большая ее часть неструктурирована и сложна в использовании. [87] Использование больших данных в здравоохранении породило серьезные этические проблемы, начиная от рисков для прав личности, конфиденциальности и автономии и заканчивая прозрачностью и доверием. [88]
Большие данные в медицинских исследованиях особенно многообещающи с точки зрения поисковых биомедицинских исследований, поскольку анализ, основанный на данных, может продвигаться вперед быстрее, чем исследования, основанные на гипотезах. [89] Затем тенденции, наблюдаемые в анализе данных, могут быть проверены в ходе традиционных, основанных на гипотезах последующих биологических исследований и, в конечном итоге, клинических исследований.
Связанной областью применения в сфере здравоохранения, которая в значительной степени опирается на большие данные, является компьютерная диагностика в медицине. [90] [ нужна страница ] Например, для мониторинга эпилепсии принято ежедневно создавать от 5 до 10 ГБ данных. [91] Аналогичным образом, одно несжатое изображение томосинтеза молочной железы в среднем содержит 450 МБ данных. [92] Это лишь некоторые из многих примеров, когда компьютерная диагностика использует большие данные. По этой причине большие данные были признаны одной из семи ключевых проблем, которые необходимо преодолеть системам компьютерной диагностики, чтобы выйти на новый уровень производительности. [93]
Образование
[ редактировать ]Исследование McKinsey Global Institute выявило нехватку 1,5 миллиона высококвалифицированных специалистов по данным и менеджеров. [53] и ряд университетов [94] [ нужен лучший источник ] включая Университет Теннесси и Калифорнийский университет в Беркли , создали магистерские программы для удовлетворения этого спроса. Частные учебные лагеря также разработали программы для удовлетворения этого спроса, в том числе платные программы, такие как «Инкубатор данных» или «Генеральная Ассамблея» . [95] В специфической области маркетинга одна из проблем, подчеркиваемых Веделем и Каннаном, [96] заключается в том, что маркетинг имеет несколько поддоменов (например, реклама, продвижение по службе,разработка продуктов, брендинг), которые используют разные типы данных.
СМИ
[ редактировать ]Чтобы понять, как средства массовой информации используют большие данные, сначала необходимо представить некоторый контекст механизма, используемого для медиапроцесса. Ник Кадри и Джозеф Туроу предположили, что специалисты в области средств массовой информации и рекламы подходят к большим данным как к множеству полезных сведений о миллионах людей. Похоже, что индустрия отходит от традиционного подхода к использованию конкретной медиа-среды, такой как газеты, журналы или телешоу, и вместо этого привлекает потребителей с помощью технологий, которые достигают целевых людей в оптимальное время и в оптимальных местах. Конечная цель — предоставить или передать сообщение или контент, который (статистически говоря) соответствует мышлению потребителя. Например, издательская среда все чаще адаптирует сообщения (рекламу) и контент (статьи) так, чтобы они были привлекательными для потребителей и были получены исключительно с помощью различных мероприятий по сбору данных . [97]
- Ориентация на потребителей (для рекламы маркетологов) [98]
- Сбор данных
- Журналистика данных : издатели и журналисты используют инструменты больших данных для предоставления уникальных и инновационных идей и инфографики .
Channel 4 , британская общественная телекомпания, является лидером в области больших данных и анализа данных . [99]
Страхование
[ редактировать ]Поставщики медицинского страхования собирают данные о социальных «детерминантах здоровья», таких как потребление еды и телевидения , семейное положение, размер одежды и покупательские привычки, на основе которых они делают прогнозы о расходах на здравоохранение, чтобы выявить проблемы со здоровьем у своих клиентов. Спорно, используются ли эти прогнозы в настоящее время для ценообразования. [100]
Интернет вещей (IoT)
[ редактировать ]Большие данные и Интернет вещей работают вместе. Данные, извлеченные из устройств Интернета вещей, обеспечивают отображение взаимосвязи устройств. Такие сопоставления используются медиаиндустрией, компаниями и правительствами для более точного таргетирования своей аудитории и повышения эффективности СМИ. Интернет вещей также все чаще применяется в качестве средства сбора сенсорных данных, и эти сенсорные данные используются в медицине, [101] производство [102] и транспорт [103] контексты.
Кевин Эштон , эксперт по цифровым инновациям, которому приписывают создание этого термина, [104] определяет Интернет вещей в этой цитате: «Если бы у нас были компьютеры, которые знали бы все, что нужно знать о вещах, — используя данные, которые они собрали без какой-либо помощи с нашей стороны, — мы были бы в состоянии отслеживать и подсчитывать все, а также значительно сократить потери и потери». и стоимость. Мы будем знать, когда что-то нужно заменить, отремонтировать или отозвать, а также являются ли они свежими или уже не в лучшем состоянии».
Информационные технологии
[ редактировать ]Особенно с 2015 года большие данные стали играть важную роль в бизнес-операциях как инструмент, помогающий сотрудникам работать более эффективно и оптимизирующий сбор и распространение информационных технологий (ИТ). Использование больших данных для решения проблем ИТ и сбора данных на предприятии называется аналитикой ИТ-операций (ITOA). [105] Применяя принципы больших данных к концепциям машинного интеллекта и глубоких вычислений, ИТ-отделы могут прогнозировать потенциальные проблемы и предотвращать их. [105] Компании ITOA предлагают платформы для управления системами , которые объединяют хранилища данных и генерируют ценную информацию на основе всей системы, а не на основе изолированных карманов данных.
Обзорная наука
[ редактировать ]По сравнению со сбором данных на основе опросов , большие данные имеют низкую стоимость за единицу данных, используют методы анализа с помощью машинного обучения и интеллектуального анализа данных и включают разнообразные и новые источники данных, например, регистры, социальные сети, приложения и другие формы цифровых данных. С 2018 года ученые-исследователи начали изучать, как большие данные и опросная наука могут дополнять друг друга, позволяя исследователям и практикам улучшить производство статистики и ее качество. В 2018, 2020 (виртуальном), 2023 и по состоянию на 2023 год было проведено три конференции Big Data Meets Survey Science (BigSurv). [update] одна конференция состоится в 2025 году, [106] специальный выпуск журнала Social Science Computer Review , [107] специальный выпуск в журнале Королевского статистического общества , [108] и специальный выпуск в EP J Data Science , [109] и книга « Большие данные встречаются с социальными науками». [110] под редакцией Крейга Хилла и пяти других членов Американской статистической ассоциации . В 2021 году члены-основатели BigSurv получили Премию новаторов Уоррена Дж. Митофски от Американской ассоциации исследований общественного мнения . [111]
Маркетинг
[ редактировать ]Большие данные примечательны в маркетинге благодаря постоянной «датафикации». [112] ежедневных потребителей Интернета, в котором отслеживаются все формы данных. Информацию о потребителях можно определить как количественную оценку многих или всех видов человеческого поведения в целях маркетинга. [113] Все более цифровой мир быстрой обработки данных делает эту идею актуальной для маркетинга, поскольку объем данных постоянно растет в геометрической прогрессии. Прогнозируется, что в течение пяти лет он увеличится с 44 до 163 зеттабайт. [114] Маркетологам часто бывает сложно ориентироваться в размерах больших данных. [115] В результате пользователи больших данных могут оказаться в невыгодном положении. Алгоритмических выводов может быть трудно достичь с такими большими наборами данных. [116] Большие данные в маркетинге — это очень прибыльный инструмент, который может использоваться крупными корпорациями, поскольку его ценность заключается в возможности прогнозирования значительных тенденций, интересов или статистических результатов с учетом интересов потребителей. [117]
Есть три важных фактора в использовании больших данных в маркетинге:
- Большие данные позволяют маркетологам выявлять модели поведения клиентов, поскольку все человеческие действия выражаются в читаемых цифрах, которые маркетологи могут анализировать и использовать в своих исследованиях. [118] Кроме того, большие данные также можно рассматривать как инструмент индивидуальной рекомендации продуктов. В частности, поскольку большие данные эффективны при анализе покупательского поведения клиентов и моделей просмотра, эта технология может помочь компаниям в продвижении конкретных персонализированных продуктов для конкретных клиентов. [119]
- Реакция рынка в режиме реального времени важна для маркетологов из-за способности перенаправлять маркетинговые усилия и корректировать их в соответствии с текущими тенденциями, что помогает поддерживать актуальность для потребителей. Это может предоставить корпорациям информацию, необходимую для заранее прогнозирования желаний и потребностей потребителей. [120]
- Амбидекстрия рынка, основанная на данных, в значительной степени подпитывается большими данными. [121] Разрабатываются новые модели и алгоритмы, позволяющие делать значимые прогнозы относительно определенных экономических и социальных ситуаций. [122]
Тематические исследования
[ редактировать ]Правительство
[ редактировать ]Китай
[ редактировать ]- Интегрированная совместная операционная платформа (IJOP, Integrated Joint Operations Platform) используется правительством для мониторинга населения, особенно уйгуров . [123] Биометрические данные , включая образцы ДНК, собираются в рамках программы бесплатных медосмотров. [124]
- К 2020 году Китай планирует дать всем своим гражданам личный рейтинг «социального кредита», основанный на их поведении. [125] Система социального кредита , пилотируемая в настоящее время в ряде китайских городов, считается формой массовой слежки , в которой используется технология анализа больших данных. [126] [127]
Индия
[ редактировать ]- Анализ больших данных был опробован для того, чтобы БДП выиграла всеобщие выборы в Индии в 2014 году. [128]
- Индийское правительство использует многочисленные методы, чтобы выяснить, как индийский электорат реагирует на действия правительства, а также идеи по усилению политики.
Израиль
[ редактировать ]- Персонализированное лечение диабета можно создать с помощью решения для обработки больших данных GlucoMe. [129]
Великобритания
[ редактировать ]Примеры использования больших данных в государственных услугах:
- Данные о рецептурных лекарствах: связав происхождение, место и время каждого рецепта, исследовательское подразделение смогло проиллюстрировать и изучить значительную задержку между выпуском любого конкретного лекарства и адаптацией Национального института здравоохранения и здравоохранения в масштабах всей Великобритании. Рекомендации по обеспечению превосходного ухода . Это говорит о том, что новым или наиболее современным лекарствам требуется некоторое время, чтобы дойти до обычного пациента. [ нужна ссылка ] [130]
- Объединение данных: местные власти объединили данные об услугах, таких как дежурство по уборке дорог, с услугами для людей из группы риска, такими как «Еда на колесах» . Подключение данных позволило местным властям избежать задержек, связанных с погодой. [131]
Соединенные Штаты
[ редактировать ]- В 2012 году администрация Обамы объявила об Инициативе по исследованию и развитию больших данных, призванной изучить, как большие данные могут быть использованы для решения важных проблем, с которыми сталкивается правительство. [132] Инициатива состоит из 84 различных программ по работе с большими данными, распределенных по шести департаментам. [133]
- Анализ больших данных сыграл большую роль в Барака Обамы успешной предвыборной кампании в 2012 году . [134]
- Федеральному правительству США принадлежат четыре из десяти самых мощных суперкомпьютеров в мире. [135] [136]
- Центр обработки данных штата Юта США был построен Агентством национальной безопасности . После завершения объект сможет обрабатывать большой объем информации, собираемой АНБ через Интернет. Точный объем дискового пространства неизвестен, но более поздние источники утверждают, что он будет порядка нескольких эксабайт . [137] [138] [139] Это создало проблемы безопасности в отношении анонимности собранных данных. [140]
Розничная торговля
[ редактировать ]- Walmart обрабатывает более 1 миллиона транзакций клиентов каждый час, которые импортируются в базы данных, которые, по оценкам, содержат более 2,5 петабайт (2560 терабайт) данных, что в 167 раз превышает объем информации, содержащейся во всех книгах Библиотеки Конгресса США . [8]
- Windermere Real Estate использует информацию о местонахождении почти 100 миллионов водителей, чтобы помочь покупателям нового жилья определить типичное время поездки на работу и обратно в разное время дня. [141]
- Система обнаружения карт FICO защищает счета по всему миру. [142]
- Омниканальная розничная торговля [143] использует большие онлайн-данные для улучшения оффлайн-опыта.
Наука
[ редактировать ]- Эксперименты Большого адронного коллайдера представляют собой около 150 миллионов датчиков, передающих данные 40 миллионов раз в секунду. В секунду происходит около 600 миллионов столкновений. После фильтрации и воздержания от записи более 99,99995% [144] из этих потоков происходит 1000 столкновений интересов в секунду. [145] [146] [147]
- В результате, работая только с менее чем 0,001% данных потока датчиков, поток данных всех четырех экспериментов БАК представляет собой годовую скорость 25 петабайт до репликации (по состоянию на 2012 г.). [update]). После репликации это становится почти 200 петабайтами.
- Если бы все данные датчиков записывались на БАК, с потоком данных было бы чрезвычайно сложно работать. До начала репликации поток данных превысит 150 миллионов петабайт в год, или почти 500 эксабайт в день. Для сравнения: это эквивалентно 500 квинтиллионам (5×10 20 ) байт в день, что почти в 200 раз больше, чем у всех остальных источников мира, вместе взятых.
- Квадратный километр представляет собой радиотелескоп, состоящий из тысяч антенн. Ожидается, что он будет введен в эксплуатацию к 2024 году. Ожидается, что в совокупности эти антенны будут собирать 14 эксабайт и хранить один петабайт в день. [148] [149] Это считается одним из самых амбициозных научных проектов, когда-либо предпринимавшихся. [150]
- Когда в 2000 году Слоановский цифровой обзор неба (SDSS) начал собирать астрономические данные, за первые несколько недель он собрал больше, чем все данные, собранные за всю историю астрономии ранее. Продолжая работу со скоростью около 200 ГБ за ночь, SDSS накопил более 140 терабайт информации. [8] Когда Большой синоптический обзорный телескоп , преемник SDSS, будет запущен в эксплуатацию в 2020 году, его разработчики ожидают, что он будет собирать такой объем данных каждые пять дней. [8]
- Первоначально расшифровка генома человека заняла 10 лет; теперь этого можно достичь менее чем за день. Секвенаторы ДНК за последние десять лет разделили стоимость секвенирования на 10 000, что в 100 раз дешевле, чем снижение стоимости, предсказанное законом Мура . [151]
- Центр НАСА по моделированию климата (NCCS) хранит 32 петабайта данных климатических наблюдений и моделирования в суперкомпьютерном кластере Discover. [152] [153]
- DNAStack от Google собирает и систематизирует образцы ДНК генетических данных со всего мира для выявления заболеваний и других медицинских дефектов. Эти быстрые и точные расчеты исключают любые «точки трения» или человеческие ошибки, которые мог допустить один из многочисленных экспертов в области науки и биологии, работающих с ДНК. DNAStack, часть Google Genomics, позволяет ученым мгновенно использовать обширную выборку ресурсов с поискового сервера Google для масштабирования социальных экспериментов, которые обычно занимают годы. [154] [155]
- содержит 23andme База данных ДНК генетическую информацию более чем 1 000 000 человек по всему миру. [156] Компания рассматривает возможность продажи «анонимных агрегированных генетических данных» другим исследователям и фармацевтическим компаниям для исследовательских целей, если пациенты дадут свое согласие. [157] [158] [159] [160] [161] Ахмад Харири, профессор психологии и нейробиологии в Университете Дьюка , который использует 23andMe в своих исследованиях с 2009 года, утверждает, что наиболее важным аспектом нового сервиса компании является то, что он делает генетические исследования доступными и относительно дешевыми для ученых. [157] Исследование, которое выявило 15 сайтов генома, связанных с депрессией, в базе данных 23andMe, привело к резкому росту запросов на доступ к хранилищу: 23andMe отправила почти 20 запросов на доступ к данным о депрессии в течение двух недель после публикации статьи. [162]
- Вычислительная гидродинамика ( CFD ) и исследования гидродинамической турбулентности генерируют огромные наборы данных. Базы данных Джонса Хопкинса по турбулентности ( JHTDB ) содержат более 350 терабайт пространственно-временных полей, полученных в результате прямого численного моделирования различных турбулентных потоков. Такими данными было трудно поделиться с помощью традиционных методов, таких как загрузка выходных файлов плоского моделирования. Доступ к данным в JHTDB можно получить с помощью «виртуальных датчиков» с различными режимами доступа, начиная от прямых запросов веб-браузера, доступа через программы Matlab, Python, Fortran и C, выполняющиеся на клиентских платформах, до отключения служб для загрузки необработанных данных. Данные были использованы в более чем 150 научных публикациях.
Спорт
[ редактировать ]Большие данные можно использовать для улучшения тренировок и понимания конкурентов с помощью спортивных датчиков. Также можно предсказать победителей в матче с помощью анализа больших данных. [163] Будущие результаты игроков также можно предсказать. [164] Таким образом, стоимость и зарплата игроков определяется данными, собранными в течение сезона. [165]
В гонках Формулы-1 гоночные автомобили с сотнями датчиков генерируют терабайты данных. Эти датчики собирают данные о давлении в шинах и эффективности сжигания топлива. [166] На основе данных инженеры и аналитики данных решают, следует ли внести изменения, чтобы выиграть гонку. Кроме того, используя большие данные, гоночные команды пытаются заранее предсказать время, когда они финишируют в гонке, на основе моделирования с использованием данных, собранных за сезон. [167]
Технология
[ редактировать ]- По состоянию на 2013 год [update]eBay.com и 40 ПБ , использует два хранилища данных объемом 7,5 петабайт а также кластер Hadoop объемом 40 ПБ для поиска, рекомендаций потребителям и мерчандайзинга. [168]
- Amazon.com ежедневно обрабатывает миллионы серверных операций, а также запросы от более чем полумиллиона сторонних продавцов. Основная технология, обеспечивающая работу Amazon, основана на Linux, и по состоянию на 2005 г. [update] у них были три крупнейшие в мире базы данных Linux емкостью 7,8 ТБ, 18,5 ТБ и 24,7 ТБ. [169]
- Facebook обрабатывает 50 миллиардов фотографий своей пользовательской базы. [170] По состоянию на июнь 2017 г. [update]Facebook достиг 2 миллиардов активных пользователей в месяц . [171]
- По состоянию на август 2012 года Google обрабатывал около 100 миллиардов поисковых запросов в месяц. [update]. [172]
COVID-19
[ редактировать ]Во время пандемии COVID-19 большие данные использовались как способ минимизировать последствия болезни. Важные применения больших данных включали минимизацию распространения вируса, выявление случаев заболевания и разработку методов лечения. [173]
Правительства использовали большие данные для отслеживания инфицированных людей, чтобы минимизировать распространение. Среди первых последователей были Китай, Тайвань, Южная Корея и Израиль. [174] [175] [176]
Исследовательская деятельность
[ редактировать ]Зашифрованный поиск и формирование кластеров в больших данных были продемонстрированы в марте 2014 года в Американском обществе инженерного образования. Гаутам Сивах участвовал в проекте «Решение проблем больших данных» Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института , а Амир Эсмаилпур из Исследовательской группы UNH исследовали ключевые особенности больших данных, такие как формирование кластеров и их взаимосвязей. Они сосредоточились на безопасности больших данных и ориентации этого термина на наличие различных типов данных в зашифрованной форме в облачном интерфейсе, предоставив необработанные определения и примеры в реальном времени в рамках технологии. Более того, они предложили подход к определению метода кодирования для продвижения к ускоренному поиску по зашифрованному тексту, что приведет к повышению безопасности больших данных. [177]
В марте 2012 года Белый дом объявил о национальной «Инициативе по большим данным», в которую входят шесть федеральных департаментов и агентств, выделивших более 200 миллионов долларов на проекты исследования больших данных. [178]
Инициатива включала грант Национального научного фонда «Экспедиции в области вычислений» в размере 10 миллионов долларов США на пять лет для AMPLab. [179] в Калифорнийском университете в Беркли. [180] AMPLab также получила средства от DARPA и более десятка промышленных спонсоров и использует большие данные для решения широкого спектра проблем, включая прогнозирование пробок на дорогах. [181] для борьбы с раком. [182]
Инициатива Белого дома по большим данным также включала обязательство Министерства энергетики предоставить 25 миллионов долларов США в течение пяти лет для создания Института управления масштабируемыми данными, анализа и визуализации (SDAV). [183] Министерства энергетики под руководством Национальной лаборатории Лоуренса Беркли . Институт SDAV стремится объединить опыт шести национальных лабораторий и семи университетов для разработки новых инструментов, которые помогут ученым управлять данными и визуализировать их на суперкомпьютерах департамента.
В мае 2012 года американский штат Массачусетс объявил об Массачусетской инициативе по работе с большими данными, которая обеспечивает финансирование со стороны правительства штата и частных компаний различным исследовательским учреждениям. [184] В Массачусетском технологическом институте находится Научно-технологический центр Intel для больших данных в Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института , который объединяет государственное, корпоративное и институциональное финансирование и исследовательские усилия. [185]
Европейская комиссия финансирует двухлетний государственно-частный форум по большим данным в рамках своей Седьмой рамочной программы, чтобы привлечь компании, ученых и другие заинтересованные стороны к обсуждению проблем больших данных. Целью проекта является определение стратегии в области исследований и инноваций, которая будет служить руководством для поддержки действий Европейской комиссии по успешному внедрению экономики больших данных. Результаты этого проекта будут использованы в качестве исходных данных для Horizon 2020 , их следующей рамочной программы . [186]
В марте 2014 года британское правительство объявило об основании Института Алана Тьюринга , названного в честь пионера компьютеров и взломщика кодов, который сосредоточится на новых способах сбора и анализа больших наборов данных. [187]
На Дне вдохновения канадского опыта открытых данных (CODE) в кампусе Университета Ватерлоо в Стратфорде участники продемонстрировали, как использование визуализации данных может повысить понимание и привлекательность наборов больших данных, а также донести их историю до мира. [188]
Вычислительные социальные науки . Любой может использовать интерфейсы прикладного программирования (API), предоставляемые держателями больших данных, такими как Google и Twitter, для проведения исследований в области социальных и поведенческих наук. [189] Часто эти API предоставляются бесплатно. [189] Тобиас Прейс и др. использовали данные Google Trends, чтобы продемонстрировать, что пользователи Интернета из стран с более высоким валовым внутренним продуктом (ВВП) на душу населения с большей вероятностью будут искать информацию о будущем, чем информацию о прошлом. Результаты показывают, что может существовать связь между поведением в Интернете и реальными экономическими показателями. [190] [191] [192] Авторы исследования изучили журналы запросов Google, составленные по соотношению объема поисков за предстоящий год (2011 г.) к объему поисков за предыдущий год (2009 г.), который они называют « индексом ориентации на будущее ». [193] Они сравнили индекс ориентации на будущее с ВВП на душу населения в каждой стране и обнаружили сильную тенденцию в странах, где пользователи Google больше интересуются будущим, иметь более высокий ВВП.
Тобиас Прейс и его коллеги Хелен Сюзанна Моат и Х. Юджин Стэнли представили метод определения онлайн-предвестников движений фондового рынка, используя торговые стратегии, основанные на данных об объеме поиска, предоставленных Google Trends. [194] Их анализ объема поиска в Google по 98 терминам различной финансовой значимости, опубликованный в журнале Scientific Reports , [195] предполагает, что увеличение объема поиска по финансово значимым поисковым запросам, как правило, предшествует крупным потерям на финансовых рынках. [196] [197] [198] [199] [200] [201] [202]
Большие наборы данных сопряжены с алгоритмическими проблемами, которых раньше не существовало. Следовательно, некоторые считают, что необходимо фундаментально изменить способы обработки. [203]
Выборка больших данных
[ редактировать ]Исследовательский вопрос, который задают в отношении больших наборов данных, заключается в том, необходимо ли рассматривать полные данные, чтобы сделать определенные выводы о свойствах данных, или достаточно хороша выборка. Само название «большие данные» содержит термин, связанный с размером, и это важная характеристика больших данных. Но выборка позволяет выбрать правильные точки данных из большего набора данных для оценки характеристик всей совокупности. При производстве различные типы сенсорных данных, таких как акустика, вибрация, давление, ток, напряжение и данные контроллера, доступны через короткие промежутки времени. Чтобы спрогнозировать время простоя, возможно, нет необходимости просматривать все данные, но выборки может быть достаточно. Большие данные можно разбить по различным категориям данных, таким как демографические, психографические, поведенческие и транзакционные данные. Имея большие наборы данных, маркетологи могут создавать и использовать более индивидуальные сегменты потребителей для более стратегического таргетинга.
Критика
[ редактировать ]Критика парадигмы больших данных бывает двух видов: та, которая ставит под сомнение последствия самого подхода, и та, которая ставит под сомнение то, как это делается в настоящее время. [204] Одним из подходов к этой критике является изучение критических данных .
Критика парадигмы больших данных
[ редактировать ]«Основная проблема заключается в том, что мы мало что знаем о лежащих в основе эмпирических микропроцессах, которые приводят к появлению типичных сетевых характеристик больших данных». [25] [ нужна страница ] В своей критике Снейдерс, Мацат и Рейпс отмечают, что часто в отношении математических свойств делаются очень сильные предположения, которые могут вообще не отражать то, что на самом деле происходит на уровне микропроцессов. Марк Грэм подверг резкой критике утверждение Криса Андерсона о том, что большие данные означают конец теории: [205] уделяя особое внимание идее о том, что большие данные всегда должны быть контекстуализированы в социальном, экономическом и политическом контекстах. [206] Даже несмотря на то, что компании инвестируют восьмизначные и девятизначные суммы, чтобы получить представление о потоке информации от поставщиков и клиентов, менее 40% сотрудников обладают достаточно зрелыми процессами и навыками для этого. Согласно статье в Harvard Business Review , чтобы преодолеть этот дефицит понимания, большие данные, независимо от того, насколько они полны или хорошо проанализированы, должны быть дополнены «большим суждением». [207]
Во многом в том же духе было отмечено, что решения, основанные на анализе больших данных, неизбежно «информируются миром, каким он был в прошлом или, в лучшем случае, таким, какой он есть в настоящее время». [67] [ нужна страница ] Основываясь на большом количестве данных о прошлом опыте, алгоритмы могут предсказывать будущее развитие, если будущее похоже на прошлое. [208] Если динамика будущего системы изменится (если это не стационарный процесс ), прошлое мало что может сказать о будущем. Чтобы делать прогнозы в изменяющихся условиях, необходимо иметь глубокое понимание динамики систем, что требует теории. [208] В ответ на эту критику Алемани Оливер и Вэйр предлагают использовать «абдуктивные рассуждения в качестве первого шага в исследовательском процессе, чтобы привнести контекст в цифровые следы потребителей и вызвать появление новых теорий». [209] Кроме того, было предложено объединить подходы, основанные на больших данных, с компьютерным моделированием, например, с агентными моделями. [67] [ нужна страница ] и сложные системы . Агентные модели становятся все лучше в прогнозировании результатов социальных сложностей даже неизвестных сценариев будущего с помощью компьютерного моделирования, основанного на наборе взаимозависимых алгоритмов. [210] [211] Наконец, использование многомерных методов, которые исследуют скрытую структуру данных, таких как факторный анализ и кластерный анализ , оказалось полезным в качестве аналитических подходов, которые выходят далеко за рамки двумерных подходов (например, таблиц непредвиденных обстоятельств ), обычно используемых с меньшими данными. наборы.
В здравоохранении и биологии традиционные научные подходы основаны на экспериментах. Для этих подходов ограничивающим фактором являются соответствующие данные, которые могут подтвердить или опровергнуть первоначальную гипотезу. [212] Сейчас в биологических науках принят новый постулат: информация, предоставляемая огромными объемами данных ( омики ) без предварительной гипотезы, дополняет, а иногда и необходима традиционным подходам, основанным на экспериментировании. [213] [214] В массовых подходах ограничивающим фактором является формулировка соответствующей гипотезы для объяснения данных. [215] пределы индукции («Скандал о славе науки и философии», CD Broad , 1926). Логика поиска перевернута, и необходимо учитывать [ нужна ссылка ]
Защитники конфиденциальности обеспокоены угрозой конфиденциальности, которую представляет увеличение объема хранения и интеграции личной информации ; Экспертные группы выпустили различные политические рекомендации, чтобы привести практику в соответствие с ожиданиями конфиденциальности. [216] Неправомерное использование больших данных в ряде случаев средствами массовой информации, компаниями и даже правительством позволило ликвидировать доверие почти ко всем фундаментальным институтам, поддерживающим общество. [217]
Барокас и Ниссенбаум утверждают, что одним из способов защиты отдельных пользователей является информирование о типах собираемой информации, о том, кому она передается, при каких ограничениях и для каких целей. [218]
Критика модели «V»
[ редактировать ]Модель больших данных «V» вызывает беспокойство, поскольку она сосредоточена на вычислительной масштабируемости и лишена потерь в восприятии и понятности информации. Это привело к созданию концепции когнитивных больших данных , которая характеризует приложения больших данных в соответствии с: [219]
- Полнота данных: понимание неочевидного из данных
- Корреляция данных, причинно-следственная связь и предсказуемость: причинность как необязательное требование для достижения предсказуемости
- Объяснимость и интерпретируемость: люди желают понять и принять то, что они понимают, тогда как алгоритмы с этим не справляются.
- Уровень автоматизированного принятия решений : алгоритмы, поддерживающие автоматизированное принятие решений и алгоритмическое самообучение.
Критика новизны
[ редактировать ]Большие наборы данных анализировались компьютерными машинами уже более ста лет, включая анализ переписи населения США, выполняемый . перфокарточными машинами IBM, которые вычисляли статистику, включая средние значения и отклонения населения по всему континенту В последние десятилетия научные эксперименты, такие как ЦЕРН, позволили получить данные такого же масштаба, что и нынешние коммерческие «большие данные». Однако в научных экспериментах данные, как правило, анализируются с использованием специализированных высокопроизводительных вычислительных (суперкомпьютерных) кластеров и сетей, а не облаков дешевых компьютеров, как в нынешней коммерческой волне, что подразумевает разницу как в культуре, так и в технологиях. куча.
Критика исполнения больших данных
[ редактировать ]Ульф-Дитрих Рейпс и Уве Мацат написали в 2014 году, что большие данные стали «причудой» в научных исследованиях. [189] Исследователь Дана Бойд выразила обеспокоенность по поводу использования больших данных в науке, пренебрегая такими принципами, как выбор репрезентативной выборки , из-за чрезмерной озабоченности обработкой огромных объемов данных. [220] Такой подход может привести к результатам, которые в той или иной степени имеют предвзятость . [221] Интеграция разнородных ресурсов данных (некоторые из которых можно считать большими данными, а другие нет) представляет собой огромные логистические и аналитические проблемы, но многие исследователи утверждают, что такая интеграция, вероятно, представляет собой наиболее многообещающие новые рубежи в науке. [222] В провокационной статье «Критические вопросы для больших данных» [223] авторы называют большие данные частью мифологии : «большие наборы данных предлагают более высокую форму интеллекта и знаний [...] с аурой правды, объективности и точности». Пользователи больших данных часто «теряются в огромном количестве цифр», а «работа с большими данными по-прежнему носит субъективный характер, и то, что они определяют количественно, не обязательно имеет больше претензий на объективную истину». [223] Последние разработки в области бизнес-аналитики, такие как упреждающая отчетность, в первую очередь направлены на повышение удобства использования больших данных за счет автоматической фильтрации бесполезных данных и корреляций . [224] Большие структуры полны ложных корреляций [225] либо из-за непричинных совпадений ( закон действительно больших чисел ), исключительно из-за природы большой случайности [226] ( теория Рэмси ), или существование неучтенных факторов , поэтому надежда первых экспериментаторов заставить большие базы данных чисел «говорить сами за себя» и совершить революцию в научном методе подвергается сомнению. [227] Кэтрин Такер указала на «ажиотаж» вокруг больших данных, написав: «Само по себе большие данные вряд ли будут иметь ценность». В статье поясняется: «Множество случаев, когда данные стоят дешево по сравнению с затратами на удержание специалистов для их обработки, позволяют предположить, что навыки обработки более важны, чем сами данные, в создании ценности для фирмы». [228]
Анализ больших данных часто оказывается поверхностным по сравнению с анализом небольших наборов данных. [229] Во многих проектах по работе с большими данными анализ больших данных не проводится, но проблема заключается в извлечении, преобразовании и загрузке части предварительной обработки данных. [229]
Большие данные — это модное словечко и «расплывчатый термин». [230] [231] но в то же время "одержимость" [231] с предпринимателями, консультантами, учеными и средствами массовой информации. Витрины больших данных, такие как Google Flu Trends, в последние годы не смогли дать хороших прогнозов, завысив количество вспышек гриппа в два раза. Точно так же награды Академии и прогнозы выборов, основанные исключительно на Твиттере, чаще оказывались неправильными, чем точными.Большие данные часто создают те же проблемы, что и малые данные; добавление дополнительных данных не решает проблемы предвзятости, но может подчеркнуть другие проблемы. В частности, такие источники данных, как Twitter, не являются репрезентативными для населения в целом, и результаты, полученные из таких источников, могут привести к неверным выводам. Google Translate , основанный на статистическом анализе текста на основе больших данных, хорошо справляется с переводом веб-страниц. Однако результаты из специализированных областей могут быть существенно искажены.С другой стороны, большие данные могут также создать новые проблемы, такие как проблема множественных сравнений : одновременная проверка большого набора гипотез может привести к множеству ложных результатов, которые ошибочно кажутся значимыми.Иоаннидис заявил, что «большинство опубликованных результатов исследований ложны». [232] по сути, из-за одного и того же эффекта: когда каждая из множества научных групп и исследователей проводит много экспериментов (т.е. обрабатывает большой объем научных данных; хотя и не с помощью технологии больших данных), вероятность того, что «значимый» результат окажется ложным, быстро растет — даже больше так, когда публикуются только положительные результаты.Более того, результаты анализа больших данных хороши настолько, насколько хороша модель, на которой они основаны. Например, большие данные использовались при попытке предсказать результаты президентских выборов в США в 2016 году. [233] с разной степенью успеха.
Критика полицейской деятельности и наблюдения за большими данными
[ редактировать ]Большие данные используются в полиции и наблюдении такими учреждениями, как правоохранительные органы и корпорации . [234] Из-за менее заметного характера наблюдения на основе данных по сравнению с традиционными методами полицейской деятельности, возражения против работы полиции с использованием больших данных возникают с меньшей вероятностью. Согласно книге Сары Брейн «Наблюдение за большими данными: случай работы полиции» , [235] Работа полиции с большими данными может воспроизводить существующее социальное неравенство тремя способами:
- Помещение людей под усиленное наблюдение с использованием математического и, следовательно, беспристрастного алгоритма.
- Увеличение охвата и числа людей, которые подлежат отслеживанию со стороны правоохранительных органов, и усугубление существующей расовой чрезмерной представленности в системе уголовного правосудия.
- Поощрение членов общества отказаться от взаимодействия с учреждениями, которые могут создать цифровой след, создавая тем самым препятствия для социальной интеграции.
Если эти потенциальные проблемы не будут исправлены или урегулированы, последствия контроля за большими данными могут продолжать формировать социальные иерархии. Сознательное использование больших данных может предотвратить превращение предубеждений на индивидуальном уровне в институциональные предубеждения, отмечает Брейн.
См. также
[ редактировать ]- Этика больших данных - Этика анализа массовых данных
- Модель зрелости больших данных - аспект информатики
- Большая память – большой объем оперативной памяти.
- Курирование данных — работа, выполняемая для обеспечения значимого и постоянного доступа к
- Хранилище, определяемое данными . Маркетинговый термин, обозначающий управление данными путем объединения уровней приложений, информации и хранения.
- Инженерия данных - подход к разработке программного обеспечения к проектированию и разработке информационных систем.
- Происхождение данных – происхождение и события данных
- Данные филантропии – Аспект культуры
- Наука о данных - область исследования, направленная на извлечение информации из данных.
- Датафикация – технологический тренд
- Документоориентированная база данных - Тип компьютерной программы.
- Список компаний, занимающихся большими данными
- Очень большая база данных — база данных, содержащая очень большой объем данных.
- XLDB - серия ежегодных конференций по базам данных, управлению данными и аналитике.
Ссылки
[ редактировать ]- ^ Гильберт, Мартин; Лопес, Присцила (2011). «Мировые технологические возможности для хранения, передачи и вычисления информации» . Наука . 332 (6025): 60–65. Бибкод : 2011Sci...332...60H . дои : 10.1126/science.1200970 . ПМИД 21310967 . S2CID 206531385 . Архивировано из оригинала 14 апреля 2016 года . Проверено 13 апреля 2016 г.
- ^ Брер, Том (июль 2016 г.). «Статистический анализ власти и современный «кризис» социальных наук» . Журнал маркетинговой аналитики . 4 (2–3). Лондон, Англия: Пэлгрейв Макмиллан : 61–65. дои : 10.1057/s41270-016-0001-3 . ISSN 2050-3318 .
- ^ Махдави-Дамгани, Бабак (2019). Модели, управляемые данными, и математические финансы: противостояние или оппозиция? (докторская диссертация). Оксфорд, Англия: Оксфордский университет . п. 21. ССНР 3521933 .
- ^ Макафи, Эндрю; Бриньольфссон, Эрик (1 октября 2012 г.). «Большие данные: революция в управлении» . Гарвардское деловое обозрение . 90 (10): 60–66, 68, 128. ISSN 0017-8012 . ПМИД 23074865 .
- ^ Перейти обратно: а б «5 В больших данных» . Перспективы здоровья Watson . 17 сентября 2016 г. Архивировано из оригинала 18 января 2021 г. Проверено 20 января 2021 г.
- ^ Каппа, Франческо; Ориани, Рафаэле; Перуффо, Энцо; Маккарти, Ян (2021). «Большие данные для создания и сохранения ценности в цифровой среде: анализ влияния объема, разнообразия и достоверности на эффективность деятельности компании» . Журнал управления инновациями в продуктах . 38 (1): 49–67. дои : 10.1111/jpim.12545 . ISSN 0737-6782 . S2CID 225209179 .
- ^ Бойд, Дана; Кроуфорд, Кейт (21 сентября 2011 г.). «Шесть провокаций для больших данных» . Сеть исследований социальных наук: Десятилетие времени Интернета: Симпозиум по динамике Интернета и общества . дои : 10.2139/ssrn.1926431 . S2CID 148610111 . Архивировано из оригинала 28 февраля 2020 года . Проверено 12 июля 2019 г.
- ^ Перейти обратно: а б с д и ж г «Данные, данные повсюду» . Экономист . 25 февраля 2010 г. Архивировано из оригинала 27 мая 2018 г. . Проверено 9 декабря 2012 года .
- ^ «Требуется сообразительность сообщества» . Природа . 455 (7209): 1 сентября 2008 г. Бибкод : 2008Natur.455....1. . дои : 10.1038/455001a . ПМИД 18769385 .
- ^ Райхман О.Дж., Джонс М.Б., член парламента Шильдхауэра (февраль 2011 г.). «Вызовы и возможности открытых данных в экологии» . Наука . 331 (6018): 703–5. Бибкод : 2011Sci...331..703R . дои : 10.1126/science.1197962 . ПМИД 21311007 . S2CID 22686503 . Архивировано из оригинала 19 октября 2020 года . Проверено 12 июля 2019 г.
- ^ Хеллерштейн, Джо (9 ноября 2008 г.). «Параллельное программирование в эпоху больших данных» . Блог Гигаом . Архивировано из оригинала 7 октября 2012 года . Проверено 21 апреля 2010 г.
- ^ Сегаран, Тоби; Хаммербахер, Джефф (2009). Красивые данные: истории создания элегантных решений для обработки данных . О'Рейли Медиа. п. 257. ИСБН 978-0-596-15711-1 . Архивировано из оригинала 12 мая 2016 года . Проверено 31 декабря 2015 г.
- ^ Перейти обратно: а б Хильберт М., Лопес П. (апрель 2011 г.). «Мировые технологические возможности для хранения, передачи и вычисления информации» (PDF) . Наука . 332 (6025): 60–5. Бибкод : 2011Sci...332...60H . дои : 10.1126/science.1200970 . ПМИД 21310967 . S2CID 206531385 . Архивировано (PDF) из оригинала 19 августа 2019 года . Проверено 11 мая 2019 г.
- ^ «IBM Что такое большие данные? – Использование больших данных на предприятии» . IBM.com. Архивировано из оригинала 24 августа 2013 года . Проверено 26 августа 2013 г.
- ^ Рейнзель, Дэвид; Ганц, Джон; Риднинг, Джон (13 апреля 2017 г.). «Эпоха данных 2025: эволюция данных к жизненно важным» (PDF) . seagate.com . Фрамингем, Массачусетс, США: Международная корпорация данных . Архивировано (PDF) из оригинала 8 декабря 2017 года . Проверено 2 ноября 2017 г.
- ^ «Согласно новому руководству IDC по расходам, глобальные расходы на решения для больших данных и аналитики достигнут 215,7 миллиардов долларов в 2021 году» . Архивировано из оригинала 23 июля 2022 года . Проверено 31 июля 2022 г.
- ^ «Доходы от больших данных и бизнес-аналитики в 2022 году» .
- ^ «Объем мирового рынка индустрии больших данных в 2011–2027 гг.» .
- ^ Перейти обратно: а б с Большие данные: следующий рубеж инноваций, конкуренции и производительности McKinsey Global Institute, май 2011 г.
- ^ Oracle и FSN, «Освоение больших данных: стратегии финансового директора по преобразованию понимания в возможности». Архивировано 4 августа 2013 г. в Wayback Machine , декабрь 2012 г.
- ^ Джейкобс, А. (6 июля 2009 г.). «Патологии больших данных» . ACMQueue . Архивировано из оригинала 8 декабря 2015 года . Проверено 21 апреля 2010 г.
- ^ Магулас, Роджер; Лорика, Бен (февраль 2009 г.). «Введение в большие данные» . Выпуск 2.0 (11). Севастополь, Калифорния: O'Reilly Media. Архивировано из оригинала 2 ноября 2021 года . Проверено 26 февраля 2021 г.
- ^ Джон Р. Мэши (25 апреля 1998 г.). «Большие данные… и следующая волна инфрастресса» (PDF) . Слайды из приглашенной беседы . Усеникс. Архивировано (PDF) из оригинала 12 октября 2016 г. Проверено 28 сентября 2016 г.
- ^ Стив Лор (1 февраля 2013 г.). «Происхождение «больших данных»: этимологический детектив» . Нью-Йорк Таймс . Архивировано из оригинала 6 марта 2016 года . Проверено 28 сентября 2016 г.
- ^ Перейти обратно: а б Снейдерс, Мацат и Рейпс 2012 .
- ^ Дедич, Н.; Станье, К. (2017). «На пути к дифференциации бизнес-аналитики, больших данных, анализа данных и открытия знаний» . Инновации в управлении и проектировании корпоративных информационных систем . Конспекты лекций по обработке деловой информации. Том. 285. Берлин; Гейдельберг: Международное издательство Springer. стр. 114–22. дои : 10.1007/978-3-319-58801-8_10 . ISBN 978-3-319-58800-1 . ISSN 1865-1356 . OCLC 909580101 . Архивировано из оригинала 27 ноября 2020 года . Проверено 7 сентября 2019 г.
- ^ Эвертс, Сара (2016). «Информационная перегрузка» . Дистилляции . Том. 2, нет. 2. С. 26–33. Архивировано из оригинала 3 апреля 2019 года . Проверено 22 марта 2018 г.
- ^ Ибрагим; Таргио Хашем, Абакер; Якуб, Ибрар; Бадрул Ануар, Нор; Мохтар, Салима; Гани, Абдулла; Улла Хан, Сами (2015). «Большие данные» об облачных вычислениях: обзор и открытые вопросы исследования». Информационные системы . 47 : 98–115. doi : 10.1016/j.is.2014.07.006 . S2CID 205488005 .
- ^ Граймс, Сет. «Большие данные: избегайте путаницы «Хочу V»» . Информационная неделя . Архивировано из оригинала 23 декабря 2015 года . Проверено 5 января 2016 г.
- ^ Фокс, Чарльз (25 марта 2018 г.). Наука о данных для транспорта . Учебники Springer по наукам о Земле, географии и окружающей среде. Спрингер. ISBN 9783319729527 . Архивировано из оригинала 1 апреля 2018 года . Проверено 31 марта 2018 г.
- ^ Китчин, Роб; Макардл, Гэвин (2016). «Что делает большие данные большими данными? Исследование онтологических характеристик 26 наборов данных» . Большие данные и общество . 3 : 1–10. дои : 10.1177/2053951716631130 . S2CID 55539845 .
- ^ Балазка, Доминик; Родигьеро, Дарио (2020). «Большие данные и маленький большой взрыв: эпистемологическая (р)эволюция» . Границы больших данных . 3 : 31. дои : 10.3389/fdata.2020.00031 . hdl : 1721.1/128865 . ПМЦ 7931920 . ПМИД 33693404 .
- ^ «Фокусизация больших данных и аналитики» (PDF) . Bigdataparis.com . Архивировано из оригинала (PDF) 25 февраля 2021 года . Проверено 8 октября 2017 г.
- ^ Перейти обратно: а б Биллингс С.А. «Идентификация нелинейных систем: методы NARMAX во временной, частотной и пространственно-временной областях». Уайли, 2013 г.
- ^ «Блог ANDSI » Большие данные DSI» . Andsi.fr . Архивировано из оригинала 10 октября 2017 года . Проверено 8 октября 2017 г.
- ^ Ле Эхо (3 апреля 2013 г.). «Les Echos – Большие данные потому, что данные низкой плотности? Низкая плотность информации как дискриминирующий фактор – Архивы» . Lesechos.fr . Архивировано из оригинала 30 апреля 2014 года . Проверено 8 октября 2017 г.
- ^ Сагироглу, Сереф (2013). «Большие данные: обзор». 2013 Международная конференция по технологиям и системам совместной работы (CTS) . стр. 42–47. дои : 10.1109/CTS.2013.6567202 . ISBN 978-1-4673-6404-1 . S2CID 5724608 .
- ^ Китчин, Роб; Макардл, Гэвин (17 февраля 2016 г.). «Что делает большие данные большими данными? Исследование онтологических характеристик 26 наборов данных» . Большие данные и общество . 3 (1): 205395171663113. doi : 10.1177/2053951716631130 .
- ^ Онай, Джейлан; Озтюрк, Элиф (2018). «Обзор исследований кредитного скоринга в эпоху больших данных». Журнал финансового регулирования и соответствия . 26 (3): 382–405. дои : 10.1108/JFRC-06-2017-0054 . S2CID 158895306 .
- ^ Четвертая V больших данных
- ^ «Измерение бизнес-ценности больших данных | IBM Big Data & Analytics Hub» . www.ibmbigdatahub.com . Архивировано из оригинала 28 января 2021 года . Проверено 20 января 2021 г.
- ^ Китчин, Роб; Макардл, Гэвин (5 января 2016 г.). «Что делает большие данные большими данными? Исследование онтологических характеристик 26 наборов данных» . Большие данные и общество . 3 (1): 205395171663113. doi : 10.1177/2053951716631130 . ISSN 2053-9517 .
- ^ «Опрос: размер крупнейших баз данных приближается к 30 терабайтам» . Eweek.com . 8 ноября 2003 г. Проверено 8 октября 2017 г.
- ^ «LexisNexis купит Seisint за 775 миллионов долларов» . Вашингтон Пост . Архивировано из оригинала 24 июля 2008 года . Проверено 15 июля 2004 г.
- ^ «Вашингтон Пост» . Вашингтон Пост . Архивировано из оригинала 19 октября 2016 года . Проверено 24 августа 2017 г.
- ^ Бертолуччи, Джефф «Hadoop: от эксперимента к ведущей платформе больших данных». Архивировано 23 ноября 2020 года на Wayback Machine , «Information Week», 2013. Проверено 14 ноября 2013 года.
- ^ Вебстер, Джон. «MapReduce: упрощенная обработка данных в больших кластерах». Архивировано 14 декабря 2009 г. на Wayback Machine , «Поисковое хранилище», 2004 г. Проверено 25 марта 2013 г.
- ^ «Предложение решений для больших данных» . МАЙК2.0. Архивировано из оригинала 16 марта 2013 года . Проверено 8 декабря 2013 г.
- ^ «Определение больших данных» . МАЙК2.0. Архивировано из оригинала 25 сентября 2018 года . Проверено 9 марта 2013 г.
- ^ Боя, К; Поковнику, А; Бэтаган, Л. (2012). «Распределенная параллельная архитектура для больших данных». Информатика Экономика . 16 (2): 116–127.
- ^ «Решение ключевых бизнес-задач с помощью большого озера данных» (PDF) . Hcltech.com . Август 2014 г. Архивировано (PDF) из оригинала 3 июля 2017 г. . Проверено 8 октября 2017 г.
- ^ «Метод проверки отказоустойчивости фреймворков MapReduce» (PDF) . Компьютерные сети. 2015. Архивировано (PDF) из оригинала 22 июля 2016 года . Проверено 13 апреля 2016 г.
- ^ Перейти обратно: а б Маньика, Джеймс; Чуй, Майкл; Бюген, Жак; Браун, Брэд; Доббс, Ричард; Роксбург, Чарльз; Байерс, Анджела Хунг (май 2011 г.). «Большие данные: следующий рубеж инноваций, конкуренции и производительности» (PDF) . Глобальный институт McKinsey. Архивировано (PDF) из оригинала 25 июля 2021 года . Проверено 22 мая 2021 г.
- ^ «Будущие направления в тензорных вычислениях и моделировании» (PDF) . Май 2009 г. Архивировано (PDF) из оригинала 17 апреля 2018 г. Проверено 4 января 2013 г.
- ^ Лу, Хайпин; Платаниотис, КН; Венецанопулос, АН (2011). «Обзор многолинейного обучения подпространства для тензорных данных» (PDF) . Распознавание образов . 44 (7): 1540–1551. Бибкод : 2011PatRe..44.1540L . дои : 10.1016/j.patcog.2011.01.004 . Архивировано (PDF) из оригинала 10 июля 2019 года . Проверено 21 января 2013 г.
- ^ Планана, Сабри; Янчак, Иван; Брезани, Питер; Верер, Александр (2016). «Обзор современного уровня интеллектуального анализа данных и языков интеграционных запросов». 2011 14-я Международная конференция по сетевым информационным системам . Компьютерное общество IEEE. стр. 341–348. arXiv : 1603.01113 . Бибкод : 2016arXiv160301113P . дои : 10.1109/НБиС.2011.58 . ISBN 978-1-4577-0789-6 . S2CID 9285984 .
- ^ Ван, Яньдун; Голдстоун, Робин; Ю, Вэйкуань; Ван, Дэн (октябрь 2014 г.). «Характеристика и оптимизация резидентной памяти MapReduce в системах HPC». 2014 28-й Международный симпозиум IEEE по параллельной и распределенной обработке . IEEE. стр. 799–808. дои : 10.1109/IPDPS.2014.87 . ISBN 978-1-4799-3800-1 . S2CID 11157612 .
- ^ Л'Эрё, А.; Гролингер, К.; Эльямани, ХФ; Капрец, МАМ (2017). «Машинное обучение с большими данными: проблемы и подходы» . Доступ IEEE . 5 : 7776–7797. Бибкод : 2017IEEA...5.7776L . дои : 10.1109/ACCESS.2017.2696365 . ISSN 2169-3536 .
- ^ Монаш, Курт (30 апреля 2009 г.). «Два огромных хранилища данных eBay» . Архивировано из оригинала 31 марта 2019 года . Проверено 11 ноября 2010 г.
Монаш, Курт (6 октября 2010 г.). «Продолжение eBay – выход Greenplum, Teradata > 10 петабайт, Hadoop имеет некоторую ценность и многое другое» . Архивировано из оригинала 31 марта 2019 года . Проверено 11 ноября 2010 г. - ^ «Ресурсы о том, как топологический анализ данных используется для анализа больших данных» . Аясди. Архивировано из оригинала 3 марта 2013 года . Проверено 5 марта 2013 г.
- ^ Новости CNET (1 апреля 2011 г.). «Сети хранения данных применять не обязательно» . Архивировано из оригинала 18 октября 2013 года . Проверено 17 апреля 2013 г.
- ^ Гильберт, Мартин (2014). «Каково содержание мировых технологических информационных и коммуникационных возможностей: сколько текста, изображений, аудио и видео?» . Информационное общество . 30 (2): 127–143. дои : 10.1080/01972243.2013.873748 . S2CID 45759014 . Архивировано из оригинала 24 июня 2020 года . Проверено 12 июля 2019 г.
- ^ Раджпурохит, Анмол (11 июля 2014 г.). «Интервью: Эми Гершкофф, директор по клиентской аналитике и анализу eBay, о том, как разрабатывать собственные внутренние инструменты бизнес-аналитики» . КДнаггетс . Архивировано из оригинала 14 июля 2014 года . Проверено 14 июля 2014 г.
В целом я считаю, что готовые инструменты бизнес-аналитики не отвечают потребностям клиентов, которые хотят получить индивидуальную информацию из своих данных. Поэтому для средних и крупных организаций, имеющих доступ к сильным техническим специалистам, я обычно рекомендую создавать собственные собственные решения.
- ^ «Правительство и большие данные: использование, проблемы и потенциал» . Компьютерный мир . 21 марта 2012 года. Архивировано из оригинала 15 сентября 2016 года . Проверено 12 сентября 2016 г.
- ^ «Белая книга: Большие данные для развития: возможности и вызовы» . Глобальный Пульс . Объединенные Нации. 2012. Архивировано из оригинала 1 июня 2020 года . Проверено 13 апреля 2016 г.
- ^ «Большие данные, большое влияние: новые возможности для международного развития» . Всемирный экономический форум и Vital Wave Consulting. Архивировано из оригинала 1 июня 2020 года . Проверено 24 августа 2012 г.
- ^ Перейти обратно: а б с д и Гильберт 2016 .
- ^ «Елена Квочко, Четыре способа говорить о больших данных (серия «Информационно-коммуникационные технологии для развития»)» . worldbank.org. 4 декабря 2012 года. Архивировано из оригинала 15 декабря 2012 года . Проверено 30 мая 2012 г.
- ^ «Даниэле Медри: Большие данные и бизнес: продолжающаяся революция» . Просмотры статистики. 21 октября 2013 года. Архивировано из оригинала 17 июня 2015 года . Проверено 21 июня 2015 г.
- ^ Тобиас Кноблох и Юлия Манске (11 января 2016 г.). «Ответственное использование данных» . D+C, Развитие и сотрудничество . Архивировано из оригинала 13 января 2017 года . Проверено 11 января 2017 г.
- ^ Манн С. и Хильберт М. (2020). AI4D: Искусственный интеллект для развития. Международный журнал коммуникации, 14 (0), 21. https://www.martinhilbert.net/ai4d-artificial-intelligence-for-development/. Архивировано 22 апреля 2021 г. в Wayback Machine.
- ^ Блюменшток, JE (2016). Борьба с бедностью с помощью данных. Наука, 353(6301), 753–754. https://doi.org/10.1126/science.aah5217 Архивировано 1 июня 2022 г. в Wayback Machine.
- ^ Блюменсток Дж., Кадамуро Г. и Он Р. (2015). Прогнозирование бедности и богатства на основе метаданных мобильных телефонов. Наука, 350 (6264), 1073–1076. https://doi.org/10.1126/science.aac4420 Архивировано 1 июня 2022 г. в Wayback Machine.
- ^ Джин, Н., Берк, М., Се, М., Дэвис, В.М., Лобелл, Д.Б., и Эрмон, С. (2016). Сочетание спутниковых изображений и машинного обучения для прогнозирования бедности. Наука, 353 (6301), 790–794. https://doi.org/10.1126/science.aaf7894 Архивировано 1 июня 2022 г. в Wayback Machine.
- ^ Перейти обратно: а б Гильберт М. и Лу К. (2020). Анализ онлайн-рынка труда в Латинской Америке и странах Карибского бассейна (UN ECLAC LC/TS.2020/83; стр. 79). Экономическая комиссия ООН для Латинской Америки и Карибского бассейна. https://www.cepal.org/en/publications/45892-online-job-market-trace-latin-america-and-caribbean . Архивировано 22 сентября 2020 г. на Wayback Machine.
- ^ ЭКЛАК ООН (Экономическая комиссия ООН для Латинской Америки и Карибского бассейна). (2020). Отслеживание цифрового следа в Латинской Америке и Карибском бассейне: уроки, извлеченные из использования больших данных для оценки цифровой экономики (Производственное развитие, гендерные вопросы LC/TS.2020/12; Documentos de Proyecto). ЭКЛАК ООН. https://repositorio.cepal.org/handle/11362/45484. Архивировано 18 сентября 2020 г. в Wayback Machine.
- ^ Банерджи, Амитав; Чаудхури, Супракаш (2010). «Статистика без слез: Популяции и выборки» . Журнал промышленной психиатрии . 19 (1): 60–65. дои : 10.4103/0972-6748.77642 . ISSN 0972-6748 . ПМК 3105563 . ПМИД 21694795 .
- ^ Олдридж, Ирен (2016). Риск в реальном времени: что инвесторам следует знать о финансовых технологиях, высокочастотной торговле и мгновенных сбоях . Стивен Кравив. Сомерсет: John Wiley & Sons, Incorporated. ISBN 978-1-119-31906-1 . OCLC 972292212 .
- ^ Олдридж, Ирен (2021). Наука о больших данных в финансах . Марко Авельянеда. Хобокен, Нью-Джерси: Уайли. ISBN 978-1-119-60297-2 . OCLC 1184122216 .
- ^ Хасан, штат Мэриленд Моршадул; Попп, Йожеф; Ола, Юдит (12 марта 2020 г.). «Современная ситуация и влияние больших данных на финансы» . Журнал больших данных . 7 (1): 21. дои : 10.1186/s40537-020-00291-z . ISSN 2196-1115 .
- ^ Хузер В., Чимино Дж. Дж. (июль 2016 г.). «Надвигающиеся проблемы использования больших данных» . Международный журнал радиационной онкологии, биологии, физики . 95 (3): 890–894. дои : 10.1016/j.ijrobp.2015.10.060 . ПМК 4860172 . ПМИД 26797535 .
- ^ Сейдич, Эрвин; Фальк, Тьяго Х. (4 июля 2018 г.). Обработка сигналов и машинное обучение для больших биомедицинских данных . Сейдич, Эрвин, Фальк, Тьяго Х. [Место публикации не указано]. ISBN 9781351061216 . OCLC 1044733829 .
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка ) - ^ Рагхупати В., Рагхупати В. (декабрь 2014 г.). «Аналитика больших данных в здравоохранении: перспективы и потенциал» . Информатика и системы здравоохранения . 2 (1): 3. дои : 10.1186/2047-2501-2-3 . ПМЦ 4341817 . ПМИД 25825667 .
- ^ Вицеконти М., Хантер П., Хоуз Р. (июль 2015 г.). «Большие данные, большие знания: большие данные для персонализированного здравоохранения» (PDF) . Журнал IEEE по биомедицинской и медицинской информатике . 19 (4): 1209–15. дои : 10.1109/JBHI.2015.2406883 . ПМИД 26218867 . S2CID 14710821 . Архивировано (PDF) из оригинала 23 июля 2018 года . Проверено 21 сентября 2019 г.
- ^ О'Донохью, Джон; Герберт, Джон (1 октября 2012 г.). «Управление данными в среде мобильного здравоохранения: датчики пациентов, мобильные устройства и базы данных». Журнал качества данных и информации . 4 (1): 5:1–5:20. дои : 10.1145/2378016.2378021 . S2CID 2318649 .
- ^ Миркес Э.М., Коутс Т.Дж., Левсли Дж., Горбан А.Н. (август 2016 г.). «Обработка недостающих данных в большом наборе медицинских данных: пример неизвестных результатов травм». Компьютеры в биологии и медицине . 75 : 203–16. arXiv : 1604.00627 . Бибкод : 2016arXiv160400627M . doi : 10.1016/j.compbiomed.2016.06.004 . ПМИД 27318570 . S2CID 5874067 .
- ^ Мердок Т.Б., Детский А.С. (апрель 2013 г.). «Неизбежное применение больших данных в здравоохранении». ДЖАМА . 309 (13): 1351–2. дои : 10.1001/jama.2013.393 . ПМИД 23549579 . S2CID 20462354 .
- ^ Вайена Э., Салате М., Мэдофф Л.К., Браунштейн Дж.С. (февраль 2015 г.). «Этические проблемы больших данных в общественном здравоохранении» . PLOS Вычислительная биология . 11 (2): e1003904. Бибкод : 2015PLSCB..11E3904V . дои : 10.1371/journal.pcbi.1003904 . ПМК 4321985 . ПМИД 25664461 .
- ^ Коупленд, CS (июль – август 2017 г.). «Обнаружение управления данными» (PDF) . Журнал здравоохранения Нового Орлеана : 22–27. Архивировано (PDF) из оригинала 5 декабря 2019 года . Проверено 5 декабря 2019 г.
- ^ Янасэ и Триантафиллу 2019 .
- ^ Донг Х, Бахрус Н., Садху Э., Джексон Т., Чухман М., Джонсон Р., Бойд А., Хайнс Д. (2013). «Использование платформы Hadoop для крупномасштабных приложений клинической информатики». Совместные саммиты AMIA по трансляционным научным исследованиям. Совместные саммиты AMIA по трансляционной науке . 2013 : 53. ПМИД 24303235 .
- ^ Клюни, Д. (2013). «Томосинтез молочной железы бросает вызов инфраструктуре цифровой визуализации» . Группа науки и медицины. Архивировано из оригинала 24 февраля 2021 года . Проверено 28 ноября 2023 г.
- ^ Янасэ Дж., Триантафиллу Э. (2019b). «Семь ключевых задач будущего компьютерной диагностики в медицине». Международный журнал медицинской информатики . 129 : 413–22. doi : 10.1016/j.ijmedinf.2019.06.017 . PMID 31445285 . S2CID 198287435 .
- ^ «Степени в области больших данных: причуда или быстрый путь к карьерному успеху» . Форбс . Архивировано из оригинала 3 марта 2016 года . Проверено 21 февраля 2016 г.
- ^ «Нью-Йорк открывает новый учебный лагерь для специалистов по обработке данных: он бесплатный, но попасть в него труднее, чем в Гарвард» . Венчурный бит . Архивировано из оригинала 15 февраля 2016 года . Проверено 21 февраля 2016 г.
- ^ Ведель, Мишель; Каннан, ПК (2016). «Маркетинговая аналитика для сред с большим объемом данных». Журнал маркетинга . 80 (6): 97–121. дои : 10.1509/jm.15.0413 . S2CID 168410284 .
- ^ Могли, Ник; Туров, Джозеф (2014). «Реклама, большие данные и очистка публичной сферы: новые подходы маркетологов к субсидированию контента». Международный журнал коммуникации . 8 : 1710–1726.
- ^ «Почему агентства цифровой рекламы терпят неудачу в привлечении клиентов и остро нуждаются в обновлении с помощью искусственного интеллекта» . Ишти.орг . 15 апреля 2018 года. Архивировано из оригинала 12 февраля 2019 года . Проверено 15 апреля 2018 г.
- ^ «Большие данные и аналитика: C4 и Genius Digital» . Ibc.org . Архивировано из оригинала 8 октября 2017 года . Проверено 8 октября 2017 г.
- ^ Маршалл Аллен (17 июля 2018 г.). «Медицинские страховщики собирают информацию о вас – и это может поднять ваши ставки» . www.propublica.org . Архивировано из оригинала 21 июля 2018 года . Проверено 21 июля 2018 г.
- ^ «QuiO названа чемпионом по инновациям на конкурсе Accenture HealthTech Innovation Challenge» . Businesswire.com . 10 января 2017 года. Архивировано из оригинала 22 марта 2017 года . Проверено 8 октября 2017 г.
- ^ «Программная платформа для инноваций в операционных технологиях» (PDF) . Predix.com . Архивировано из оригинала (PDF) 22 марта 2017 года . Проверено 8 октября 2017 г.
- ^ З. Дженифер Ван (март 2017 г.). «Умный транспорт на основе больших данных: основная история мобильности, преобразованной с помощью Интернета вещей» . Архивировано из оригинала 4 июля 2018 года . Проверено 4 июля 2018 г.
- ^ «Эта штука Интернета вещей» . 22 июня 2009 г. Архивировано из оригинала 2 мая 2013 г. . Проверено 29 декабря 2017 г.
- ^ Перейти обратно: а б Сольник, Рэй. «Время пришло: аналитические возможности для ИТ-операций» . Журнал дата-центра . Архивировано из оригинала 4 августа 2016 года . Проверено 21 июня 2016 г.
- ^ «BigSurv: большие данные и исследовательская наука» . Проверено 15 октября 2023 г.
- ^ Эк, Адам; Казар, Ана Лусия Кордова; Каллегаро, Марио; Бимер, Пол (2021). « Большие данные встречаются с исследовательской наукой » . Компьютерный обзор социальных наук . 39 (4): 484–488. дои : 10.1177/0894439319883393 .
- ^ «Специальный выпуск: Большие данные встречаются с исследовательской наукой» . Журнал Королевского статистического общества, серия A. 185 (С2): С165–С166.
- ^ «Интеграция данных опросов и данных, не связанных с опросами, для измерения поведения и общественного мнения» . www.springeropen.com . Проверено 19 октября 2023 г.
- ^ Хилл, Крейг А.; Бимер, Пол П.; Баскирк, Трент Д.; Япец, Лилли; Киршнер, Антье; Колеников, Стас; Либерг, Ларс Э., ред. (13 октября 2020 г.). Большие данные встречаются с исследовательской наукой: сборник инновационных методов (1-е изд.). Уайли. дои : 10.1002/9781118976357 . ISBN 978-1-118-97632-6 . S2CID 240797608 .
- ^ «Бывшие лауреаты премии новаторов Уоррена Дж. Митофски - AAPOR» . 7 июня 2023 г. Проверено 19 октября 2023 г.
- ^ Стронг, К. (2015). Гуманизация больших данных: маркетинг на стыке данных, социальных наук и понимания потребителей . Коган Пейдж.
- ^ Стронг, К. (2015). Гуманизация больших данных: маркетинг на стыке данных, социальных наук и понимания потребителей . Коган Пейдж.
- ^ Бериша Б., Мезиу Э. и Шабани И. (2022). Аналитика больших данных в облачных вычислениях: обзор. Журнал облачных вычислений , 11 (1), 1-10. дои : 10.1186/s13677-022-00301-w
- ^ Босх, Волкер (01 ноября 2016 г.). «Большие данные в исследованиях рынка: почему больше данных не означает автоматически лучшую информацию». Обзор маркетинговой информации NIM . 8 (2): 56–63. два : 10.1515/gfkmir-2016-0017 .
- ^ Макфарланд, Дэниел А; МакФарланд, Х. Ричард (1 декабря 2015 г.). «Большие данные и опасность быть неточными». Большие данные и общество . 2 (2): 205395171560249. дои : 10.1177/2053951715602495 . ISSN 2053-9517 .
- ^ Шивараджа, Утайасанкар; Камаль, Мухаммад Мустафа; Ирани, Захир; Вираккоди, Вишант (01 января 2017 г.). «Критический анализ проблем больших данных и аналитических методов». Журнал бизнес-исследований . 70 : 263–286. дои : 10.1016/j.jbusres.2016.08.001 . ISSN 0148-2963 .
- ^ Де Лука, Луиджи М.; Херхаузен, Деннис; Троило, Габриэле; Росси, Андреа (01 июля 2021 г.). «Как и когда окупаются инвестиции в большие данные? Роль маркетинговых возможностей и инноваций в сфере услуг». Журнал Академии маркетинговых наук . 49 (4): 790–810.
- ^ Гасемагаи, Марьям; Чалич, Горан (январь 2020 г.). «Оценка влияния больших данных на инновационные показатели компаний: большие данные не всегда являются лучшими данными» . Журнал бизнес-исследований . 108 : 147–162. дои : 10.1016/j.jbusres.2019.09.062 . ISSN 0148-2963 .
- ^ Де Лука, Луиджи М.; Херхаузен, Деннис; Троило, Габриэле; Росси, Андреа (01 июля 2021 г.). «Как и когда окупаются инвестиции в большие данные? Роль маркетинговых возможностей и инноваций в сфере услуг». Журнал Академии маркетинговых наук . 49 (4): 790–810.
- ^ Де Лука, Луиджи М.; Херхаузен, Деннис; Троило, Габриэле; Росси, Андреа (01 июля 2021 г.). «Как и когда окупаются инвестиции в большие данные? Роль маркетинговых возможностей и инноваций в сфере услуг». Журнал Академии маркетинговых наук . 49 (4): 790–810.
- ^ Грибаускас, Андрюс; Пилинкене, Вайда; Стунджиене, Алина (3 августа 2021 г.). «Прогнозная аналитика с использованием больших данных для рынка недвижимости во время пандемии COVID-19». Журнал больших данных . 8 (1): 105. два : 10.1186/s40537-021-00476-0 . ISSN 2196-1115 . PMC 8329615. PMID 34367876.
- ^ Джош Рогин (2 августа 2018 г.). «Этническая чистка возвращается – в Китае» . Нет. Вашингтон Пост. Архивировано из оригинала 31 марта 2019 года . Проверено 4 августа 2018 г.
Добавьте к этому беспрецедентный режим безопасности и наблюдения в Синьцзяне, который включает в себя всеобъемлющий мониторинг на основе удостоверений личности, контрольно-пропускных пунктов, распознавания лиц и сбора ДНК у миллионов людей. Власти передают все эти данные в машину искусственного интеллекта, которая оценивает лояльность людей к Коммунистической партии, чтобы контролировать каждый аспект их жизни.
- ^ «Китай: Большие данные способствуют репрессиям в регионе меньшинств: программа превентивной полицейской деятельности помечает людей для расследований и задержаний» . hrw.org . Хьюман Райтс Вотч. 26 февраля 2018 года. Архивировано из оригинала 21 декабря 2019 года . Проверено 4 августа 2018 г.
- ^ «Дисциплина и наказание: рождение системы социального кредита в Китае» . Нация . 23 января 2019 года. Архивировано из оригинала 13 сентября 2019 года . Проверено 8 августа 2019 г.
- ^ «Китайская система мониторинга поведения запрещает некоторым путешествовать и покупать недвижимость» . Новости CBS . 24 апреля 2018 г. Архивировано из оригинала 13 августа 2019 г. . Проверено 8 августа 2019 г.
- ^ «Сложная правда о системе социального кредита Китая» . ПРОВОДНОЙ . 21 января 2019 года. Архивировано из оригинала 8 августа 2019 года . Проверено 8 августа 2019 г.
- ^ «Новости: Живая Мята» . Достаточно ли индийские компании понимают большие данные? . Живая мята. 23 июня 2014 года. Архивировано из оригинала 29 ноября 2014 года . Проверено 22 ноября 2014 г.
- ^ «Израильский стартап использует большие данные и минимальное оборудование для лечения диабета» . Таймс Израиля . Архивировано из оригинала 1 марта 2018 года . Проверено 28 февраля 2018 г.
- ^ Сингх, Гурпаркаш; Шультесс, Дуэйн; Хьюз, Найджел; Ванньювенхейз, Барт; Калра, Дипак (2018). «Большие данные реального мира для клинических исследований и разработки лекарств» . Открытие наркотиков сегодня . 23 (3): 652–660. дои : 10.1016/j.drudis.2017.12.002 . ПМИД 29294362 .
- ^ «Последние достижения мобильных облачных вычислений и Интернета вещей для приложений больших данных: опрос» . Международный журнал сетевого управления. 11 марта 2016 г. Архивировано из оригинала 1 июня 2022 г. Проверено 14 сентября 2016 г.
- ^ Калил, Том (29 марта 2012 г.). «Большие данные – это большое дело» . Белый дом . Архивировано из оригинала 10 января 2017 года . Проверено 26 сентября 2012 г. - из Национального архива .
- ^ Администрация Президента (март 2012 г.). «Большие данные в федеральном правительстве» (PDF) . Управление научно-технической политики . Архивировано (PDF) из оригинала 21 января 2017 года . Проверено 26 сентября 2012 г. - из Национального архива .
- ^ Лэмпитт, Эндрю (14 февраля 2013 г.). «Реальная история о том, как анализ больших данных помог Обаме победить» . Инфомир . Архивировано из оригинала 5 июля 2014 года . Проверено 31 мая 2014 г.
- ^ «Ноябрь 2023 | ТОП500» . Архивировано из оригинала 7 апреля 2024 года . Проверено 20 апреля 2024 г.
- ^ Гувер, Дж. Николас. «10 самых мощных государственных суперкомпьютеров» . Информационная неделя . УБМ. Архивировано из оригинала 16 октября 2013 года . Проверено 26 сентября 2012 г.
- ^ Бэмфорд, Джеймс (15 марта 2012 г.). «АНБ строит крупнейший в стране шпионский центр (смотрите, что говорите)» . Проводной . Архивировано из оригинала 4 апреля 2012 года . Проверено 18 марта 2013 г.
- ^ «Проведена церемония закладки фундамента центра обработки данных в Юте стоимостью 1,2 миллиарда долларов» . Агентство национальной безопасности Центральная служба безопасности. Архивировано из оригинала 5 сентября 2013 года . Проверено 18 марта 2013 г.
- ^ Хилл, Кашмир. «Чертежи смехотворно дорогого центра обработки данных АНБ в штате Юта позволяют предположить, что он содержит меньше информации, чем предполагалось» . Форбс . Архивировано из оригинала 29 марта 2018 года . Проверено 31 октября 2013 г.
- ^ Смит, Джерри; Холлман, Бен (12 июня 2013 г.). «Споры о шпионаже АНБ подчеркивают важность больших данных» . Хаффингтон Пост . Архивировано из оригинала 19 июля 2017 года . Проверено 7 мая 2018 г.
- ^ Вингфилд, Ник (12 марта 2013 г.). «Более точное прогнозирование поездок на работу для потенциальных покупателей жилья» . Нью-Йорк Таймс . Архивировано из оригинала 29 мая 2013 года . Проверено 21 июля 2013 г.
- ^ «FICO® Falcon® Менеджер по борьбе с мошенничеством» . Фико.com. Архивировано из оригинала 11 ноября 2012 года . Проверено 21 июля 2013 г.
- ^ Бриньольфссон, Эрик; Ху, Ю Джеффри; Рахман, Мохаммад С. (21 мая 2013 г.). «Конкуренция в эпоху омниканальной розничной торговли» . Обзор менеджмента Слоана MIT .
- ^ Александру, Дэн. «Проф» (PDF) . cds.cern.ch. ЦЕРН. Архивировано (PDF) из оригинала 15 июля 2017 года . Проверено 24 марта 2015 г.
- ^ «Брошюра БАК, английская версия. Презентация самого большого и мощного ускорителя частиц в мире — Большого адронного коллайдера (БАК), запущенного в 2008 году. Для общего сведения объясняются его роль, характеристики, технологии и т. д. общественность» . ЦЕРН-Брошюра-2010-006-Рус. Брошюра по БАК, английская версия . ЦЕРН. Архивировано из оригинала 19 марта 2019 года . Проверено 20 января 2013 г.
- ^ «Руководство по LHC, английская версия. Сборник фактов и цифр о Большом адронном коллайдере (БАК) в форме вопросов и ответов» . ЦЕРН-Брошюра-2008-001-Рус. Руководство по БАК, английская версия . ЦЕРН. Архивировано из оригинала 7 апреля 2020 года . Проверено 20 января 2013 г.
- ^ Брамфил, Джефф (19 января 2011 г.). «Физика высоких энергий: по петабайтному шоссе» . Природа . 469 (7330): 282–83. Бибкод : 2011Natur.469..282B . дои : 10.1038/469282a . ПМИД 21248814 . S2CID 533166 .
- ^ «IBM Research – Цюрих» (PDF) . Цюрих.ibm.com . Архивировано из оригинала 1 июня 2022 года . Проверено 8 октября 2017 г.
- ^ «Будущие массивы телескопов стимулируют развитие обработки эксабайтов» . Арс Техника . 2 апреля 2012 г. Архивировано из оригинала 31 марта 2019 г. . Проверено 15 апреля 2015 г.
- ^ «Заявка Австралии на массив квадратных километров – взгляд изнутри» . Разговор . 1 февраля 2012 года. Архивировано из оригинала 12 октября 2016 года . Проверено 27 сентября 2016 г.
- ^ «Делорт П., Форум технологического прогнозирования ICCP ОЭСР, 2012 г.» (PDF) . ОЭСР.org . Архивировано (PDF) из оригинала 19 июня 2017 года . Проверено 8 октября 2017 г.
- ^ «НАСА - НАСА Годдард представляет Центр НАСА по моделированию климата» . НАСА.gov . Архивировано из оригинала 3 апреля 2016 года . Проверено 13 апреля 2016 г.
- ^ Вебстер, Фил. «Суперкомпьютеры климата: миссия НАСА по работе с большими данными» . ЦСК Мир . Корпорация компьютерных наук. Архивировано из оригинала 4 января 2013 года . Проверено 18 января 2013 г.
- ^ «Эти шесть великих идей нейробиологии могут совершить прыжок из лаборатории на рынок» . Глобус и почта . 20 ноября 2014 г. Архивировано из оригинала 11 октября 2016 г. . Проверено 1 октября 2016 г.
- ^ «DNAstack обрабатывает огромные и сложные наборы данных ДНК с помощью Google Genomics» . Облачная платформа Google. Архивировано из оригинала 24 сентября 2016 года . Проверено 1 октября 2016 г.
- ^ «23andMe – Родословная» . 23andme.com . Архивировано из оригинала 18 декабря 2016 года . Проверено 29 декабря 2016 г.
- ^ Перейти обратно: а б Потенца, Алессандра (13 июля 2016 г.). «23andMe хочет, чтобы исследователи использовали ее наборы, чтобы расширить свою коллекцию генетических данных» . Грань . Архивировано из оригинала 29 декабря 2016 года . Проверено 29 декабря 2016 г.
- ^ «Этот стартап секвенирует вашу ДНК, чтобы вы могли внести свой вклад в медицинские исследования» . Компания Фаст . 23 декабря 2016 года. Архивировано из оригинала 29 декабря 2016 года . Проверено 29 декабря 2016 г.
- ^ Сейф, Чарльз. «23andMe ужасен, но не по тем причинам, по которым думает FDA» . Научный американец . Архивировано из оригинала 29 декабря 2016 года . Проверено 29 декабря 2016 г.
- ^ Залесский, Эндрю (22 июня 2016 г.). «Этот биотехнологический стартап делает ставку на то, что ваши гены создадут следующее чудо-лекарство» . CNBC. Архивировано из оригинала 29 декабря 2016 года . Проверено 29 декабря 2016 г.
- ^ Регаладо, Антонио. «Как 23andMe превратила вашу ДНК в машину по разработке лекарств стоимостью 1 миллиард долларов» . Обзор технологий Массачусетского технологического института . Архивировано из оригинала 29 декабря 2016 года . Проверено 29 декабря 2016 г.
- ^ «23andMe сообщает о резком росте запросов на данные после исследования депрессии Pfizer | FierceBiotech» . www.fightbiotech.com . 22 августа 2016 года. Архивировано из оригинала 29 декабря 2016 года . Проверено 29 декабря 2016 г.
- ^ Полюбуйтесь Мойо (23 октября 2015 г.). «Ученые, работающие с данными, предсказывают поражение Спрингбока» . itweb.co.za . Архивировано из оригинала 22 декабря 2015 года . Проверено 12 декабря 2015 г.
- ^ Бай, Чжунбо; Бай, Сяомэй (2021). «Большие данные о спорте: управление, анализ, приложения и проблемы» . Сложность . 2021 : 1–11. дои : 10.1155/2021/6676297 .
- ^ Регина Пазвакавамбва (17 ноября 2015 г.). «Прогнозная аналитика, большие данные меняют спорт» . itweb.co.za . Архивировано из оригинала 22 декабря 2015 года . Проверено 12 декабря 2015 г.
- ^ Дэйв Райан (13 ноября 2015 г.). «Спорт: где большие данные наконец-то обретают смысл» . huffingtonpost.com . Архивировано из оригинала 22 декабря 2015 года . Проверено 12 декабря 2015 г.
- ^ Фрэнк Би. «Как команды Формулы-1 используют большие данные, чтобы получить преимущество» . Форбс . Архивировано из оригинала 20 декабря 2015 года . Проверено 12 декабря 2015 г.
- ^ Тэй, Лиз. «Внутри хранилища данных eBay объемом 90 ПБ» . ITНовости. Архивировано из оригинала 15 февраля 2016 года . Проверено 12 февраля 2016 г.
- ^ Лейтон, Джулия (25 января 2006 г.). «Технологии Амазонки» . Деньги.howstuffworks.com. Архивировано из оригинала 28 февраля 2013 года . Проверено 5 марта 2013 г.
- ^ «Масштабирование Facebook до 500 миллионов пользователей и выше» . Facebook.com. Архивировано из оригинала 5 июля 2013 года . Проверено 21 июля 2013 г.
- ^ Констин, Джош (27 июня 2017 г.). «У Facebook сейчас 2 миллиарда пользователей в месяц… и ответственность» . ТехКранч . Архивировано из оригинала 27 декабря 2020 года . Проверено 3 сентября 2018 г.
- ^ «Google по-прежнему выполняет не менее 1 триллиона поисковых запросов в год» . Земля поисковых систем . 16 января 2015 года. Архивировано из оригинала 15 апреля 2015 года . Проверено 15 апреля 2015 г.
- ^ Халим, Абид; Джавайд, Мохд; Хан, Ибрагим; Вайшья, Раджу (2020). «Значительные применения больших данных в условиях пандемии COVID-19» . Индийский журнал ортопедии . 54 (4): 526–528. дои : 10.1007/s43465-020-00129-z . ПМК 7204193 . ПМИД 32382166 .
- ^ Мананкур, Винсент (10 марта 2020 г.). «Коронавирус проверяет решимость Европы в отношении конфиденциальности» . Политик . Архивировано из оригинала 20 марта 2020 года . Проверено 30 октября 2020 г. .
- ^ Чоудхури, Амит Рой (27 марта 2020 г.). «Правительство во времена короны» . Губернаторский инсайдер . Архивировано из оригинала 20 марта 2020 года . Проверено 30 октября 2020 г. .
- ^ Селлан-Джонс, Рори (11 февраля 2020 г.). «Китай запускает приложение «детектор близкого контакта» с коронавирусом» . Би-би-си . Архивировано из оригинала 28 февраля 2020 года . Проверено 30 октября 2020 г. .
- ^ Сивах, Гаутам; Эсмаилпур, Амир (март 2014 г.). Зашифрованный поиск и формирование кластеров в больших данных (PDF) . Конференция ASEE 2014 Зона I. Университет Бриджпорта , Бриджпорт , Коннектикут, США. Архивировано из оригинала (PDF) 9 августа 2014 года . Проверено 26 июля 2014 г.
- ^ «Администрация Обамы представляет инициативу «больших данных»: объявляет о вложении 200 миллионов долларов в новые инвестиции в исследования и разработки» (PDF) . Управление научно-технической политики . Архивировано (PDF) из оригинала 21 января 2017 года – в Национальном архиве .
- ^ «AMPLab в Калифорнийском университете в Беркли» . Amplab.cs.berkeley.edu. Архивировано из оригинала 6 мая 2011 года . Проверено 5 марта 2013 г.
- ^ «NSF возглавляет федеральные усилия в области больших данных» . Национальный научный фонд (NSF). 29 марта 2012 г. Архивировано из оригинала 31 марта 2019 г. . Проверено 6 апреля 2018 г.
- ^ Тимоти Хантер; Теодор Молдован; Матей Захария; Джастин Ма; Майкл Франклин; Питер Аббель ; Александр Байен (октябрь 2011 г.). Масштабирование системы Mobile Millennium в облаке . Архивировано из оригинала 31 марта 2019 года . Проверено 2 ноября 2012 г.
- ^ Дэвид Паттерсон (5 декабря 2011 г.). «Ученые-компьютерщики могут иметь все необходимое, чтобы помочь вылечить рак» . Нью-Йорк Таймс . Архивировано из оригинала 30 января 2017 года . Проверено 26 февраля 2017 г.
- ^ «Госсекретарь Чу объявляет о создании нового института, который поможет ученым улучшить исследования массивов данных на суперкомпьютерах Министерства энергетики» . Energy.gov. Архивировано из оригинала 3 апреля 2019 года . Проверено 2 ноября 2012 г.
- ^ Янг, Шеннон (30 мая 2012 г.). «Губернатор Массачусетского технологического института объявляет об инициативе по большим данным» . Бостон.com . Архивировано из оригинала 29 июля 2021 года . Проверено 29 июля 2021 г.
- ^ «Большие данные @ CSAIL» . Bigdata.csail.mit.edu. 22 февраля 2013 года. Архивировано из оригинала 30 марта 2013 года . Проверено 5 марта 2013 г.
- ^ «Государственно-частный форум по большим данным» . Cordis.europa.eu. 1 сентября 2012 года. Архивировано из оригинала 9 марта 2021 года . Проверено 16 марта 2020 г.
- ^ «Институт Алана Тьюринга будет создан для исследования больших данных» . Новости Би-би-си . 19 марта 2014 г. Архивировано из оригинала 18 августа 2021 г. . Проверено 19 марта 2014 г.
- ^ «День вдохновения в Университете Ватерлоо, кампус Стратфорда» . betakit.com/. Архивировано из оригинала 26 февраля 2014 года . Проверено 28 февраля 2014 г.
- ^ Перейти обратно: а б с Рейпс, Ульф-Дитрих; Мацат, Уве (2014). «Майнинг «больших данных» с помощью сервисов больших данных» . Международный журнал интернет-науки . 1 (1): 1–8. Архивировано из оригинала 14 августа 2014 года . Проверено 14 августа 2014 г.
- ^ Прейс Т., Моат Х.С., Стэнли Х.Э., Бишоп С.Р. (2012). «Количественная оценка преимуществ видения вперед» . Научные отчеты . 2 : 350. Бибкод : 2012NatSR...2E.350P . дои : 10.1038/srep00350 . ПМК 3320057 . ПМИД 22482034 .
- ^ Маркс, Пол (5 апреля 2012 г.). «Интернет-поиски будущего связаны с экономическим успехом» . Новый учёный . Архивировано из оригинала 8 апреля 2012 года . Проверено 9 апреля 2012 г.
- ^ Джонстон, Кейси (6 апреля 2012 г.). «Google Trends раскрывает информацию о менталитете более богатых стран» . Арс Техника . Архивировано из оригинала 7 апреля 2012 года . Проверено 9 апреля 2012 г.
- ^ Тобиас Прейс (24 мая 2012 г.). «Дополнительная информация: Индекс ориентации на будущее доступен для скачивания» (PDF) . Архивировано (PDF) из оригинала 17 января 2013 года . Проверено 24 мая 2012 г.
- ^ Филип Болл (26 апреля 2013 г.). «Подсчет поисковых запросов в Google предсказывает движения рынка» . Природа . дои : 10.1038/nature.2013.12879 . S2CID 167357427 . Архивировано из оригинала 27 сентября 2013 года . Проверено 9 августа 2013 г.
- ^ Прейс Т., Моат Х.С., Стэнли Х.Э. (2013). «Количественная оценка торгового поведения на финансовых рынках с помощью Google Trends» . Научные отчеты . 3 : 1684. Бибкод : 2013NatSR...3E1684P . дои : 10.1038/srep01684 . ПМЦ 3635219 . ПМИД 23619126 .
- ^ Ник Билтон (26 апреля 2013 г.). «Поисковые запросы Google могут предсказывать фондовый рынок, результаты исследования» . Нью-Йорк Таймс . Архивировано из оригинала 2 июня 2013 года . Проверено 9 августа 2013 г.
- ^ Кристофер Мэтьюз (26 апреля 2013 г.). «Проблемы с вашим инвестиционным портфелем? Погуглите!» . Время . Архивировано из оригинала 21 августа 2013 года . Проверено 9 августа 2013 г.
- ^ Филип Болл (26 апреля 2013 г.). «Подсчет поисковых запросов в Google предсказывает движения рынка» . Природа . дои : 10.1038/nature.2013.12879 . S2CID 167357427 . Архивировано из оригинала 27 сентября 2013 года . Проверено 9 августа 2013 г.
- ^ Бернхард Уорнер (25 апреля 2013 г.). « Исследователи больших данных обращаются к Google, чтобы победить рынки» . Блумберг Бизнесуик . Архивировано из оригинала 23 июля 2013 года . Проверено 9 августа 2013 г.
- ^ Хэмиш Макрей (28 апреля 2013 г.). «Хэмиш Макрей: Нужна ценная информация о настроениях инвесторов? Погуглите» . Независимый . Лондон. Архивировано из оригинала 25 июля 2018 года . Проверено 9 августа 2013 г.
- ^ Ричард Уотерс (25 апреля 2013 г.). «Поиск Google оказался новым словом в прогнозировании фондового рынка» . Файнэншл Таймс . Архивировано из оригинала 1 июня 2022 года . Проверено 9 августа 2013 г.
- ^ Джейсон Палмер (25 апреля 2013 г.). «Поисковые запросы Google предсказывают движения рынка» . Би-би-си . Архивировано из оригинала 5 июня 2013 года . Проверено 9 августа 2013 г.
- ^ Э. Сейдич (март 2014 г.). «Адаптировать текущие инструменты для использования с большими данными». Природа . 507 (7492): 306.
- ^ Крис Кимбл; Яннис Милолидакис (7 октября 2015 г.). «Большие данные и бизнес-аналитика: развенчание мифов». Глобальное деловое и организационное совершенство . 35 (1): 23–34. arXiv : 1511.03085 . дои : 10.1002/JOE.21642 . ISSN 1932-2054 . Викиданные Q56532925 .
- ^ Крис Андерсон (23 июня 2008 г.). «Конец теории: поток данных делает научный метод устаревшим» . Проводной . Архивировано из оригинала 27 марта 2014 года . Проверено 5 марта 2017 г.
- ^ Грэм М. (9 марта 2012 г.). «Большие данные и конец теории?» . Хранитель . Лондон. Архивировано из оригинала 24 июля 2013 года . Проверено 14 декабря 2016 г.
- ^ Шах, Шветанк; Хорн, Эндрю; Капелла, Хайме (апрель 2012 г.). «Хорошие данные не гарантируют хороших решений» . Гарвардское деловое обозрение . Архивировано из оригинала 11 сентября 2012 года . Проверено 8 сентября 2012 г.
- ^ Перейти обратно: а б Большие данные требуют большого видения для больших перемен. Архивировано 2 декабря 2016 года в Wayback Machine , Гилберт, М. (2014). Лондон: TEDx UCL, x = независимо организованные выступления TED
- ^ Алемани Оливер, Матье; Вайр, Жан-Себастьян (2015). «Большие данные и будущее производства знаний в маркетинговых исследованиях: этика, цифровые следы и абдуктивное мышление». Журнал маркетинговой аналитики . 3 (1): 5–13. дои : 10.1057/jma.2015.1 . S2CID 111360835 .
- ^ Джонатан Раух (1 апреля 2002 г.). «Заглядывание за угол» . Атлантика . Архивировано из оригинала 4 апреля 2017 года . Проверено 5 марта 2017 г.
- ^ Эпштейн, Дж. М., и Экстелл, Р. Л. (1996). Рост искусственных обществ: социальные науки снизу вверх. Книга Брэдфорда.
- ^ «Делорт П., Большие данные в биологических науках, Большие данные, Париж, 2012» (PDF) . Бигдата Париж . Архивировано из оригинала (PDF) 30 июля 2016 года . Проверено 8 октября 2017 г.
- ^ «Геномика следующего поколения: интегративный подход» (PDF) . природа. Июль 2010 г. Архивировано (PDF) из оригинала 13 августа 2017 г. . Проверено 18 октября 2016 г.
- ^ «Большие данные в биологических науках» . Октябрь 2015 г. Архивировано из оригинала 1 июня 2022 г. Проверено 18 октября 2016 г.
- ^ «Большие данные: совершаем ли мы большую ошибку?» . Файнэншл Таймс . 28 марта 2014 г. Архивировано из оригинала 30 июня 2016 г. Проверено 20 октября 2016 г.
- ^ Ом, Пол (23 августа 2012 г.). «Не создавайте базу данных о разрушениях» . Гарвардское деловое обозрение . Архивировано из оригинала 30 августа 2012 года . Проверено 29 августа 2012 г.
- ^ Бонд-Грэм, Дарвин (2018). «Перспектива больших данных». Архивировано 9 ноября 2020 года на Wayback Machine . Перспектива .
- ^ Барокас, Солон; Ниссенбаум, Хелен; Лейн, Джулия; Стодден, Виктория; Бендер, Стефан; Ниссенбаум, Хелен (июнь 2014 г.). Конец больших данных. Анонимность и согласие . Издательство Кембриджского университета. стр. 44–75. дои : 10.1017/cbo9781107590205.004 . ISBN 9781107067356 . S2CID 152939392 .
- ^ Лугмайр, А.; Штоклебен, Б; Шейб, К.; Майлапарампил, М.; Месия, Н.; Ранта, Х.; Лаб, Э. (1 июня 2016 г.). «Комплексный обзор исследований больших данных и их последствий. Что действительно «нового» в больших данных? Это когнитивные большие данные!» . Архивировано из оригинала 1 июня 2022 года . Проверено 27 ноября 2023 г.
- ^ Дана Бойд (29 апреля 2010 г.). «Конфиденциальность и публичность в контексте больших данных» . Конференция WWW 2010 . Архивировано из оригинала 22 октября 2018 года . Проверено 18 апреля 2011 г.
- ^ Катьял, Соня К. (2019). «Искусственный интеллект, реклама и дезинформация» . Ежеквартальный журнал «Реклама и общество» . 20 (4). дои : 10.1353/asr.2019.0026 . ISSN 2475-1790 . S2CID 213397212 . Архивировано из оригинала 28 октября 2020 года . Проверено 18 ноября 2020 г. .
- ^ Джонс, МБ; Шильдхауэр, член парламента; Райхман, О.Дж.; Бауэрс, С. (2006). «Новая биоинформатика: интеграция экологических данных от гена в биосферу» (PDF) . Ежегодный обзор экологии, эволюции и систематики . 37 (1): 519–544. doi : 10.1146/annurev.ecolsys.37.091305.110031 . Архивировано (PDF) из оригинала 8 июля 2019 года . Проверено 19 сентября 2012 г.
- ^ Перейти обратно: а б Бойд, Д.; Кроуфорд, К. (2012). «Критические вопросы для больших данных». Информация, коммуникация и общество . 15 (5): 662–679. дои : 10.1080/1369118X.2012.678878 . hdl : 10983/1320 . S2CID 51843165 .
- ^ Неудачный запуск: от больших данных к большим решениям. Архивировано 6 декабря 2016 года в Wayback Machine , Forte Wares.
- ^ «15 безумных вещей, которые взаимосвязаны» . Архивировано из оригинала 27 июня 2019 года . Проверено 27 июня 2019 г.
- ^ «Случайные структуры и алгоритмы» . Архивировано из оригинала 27 июня 2019 года . Проверено 27 июня 2019 г.
- ^ Кристиан С. Калуде, Джузеппе Лонго, (2016), Поток ложных корреляций в больших данных, Основы науки
- ^ Аня Ламбрехт и Кэтрин Такер (2016) «4 ошибки, которые большинство менеджеров совершают при работе с аналитикой», Harvard Business Review , 12 июля. https://hbr.org/2016/07/the-4-mistakes-most-managers-make -with-analytics. Архивировано 26 января 2022 г. в Wayback Machine.
- ^ Перейти обратно: а б Григорий Пятецкий (12 августа 2014 г.). «Интервью: Майкл Бертольд, основатель KNIME, об исследованиях, креативности, больших данных и конфиденциальности, часть 2» . КДнаггетс. Архивировано из оригинала 13 августа 2014 года . Проверено 13 августа 2014 г.
- ^ Пелт, Мейсон (26 октября 2015 г.). « Большие данные» — слишком часто используемое модное слово, и этот бот в Твиттере это доказывает» . Силиконовый угол . Архивировано из оригинала 30 октября 2015 года . Проверено 4 ноября 2015 г.
- ^ Перейти обратно: а б Харфорд, Тим (28 марта 2014 г.). «Большие данные: совершаем ли мы большую ошибку?» . Файнэншл Таймс . Архивировано из оригинала 7 апреля 2014 года . Проверено 7 апреля 2014 г.
- ^ Иоаннидис Дж. П. (август 2005 г.). «Почему большинство опубликованных результатов исследований являются ложными» . ПЛОС Медицина . 2 (8): е124. дои : 10.1371/journal.pmed.0020124 . ПМЦ 1182327 . ПМИД 16060722 .
- ^ Лор, Стив; Певица Наташа (10 ноября 2016 г.). «Как данные не помогли нам назначить выборы» . Нью-Йорк Таймс . ISSN 0362-4331 . Архивировано из оригинала 25 ноября 2016 года . Проверено 27 ноября 2016 г. .
- ^ «Как полицейская деятельность, основанная на данных, угрожает свободе человека» . Экономист . 4 июня 2018 г. ISSN 0013-0613 . Архивировано из оригинала 27 октября 2019 года . Проверено 27 октября 2019 г.
- ^ Брейн, Сара (29 августа 2017 г.). «Наблюдение за большими данными: случай полиции» . Американский социологический обзор . 82 (5): 977–1008. дои : 10.1177/0003122417725865 . ПМЦ 10846878 . ПМИД 38322733 . S2CID 3609838 .
Библиография
[ редактировать ]- Хилберт, М. (2016), «Большие данные для развития: обзор обещаний и проблем», Обзор политики развития , 34 (1): 135–74, doi : 10.1111/dpr.12142 ; свободный доступ , Архивировано 21 апреля 2021 г. на Wayback Machine.
- Снейдерс, К.; Мацат, У.; Рейпс, У.-Д. (2012). « Большие данные: большие пробелы в знаниях в области Интернета» . Международный журнал интернет-науки . 7 : 1–5. Архивировано из оригинала 23 ноября 2019 года . Проверено 13 апреля 2013 г.
- Янасэ, Дж; Триантафиллу, Э (2019). «Систематический обзор компьютерной диагностики в медицине: прошлые и настоящие разработки». Экспертные системы с приложениями . 138 : 112821. doi : 10.1016/j.eswa.2019.112821 . S2CID 199019309 .
Дальнейшее чтение
[ редактировать ]- Питер Киннэрд; Инбал Талгам-Коэн, ред. (2012). «Большие данные» . XRDS: Crossroads, Журнал ACM для студентов . Том. 19, нет. 1. Ассоциация вычислительной техники . ISSN 1528-4980 . OCLC 779657714 .
- Юре Лесковец ; Ананд Раджараман ; Джеффри Д. Уллман (2014). Интеллектуальный анализ огромных наборов данных . Издательство Кембриджского университета. ISBN 978-1-10707723-2 . OCLC 888463433 .
- Виктор Майер-Шенбергер ; Кеннет Кукиер (2013). Большие данные: революция, которая изменит то, как мы живем, работаем и думаем . Хоутон Миффлин Харкорт. ISBN 978-1-29990302-9 . OCLC 828620988 .
- Пресс, Гил (9 мая 2013 г.). «Очень краткая история больших данных» . Forbes.com . Джерси-Сити, Нью-Джерси . Проверено 17 сентября 2016 г.
- Стивенс-Давидовиц, Сет (2017). Все лгут: большие данные, новые данные и что Интернет может рассказать нам о том, кто мы на самом деле . Книги Дей-Стрит. ISBN 978-0-06239085-1 .
- «Большие данные: революция в управлении» . Гарвардское деловое обозрение . Октябрь 2012.
- О'Нил, Кэти (2017). Оружие математического разрушения: как большие данные увеличивают неравенство и угрожают демократии . Бродвейские книги. ISBN 978-0-55341883-5 .
Внешние ссылки
[ редактировать ] СМИ, связанные с большими данными, на Викискладе?
СМИ, связанные с большими данными, на Викискладе?  Словарное определение больших данных в Викисловаре
Словарное определение больших данных в Викисловаре