База данных
В вычислительной технике база данных — это организованный набор данных или тип хранилища данных , основанный на использовании системы управления базами данных ( СУБД ), программного обеспечения , которое взаимодействует с конечными пользователями , приложениями и самой базой данных для сбора и анализа данных. . СУБД дополнительно включает в себя основные средства, предназначенные для администрирования базы данных. Совокупность базы данных, СУБД и связанных с ней приложений можно назвать системой баз данных . Часто термин «база данных» также широко используется для обозначения любой СУБД, системы баз данных или приложения, связанного с базой данных.
Небольшие базы данных могут храниться в файловой системе , тогда как большие базы данных размещаются в компьютерных кластерах или облачных хранилищах . Проектирование баз данных охватывает формальные методы и практические соображения, включая моделирование данных , эффективное представление и хранение данных, языки запросов , безопасность и конфиденциальность конфиденциальных данных, а также распределенных вычислений вопросы , включая поддержку одновременного доступа и отказоустойчивости .
Ученые-компьютерщики могут классифицировать системы управления базами данных в соответствии с моделями баз данных , которые они поддерживают. Реляционные базы данных стали доминирующими в 1980-х годах. Они моделируют данные в виде строк и столбцов в ряде таблиц , и подавляющее большинство из них используют SQL для записи и запроса данных. В 2000-х годах стали популярны нереляционные базы данных, называемые NoSQL , поскольку они используют разные языки запросов .
Терминология и обзор
Формально «база данных» относится к набору связанных данных, доступ к которым осуществляется с помощью «системы управления базами данных» (СУБД), которая представляет собой интегрированный набор компьютерного программного обеспечения , позволяющий пользователям взаимодействовать с одной или несколькими базами данных и обеспечивающий доступ к все данные, содержащиеся в базе данных (хотя могут существовать ограничения, ограничивающие доступ к определенным данным). СУБД предоставляет различные функции, которые позволяют вводить, хранить и извлекать большие объемы информации, а также предоставляет способы управления организацией этой информации.
Из-за тесной связи между ними термин «база данных» часто используется небрежно для обозначения как базы данных, так и СУБД, используемой для управления ею.
За пределами мира профессиональных информационных технологий термин «база данных» часто используется для обозначения любого набора связанных данных (например, электронной таблицы или картотеки), поскольку требования к размеру и использованию обычно требуют использования системы управления базой данных. [1]
Существующие СУБД предоставляют различные функции, позволяющие управлять базой данных и ее данными, которые можно разделить на четыре основные функциональные группы:
- Определение данных . Создание, изменение и удаление определений, подробно описывающих, как должны быть организованы данные.
- Обновление — вставка, изменение и удаление самих данных. [2]
- Извлечение — выбор данных в соответствии с заданными критериями (например, запрос, позиция в иерархии или позиция по отношению к другим данным) и предоставление этих данных либо непосредственно пользователю, либо предоставление их для дальнейшей обработки самой базой данных. или другими приложениями. Полученные данные могут быть доступны в более или менее прямой форме без изменений, поскольку они хранятся в базе данных, или в новой форме, полученной путем их изменения или объединения с существующими данными из базы данных. [3]
- Администрирование — регистрация и мониторинг пользователей, обеспечение безопасности данных, мониторинг производительности, поддержание целостности данных, управление параллельным доступом и восстановление информации, которая была повреждена каким-либо событием, например неожиданным сбоем системы. [4]
И база данных, и ее СУБД соответствуют принципам конкретной модели базы данных . [5] «Система базы данных» в совокупности относится к модели базы данных, системе управления базой данных и базе данных. [6]
Физически серверы баз данных представляют собой выделенные компьютеры, на которых хранятся реальные базы данных и на которых работают только СУБД и соответствующее программное обеспечение. Серверы баз данных обычно представляют собой многопроцессорные компьютеры с большим объемом памяти и RAID, дисковыми массивами используемыми для стабильного хранения. Аппаратные ускорители баз данных, подключаемые к одному или нескольким серверам по высокоскоростному каналу, также используются в средах обработки транзакций большого объема . СУБД лежат в основе большинства приложений баз данных . СУБД могут быть построены на основе специального многозадачного ядра со встроенной поддержкой сети , но современные СУБД обычно полагаются на стандартную операционную систему для обеспечения этих функций. [ нужна ссылка ]
Поскольку СУБД составляют значительный рынок , поставщики компьютеров и систем хранения данных часто учитывают требования СУБД в своих собственных планах развития. [7]
Базы данных и СУБД можно разделить на категории в соответствии с моделями баз данных, которые они поддерживают (например, реляционная или XML ), типом компьютера, на котором они работают (от кластера серверов до мобильного телефона ), языком запросов ( s), используемые для доступа к базе данных (например, SQL или XQuery ), и их внутреннюю разработку, которая влияет на производительность, масштабируемость , отказоустойчивость и безопасность.
История
Размеры, возможности и производительность баз данных и соответствующих им СУБД выросли на порядки. Такое увеличение производительности стало возможным благодаря технологическому прогрессу в области процессоров , компьютерной памяти , компьютерной памяти и компьютерных сетей . Концепция базы данных стала возможной благодаря появлению носителей данных с прямым доступом, таких как магнитные диски , которые стали широко доступны в середине 1960-х годов; более ранние системы полагались на последовательное хранение данных на магнитной ленте . Последующее развитие технологии баз данных можно разделить на три эпохи в зависимости от модели или структуры данных: навигационную , [8] SQL/ реляционный и постреляционный.
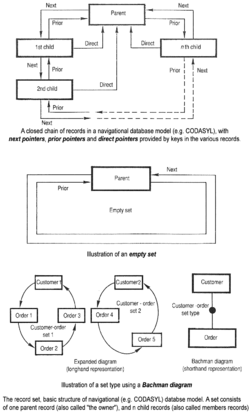
Двумя основными ранними моделями навигационных данных были иерархическая модель и модель CODASYL ( сетевая модель ). Они характеризовались использованием указателей (часто адресов физических дисков) для отслеживания связей между одной записью и другой.
, Реляционная модель впервые предложенная в 1970 году Эдгаром Ф. Коддом , отошла от этой традиции, настаивая на том, что приложения должны искать данные по содержимому, а не путем перехода по ссылкам. Реляционная модель использует наборы таблиц в стиле бухгалтерской книги, каждая из которых используется для разных типов объектов . Лишь в середине 1980-х годов вычислительное оборудование стало достаточно мощным, чтобы обеспечить широкое развертывание реляционных систем (СУБД плюс приложения). Однако к началу 1990-х годов реляционные системы доминировали во всех приложениях крупномасштабной обработки данных , а по состоянию на 2018 год [update] они остаются доминирующими: IBM Db2 , Oracle , MySQL и Microsoft SQL Server являются наиболее популярными СУБД . [9] Доминирующий язык баз данных, стандартизированный SQL для реляционной модели, повлиял на языки баз данных для других моделей данных. [ нужна ссылка ]
Объектные базы данных были разработаны в 1980-х годах, чтобы преодолеть неудобство объектно-реляционного несоответствия импедансов , что привело к появлению термина «постреляционный», а также к развитию гибридных объектно-реляционных баз данных .
Следующее поколение постреляционных баз данных в конце 2000-х годов стало известно как базы данных NoSQL , представив быстрые хранилища «ключ-значение» и документо-ориентированные базы данных . Конкурирующее «следующее поколение», известное как базы данных NewSQL, предприняло попытку новых реализаций, которые сохранили реляционную модель/модель SQL, стремясь при этом соответствовать высокой производительности NoSQL по сравнению с коммерчески доступными реляционными СУБД.
1960-е годы, навигационная СУБД.
Введение термина « база данных» совпало с появлением с середины 1960-х годов устройств хранения данных с прямым доступом (дисков и барабанов). Этот термин представлял собой контраст с ленточными системами прошлого, позволяя совместное интерактивное использование вместо ежедневной пакетной обработки . Оксфордский словарь английского языка цитирует отчет Калифорнийской корпорации системного развития за 1962 год как первый, в котором термин «база данных» использовался в конкретном техническом смысле. [10]
По мере роста скорости и возможностей компьютеров появился ряд систем баз данных общего назначения; к середине 1960-х годов ряд таких систем поступил в коммерческое использование. Интерес к стандарту начал расти, и Чарльз Бахман , автор одного из таких продуктов, Integrated Data Store (IDS), основал Группу задач по базам данных в рамках CODASYL , группу, ответственную за создание и стандартизацию COBOL . В 1971 году Database Task Group представила свой стандарт, который в целом стал известен как подход CODASYL , и вскоре на рынок вышел ряд коммерческих продуктов, основанных на этом подходе.
Подход CODASYL предоставил приложениям возможность перемещаться по связанному набору данных, который был сформирован в большую сеть. Приложения могли находить записи одним из трех способов:
- Использование первичного ключа (так называемого ключа CALC, обычно реализуемого путем хеширования )
- Перемещение отношений (называемых наборами ) от одной записи к другой.
- Сканирование всех записей в последовательном порядке
Более поздние системы добавили B-деревья для обеспечения альтернативных путей доступа. Многие базы данных CODASYL также добавили декларативный язык запросов для конечных пользователей (в отличие от навигационного API ). Однако базы данных CODASYL были сложными и требовали значительного обучения и усилий для создания полезных приложений.
В 1966 году у IBM также была собственная СУБД, известная как Система управления информацией (IMS). IMS была разработкой программного обеспечения, написанного для программы Apollo на System/360 . IMS в целом была похожа по концепции на CODASYL, но использовала строгую иерархию для своей модели навигации по данным вместо сетевой модели CODASYL. Обе концепции позже стали известны как навигационные базы данных из-за способа доступа к данным: этот термин был популяризирован благодаря Бахмана на премии Тьюринга презентации в 1973 году «Программист как навигатор» . IMS классифицируется IBM как иерархическая база данных . IDMS и Cincom Systems — ВСЕГО [ сломанный якорь ] базы данных классифицируются как сетевые базы данных. IMS продолжает использоваться с 2014 года. [update]. [11]
1970-е годы, реляционная СУБД
Эдгар Ф. Кодд работал в IBM в Сан-Хосе, Калифорния , в одном из филиалов компании, которые в основном занимались разработкой систем с жесткими дисками . Он был недоволен навигационной моделью CODASYL, особенно отсутствием функции «поиска». В 1970 году он написал ряд статей, в которых изложил новый подход к построению баз данных, кульминацией которого в конечном итоге стала новаторская «Реляционная модель данных для больших общих банков данных» . [12]
В этой статье он описал новую систему хранения и работы с большими базами данных. Вместо того, чтобы записи хранились в каком-то связанном списке записей произвольной формы, как в CODASYL, идея Кодда заключалась в том, чтобы организовать данные в виде нескольких « таблиц », каждая из которых использовалась для различного типа объектов. Каждая таблица будет содержать фиксированное количество столбцов, содержащих атрибуты сущности. Один или несколько столбцов каждой таблицы были назначены первичным ключом , с помощью которого можно было однозначно идентифицировать строки таблицы; перекрестные ссылки между таблицами всегда использовали эти первичные ключи, а не адреса дисков, и запросы объединяли таблицы на основе этих ключевых связей, используя набор операций, основанных на математической системе реляционного исчисления (от которой модель получила свое название). Разделение данных на набор нормализованных таблиц (или отношений ) было направлено на то, чтобы каждый «факт» сохранялся только один раз, что упрощало операции обновления. Виртуальные таблицы, называемые представлениями, могут представлять данные по-разному для разных пользователей, но представления не могут обновляться напрямую.
Для определения модели Кодд использовал математические термины: отношения, кортежи и домены, а не таблицы, строки и столбцы. Терминология, которая теперь знакома, пришла из ранних реализаций. Позже Кодд раскритиковал тенденцию практических реализаций отходить от математических основ, на которых была основана модель.

Использование первичных ключей (ориентированных на пользователя идентификаторов) для представления межтабличных связей, а не адресов дисков, имело две основные причины. С инженерной точки зрения это позволило перемещать и изменять размеры таблиц без дорогостоящей реорганизации базы данных. Но Кодда больше интересовала разница в семантике: использование явных идентификаторов упрощало определение операций обновления с чистыми математическими определениями, а также позволяло определять операции запроса в терминах устоявшейся дисциплины исчисления предикатов первого порядка ; поскольку эти операции имеют чистые математические свойства, становится возможным переписывать запросы доказуемо правильными способами, что является основой оптимизации запросов. По сравнению с иерархической или сетевой моделями потери выразительности не происходит, хотя связи между таблицами уже не столь явны.
В иерархической и сетевой моделях допускалось, чтобы записи имели сложную внутреннюю структуру. Например, история заработной платы сотрудника может быть представлена как «повторяющаяся группа» в записи сотрудника. В реляционной модели процесс нормализации привел к замене таких внутренних структур данными, хранящимися в нескольких таблицах, связанных только логическими ключами.
Например, система баз данных обычно используется для отслеживания информации о пользователях, их имени, данных для входа в систему, различных адресов и номеров телефонов. При навигационном подходе все эти данные будут помещены в одну запись переменной длины. В реляционном подходе данные будут нормализованы в таблицу пользователей, таблицу адресов и таблицу номеров телефонов (например). Записи будут создаваться в этих дополнительных таблицах только в том случае, если адрес или номера телефонов действительно будут указаны.
Помимо идентификации строк/записей с использованием логических идентификаторов, а не адресов дисков, Кодд изменил способ, которым приложения собирают данные из нескольких записей. Вместо того, чтобы требовать от приложений сбора данных по одной записи за раз путем навигации по ссылкам, они будут использовать декларативный язык запросов, описывающий, какие данные требуются, а не путь доступа, по которому их следует найти. Поиск эффективного пути доступа к данным стал обязанностью системы управления базами данных, а не программиста приложения. Этот процесс, называемый оптимизацией запросов, зависел от того, что запросы выражались с точки зрения математической логики.
Статью Кодда подхватили два человека в Беркли, Юджин Вонг и Майкл Стоунбрейкер . Они начали проект, известный как INGRES, используя финансирование, которое уже было выделено на проект географической базы данных, и студентов-программистов для создания кода. Начиная с 1973 года, INGRES представила свои первые тестовые продукты, которые в целом были готовы к широкому использованию в 1979 году. INGRES был похож на System R во многих отношениях, включая использование «языка» для доступа к данным , известного как QUEL . Со временем INGRES перешла на новый стандарт SQL.
Сама IBM провела одну тестовую реализацию реляционной модели PRTV и производственную версию Business System 12 , производство которых сейчас прекращено. Honeywell написала MRDS для Multics , и теперь есть две новые реализации: Alphora Dataphor и Rel. Большинство других реализаций СУБД, обычно называемых реляционными, на самом деле являются СУБД SQL.
В 1970 году Мичиганский университет начал разработку системы управления информацией MICRO. [13] на основе Д. Л. Чайлдса . теоретико-множественной модели данных [14] [15] [16] MICRO использовался для управления очень большими наборами данных Министерством труда США , Агентством по охране окружающей среды США и исследователями из Университета Альберты , Мичиганского университета и Университета штата Уэйн . Он работал на мейнфреймах IBM с использованием Michigan Terminal System . [17] Система оставалась в производстве до 1998 года.
Комплексный подход
В 1970-х и 1980-х годах предпринимались попытки создать системы баз данных с интегрированным аппаратным и программным обеспечением. Основная философия заключалась в том, что такая интеграция обеспечит более высокую производительность при меньших затратах. Примерами были IBM System/38 , раннее предложение Teradata , и Britton Lee, Inc. машина базы данных
Другим подходом к аппаратной поддержке управления базами данных был ICL компании ускоритель CAFS — аппаратный контроллер диска с программируемыми возможностями поиска. В долгосрочной перспективе эти усилия в целом оказались безуспешными, поскольку специализированные машины баз данных не могли идти в ногу с быстрым развитием и прогрессом компьютеров общего назначения. Таким образом, большинство систем баз данных в настоящее время представляют собой программные системы, работающие на аппаратном обеспечении общего назначения и использующие компьютерное хранилище данных общего назначения. Однако эта идея до сих пор реализуется в некоторых приложениях некоторыми компаниями, такими как Netezza и Oracle ( Exadata ).
Конец 1970-х, СУБД SQL.
IBM начала работу над прототипом системы, основанной на концепциях Кодда, под названием System R в начале 1970-х годов. Первая версия была готова в 1974/5 году, а затем началась работа над многотабличными системами, в которых данные можно было бы разделить, чтобы все данные записи (некоторые из которых были необязательными) не приходилось хранить в один большой «кусок». Последующие многопользовательские версии были протестированы клиентами в 1978 и 1979 годах, и к этому времени был разработан стандартизированный язык запросов — SQL. [ нужна ссылка ] – было добавлено. Идеи Кодда зарекомендовали себя как работоспособные и превосходящие CODASYL, что подтолкнуло IBM к разработке настоящей производственной версии System R, известной как SQL/DS , а затем и базы данных 2 ( IBM Db2 ).
Ларри Эллисона База данных Oracle (или, проще говоря, Oracle ) началась с другой цепочки, основанной на документах IBM по System R. Хотя внедрение Oracle V1 было завершено в 1978 году, только в Oracle Version 2 Эллисон опередил IBM на рынке 1979. [18]
Стоунбрейкер применил уроки INGRES для разработки новой базы данных Postgres, которая теперь известна как PostgreSQL . PostgreSQL часто используется для глобальных критически важных приложений (реестры доменных имен .org и .info используют его в качестве основного хранилища данных , как и многие крупные компании и финансовые учреждения).
В Швеции также прочитали статью Кодда и Mimer SQL разработали в середине 1970-х годов в Уппсальском университете . В 1984 году этот проект был выделен в самостоятельное предприятие.
Другая модель данных, модель «сущность-связь» , появилась в 1976 году и завоевала популярность при проектировании баз данных , поскольку в ней подчеркивалось более знакомое описание, чем в более ранней реляционной модели. Позже конструкции «сущность-связь» были модернизированы в качестве конструкции моделирования данных для реляционной модели, и разница между ними стала несущественной. [ нужна ссылка ]
1980-е, на рабочем столе
1980-е годы ознаменовали эпоху настольных компьютеров . Новые компьютеры предоставили своим пользователям электронные таблицы, такие как Lotus 1-2-3 , и программное обеспечение для баз данных, такое как dBASE . Продукт dBASE был легким и простым для понимания любым пользователем компьютера «из коробки». К. Уэйн Рэтлифф , создатель dBASE, заявил: «DBASE отличалась от таких программ, как BASIC, C, FORTRAN и COBOL, тем, что большая часть грязной работы уже была проделана. Манипулирование данными выполняется с помощью dBASE, а не с помощью пользователя, чтобы пользователь мог сосредоточиться на том, что он делает, вместо того, чтобы возиться с грязными деталями открытия, чтения и закрытия файлов, а также управления распределением пространства». [19] dBASE была одной из самых продаваемых программных продуктов в 1980-х и начале 1990-х годов.
1990-е, объектно-ориентированный
В 1990-е годы, наряду с ростом объектно-ориентированного программирования , наблюдался рост способов обработки данных в различных базах данных. Программисты и дизайнеры начали относиться к данным в своих базах данных как к объектам . То есть, если данные человека находились в базе данных, атрибуты этого человека, такие как адрес, номер телефона и возраст, теперь считались принадлежащими этому человеку, а не посторонними данными. Это позволяет связывать отношения между данными с объектами и их атрибутами , а не с отдельными полями. [20] Термин « объектно-реляционное несоответствие импеданса » описывал неудобства перевода между запрограммированными объектами и таблицами базы данных. Объектные и объектно-реляционные базы данных пытаются решить эту проблему, предоставляя объектно-ориентированный язык (иногда в виде расширения SQL), который программисты могут использовать в качестве альтернативы чисто реляционному SQL. Что касается программирования, библиотеки, известные как объектно-реляционные отображения (ORM), пытаются решить ту же проблему.
2000-е, NoSQL и NewSQL
Базы данных XML — это тип структурированной документо-ориентированной базы данных, которая позволяет выполнять запросы на основе атрибутов документа XML . Базы данных XML в основном используются в приложениях, где данные удобно рассматривать как набор документов со структурой, которая может варьироваться от очень гибкой до очень жесткой: примеры включают научные статьи, патенты, налоговые декларации и кадровые записи.
Базы данных NoSQL часто работают очень быстро, не требуют фиксированных схем таблиц, избегают операций соединения за счет хранения денормализованных данных и предназначены для горизонтального масштабирования .
В последние годы существует большой спрос на массово распределенные базы данных с высокой устойчивостью к разделению, но согласно теореме CAP невозможно, чтобы распределенная система одновременно обеспечивала гарантии согласованности , доступности и устойчивости к разделению. Распределенная система может одновременно удовлетворять любым двум из этих гарантий, но не всем трем. По этой причине многие базы данных NoSQL используют так называемую итоговую согласованность , чтобы обеспечить гарантии доступности и устойчивости разделов при пониженном уровне согласованности данных.
NewSQL — это класс современных реляционных баз данных, целью которого является обеспечение той же масштабируемой производительности, что и системы NoSQL, для рабочих нагрузок онлайн-обработки транзакций (чтение-запись), при этом используя SQL и сохраняя гарантии ACID , присущие традиционной системе баз данных.
Варианты использования
Базы данных используются для поддержки внутренних операций организаций и для поддержки онлайн-взаимодействия с клиентами и поставщиками (см. Корпоративное программное обеспечение ).
Базы данных используются для хранения административной информации и более специализированных данных, таких как инженерные данные или экономические модели. Примеры включают компьютеризированные библиотечные системы, системы бронирования авиабилетов , компьютеризированные системы инвентаризации запчастей и многие системы управления контентом , которые хранят веб-сайты в виде коллекций веб-страниц в базе данных.
Классификация
Один из способов классификации баз данных предполагает тип их содержимого, например: библиографические , документально-текстовые, статистические или мультимедийные объекты. Другой способ — по области применения, например: бухгалтерский учет, музыкальные композиции, фильмы, банковское дело, производство или страхование. Третий способ — это использование некоторых технических аспектов, таких как структура базы данных или тип интерфейса. В этом разделе перечислено несколько прилагательных, используемых для характеристики различных типов баз данных.
- База данных в памяти — это база данных, которая в основном находится в основной памяти , но обычно имеет резервную копию в энергонезависимом хранилище данных компьютера. Базы данных в основной памяти работают быстрее, чем дисковые базы данных, поэтому часто используются там, где время отклика имеет решающее значение, например, в телекоммуникационном сетевом оборудовании.
- Активная база данных включает в себя архитектуру, управляемую событиями, которая может реагировать на условия как внутри, так и за пределами базы данных. Возможные варианты использования включают мониторинг безопасности, оповещение, сбор статистики и авторизацию. Многие базы данных предоставляют активные функции базы данных в виде триггеров базы данных .
- Облачная база данных опирается на облачные технологии . И база данных, и большая часть ее СУБД находятся удаленно, «в облаке», а ее приложения разрабатываются программистами, а затем обслуживаются и используются конечными пользователями через веб-браузер и открытые API .
- Хранилища данных [ нужна ссылка ] архивируйте данные из операционных баз данных и часто из внешних источников, таких как фирмы, занимающиеся исследованием рынка. Хранилище становится центральным источником данных для использования менеджерами и другими конечными пользователями, у которых может не быть доступа к оперативным данным. Например, данные о продажах могут быть агрегированы в еженедельные итоги и преобразованы из внутренних кодов продуктов для использования UPC , чтобы их можно было сравнить с данными ACNielsen . Некоторые базовые и важные компоненты хранилища данных включают извлечение, анализ и анализ данных, преобразование, загрузку и управление данными, чтобы сделать их доступными для дальнейшего использования.
- сочетает Дедуктивная база данных в себе логическое программирование с реляционной базой данных.
- — Распределенная база данных это база данных, в которой и данные, и СУБД охватывают несколько компьютеров.
- предназначена Документоориентированная база данных для хранения, извлечения и управления документоориентированной или полуструктурированной информацией. Документоориентированные базы данных — одна из основных категорий баз данных NoSQL.
- Встроенная система баз данных — это СУБД, которая тесно интегрирована с прикладным программным обеспечением, требующим доступа к хранимым данным таким образом, что СУБД скрыта от конечных пользователей приложения и практически не требует постоянного обслуживания. [21]
- Базы данных конечных пользователей состоят из данных, разработанных отдельными конечными пользователями. Примерами являются коллекции документов, электронных таблиц, презентаций, мультимедиа и других файлов. Несколько продуктов [ который? ] существуют для поддержки таких баз данных.
- Система объединенных баз данных состоит из нескольких отдельных баз данных, каждая из которых имеет свою собственную СУБД. Она обрабатывается как единая база данных объединенной системой управления базами данных (FDBMS), которая прозрачно интегрирует несколько автономных СУБД, возможно, разных типов (в этом случае это также будет гетерогенная система баз данных ), и предоставляет им интегрированное концептуальное представление. .
- Иногда термин «множественная база данных» используется как синоним объединенной базы данных, хотя он может относиться к менее интегрированной (например, без FDBMS и управляемой интегрированной схемы) группе баз данных, которые взаимодействуют в одном приложении. В этом случае промежуточное программное обеспечение для распространения обычно используется , которое обычно включает протокол атомарной фиксации (ACP), например, протокол двухфазной фиксации , чтобы разрешить распределенные (глобальные) транзакции между участвующими базами данных.
- База данных графов — это разновидность базы данных NoSQL, которая использует графовые структуры с узлами, ребрами и свойствами для представления и хранения информации. Общие базы данных графов, которые могут хранить любой граф, отличаются от специализированных баз данных графов, таких как тройные хранилища и сетевые базы данных .
- СУБД массивов — это разновидность СУБД NoSQL, которая позволяет моделировать, хранить и извлекать (обычно большие) многомерные массивы, такие как спутниковые изображения и результаты моделирования климата.
- В базе данных гипертекста или гипермедиа любое слово или фрагмент текста, представляющий объект, например другой фрагмент текста, статью, изображение или фильм, может быть гиперссылкой связан с этим объектом . Гипертекстовые базы данных особенно полезны для организации больших объемов разрозненной информации. Например, они полезны для организации онлайн-энциклопедий , где пользователи могут удобно перемещаться по тексту. Таким образом, Всемирная паутина представляет собой большую распределенную базу данных гипертекста.
- База знаний (сокращенно KB , kb или Δ [22] [23] ) — это особый вид базы данных для управления знаниями , предоставляющий средства для компьютеризированного сбора, организации поиска знаний и . Также коллекция данных, представляющих проблемы с их решениями и связанный с ними опыт.
- может Мобильная база данных храниться в памяти или синхронизироваться с мобильным вычислительным устройством.
- Операционные базы данных хранят подробные данные о деятельности организации. Обычно они обрабатывают относительно большие объемы обновлений с помощью транзакций . Примеры включают базы данных клиентов , в которых записана контактная, кредитная и демографическая информация о клиентах компании, базы данных персонала, в которых хранится такая информация, как зарплата, льготы, данные о навыках сотрудников, системы планирования ресурсов предприятия , которые записывают подробную информацию о компонентах продукта, запасах деталей и финансовых показателях. базы данных, которые отслеживают деньги организации, бухгалтерский учет и финансовые операции.
- Параллельная база данных стремится повысить производительность за счет распараллеливания таких задач, как загрузка данных, построение индексов и оценка запросов.
- Основными параллельными архитектурами СУБД, обусловленными базовой аппаратной архитектурой, являются:
- Архитектура общей памяти , при которой несколько процессоров совместно используют пространство основной памяти, а также другие хранилища данных.
- Архитектура общего диска , в которой каждый процессорный блок (обычно состоящий из нескольких процессоров) имеет собственную основную память, но все блоки совместно используют другое хранилище.
- Архитектура без разделяемого доступа , в которой каждый процессор имеет собственную основную память и другое хранилище.
- Основными параллельными архитектурами СУБД, обусловленными базовой аппаратной архитектурой, являются:
- Вероятностные базы данных используют нечеткую логику для получения выводов на основе неточных данных.
- Базы данных реального времени обрабатывают транзакции достаточно быстро, чтобы результат мог быть возвращен и немедленно обработан.
- может Пространственная база данных хранить данные с многомерными функциями. Запросы к таким данным включают запросы на основе местоположения, например «Где находится ближайший отель в моем районе?».
- Темпоральная база данных имеет встроенные временные аспекты, например темпоральную модель данных и темпоральную версию SQL . Более конкретно, временные аспекты обычно включают время действия и время транзакции.
- Терминологически ориентированная база данных основывается на объектно-ориентированной базе данных , часто адаптированной для конкретной области.
- База данных неструктурированных данных предназначена для управляемого и защищенного хранения разнообразных объектов, которые естественным и удобным образом не помещаются в обычные базы данных. Оно может включать сообщения электронной почты, документы, журналы, мультимедийные объекты и т. д. Название может ввести в заблуждение, поскольку некоторые объекты могут быть высокоструктурированными. Однако вся возможная коллекция объектов не умещается в заранее определенную структурированную структуру. Большинство существующих СУБД в настоящее время поддерживают неструктурированные данные различными способами, и появляются новые специализированные СУБД.
Система управления базой данных
Коннолли и Бегг определяют систему управления базами данных (СУБД) как «программную систему, которая позволяет пользователям определять, создавать, поддерживать и контролировать доступ к базе данных». [24] Примеры СУБД включают MySQL , MariaDB , PostgreSQL , Microsoft SQL Server , Oracle Database и Microsoft Access .
Аббревиатура СУБД иногда расширяется для обозначения базовой модели базы данных : РСУБД для реляционной модели , ООСУБД для объектной (ориентированной) и ОРСУБД для объектно-реляционной модели . Другие расширения могут указывать на некоторые другие характеристики, например DDBMS для распределенных систем управления базами данных.
Функциональность, предоставляемая СУБД, может сильно различаться. Основная функциональность — хранение, поиск и обновление данных. Кодд предложил следующие функции и сервисы, которые должна обеспечивать полноценная СУБД общего назначения: [25]
- Хранение, поиск и обновление данных
- Доступный пользователю каталог или словарь данных, описывающий метаданные.
- Поддержка транзакций и параллелизма
- Средства восстановления базы данных в случае ее повреждения.
- Поддержка авторизации доступа и обновления данных
- Доступ к поддержке из удаленных мест
- Обеспечение соблюдения ограничений для обеспечения соответствия данных в базе данных определенным правилам.
Также обычно ожидается, что СУБД будет предоставлять набор утилит для таких целей, которые могут быть необходимы для эффективного администрирования базы данных, включая утилиты импорта, экспорта, мониторинга, дефрагментации и анализа. [26] Основная часть СУБД, взаимодействующая между базой данных и интерфейсом приложения, иногда называемая ядром базы данных .
Часто СУБД имеют параметры конфигурации, которые можно настраивать статически и динамически, например максимальный объем основной памяти на сервере, который может использовать база данных. Тенденция заключается в том, чтобы свести к минимуму объем ручной настройки, а для таких случаев, как встроенные базы данных, необходимость полного отсутствия администрирования имеет первостепенное значение.
Крупные корпоративные СУБД имели тенденцию к увеличению размера и функциональности, и на протяжении всего их существования на разработку уходили тысячи человеческих лет. [а]
Ранние многопользовательские СУБД обычно позволяли приложению находиться только на одном компьютере с доступом через терминалы или программное обеспечение эмуляции терминала. Архитектура клиент-сервер представляла собой разработку, в которой приложение размещалось на рабочем столе клиента, а база данных — на сервере, что позволяло распределять обработку. Это превратилось в многоуровневую архитектуру, включающую серверы приложений и веб-серверы с интерфейсом конечного пользователя через веб-браузер , а база данных напрямую подключена только к соседнему уровню. [28]
СУБД общего назначения будет предоставлять общедоступные интерфейсы прикладного программирования (API) и, опционально, процессор для языков баз данных , таких как SQL , что позволит писать приложения для взаимодействия с базой данных и манипулирования ею. СУБД специального назначения может использовать частный API, быть специально настроена и связана с одним приложением. Например, система электронной почты выполняет многие функции СУБД общего назначения, такие как вставка сообщений, удаление сообщений, обработка вложений, поиск в черном списке, связывание сообщений с адресом электронной почты и т. д., однако эти функции ограничены тем, что требуется для обработки. электронная почта.
Приложение
Внешнее взаимодействие с базой данных будет осуществляться через прикладную программу, взаимодействующую с СУБД. [29] Это может быть как инструмент базы данных , который позволяет пользователям выполнять SQL-запросы в текстовом или графическом виде, так и веб-сайт, который использует базу данных для хранения и поиска информации.
Интерфейс прикладной программы
Программист интерфейс прикладной будет кодировать взаимодействие с базой данных (иногда называемой источником данных ) через программы (API) или через язык базы данных . Конкретный выбранный API или язык должен поддерживаться СУБД, возможно, косвенно через препроцессор или мостовой API. Некоторые API стремятся быть независимыми от базы данных, ODBC широко известным примером является . Другие распространенные API включают JDBC и ADO.NET .
Языки базы данных
Языки баз данных — это языки специального назначения, которые позволяют выполнять одну или несколько из следующих задач, иногда называемых подъязыками :
- Язык управления данными (DCL) – контролирует доступ к данным;
- Язык определения данных (DDL) – определяет типы данных, такие как создание, изменение или удаление таблиц, а также связи между ними;
- Язык манипулирования данными (DML) — выполняет такие задачи, как вставка, обновление или удаление экземпляров данных;
- Язык запросов данных (DQL) – позволяет искать информацию и вычислять полученную информацию.
Языки баз данных специфичны для конкретной модели данных. Яркие примеры включают:
- SQL сочетает в себе функции определения данных, манипулирования ими и выполнения запросов на одном языке. Это был один из первых коммерческих языков для реляционной модели, хотя он в некоторых отношениях отличается от реляционной модели, описанной Коддом (например, строки и столбцы таблицы можно упорядочить). SQL стал стандартом Американского национального института стандартов (ANSI) в 1986 году и Международной организации по стандартизации (ISO) в 1987 году. С тех пор стандарты регулярно совершенствуются и поддерживаются (с различной степенью соответствия) всеми основными коммерческими реляционные СУБД. [30] [31]
- OQL — стандарт языка объектных моделей (от Object Data Management Group ). Это повлияло на разработку некоторых новых языков запросов, таких как JDOQL и EJB QL .
- XQuery — это стандартный язык запросов XML, реализованный системами баз данных XML, такими как MarkLogic и eXist , реляционными базами данных с возможностью XML, такими как Oracle и Db2, а также процессорами XML в памяти, такими как Saxon .
- SQL/XML сочетает в себе XQuery и SQL. [32]
Язык базы данных также может включать в себя такие функции, как:
- Конфигурация и управление механизмом хранения данных, специфичные для СУБД.
- Вычисления для изменения результатов запроса, такие как подсчет, суммирование, усреднение, сортировка, группировка и перекрестные ссылки.
- Применение ограничений (например, в автомобильной базе данных разрешен только один тип двигателя на автомобиль)
- Версия интерфейса прикладного программирования языка запросов для удобства программиста.
Хранилище
Хранилище базы данных — это контейнер физической материализации базы данных. Он включает внутренний (физический) уровень архитектуры базы данных. Он также содержит всю необходимую информацию (например, метаданные , «данные о данных» и внутренние структуры данных ) для восстановления концептуального уровня и внешнего уровня из внутреннего уровня, когда это необходимо. Базы данных как цифровые объекты содержат три уровня информации, которую необходимо хранить: данные, структуру и семантику. Правильное хранение всех трех слоев необходимо для сохранения и долговечности базы данных в будущем. [33] За размещение данных в постоянном хранилище обычно отвечает механизм базы данных, известный как «механизм хранения». операционных систем Хотя обычно доступ к СУБД осуществляется через базовую операционную систему (и часто с использованием файловых систем в качестве промежуточных звеньев для структуры хранилища), свойства хранилища и параметры конфигурации чрезвычайно важны для эффективной работы СУБД и, таким образом, тщательно поддерживаются СУБД. администраторы баз данных. База данных СУБД во время работы всегда находится в нескольких типах хранилищ (например, в памяти и во внешнем хранилище). Данные базы данных и дополнительная необходимая информация, возможно, в очень больших объемах, кодируются в битах. Данные обычно находятся в хранилище в структурах, которые выглядят совершенно иначе, чем данные на концептуальном и внешнем уровнях, но таким образом, который пытается оптимизировать (наилучшую возможную) реконструкцию этих уровней, когда это необходимо пользователям и программам. что касается вычисления дополнительных типов необходимой информации из данных (например, при запросе к базе данных).
Некоторые СУБД поддерживают указание того, какая кодировка символов использовалась для хранения данных, поэтому в одной базе данных можно использовать несколько кодировок.
Механизм хранения данных использует различные низкоуровневые структуры хранения базы данных для сериализации модели данных, чтобы ее можно было записать на выбранный носитель. Для повышения производительности можно использовать такие методы, как индексирование. Обычное хранилище ориентировано на строки, но существуют также базы данных, ориентированные на столбцы и корреляционные .
Материализованные представления
Часто избыточность хранилища используется для повышения производительности. Типичным примером является хранение материализованных представлений , которые состоят из часто необходимых внешних представлений или результатов запросов. Хранение таких представлений экономит дорогостоящие вычисления каждый раз, когда они необходимы. Недостатками материализованных представлений являются накладные расходы, возникающие при их обновлении для обеспечения их синхронизации с исходными обновленными данными базы данных, а также стоимость избыточности хранилища.
Репликация
Иногда база данных использует избыточность хранилища путем репликации объектов базы данных (с одной или несколькими копиями) для повышения доступности данных (как для повышения производительности одновременного доступа нескольких конечных пользователей к одному и тому же объекту базы данных, так и для обеспечения устойчивости в случае частичного сбоя распределенная база данных). Обновления реплицированного объекта необходимо синхронизировать между копиями объекта. Во многих случаях реплицируется вся база данных.
Виртуализация
Благодаря виртуализации данных используемые данные остаются в исходных местоположениях, и устанавливается доступ в режиме реального времени, что позволяет проводить аналитику из нескольких источников. Это может помочь решить некоторые технические трудности, такие как проблемы совместимости при объединении данных с различных платформ, снизить риск ошибок, вызванных ошибочными данными, и гарантировать использование новейших данных. Кроме того, отказ от создания новой базы данных, содержащей личную информацию, может облегчить соблюдение правил конфиденциальности. Однако при виртуализации данных подключение ко всем необходимым источникам данных должно быть работоспособным, поскольку локальная копия данных отсутствует, что является одним из основных недостатков подхода. [34]
Безопасность
Эта статья противоречит статье « Безопасность базы данных» . ( март 2013 г. ) |
Безопасность базы данных касается всех различных аспектов защиты содержимого базы данных, ее владельцев и пользователей. Он варьируется от защиты от преднамеренного несанкционированного использования базы данных до непреднамеренного доступа к базе данных со стороны неавторизованных лиц (например, человека или компьютерной программы).
Контроль доступа к базе данных заключается в контроле того, кому (человеку или определенной компьютерной программе) разрешен доступ к какой информации в базе данных. Информация может включать в себя конкретные объекты базы данных (например, типы записей, конкретные записи, структуры данных), определенные вычисления над определенными объектами (например, типы запросов или конкретные запросы) или использование определенных путей доступа к первым (например, использование определенных индексов). или другие структуры данных для доступа к информации). Контроль доступа к базе данных устанавливается специально уполномоченным (владельцем базы данных) персоналом, использующим выделенные защищенные интерфейсы СУБД.
Этим можно управлять непосредственно на индивидуальной основе, или путем назначения отдельных лиц и привилегий группам, или (в наиболее сложных моделях) путем назначения отдельных лиц и групп на роли, которым затем предоставляются права. Безопасность данных не позволяет неавторизованным пользователям просматривать или обновлять базу данных. Используя пароли, пользователям предоставляется доступ ко всей базе данных или ее подмножествам, называемым «подсхемами». Например, база данных сотрудников может содержать все данные об отдельном сотруднике, но одной группе пользователей может быть разрешен просмотр только данных о заработной плате, а другим разрешен доступ только к истории работы и медицинским данным. Если СУБД предоставляет возможность интерактивного входа и обновления базы данных, а также ее опроса, эта возможность позволяет управлять персональными базами данных.
Безопасность данных в целом связана с защитой определенных фрагментов данных как физически (т. е. от повреждения, уничтожения или удаления; например, см. раздел « Физическая безопасность »), так и интерпретации их или их частей в значимую информацию (например, путем просмотр строк битов, которые они содержат, и определение конкретных действительных номеров кредитных карт, например, см . «Шифрование данных »;
Изменяйте и получайте доступ к записям журнала, кто к каким атрибутам обращался, что было изменено и когда это было изменено. Службы ведения журналов позволяют позднее провести судебный аудит базы данных , ведя учет случаев доступа и изменений. Иногда код уровня приложения используется для записи изменений, а не для их сохранения в базе данных. Мониторинг можно настроить для обнаружения нарушений безопасности. Поэтому организации должны серьезно относиться к безопасности баз данных из-за множества преимуществ, которые она предоставляет. Организации будут защищены от нарушений безопасности и хакерских действий, таких как проникновение в брандмауэр, распространение вирусов и программ-вымогателей. Это помогает защитить важную информацию компании, которая ни при каких обстоятельствах не может быть передана посторонним. [35]
Транзакции и параллелизм
Транзакции базы данных можно использовать для обеспечения определенного уровня отказоустойчивости и целостности данных после восстановления после сбоя . Транзакция базы данных — это единица работы, обычно инкапсулирующая ряд операций над базой данных (например, чтение объекта базы данных, запись, получение или снятие блокировки и т. д.), абстракция, поддерживаемая в базе данных, а также в других системах. Каждая транзакция имеет четко определенные границы, в которых выполнение программы/кода включается в эту транзакцию (определяется программистом транзакции с помощью специальных команд транзакции).
Аббревиатура ACID описывает некоторые идеальные свойства транзакции базы данных: атомарность , согласованность , изоляция и долговечность .
Миграция
База данных, созданная с помощью одной СУБД, не переносима на другую СУБД (т. е. другая СУБД не может ее запустить). Однако в некоторых ситуациях желательно перенести базу данных из одной СУБД в другую. Причины в первую очередь экономические (разные СУБД могут иметь разную совокупную стоимость владения или совокупную стоимость владения), функциональные и эксплуатационные (разные СУБД могут иметь разные возможности). Миграция предполагает преобразование базы данных из одного типа СУБД в другой. Преобразование должно сохранить (если возможно) приложение, связанное с базой данных (т. е. все связанные прикладные программы), в неприкосновенности. Таким образом, концептуальный и внешний архитектурный уровни базы данных должны быть сохранены при преобразовании. Может быть желательно, чтобы также сохранялись некоторые аспекты внутреннего уровня архитектуры. Сложная или большая миграция базы данных сама по себе может быть сложным и дорогостоящим (однократным) проектом, который следует учитывать при принятии решения о миграции. И это несмотря на то, что могут существовать инструменты, облегчающие миграцию между конкретными СУБД. Обычно поставщик СУБД предоставляет инструменты, помогающие импортировать базы данных из других популярных СУБД.
Сборка, обслуживание и настройка
После проектирования базы данных для приложения следующим этапом является ее создание. Обычно для этой цели можно выбрать подходящую СУБД общего назначения. СУБД предоставляет необходимые пользовательские интерфейсы , которые администраторы баз данных могут использовать для определения структур данных необходимого приложения в рамках соответствующей модели данных СУБД. Другие пользовательские интерфейсы используются для выбора необходимых параметров СУБД (например, связанных с безопасностью, параметров распределения памяти и т. д.).
Когда база данных готова (определены все ее структуры данных и другие необходимые компоненты), она обычно заполняется исходными данными приложения (инициализация базы данных, которая обычно представляет собой отдельный проект; во многих случаях с использованием специализированных интерфейсов СУБД, поддерживающих массовую вставку) перед приведение его в действие. В некоторых случаях база данных становится работоспособной, когда в ней отсутствуют данные приложения, и данные накапливаются во время ее работы.
После того как база данных создана, инициализирована и заполнена, ее необходимо поддерживать. Возможно, потребуется изменить различные параметры базы данных, а базу данных, возможно, потребуется настроить ( настроить ) для повышения производительности; структуры данных приложения могут быть изменены или добавлены, могут быть написаны новые связанные прикладные программы для расширения функциональности приложения и т. д.
Резервное копирование и восстановление
Иногда желательно вернуть базу данных в предыдущее состояние (по многим причинам, например, в случаях, когда база данных оказывается поврежденной из-за ошибки программного обеспечения или если она была обновлена ошибочными данными). Чтобы добиться этого, операция резервного копирования выполняется время от времени или постоянно, при этом каждое желаемое состояние базы данных (т. е. значения ее данных и их внедрение в структуры данных базы данных) сохраняется в выделенных файлах резервных копий (существует множество методов для эффективного выполнения этого). Когда администратор базы данных решает вернуть базу данных в это состояние (например, путем указания этого состояния по желаемому моменту времени, когда база данных находилась в этом состоянии), эти файлы используются для восстановления этого состояния.
Статический анализ
Методы статического анализа для проверки программного обеспечения могут применяться также в сценариях языков запросов. * В частности, структура интерпретации Abstract была расширена на область языков запросов для реляционных баз данных как способ поддержки надежных методов аппроксимации. [36] Семантика языков запросов может быть настроена в соответствии с подходящими абстракциями конкретной области данных. Абстракция систем реляционных баз данных имеет множество интересных приложений, в частности, в целях безопасности, таких как детальный контроль доступа, нанесение водяных знаков и т. д.
Разные функции
Другие функции СУБД могут включать в себя:
- Журналы базы данных . Это помогает вести историю выполненных функций.
- Графический компонент для создания графиков и диаграмм, особенно в системе хранилища данных.
- Оптимизатор запросов . Выполняет оптимизацию запросов для каждого запроса, чтобы выбрать эффективный план запроса (частичный порядок (дерево) операций), который будет выполняться для вычисления результата запроса. Может быть специфичным для конкретного механизма хранения.
- Инструменты или средства для проектирования баз данных, программирования приложений, обслуживания прикладных программ, анализа и мониторинга производительности базы данных, мониторинга конфигурации базы данных, конфигурации оборудования СУБД (СУБД и связанная с ней база данных могут охватывать компьютеры, сети и блоки хранения) и связанного сопоставления базы данных (особенно для распределенная СУБД), мониторинг распределения хранилища и структуры базы данных, миграция хранилища и т. д.
Все чаще звучат призывы к созданию единой системы, которая включала бы все эти основные функции в одну и ту же среду сборки, тестирования и развертывания для управления базами данных и контроля версий. Заимствуя другие разработки в индустрии программного обеспечения, некоторые продают такие предложения как « DevOps для баз данных». [37]
Проектирование и моделирование

Первой задачей разработчика базы данных является создание концептуальной модели данных , отражающей структуру информации, которая будет храниться в базе данных. Распространенным подходом к этому является разработка модели «сущность-связь» , часто с помощью инструментов рисования. Другой популярный подход — унифицированный язык моделирования . Успешная модель данных будет точно отражать возможное состояние моделируемого внешнего мира: например, если у людей может быть более одного номера телефона, это позволит собирать эту информацию. Разработка хорошей концептуальной модели данных требует хорошего понимания предметной области приложения; обычно он включает в себя задавание глубоких вопросов о вещах, представляющих интерес для организации, например: «Может ли клиент также быть поставщиком?» или «Если продукт продается в двух разных формах упаковки, это один и тот же продукт или разные продукты?» ", или "если самолет летит из Нью-Йорка в Дубай через Франкфурт, это один рейс или два (а может быть, даже три)?". Ответы на эти вопросы определяют определения терминологии, используемой для объектов (клиентов, продуктов, рейсов, сегментов рейсов), а также их отношений и атрибутов.
Создание концептуальной модели данных иногда включает в себя входные данные из бизнес-процессов или анализ рабочего процесса в организации. Это может помочь определить, какая информация необходима в базе данных, а какую можно не учитывать. Например, это может помочь при принятии решения о том, должна ли база данных хранить исторические данные, а также текущие данные.
После создания концептуальной модели данных, которая устраивает пользователей, следующим этапом является преобразование ее в схему , реализующую соответствующие структуры данных в базе данных. Этот процесс часто называют логическим проектированием базы данных, а на выходе получается логическая модель данных, выраженная в форме схемы. В то время как концептуальная модель данных (по крайней мере теоретически) не зависит от выбора технологии базы данных, логическая модель данных будет выражаться в терминах конкретной модели базы данных, поддерживаемой выбранной СУБД. (Термины «модель данных» и «модель базы данных» часто используются как взаимозаменяемые, но в этой статье мы используем модель данных для проектирования конкретной базы данных, а модель базы данных — для обозначения моделирования, используемого для выражения этого проекта).
Наиболее популярной моделью баз данных для баз данных общего назначения является реляционная модель, или, точнее, реляционная модель, представленная языком SQL. В процессе создания логической структуры базы данных с использованием этой модели используется методический подход, известный как нормализация . Цель нормализации — гарантировать, что каждый элементарный «факт» записывается только в одном месте, чтобы вставки, обновления и удаления автоматически сохраняли согласованность.
Заключительный этап проектирования базы данных — принятие решений, влияющих на производительность, масштабируемость, восстановление, безопасность и тому подобное, которые зависят от конкретной СУБД. Это часто называют физическим проектированием базы данных , а результатом является физическая модель данных . Ключевой целью на этом этапе является независимость данных . Это означает, что решения, принимаемые в целях оптимизации производительности, должны быть невидимы для конечных пользователей и приложений. Существует два типа независимости данных: физическая независимость данных и логическая независимость данных. Физическое проектирование обусловлено главным образом требованиями к производительности и требует хорошего знания ожидаемой рабочей нагрузки и шаблонов доступа, а также глубокого понимания функций, предлагаемых выбранной СУБД.
Еще одним аспектом проектирования физической базы данных является безопасность. Он включает в себя как определение контроля доступа к объектам базы данных, так и определение уровней и методов безопасности для самих данных.
Модели
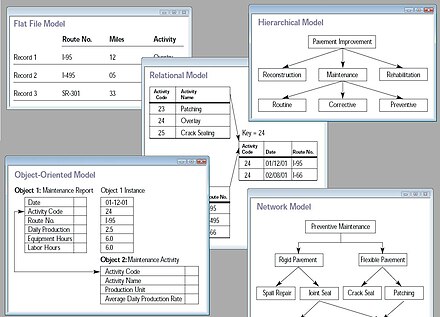
Модель базы данных — это тип модели данных, который определяет логическую структуру базы данных и фундаментально определяет, каким образом данные могут храниться, организовываться и манипулироваться ими. Самым популярным примером модели базы данных является реляционная модель (или SQL-аппроксимация реляционной модели), в которой используется табличный формат.
Общие логические модели данных для баз данных включают:
- Навигационные базы данных
- Реляционная модель
- Модель сущность-связь
- Объектная модель
- Модель документа
- Модель сущность-атрибут-значение
- Звездный график
Объектно-реляционная база данных объединяет две связанные структуры.
Модели физических данных включают в себя:
Другие модели включают в себя:
Специализированные модели оптимизированы для определенных типов данных:
Внешний, концептуальный и внутренний взгляды
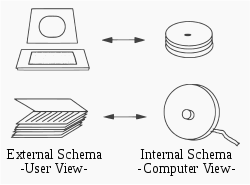
Система управления базами данных обеспечивает три представления данных базы данных:
- Внешний уровень определяет, как каждая группа конечных пользователей видит организацию данных в базе данных. Одна база данных может иметь любое количество представлений на внешнем уровне.
- Концептуальный уровень (или логический уровень ) объединяет различные внешние представления в совместимое глобальное представление. [39] Он обеспечивает синтез всех внешних представлений. Это выходит за рамки возможностей различных конечных пользователей баз данных и скорее представляет интерес для разработчиков приложений баз данных и администраторов баз данных.
- Внутренний уровень (или физический уровень ) — это внутренняя организация данных внутри СУБД. Он касается стоимости, производительности, масштабируемости и других эксплуатационных вопросов. Он касается структуры хранения данных, используя структуры хранения, такие как индексы, для повышения производительности. Иногда он сохраняет данные отдельных представлений ( материализованных представлений ), вычисленных на основе общих данных, если существует обоснование производительности для такой избыточности. Он уравновешивает требования к производительности всех внешних представлений, возможно, противоречивые, в попытке оптимизировать общую производительность всех действий.
Хотя обычно существует только одно концептуальное и внутреннее представление данных, может быть любое количество различных внешних представлений. Это позволяет пользователям просматривать информацию базы данных с более деловой точки зрения, а не с технической точки зрения обработки. Например, финансовому отделу компании необходимы сведения о платежах всех сотрудников в составе расходов компании, но не нужны сведения о сотрудниках, которые представляют интерес для отдела кадров . Таким образом, разным отделам нужны разные представления базы данных компании.
Трехуровневая архитектура базы данных связана с концепцией независимости данных , которая была одной из основных первоначальных движущих сил реляционной модели. [39] Идея состоит в том, что изменения, сделанные на определенном уровне, не влияют на представление на более высоком уровне. Например, изменения на внутреннем уровне не влияют на прикладные программы, написанные с использованием интерфейсов концептуального уровня, что снижает влияние внесения физических изменений на повышение производительности.
Концептуальный взгляд обеспечивает уровень косвенности между внутренним и внешним. С одной стороны, он обеспечивает общее представление базы данных, независимое от различных внешних структур представления, а с другой стороны, абстрагирует детали того, как данные хранятся или управляются (внутренний уровень). В принципе, каждый уровень и даже каждое внешнее представление могут быть представлены различной моделью данных. На практике обычно данная СУБД использует одну и ту же модель данных как для внешнего, так и для концептуального уровня (например, реляционная модель). Внутренний уровень, который скрыт внутри СУБД и зависит от ее реализации, требует другого уровня детализации и использует свои типы типов структур данных.
Исследовать
Технология баз данных была активной темой исследований с 1960-х годов как в академических кругах , так и в группах компаний, занимающихся исследованиями и разработками (например, IBM Research ). Научно-исследовательская деятельность включает теорию и разработку прототипов . Известные темы исследований включали модели , концепцию атомарных транзакций, соответствующие методы управления параллелизмом , языки запросов и оптимизации запросов методы , RAID и многое другое.
В области исследования баз данных есть несколько специализированных академических журналов (например, ACM Transactions on Database Systems -TODS, Data and Knowledge Engineering -DKE) и ежегодных конференций (например, ACM SIGMOD , ACM PODS , VLDB , IEEE ICDE).
См. также
- Сравнение инструментов базы данных
- Сравнение объектных систем управления базами данных
- Сравнение объектно-реляционных систем управления базами данных
- Сравнение систем управления реляционными базами данных
- Иерархия данных
- Банк данных
- Хранилище данных
- Теория баз данных
- Тестирование базы данных
- Архитектура, ориентированная на базу данных
- Ученый-компьютерщик
- База данных как IPC
- ДБОС
- База данных в виде плоских файлов
- ИЯФ (база данных)
- Журнал управления базами данных
- Набор данных, ориентированный на вопросы
Примечания
Ссылки
- ^ Ульман и Видом 1997 , с. 1.
- ^ «Обновление определения и значения» . Мерриам-Вебстер . Архивировано из оригинала 25 февраля 2024 года.
- ^ «Определение и значение поиска» . Мерриам-Вебстер . Архивировано из оригинала 27 июня 2023 г.
- ^ «Определение и значение администрации» . Мерриам-Вебстер . Архивировано из оригинала 6 декабря 2023 года.
- ^ Цитчизрис и Лоховский 1982 .
- ^ Бейнон-Дэвис 2003 .
- ^ Нельсон и Нельсон 2001 .
- ^ Бахман 1973 .
- ^ «Индекс топовой базы данных TOPDB» . pypl.github.io .
- ^ «база данных, n» . ОЭД онлайн . Издательство Оксфордского университета. Июнь 2013 года . Проверено 12 июля 2013 г. (Требуется подписка.)
- ^ Корпорация IBM (октябрь 2013 г.). «Серверы транзакций и баз данных IBM Information Management System (IMS) 13 обеспечивают высокую производительность и низкую совокупную стоимость владения» . Проверено 20 февраля 2014 г.
- ^ Кодд 1970 .
- ^ Херши и Истхоуп 1972 .
- ^ Север 2010 .
- ^ Чайлдс 1968a .
- ^ Чайлдс 1968b .
- ^ М. А. Кан; Д.Л. Румельхарт; Б.Л. Бронсон (октябрь 1977 г.). Справочное руководство по системе управления информацией MICRO (Версия 5.0) . Институт труда и производственных отношений (ILIR), Мичиганский университет и Государственный университет Уэйна.
- ^ «Хронология 30-летия Oracle» (PDF) . Архивировано (PDF) из оригинала 20 марта 2011 г. Проверено 23 августа 2017 г.
- ^ Интервью с Уэйном Рэтлиффом . История FoxPro. Проверено 12 июля 2013 г.
- ^ Разработка объектно-ориентированной СУБД; Портленд, Орегон, США; Страницы: 472–482; 1986 год; ISBN 0-89791-204-7
- ^ Грейвс, Стив. «Базы данных COTS для встраиваемых систем». Архивировано 14 ноября 2007 г. в журнале Wayback Machine , журнал Embedded Computing Design , январь 2007 г. Проверено 13 августа 2008 г.
- ^ Аргументация в области искусственного интеллекта Ияда Рахвана, Гильермо Р. Симари
- ^ «Семантика OWL DL» . Проверено 10 декабря 2010 г.
- ^ Коннолли и Бегг 2014 , с. 64.
- ^ Коннолли и Бегг 2014 , стр. 97–102.
- ^ Коннолли и Бегг 2014 , с. 102.
- ^ Чонг и др. 2007 .
- ^ Коннолли и Бегг, 2014 , стр. 106–113.
- ^ Коннолли и Бегг 2014 , с. 65.
- ^ Чаппл 2005 .
- ^ «Язык структурированных запросов (SQL)» . Машины международного бизнеса. 27 октября 2006 года . Проверено 10 июня 2007 г.
- ^ Вагнер 2010 .
- ^ Рамальо, JC; Фариа, Л.; Хелдер, С.; Коутада, М. (31 декабря 2013 г.). «Набор инструментов для сохранения баз данных: гибкий инструмент для нормализации баз данных и предоставления доступа к ним» . Национальная библиотека Португалии (BNP) . Университет Минхо.
- ^ Пайхо, Сказка; Туоминен, Пекка; Рёкман, Юри; Юликераля, Маркус; Паюла, Юха; Сиикавирта, Ханне (2022). «Возможности собранных городских данных для умных городов» . ИЭПП «Умные города» . 4 (4): 275–291. дои : 10.1049/smc2.12044 . S2CID 253467923 .
- ^ Дэвид Ю. Чан; Виктория Чиу; Миклош А. Васархели (2018). Непрерывный аудит: теория и применение (1-е изд.). Бингли, Великобритания: Издательство Emerald Publishing. ISBN 978-1-78743-413-4 . OCLC 1029759767 .
- ^ Гальдер и Кортези 2011 .
- ^ Бен Линдерс (28 января 2016 г.). «Как администрирование баз данных вписывается в DevOps» . Проверено 15 апреля 2017 г.
- ^ itl.nist.gov (1993) Определение интеграции для информационного моделирования (IDEFIX). Архивировано 3 декабря 2013 г. в Wayback Machine . 21 декабря 1993 года.
- ^ Jump up to: Перейти обратно: а б Дата 2003 г. , стр. 31–32.
Источники
- Бахман, Чарльз В. (1973). «Программист как навигатор» . Коммуникации АКМ . 16 (11): 653–658. дои : 10.1145/355611.362534 .
- Бейнон-Дэвис, Пол (2003). Системы баз данных (3-е изд.). Пэлгрейв Макмиллан. ISBN 978-1403916013 .
- Чаппл, Майк (2005). «Основы SQL» . Базы данных . О сайте.com. Архивировано из оригинала 22 февраля 2009 года . Проверено 28 января 2009 г.
- Чайлдс, Дэвид Л. (1968a). Описание теоретико-множественной структуры данных (PDF) (Технический отчет). Проект CONCOMP (Исследование диалогового использования компьютеров). Мичиганский университет. Технический отчет 3.
- Чайлдс, Дэвид Л. (1968b). Осуществимость теоретико-множественной структуры данных: общая структура, основанная на воссозданном определении (PDF) (Технический отчет). Проект CONCOMP (Исследование диалогового использования компьютеров). Мичиганский университет. Технический отчет 6.
- Чонг, Рауль Ф.; Ван, Сяомэй; Данг, Майкл; Сноу, Дуэйн Р. (2007). «Введение в DB2» . Понимание DB2: визуальное обучение на примерах (2-е изд.). IBM Press Pearson plc. ISBN 978-0131580183 . Проверено 17 марта 2013 г.
- Кодд, Эдгар Ф. (1970). «Реляционная модель данных для больших общих банков данных» (PDF) . Коммуникации АКМ . 13 (6): 377–387. дои : 10.1145/362384.362685 . S2CID 207549016 .
- Коннолли, Томас М.; Бегг, Кэролайн Э. (2014). Системы баз данных - практический подход к реализации дизайна и управлению (6-е изд.). Пирсон. ISBN 978-1292061184 .
- Дата, CJ (2003). Введение в системы баз данных (8-е изд.). Пирсон. ISBN 978-0321197849 .
- Гальдер, Раджу; Кортези, Агостино (2011). «Абстрактная интерпретация языков запросов к базам данных» (PDF) . Компьютерные языки, системы и структуры . 38 (2): 123–157. дои : 10.1016/j.cl.2011.10.004 . ISSN 1477-8424 .
- Херши, Уильям; Истхоуп, Кэрол (1972). Теоретико-множественная структура данных и язык поиска . Весенняя совместная компьютерная конференция, май 1972 г. Форум ACM SIGIR . Том. 7, нет. 4. С. 45–55. дои : 10.1145/1095495.1095500 .
- Нельсон, Энн Фулчер; Нельсон, Уильям Харрис Морхед (2001). Построение электронной коммерции: с помощью построения веб-баз данных . Прентис Холл. ISBN 978-0201741308 .
- Норт, Кен (10 марта 2010 г.). «Наборы, модели данных и независимость данных» . Доктор Добб . Архивировано из оригинала 24 октября 2012 года.
- Цитчизрис, Дионисий К.; Лоховский, Фред Х. (1982). Модели данных . Прентис-Холл. ISBN 978-0131964280 .
- Уллман, Джеффри; Видом, Дженнифер (1997). Первый курс систем баз данных . Прентис-Холл. ISBN 978-0138613372 .
- Вагнер, Майкл (2010), SQL/XML:2006 - Оценка соответствия стандартам выбранных систем баз данных , Diplomica Verlag, ISBN 978-3836696098
Дальнейшее чтение
- Лин Лю и Тамер М. Озсу (ред.) (2009). « Энциклопедия систем баз данных» , 4100 стр. 60 илл. ISBN 978-0-387-49616-0 .
- Грей Дж. и Рейтер А. Обработка транзакций: концепции и методы , 1-е издание, Morgan Kaufmann Publishers, 1992.
- Кронке, Дэвид М. и Дэвид Дж. Ауэр. Концепции базы данных. 3-е изд. Нью-Йорк: Прентис, 2007.
- Рагху Рамакришнан и Йоханнес Герке , Системы управления базами данных .
- Абрахам Зильбершац , Генри Ф. Корт , С. Сударшан, Концепции системы баз данных .
- Лайтстоун, С.; Теори, Т.; Надо, Т. (2007). Проектирование физических баз данных: руководство для специалистов по базам данных по использованию индексов, представлений, хранилищ и т. д . Морган Кауфманн Пресс. ISBN 978-0-12-369389-1 .
- Теори, Т.; Лайтстоун, С. и Надо, Т. Моделирование и проектирование баз данных: логическое проектирование , 4-е издание, Morgan Kaufmann Press, 2005. ISBN 0-12-685352-5 .
- Плейлист курсов по базе данных CMU
- С OCW 6830 | Осень 2010 г. | Системы баз данных
- Беркли CS W186
Внешние ссылки
- Расширение файла DB – информация о файлах с расширением DB.