Семантическая сеть

| Семантика | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
|
Семантика языки программирования | ||||||||
|
||||||||
Семантическая сеть , иногда известная как Web 3.0 (не путать с Web3 ), является расширением Всемирной паутины посредством стандартов. [1] установлен Консорциумом Всемирной паутины (W3C). Цель семантической сети — сделать данные Интернета машиночитаемыми.
Чтобы обеспечить кодирование семантики данных, используются такие технологии, как Resource Description Framework (RDF). [2] и язык веб-онтологии (OWL) [3] используются. Эти технологии используются для формального представления метаданных . Например, онтология может описывать концепции , отношения между сущностями и категориями вещей. Эта встроенная семантика предлагает значительные преимущества, такие как анализ данных и работа с разнородными источниками данных. [4]
Эти стандарты продвигают общие форматы данных и протоколы обмена в Интернете, в основном RDF. По мнению W3C, «Семантическая сеть обеспечивает общую структуру, которая позволяет совместно использовать и повторно использовать данные в пределах границ приложений, предприятий и сообществ». [5] Поэтому семантическая сеть рассматривается как интегратор различных контентных и информационных приложений и систем.
Этот термин был придуман Тимом Бернерсом-Ли для обозначения сети данных (или сети данных ). [6] которые могут быть обработаны машинами [7] в котором большая часть смысла машиночитаема — то есть такой , . Хотя критики ставят под сомнение ее осуществимость, сторонники утверждают, что применение в библиотечной и информационной науке , промышленности, биологии и исследованиях в области гуманитарных наук уже доказало обоснованность первоначальной концепции. [8]
Бернерс-Ли первоначально выразил свое видение семантической сети в 1999 году следующим образом:
У меня есть мечта о Сети, [в которой компьютеры] смогут анализировать все данные в сети – контент, ссылки и транзакции между людьми и компьютерами. «Семантическая сеть», которая сделает это возможным, еще не появилась, но когда она появится, повседневными механизмами торговли, бюрократии и нашей повседневной жизни будут управлять машины, разговаривающие с машинами. « Интеллектуальные агенты », которых люди рекламировали на протяжении веков, наконец-то материализуются. [9]
2001 года в журнале Scientific American В статье Бернерса-Ли, Хендлера и Лассилы описывается ожидаемая эволюция существующей сети к семантической сети. [10] В 2006 году Бернерс-Ли и его коллеги заявили: «Эта простая идея… остается по большей части нереализованной». [11] В 2013 году более четырех миллионов веб-доменов (из примерно 250 миллионов) содержали разметку семантической сети. [12]
Пример [ править ]
В следующем примере текст «Пауль Шустер родился в Дрездене» на веб-сайте будет снабжен аннотацией, связывающей человека с местом его рождения. Следующий фрагмент HTML показывает, как описывается небольшой граф в RDFa синтаксисе с использованием словаря Schema.org и идентификатора Wikidata :
<div vocab="https://schema.org/" typeof="Person">
<span property="name">Paul Schuster</span> was born in
<span property="birthPlace" typeof="Place" href="https://www.wikidata.org/entity/Q1731">
<span property="name">Dresden</span>.
</span>
</div>

В примере определяются следующие пять троек (показаны в синтаксисе Turtle ). Каждая тройка представляет одно ребро в результирующем графе: первый элемент тройки ( субъект ) — это имя узла, в котором начинается ребро, второй элемент ( предикат ) — тип ребра, а последний и третий элемент ( объект ) либо имя узла, где заканчивается ребро, либо буквальное значение (например, текст, число и т. д.).
_:a <https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <https://schema.org/Person> .
_:a <https://schema.org/name> "Paul Schuster" .
_:a <https://schema.org/birthPlace> <https://www.wikidata.org/entity/Q1731> .
<https://www.wikidata.org/entity/Q1731> <https://schema.org/itemtype> <https://schema.org/Place> .
<https://www.wikidata.org/entity/Q1731> <https://schema.org/name> "Dresden" .
Тройки приводят к графу, показанному на данном рисунке .
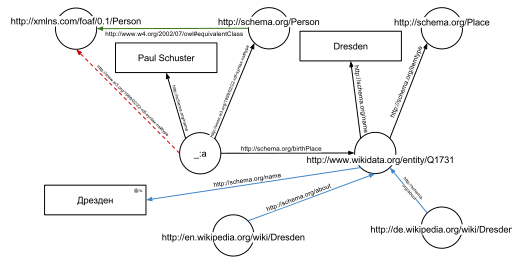
Одним из преимуществ использования унифицированных идентификаторов ресурсов (URI) является то, что их можно разыменовать с помощью протокола HTTP . Согласно так называемым принципам связанных открытых данных , такой разыменованный URI должен привести к созданию документа, который предлагает дополнительные данные о данном URI. В этом примере все URI, как для ребер, так и для узлов (например, http://schema.org/Person, http://schema.org/birthPlace, http://www.wikidata.org/entity/Q1731) можно разыменовать, что приведет к созданию дополнительных графов RDF, описывающих URI, например, что Дрезден — город в Германии или что человек в смысле этого URI может быть вымышленным.
Второй график показывает предыдущий пример, но теперь дополнен несколькими тройками из документов, полученными в результате разыменования. https://schema.org/Person (зеленый край) и https://www.wikidata.org/entity/Q1731 (синие края).
В дополнение к ребрам, явно заданным в соответствующих документах, ребра могут быть автоматически выведены: тройка
_:a <https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Person> .
из исходного фрагмента RDFa и тройки
<https://schema.org/Person> <http://www.w3.org/2002/07/owl#equivalentClass> <http://xmlns.com/foaf/0.1/Person> .
из документа по адресу https://schema.org/Person (зеленый край на рисунке) позволяют вывести следующую тройку, учитывая семантику OWL (красная пунктирная линия на втором рисунке):
_:a <https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> .
Предыстория [ править ]
Концепция модели семантической сети была сформирована в начале 1960-х годов такими исследователями, как ученый-когнитивист Аллан М. Коллинз , лингвист М. Росс Куиллиан и психолог Элизабет Ф. Лофтус, как форма представления семантически структурированных знаний. При применении в контексте современного Интернета он расширяет сеть гиперссылок, удобочитаемых человеком веб-страниц , вставляя машиночитаемые метаданные о страницах и о том, как они связаны друг с другом. Это позволяет автоматическим агентам более интеллектуально получать доступ к Интернету и выполнять больше задач от имени пользователей. Термин «Семантическая сеть» был придуман Тимом Бернерсом-Ли . [7] изобретатель Всемирной паутины и директор Консорциума Всемирной паутины (« W3C »), который курирует разработку предлагаемых стандартов семантической паутины. Он определяет семантическую сеть как «сеть данных, которые могут обрабатываться машинами прямо или косвенно».
Многие из технологий, предложенных W3C, уже существовали до того, как они были позиционированы под эгидой W3C. Они используются в различных контекстах, особенно в тех, которые связаны с информацией, которая охватывает ограниченную и определенную область, и где обмен данными является общей необходимостью, например, научные исследования или обмен данными между предприятиями. Кроме того, появились и другие технологии с аналогичными целями, например микроформаты .
Ограничения HTML [ править ]
Многие файлы на обычном компьютере также можно условно разделить на документы, читаемые человеком, и данные, читаемые компьютером. Такие документы, как почтовые сообщения, отчеты и брошюры, читаются людьми. Данные, такие как календари, адресные книги, списки воспроизведения и электронные таблицы, представляются с помощью прикладной программы, которая позволяет их просматривать, искать и комбинировать.
В настоящее время Всемирная паутина основана главным образом на документах, написанных на языке гипертекстовой разметки (HTML), соглашении о разметке, которое используется для кодирования текста с вкраплениями мультимедийных объектов, таких как изображения и интерактивные формы. Теги метаданных предоставляют метод, с помощью которого компьютеры могут классифицировать содержимое веб-страниц. В приведенных ниже примерах именам полей «ключевые слова», «описание» и «автор» присвоены такие значения, как «вычисления», «дешевые виджеты на продажу» и «Джон Доу».
<meta name="keywords" content="computing, computer studies, computer" />
<meta name="description" content="Cheap widgets for sale" />
<meta name="author" content="John Doe" />
Благодаря такой маркировке и категоризации метаданных другие компьютерные системы, желающие получить доступ к этим данным и поделиться ими, могут легко идентифицировать соответствующие значения.
С помощью HTML и инструмента для его отображения (возможно, программного обеспечения веб-браузера , возможно, другого пользовательского агента ) можно создать и представить страницу со списком товаров, выставленных на продажу. HTML-код этой страницы каталога может содержать простые утверждения на уровне документа, такие как «Название этого документа — «Widget Superstore » », но в самом HTML-коде нет возможности однозначно утверждать, что, например, номер позиции X586172 является кодом Acme. Gizmo с розничной ценой 199 евро или что это потребительский товар. Скорее, HTML может только сказать, что диапазон текста «X586172» должен быть расположен рядом с «Acme Gizmo», «199 евро» и т. д. Невозможно сказать «это каталог» или даже установить это. «Acme Gizmo» — это своего рода титул, а «199 евро» — это цена. Также невозможно выразить, что эти фрагменты информации связаны вместе при описании отдельного элемента, отличного от других элементов, возможно, перечисленных на странице.
Семантический HTML относится к традиционной практике HTML, заключающейся в разметке в соответствии с намерением, а не непосредственном указании деталей макета. Например, использование <em> обозначающий «акцент», а не <i>, который определяет курсив . Детали макета оставляются на усмотрение браузера в сочетании с каскадными таблицами стилей . Но эта практика не позволяет определить семантику таких объектов, как предметы для продажи или цены.
Микроформаты расширяют синтаксис HTML для создания машиночитаемой семантической разметки объектов, включая людей, организации, события и продукты. [13] Подобные инициативы включают RDFa , Microdata и Schema.org .
Семантические веб-решения [ править ]
Семантическая сеть продвигает решение еще дальше. Он включает публикацию на языках, специально предназначенных для данных: структура описания ресурсов (RDF), язык веб-онтологий (OWL) и расширяемый язык разметки ( XML ). HTML описывает документы и связи между ними. RDF, OWL и XML, напротив, могут описывать произвольные вещи, такие как люди, встречи или части самолета.
Эти технологии объединяются для предоставления описаний, которые дополняют или заменяют содержимое веб-документов. Таким образом, контент может проявляться как описательные данные, хранящиеся в доступных через Интернет базах данных . [14] или как разметка внутри документов (в частности, в расширяемом HTML ( XHTML ) с вкраплениями XML или, что чаще, исключительно в XML, с сигналами макета или рендеринга, хранящимися отдельно). Машиночитаемые описания позволяют контент-менеджерам добавлять смысл к контенту, т. е. описывать структуру наших знаний об этом контенте. Таким образом, машина может обрабатывать знания сама, а не текст, используя процессы, аналогичные человеческим дедуктивным рассуждениям и выводам , тем самым получая более значимые результаты и помогая компьютерам выполнять автоматизированный сбор информации и исследования.
Пример тега, который будет использоваться на несемантической веб-странице:
<item>blog</item>
Кодирование аналогичной информации на семантической веб-странице может выглядеть следующим образом:
<item rdf:about="https://example.org/semantic-web/">Semantic Web</item>
Тим Бернерс-Ли называет получившуюся сеть связанных данных гигантским глобальным графом , в отличие от Всемирной паутины на основе HTML. Бернерс-Ли утверждает, что если в прошлом был обмен документами, то будущее — это обмен данными . Его ответ на вопрос «как» содержит три пункта наставления. Во-первых, URL-адрес должен указывать на данные. Во-вторых, любой, кто обращается к URL-адресу, должен получить данные обратно. В-третьих, связи в данных должны указывать на дополнительные URL-адреса с данными.
Теги и идентификаторы [ править ]
Теги , включая иерархические категории и теги, которые добавляются и поддерживаются совместно (например, с помощью фолксономий ), могут считаться частью потенциального использования или шагом к семантической концепции Интернета. [15] [16] [17]
Уникальные идентификаторы , включая иерархические категории и совместно добавляемые категории, инструменты анализа (например, алгоритмы scite.ai) [18] а метаданные , включая теги, могут использоваться для создания форм семантических сетей – сетей, которые в определенной степени являются семантическими. В частности, это использовалось для структурирования научных исследований, в том числе по темам исследований и научным областям в проектах OpenAlex , [19] [20] [21] Wikidata и Scholia , которые находятся в стадии разработки и предоставляют API , веб-страницы, каналы и графики для различных семантических запросов .
Веб 3.0 [ править ]
Тим Бернерс-Ли описал семантическую сеть как компонент Web 3.0. [22]
Люди продолжают спрашивать, что такое Web 3.0. Я думаю, возможно, когда у вас будет наложение масштабируемой векторной графики – все колеблется, складывается и выглядит туманным – в Web 2.0 и доступ к семантической сети, интегрированной в огромном пространстве данных, вы получите доступ к невероятному ресурсу данных. …
- Тим Бернерс-Ли, 2006 г.
«Семантическая сеть» иногда используется как синоним «Веб 3.0». [23] хотя определение каждого термина различается.
Проблемы [ править ]
Некоторые из проблем семантической сети включают обширность, неопределенность, неопределенность, непоследовательность и обман. Автоматизированным системам рассуждения придется иметь дело со всеми этими проблемами, чтобы реализовать обещания семантической сети.
- Обширность: Всемирная паутина содержит многие миллиарды страниц. SNOMED CT медицинской терминологии Одна только онтология содержит 370 000 названий классов , а существующие технологии пока не способны устранить все семантически дублированные термины. Любой автоматизированной системе рассуждения придется иметь дело с действительно огромными входными данными.
- Неясность: это неточные понятия, такие как «молодой» или «высокий». Это возникает из-за неясности пользовательских запросов, концепций, представленных поставщиками контента, соответствия терминов запроса терминам поставщика и попыток объединить различные базы знаний с перекрывающимися, но слегка разными концепциями. Нечеткая логика — наиболее распространенный метод борьбы с неопределенностью.
- Неопределенность: это точные понятия с неопределенными значениями. Например, у пациента может быть набор симптомов, которые соответствуют множеству различных диагнозов, каждый из которых имеет разную вероятность. Вероятностные методы рассуждения обычно используются для устранения неопределенности.
- Непоследовательность: это логические противоречия, которые неизбежно возникнут при разработке больших онтологий, а также при объединении онтологий из отдельных источников. Дедуктивные рассуждения терпят катастрофические неудачи, когда сталкиваются с противоречием, поскольку «из противоречия вытекает все» . Оправданные рассуждения и паранепротиворечивые рассуждения — это два метода, которые можно использовать для борьбы с несогласованностью.
- Обман: это когда производитель информации намеренно вводит в заблуждение потребителя информации. криптографии В настоящее время для устранения этой угрозы используются методы . Однако, предоставляя средства для определения целостности информации, включая ту, которая касается личности лица, создавшего или опубликовавшего информацию, вопросы достоверности по-прежнему необходимо решать в случаях потенциального обмана.
Этот список проблем носит скорее иллюстративный, чем исчерпывающий характер, и он сосредоточен на проблемах слоев «объединяющей логики» и «доказательства» семантической сети. Инкубаторская группа Консорциума Всемирной паутины (W3C) по обоснованию неопределенности во Всемирной паутине [24] В итоговом отчете (URW3-XG) эти проблемы объединены под одним заголовком «неопределенность». [25] Многие из упомянутых здесь методов потребуют расширения языка веб-онтологий (OWL), например, для аннотирования условных вероятностей. Это область активных исследований. [26]
Стандарты [ править ]
Стандартизацией семантической сети в контексте Web 3.0 занимается W3C. [27]
Компоненты [ править ]
Термин «Семантическая сеть» часто используется более конкретно для обозначения форматов и технологий, которые ее обеспечивают. [5] Сбор, структурирование и восстановление связанных данных обеспечиваются технологиями, которые обеспечивают формальное описание концепций, терминов и отношений в данной области знаний . Эти технологии определены как стандарты W3C и включают в себя:
- Структура описания ресурсов (RDF), общий метод описания информации.
- Схема RDF (RDFS)
- Простая система организации знаний (СКОС)
- SPARQL , язык запросов RDF.
- Notation3 (N3), разработанный с учетом удобства чтения человеком.
- N-Triples — формат хранения и передачи данных.
- Черепаха (краткий тройной язык RDF)
- Язык веб-онтологии (OWL), семейство языков представления знаний.
- Формат обмена правилами (RIF), структура диалектов языка веб-правил, поддерживающая обмен правилами в Интернете.
- Нотация объектов JavaScript для связанных данных (JSON-LD), метод описания данных на основе JSON.
- ActivityPub — универсальный способ взаимодействия клиента и сервера друг с другом. Это использует популярная децентрализованная социальная сеть Mastodon .
Стек семантической сети иллюстрирует архитектуру семантической сети. Функции и взаимоотношения компонентов можно резюмировать следующим образом: [28]
- XML предоставляет элементарный синтаксис для структуры контента в документах, но не связывает семантику со значением содержащегося в нем контента. XML в настоящее время не является необходимым компонентом технологий семантической паутины в большинстве случаев, поскольку существуют альтернативные синтаксисы, такие как Turtle . Turtle является стандартом де-факто, но не прошел формальный процесс стандартизации.
- XML-схема — это язык для предоставления и ограничения структуры и содержимого элементов, содержащихся в документах XML.
- RDF — это простой язык для выражения моделей данных , которые относятся к объектам (« веб-ресурсам ») и их отношениям. Модель на основе RDF может быть представлена в различных синтаксисах, например, RDF/XML , N3, Turtle и RDFa. RDF — это фундаментальный стандарт семантической сети. [29] [30]
- Схема RDF расширяет RDF и представляет собой словарь для описания свойств и классов ресурсов на основе RDF с семантикой для обобщенных иерархий таких свойств и классов.
- OWL добавляет больше словаря для описания свойств и классов: среди прочего, отношения между классами (например, непересекаемость), мощность (например, «точно один»), равенство, более богатая типизация свойств, характеристики свойств (например, симметрия) и перечислимые классы.
- SPARQL — это протокол и язык запросов для источников данных семантической сети.
- RIF — это формат обмена правилами W3C. Это язык XML для выражения веб-правил, которые могут выполнять компьютеры. RIF предоставляет несколько версий, называемых диалектами. Он включает в себя диалект базовой логики RIF (RIF-BLD) и диалект правил производства RIF (RIF PRD).
стандартизации состояние Текущее
Устоявшиеся стандарты:
- RDF — структура описания ресурсов
- RDFS — схема структуры описания ресурсов
- RIF — формат обмена правилами
- SPARQL — «Протокол SPARQL и язык запросов RDF»
- Юникод
- URI – универсальный идентификатор ресурса.
- OWL — язык веб-онтологий
- XML — расширяемый язык разметки
Еще не до конца реализовано:
- Объединение слоев логики и доказательства
- SWRL — язык правил семантической сети
Приложения [ править ]
Цель состоит в том, чтобы повысить удобство использования и полезность Интернета и связанных с ним ресурсов путем создания семантических веб-сервисов , таких как:
- Серверы, которые предоставляют существующие системы данных с использованием стандартов RDF и SPARQL. Существует множество конвертеров в RDF из разных приложений. [31] Реляционные базы данных являются важным источником. Семантический веб-сервер подключается к существующей системе, не влияя на ее работу.
- Документы, «размеченные» семантической информацией ( расширение HTML
<meta>теги, используемые на современных веб-страницах для предоставления информации поисковым системам, использующим веб-сканеры ). Это может быть понятная машине информация о понятном человеку содержании документа (например, создатель, название, описание и т. д.) или это могут быть чисто метаданные, представляющие набор фактов (например, ресурсы и услуги в других местах сайта). ). Обратите внимание: все , что можно идентифицировать с помощью универсального идентификатора ресурса (URI), можно описать, поэтому семантическая сеть может рассуждать о животных, людях, местах, идеях и т. д. В документах HTML можно использовать четыре формата семантических аннотаций; Микроформат, RDFa, микроданные и JSON-LD . [32] Семантическая разметка часто создается автоматически, а не вручную.

- Общие словари метаданных ( онтологии ) и карты между словарями, которые позволяют создателям документов знать, как размечать свои документы, чтобы агенты могли использовать информацию в предоставленных метаданных (так что Автор в смысле «Автор страницы» не будет следует путать с «Автором» в смысле книги, являющейся предметом рецензии на книгу).
- Автоматизированные агенты для выполнения задач для пользователей семантической сети с использованием этих данных.
- Семантический перевод . Альтернативным или дополнительным подходом являются улучшения контекстуального и семантического понимания текстов – этому можно помочь с помощью методов семантической сети, чтобы при ручном или полуавтоматическом постредактировании нужно было исправлять лишь все меньшее количество неправильных переводов .
- Веб-службы (часто с собственными агентами) для предоставления информации конкретно агентам, например, служба доверия , которую агент может запросить, если какой-либо интернет-магазин имеет историю плохого обслуживания или рассылки спама .
- Идеи семантической сети реализуются на сайтах совместного структурированного сопоставления аргументов , где их отношения организованы семантически, аргументы могут быть зеркально отображены (связаны) в нескольких местах, повторно использованы (копированы), оценены и изменены как семантически отдельные единицы. Идеи для такой или более широко распространенной «Всемирной паутины аргументов» появились как минимум в 2007 году. [33] и были в некоторой степени реализованы в Аргумане [34] и Киало . Дальнейшие шаги в направлении семантических веб-сервисов могут включать в себя включение «запросов», поисковых систем с аргументами, [35] и «подведение итогов спорных и согласованных моментов дискуссии». [36]
Такие услуги могут быть полезны для общедоступных поисковых систем или могут использоваться для управления знаниями внутри организации. Бизнес-приложения включают в себя:
- Содействие интеграции информации из смешанных источников [37]
- Устранение двусмысленностей в корпоративной терминологии
- Улучшение поиска информации , тем самым уменьшая информационную перегрузку и повышая точность и точность получаемых данных. [38] [39] [40] [41]
- Определение соответствующей информации относительно данного домена [42]
- Оказание поддержки в принятии решений
В корпорации существует закрытая группа пользователей, и руководство может обеспечивать соблюдение правил компании, таких как принятие определенных онтологий и использование семантических аннотаций . меньшие По сравнению с общедоступной семантической сетью требования к масштабируемости , и в целом информации, циркулирующей внутри компании, можно доверять больше; конфиденциальность не является проблемой, если не считать обработки данных клиентов.
реакции Скептические
Практическая осуществимость [ править ]
Критики подвергают сомнению принципиальную возможность полной или даже частичной реализации Семантической сети, указывая как на трудности ее настройки, так и на отсутствие универсальной полезности, которая не позволяет вложить необходимые усилия. В статье 2003 года Маршалл и Шипман отмечают когнитивные издержки, присущие формализации знаний по сравнению с созданием традиционного веб- гипертекста : [43]
Хотя изучение основ HTML относительно просто, изучение языка или инструмента представления знаний требует от автора изучения методов абстракции представления и их влияния на рассуждения. Например, понимание отношений класса-экземпляра или отношений суперкласса-подкласса — это нечто большее, чем понимание того, что одна концепция является «типом» другой концепции. [...] Эти абстракции преподаются ученым-компьютерщикам в целом и инженерам по знаниям в частности, но они не соответствуют аналогичному значению на естественном языке, когда речь идет о «типе» чего-либо. Эффективное использование такого формального представления требует от автора стать квалифицированным инженером по знаниям в дополнение к любым другим навыкам, требуемым в предметной области. [...] После того, как кто-то выучил формальный язык представления, часто приходится прилагать гораздо больше усилий для выражения идей в этом представлении, чем в менее формальном представлении [...]. Действительно, это форма программирования, основанная на объявлении семантических данных и требующая понимания того, как алгоритмы рассуждения будут интерпретировать созданные структуры.
По мнению Маршалла и Шипмана, неявная и изменяющаяся природа многих знаний усугубляет проблему инженерии знаний и ограничивает применимость семантической сети в конкретных областях. Еще одна проблема, на которую они указывают, — это способы выражения знаний, специфичные для предметной области или организации, которые должны быть решены посредством соглашения сообщества, а не только техническими средствами. [43] Как оказалось, специализированные сообщества и организации для внутрикорпоративных проектов имеют тенденцию применять семантические веб-технологии в большей степени, чем периферийные и менее специализированные сообщества. [44] Практические ограничения на пути внедрения оказались менее сложными там, где сфера применения и масштабы более ограничены, чем у широкой публики и Всемирной паутины. [44]
Наконец, Маршалл и Шипман видят прагматические проблемы в идее интеллектуальных агентов ( в стиле «Навигатора знаний »), работающих в семантической сети, курируемой в основном вручную: [43]
В ситуациях, когда потребности пользователей известны и распределенные информационные ресурсы хорошо описаны, этот подход может быть весьма эффективным; В непредвиденных ситуациях, которые объединяют неожиданный массив информационных ресурсов, подход Google оказывается более надежным. Более того, семантическая сеть опирается на более хрупкие цепочки вывода; недостающий элемент цепочки приводит к невозможности выполнить желаемое действие, в то время как человек может дополнить недостающие части, используя подход, более похожий на Google. [...] соотношение затрат и выгод может работать в пользу специально созданных метаданных семантической сети, направленных на объединение разумных, хорошо структурированных информационных ресурсов, специфичных для конкретной предметной области; Пристальное внимание к потребностям пользователей/заказчиков будет способствовать успеху этих федераций.
Кори Доктороу Критика (« метадерьмо ») [45] с точки зрения человеческого поведения и личных предпочтений. Например, люди могут включать в веб-страницы ложные метаданные, пытаясь ввести в заблуждение механизмы семантической паутины, которые наивно предполагают достоверность метаданных. Это явление было хорошо известно благодаря метатегам, которые обманом заставили алгоритм ранжирования Altavista повысить рейтинг определенных веб-страниц: индексирующая система Google специально выявляет такие попытки манипуляции. Питер Герденфорс и Тимо Хонкела отмечают, что основанные на логике технологии семантической сети охватывают лишь часть соответствующих явлений, связанных с семантикой. [46] [47]
и Цензура конфиденциальность
Энтузиазм по поводу семантической сети может быть умерен опасениями по поводу цензуры и конфиденциальности . Например, методы анализа текста теперь можно легко обойти, используя другие слова, например метафоры, или используя изображения вместо слов. Передовая реализация семантической сети значительно облегчила бы правительствам контроль над просмотром и созданием онлайн-информации, поскольку эту информацию было бы намного легче понять автоматической машине, блокирующей контент. Кроме того, также поднимался вопрос о том, что при использовании файлов FOAF и метаданных геолокации будет очень мало анонимности, связанной с авторством статей о таких вещах, как личный блог. Некоторые из этих проблем были решены в проекте «Policy Aware Web». [48] и является активной темой исследований и разработок.
Удвоение форматов вывода [ править ]
Другая критика семантической сети заключается в том, что создание и публикация контента потребует гораздо больше времени, поскольку для одного фрагмента данных потребуется два формата: один для просмотра людьми, а другой для машин. Однако многие разрабатываемые веб-приложения решают эту проблему путем создания машиночитаемого формата после публикации данных или запроса таких данных от машины. Одной из реакций на такого рода критику стало развитие микроформатов. Еще одним аргументом в защиту осуществимости семантической сети является вероятное падение цен на задачи человеческого интеллекта на цифровых рынках труда, таких как Amazon от Mechanical Turk . [ нужна ссылка ]
Такие спецификации, как eRDF и RDFa, позволяют встраивать произвольные данные RDF в страницы HTML. Механизм GRDDL (выбор описаний ресурсов из диалектов языка) позволяет автоматически интерпретировать существующие материалы (включая микроформаты) как RDF, поэтому издателям нужно использовать только один формат, например HTML.
Исследовательская деятельность по корпоративным приложениям [ править ]
Первой исследовательской группой, специально сосредоточившейся на корпоративной семантической сети, была команда ACACIA в INRIA-Sophia-Antipolis , основанная в 2002 году. Результаты их работы включают RDF(S) программу Corese. основанную на [49] поисковая система и применение технологии семантической сети в сфере распределенного искусственного интеллекта для управления знаниями (например, онтологии и многоагентные системы для корпоративной семантической сети) [50] и электронное обучение . [51]
С 2008 года исследовательская группа корпоративной семантической сети, расположенная в Свободном университете Берлина , занимается строительными блоками: корпоративным семантическим поиском, корпоративным семантическим сотрудничеством и разработкой корпоративной онтологии. [52]
Инженерные исследования онтологий включают в себя вопрос о том, как привлечь неопытных пользователей к созданию онтологий и семантически аннотированного контента. [53] и для извлечения явных знаний из взаимодействия пользователей внутри предприятий.
Будущее приложений [ править ]
Тим О'Рейли , придумавший термин Web 2.0, предложил долгосрочное видение семантической сети как сети данных, в которой сложные приложения перемещаются по ней и манипулируют ею. [54] Сеть данных преобразует Всемирную паутину из распределенной файловой системы в распределенную базу данных . [55]
См. также [ править ]
- РАНО
- Управление бизнес-семантикой
- Вычислительная семантика
- Кале (продукт Reuters)
- ДБпедия
- Модель сущность-атрибут-значение
- Портал открытых данных ЕС
- Гиперданные
- Интернет вещей
- Связанные данные
- Список новых технологий
- Следующаябио
- Выравнивание онтологии
- Обучение онтологии
- РДФ и СОВА
- Семантические вычисления
- Семантическая геопространственная сеть
- Семантическая неоднородность
- Семантическая интеграция
- Семантическое соответствие
- Семантика Медиавиики
- Семантическая сенсорная сеть
- Семантическая социальная сеть
- Семантическая технология
- Семантическая сеть
- Семантически связанные онлайн-сообщества
- Смарт-М3
- Социальная семантическая сеть
- Веб-инжиниринг
- Веб-ресурс
- Веб-наука
Ссылки [ править ]
- ^ Семантическая сеть в W3C: https://www.w3.org/standards/semanticweb/
- ^ «Консорциум World Wide Web (W3C), «Спецификация синтаксиса RDF/XML (пересмотренная)», 25 февраля 2014 г.» .
- ^ «Консорциум Всемирной паутины (W3C), «Обзор языка веб-онтологии OWL», рекомендация W3C, 10 февраля 2004 г.» .
- ^ Чунг, Сын Хва (2018). «Подход MOUSE: отображение онтологий с использованием UML для системных инженеров» . Журнал компьютерных обзоров : 8–29. ISSN 2581-6640 .
- ^ Jump up to: Перейти обратно: а б «Семантическая веб-активность W3C» . Консорциум Всемирной паутины (W3C). 7 ноября 2011 года . Проверено 26 ноября 2011 г.
- ^ «Вопросы и ответы с Тимом Бернерсом-Ли, специальный репортаж» . Блумберг . Проверено 14 апреля 2018 г.
- ^ Jump up to: Перейти обратно: а б Бернерс-Ли, Тим; Джеймс Хендлер; Ора Лассила (17 мая 2001 г.). «Семантическая сеть» . Научный американец . Проверено 2 июля 2019 г.
- ^ Ли Фейгенбаум (1 мая 2007 г.). «Семантическая сеть в действии» . Научный американец . Проверено 24 февраля 2010 г.
- ^ Бернерс-Ли, Тим ; Фишетти, Марк (1999). Плетение паутины . ХарперСанФранциско . глава 12 . ISBN 978-0-06-251587-2 .
- ^ Бернерс-Ли, Тим; Хендлер, Джеймс; Лассила, Ора (17 мая 2001 г.). «Семантическая сеть» (PDF) . Научный американец . Том. 284, нет. 5. С. 34–43. JSTOR 26059207 . S2CID 56818714 . Архивировано из оригинала (PDF) 10 октября 2017 года . Проверено 13 марта 2008 г.
- ^ Найджел Шедболт; Венди Холл; Тим Бернерс-Ли (2006). «Возвращение к семантической сети» (PDF) . Интеллектуальные системы IEEE . Архивировано из оригинала (PDF) 20 марта 2013 года . Проверено 13 апреля 2007 г.
- ^ Раманатан В. Гуха (2013). «Свет в конце туннеля» . Основной доклад Международной конференции по семантической сети 2013 . Проверено 8 марта 2015 г.
- ^ Олсопп, Джон (март 2007 г.). Микроформаты: расширение возможностей вашей разметки для Web 2.0 . Друзья ЭД . п. 368 . ISBN 978-1-59059-814-6 .
- ^ Артем Чеботко и Шийонг Лу, «Запросы в семантической сети: эффективный подход с использованием реляционных баз данных», LAP Lambert Academic Publishing , ISBN 978-3-8383-0264-5 , 2009 г.
- ^ «На пути к семантической сети: предложения по совместным тегам» (PDF) .
- ^ Специя, Люсия; Мотта, Энрико (2007). «Интеграция фольксономии с семантической сетью». Семантическая сеть: исследования и приложения . Конспекты лекций по информатике. Том. 4519. Спрингер. стр. 624–639. дои : 10.1007/978-3-540-72667-8_44 . ISBN 978-3-540-72666-1 .
- ^ «Преодоление разрыва между фолксономиями и семантической сетью: отчет об опыте» (PDF) .
- ^ Николсон, Джош М.; Мордаунт, Майло; Лопес, Патрис; Уппала, Ашиш; Розати, Доменик; Родригес, Невес П.; Грабиц, Питер; Райф, Шон К. (5 ноября 2021 г.). «scite: интеллектуальный индекс цитирования, который отображает контекст цитат и классифицирует их намерения с помощью глубокого обучения» . Количественные научные исследования . 2 (3): 882–898. дои : 10.1162/qss_a_00146 .
- ^ Сингх Чавла, Далмит (24 января 2022 г.). «Запуск массивного открытого индекса научных статей» . Природа . дои : 10.1038/d41586-022-00138-y . Проверено 14 февраля 2022 г.
- ^ «OpenAlex: многообещающая альтернатива Microsoft Academic Graph» . Сингапурский университет менеджмента (SMU) . Проверено 14 февраля 2022 г.
- ^ «Документация OpenAlex» . Проверено 18 февраля 2022 г.
- ^ Шеннон, Виктория (23 мая 2006 г.). «Более революционный» Интернет» . Интернэшнл Геральд Трибьюн . Проверено 26 июня 2006 г.
- ^ «Объяснение Web 3.0, плюс история Web 1.0 и 2.0» . Инвестопедия . Проверено 21 октября 2022 г.
- ^ «Обоснование неопределенности W3C для Всемирной паутины» . www.w3.org . Проверено 14 мая 2021 г.
- ^ «Обоснование неопределенности для Всемирной паутины» . W3.org . Проверено 20 декабря 2018 г.
- ^ Лукасевич, Томас; Умберто Страчча (2008). «Управление неопределенностью и расплывчатостью в логике описания семантической сети» (PDF) . Веб-семантика: наука, сервисы и агенты во Всемирной паутине . 6 (4): 291–308. дои : 10.1016/j.websem.2008.04.001 .
- ^ «Семантические веб-стандарты» . W3.org . Проверено 14 апреля 2018 г.
- ^ «Обзор языка веб-онтологии OWL» . Консорциум Всемирной паутины (W3C). 10 февраля 2004 года . Проверено 26 ноября 2011 г.
- ^ «Структура описания ресурсов (RDF)» . Консорциум Всемирной паутины .
- ^ Аллеманг, Дин; Хендлер, Джеймс; Гандон, Фабьен (3 августа 2020 г.). Семантическая сеть для рабочего онтолога: эффективное моделирование связанных данных, RDFS и OWL (Третье изд.). [Нью-Йорк, Нью-Йорк, США]: ACM Books; 3-е издание. ISBN 978-1450376143 .
- ^ «ConverterToRdf — W3C Wiki» . W3.org . Проверено 20 декабря 2018 г.
- ^ Сикос, Лесли Ф. (2015). Освоение структурированных данных в семантической сети: от микроданных HTML5 к связанным открытым данным . Апресс. п. 23. ISBN 978-1-4842-1049-9 .
- ^ Кизель, Йоханнес; Ланг, Кевин; Ваксмут, Хеннинг; Хорнекер, Ева; Штейн, Бенно (14 марта 2020 г.). «Исследование ожиданий от голосового и разговорного поиска аргументов в Интернете». Материалы конференции 2020 года по взаимодействию и поиску информации между людьми . АКМ. стр. 53–62. дои : 10.1145/3343413.3377978 . ISBN 9781450368926 . S2CID 212676751 .
- ^ Ветере, Гвидо (30 июня 2018 г.). «Невозможная необходимость децентрализованных социальных платформ». DigitCult — научный журнал о цифровых культурах . 3 (1): 41–50. дои : 10.4399/97888255159096 .
- ^ Бикакис, Антонис; Флорис, Гиоргос; Паткос, Теодор; Плексусакис, Димитрис (2023). «Очерк видения сети дебатов» . Границы искусственного интеллекта . 6 . дои : 10.3389/frai.2023.1124045 . ISSN 2624-8212 . ПМК 10313200 . ПМИД 37396970 .
- ^ Шнайдер, Джоди; Гроза, Тюдор; Пассан, Александр. «Обзор аргументации в пользу социальной семантической сети» (PDF) .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Чжан, Чуанжун; Чжао, Тянь; Ли, Вэйдун (2015). Геопространственная семантическая сеть . Springer International Publishing: Выходные данные: Springer. ISBN 978-3-319-17801-1 .
- ^ Омар Алонсо и Уго Сарагоса. 2008. Использование семантических аннотаций при поиске информации: ESAIR '08. Форум SIGIR 42, 1 (июнь 2008 г.), 55–58. дои : 10.1145/1394251.1394262
- ^ Яап Кампс, Юсси Карлгрен и Ральф Шенкель. 2011. Отчет о третьем семинаре по использованию семантических аннотаций в информационном поиске (ESAIR). Форум SIGIR 45, 1 (май 2011 г.), 33–41. дои : 10.1145/1988852.1988858
- ^ Яап Кампс, Юсси Карлгрен , Питер Мика и Ванесса Мердок. 2012. Пятый семинар по использованию семантических аннотаций в информационном поиске: ESAIR '12). В материалах 21-й международной конференции ACM по управлению информацией и знаниями (CIKM '12). ACM, Нью-Йорк, Нью-Йорк, США, 2772–2773. дои : 10.1145/2396761.2398761
- ^ Омар Алонсо, Яап Кампс и Юсси Карлгрен . 2015. Отчет о седьмом семинаре по использованию семантических аннотаций в информационном поиске (ESAIR '14). Форум SIGIR 49, 1 (июнь 2015 г.), 27–34. дои : 10.1145/2795403.2795412
- ^ Куриакосе, Джон (сентябрь 2009 г.). «Понимание и внедрение технологии семантической сети» . Каттер IT-журнал . 22 (9). ИНФОРМАЦИОННАЯ КОРП. КАТТЕРА: 10–18.
- ^ Jump up to: Перейти обратно: а б с Маршалл, Кэтрин С.; Шипман, Фрэнк М. (2003). Какая семантическая сеть? (PDF) . Учеб. Конференция АКМ. о гипертексте и гипермедиа. стр. 57–66. Архивировано из оригинала (PDF) 23 сентября 2015 г. Проверено 17 апреля 2015 г.
- ^ Jump up to: Перейти обратно: а б Иван Герман (2007). Состояние семантической сети (PDF) . Смысловые дни 2007 . Проверено 26 июля 2007 г.
- ^ Доктороу, Кори. «Метакрап: поджигаем семь подставных людей метаутопии» . www.well.com/ . Проверено 11 сентября 2023 г.
- ^ Герденфорс, Питер (2004). Как сделать семантическую сеть более семантической . ИОС Пресс. стр. 17–34.
{{cite book}}:|work=игнорируется ( помогите ) - ^ Хонкела, Тимо; Конёнен, Вилле; Линд-Кнуутила, Тиина; Пауккери, Мари-Санна (2008). «Моделирование процессов формирования понятий и коммуникации». Журнал экономической методологии . 15 (3): 245–259. дои : 10.1080/13501780802321350 . S2CID 16994027 .
- ^ «Веб-проект, учитывающий политику» . Policyawareweb.org . Проверено 14 июня 2013 г.
- ^ Корби, Оливье; Диенг-Кунц, Роуз; Цукер, Кэтрин Фарон; Гандон, Фабьен (2006). «Поиск в семантической сети: приблизительная обработка запросов на основе онтологий» . Интеллектуальные системы IEEE . 21 : 20–27. дои : 10.1109/MIS.2006.16 . S2CID 11488848 .
- ^ Гандон, Фабьен (7 ноября 2002 г.). Распределенный искусственный интеллект и управление знаниями: онтологии и многоагентные системы для корпоративной семантической сети (докторская диссертация). Университет Ниццы София-Антиполис.
- ^ Буффа, Мишель; Деор, Сильвен; Фарон-Цукер, Кэтрин; Сандер, Питер (2005). «На пути к корпоративному подходу семантической сети при проектировании систем обучения: обзор проекта пробных решений» (PDF) . Международный семинар по применению семантических веб-технологий для электронного обучения . Амстердам, Голландия. стр. 73–76.
- ^ «Корпоративный семантический веб — Главная» . Corporate-semantic-web.de . Проверено 14 апреля 2018 г.
- ^ Хинце, Анника; Хиз, Ральф; Лузак-Рёш, Маркус; Пашке, Адриан (2012). «Семантическое обогащение неспециалистами: удобство использования инструментов ручного аннотирования» (PDF) . ISWC'12 — Материалы 11-й международной конференции по The Semantic Web . Бостон, США. стр. 165–181.
- ^ Мэтисон, SA (6 апреля 2006 г.). «Распространите информацию и присоединяйтесь к ней» . Хранитель . Проверено 14 апреля 2018 г.
- ^ Спивак, Нова (18 сентября 2007 г.). «Семантическая сеть, коллективный разум и гиперданные» . novaspivack.typepad.com/nova_spivacks_weblog [Этот блог переехал на NovaSpivack.com] . Проверено 14 апреля 2018 г.
Дальнейшее чтение [ править ]
- Лиян Юй (14 декабря 2014 г.). Руководство разработчика по семантической сети, 2-е изд . Спрингер. ISBN 978-3-662-43796-4 .
- «Программируемая сеть» Аарона Шварца: незаконченная работа, подаренная издательством Morgan & Claypool Publishers после смерти Аарона Шварца в январе 2013 года.
- Григорис Антониу, Франк ван Хармелен (31 марта 2008 г.). Учебник по семантической сети, 2-е издание . Массачусетский технологический институт Пресс . ISBN 978-0-262-01242-3 .
- Аллеманг, Дин; Хендлер, Джеймс; Гандон, Фабьен (3 августа 2020 г.). Семантическая сеть для рабочего онтолога: эффективное моделирование связанных данных, RDFS и OWL (Третье изд.). [Нью-Йорк, Нью-Йорк, США]: ACM Books; 3-е издание. ISBN 978-1450376143 .
- Паскаль Хитцлер ; Маркус Крёч; Себастьян Рудольф (25 августа 2009 г.). Основы семантических веб-технологий . CRCPress. ISBN 978-1-4200-9050-5 .
- Томас Б. Пассен (1 марта 2004 г.). Руководство исследователя по семантической сети . Публикации Мэннинга. ISBN 978-1-932394-20-7 .
- Джеффри Т. Поллок (23 марта 2009 г.). Семантическая сеть для чайников . Для чайников. ISBN 978-0-470-39679-7 .
- Хитцлер, Паскаль (февраль 2021 г.). «Обзор поля семантической сети» . Коммуникации АКМ . 64 (2): 76–83. дои : 10.1145/3397512 .
- Унни, Дипак (март 2023 г.). «FAIRификация данных, связанных со здоровьем, с использованием семантических веб-технологий в Швейцарской сети персонализированного здоровья» . Научные данные . 10 (1): 127. Бибкод : 2023NatSD..10..127T . дои : 10.1038/s41597-023-02028-y . ПМЦ 10006404 . ПМИД 36899064 .