Структурное выравнивание
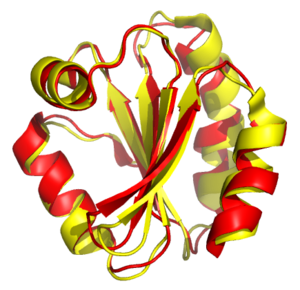
Структурное выравнивание пытается установить гомологию между двумя или более полимерными структурами на основе их формы и трехмерной конформации . Этот процесс обычно применяется к белков третичным структурам , но его также можно использовать для больших молекул РНК . В отличие от простой структурной суперпозиции, где известны по крайней мере некоторые эквивалентные остатки двух структур, структурное выравнивание не требует априорного знания эквивалентных положений. Структурное выравнивание является ценным инструментом для сравнения белков с низким сходством последовательностей, когда эволюционные отношения между белками не могут быть легко обнаружены с помощью стандартных методов выравнивания последовательностей . Таким образом, структурное выравнивание можно использовать для обозначения эволюционных отношений между белками, которые имеют очень мало общих последовательностей. Однако следует проявлять осторожность при использовании результатов в качестве доказательства общего эволюционного происхождения из-за возможных мешающих эффектов конвергентной эволюции , посредством которой множественные неродственные аминокислотные последовательности сходятся в общей третичной структуре .
Структурные выравнивания могут сравнивать две последовательности или несколько последовательностей . Поскольку эти выравнивания основаны на информации обо всех трехмерных конформациях последовательностей запроса, этот метод можно использовать только для последовательностей, где эти структуры известны. Обычно их обнаруживают с помощью рентгеновской кристаллографии или ЯМР-спектроскопии . Можно выполнить структурное выравнивание структур, созданных методами прогнозирования структуры . Действительно, оценка таких прогнозов часто требует структурного согласования модели и истинно известной структуры для оценки качества модели. [1] Структурные выравнивания особенно полезны при анализе данных структурной геномики и протеомики , и их можно использовать в качестве точек сравнения для оценки выравниваний, полученных методами биоинформатики, основанными исключительно на последовательностях . [2] [3] [4]
Результатом структурного выравнивания является суперпозиция наборов координат атомов и минимальное среднеквадратичное отклонение ( RMSD ) между структурами. СКО двух выровненных структур указывает на их расхождение друг от друга. Структурное выравнивание может быть осложнено существованием нескольких белковых доменов внутри одной или нескольких входных структур, поскольку изменения в относительной ориентации доменов между двумя выравниваемыми структурами могут искусственно увеличивать RMSD.
Данные, полученные путем структурного выравнивания
[ редактировать ]Минимальная информация, полученная в результате успешного структурного выравнивания, представляет собой набор остатков, которые считаются эквивалентными между структурами. Этот набор эквивалентностей затем обычно используется для наложения трехмерных координат для каждой входной структуры. (Обратите внимание, что один входной элемент может быть зафиксирован как ссылка, и поэтому его наложенные координаты не изменяются.) Подобранные структуры могут использоваться для расчета взаимных значений RMSD, а также других более сложных мер структурного сходства, таких как тест глобального расстояния. (ГДТ, [5] метрика, используемая в CASP ). Структурное выравнивание также подразумевает соответствующее одномерное выравнивание последовательностей , на основании которого можно рассчитать идентичность последовательностей или процент остатков, идентичных между входными структурами, как меру того, насколько тесно связаны две последовательности.
Виды сравнений
[ редактировать ]Поскольку белковые структуры состоят из аминокислот, которых боковые цепи связаны общей белковой основой, для создания структурного выравнивания и расчета соответствующих значений RMSD можно использовать ряд различных возможных подмножеств атомов, составляющих белковую макромолекулу. При выравнивании структур с очень разными последовательностями атомы боковой цепи обычно не принимаются во внимание, поскольку их идентичность различается для многих выровненных остатков. По этой причине в методах структурного выравнивания обычно по умолчанию используются только атомы основной цепи, включенные в пептидную связь . Для простоты и эффективности часто альфа-углерода рассматривают только положения , поскольку пептидная связь имеет минимально вариантную плоскую конформацию. Только когда структуры, подлежащие выравниванию, очень похожи или даже идентичны, имеет смысл выравнивать положения атомов боковой цепи, и в этом случае RMSD отражает не только конформацию основной цепи белка, но также ротамерные состояния боковых цепей. Другие критерии сравнения, которые уменьшают шум и поддерживают положительные совпадения, включают: присвоение вторичной структуры , карты нативных контактов или модели взаимодействия остатков, меры упаковки боковой цепи и меры удержания водородных связей . [6]
Структурная суперпозиция
[ редактировать ]Самое простое возможное сравнение белковых структур не предпринимает попыток выровнять входные структуры и требует предварительно рассчитанного выравнивания в качестве входных данных, чтобы определить, какие из остатков в последовательности следует учитывать при расчете RMSD. Структурная суперпозиция обычно используется для сравнения нескольких конформаций одного и того же белка (в этом случае выравнивание не требуется, поскольку последовательности одинаковы) и для оценки качества выравнивания, полученного с использованием только информации о последовательностях между двумя или более последовательностями, структуры которых известны. . Этот метод традиционно использует простой алгоритм подбора методом наименьших квадратов, в котором оптимальные вращения и перемещения находятся путем минимизации суммы квадратов расстояний между всеми структурами в суперпозиции. [7] Совсем недавно методы максимального правдоподобия и байесовские методы значительно повысили точность оценок поворотов, сдвигов и ковариационных матриц для суперпозиции. [8] [9]
Алгоритмы, основанные на многомерных вращениях и модифицированных кватернионах, были разработаны для определения топологических связей между белковыми структурами без необходимости заранее определенного выравнивания. Такие алгоритмы успешно идентифицировали канонические складки, такие как расслоение из четырех спиралей . [10] Метод SuperPose достаточно расширяем, чтобы корректировать относительное вращение доменов и другие структурные ошибки. [11]
Оценка сходства
[ редактировать ]Часто целью поиска структурной суперпозиции является не столько сама суперпозиция, сколько оценка сходства двух структур или уверенность в удаленном совпадении. [1] [2] [3] Тонким, но важным отличием от максимальной структурной суперпозиции является преобразование выравнивания в значимую оценку сходства. [12] [13] Большинство методов выводят своего рода «оценку», указывающую качество суперпозиции. [5] [14] [15] [12] [13] Однако на самом деле человек хочет не просто оценить «Z-показатель» или предполагаемое значение E, возникающее при случайном наблюдении наблюдаемой суперпозиции, но вместо этого человек желает, чтобы оцененное значение E тесно коррелировало с истинным значением E. Крайне важно, что даже если оценочное E-значение метода в среднем точно верно , если ему не хватает низкого стандартного отклонения в процессе генерации оценочного значения, тогда ранговое упорядочение относительного сходства исследуемого белка с набором сравнения редко будет согласовываться с «истинный» порядок. [12] [13]
Различные методы будут накладывать разное количество остатков, поскольку они используют разные гарантии качества и разные определения «перекрытия»; некоторые включают только остатки, соответствующие множеству локальных и глобальных критериев суперпозиции, а другие более жадные, гибкие и неразборчивые. Большее количество наложенных друг на друга атомов может означать большее сходство, но оно не всегда может давать лучшее значение E, количественно определяющее маловероятность суперпозиции, и, следовательно, не так полезно для оценки сходства, особенно у отдаленных гомологов. [1] [2] [3] [4]
Алгоритмическая сложность
[ редактировать ]Оптимальное решение
[ редактировать ]Было показано, что оптимальное « нанизывание » белковой последовательности на известную структуру и достижение оптимального множественного выравнивания последовательностей являются NP-полными . [16] [17] Однако это не означает, что проблема структурного выравнивания является NP-полной. Строго говоря, оптимальное решение проблемы выравнивания структуры белка известно только для определенных показателей сходства структуры белка, таких как меры, используемые в экспериментах по предсказанию структуры белка, GDT_TS. [5] и МаксСуб. [14] Эти меры можно строго оптимизировать с помощью алгоритма, способного максимизировать количество атомов в двух белках, которые могут быть наложены друг на друга при заранее определенном расстоянии. [15] К сожалению, алгоритм оптимального решения непрактичен, поскольку время его работы зависит не только от длины, но и от внутренней геометрии входных белков.
Примерное решение
[ редактировать ]Были разработаны приближенные алгоритмы структурного выравнивания с полиномиальным временем , которые создают семейство «оптимальных» решений в пределах параметра аппроксимации для заданной оценочной функции. [15] [18] Хотя эти алгоритмы теоретически классифицируют задачу приблизительного выравнивания структуры белка как «разрешимую», они по-прежнему слишком дороги в вычислительном отношении для крупномасштабного анализа структуры белка. Как следствие, практических алгоритмов, которые сходятся к глобальным решениям выравнивания с учетом оценочной функции, не существует. Таким образом, большинство алгоритмов являются эвристическими, но были разработаны практические алгоритмы, которые гарантируют сходимость, по крайней мере, к локальным максимизаторам скоринговых функций. [19]
Представление структур
[ редактировать ]Белковые структуры должны быть представлены в каком-то координатно-независимом пространстве, чтобы их можно было сравнивать. Обычно это достигается путем построения матрицы последовательностей или серии матриц, которые охватывают сравнительные показатели, а не абсолютные расстояния относительно фиксированного координатного пространства. Интуитивное представление — это матрица расстояний , которая представляет собой двумерную матрицу, содержащую все попарные расстояния между некоторым подмножеством атомов в каждой структуре (например, альфа-углеродами ). Размерность матрицы увеличивается по мере увеличения количества структур, подлежащих одновременному выравниванию. Сведение белка к грубой метрике, такой как элементы вторичной структуры (SSE) или структурные фрагменты, также может привести к разумному выравниванию, несмотря на потерю информации из-за отбрасывания расстояний, поскольку шум также отбрасывается. [20] Выбор представления для облегчения вычислений имеет решающее значение для разработки эффективного механизма выравнивания.
Методы
[ редактировать ]Методы структурного выравнивания использовались при сравнении отдельных структур или наборов структур, а также при создании баз данных сравнения «все со всеми», которые измеряют расхождение между каждой парой структур, присутствующих в Банке данных белков (PDB). Такие базы данных используются для классификации белков по их складчатости .
легкость
[ редактировать ]
Распространенным и популярным методом структурного выравнивания является метод DALI, или метод Distance-matrix ALIgnment, который разбивает входные структуры на гексапептидные фрагменты и вычисляет матрицу расстояний путем оценки моделей контактов между последовательными фрагментами. [21] Особенности вторичной структуры матрицы , включающие смежные по порядку остатки, появляются на главной диагонали ; остальные диагонали в матрице отражают пространственные контакты между остатками, не расположенными рядом друг с другом в последовательности. Когда эти диагонали параллельны главной диагонали, объекты, которые они представляют, параллельны; когда они перпендикулярны, их элементы антипараллельны. Это представление требует большого объема памяти, поскольку элементы квадратной матрицы симметричны (и, следовательно, избыточны) относительно главной диагонали.
Когда матрицы расстояний двух белков имеют одинаковые или схожие характеристики примерно в одних и тех же положениях, можно сказать, что они имеют одинаковые складки с петлями одинаковой длины, соединяющими элементы их вторичной структуры. Фактический процесс выравнивания DALI требует поиска сходства после построения матриц расстояний двух белков; обычно это осуществляется с помощью серии перекрывающихся подматриц размером 6x6. Затем совпадения подматриц снова собираются в окончательное выравнивание с помощью стандартного алгоритма максимизации оценок — исходная версия DALI использовала моделирование Монте-Карло для максимизации показателя структурного сходства, который является функцией расстояний между предполагаемыми соответствующими атомами. В частности, более удаленные атомы внутри соответствующих элементов экспоненциально уменьшаются, чтобы уменьшить влияние шума, вызванного подвижностью петли, кручением спирали и другими незначительными структурными изменениями. [20] Поскольку DALI опирается на матрицу расстояний «все ко всем», он может учитывать возможность того, что структурно выровненные объекты могут появляться в разных порядках в двух сравниваемых последовательностях.
Метод DALI также использовался для создания базы данных, известной как FSSP (складчатая классификация, основанная на выравнивании структуры и структуры белков или семейств структурно сходных белков), в которой все известные белковые структуры выровнены друг с другом для определения их структурных соседей и классификация складок. Существует база данных с возможностью поиска на основе DALI, а также загружаемая программа и веб-поиск на основе отдельной версии, известной как DaliLite.
Комбинаторное расширение
[ редактировать ]Метод комбинаторного расширения (CE) аналогичен DALI тем, что он также разбивает каждую структуру в наборе запросов на ряд фрагментов, которые затем пытается собрать в полное соответствие. Серия попарных комбинаций фрагментов, называемых парами выровненных фрагментов или AFP, используется для определения матрицы сходства, с помощью которой генерируется оптимальный путь для определения окончательного выравнивания. В матрицу включаются только те AFP, которые соответствуют заданным критериям локального сходства, что позволяет сократить необходимое пространство поиска и тем самым повысить эффективность. [22] Возможен ряд показателей сходства; Первоначальное определение метода CE включало только структурные суперпозиции и расстояния между остатками, но с тех пор было расширено и теперь включает локальные свойства окружающей среды, такие как вторичная структура, воздействие растворителя, характер водородных связей и двугранные углы . [22]
Путь выравнивания рассчитывается как оптимальный путь через матрицу сходства путем линейного продвижения по последовательностям и расширения выравнивания со следующей возможной парой AFP с высоким рейтингом. Исходная пара AFP, которая закладывает основу выравнивания, может возникнуть в любой точке матрицы последовательности. Затем расширения переходят к следующему AFP, который соответствует заданным критериям расстояния, ограничивающим выравнивание небольшими размерами зазоров. Размер каждого AFP и максимальный размер зазора являются обязательными входными параметрами, но обычно для них устанавливаются эмпирически определенные значения 8 и 30 соответственно. [22] Подобно DALI и SSAP, CE использовался для создания базы данных классификации кратности «все ко всем». Архивировано 3 декабря 1998 г. в Wayback Machine на основе известных белковых структур в PDB.
RCSB PDB недавно выпустил обновленную версию CE, Mammoth и FATCAT как часть инструмента сравнения белков RCSB PDB . Он представляет собой новый вариант CE, который может обнаруживать круговые перестановки в белковых структурах. [23]
Мамонт
[ редактировать ]МАМОНТ [12] подходит к проблеме выравнивания с другой целью, чем почти все другие методы. Вместо того, чтобы пытаться найти выравнивание, которое максимально перекрывает наибольшее количество остатков, он ищет подмножество структурного выравнивания, которое с наименьшей вероятностью произойдет случайно. Для этого он отмечает выравнивание локальных мотивов флажками, указывающими, какие остатки одновременно удовлетворяют более строгим критериям: 1) перекрытие локальных структур 2) регулярная вторичная структура 3) 3D-суперпозиция 4) одинаковый порядок в первичной последовательности. Он преобразует статистику количества остатков с совпадениями с высокой степенью достоверности и размера белка, чтобы случайно вычислить значение ожидания для результата. Он превосходно подходит для сопоставления удаленных гомологов, особенно структур, созданных путем предсказания структуры ab initio, с семействами структур, такими как SCOP, поскольку он делает упор на извлечение статистически надежного субвыравнивания, а не на достижение максимального выравнивания последовательностей или максимальной трехмерной суперпозиции. [2] [3]
Для каждого перекрывающегося окна из 7 последовательных остатков он вычисляет набор единичных векторов направления смещения между соседними остатками C-альфа. Локальные мотивы «все против всех» сравниваются на основе оценки URMS. Эти значения становятся записями оценки парного выравнивания для динамического программирования, которое производит начальное парное выравнивание остатков. На втором этапе используется модифицированный алгоритм MaxSub: одна выровненная пара из 7 резидентов в каждом белке используется для ориентации двух полноразмерных белковых структур так, чтобы максимально наложить эти 7 C-альфа, затем в этой ориентации он сканирует любые дополнительные выровненные пары. которые близки в 3D. Он переориентирует структуры для наложения этого расширенного набора и выполняет итерации до тех пор, пока в 3D больше не перестанут совпадать пары. Этот процесс перезапускается для каждого 7-го окна остатков в выравнивании семян. Результатом является максимальное количество атомов, найденное из любого из этих начальных начальных чисел. Эта статистика преобразуется в калиброванное значение E для сходства белков.
Mammoth не пытается повторить первоначальное выравнивание или расширить подмножество высокого качества. Следовательно, отображаемое начальное выравнивание нельзя справедливо сравнивать с выравниванием DALI или TM, поскольку оно было сформировано просто как эвристика для сокращения пространства поиска. (Его можно использовать, если требуется выравнивание, основанное исключительно на локальном сходстве структурных мотивов, независимом от выравнивания атомов твердого тела на больших расстояниях.) Из-за той же экономии оно значительно более чем в десять раз быстрее, чем DALI, CE и TM-выравнивание. [24] Его часто используют в сочетании с этими более медленными инструментами для предварительного просмотра больших баз данных с целью извлечения только лучших структур, связанных с E-значением, для более исчерпывающей суперпозиции или дорогостоящих вычислений. [25] [26]
Он оказался особенно успешным при анализе структур-ловушек на основе предсказания структуры ab initio. [1] [2] [3] Эти приманки печально известны тем, что обеспечивают правильную структуру мотива локального фрагмента и формируют некоторые ядра правильной трехмерной третичной структуры, но неправильно получают полноразмерную третичную структуру. В этом сумеречном режиме удаленной гомологии e-значения Мамонта для CASP [1] Было показано, что оценка прогнозирования структуры белка значительно больше коррелирует с рангом человека, чем SSAP или DALI. [12] Способность Mammoths извлекать частичные перекрытия по множеству критериев с белками известной структуры и ранжировать их по соответствующим E-значениям в сочетании с его скоростью облегчает сканирование огромного количества моделей-ловушек в базе данных PDB для идентификации наиболее вероятных правильных ловушек на основе их отдаленная гомология с известными белками. [2]
ССАП
[ редактировать ]Метод SSAP (Программа последовательного выравнивания структур) использует двойное динамическое программирование атом-атом для создания структурного выравнивания на основе векторов в структурном пространстве. Вместо альфа-углеродов, обычно используемых для структурного выравнивания, SSAP конструирует свои векторы из бета-углеродов для всех остатков, кроме глицина, метод, который, таким образом, учитывает ротамерное состояние каждого остатка, а также его расположение вдоль основной цепи. SSAP работает, сначала создавая серию векторов расстояний между остатками между каждым остатком и его ближайшими несмежными соседями в каждом белке. Затем строится серия матриц, содержащая векторные различия между соседями для каждой пары остатков, для которых были построены векторы. Динамическое программирование, применяемое к каждой результирующей матрице, определяет ряд оптимальных локальных согласований, которые затем суммируются в «сводную» матрицу, к которой снова применяется динамическое программирование для определения общего структурного согласования.
Изначально SSAP создавал только парные выравнивания, но с тех пор был расширен и до множественных выравниваний. [27] Он был применен по принципу «все ко всем» для создания иерархической схемы классификации, известной как CATH (класс, архитектура, топология, гомология). [28] который использовался для создания базы данных классификации структуры белков CATH .
Последние события
[ редактировать ]Совершенствование методов структурного выравнивания представляет собой активную область исследований, и часто предлагаются новые или модифицированные методы, которые, как утверждается, имеют преимущества по сравнению со старыми и более широко распространенными методами. В недавнем примере, TM-align, используется новый метод взвешивания матрицы расстояний, к которому стандартное динамическое программирование . затем применяется [29] [13] Взвешивание предлагается для ускорения сходимости динамического программирования и корректировки эффектов, возникающих из-за длины выравнивания. В сравнительном исследовании сообщалось, что TM-align улучшает скорость и точность по сравнению с DALI и CE. [29]
Другими многообещающими методами структурного выравнивания являются методы локального структурного выравнивания. Они обеспечивают сравнение предварительно выбранных частей белков (например, сайтов связывания, определенных пользователем структурных мотивов). [30] [31] [32] против сайтов связывания или структурных баз данных цельных белков. Серверы MultiBind и MAPPIS [32] [33] позволяют идентифицировать общие пространственные расположения физико-химических свойств, таких как донорные, акцепторные, алифатические, ароматические или гидрофобные Н-связи, в наборе сайтов связывания белков, предоставленных пользователем и определяемых взаимодействиями с небольшими молекулами (MultiBind), или в наборе предоставленных пользователем сайтов связывания белков. белок-белковые интерфейсы (MAPPIS). Другие обеспечивают сравнение целых белковых структур. [34] против ряда представленных пользователем структур или против большой базы данных белковых структур в разумные сроки ( ProBiS [35] ). В отличие от подходов глобального выравнивания, подходы локального структурного выравнивания подходят для обнаружения локально консервативных паттернов функциональных групп, которые часто появляются в сайтах связывания и существенно участвуют в связывании лигандов. [33] В качестве примера, сравнивая G-Losa, [36] инструмент выравнивания локальной структуры с TM-align, методом, основанным на глобальном выравнивании структуры. Хотя G-Losa предсказывает положение лекарствоподобных лигандов в одноцепочечных белках-мишенях более точно, чем TM-align, общий показатель успеха TM-align лучше. [37]
Однако по мере того, как усовершенствования алгоритмов и производительность компьютеров устранили чисто технические недостатки старых подходов, стало ясно, что не существует единого универсального критерия «оптимального» структурного выравнивания. TM-align, например, особенно надежен при количественном сравнении наборов белков с большими различиями в длинах последовательностей, но он лишь косвенно фиксирует водородные связи или сохранение порядка вторичной структуры, которые могут быть лучшими показателями для выравнивания эволюционно родственных белков. Таким образом, недавние разработки были сосредоточены на оптимизации определенных атрибутов, таких как скорость, количественная оценка оценок, корреляция с альтернативными золотыми стандартами или терпимость к несовершенству структурных данных или структурных моделей ab initio. Альтернативная методология, которая набирает популярность, заключается в использовании консенсуса различных методов для установления структурного сходства белков. [38]
Этот раздел нуждается в дополнении: добавьте обсуждение следующих тем: A) гибкое выравнивание по сравнению с жестким телом B) зависимое от порядка последовательности и независимое C) выравнивание биологических сборок [39] . Вы можете помочь, добавив к нему . ( июль 2012 г. ) |
Структурное выравнивание РНК
[ редактировать ]Методы структурного выравнивания традиционно применялись исключительно к белкам как к первичным биологическим макромолекулам , принимающим характерные трехмерные структуры. Однако большие молекулы РНК также образуют характерные третичные структуры , которые опосредуются в первую очередь водородными связями, образующимися между парами оснований , а также укладкой оснований . Функционально сходные некодирующие молекулы РНК может быть особенно трудно выделить из данных геномики, поскольку структура более консервативна, чем последовательность, как в РНК, так и в белках. [40] а более ограниченный алфавит РНК уменьшает информационное содержание любого данного нуклеотида в любой заданной позиции.
Однако из-за растущего интереса к структурам РНК и роста числа экспериментально определенных трехмерных структур РНК в последнее время разработано мало методов сходства структур РНК. Одним из таких методов является, например, SETTER. [41] который разлагает каждую структуру РНК на более мелкие части, называемые единицами общей вторичной структуры (GSSU). GSSU впоследствии выравниваются, и эти частичные выравнивания объединяются с окончательным выравниванием структуры РНК и оцениваются. Метод реализован в веб-сервере SETTER . [42]
Недавно опубликован и реализован в программе FOLDALIGN недавний метод попарного структурного выравнивания последовательностей РНК с низкой идентичностью последовательностей . [43] Однако этот метод не является настоящим аналогом методов структурного выравнивания белков, поскольку он вычислительно предсказывает структуры входных последовательностей РНК, а не требует экспериментально определенных структур в качестве входных данных. Хотя вычислительное предсказание процесса сворачивания белка на сегодняшний день не является особенно успешным, структуры РНК без псевдоузлов часто можно разумно предсказать с использованием методов подсчета, основанных на свободной энергии , которые учитывают спаривание и укладку оснований. [44]
Программное обеспечение
[ редактировать ]Выбор программного инструмента для структурного выравнивания может оказаться непростой задачей из-за большого разнообразия доступных пакетов, которые существенно различаются по методологии и надежности. Частичное решение этой проблемы было представлено в [38] и стал общедоступным через веб-сервер ProCKSI. Более полный список доступного в настоящее время и свободно распространяемого программного обеспечения для структурного выравнивания можно найти в разделе « Программное обеспечение для структурного выравнивания» .
Свойства некоторых серверов структурного выравнивания и пакетов программного обеспечения обобщены и протестированы на примерах в разделе Structural Alignment Tools на Proteopedia.Org .
См. также
[ редактировать ]Ссылки
[ редактировать ]- ^ Перейти обратно: а б с д и Крыштафович А, Монастырский Б, Фиделис К (2016). «Статистика CASP11 и система оценки центра прогнозирования» . Белки . 84 (Приложение 1): (Приложение 1): 15–19. дои : 10.1002/прот.25005 . ПМЦ 5479680 . ПМИД 26857434 .
- ^ Перейти обратно: а б с д и ж Ларс Мальмстрем Майкл Риффл; Чарли Э.М. Штраусс; Дилан Чивиан; Триша Н. Дэвис; Ричард Бонно; Дэвид Бейкер (2007). «Назначение суперсемейства дрожжевого протеома посредством интеграции прогнозирования структуры с онтологией генов» . ПЛОС Биол . 5 (4): e76, соответствующий автор1, 2. doi : 10.1371/journal.pbio.0050076 . ПМЦ 1828141 . ПМИД 17373854 .
- ^ Перейти обратно: а б с д и Дэвид Э. Ким; Дилан Чивиан; Дэвид Бейкер (2004). «Предсказание и анализ структуры белка с использованием сервера Robetta» . Исследования нуклеиновых кислот . 32 (проблема с веб-сервером): W526–W531 (проблема с веб-сервером): W526–W531. дои : 10.1093/nar/gkh468 . ПМК 441606 . ПМИД 15215442 .
- ^ Перейти обратно: а б Чжан Ю, Сколник Дж (2005). «Проблема предсказания структуры белка может быть решена с использованием текущей библиотеки PDB» . Proc Natl Acad Sci США . 102 (4): 1029–34. Бибкод : 2005PNAS..102.1029Z . дои : 10.1073/pnas.0407152101 . ПМЦ 545829 . ПМИД 15653774 .
- ^ Перейти обратно: а б с Земля А. (2003). «LGA — метод поиска трехмерных сходств в белковых структурах» . Исследования нуклеиновых кислот . 31 (13): 3370–3374. дои : 10.1093/nar/gkg571 . ПМК 168977 . ПМИД 12824330 .
- ^ Годзик А (1996). «Структурное соответствие между двумя белками: есть ли уникальный ответ?» . Белковая наука . 5 (7): 1325–38. дои : 10.1002/pro.5560050711 . ПМК 2143456 . ПМИД 8819165 .
- ^ Мартин АКР (1982). «Быстрое сравнение белковых структур». Акта Кристаллогр А. 38 (6): 871–873. Бибкод : 1982AcCrA..38..871M . дои : 10.1107/S0567739482001806 .
- ^ Теобальд Д.Л., Вуттке Д.С. (2006). «Эмпирические байесовские иерархические модели для регуляризации оценки максимального правдоподобия в матричной гауссовской задаче Прокруста» . Труды Национальной академии наук . 103 (49): 18521–18527. Бибкод : 2006PNAS..10318521T . дои : 10.1073/pnas.0508445103 . ПМЦ 1664551 . ПМИД 17130458 .
- ^ Теобальд Д.Л., Вуттке Д.С. (2006). «ТЕЗЕЙ: Суперпозиция максимального правдоподобия и анализ макромолекулярных структур» . Биоинформатика . 22 (17): 2171–2172. doi : 10.1093/биоинформатика/btl332 . ПМЦ 2584349 . ПМИД 16777907 .
- ^ Дидерихс К. (1995). «Структурная суперпозиция белков с неизвестным выравниванием и обнаружение топологического сходства с использованием алгоритма шестимерного поиска» . Белки . 23 (2): 187–95. дои : 10.1002/прот.340230208 . ПМИД 8592700 . S2CID 3469775 .
- ^ Маити Р., Ван Домселар Г.Х., Чжан Х., Вишарт Д.С. (2004). «SuperPose: простой сервер для сложной структурной суперпозиции» . Нуклеиновые кислоты Рез . 32 (проблема с веб-сервером): W590–4. дои : 10.1093/nar/gkh477 . ПМК 441615 . ПМИД 15215457 .
- ^ Перейти обратно: а б с д и Ортис, Арканзас; Штраус CE; Олмеа О. (2002). «МАМОНТ (сопоставление молекулярных моделей, полученных из теории): автоматизированный метод сравнения моделей» . Белковая наука . 11 (11): 2606–2621. дои : 10.1110/ps.0215902 . ПМЦ 2373724 . ПМИД 12381844 .
- ^ Перейти обратно: а б с д Чжан Ю, Сколник Дж (2004). «Функция оценки для автоматической оценки качества шаблона структуры белка». Белки . 57 (4): 702–710. дои : 10.1002/прот.20264 . ПМИД 15476259 . S2CID 7954787 .
- ^ Перейти обратно: а б Сью Н., Элофссон А., Рыхлевск Л., Фишер Д. (2000). «MaxSub: автоматизированная мера оценки качества прогнозирования структуры белков» . Биоинформатика . 16 (9): 776–85. дои : 10.1093/биоинформатика/16.9.776 . ПМИД 11108700 .
- ^ Перейти обратно: а б с Полексич А (2009). «Алгоритмы оптимального выравнивания структуры белка» . Биоинформатика . 25 (21): 2751–2756. doi : 10.1093/биоинформатика/btp530 . ПМИД 19734152 .
- ^ Латроп Р.Х. (1994). «Проблема объединения белков с предпочтениями взаимодействия аминокислотных последовательностей является NP-полной». Белок англ . 7 (9): 1059–68. CiteSeerX 10.1.1.367.9081 . дои : 10.1093/белок/7.9.1059 . ПМИД 7831276 .
- ^ Ван Л., Цзян Т. (1994). «О сложности множественного выравнивания последовательностей». Журнал вычислительной биологии . 1 (4): 337–48. CiteSeerX 10.1.1.408.894 . дои : 10.1089/cmb.1994.1.337 . ПМИД 8790475 .
- ^ Колодный Р., Линиал Н. (2004). «Приблизительное структурное выравнивание белка за полиномиальное время» . ПНАС . 101 (33): 12201–12206. дои : 10.1073/pnas.0404383101 . ПМК 514457 . ПМИД 15304646 .
- ^ Мартинес Л., Андреани Р., Мартинес Х.М. (2007). «Конвергентные алгоритмы структурного выравнивания белков» . БМК Биоинформатика . 8 : 306. дои : 10.1186/1471-2105-8-306 . ЧВК 1995224 . ПМИД 17714583 .
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Перейти обратно: а б Крепление ДМ. (2004). Биоинформатика: анализ последовательностей и генома 2-е изд. Лабораторный пресс Колд-Спринг-Харбор: Колд-Спринг-Харбор, Нью-Йорк ISBN 0879697121
- ^ Холм Л., Сандер С. (1996). «Картирование белковой вселенной». Наука . 273 (5275): 595–603. Бибкод : 1996Sci...273..595H . дои : 10.1126/science.273.5275.595 . ПМИД 8662544 . S2CID 7509134 .
- ^ Перейти обратно: а б с Шиндялов И.Н.; Борн ЧП (1998). «Выравнивание структуры белка путем постепенного комбинаторного расширения (CE) оптимального пути» . Белковая инженерия . 11 (9): 739–747. дои : 10.1093/протеин/11.9.739 . ПМИД 9796821 .
- ^ Прлик А., Бливен С., Роуз П.В., Блюм В.Ф., Бизон С., Годзик А., Борн П.Е. (2010). «Предварительно рассчитанное выравнивание структуры белка на веб-сайте RCSB PDB» . Биоинформатика . 26 (23): 2983–2985. doi : 10.1093/биоинформатика/btq572 . ПМК 3003546 . ПМИД 20937596 .
- ^ Пин-Хао Чи; Бин Панг; Дмитрий Коркин; Чи-Рен Шю (2009). «Эффективная классификация и поиск по SCOP-фолдам с использованием индексного выравнивания белковых субструктур» . Биоинформатика . 25 (19): 2559–2565. doi : 10.1093/биоинформатика/btp474 . ПМИД 19667079 .
- ^ Сара Чик; Юань Ци; Шри Кришна; Лиза Н. Кинч; Ник В. Гришин (2004). «SCOPmap: Автоматизированное отнесение белковых структур к эволюционным суперсемействам» . БМК Биоинформатика . 5 (197): 197. дои : 10.1186/1471-2105-5-197 . ПМЦ 544345 . ПМИД 15598351 .
- ^ Кай Ван; Рам Самудрала (2005). «FSSA: новый метод идентификации функциональных сигнатур на основе структурных согласований» . Биоинформатика . 21 (13): 2969–2977. doi : 10.1093/биоинформатика/bti471 . ПМИД 15860561 .
- ^ Тейлор В.Р., Флорес Т.П., Оренго, Калифорния (1994). «Множественное выравнивание белковых структур» . Белковая наука . 3 (10): 1858–70. дои : 10.1002/pro.5560031025 . ПМК 2142613 . ПМИД 7849601 .
- ^ Оренго Калифорния, Мичи А.Д., Джонс С., Джонс Д.Т., Суинделлс М.Б., Торнтон Дж.М. (1997). «CATH: Иерархическая классификация структур белковых доменов» . Структура . 5 (8): 1093–1108. дои : 10.1016/S0969-2126(97)00260-8 . ПМИД 9309224 .
- ^ Перейти обратно: а б Чжан Ю, Сколник Дж (2005). «TM-align: алгоритм выравнивания структуры белка, основанный на TM-оценке» . Исследования нуклеиновых кислот . 33 (7): 2302–2309. дои : 10.1093/nar/gki524 . ПМЦ 1084323 . ПМИД 15849316 .
- ^ Стефано Ангаран; Мэри Эллен Бок ; Клаудио Гарутти; Кончеттина Герра1 (2009). «MolLoc: веб-инструмент для локального структурного выравнивания молекулярных поверхностей» . Исследования нуклеиновых кислот . 37 (проблема с веб-сервером): W565–70. дои : 10.1093/нар/gkp405 . ПМЦ 2703929 . ПМИД 19465382 .
{{cite journal}}: CS1 maint: числовые имена: список авторов ( ссылка ) - ^ Гаэль Дебре; Арно Мартель; Филипп Кюниасс (2009). «РАСМОТ-3D PRO: веб-сервер поиска 3D-мотивов» . Исследования нуклеиновых кислот . 37 (проблема с веб-сервером): W459–64. дои : 10.1093/нар/gkp304 . ПМК 2703991 . ПМИД 19417073 .
- ^ Перейти обратно: а б Александра Шульман-Пелег; Максим Шацкий; Рут Нусинов; Хаим Дж. Вольфсон (2008). «MultiBind и MAPPIS: веб-серверы для множественного выравнивания сайтов 3D-связывания белков и их взаимодействия» . Исследования нуклеиновых кислот . 36 (проблема с веб-сервером): W260–4. дои : 10.1093/нар/gkn185 . ПМК 2447750 . ПМИД 18467424 .
- ^ Перейти обратно: а б Александра Шульман-Пелег; Максим Шацкий; Рут Нусинов; Хаим Дж. Вольфсон (2007). «Пространственное химическое сохранение взаимодействий горячих точек в белково-белковых комплексах» . БМК Биология . 5 (43): 43. дои : 10.1186/1741-7007-5-43 . ПМК 2231411 . ПМИД 17925020 .
- ^ Габриэле Осиелло; Пьер Федерико Герардини; Паоло Маркатили; Анна Трамонтано; Аллегра Виа; Мануэла Хельмер-Циттерих (2008). «FunClust: веб-сервер для идентификации структурных мотивов в наборе негомологичных белковых структур» . БМК Биология . 9 (Приложение 2): S2. дои : 10.1186/1471-2105-9-S2-S2 . ПМК 2323665 . ПМИД 18387204 .
- ^ Янез Конц; Душанка Янежич (2010). «Алгоритм ProBiS для обнаружения структурно сходных сайтов связывания белков путем локального структурного выравнивания» . Биоинформатика . 26 (9): 1160–1168. doi : 10.1093/биоинформатика/btq100 . ПМЦ 2859123 . ПМИД 20305268 .
- ^ Хуэй Сун Ли; Вонпиль Им (2012). «Идентификация шаблонов лигандов с использованием выравнивания локальной структуры для разработки структурно-ориентированных лекарств» . Журнал химической информации и моделирования . 52 (10): 2784–2795. дои : 10.1021/ci300178e . ПМЦ 3478504 . ПМИД 22978550 .
- ^ Хуэй Сун Ли; Вонпиль Им (2013). «Обнаружение сайта связывания лиганда путем выравнивания локальной структуры и его взаимодополняемость» . Журнал химической информации и моделирования . 53 (9): 2462–2470. дои : 10.1021/ci4003602 . ПМК 3821077 . ПМИД 23957286 .
- ^ Перейти обратно: а б Бартел Д., Херст Дж. Д., Блажевич Дж., Берк Е.К. и Красногор Н. (2007). «ProCKSI: система поддержки принятия решений для сравнения белков (структуры), знаний, сходства и информации» . БМК Биоинформатика . 8 : 416. дои : 10.1186/1471-2105-8-416 . ПМК 2222653 . ПМИД 17963510 .
{{cite journal}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Сиппл, М.; Видерштейн, М. (2012). «Обнаружение пространственных корреляций в белковых структурах и молекулярных комплексах» . Структура . 20 (4): 718–728. дои : 10.1016/j.str.2012.01.024 . ПМК 3320710 . ПМИД 22483118 .
- ^ Тораринссон Э., Савера М., Хавгаард Дж.Х., Фредхольм М., Городкин Дж. (2006). «Тысячи соответствующих геномных областей человека и мыши, не совпадающих по первичной последовательности, содержат общую структуру РНК» . Геном Рез . 16 (7): 885–9. дои : 10.1101/гр.5226606 . ПМЦ 1484455 . ПМИД 16751343 .
- ^ Хокша Д, Свозил Д (2012). «Эффективное сравнение парных структур РНК методом SETTER» . Биоинформатика . 28 (14): 1858–1864. doi : 10.1093/биоинформатика/bts301 . ПМИД 22611129 .
- ^ Чех П., Свозил Д., Хокша Д. (2012). «SETTER: веб-сервер для сравнения структур РНК» . Исследования нуклеиновых кислот . 40 (П1): Н42–Н48. дои : 10.1093/nar/gks560 . ПМЦ 3394248 . ПМИД 22693209 .
- ^ Хавгаард Дж.Х., Люнгсо Р.Б., Стормо Г.Д., Городкин Дж. (2005). «Попарное локальное структурное выравнивание последовательностей РНК со сходством последовательностей менее 40%» . Биоинформатика . 21 (9): 1815–24. doi : 10.1093/биоинформатика/bti279 . ПМИД 15657094 .
- ^ Мэтьюз Д.Х., Тернер Д.Х. (2006). «Прогнозирование вторичной структуры РНК путем минимизации свободной энергии». Curr Opin Struct Biol . 16 (3): 270–8. дои : 10.1016/j.sbi.2006.05.010 . ПМИД 16713706 .
Дальнейшее чтение
[ редактировать ]- Борн П.Е., Шиндялов И.Н. (2003): Сравнение и выравнивание структур . В: Борн, П.Е., Вайсиг, Х. (ред.): Структурная биоинформатика . Хобокен, Нью-Джерси: Уайли-Лисс. ISBN 0-471-20200-2
- Юань X, Быстрофф К. (2004) «Непоследовательные выравнивания на основе структуры выявляют независимые от топологии механизмы упаковки ядра в белках», Биоинформатика . 5 ноября 2004 г.
- Юнг Дж, Ли Б (2000). «Выравнивание структуры белка с использованием профилей окружающей среды» . Белок англ . 13 (8): 535–543. дои : 10.1093/протеин/13.8.535 . ПМИД 10964982 .
- Йе, Годзик А (2005). «Множественное гибкое выравнивание структур с использованием графов частичного порядка» . Биоинформатика . 21 (10): 2362–2369. doi : 10.1093/биоинформатика/bti353 . ПМИД 15746292 .
- Сиппл М., Видерштейн М. (2008). «Заметка о сложных проблемах выравнивания структуры» . Биоинформатика . 24 (3): 426–427. doi : 10.1093/биоинформатика/btm622 . ПМИД 18174182 .