Переобучение
Эта статья нуждается в дополнительных цитатах для проверки . ( август 2017 г. ) |
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|


В математическом моделировании переоснащение — это «проведение анализа, который слишком близко или точно соответствует определенному набору данных и, следовательно, может не соответствовать дополнительным данным или надежно предсказать будущие наблюдения». [1] Переоснащенная модель — это математическая модель , которая содержит больше параметров , чем можно оправдать данными. [2] В математическом смысле эти параметры представляют степень многочлена . Суть переоснащения состоит в том, чтобы неосознанно извлечь часть остаточных отклонений (т. е. шума ), как если бы эти изменения представляли собой основную структуру модели. [3] : 45
Недостаточное соответствие происходит, когда математическая модель не может адекватно отразить основную структуру данных. Недостаточно подобранная модель — это модель, в которой отсутствуют некоторые параметры или термины, которые присутствовали бы в правильно заданной модели. [2] Недостаточное соответствие может произойти, например, при подгонке линейной модели к нелинейным данным. Такая модель будет иметь плохую предсказательную эффективность.
Возможность переобучения существует, поскольку критерий, используемый для выбора модели , не совпадает с критерием, используемым для оценки пригодности модели. Например, модель может быть выбрана путем максимизации ее производительности на некотором наборе обучающих данных , но ее пригодность может определяться ее способностью хорошо работать на невидимых данных; переобучение происходит, когда модель начинает «запоминать» обучающие данные, а не «учиться» делать обобщения на основе тренда.
Крайний пример: если количество параметров равно количеству наблюдений или превышает его, то модель может идеально предсказать обучающие данные, просто запомнив данные целиком. (Иллюстрацию см. на рис. 2.) Однако такая модель обычно дает серьезные сбои при составлении прогнозов.
Переоснащение напрямую связано с ошибкой аппроксимации выбранного класса функций и ошибкой оптимизации процедуры оптимизации. Класс функции, который в соответствующем смысле слишком велик по отношению к размеру набора данных, скорее всего, будет переобучен. [4] Даже если подобранная модель не имеет чрезмерного количества параметров, следует ожидать, что подобранная взаимосвязь будет работать менее эффективно на новом наборе данных, чем на наборе данных, использованном для подбора (явление, иногда называемое сокращением ). [2] частности, значение коэффициента детерминации уменьшится В относительно исходных данных.
Чтобы уменьшить вероятность или количество переоснащения, доступно несколько методов (например, сравнение моделей , перекрестная проверка , регуляризация , ранняя остановка , обрезка , байесовские априорные вычисления или отсев ). В основе некоторых методов лежит либо (1) явное наложение штрафов за слишком сложные модели, либо (2) проверка способности модели к обобщению путем оценки ее производительности на наборе данных, не используемых для обучения, который, как предполагается, аппроксимирует типичные невидимые данные, которые модель столкнется.
Статистический вывод
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( октябрь 2017 г. ) |
В статистике вывод делается на основе статистической модели , выбранной с помощью некоторой процедуры. Бёрнем и Андерсон в своей часто цитируемой работе по выбору модели утверждают, что во избежание переобучения нам следует придерживаться « принципа бережливости ». [3] Авторы также утверждают следующее. [3] : 32–33
Переоснащенные модели ... часто не имеют смещения в средствах оценки параметров, но имеют неоправданно большие оцененные (и фактические) отклонения выборки (точность средств оценки низкая по сравнению с тем, чего можно было бы достичь с помощью более экономной модели) . Ложные эффекты лечения, как правило, выявляются, а ложные переменные включаются в переоснащенные модели. ... Модель наилучшего приближения достигается путем правильного балансирования ошибок недостаточного и переоснащения.
Переобучение, скорее всего, станет серьезной проблемой, когда имеется мало теории для проведения анализа, отчасти потому, что тогда существует большое количество моделей для выбора. В книге «Выбор модели и усреднение модели» (2008) об этом говорится так. [5]
Имея набор данных, вы можете подобрать тысячи моделей одним нажатием кнопки, но как выбрать лучшую? При таком большом количестве моделей-кандидатов переобучение представляет собой реальную опасность. Является ли обезьяна, напечатавшая «Гамлета», хорошим писателем?
Регрессия
[ редактировать ]В регрессионном анализе часто происходит переобучение. [6] есть p В качестве крайнего примера: если в линейной регрессии переменных с p точками данных, подобранная линия может проходить точно через каждую точку. [7] Для логистической регрессии или моделей пропорциональных рисков Кокса существует множество практических правил (например, 5–9, [8] 10 [9] и 10–15 [10] — правило 10 наблюдений на каждую независимую переменную известно как « правило одного из десяти »). В процессе выбора модели регрессии среднеквадратическая ошибка случайной функции регрессии может быть разделена на случайный шум, погрешность аппроксимации и дисперсию оценки функции регрессии. Компромисс смещения и дисперсии часто используется для преодоления моделей переобучения.
При большом наборе объясняющих переменных , которые на самом деле не имеют никакого отношения к прогнозируемой зависимой переменной , некоторые переменные, как правило, будут ошибочно признаны статистически значимыми , и исследователь может, таким образом, сохранить их в модели, тем самым переобучив модель. Это известно как парадокс Фридмана .
Машинное обучение
[ редактировать ]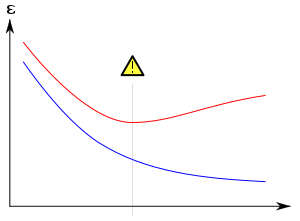
Обычно алгоритм обучения обучается с использованием некоторого набора «обучающих данных»: примерных ситуаций, для которых известен желаемый результат. Цель состоит в том, чтобы алгоритм также хорошо работал при прогнозировании выходных данных при подаче «данных проверки», которые не встречались во время его обучения.
Переоснащение — это использование моделей или процедур, которые нарушают принцип бритвы Оккама , например, путем включения большего количества регулируемых параметров, чем в конечном итоге оптимально, или использования более сложного подхода, чем в конечном итоге оптимально. В качестве примера, когда имеется слишком много настраиваемых параметров, рассмотрим набор данных, в котором данные обучения для y могут быть адекватно предсказаны с помощью линейной функции двух независимых переменных. Такая функция требует всего три параметра (точка пересечения и два наклона). Замена этой простой функции новой, более сложной квадратичной функцией или новой, более сложной линейной функцией от более чем двух независимых переменных сопряжена с риском: бритва Оккама подразумевает, что любая данная сложная функция априори менее вероятна, чем любая заданная простая функция. функция. Если вместо простой функции выбрана новая, более сложная функция, и если не было достаточно большого прироста обучающих данных, подходящего для компенсации увеличения сложности, то новая сложная функция «подгоняет» данные, и сложная переоснащенная функция будет вероятно, будет работать хуже, чем более простая функция, на данных проверки вне набора обучающих данных, хотя сложная функция работает так же хорошо или, возможно, даже лучше, на наборе обучающих данных. [11]
При сравнении различных типов моделей сложность нельзя измерить только путем подсчета количества параметров в каждой модели; Необходимо также учитывать выразительность каждого параметра. Например, нетривиально напрямую сравнить сложность нейронной сети (которая может отслеживать криволинейные связи) с m параметрами с регрессионной моделью с n параметрами. [11]
Переобучение особенно вероятно в тех случаях, когда обучение проводилось слишком долго или когда примеры обучения редки, что заставляет учащегося приспосабливаться к очень специфическим случайным особенностям обучающих данных, которые не имеют причинной связи с целевой функцией . В этом процессе переобучения производительность на обучающих примерах по-прежнему увеличивается, а производительность на невидимых данных ухудшается.
В качестве простого примера рассмотрим базу данных розничных покупок, которая включает купленный товар, покупателя, а также дату и время покупки. Легко построить модель, которая будет идеально соответствовать обучающему набору, используя дату и время покупки для прогнозирования других атрибутов, но эта модель вообще не будет обобщаться на новые данные, потому что прошлые события никогда не повторятся.
Обычно говорят, что алгоритм обучения переобучен по сравнению с более простым, если он более точен в подборе известных данных (рефсайт), но менее точен в прогнозировании новых данных (форсайт). Интуитивно понять переобучение можно из того факта, что информацию из всего прошлого опыта можно разделить на две группы: информацию, актуальную для будущего, и нерелевантную информацию («шум»). При прочих равных условиях, чем сложнее предсказать критерий (т. е. чем выше его неопределенность), тем больше шума существует в прошлой информации, которую необходимо игнорировать. Проблема заключается в том, какую часть игнорировать. Алгоритм обучения, который может снизить риск подгонки шума, называется « робастным ».
Последствия
[ редактировать ]
Наиболее очевидным последствием переоснащения является низкая производительность набора проверочных данных. К другим негативным последствиям относятся:
- Функция, которая переоснащена, скорее всего, запросит больше информации о каждом элементе в наборе проверочных данных, чем оптимальная функция; сбор этих дополнительных ненужных данных может оказаться дорогостоящим или чреваты ошибками, особенно если каждый отдельный фрагмент информации должен быть собран путем человеческого наблюдения и ввода данных вручную. [11]
- Более сложная, перенастроенная функция, скорее всего, будет менее переносимой, чем простая. С одной стороны, линейная регрессия с одной переменной настолько портативна, что при необходимости ее можно даже выполнить вручную. Другой крайностью являются модели, которые можно воспроизвести только путем точного копирования всей установки исходного разработчика модели, что затрудняет повторное использование или научное воспроизведение. [11]
- Возможно, удастся восстановить детали отдельных экземпляров обучения из обучающего набора переоборудованной модели машинного обучения. Это может быть нежелательно, если, например, данные обучения включают конфиденциальную личную информацию (PII). Это явление также создает проблемы в области искусственного интеллекта и авторского права : разработчики некоторых генеративных моделей глубокого обучения, таких как Stable Diffusion и GitHub Copilot, подвергаются иску за нарушение авторских прав, поскольку было обнаружено, что эти модели способны воспроизводить определенные элементы, защищенные авторским правом, из данные их обучения. [12] [13]
Средство
[ редактировать ]Оптимальная функция обычно требует проверки на более крупных или совершенно новых наборах данных. Однако существуют такие методы, как минимальное остовное дерево или время жизни корреляции , которые применяют зависимость между коэффициентами корреляции и временными рядами (шириной окна). Когда ширина окна достаточно велика, коэффициенты корреляции стабильны и больше не зависят от размера ширины окна. Следовательно, корреляционную матрицу можно создать путем расчета коэффициента корреляции между исследуемыми переменными. Топологически эту матрицу можно представить как сложную сеть, в которой визуализируются прямые и косвенные влияния между переменными. Регуляризация отсева также может повысить надежность и, следовательно, уменьшить переобучение за счет вероятностного удаления входных данных в слой.
Недооснащение
[ редактировать ]
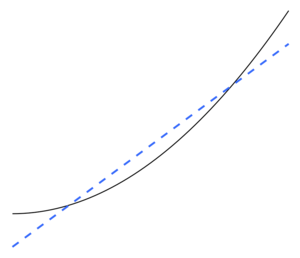
Недостаточное оснащение — это противоположность переобучения, означающее, что статистическая модель или алгоритм машинного обучения слишком упрощены, чтобы точно отразить закономерности в данных. Признаком недостаточного подгонки является то, что в текущей используемой модели или алгоритме обнаружена высокая систематическая ошибка и низкая дисперсия (обратная сторона переобучения: низкая систематическая ошибка и высокая дисперсия ). Это можно получить из компромисса смещения и дисперсии , который представляет собой метод анализа модели или алгоритма на предмет ошибки смещения, ошибки дисперсии и неуменьшаемой ошибки. При высоком смещении и низкой дисперсии результат модели заключается в том, что она будет неточно представлять точки данных и, следовательно, не сможет предсказать будущие результаты данных (см. Ошибка обобщения ). Как показано на рисунке 5, линейная линия не может представлять все заданные точки данных, поскольку линия не похожа на кривизну точек. Мы ожидали бы увидеть линию в форме параболы, как показано на рисунках 6 и 1. Если бы мы использовали рисунок 5 для анализа, мы получили бы ложные прогнозные результаты, противоположные результатам, если бы мы проанализировали рисунок 6.
Бернэм и Андерсон утверждают следующее. [3] : 32
...недооснащенная модель будет игнорировать некоторые важные воспроизводимые (т. е. концептуально воспроизводимые в большинстве других образцов) структуры данных и, таким образом, не сможет выявить эффекты, которые фактически подтверждаются данными. В этом случае смещение в средствах оценки параметров часто бывает значительным, а дисперсия выборки недооценивается, причем оба фактора приводят к плохому охвату доверительного интервала. Недооснащенные модели имеют тенденцию упускать из виду важные эффекты лечения в экспериментальных условиях.
Решение проблемы недостаточного оснащения
[ редактировать ]Есть несколько способов борьбы с недостаточностью:
- Увеличьте сложность модели. Если модель слишком проста, возможно, придется увеличить ее сложность, добавив больше функций, увеличив количество параметров или используя более гибкую модель. Однако делать это следует осторожно, чтобы избежать переобучения. [14]
- Используйте другой алгоритм. Если текущий алгоритм не может уловить закономерности в данных, возможно, придется попробовать другой. Например, для некоторых типов данных нейронная сеть может быть более эффективной, чем модель линейной регрессии. [14]
- Увеличьте объем обучающих данных. Если модель не подходит из-за нехватки данных, может помочь увеличение объема обучающих данных. Это позволит модели лучше отразить основные закономерности в данных. [14]
- Регуляризация. Регуляризация — это метод, используемый для предотвращения переобучения путем добавления штрафного члена к функции потерь, который препятствует использованию больших значений параметров. Его также можно использовать для предотвращения недостаточной подгонки за счет контроля сложности модели. [15]
- Ансамблевые методы . Ансамблевые методы объединяют несколько моделей для создания более точного прогноза. Это может помочь уменьшить недостаточное соответствие, позволяя нескольким моделям работать вместе для выявления основных закономерностей в данных.
- Разработка функций . Разработка функций включает в себя создание новых функций модели из существующих, которые могут быть более актуальными для рассматриваемой проблемы. Это может помочь повысить точность модели и предотвратить недообучение. [14]
Доброкачественное переобучение
[ редактировать ]Доброкачественное переоснащение описывает феномен статистической модели, которая, по-видимому, хорошо обобщает невидимые данные, даже если она идеально подходит для зашумленных обучающих данных (т. е. обеспечивает идеальную точность прогнозирования на обучающем наборе). Это явление представляет особый интерес для глубоких нейронных сетей , но изучается с теоретической точки зрения в контексте гораздо более простых моделей, таких как линейная регрессия . В частности, было показано, что чрезмерная параметризация важна для доброкачественного переобучения в этой ситуации. Другими словами, количество направлений в пространстве параметров, не имеющих значения для прогнозирования, должно значительно превышать размер выборки. [16]
См. также
[ редактировать ]- Компромисс смещения и дисперсии
- Подгонка кривой
- Извлечение данных
- Выбор функции
- Разработка функций
- Парадокс Фридмана
- Ошибка обобщения
- Хорошая посадка
- Время жизни корреляции
- Выбор модели
- Исследовательские степени свободы
- Бритва Оккама
- Основная модель
- Размерность Вапника-Червоненкиса : больший размер VC подразумевает больший риск переобучения.
Примечания
[ редактировать ]- ^ Определение « переоснащения » на OxfordDictionaries.com : это определение предназначено специально для статистики.
- ^ Jump up to: а б с Эверитт Б.С., Скрондал А. (2010), Кембриджский статистический словарь , издательство Кембриджского университета .
- ^ Jump up to: а б с д Бернхэм, КП; Андерсон, Д.Р. (2002), Выбор модели и мультимодельный вывод (2-е изд.), Springer-Verlag .
- ^ Ботту, Леон; Буске, Оливье (30 сентября 2011 г.), «Компромиссы крупномасштабного обучения» , Оптимизация для машинного обучения , The MIT Press, стр. 351–368, doi : 10.7551/mitpress/8996.003.0015 , ISBN 978-0-262-29877-3 , получено 8 декабря 2023 г.
- ^ Класкенс, Г. ; Хьорт, Нидерланды (2008), Выбор модели и усреднение модели , Издательство Кембриджского университета .
- ^ Харрелл, Ф. Е. младший (2001), Стратегии регрессионного моделирования , Springer .
- ^ Марта К. Смит (13 июня 2014 г.). «Переоснащение» . Техасский университет в Остине . Проверено 31 июля 2016 г.
- ^ Виттингофф, Э.; Маккалок, CE (2007). «Ослабление правила десяти событий на переменную в логистической регрессии и регрессии Кокса». Американский журнал эпидемиологии . 165 (6): 710–718. дои : 10.1093/aje/kwk052 . ПМИД 17182981 .
- ^ Дрейпер, Норман Р.; Смит, Гарри (1998). Прикладной регрессионный анализ (3-е изд.). Уайли . ISBN 978-0471170822 .
- ^ Джим Фрост (3 сентября 2015 г.). «Опасность переоснащения регрессионных моделей» . Проверено 31 июля 2016 г.
- ^ Jump up to: а б с д Хокинс, Дуглас М. (2004). «Проблема переобучения». Журнал химической информации и моделирования . 44 (1): 1–12. дои : 10.1021/ci0342472 . ПМИД 14741005 . S2CID 12440383 .
- ^ Jump up to: а б Ли, Тимоти Б. (3 апреля 2023 г.). «Иски об авторских правах Stable Diffusion могут стать юридическим потрясением для ИИ» . Арс Техника .
- ^ Винсент, Джеймс (08 ноября 2022 г.). «Иск, который может переписать правила авторского права ИИ» . Грань . Проверено 7 декабря 2022 г.
- ^ Jump up to: а б с д «ML | Недооснащение и переоснащение» . Гики для Гиков . 2017-11-23 . Проверено 27 февраля 2023 г.
- ^ Нусрат, Исмоилов; Чан, Сунг-Бон (ноябрь 2018 г.). «Сравнение методов регуляризации в глубоких нейронных сетях» . Симметрия . 10 (11): 648. Бибкод : 2018Symm...10..648N . дои : 10.3390/sym10110648 . ISSN 2073-8994 .
- ^ Бартлетт, П.Л., Лонг, П.М., Лугоши, Г., и Циглер, А. (2019). Доброкачественное переобучение в линейной регрессии. Труды Национальной академии наук, 117, 30063–30070.
Ссылки
[ редактировать ]- Лейнвебер, диджей (2007). «Глупые трюки с майнерами данных». Журнал инвестирования . 16 :15–22. дои : 10.3905/joi.2007.681820 . S2CID 108627390 .
- Тетко, И.В.; Ливингстон, диджей; Луйк, А.И. (1995). «Исследования нейронных сетей. 1. Сравнение переобучения и переобучения» (PDF) . Журнал химической информации и моделирования . 35 (5): 826–833. дои : 10.1021/ci00027a006 .
- Совет 7: Минимизируйте переобучение . Чикко, Д. (декабрь 2017 г.). «Десять быстрых советов по машинному обучению в вычислительной биологии» . Добыча биоданных . 10 (35): 35. дои : 10.1186/s13040-017-0155-3 . ПМК 5721660 . ПМИД 29234465 .
Дальнейшее чтение
[ редактировать ]- Кристиан, Брайан ; Гриффитс, Том (апрель 2017 г.), «Глава 7: Переоснащение», Алгоритмы, по которым можно жить: информатика человеческих решений , Уильям Коллинз , стр. 149–168, ISBN 978-0-00-754799-9
Внешние ссылки
[ редактировать ]- Проблема переоснащения данных – Университет Стоуни-Брук
- Что такое «переобучение»? - Эндрю Гельмана Блог
- CSE546: компромисс между смещением линейной регрессии и дисперсией – Вашингтонский университет
- Что такое недостаточное оснащение – IBM
Дифференцируемые вычисления |
|---|