Энтропия (теория информации)
Эта статья нуждается в дополнительных цитатах для проверки . ( февраль 2019 г. ) |
| Теория информации |
|---|
 |
В теории информации энтропия величины случайной — это средний уровень «информации», «неожиданности» или «неопределенности» , присущий возможным результатам переменной. Учитывая дискретную случайную величину , который принимает значения из набора и распределяется по , энтропия где обозначает сумму возможных значений переменной. Выбор базы для , логарифм , варьируется для разных приложений. База 2 дает единицу измерения битов (или « шеннон »), тогда как база e дает «натуральные единицы» nat , а база 10 дает единицы «диты», «баны» или « хартли ». Эквивалентное определение энтропии — это ожидаемое значение собственной информации переменной. [1]


![{\displaystyle p\colon {\mathcal {X}}\to [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/937cff631c9e7bd8e359d598557d62ef8910597b)



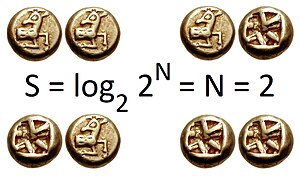
Понятие информационной энтропии было введено Клодом Шенноном в его статье 1948 года « Математическая теория коммуникации ». [2] [3] и также называется энтропией Шеннона . Теория Шеннона определяет систему передачи данных , состоящую из трех элементов: источника данных, канала связи и приемника. «Фундаментальная проблема коммуникации», как выразился Шеннон, заключается в том, чтобы приемник мог определить, какие данные были сгенерированы источником, на основе сигнала, который он получает по каналу. [2] [3] Шеннон рассмотрел различные способы кодирования, сжатия и передачи сообщений из источника данных и в своей теореме о кодировании источника доказал , что энтропия представляет собой абсолютный математический предел того, насколько хорошо данные из источника могут быть сжаты без потерь в совершенно бесшумный канал. Шеннон значительно усилил этот результат для шумных каналов в своей теореме о кодировании шумных каналов .
Энтропия в теории информации прямо аналогична энтропии в статистической термодинамике . Аналогия возникает, когда значения случайной величины обозначают энергии микросостояний, поэтому формула Гиббса для энтропии формально идентична формуле Шеннона. Энтропия имеет отношение к другим областям математики, таким как комбинаторика и машинное обучение . Это определение можно вывести из набора аксиом, устанавливающих, что энтропия должна быть мерой того, насколько информативен средний результат переменной. Для непрерывной случайной величины дифференциальная энтропия аналогична энтропии. Определение обобщает вышесказанное.
![{\displaystyle \mathbb {E} [-\log p(X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/392d6bb368ca2b76ced69928ed3338cfab7e172d)
Введение
[ редактировать ]Основная идея теории информации заключается в том, что «информационная ценность» передаваемого сообщения зависит от степени неожиданности содержания сообщения. Если происходит весьма вероятное событие, сообщение несет очень мало информации. С другой стороны, если происходит маловероятное событие, сообщение будет гораздо более информативным. Например, знание того, что какое-то конкретное число не будет выигрышным в лотерее, дает очень мало информации, поскольку любое конкретное выбранное число почти наверняка не выиграет. Однако знание о том, что определенное число выиграет в лотерею, имеет высокую информационную ценность, поскольку сообщает о наступлении события с очень низкой вероятностью.
Информационное содержание , также называемое неожиданностью или самоинформацией. события — это функция, которая возрастает с увеличением вероятности события уменьшается. Когда близко к 1, неожиданность события мала, но если близко к 0, неожиданность события высока. Эта связь описывается функцией где — логарифм , который дает 0 сюрпризов, когда вероятность события равна 1. [4] Фактически, log — единственная функция, которая удовлетворяет определенному набору условий, определенных в разделе § Характеристика .



Следовательно, мы можем определить информацию или неожиданность события. к или эквивалентно,


Энтропия измеряет ожидаемое (т. е. среднее) количество информации, передаваемой путем определения результата случайного испытания. [5] : 67 Это означает, что энтропия при броске игральной кости выше, чем при подбрасывании монеты, поскольку каждый исход при подбрасывании игральной кости имеет меньшую вероятность ( ), чем каждый результат подбрасывания монеты ( ).


Рассмотрим монету с вероятностью p выпадения орла и вероятностью 1 − p выпадения решки. Максимальный сюрприз – это случай, когда p = 1/2 , при котором один результат не ожидается по сравнению с другим. В этом случае энтропия подбрасывания монеты равна одному биту . (Аналогично, один трит с равновероятными значениями содержит (около 1,58496) бит информации, поскольку оно может иметь одно из трех значений.) Минимальная неожиданность — это когда p = 0 или p = 1 , когда результат события известен заранее, а энтропия равна нулю битов. Когда энтропия равна нулю, это иногда называют единицей, где вообще нет неопределенности – нет свободы выбора – нет информации . Другие значения p дают энтропию между нулем и единицей битов.

Пример
[ редактировать ]Теория информации полезна для расчета наименьшего количества информации, необходимой для передачи сообщения, например, при сжатии данных . Например, рассмотрим передачу последовательностей, содержащих 4 символа «A», «B», «C» и «D», по двоичному каналу. Если все 4 буквы равновероятны (25%), нельзя добиться лучшего результата, чем использовать два бита для кодирования каждой буквы. «A» может кодироваться как «00», «B» как «01», «C» как «10» и «D» как «11». Однако, если вероятности каждой буквы неравны, скажем, «A» встречается с вероятностью 70%, «B» с вероятностью 26%, а «C» и «D» с вероятностью 2% каждая, можно назначить коды переменной длины. В этом случае «A» будет кодироваться как «0», «B» как «10», «C» как «110» и «D» как «111». При таком представлении в 70% случаев необходимо отправить только один бит, в 26% случаев — два бита и только в 4% случаев — 3 бита. В среднем требуется менее 2 битов, поскольку энтропия ниже (из-за высокой распространенности «А», за которым следует «В» — вместе 96% символов). Вычисление суммы вероятностно-взвешенных логарифмических вероятностей измеряет и отражает этот эффект.
Английский текст, рассматриваемый как строка символов, имеет довольно низкую энтропию; т.е. это достаточно предсказуемо. Мы можем быть вполне уверены, что, например, «е» будет гораздо более распространено, чем «z», что сочетание «цюй» будет гораздо более распространено, чем любое другое сочетание с «q» в нем, и что сочетание «th» будет более распространенным, чем «z», «q» или «qu». По первым буквам зачастую можно угадать остальную часть слова. Английский текст имеет от 0,6 до 1,3 бит энтропии на символ сообщения. [6] : 234
Определение
[ редактировать ]Названный в честь Н-теоремы Больцмана , Шеннон определил энтропию Н (греческая заглавная буква эта ) дискретной случайной величины. , который принимает значения из набора и распределяется по такой, что :

![{\displaystyle p:{\mathcal {X}}\to [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f219961c04ea0285eff7416f743c7684e0da25fa)
![{\displaystyle p(x):=\mathbb {P} [X=x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9aa0ae7ad3abfcf67512937135163355464fa594)
![{\displaystyle \mathrm {H} (X)=\mathbb {E} [\operatorname {I} (X)]=\mathbb {E} [-\log p(X)].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5ff47e0ff30877da3b4c93b311fe1cc4b4194a86)
Здесь — значения , а — информационное содержание X. оператор ожидаемого I [7] : 11 [8] : 19–20 сама по себе является случайной величиной.


Энтропию можно явно записать как: где b — основание логарифма . используемого Общие значения b — 2, число Эйлера e и 10, а соответствующими единицами энтропии являются биты для b = 2 , nats для b = e и запреты для b = 10 . [9]

В случае для некоторых значение соответствующего слагаемого 0 log b (0) принимается равным 0 , что соответствует пределу : [10] : 13



Можно также определить условную энтропию двух переменных и получение значений из наборов и соответственно, как: [10] : 16 где и . Под этой величиной следует понимать остаточную случайность в случайной величине учитывая случайную величину .



![{\displaystyle p_{X,Y}(x,y):=\mathbb {P} [X=x,Y=y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/78582c96838c79f6c42f9e40afd3a01d4cbfaf6a)
![{\displaystyle p_{Y}(y)=\mathbb {P} [Y=y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/92fdcaec99cdc3e8031abfeffc84addb07477e2c)
Теория меры
[ редактировать ]Энтропию можно формально определить на языке теории меры следующим образом: [11] Позволять быть вероятностным пространством . Позволять быть событием . Сюрприз является




сюрприз Ожидаемый является

А -почти раздел представляет собой набор семейств такой, что и для всех отдельных . (Это ослабление обычных условий разбиения.) Энтропия является







Позволять быть сигма-алгеброй на . Энтропия является Наконец, энтропия вероятностного пространства равна , то есть энтропия по отношению к сигма-алгебры всех измеримых подмножеств .



Пример
[ редактировать ]
Здесь энтропия составляет не более 1 бита, и для сообщения результата подбрасывания монеты (2 возможных значения) потребуется в среднем не более 1 бита (ровно 1 бит для честной монеты). Результат честного кубика (6 возможных значений) будет иметь энтропию log 2 6 бит.
Рассмотрим подбрасывание монеты с известной, но не обязательно справедливой вероятностью выпадения орла или решки; это можно смоделировать как процесс Бернулли .
Энтропия неизвестного результата следующего подбрасывания монеты максимизируется, если монета честная (то есть, если вероятность орла и решки равна 1/2). Это ситуация максимальной неопределенности, поскольку предсказать исход следующего броска труднее всего; результат каждого подбрасывания монеты дает один полный бит информации. Это потому, что

Однако если мы знаем, что монета нечестная, но выпадает орел или решка с вероятностью p и q , где p ≠ q , тогда неопределенности будет меньше. Каждый раз, когда его бросают, одна сторона с большей вероятностью поднимется, чем другая. Снижение неопределенности количественно выражается в более низкой энтропии: в среднем каждый бросок монеты дает менее одного полного бита информации. Например, если р = 0,7, то

Равномерная вероятность дает максимальную неопределенность и, следовательно, максимальную энтропию. Таким образом, энтропия может уменьшаться только по сравнению со значением, связанным с равномерной вероятностью. Крайним случаем является двусторонняя монета, у которой никогда не выпадает решка, или двусторонняя монета, у которой никогда не выпадает решка. Тогда нет никакой неопределенности. Энтропия равна нулю: каждый бросок монеты не дает новой информации, поскольку результат каждого броска монеты всегда определен. [10] : 14–15
Характеристика
[ редактировать ]Чтобы понять значение −Σ p i log( p i ) , сначала определите информационную функцию I в терминах события i с вероятностью p i . Количество информации, полученной в результате наблюдения события i, следует из решения Шеннона фундаментальных свойств информации : [12]
- I( p ) по монотонно убывает p : увеличение вероятности события уменьшает информацию от наблюдаемого события, и наоборот.
- I(1) = 0 : события, которые происходят всегда, не передают информацию.
- I( p1 , · p2 независимых ) = I( p1 ) + I( p2 . ) : информация, полученная из событий представляет собой сумму информации, полученной из каждого события
Учитывая два независимых события, если первое событие может дать один из n равновероятных исходов, а другое имеет один из m равновероятных исходов, то существует mn равновероятных исходов совместного события. Это означает, что если биты log 2 ( n ) необходимы для кодирования первого значения и биты log 2 ( m ) для кодирования второго, то требуется log 2 ( mn ) = log 2 ( m ) + log 2 ( n ). для кодирования обоих .
Шеннон обнаружил, что подходящий выбор дается: [13]


Фактически, единственно возможные значения являются для . Кроме того, выбор значения k эквивалентен выбору значения для , так что x соответствует основанию логарифма . Таким образом, энтропия характеризуется четырьмя вышеперечисленными свойствами.




Доказательство






![{\displaystyle p\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/33c3a52aa7b2d00227e85c641cca67e85583c43c)
Различные единицы информации ( биты для двоичного логарифма log 2 , nats для натурального логарифма ln , запреты для десятичного логарифма log 10 и т. д.) являются постоянными кратными друг другу. Например, в случае честного подбрасывания монеты орел предоставляет log 2 (2) = 1 бит информации, что составляет примерно 0,693 натс или 0,301 десятичной цифры. Из-за аддитивности n бросков предоставляют n бит информации, что составляет примерно 0,693 n nats или 0,301 n десятичных цифр.
Смысл сообщений наблюдаемых событий (смысл ) не имеет значения в определении энтропии. Энтропия учитывает только вероятность наблюдения конкретного события, поэтому информация, которую она инкапсулирует, — это информация об основном распределении вероятностей , а не о значении самих событий.
Альтернативная характеристика
[ редактировать ]Другая характеристика энтропии использует следующие свойства. Обозначим p i = Pr( X = x i ) и Η n ( p 1 , ..., p n ) = Η ( X ) .
- Непрерывность: H должна быть непрерывной , так что изменение значений вероятностей на очень небольшую величину должно изменить энтропию лишь на небольшую величину.
- Симметрия: H не должен меняться, если исходы x i переупорядочиваются. То есть, для любой перестановки из .
- Максимум: должно быть максимальным, если все исходы равновероятны, т.е. .
- Увеличение количества исходов: для равновероятных событий энтропия должна увеличиваться с увеличением количества исходов, т.е.
- Аддитивность: для данного ансамбля из n равномерно распределенных элементов, которые разбиты на k блоков (подсистем) по b 1 , ..., b k элементов в каждой, энтропия всего ансамбля должна быть равна сумме энтропии система ящиков и отдельные энтропии ящиков, каждая из которых взвешена с вероятностью нахождения в этом конкретном ящике.






Обсуждение
[ редактировать ]Правило аддитивности имеет следующие последствия: для натуральных чисел b i где b 1 + ... + b k = n ,

Выбор k = n , b 1 = ... = bn = 1 означает, что энтропия определенного результата равна нулю: Η 1 (1) = 0 . Это означает, что эффективность исходного набора с n символами можно определить просто как равную его n -арной энтропии. См. также Избыточность (теория информации) .
Характеризация здесь налагает аддитивное свойство по отношению к разбиению множества . Между тем, условная вероятность определяется с точки зрения мультипликативного свойства: . Обратите внимание, что логарифм является промежуточным звеном между этими двумя операциями. Условная энтропия и связанные с ней величины, в свою очередь, наследуют простое соотношение. Определение теории меры в предыдущем разделе определяло энтропию как сумму ожидаемых сюрпризов. для экстремального разбиения. Здесь логарифм является специальным, а энтропия сама по себе не является мерой. По крайней мере, в теории информации двоичной строки, поддается практическим интерпретациям.



На основе таких отношений было определено множество связанных и конкурирующих величин. Например, анализ Дэвида Эллермана «логики разделов» определяет конкурирующую меру в структурах, двойственных мерам подмножеств универсального множества. [14] Информация выражается количественно как «диты» (различия), мера по разделам. «Диты» можно преобразовать в биты Шеннона , чтобы получить формулы условной энтропии и так далее.
Альтернативная характеристика через аддитивность и субаддитивность
[ редактировать ]Другая краткая аксиоматическая характеристика энтропии Шеннона была дана Акселем , Форте и Нг: [15] через следующие свойства:
- Субаддитивность: для совместно распределенных случайных величин .
- Аддитивность: когда случайные величины независимы.
- Расширяемость: , т. е. добавление результата с нулевой вероятностью не меняет энтропию.
- Симметрия: инвариантен относительно перестановки .
- Малый для малых вероятностей: .







Обсуждение
[ редактировать ]Было показано, что любая функция удовлетворяющее вышеуказанным свойствам, должно быть постоянным кратным энтропии Шеннона с неотрицательной константой. [15] По сравнению с ранее упомянутыми характеризациями энтропии, эта характеристика фокусируется на свойствах энтропии как функции случайных величин (субаддитивность и аддитивность), а не на свойствах энтропии как функции вектора вероятности. .

Стоит отметить, что если отбросить свойство «малая для малых вероятностей», то должна быть неотрицательной линейной комбинацией энтропии Шеннона и энтропии Хартли . [15]
Дополнительные свойства
[ редактировать ]Энтропия Шеннона удовлетворяет следующим свойствам, для некоторых из которых полезно интерпретировать энтропию как ожидаемое количество полученной информации (или устраненной неопределенности) путем выявления значения случайной величины X :
- Добавление или удаление события с нулевой вероятностью не увеличивает энтропию:
- .
- Максимальная энтропия события с n различными исходами равна log b ( n ) : она достигается за счет равномерного распределения вероятностей. То есть неопределенность максимальна, когда все возможные события равновероятны:
- . [10] : 29

- Энтропия или количество информации, выявленной путем оценки ( X , Y ) (то есть оценки X и Y одновременно), равна информации, полученной путем проведения двух последовательных экспериментов: сначала оценивая значение Y , затем выявляя значение X. учитывая, что вы знаете значение Y . Это может быть записано как: [10] : 16

- Если где является функцией, то . Применяя предыдущую формулу к урожайность




- так энтропия переменной может уменьшаться только тогда, когда последняя передается через функцию.


- Если X и Y — две независимые случайные величины, то знание значения Y не влияет на наше знание значения X (поскольку они не влияют друг на друга своей независимостью):

- В более общем смысле для любых случайных величин X и Y мы имеем
- . [10] : 29

- Энтропия двух одновременных событий есть не более чем сумма энтропий каждого отдельного события, т.е. , с равенством тогда и только тогда, когда два события независимы. [10] : 28
- Энтропия является вогнутой относительно функции массы вероятности , то есть [10] : 30


- для всех функций вероятности и . [10] : 32
- Соответственно, функция отрицательной энтропии (негэнтропии) является выпуклой, а ее выпуклая сопряженная функция — LogSumExp .



Аспекты
[ редактировать ]Связь с термодинамической энтропией
[ редактировать ]Вдохновением для принятия слова «энтропия» в теории информации послужило близкое сходство между формулой Шеннона и очень похожими известными формулами статистической механики .
В статистической термодинамике наиболее общей формулой термодинамической энтропии S является термодинамической системы энтропия Гиббса.

где k B — постоянная Больцмана , а pi — вероятность микросостояния . была Энтропия Гиббса определена Дж. Уиллардом Гиббсом в 1878 году после более ранней работы Больцмана (1872). [16]
Энтропия Гиббса практически без изменений переносится в мир квантовой физики и дает энтропию фон Неймана, введенную Джоном фон Нейманом в 1927 году:

где ρ — матрица плотности квантовомеханической системы, а Tr — след . [17]
На повседневном практическом уровне связь между информационной энтропией и термодинамической энтропией неочевидна. Физики и химики склонны больше интересоваться изменениями энтропии по мере того, как система самопроизвольно развивается от своих начальных условий в соответствии со вторым законом термодинамики , а не неизменным распределением вероятностей. Как показывает мелочность константы Больцмана k B , изменения S / k B даже для крошечных количеств веществ в химических и физических процессах представляют собой количества энтропии, которые чрезвычайно велики по сравнению с чем-либо при сжатии данных или обработке сигналов . В классической термодинамике энтропия определяется с точки зрения макроскопических измерений и не имеет отношения к какому-либо распределению вероятностей, которое имеет центральное значение для определения информационной энтропии.
Связь между термодинамикой и тем, что сейчас известно как теория информации, была впервые установлена Людвигом Больцманом и выражена его уравнением :

где - термодинамическая энтропия конкретного макросостояния (определяемая термодинамическими параметрами, такими как температура, объем, энергия и т. д.), W - количество микросостояний (различных комбинаций частиц в различных энергетических состояниях), которые могут создать данное макросостояние, и k B — постоянная Больцмана . [18] Предполагается, что каждое микросостояние равновероятно, так что вероятность данного микросостояния равна p i = 1/ W . Когда эти вероятности подставляются в приведенное выше выражение для энтропии Гиббса (или, что то же самое, умноженное на k B энтропию Шеннона), получается уравнение Больцмана. С точки зрения теории информации, информационная энтропия системы — это количество «недостающей» информации, необходимой для определения микросостояния с учетом макросостояния.

По мнению Джейнса (1957), [19] Термодинамическую энтропию, объясненную статистической механикой , следует рассматривать как применение теории информации Шеннона: термодинамическая энтропия интерпретируется как пропорциональная количеству дополнительной информации Шеннона, необходимой для определения подробного микроскопического состояния системы, которая остается непередаваемой описание исключительно в терминах макроскопических переменных классической термодинамики, где константа пропорциональности представляет собой просто константу Больцмана . Добавление тепла к системе увеличивает ее термодинамическую энтропию, поскольку увеличивает количество возможных микроскопических состояний системы, которые согласуются с измеримыми значениями ее макроскопических переменных, что делает любое полное описание состояния более длинным. (См. статью: Термодинамика максимальной энтропии ). Демон Максвелла может (гипотетически) уменьшить термодинамическую энтропию системы, используя информацию о состояниях отдельных молекул; но, как отметил Ландауэр (с 1961 г.) и соавт. [20] показали, что для функционирования демон сам должен увеличить термодинамическую энтропию, по крайней мере, на количество информации Шеннона, которую он предлагает сначала получить и сохранить; и поэтому полная термодинамическая энтропия не уменьшается (что разрешает парадокс). Принцип Ландауэра устанавливает нижний предел количества тепла, которое компьютер должен вырабатывать для обработки заданного объема информации, хотя современные компьютеры гораздо менее эффективны.
Сжатие данных
[ редактировать ]Определение энтропии, данное Шенноном, применительно к источнику информации, может определить минимальную пропускную способность канала, необходимую для надежной передачи источника в виде закодированных двоичных цифр. Энтропия Шеннона измеряет информацию, содержащуюся в сообщении, а не ту часть сообщения, которая определена (или предсказуема). Примеры последнего включают избыточность в языковой структуре или статистические свойства, связанные с частотами появления пар букв или слов, троек и т. д. Минимальная пропускная способность канала может быть реализована теоретически с использованием типичного набора или на практике с использованием Хаффмана , Лемпеля-Зива или арифметическое кодирование . (См. также «Колмогоровская сложность ».) На практике алгоритмы сжатия намеренно включают некоторую разумную избыточность в виде контрольных сумм для защиты от ошибок. Уровень энтропии источника данных — это среднее количество бит на символ, необходимое для его кодирования. Эксперименты Шеннона с людьми-предсказателями показывают скорость передачи информации от 0,6 до 1,3 бита на символ в английском языке; [21] Алгоритм сжатия PPM может обеспечить степень сжатия 1,5 бита на символ в английском тексте.
Если схема сжатия без потерь — та, в которой вы всегда можете восстановить все исходное сообщение путем распаковки — тогда сжатое сообщение содержит то же количество информации, что и исходное, но передается меньшим количеством символов. Он имеет больше информации (более высокую энтропию) на символ. Сжатое сообщение имеет меньшую избыточность . Теорема Шеннона о кодировании исходного кода утверждает, что схема сжатия без потерь не может сжимать сообщения в среднем так, чтобы в каждом бите сообщения содержалось более одного бита информации, но что любое значение менее одного бита информации на бит сообщения может быть достигнуто путем использования подходящего алгоритма кодирования. схема кодирования. Энтропия сообщения на бит, умноженная на длину этого сообщения, является мерой того, сколько общей информации содержит сообщение. Теорема Шеннона также подразумевает, что ни одна схема сжатия без потерь не может сократить все сообщения. Если некоторые сообщения выходят короче, хотя бы одно должно выйти длиннее из-за принципа «ячейки» . При практическом использовании это, как правило, не является проблемой, поскольку обычно интересует сжатие только определенных типов сообщений, таких как документ на английском языке, а не бессмысленный текст или цифровые фотографии, а не шум, и неважно, если Алгоритм сжатия увеличивает некоторые маловероятные или неинтересные последовательности.
Исследование, проведенное в журнале Science в 2011 году , оценивает мировые технологические возможности для хранения и передачи оптимально сжатой информации, нормализованной с помощью наиболее эффективных алгоритмов сжатия, доступных в 2007 году, таким образом оценивая энтропию технологически доступных источников. [22] : 60–65
| Тип информации | 1986 | 2007 |
|---|---|---|
| Хранилище | 2.6 | 295 |
| Транслировать | 432 | 1900 |
| Телекоммуникации | 0.281 | 65 |
Авторы оценивают технологические возможности человечества по хранению информации (полностью энтропийно сжатой) в 1986 году и снова в 2007 году. Они разбивают информацию на три категории — хранить информацию на носителе, получать информацию через односторонние сети вещания или обмениваться информацией. через двусторонние телекоммуникационные сети. [22]
Энтропия как мера разнообразия
[ редактировать ]Энтропия является одним из нескольких способов измерения биоразнообразия и применяется в форме индекса Шеннона . [23] Индекс разнообразия — это количественная статистическая мера того, сколько различных типов существует в наборе данных, например видов в сообществе, с учетом экологического богатства , равномерности и доминирования . В частности, энтропия Шеннона представляет собой логарифм 1 D , индекс истинного разнообразия с параметром, равным 1. Индекс Шеннона связан с пропорциональным обилием типов.
Энтропия последовательности
[ редактировать ]Существует ряд концепций, связанных с энтропией, которые математически количественно определяют информационное содержание последовательности или сообщения:
- самоинформация отдельного сообщения или символа , взятая из заданного распределения вероятностей (сообщение или последовательность, рассматриваемые как отдельное событие),
- совместная энтропия символов, образующих сообщение или последовательность (рассматриваемую как набор событий),
- скорость энтропии случайного процесса (сообщение или последовательность рассматриваются как последовательность событий).
(«Скорость самоинформации» также может быть определена для определенной последовательности сообщений или символов, генерируемых данным случайным процессом: она всегда будет равна скорости энтропии в случае стационарного процесса .) Другие количества информации также используются для сравнения или связи различных источников информации.
Важно не путать приведенные выше понятия. Часто только из контекста становится ясно, о каком из них идет речь. Например, когда кто-то говорит, что «энтропия» английского языка составляет около 1 бита на символ, на самом деле он моделирует английский язык как случайный процесс и говорит о уровне его энтропии . Сам Шеннон использовал этот термин именно так.
Если используются очень большие блоки, оценка уровня энтропии на каждый символ может стать искусственно заниженной, поскольку распределение вероятностей последовательности точно не известно; это всего лишь оценка. Если рассматривать текст каждой когда-либо опубликованной книги как последовательность, где каждый символ представляет собой текст полной книги, и если имеется N опубликованных книг и каждая книга публикуется только один раз, то оценка вероятности каждой книги будет равна 1/ N , а энтропия (в битах) равна −log 2 (1/ N ) = log 2 ( N ) . На практике это соответствует присвоению каждой книге уникального идентификатора и использованию его вместо текста книги всякий раз, когда кто-то хочет сослаться на книгу. Это чрезвычайно полезно для разговоров о книгах, но не столь полезно для характеристики информационного содержания отдельной книги или языка в целом: невозможно восстановить книгу по ее идентификатору, не зная распределения вероятностей, т.е. , полный текст всех книг. Ключевая идея заключается в том, что необходимо учитывать сложность вероятностной модели. Колмогоровская сложность — это теоретическое обобщение этой идеи, позволяющее рассматривать информативность последовательности независимо от какой-либо конкретной вероятностной модели; он рассматривает кратчайшую программу для универсального компьютера , выводящую последовательность. Код, который достигает уровня энтропии последовательности для данной модели плюс кодовая книга (т. е. вероятностная модель), является одной из таких программ, но, возможно, не самой короткой.
Последовательность Фибоначчи — это 1, 1, 2, 3, 5, 8, 13, .... рассматривая последовательность как сообщение, а каждое число как символ, символов почти столько же, сколько символов в сообщении, что дает энтропия приблизительно равна log 2 ( n ) . Первые 128 символов последовательности Фибоначчи имеют энтропию примерно 7 бит/символ, но последовательность можно выразить с помощью формулы [ F( n ) = F( n -1) + F( n -2) для n = 3 , 4, 5, ... , F(1) =1 , F(2) = 1 ] и эта формула имеет гораздо меньшую энтропию и применима к любой длине последовательности Фибоначчи.
Ограничения энтропии в криптографии
[ редактировать ]В криптоанализе энтропия часто грубо используется как мера непредсказуемости криптографического ключа, хотя ее реальная неопределенность неизмерима. Например, 128-битный ключ, который генерируется равномерно и случайным образом, имеет энтропию 128 бит. Это также занимает (в среднем) догадывается сломать грубой силой. Энтропия не может уловить необходимое количество предположений, если возможные ключи выбраны неравномерно. [24] [25] Вместо этого можно использовать меру, называемую догадками, для измерения усилий, необходимых для атаки методом грубой силы. [26]

Другие проблемы могут возникнуть из-за неравномерности распределений, используемых в криптографии. Например, двоичный одноразовый блокнот на 1 000 000 цифр с использованием исключающего или. Если блокнот имеет 1 000 000 бит энтропии, он идеален. Если блокнот имеет 999 999 бит энтропии, распределенной равномерно (каждый отдельный бит блока имеет 0,999999 бит энтропии), это может обеспечить хорошую безопасность. Но если блокнот имеет 999 999 бит энтропии, где первый бит фиксирован, а остальные 999 999 бит совершенно случайны, первый бит зашифрованного текста вообще не будет зашифрован.
Данные как марковский процесс
[ редактировать ]Распространенный способ определения энтропии текста основан на марковской модели текста. Для источника нулевого порядка (каждый символ выбирается независимо от последних символов) двоичная энтропия равна:

где p i - вероятность i . первого порядка Для марковского источника (того, в котором вероятность выбора символа зависит только от непосредственно предшествующего символа) уровень энтропии равен:
- [ нужна ссылка ]

где я — состояние (некоторые предшествующие символы) и - вероятность j, если i является предыдущим символом.

Для марковского источника второго порядка уровень энтропии равен

Эффективность (нормированная энтропия)
[ редактировать ]Исходный набор с неравномерным распределением будет иметь меньшую энтропию, чем тот же набор с равномерным распределением (т.е. «оптимизированный алфавит»). Этот дефицит энтропии можно выразить как соотношение, называемое эффективностью: [27]

Применяя основные свойства логарифма, эту величину можно также выразить как:

Эффективность полезна для количественной оценки эффективного использования канала связи . Эту формулировку также называют нормализованной энтропией, поскольку энтропия делится на максимальную энтропию. . Более того, эффективность безразлична к выбору (положительного) основания b , на что указывает нечувствительность к последнему логарифму выше.

Энтропия для непрерывных случайных величин
[ редактировать ]Дифференциальная энтропия
[ редактировать ]Энтропия Шеннона ограничена случайными величинами, принимающими дискретные значения. Соответствующая формула для непрерывной случайной величины с функцией плотности вероятности f ( x ) с конечным или бесконечным носителем на реальной линии определяется по аналогии, используя приведенную выше форму энтропии в качестве ожидания: [10] : 224

![{\displaystyle \mathrm {H} (X)=\mathbb {E} [-\log f(X)]=-\int _ {\mathbb {X} }f(x)\log f(x)\, \mathrm {d} x.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9e222b735b621457042c194ed573f7455ffd8393)
Это дифференциальная энтропия (или непрерывная энтропия). Предвестником непрерывной энтропии h [ f ] выражение для функционала Н в Н-теореме Больцмана является .
Хотя аналогия между обеими функциями наводит на размышления, необходимо задать следующий вопрос: является ли дифференциальная энтропия действительным расширением дискретной энтропии Шеннона? Дифференциальной энтропии не хватает ряда свойств, которыми обладает дискретная энтропия Шеннона – она может быть даже отрицательной – и были предложены поправки, в частности, ограничивающие плотность дискретных точек .
Чтобы ответить на этот вопрос, необходимо установить связь между двумя функциями:
Чтобы получить вообще конечную меру, когда размер ячейки стремится к нулю. В дискретном случае размер интервала представляет собой (неявную) ширину каждого из n (конечных или бесконечных) интервалов, вероятности которых обозначаются p n . Поскольку непрерывная область обобщена, ширину необходимо указать явно.
Для этого начните с непрерывной функции f, дискретизированной на ячейки размером .По теореме о среднем значении существует значение x i в каждом интервале такое, что интеграл функции f можно аппроксимировать (в римановом смысле) формулой где этот предел и «размер контейнера стремится к нулю» эквивалентны.



Мы будем обозначать и разложив логарифм, получим


При ∆ → 0 имеем

Примечание; log(Δ) → −∞ при Δ → 0 требует специального определения дифференциальной или непрерывной энтропии:
![{\displaystyle h[f]=\lim _{\Delta \to 0}\left(\mathrm {H} ^{\Delta }+\log \Delta \right)=-\int _{-\infty }^ {\infty }f(x)\log f(x)\,dx,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d522982a9afc1539b88695a28b7aa3ffd2fa2d8)
которая, как было сказано ранее, называется дифференциальной энтропией. Это означает, что дифференциальная энтропия не является пределом энтропии Шеннона при n → ∞ . Скорее, он отличается от предела энтропии Шеннона бесконечным смещением (см. также статью об информационном измерении ).
Предельная плотность дискретных точек
[ редактировать ]В результате оказывается, что, в отличие от энтропии Шеннона, дифференциальная энтропия не вообще является хорошей мерой неопределенности или информации. Например, дифференциальная энтропия может быть отрицательной; также он не инвариантен относительно непрерывных преобразований координат. Эту проблему можно проиллюстрировать изменением единиц измерения, когда x является размерной переменной. f ( x ) тогда будет иметь единицы измерения 1/ x . Аргумент логарифма должен быть безразмерным, иначе он неправильный, так что дифференциальная энтропия, указанная выше, будет несобственной. Если Δ является некоторым «стандартным» значением x (т.е. «размером контейнера») и, следовательно, имеет те же единицы измерения, то модифицированную дифференциальную энтропию можно записать в правильной форме как:

и результат будет одинаковым для любого выбора единиц измерения x . Фактически предел дискретной энтропии как будет также включать срок , что в общем случае было бы бесконечным. Это ожидаемо: непрерывные переменные обычно имеют бесконечную энтропию при дискретизации. Предельная плотность дискретных точек на самом деле является мерой того, насколько легче описать распределение, чем распределение, однородное по схеме квантования.


Относительная энтропия
[ редактировать ]Еще одна полезная мера энтропии, которая одинаково хорошо работает как в дискретном, так и в непрерывном случае, — это относительная энтропия распределения. Оно определяется как расхождение Кульбака – Лейблера от распределения до эталонной меры m следующим образом. Предположим, что распределение вероятностей p абсолютно непрерывно относительно меры m , т.е. имеет вид p ( dx ) = f ( x ) m ( dx ) для некоторой неотрицательной m -интегрируемой функции f с m -интегралом 1, тогда относительную энтропию можно определить как

В этом виде относительная энтропия обобщает (с точностью до смены знака) как дискретную энтропию, где мера m является считающей мерой , так и дифференциальную энтропию, где мера m является мерой Лебега . Если мера m сама по себе является распределением вероятностей, относительная энтропия неотрицательна и равна нулю, если p = m в качестве меры. Он определен для любого пространства с мерой, следовательно, не зависит от координат и инвариантен относительно перепараметризации координат, если правильно принять во внимание преобразование меры m . Относительная энтропия, а также (неявно) энтропия и дифференциальная энтропия действительно зависят от «эталонной» меры m .
Использование в теории чисел
[ редактировать ]Теренс Тао использовал энтропию, чтобы установить полезную связь, пытаясь решить проблему несоответствия Эрдеша . [28]
Интуитивно идея доказательства заключалась в том, что между последовательными случайными величинами имеется низкая информация с точки зрения энтропии Шеннона (здесь случайная величина определяется с помощью функции Лиувилля (которая является полезной математической функцией для изучения распределения простых чисел) X H = . А в интервале [n, n+H] сумма на этом интервале может стать сколь угодно большой. Например, последовательность +1 (которые могут принимать значения X H' ) имеет тривиально низкую энтропию, и их сумма станет большой. Но ключевой вывод заключался в том, чтобы показать уменьшение энтропии на немалую величину при расширении H, что приводит к неограниченному росту математического объекта по этой случайной величине, что эквивалентно показу неограниченного роста в соответствии с проблемой несоответствия Эрдеша .

Доказательство довольно сложное, и оно привело к прорывам не только в новом использовании энтропии Шеннона, но и в использовании функции Лиувилля вместе со средними значениями модулированных мультипликативных функций. Архивировано 28 октября 2023 года в Wayback Machine за короткие промежутки времени. Доказательство этого также преодолело «барьер паритета». Архивировано 7 августа 2023 года в Wayback Machine для этой конкретной проблемы.
Хотя использование энтропии Шеннона в доказательстве является новым, оно, вероятно, откроет новые исследования в этом направлении.
Использование в комбинаторике
[ редактировать ]Энтропия стала полезной величиной в комбинаторике .
Неравенство Лумиса – Уитни
[ редактировать ]Простым примером этого является альтернативное доказательство неравенства Лумиса–Уитни : для любого подмножества A ⊆ Z д , у нас есть

где Pi — ортогональная проекция по i-й координате:

Доказательство следует как простое следствие неравенства Ширера : если X 1 , ..., X d — случайные величины, а S 1 , ..., Sn — подмножества {1, ..., d } такие, что каждое целое число между 1 и d лежит ровно в r из этих подмножеств, то
![{\displaystyle \mathrm {H} [(X_{1},\ldots,X_{d})]\leq {\frac {1}{r}}\sum _{i=1}^{n}\mathrm {H} [(X_{j})_{j\in S_{i}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6d219e5f3250e54a77586cd05731ff2ee0db7ee)
где декартовым произведением случайных величин X j с индексами j в Si является (поэтому размерность этого вектора равна размеру Si ) .

Мы обрисуем, как из этого следует Лумис-Уитни: Действительно, пусть X — равномерно распределенная случайная величина со значениями в A и так, что каждая точка в A встречается с равной вероятностью. Тогда (в силу упомянутых выше дополнительных свойств энтропии) Η( X ) = log| А | , где | А | обозначает мощность A . Пусть S i = {1, 2, ..., i −1, i +1, ..., d }. Диапазон содержится в Pi , ( A ) и, следовательно . Теперь используйте это, чтобы ограничить правую часть неравенства Ширера и возвести в степень противоположные части полученного неравенства.
![{\displaystyle \mathrm {H} [(X_{j})_{j\in S_{i}}]\leq \log |P_{i}(A)|}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e775922b5cf13b31bbf4fec16e82d4f492378cba)
Приближение к биномиальному коэффициенту
[ редактировать ]Для целых чисел 0 < k < n пусть q = k / n . Затем

где
- [29] : 43

Доказательство (эскиз)



Хорошая интерпретация этого состоит в том, что количество двоичных строк длины n, содержащих ровно k многих единиц, примерно равно . [30]

Использование в машинном обучении
[ редактировать ]Методы машинного обучения в основном возникают из статистики, а также из теории информации. В общем, энтропия — это мера неопределенности, а цель машинного обучения — минимизировать неопределенность.
Алгоритмы обучения дерева решений используют относительную энтропию для определения правил принятия решений, которые управляют данными в каждом узле. [31] Получение информации в деревьях решений , что равно разнице между энтропией и условная энтропия данный , количественно определяет ожидаемую информацию или уменьшение энтропии благодаря дополнительному знанию значения атрибута. . Полученная информация используется для определения того, какие атрибуты набора данных предоставляют больше всего информации, и их следует использовать для оптимального разделения узлов дерева.

Модели байесовского вывода часто применяют принцип максимальной энтропии для получения априорных распределений вероятностей. [32] Идея состоит в том, что распределение, которое лучше всего отражает текущее состояние знаний о системе, имеет наибольшую энтропию и, следовательно, подходит в качестве априорного.
Классификация в машинном обучении, выполняемая с помощью логистической регрессии или искусственных нейронных сетей, часто использует стандартную функцию потерь, называемую перекрестной энтропийной потерей, которая минимизирует среднюю перекрестную энтропию между фактическими и прогнозируемыми распределениями. [33] В общем, перекрестная энтропия — это мера различий между двумя наборами данных, аналогичная расхождению KL (также известному как относительная энтропия).
См. также
[ редактировать ]- Приблизительная энтропия (ApEn)
- Энтропия (термодинамика)
- Перекрестная энтропия - это мера среднего количества битов, необходимых для идентификации события из набора возможностей между двумя распределениями вероятностей.
- Энтропия (стрела времени)
- Энтропийное кодирование – схема кодирования, которая присваивает символам коды таким образом, чтобы длина кода соответствовала вероятностям символов.
- Оценка энтропии
- Неравенство энтропийной мощности
- Информация о Фишере
- Энтропия графа
- Расстояние Хэмминга
- История энтропии
- История теории информации
- Сложность колебания информации
- Информационная геометрия
- Энтропия Колмогорова–Синая в динамических системах
- Расстояние Левенштейна
- Взаимная информация
- Растерянность
- Качественная вариация - другие меры статистической дисперсии номинальных распределений.
- Квантовая относительная энтропия – мера различимости двух квантовых состояний.
- Энтропия Реньи – обобщение энтропии Шеннона; это один из семейства функционалов для количественной оценки разнообразия, неопределенности или случайности системы.
- Случайность
- Выборочная энтропия (SampEn)
- Индекс Шеннона
- Частичный индекс
- Типогликемия
Ссылки
[ редактировать ]- ^ Патрия, РК; Бил, Пол (2011). Статистическая механика (Третье изд.). Академическая пресса. п. 51. ИСБН 978-0123821881 .
- ^ Перейти обратно: а б Шеннон, Клод Э. (июль 1948 г.). «Математическая теория связи» . Технический журнал Bell System . 27 (3): 379–423. дои : 10.1002/j.1538-7305.1948.tb01338.x . hdl : 10338.dmlcz/101429 . ( PDF , заархивировано отсюда . Архивировано 20 июня 2014 г. в Wayback Machine )
- ^ Перейти обратно: а б Шеннон, Клод Э. (октябрь 1948 г.). «Математическая теория связи» . Технический журнал Bell System . 27 (4): 623–656. дои : 10.1002/j.1538-7305.1948.tb00917.x . hdl : 11858/00-001M-0000-002C-4317-B . ( PDF , заархивировано отсюда . Архивировано 10 мая 2013 г. в Wayback Machine )
- ^ «Энтропия (для науки о данных) ясно объяснена!!!» . Архивировано из оригинала 5 октября 2021 года . Проверено 5 октября 2021 г. - через YouTube .
- ^ Маккей, Дэвид Дж. К. (2003). Теория информации, вывод и алгоритмы обучения . Издательство Кембриджского университета. ISBN 0-521-64298-1 . Архивировано из оригинала 17 февраля 2016 года . Проверено 9 июня 2014 г.
- ^ Шнайер, Б: Прикладная криптография , второе издание, Джон Уайли и сыновья.
- ^ Борда, Моника (2011). Основы теории информации и кодирования . Спрингер. ISBN 978-3-642-20346-6 .
- ^ Хан, Те Сун; Кобаяши, Кинго (2002). Математика информации и кодирования . Американское математическое общество. ISBN 978-0-8218-4256-0 .
- ^ Шнайдер, Т.Д., Букварь по теории информации с приложением по логарифмам. [ постоянная мертвая ссылка ] , Национальный институт рака, 14 апреля 2007 г.
- ^ Перейти обратно: а б с д и ж г час я дж к Томас М. Кавер; Джой А. Томас (1991). Элементы теории информации . Хобокен, Нью-Джерси: Уайли. ISBN 978-0-471-24195-9 .
- ^ Энтропия в n Lab
- ^ Картер, Том (март 2014 г.). Введение в теорию информации и энтропию (PDF) . Санта Фе. Архивировано (PDF) из оригинала 4 июня 2016 года . Проверено 4 августа 2017 г.
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка ) - ^ Чакрабарти, К.Г. и Индранил Чакрабарти. «Энтропия Шеннона: аксиоматическая характеристика и применение». Международный журнал математики и математических наук , 2005. 17 (2005): 2847-2854 URL. Архивировано 5 октября 2021 года в Wayback Machine.
- ^ Эллерман, Дэвид (октябрь 2017 г.). «Теория логической информации: новые логические основы теории информации» (PDF) . Логический журнал IGPL . 25 (5): 806–835. дои : 10.1093/jigpal/jzx022 . Архивировано (PDF) из оригинала 25 декабря 2022 года . Проверено 2 ноября 2022 г.
- ^ Перейти обратно: а б с Ашель, Дж.; Форте, Б.; Нг, Коннектикут (1974). «Почему энтропии Шеннона и Хартли «естественны» ». Достижения в области прикладной теории вероятности . 6 (1): 131–146. дои : 10.2307/1426210 . JSTOR 1426210 . S2CID 204177762 .
- ^ Сравните: Больцман, Людвиг (1896, 1898). Vorlesungen über Gastheorie: 2 тома – Лейпциг, 1895/98 UB: O 5262-6. Английская версия: Лекции по теории газов. Перевод Стивена Г. Браша (1964) Беркли: Издательство Калифорнийского университета; (1995) Нью-Йорк: Дувр ISBN 0-486-68455-5
- ^ Жичковски, Кароль (2006). Геометрия квантовых состояний: введение в квантовую запутанность . Издательство Кембриджского университета. п. 301.
- ^ Шарп, Ким; Мачинский, Франц (2015). «Перевод статьи Людвига Больцмана «О связи второй основной теоремы механической теории теплоты и вероятностных расчетов относительно условий теплового равновесия» » . Энтропия . 17 : 1971–2009. дои : 10.3390/e17041971 .
- ^ Джейнс, ET (15 мая 1957 г.). «Теория информации и статистическая механика» . Физический обзор . 106 (4): 620–630. Бибкод : 1957PhRv..106..620J . дои : 10.1103/PhysRev.106.620 . S2CID 17870175 .
- ^ Ландауэр, Р. (июль 1961 г.). «Необратимость и тепловыделение в вычислительном процессе» . Журнал исследований и разработок IBM . 5 (3): 183–191. дои : 10.1147/рд.53.0183 . ISSN 0018-8646 . Архивировано из оригинала 15 декабря 2021 года . Проверено 15 декабря 2021 г.
- ^ Марк Нельсон (24 августа 2006 г.). «Премия Хаттера» . Архивировано из оригинала 1 марта 2018 года . Проверено 27 ноября 2008 г.
- ^ Перейти обратно: а б «Мировые технологические возможности для хранения, передачи и вычисления информации». Архивировано 27 июля 2013 г. в Wayback Machine , Мартин Гилберт и Присцила Лопес (2011), Science , 332 (6025); бесплатный доступ к статье здесь: martinhilbert.net/WorldInfoCapacity.html.
- ^ Спеллерберг, Ян Ф.; Федор, Питер Дж. (2003). «Дань уважения Клоду Шеннону (1916–2001) и призыв к более строгому использованию видового богатства, видового разнообразия и индекса Шеннона-Винера» . Глобальная экология и биогеография . 12 (3): 177–179. Бибкод : 2003GloEB..12..177S . дои : 10.1046/j.1466-822X.2003.00015.x . ISSN 1466-8238 . S2CID 85935463 .
- ^ Мэсси, Джеймс (1994). «Угадайка и энтропия» (PDF) . Учеб. Международный симпозиум IEEE по теории информации . Архивировано (PDF) из оригинала 1 января 2014 года . Проверено 31 декабря 2013 г.
- ^ Мэлоун, Дэвид; Салливан, Уэйн (2005). «Догадки не заменят энтропию» (PDF) . Материалы конференции по информационным технологиям и телекоммуникациям . Архивировано (PDF) из оригинала 15 апреля 2016 года . Проверено 31 декабря 2013 г.
- ^ Плиам, Джон (1999). «Избранные области криптографии». Международный семинар по избранным областям криптографии . Конспекты лекций по информатике. Том. 1758. стр. 62–77. дои : 10.1007/3-540-46513-8_5 . ISBN 978-3-540-67185-5 .
- ^ Индексы качественной изменчивости.А. Р. Уилкокс – 1967 г. https://www.osti.gov/servlets/purl/4167340
- ^ Тао, Теренс (28 февраля 2016 г.). «Проблема несоответствия Эрдёша» . Дискретный анализ . arXiv : 1509.05363v6 . дои : 10.19086/da.609 . S2CID 59361755 . Архивировано из оригинала 25 сентября 2023 года . Проверено 20 сентября 2023 г.
- ^ Аоки, Новые подходы к макроэкономическому моделированию.
- ^ Вероятность и вычисления, М. Митценмахер и Э. Упфал, Cambridge University Press
- ^ Батра, Мридула; Агравал, Рашми (2018). «Сравнительный анализ алгоритмов дерева решений» . В Паниграхи — Биджая Кетан; Хода, Миннесота; Шарма, Винод; Гоэл, Шивендра (ред.). Компьютеры, вдохновленные природой . Достижения в области интеллектуальных систем и вычислений. Том. 652. Сингапур: Спрингер. стр. 31–36. дои : 10.1007/978-981-10-6747-1_4 . ISBN 978-981-10-6747-1 . Архивировано из оригинала 19 декабря 2022 года . Проверено 16 декабря 2021 г.
- ^ Джейнс, Эдвин Т. (сентябрь 1968 г.). «Априорные вероятности» . Транзакции IEEE по системным наукам и кибернетике . 4 (3): 227–241. дои : 10.1109/TSSC.1968.300117 . ISSN 2168-2887 . Архивировано из оригинала 16 декабря 2021 года . Проверено 16 декабря 2021 г.
- ^ Рубинштейн, Реувен Ю.; Крозе, Дирк П. (9 марта 2013 г.). Метод перекрестной энтропии: унифицированный подход к комбинаторной оптимизации, моделированию Монте-Карло и машинному обучению . Springer Science & Business Media. ISBN 978-1-4757-4321-0 .
Эта статья включает в себя материал из энтропии Шеннона на PlanetMath , который доступен под лицензией Creative Commons Attribution/Share-Alike License .
Дальнейшее чтение
[ редактировать ]Учебники по теории информации
[ редактировать ]- Ковер, Т.М. , Томас, Дж.А. (2006), Элементы теории информации – 2-е изд. , Вили-Интерсайенс, ISBN 978-0-471-24195-9
- Маккей, DJC (2003), Теория информации, логический вывод и алгоритмы обучения , издательство Кембриджского университета, ISBN 978-0-521-64298-9
- Арндт, К. (2004), Информационные меры: информация и ее описание в науке и технике , Springer, ISBN 978-3-540-40855-0
- Грей, Р.М. (2011), Теория энтропии и информации , Springer.
- Мартин, Натаниэль ФГ; Англия, Джеймс В. (2011). Математическая теория энтропии . Издательство Кембриджского университета. ISBN 978-0-521-17738-2 .
- Шеннон, CE , Уивер, В. (1949) Математическая теория связи , Univ of Illinois Press. ISBN 0-252-72548-4
- Стоун, СП (2014), Глава 1 теории информации: введение в учебное пособие. Архивировано 3 июня 2016 г. в Wayback Machine , Университет Шеффилда, Англия. ISBN 978-0956372857 .
Внешние ссылки
[ редактировать ]- «Энтропия» , Энциклопедия математики , EMS Press , 2001 [1994]
- «Энтропия». Архивировано 4 июня 2016 года в Wayback Machine в Rosetta Code — репозитории реализаций энтропии Шеннона на разных языках программирования.
- Энтропия. Архивировано 31 мая 2016 года в междисциплинарном журнале Wayback Machine, посвященном всем аспектам концепции энтропии. Открытый доступ.
сжатия данных Методы |
|---|