Обычные наименьшие квадраты
| Часть серии о |
| Регрессионный анализ |
|---|
| Модели |
| Оценка |
| Фон |

В статистике . обычный метод наименьших квадратов ( OLS ) — это тип линейного метода наименьших квадратов для выбора неизвестных параметров в модели линейной регрессии (с фиксированным первым уровнем) [ нужны разъяснения ] эффекты линейной функции набора объясняющих переменных ) по принципу наименьших квадратов : минимизация суммы квадратов разностей между наблюдаемой зависимой переменной (значениями наблюдаемой переменной) во входном наборе данных и выходе (линейная) функция независимой переменной . Некоторые источники считают OLS линейной регрессией. [1]
Геометрически это рассматривается как сумма квадратов расстояний, параллельных оси зависимой переменной, между каждой точкой данных в наборе и соответствующей точкой на поверхности регрессии — чем меньше различия, тем лучше модель соответствует данным. . Полученную оценку можно выразить простой формулой, особенно в случае простой линейной регрессии находится один регрессор , в которой в правой части уравнения регрессии .
Оценка OLS согласована для фиксированных эффектов первого уровня, когда регрессоры являются экзогенными , и формирует идеальную коллинеарность (условие ранга), согласованную для оценки дисперсии остатков, когда регрессоры имеют конечные четвертые моменты. [2] и - по теореме Гаусса-Маркова - оптимальным в классе линейных несмещенных оценок, ошибки гомоскедастичны и когда серийно некоррелированы . В этих условиях метод МНК обеспечивает несмещенную оценку с минимальной дисперсией, когда ошибки имеют конечные дисперсии . При дополнительном предположении, что ошибки обычно распределяются с нулевым средним значением, OLS является оценщиком максимального правдоподобия , который превосходит любой нелинейный несмещенный оценщик.
Линейная модель
[ редактировать ]Предположим, данные состоят из наблюдения . Каждое наблюдение включает скалярный ответ и вектор-столбец из параметры (регрессоры), т.е. . В модели линейной регрессии переменная отклика , является линейной функцией регрессоров:






![{\displaystyle \mathbf {x} _{i}=\left[x_{i1},x_{i2},\dots,x_{ip}\right]^{\operatorname {T} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3278872b5bdb53e6af3474d92e9926c0238e8935)

или в векторной форме,

где , как было введено ранее, является вектор-столбцом -е наблюдение всех объясняющих переменных; это вектор неизвестных параметров; и скаляр представляет собой ненаблюдаемые случайные величины ( ошибки ) -е наблюдение. учитывает влияние на ответы из источников, отличных от независимых переменных . Эту модель также можно записать в матричной записи как




где и являются векторы переменных отклика и ошибок наблюдения и это матрица регрессоров, также иногда называемая матрицей плана , строка которой является и содержит -ые наблюдения по всем объясняющим переменным.






Обычно в набор регрессоров входит постоянный член скажем, взяв для всех . Коэффициент соответствующий этому регрессору называется перехватом . Без пересечения подобранная линия вынуждена пересекать начало координат, когда .




Регрессоры не обязательно должны быть независимыми, чтобы оценка была последовательной, но мультиколлинеарность делает оценку непоследовательной. В качестве конкретного примера, когда регрессоры не являются независимыми, мы могли бы предположить, что ответ линейно зависит как от значения, так и от его квадрата; в этом случае мы бы включили один регрессор, значение которого равно квадрату другого регрессора. В этом случае модель была бы квадратичной по второму регрессору, но, тем не менее, по-прежнему считается линейной моделью, поскольку модель по-прежнему линейна по параметрам ( ).
Матричная/векторная формулировка
[ редактировать ]Рассмотрим переопределенную систему

из линейные уравнения в неизвестные коэффициенты , , с . Это можно записать в матричной форме как



где

(Примечание: для линейной модели, описанной выше, не все элементы в содержит информацию о точках данных. Первый столбец заполняется единицами, . Только остальные столбцы содержат фактические данные. Итак, здесь равно числу регрессоров плюс один).

Такая система обычно не имеет точного решения, поэтому цель состоит в том, чтобы найти коэффициенты которые «наилучшим образом» соответствуют уравнениям в смысле решения квадратичной минимизации задачи

где целевая функция дается


Обоснование выбора этого критерия приведено в разделе «Свойства» ниже. Эта задача минимизации имеет единственное решение при условии, что столбцы матрицы и линейно независимы определяются путем решения так называемых нормальных уравнений :

Матрица известна как нормальная матрица или матрица Грама , а матрица известна как моментная матрица регрессии и регрессоров. [3] Окончательно, наименьших квадратов вектор коэффициентов гиперплоскости , выраженный как




или

Оценка
[ редактировать ]Предположим, b является значением «кандидата» для вектора параметров β . Величина y i − x i Т b , называемый остатком для i -го наблюдения, измеряет вертикальное расстояние между точкой данных ( x i , y i ) и гиперплоскостью y = x Т b и, таким образом, оценивает степень соответствия фактических данных модели. Сумма квадратов остатков ( SSR ) (также называемая суммой ошибок квадратов ( ESS ) или остаточной суммой квадратов ( RSS )) [4] является мерой общего соответствия модели:

где T матрицы обозначает транспонирование , а строки X , обозначающие значения всех независимых переменных, связанных с конкретным значением зависимой переменной, равны X i = x i Т . Значение b, которое минимизирует эту сумму, называется оценкой МНК для β . Функция S ( b ) квадратична по b с положительно определенным гессианом , и поэтому эта функция обладает единственным глобальным минимумом в точке , что можно задать явной формулой: [5] [доказательство]


Произведение N = X Т X — матрица Грама и обратная ей, Q = N –1 , является матрицей- β кофактором , [6] [7] [8] тесно связана с его ковариационной матрицей C β .Матрица ( X Т Х ) –1 Х Т = Q Х Т называется псевдообратной матрицей Мура-Пенроуза X. Эта формулировка подчеркивает тот факт, что оценка может быть выполнена тогда и только тогда, когда между объясняющими переменными нет идеальной мультиколлинеарности (что привело бы к тому, что матрица грамма не имела обратной).
После того, как мы оценили β , подобранные значения (или прогнозируемые значения ) из регрессии будут

где P = X ( X Т Х ) −1 Х Т — матрица проекции на пространство V, на столбцы X. натянутое Эту матрицу P также иногда называют шляпной матрицей , потому что она «надевает шляпу» на переменную y . Другая матрица, тесно связанная с P , — это аннулятор матрица- M = I n − P ; это матрица проекции на пространство, ортогональное V . Обе матрицы P и M симметричны идемпотентны и что (это означает, P 2 = П и М 2 = M ) и относятся к матрице данных X через тождества PX = X и MX = 0 . [9] Матрица M создает остатки регрессии:

Используя эти остатки, мы можем оценить значение σ 2 используя приведенную статистику хи-квадрат :

Знаменатель n − p — это статистические степени свободы . Первая величина, с 2 , — оценка МНК для σ 2 , тогда как второй, , – оценка MLE для σ 2 . Эти две оценки очень похожи в больших выборках; первая оценка всегда несмещена , тогда как вторая оценка смещена, но имеет меньшую среднеквадратичную ошибку . На практике с 2 используется чаще, так как он более удобен для проверки гипотез. Квадратный корень из s 2 называется стандартной ошибкой регрессии , [10] стандартная ошибка регрессии , [11] [12] или стандартная ошибка уравнения . [9]

Обычно степень соответствия регрессии МНК оценивают путем сравнения того, насколько первоначальная вариация в выборке может быть уменьшена путем регрессии X. на Коэффициент детерминации R 2 определяется как отношение «объяснимой» дисперсии к «общей» дисперсии зависимой переменной y в тех случаях, когда сумма квадратов регрессии равна сумме квадратов остатков: [13]

где TSS — общая сумма квадратов зависимой переменной, , и представляет собой матрицу размера n × n из единиц. ( — центрирующая матрица , эквивалентная регрессии на константу; он просто вычитает среднее значение из переменной.) Чтобы R 2 Чтобы иметь смысл, матрица X данных о регрессорах должна содержать вектор-столбец из единиц, чтобы представлять константу, коэффициент которой является точкой пересечения регрессии. В этом случае Р 2 всегда будет числом от 0 до 1, причем значения, близкие к 1, указывают на хорошую степень соответствия.



Дисперсия в предсказании независимой переменной как функции зависимой переменной приведена в статье Полиномиальные наименьшие квадраты .
Простая модель линейной регрессии
[ редактировать ]Если матрица данных X содержит только две переменные, константу и скалярный регрессор x i , то это называется «простой моделью регрессии». Этот случай часто рассматривается на занятиях по статистике для начинающих, поскольку он дает гораздо более простые формулы, подходящие даже для ручного расчета. Параметры обычно обозначаются как ( α , β ) :

Оценки методом наименьших квадратов в этом случае даются простыми формулами
![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}{(x_{i}-{\bar {x}}) (y_{i}-{\bar {y}})}}{\sum _{i=1}^{n}{(x_{i}-{\bar {x}})^{2}}} }\\[2pt]{\widehat {\alpha }}&={\bar {y}}-{\widehat {\beta }}\,{\bar {x}}\ ,\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/932c6407f7ceba533fef69961fe504fc3b565e1e)
Альтернативные выводы
[ редактировать ]В предыдущем разделе оценка наименьших квадратов было получено как значение, минимизирующее сумму квадратов остатков модели. Однако ту же оценку можно получить и из других подходов. Во всех случаях формула для оценки OLS остается той же: ^ β = ( X Т Х ) −1 Х Т й ; единственная разница заключается в том, как мы интерпретируем этот результат.

Проекция
[ редактировать ]


Возможно, этот раздел необходимо почистить. Он был объединен с методом линейных наименьших квадратов . |
Для математиков МНК — это приближенное решение переопределенной системы линейных уравнений Xβ ≈ y , где β — неизвестное. Предполагая, что система не может быть решена точно (количество уравнений n намного больше числа неизвестных p ), мы ищем решение, которое могло бы обеспечить наименьшее расхождение между правой и левой частями. Другими словами, мы ищем решение, удовлетворяющее

где ‖ · ‖ — стандарт L 2 норма в n -мерном евклидовом пространстве R н . Предсказанная величина Xβ представляет собой некую линейную комбинацию векторов регрессоров. Таким образом, вектор остатка y − Xβ будет иметь наименьшую длину, когда y проецируется ортогонально на линейное подпространство , натянутое столбцами X . Оценщик OLS в этом случае можно интерпретировать как коэффициенты векторного разложения ^ y = Py базиса X. вдоль
Другими словами, уравнения градиента в минимуме можно записать как:

Геометрическая интерпретация этих уравнений состоит в том, что вектор остатков ортогонально пространству столбцов X , поскольку скалярное произведение равен нулю для любого конформного вектора v . Это означает, что является кратчайшим из всех возможных векторов , то есть дисперсия остатков минимально возможная. Это показано справа.




Представляем и матрица K в предположении, что матрица неособ и K Т X = 0 (см. Ортогональные проекции ), вектор невязки должен удовлетворять следующему уравнению:

![{\displaystyle [\mathbf {X} \ \mathbf {K}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac770308f79814997ffbdfd971621c67b76aef6)

Таким образом, уравнение и решение линейного метода наименьших квадратов описываются следующим образом:

Другой способ взглянуть на это — рассматривать линию регрессии как средневзвешенное значение линий, проходящих через комбинацию любых двух точек в наборе данных. [14] Хотя этот способ расчета требует больше вычислительных затрат, он обеспечивает лучшую интуицию при использовании МНК.
Максимальная вероятность
[ редактировать ]Средство оценки OLS идентично средству оценки максимального правдоподобия (MLE) при условии нормальности ошибок. [15] [доказательство] Это предположение о нормальности имеет историческое значение, поскольку оно послужило основой для ранних работ Юла и Пирсона по линейному регрессионному анализу . [ нужна ссылка ] Из свойств MLE мы можем сделать вывод, что оценка OLS асимптотически эффективна (в смысле достижения границы Крамера–Рао для дисперсии), если выполняется предположение о нормальности. [16]
Обобщенный метод моментов
[ редактировать ]В iid случае оценку МНК также можно рассматривать как оценку GMM, возникающую из моментных условий
![{\displaystyle \mathrm {E} {\big [}\,x_{i}\left(y_{i}-x_{i}^{\operatorname {T} }\beta \right)\, {\big ] }=0.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1d7894c141dad7e6dae3aed8bb708aada174daf2)
Эти моментные условия гласят, что регрессоры не должны быть коррелированы с ошибками. Поскольку x i является p -вектором, количество моментных условий равно размерности вектора параметров β и, таким образом, система точно идентифицируется. Это так называемый классический случай GMM, когда оценка не зависит от выбора весовой матрицы.
Обратите внимание, что исходное предположение о строгой экзогенности E[ ε i | x i ] = 0 подразумевает гораздо более богатый набор моментных условий, чем указано выше. В частности, из этого предположения следует, что для любой вектор-функции ƒ будет выполняться моментное условие E[ ƒ ( x i )· ε i ] = 0 . можно показать Однако с помощью теоремы Гаусса-Маркова , что оптимальный выбор функции ƒ состоит в том, чтобы взять ƒ ( x ) = x , что приводит к уравнению момента, опубликованному выше.
Характеристики
[ редактировать ]Предположения
[ редактировать ]Существует несколько различных схем, в которых можно использовать модель линейной регрессии , чтобы сделать применимым метод МНК. Каждая из этих настроек дает одни и те же формулы и одинаковые результаты. Единственная разница заключается в интерпретации и предположениях, которые необходимо сделать, чтобы метод дал значимые результаты. Выбор применимой структуры зависит главным образом от характера имеющихся данных и от задачи вывода, которую необходимо выполнить.
Одно из различий в интерпретации заключается в том, следует ли рассматривать регрессоры как случайные переменные или как заранее определенные константы. В первом случае ( случайный план ) регрессоры xi являются случайными и выбираются вместе с yi совокупности , из некоторой как в обсервационном исследовании . Такой подход позволяет более естественно изучать асимптотические свойства оценок. В другой интерпретации ( фиксированный план ) регрессоры X рассматриваются как известные константы, заданные планом , а выборка y производится условно по значениям X , как в эксперименте . Для практических целей это различие часто не имеет значения, поскольку оценка и вывод выполняются с X. учетом Все результаты, изложенные в этой статье, находятся в рамках метода случайного планирования.
Классическая модель линейной регрессии
[ редактировать ]Классическая модель фокусируется на оценке и выводе «конечной выборки», что означает, что количество наблюдений n фиксировано. Это контрастирует с другими подходами, изучающими асимптотическое поведение МНК и изучающими поведение при большом количестве выборок.
- Правильная спецификация . Линейная функциональная форма должна совпадать с формой реального процесса генерации данных.
- Строгая экзогенность . Ошибки в регрессии должны иметь условный средний ноль: [17] Непосредственным следствием предположения экзогенности является то, что ошибки имеют нулевое среднее значение: E[ ε ] = 0 (для закона полного ожидания ), и что регрессоры не коррелируют с ошибками: E[ X Т ε ] знак равно 0 . Предположение экзогенности имеет решающее значение для теории МНК. Если это справедливо, то переменные регрессора называются экзогенными . Если это не так, то те регрессоры, которые коррелируют с членом ошибки, называются эндогенными , [18] и оценка OLS становится смещенной. В этом случае метод инструментальных переменных . для вывода можно использовать
- Никакой линейной зависимости . Все регрессоры в X должны быть линейно независимыми . Математически это означает, что матрица X должна иметь полный ранг столбца : почти наверняка [19] Обычно также предполагается, что регрессоры имеют конечные моменты, по крайней мере, до второго момента. Тогда матрица Q xx = E[ X Т X / n ] конечно и положительно полуопределено. Когда это предположение нарушается, регрессоры называются линейно зависимыми или совершенно мультиколлинеарными . В таком случае значение коэффициента регрессии β узнать невозможно, хотя предсказание значений y все еще возможно для новых значений регрессоров, лежащих в том же линейно зависимом подпространстве.
- Сферические ошибки : [19] где I n — единичная матрица в размерности n , а σ 2 — это параметр, который определяет дисперсию каждого наблюдения. Это σ 2 считается мешающим параметром в модели , хотя обычно он также оценивается. Если это предположение нарушается, то оценки МНК все еще действительны, но уже не эффективны. Это предположение принято разбивать на две части:
- Гомоскедастичность : E[ ε i 2 | Х ] = п 2 , что означает, что член ошибки имеет ту же дисперсию σ 2 в каждом наблюдении. Когда это требование нарушается, это называется гетероскедастичностью , в таком случае более эффективной оценкой будет метод взвешенных наименьших квадратов . Если ошибки имеют бесконечную дисперсию, то оценки МНК также будут иметь бесконечную дисперсию (хотя по закону больших чисел они, тем не менее, будут стремиться к истинным значениям, пока ошибки имеют нулевое среднее). В этом случае надежные методы оценки . рекомендуется использовать
- Нет автокорреляции : ошибки не коррелируют между наблюдениями: E[ ε i ε j | Икс ] знак равно 0 для я ≠ j . Это предположение может быть нарушено в контексте данных временных рядов , панельных данных , кластерных выборок, иерархических данных, данных повторных измерений, продольных данных и других данных с зависимостями. В таких случаях обобщенный метод наименьших квадратов обеспечивает лучшую альтернативу, чем МНК. Другое выражение автокорреляции — серийная корреляция .
- Нормальность . Иногда дополнительно предполагается, что ошибки имеют нормальное распределение, обусловленное регрессорами: [20] Это предположение не является необходимым для достоверности метода МНК, хотя некоторые дополнительные свойства конечной выборки могут быть установлены в случае, когда это необходимо (особенно в области проверки гипотез). Кроме того, когда ошибки являются нормальными, оценка OLS эквивалентна оценке максимального правдоподобия (MLE) и, следовательно, асимптотически эффективна в классе всех регулярных оценок . Важно отметить, что предположение о нормальности применимо только к погрешностям; Вопреки распространенному заблуждению, ответная (зависимая) переменная не обязательно должна иметь нормальное распределение. [21]
![{\displaystyle \operatorname {E} [\,\varepsilon \mid X\,]=0.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dcdfa07f07180573874658708bc2a889d5416199)
![{\displaystyle \Pr \!{\big [}\,\operatorname {rank} (X)=p\, {\big ]}=1.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6a11be3b89ce51c6441155fddbe512a991132fbf)
![{\displaystyle \operatorname {Var} [\,\varepsilon \mid X\,]=\sigma ^{2}I_{n},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0df70427bd7e0b69175caf9150b2d465dd152474)

Независимые и одинаково распределенные (iid)
[ редактировать ]В некоторых приложениях, особенно с данными поперечного сечения , налагается дополнительное предположение — что все наблюдения независимы и одинаково распределены . Это означает, что все наблюдения берутся из случайной выборки , что упрощает и облегчает интерпретацию всех перечисленных ранее предположений. Также эта структура позволяет формулировать асимптотические результаты (например, размер выборки n → ∞ ), которые понимаются как теоретическая возможность получения новых независимых наблюдений из процесса генерации данных . Список предположений в этом случае следующий:
- наблюдения iid : ( x i , y i ) не зависит от и имеет то же распределение , что и ( x j , y j ) для всех i ≠ j ;
- нет идеальной мультиколлинеарности : Q xx = E[ x i x i Т ] — положительно определенная матрица ;
- экзогенность : E[ ε я | х я ] = 0;
- гомоскедастичность : Var[ ε я | Икс я ] знак равно σ 2 .
Модель временных рядов
[ редактировать ]- Случайный процесс { xi , yi } стационарен и эргодичен ; если { x i , y i } нестационарно, результаты МНК часто оказываются ложными, если только { x i , y i } не является коинтегрирующим . [22]
- Регрессоры заранее определены : E[ x i ε i ] = 0 для всех i = 1, ..., n ;
- Матрица p × p = Q xx E[ x i x i Т ] имеет полный ранг и, следовательно, положительно определен ;
- { x i ε i } — разностная последовательность мартингала с конечной матрицей вторых моментов Q xxε ² = E[ ε i 2 х я х я Т ] .
Конечные свойства выборки
[ редактировать ]Прежде всего, при условии строгой экзогенности оценки МНК и с 2 являются несмещенными , то есть их ожидаемые значения совпадают с истинными значениями параметров: [23] [доказательство]

![{\displaystyle \operatorname {E} [\, {\hat {\beta }}\mid X\,] = \beta,\quad \operatorname {E} [\,s^{2}\mid X\,] =\сигма ^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/67bc2fd0f90c46da207712893fdcea01e729026c)
Если строгая экзогенность не соблюдается (как в случае со многими моделями временных рядов , где экзогенность предполагается только в отношении прошлых потрясений, но не будущих), то эти оценки будут смещены в конечных выборках.
Ковариационная матрица отклонения (или просто ковариационная матрица ) равно [24]
![{\displaystyle \operatorname {Var} [\,{\hat {\beta }}\mid X\,]=\sigma ^{2}\left(X^{\operatorname {T} }X\right)^{ -1}=\sigma ^{2}В.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/08f6cb596d94073731ee47f4a2571dbbfc1d214a)
В частности, стандартная ошибка каждого коэффициента равен квадратному корню из j -го диагонального элемента этой матрицы. Оценка этой стандартной ошибки получается заменой неизвестной величины σ 2 с его оценкой s 2 . Таким образом,


Также легко показать, что оценка не коррелирует с остатками модели: [24]
![{\displaystyle \operatorname {Cov} [\, {\hat {\beta }}, {\hat {\varepsilon }}\mid X\,]=0.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/664c1a5e37957a1aa2ae381b9bcb07350c2c816c)
Теорема Гаусса -Маркова утверждает, что в предположении сферических ошибок (т. е. ошибки должны быть некоррелированными и гомоскедастическими ) оценка эффективен в классе линейных несмещенных оценок. Это называется лучшей линейной несмещенной оценкой (СИНИЙ). Эффективность следует понимать так, как если бы мы нашли какой-то другой оценщик. который был бы линейным по y и несмещенным, тогда [24]

![{\displaystyle \operatorname {Var} [\, {\tilde {\beta }}\mid X\,]-\operatorname {Var} [\, {\hat {\beta }}\mid X\,]\geq 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/53796c9205889cc4d675b9749a58eb97fcd998f1)
в том смысле, что это неотрицательно-определенная матрица . Эта теорема устанавливает оптимальность только в классе линейных несмещенных оценок, что весьма ограничительно. В зависимости от распределения ошибок ε другие нелинейные средства оценки могут давать лучшие результаты, чем OLS.
Предполагая нормальность
[ редактировать ]Все перечисленные выше свойства действительны независимо от основного распределения условий ошибки. Однако если вы готовы предположить, что предположение о нормальности выполнено (т. е. что ε ~ N (0, σ 2 Если n ) ), то можно указать дополнительные свойства оценок МНК.
Оценщик нормально распределяется со средним значением и дисперсией, указанными ранее: [25]

Эта оценка достигает границы Крамера – Рао для модели и, таким образом, является оптимальной в классе всех несмещенных оценок. [16] Обратите внимание, что в отличие от теоремы Гаусса–Маркова этот результат устанавливает оптимальность как среди линейных, так и среди нелинейных оценок, но только в случае нормально распределенных членов ошибки.
Оценщик s 2 будет пропорциональна распределению хи-квадрат : [26]

Дисперсия этой оценки равна 2 σ 4 /( n − p ) , который не достигает границы Крамера–Рао для 2 σ 4 / н . Однако было показано, что несмещенных оценок σ не существует. 2 с дисперсией меньшей, чем у оценки s 2 . [27] Если мы готовы разрешить использование смещенных оценок и рассмотреть класс оценок, которые пропорциональны сумме квадратов остатков (SSR) модели, то лучшей (в смысле среднеквадратической ошибки ) оценки в этом классе будет ~ п 2 = SSR / ( n − p + 2) , что даже превосходит границу Крамера–Рао в случае, когда существует только один регрессор ( p = 1 ). [28]
Более того, оценщики и с 2 независимы , [29] факт, который пригодится при построении t- и F-тестов для регрессии.
Влиятельные наблюдения
[ редактировать ]Как уже говорилось ранее, оценщик является линейным по y , что означает, что оно представляет собой линейную комбинацию зависимых переменных y i . Веса в этой линейной комбинации являются функциями регрессоров X и обычно неравны. Наблюдения с высокими весами называются влиятельными , поскольку они оказывают более выраженное влияние на значение оценки.
Чтобы проанализировать, какие наблюдения оказывают влияние, мы удаляем конкретное j -е наблюдение и рассматриваем, насколько изменятся оцененные величины (аналогично методу складного ножа ). Можно показать, что изменение оценки МНК для β будет равно [30]

где hj = xj Т ( Х Т Х ) −1 x j — j -й диагональный элемент матрицы шляпки P , а x j — вектор регрессоров, соответствующий j -му наблюдению. Аналогично, изменение прогнозируемого значения для j -го наблюдения в результате исключения этого наблюдения из набора данных будет равно [30]

Судя по свойствам матрицы шляпы, 0 ≤ h j ≤ 1 , и они суммируются до p , так что в среднем h j ≈ p/n . Эти величины называются hj рычагами , а наблюдения с высокими hj называются рычага точками . [31] Обычно наблюдения с высоким уровнем влияния следует проверять более тщательно, если они ошибочны, являются выбросами или каким-либо другим образом нетипичны для остального набора данных.
Разделенная регрессия
[ редактировать ]Иногда переменные и соответствующие параметры регрессии можно логически разделить на две группы, чтобы регрессия приняла форму

где X 1 и X 2 имеют размеры n × p 1 , n × p 2 , а β 1 , β 2 представляют собой векторы p 1 × 1 и p 2 × 1, причем p 1 + p 2 = p .
Теорема Фриша – Во – Ловелла утверждает, что в этой регрессии остатки и оценка МНК будут численно идентичны остаткам и оценке МНК для β 2 в следующей регрессии: [32]



где M 1 — матрица аннулятора для регрессоров X 1 .
Теорема может быть использована для установления ряда теоретических результатов. Например, наличие регрессии с константой и другим регрессором эквивалентно вычитанию средних значений из зависимой переменной и регрессора, а затем запуску регрессии для переменных с пониженным значением, но без постоянного члена.
Ограниченная оценка
[ редактировать ]Предположим, известно, что коэффициенты регрессии удовлетворяют системе линейных уравнений

где Q — p × q матрица полного ранга размера , а c — размера q вектор известных констант × 1, где q < p . наименьших квадратов эквивалентна минимизации суммы квадратов остатков модели с учетом ограничения A. В этом случае оценка методом Оценка методом наименьших квадратов с ограничениями (CLS) может быть задана явной формулой: [33]

Это выражение для ограниченной оценки справедливо до тех пор, пока матрица X Т X обратим. В начале статьи предполагалось, что эта матрица имеет полный ранг, и было отмечено, что при невыполнении условия ранга β не будет идентифицируемой. Однако может случиться так, что добавление ограничения A сделает β идентифицируемым, и в этом случае хотелось бы найти формулу для оценки. Оценка равна [34]

где R — матрица размера p ×( p − q ) такая, что матрица [ QR ] невырождена, а R Т Q = 0 . Такую матрицу всегда можно найти, хотя, как правило, она не единственна. Вторая формула совпадает с первой в случае, когда X Т X обратим. [34]
Большой образец недвижимости
[ редактировать ]Оценщики методом наименьших квадратов представляют собой точечные оценки параметров модели линейной регрессии β . Однако, как правило, мы также хотим знать, насколько близки эти оценки к истинным значениям параметров. Другими словами, мы хотим построить интервальные оценки .
Поскольку мы не сделали никаких предположений о распределении члена ошибки ε i , невозможно вывести распределение оценок и . Тем не менее, мы можем применить центральную предельную теорему , чтобы получить их асимптотические свойства, когда размер выборки n стремится к бесконечности. Хотя размер выборки обязательно конечен, принято предполагать, что n «достаточно велико», так что истинное распределение оценки OLS близко к своему асимптотическому пределу.

что при предположениях модели оценка наименьших квадратов для β непротиворечива Мы можем показать , (т.е. сходится по вероятности к β ) и асимптотически нормально: [доказательство]

где

Интервалы
[ редактировать ]Используя это асимптотическое распределение, аппроксимируйте двусторонние доверительные интервалы для j -го компонента вектора. может быть построен как
- на уровне достоверности 1 - α ,
![{\displaystyle \beta _{j}\in {\bigg [}\ {\hat {\beta }}_{j}\pm q_{1-{\frac {\alpha }{2}}}^{{ \mathcal {N}}(0,1)}\!{\sqrt {{\hat {\sigma }}^{2}\left[Q_{xx}^{-1}\right]_{jj}} }\ {\бигг ]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf79688aac9f662ff39253fbfb0d234246d370e5)
где q обозначает функцию квантиля стандартного нормального распределения, а [·] jj — j -й диагональный элемент матрицы.
Аналогично, оценка методом наименьших квадратов для σ 2 также непротиворечива и асимптотически нормальна (при условии существования четвертого момента ε i ) с предельным распределением
![{\displaystyle ({\hat {\sigma }}^{2}-\sigma ^{2})\ {\xrightarrow {d}}\ {\mathcal {N}}\left(0,\;\operatorname { E} \left[\varepsilon _{i}^{4}\right]-\sigma ^{4}\right).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7c909dea2a4f0bf40e253680b953d1bfbb66298f)
Эти асимптотические распределения можно использовать для прогнозирования, проверки гипотез, построения других оценок и т. д. В качестве примера рассмотрим задачу прогнозирования. Предполагать — это некоторая точка в области распределения регрессоров, и нужно знать, какой была бы переменная отклика в этой точке. Средний ответ – это количество , тогда как прогнозируемый ответ . Очевидно, что прогнозируемый ответ является случайной величиной, его распределение можно получить из распределения :




что позволяет построить доверительные интервалы для среднего ответа предстоит построить:

- на уровне достоверности 1- α .
![{\displaystyle y_{0}\in \left[\ x_{0}^{\mathrm {T} }{\hat {\beta }}\pm q_{1-{\frac {\alpha }{2}} }^{{\mathcal {N}}(0,1)}\!{\sqrt {{\hat {\sigma }}^{2}x_{0}^{\mathrm {T} }Q_{xx} ^{-1}x_{0}}}\ \right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf86d7a311c97d35fb6e039c3cd74bc9f3e752bf)
Проверка гипотез
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( февраль 2017 г. ) |
Особенно широко используются два теста гипотез. Во-первых, нужно знать, является ли предполагаемое уравнение регрессии чем-то лучше, чем простое предсказание того, что все значения переменной отклика равны ее выборочному среднему (если нет, то говорят, что оно не имеет объяснительной силы). Нулевая гипотеза об отсутствии объяснительной ценности оцененной регрессии проверяется с помощью F-теста . Если вычисленное значение F оказывается достаточно большим, чтобы превысить его критическое значение для заранее выбранного уровня значимости, нулевая гипотеза отклоняется и альтернативная гипотеза принимается о том, что регрессия имеет объяснительную силу. В противном случае принимается нулевая гипотеза об отсутствии объяснительной силы.
Во-вторых, для каждой интересующей объясняющей переменной нужно знать, значительно ли ее расчетный коэффициент отличается от нуля, то есть действительно ли эта конкретная объясняющая переменная обладает объяснительной силой в предсказании переменной отклика. Здесь нулевая гипотеза состоит в том, что истинный коэффициент равен нулю. коэффициента Эта гипотеза проверяется путем вычисления t-статистики как отношения оценки коэффициента к его стандартной ошибке . Если t-статистика больше заранее определенного значения, нулевая гипотеза отклоняется и обнаруживается, что переменная имеет объяснительную силу, а ее коэффициент значительно отличается от нуля. В противном случае принимается нулевая гипотеза о нулевом значении истинного коэффициента.
Кроме того, тест Чоу используется для проверки того, имеют ли две подвыборки одинаковые значения истинного коэффициента. Сумма квадратов остатков регрессий в каждом из подмножеств и в объединенном наборе данных сравнивается путем вычисления F-статистики; если оно превышает критическое значение, нулевая гипотеза об отсутствии различий между двумя подмножествами отклоняется; в противном случае оно принимается.
Пример с реальными данными
[ редактировать ]В следующем наборе данных приведены средние показатели роста и веса американских женщин в возрасте 30–39 лет (источник: Всемирный альманах и Книга фактов, 1975 ).
Высота (м) 1.47 1.50 1.52 1.55 1.57 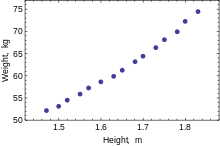
Диаграмма рассеяния данных: зависимость слегка изогнута, но близка к линейной. Вес (кг) 52.21 53.12 54.48 55.84 57.20 Высота (м) 1.60 1.63 1.65 1.68 1.70 Вес (кг) 58.57 59.93 61.29 63.11 64.47 Высота (м) 1.73 1.75 1.78 1.80 1.83 Вес (кг) 66.28 68.10 69.92 72.19 74.46

Когда моделируется только одна зависимая переменная, диаграмма рассеяния покажет форму и силу связи между зависимой переменной и регрессорами. Это также может выявить выбросы, гетероскедастичность и другие аспекты данных, которые могут усложнить интерпретацию подобранной регрессионной модели. Диаграмма рассеяния показывает, что связь сильная и может быть аппроксимирована квадратичной функцией. OLS может обрабатывать нелинейные отношения, вводя регрессор HEIGHT. 2 . Затем регрессионная модель становится множественной линейной моделью:

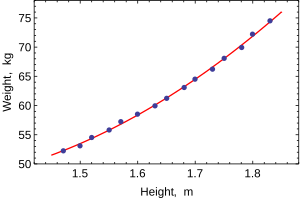
Вывод большинства популярных статистических пакетов будет выглядеть примерно так:
Метод Наименьшие квадраты Зависимая переменная МАССА Наблюдения 15 Параметр Ценить Стандартная ошибка t-статистика p-значение 128.8128 16.3083 7.8986 0.0000 –143.1620 19.8332 –7.2183 0.0000 61.9603 6.0084 10.3122 0.0000 Р 2 0.9989 SE регрессии 0.2516 Скорректированный R 2 0.9987 Модель суммы кв. 692.61 Логарифмическое правдоподобие 1.0890 Остаточная сумма кв. 0.7595 Статистика Дурбина-Ватсона. 2.1013 Общая сумма кв. 693.37 Критерий Акаике 0.2548 F-статистика 5471.2 критерий Шварца 0.3964 p-значение (F-статистика) 0.0000


В этой таблице:
- В столбце «Значение» приведены оценки параметров β j по методу наименьших квадратов.
- В столбце «Стандартная ошибка» показаны стандартные ошибки оценки каждого коэффициента:
- и Столбцы t-статистики p -значения проверяют, может ли какой-либо из коэффициентов быть равен нулю. - статистика t рассчитывается просто как . Если ошибки ε подчиняются нормальному распределению, t соответствует распределению Стьюдента. При более слабых условиях t асимптотически нормально. Большие значения t указывают на то, что нулевую гипотезу можно отвергнуть и что соответствующий коэффициент не равен нулю. Второй столбец, p -value , выражает результаты проверки гипотезы как уровень значимости . Обычно значения p меньше 0,05 считаются свидетельством того, что коэффициент численности населения не равен нулю.
- R-квадрат — это коэффициент детерминации , указывающий на степень соответствия регрессии. Эта статистика будет равна единице, если соответствие идеальное, и нулю, когда регрессоры X не имеют никакой объяснительной силы. Это смещенная оценка генерального R-квадрата , и она никогда не уменьшится, если будут добавлены дополнительные регрессоры, даже если они не имеют значения.
- Скорректированный R-квадрат — это слегка модифицированная версия , предназначенный для наказания за избыточное количество регрессоров, которые не увеличивают объяснительную силу регрессии. Эта статистика всегда меньше, чем , может уменьшаться по мере добавления новых регрессоров и даже быть отрицательным для плохо подходящих моделей:
![{\displaystyle {\hat {\sigma }}_{j}=\left({\hat {\sigma }}^{2}\left[Q_{xx}^{-1}\right]_{jj} \right)^{\frac {1}{2}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5087e66171bf3ef9ad3ac75decdd715274919669)



- Логарифмическое правдоподобие рассчитывается в предположении, что ошибки подчиняются нормальному распределению. Несмотря на то, что это предположение не очень разумно, эта статистика все же может найти применение при проведении LR-тестов.
- Статистика Дурбина-Ватсона проверяет, существуют ли какие-либо доказательства серийной корреляции между остатками. Как правило, значение меньше 2 будет свидетельствовать о положительной корреляции.
- Информационный критерий Акаике и критерий Шварца используются для выбора модели. Обычно при сравнении двух альтернативных моделей меньшие значения одного из этих критериев указывают на лучшую модель. [35]
- Стандартная ошибка регрессии — это оценка σ , стандартной ошибки термина ошибки.
- Общая сумма квадратов , модельная сумма квадратов и остаточная сумма квадратов говорят нам, какая часть исходных изменений в выборке была объяснена регрессией.
- F-статистика пытается проверить гипотезу о том, что все коэффициенты (кроме точки пересечения) равны нулю. Эта статистика имеет распределение F ( p – 1 , n – p ) при нулевой гипотезе и предположении нормальности, а ее значение p указывает на вероятность того, что гипотеза действительно верна. другие тесты, такие как тест Вальда или тест LR . Обратите внимание: если ошибки не являются нормальными, эта статистика становится недействительной, и следует использовать

Обычный анализ методом наименьших квадратов часто включает использование диагностических графиков, предназначенных для обнаружения отклонений данных от предполагаемой формы модели. Вот некоторые из распространенных диагностических графиков:
- Остатки от объясняющих переменных в модели. Нелинейная связь между этими переменными предполагает, что линейность условной средней функции может не соблюдаться. Различные уровни изменчивости остатков для разных уровней объясняющих переменных позволяют предположить возможную гетероскедастичность.
- Остатки от объясняющих переменных, которых нет в модели. Любая связь остатков с этими переменными предполагает рассмотрение этих переменных для включения в модель.
- Остатки против подобранных значений, .
- Остатки против предыдущего остатка. Этот график может выявить серийные корреляции в остатках.

Важным фактором при выполнении статистических выводов с использованием регрессионных моделей является способ выборки данных. В этом примере данные представляют собой средние значения, а не измерения по отдельным женщинам. Подгонка модели очень хорошая, но это не означает, что вес отдельной женщины можно с высокой точностью предсказать, основываясь только на ее росте.
Чувствительность к округлению
[ редактировать ]Этот пример также демонстрирует, что коэффициенты, определенные в результате этих расчетов, чувствительны к тому, как подготавливаются данные. Первоначально высоты были округлены до ближайшего дюйма, а затем были преобразованы и округлены до ближайшего сантиметра. Поскольку коэффициент преобразования составляет один дюйм в 2,54 см, это не точное преобразование. Исходные дюймы можно восстановить с помощью Round(x/0,0254), а затем повторно преобразовать в метрические без округления. Если это сделать, результаты будут такими:
| Конст | Высота | Высота 2 | |
|---|---|---|---|
| Преобразовано в метрическую систему с округлением. | 128.8128 | −143.162 | 61.96033 |
| Преобразовано в метрическую систему без округления. | 119.0205 | −131.5076 | 58.5046 |
Использование любого из этих уравнений для прогнозирования веса женщины ростом 5 футов 6 дюймов (1,6764 м) дает аналогичные значения: 62,94 кг с округлением против 62,98 кг без округления. Таким образом, кажущееся небольшим изменение данных оказывает реальное влияние на коэффициенты. но небольшое влияние на результаты уравнения.
Хотя это может выглядеть безобидным в середине диапазона данных, оно может стать значимым в крайних точках или в случае, когда подобранная модель используется для проецирования за пределы диапазона данных ( экстраполяция ).
Это подчеркивает распространенную ошибку: этот пример представляет собой злоупотребление МНК, которое по своей сути требует, чтобы ошибки в независимой переменной (в данном случае высоте) были нулевыми или, по крайней мере, незначительными. Первоначальное округление до ближайшего дюйма плюс любые фактические ошибки измерения составляют конечную и существенную ошибку. В результате подобранные параметры не являются лучшими оценками, какими они предположительно являются. Хотя это и не совсем ложно, ошибка в оценке будет зависеть от относительного размера ошибок x и y .
Еще один пример с менее реальными данными
[ редактировать ]Постановка задачи
[ редактировать ]Мы можем использовать механизм наименьших квадратов, чтобы вычислить уравнение орбиты двух тел в полярных базовых координатах. Обычно используется уравнение где это радиус того, как далеко объект находится от одного из тел. В уравнении параметры и используются для определения траектории орбиты. Мы измерили следующие данные.



| (в градусах) | 43 | 45 | 52 | 93 | 108 | 116 |
|---|---|---|---|---|---|---|
| 4.7126 | 4.5542 | 4.0419 | 2.2187 | 1.8910 | 1.7599 |

Нам нужно найти приближение метода наименьших квадратов и для приведенных данных.
Решение
[ редактировать ]Сначала нам нужно представить e и p в линейной форме. Итак, мы перепишем уравнение как . Кроме того, можно было бы уместить апсиды , расширив с дополнительным параметром как , который линеен в обоих случаях и в дополнительной базисной функции , привык к дополнительному . Мы используем исходную двухпараметрическую форму для представления наших данных наблюдений как:





где является и является и строится по первому столбцу, представляющему собой коэффициент при а второй столбец представляет собой коэффициент и значения для соответствующих так и










Решив, получим

так и


См. также
[ редактировать ]- Байесовский метод наименьших квадратов
- Регрессия Фамы – Макбета
- Нелинейный метод наименьших квадратов
- Численные методы линейного метода наименьших квадратов
- Идентификация нелинейной системы
Ссылки
[ редактировать ]- ^ «Происхождение обычных предположений наименьших квадратов» . Колонка функций . 01.03.2022 . Проверено 16 мая 2024 г.
- ^ «Каков полный список обычных предположений линейной регрессии?» . Крест проверен . Проверено 28 сентября 2022 г.
- ^ Гольдбергер, Артур С. (1964). «Классическая линейная регрессия» . Эконометрическая теория . Нью-Йорк: Джон Уайли и сыновья. стр. 158 . ISBN 0-471-31101-4 .
- ^ Хаяси, Фумио (2000). Эконометрика . Издательство Принстонского университета. п. 15.
- ^ Хаяси (2000 , стр. 18)
- ^ Гилани, Чарльз Д.; Пол Р. Вольф, доктор философии (12 июня 2006 г.). Корректирующие расчеты: пространственный анализ данных . ISBN 9780471697282 .
- ^ Хофманн-Велленхоф, Бернхард; Лихтенеггер, Герберт; Васл, Эльмар (20 ноября 2007 г.). GNSS – глобальные навигационные спутниковые системы: GPS, ГЛОНАСС, Galileo и другие . ISBN 9783211730171 .
- ^ Сюй, Гочан (5 октября 2007 г.). GPS: теория, алгоритмы и приложения . ISBN 9783540727156 .
- ^ Перейти обратно: а б Хаяси (2000 , стр. 19)
- ^ Джулиан Фарауэй (2000), Практическая регрессия и Anova с использованием R
- ^ Кенни, Дж.; Хранение, Е.С. (1963). Математика статистики . ван Ностранд. п. 187.
- ^ Цвиллингер, Д. (1995). Стандартные математические таблицы и формулы . Чепмен и Холл/CRC. п. 626. ИСБН 0-8493-2479-3 .
- ^ Хаяши (2000 , стр. 20)
- ^ Акбарзаде, Вахаб (7 мая 2014 г.). «Оценка линии» .
- ^ Хаяси (2000 , стр. 49)
- ^ Перейти обратно: а б Хаяси (2000 , стр. 52)
- ^ Хаяси (2000 , стр. 7)
- ^ Хаяси (2000 , стр. 187)
- ^ Перейти обратно: а б Хаяси (2000 , стр. 10)
- ^ Хаяси (2000 , стр. 34)
- ^ Уильямс, Миннесота; Грахалес, Калифорния; Куркевич, Д (2013). «Предположения множественной регрессии: исправление двух заблуждений» . Практическая оценка, исследования и оценка . 18 (11).
- ^ «Напоминание о выводе EViews» (PDF) . Проверено 28 декабря 2020 г.
- ^ Хаяси (2000 , стр. 27, 30)
- ^ Перейти обратно: а б с Хаяси (2000 , стр. 27)
- ^ Амемия, Такеши (1985). Продвинутая эконометрика . Издательство Гарвардского университета. п. 13 . ISBN 9780674005600 .
- ^ Амемия (1985 , стр. 14)
- ^ Рао, ЧР (1973). Линейный статистический вывод и его приложения (второе изд.). Нью-Йорк: Дж. Уайли и сыновья. п. 319. ИСБН 0-471-70823-2 .
- ^ Амемия (1985 , стр. 20)
- ^ Амемия (1985 , стр. 27)
- ^ Перейти обратно: а б Дэвидсон, Рассел; Маккиннон, Джеймс Г. (1993). Оценка и вывод в эконометрике . Нью-Йорк: Издательство Оксфордского университета. п. 33. ISBN 0-19-506011-3 .
- ^ Дэвидсон и Маккиннон (1993 , стр. 36)
- ^ Дэвидсон и Маккиннон (1993 , стр. 20)
- ^ Амемия (1985 , стр. 21)
- ^ Перейти обратно: а б Амемия (1985 , стр. 22)
- ^ Бернэм, Кеннет П.; Дэвид Андерсон (2002). Выбор модели и многомодельный вывод (2-е изд.). Спрингер. ISBN 0-387-95364-7 .
Дальнейшее чтение
[ редактировать ]- Догерти, Кристофер (2002). Введение в эконометрику (2-е изд.). Нью-Йорк: Издательство Оксфордского университета. стр. 48–113. ISBN 0-19-877643-8 .
- Гуджарати, Дамодар Н .; Портер, Дон К. (2009). Базовая экономика (Пятое изд.). Бостон: МакГроу-Хилл Ирвин. стр. 55–96. ISBN 978-0-07-337577-9 .
- Привет, Кристиан; Фармер, Пол; Фрэнсис, Филип Х.; Клок, Теун; ван Дейк, Герман К. (2004). Эконометрические методы с применением в бизнесе и экономике (1-е изд.). Оксфорд: Издательство Оксфордского университета. стр. 76–115. ISBN 978-0-19-926801-6 .
- Хилл, Р. Картер; Гриффитс, Уильям Э.; Лим, Гуай К. (2008). Принципы эконометрики (3-е изд.). Хобокен, Нью-Джерси: John Wiley & Sons. стр. 8–47. ISBN 978-0-471-72360-8 .
- Вулдридж, Джеффри (2008). «Простая модель регрессии» . Вводная эконометрика: современный подход (4-е изд.). Мейсон, Огайо: Cengage Learning. стр. 22–67. ISBN 978-0-324-58162-1 .
| Вычислительная статистика | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Корреляция и зависимость | |||||||||
| Регрессионный анализ | |||||||||
| Регрессия как статистическая модель |
| ||||||||
| Разложение дисперсии | |||||||||
| Исследование модели | |||||||||
| Фон | |||||||||
| Планирование экспериментов | |||||||||
| Численное приближение | |||||||||
| Приложения | |||||||||