Расширенный код Unix
В этой статье есть несколько проблем. Пожалуйста, помогите улучшить его или обсудите эти проблемы на странице обсуждения . ( Узнайте, как и когда удалять эти шаблонные сообщения )
|
Расширенный код Unix ( EUC ) — это многобайтовая система кодирования символов , используемая в основном для японского , корейского и символов упрощенного китайского языков .
Наиболее часто используемые коды EUC — это кодировки переменной длины , в которых символ, принадлежащий набору кодированных символов, совместимому с ISO/IEC 646 (например, ASCII ), занимает один байт, и символ, принадлежащий набору кодированных символов 94×94 (например, GB). 2312 ), представленный двумя байтами. EUC -CN Форма GB 2312 и EUC-KR являются примерами таких двухбайтовых кодов EUC. EUC-JP включает символы, представленные тремя байтами, включая начальный код сдвига , тогда как один символ в EUC-TW может занимать до четырех байтов.
Современные приложения с большей вероятностью будут использовать UTF-8 , который поддерживает все символы кодов EUC и многое другое и, как правило, более переносим с меньшим количеством отклонений и ошибок поставщиков. Однако EUC по-прежнему очень популярен, особенно EUC-KR для Южной Кореи.
Структура кодирования [ править ]

Структура EUC основана на стандарте ISO/IEC 2022 , который определяет систему наборов графических символов, которые могут быть представлены последовательностью из 94 7-битных байтов 0x21–7E или, альтернативно, 0xA1–FE, если восьмой бит доступен. Это позволяет использовать наборы из 94 графических символов или 8836 (94 2 ) символов, или 830584 (94 3 ) персонажи. Хотя изначально 0x20 и 0x7F всегда были пробелом и символ удаления , а 0xA0 и 0xFF не использовались, более поздние редакции ISO/IEC 2022 разрешали использование байтов 0xA0 и 0xFF (или 0x20 и 0x7F) в наборах при определенных обстоятельствах, что позволяло включать наборы из 96 символов. Диапазоны 0x00–1F и 0x80–9F используются для управляющих кодов C0 и C1 .
EUC — это семейство 8-битных профилей ISO/IEC 2022 , в отличие от 7-битных профилей, таких как ISO-2022-JP . Таким образом, только наборы символов, соответствующие стандарту ISO 2022, могут иметь формы EUC. С помощью схемы EUC можно представить до четырех наборов кодированных символов (называемых G0, G1, G2 и G3 или кодовых наборов 0, 1, 2 и 3). Набор G0 установлен на набор кодированных символов, совместимый со стандартом ISO/IEC 646, такой как US-ASCII , ISO 646:KR ( KS X 1003 ) или ISO 646:JP (нижняя половина JIS X 0201 ), и вызывается через GL (т. е. 0x21–0x7E, при этом старший бит очищен). [1] Если используется US-ASCII, это делает код расширенной кодировкой ASCII ; Наиболее распространенным отклонением от US-ASCII является то, что 0x5C ( обратная косая черта в US-ASCII) часто используется для обозначения знака иены в EUC-JP (см. ниже) и знака вон в EUC-KR.
Другие наборы кодов вызываются через GR (т.е. с набором старших битов). Следовательно, чтобы получить форму EUC символа, устанавливается старший бит каждого байта кодирования (что эквивалентно добавлению 128 к каждому 7-битному байту кодирования или добавлению 160 к каждому числу в коде кутен ); ли конкретный байт в строке символов это позволяет программному обеспечению легко определить, принадлежит коду ISO 646 или расширенному коду. Символам в кодовых наборах 2 и 3 предшествуют управляющие коды. СС2 (0x8E) и SS3 (0x8F) соответственно и вызывается через GR. Помимо исходного кода сдвига, любой байт за пределами диапазона 0xA0–0xFF, появляющийся в символе из наборов кодов с 1 по 3, не является допустимым кодом EUC. [1]
Сам код EUC не использует последовательности объявлений и обозначений из ISO 2022 . [1] Однако спецификация кода эквивалентна следующей последовательности из четырех последовательностей объявлений ISO 2022 , значения которых распределяются следующим образом. [1]
| Индивидуальная последовательность | Шестнадцатеричный | Особенность EUC обозначена |
|---|---|---|
ESC SP C | 1B 20 43 | ISO-8 (8 бит, G0 в GL, G1 в GR) |
ESC SP Z | 1B 20 5A | Доступ к G2 осуществляется через SS2 |
ESC SP [ | 1B 20 5B | Доступ к G3 осуществляется через SS3 |
ESC SP \ | 1B 20 5C | Односменный вызов через GR |
Формат фиксированной длины [ править ]

на основе ISO-2022 Описанное выше кодирование переменной длины иногда называют упакованным форматом EUC , который представляет собой формат кодирования, обычно обозначаемый как EUC. Однако при внутренней обработке данных EUC может использоваться формат преобразования фиксированной длины, называемый полным двухбайтовым форматом EUC . Это представляет собой: [2]
- Код устанавливает 0 как два байта в диапазоне 0x21–0x7E (за исключением того, что первый может быть 0x00).
- Кодовый набор 1 состоит из двух байтов в диапазоне 0xA0–0xFF (за исключением того, что первый может быть 0x80).
- Кодовый набор 2 представляет собой байт в диапазоне 0x21–0x7E (или 0x00), за которым следует байт в диапазоне 0xA0–0xFF.
- Кодовый набор 3 представляет собой байт в диапазоне 0xA0–0xFF (или 0x80), за которым следует байт в диапазоне 0x21–0x7E.
Начальные байты 0x00 и 0x80 используются в тех случаях, когда набор кодов использует только один байт. Существует также четырехбайтовый формат фиксированной длины. [2] Эти форматы кодирования фиксированной длины подходят для внутренней обработки и обычно не встречаются при обмене.
EUC-JP зарегистрирован в IANA в обоих форматах: упакованном формате как «EUC-JP» или «csEUCPkdFmtJapanese» и формате фиксированной ширины как «csEUCFixWidJapanese». [3] Только упакованный формат включен в стандарт кодирования WHATWG, используемый HTML5 . [4]
EUC-CN [ править ]
 | |
| МИМ / IANA | ГБ2312 |
|---|---|
| Псевдоним(а) | csGB2312, CN-ГБ [5] |
| Язык(и) | Упрощенный китайский , английский , русский |
| Стандартный | ГБ 2312 (1980) |
| Классификация | Расширенный ASCII , кодировка переменной длины , кодировка CJK , EUC |
| Расширяет | США-ASCII |
| Расширения | 748, ГБК , ГБ 18030 , x-mac-chinesesimp |
| Преобразует/кодирует | ГБ 2312 |
| Преемник | ГБК , ГБ 18030 |
EUC-CN [6] — это обычная закодированная форма стандарта GB 2312 для упрощенных китайских иероглифов . В отличие от японского JIS X 0208 и ISO-2022-JP , GB 2312 обычно не используется в 7-битной версии кода ISO 2022 . [а] вариантная форма под названием HZ (которая ограничивает текст GB 2312 иногда использовалась хотя в USENET последовательностями ASCII) .
Символ ASCII представлен в своей обычной кодировке. Символ из GB 2312 представлен двумя байтами, оба из диапазона 0xA1–0xFE.
748 код [ править ]
Кодировка, связанная с EUC-CN, - это код «748», используемый в системе набора текста WITS, разработанной пекинской компанией Founder Technology (теперь устаревшей из-за ее новой системы набора текста FITS). Код 748 содержит весь код GB 2312 , но не соответствует стандарту ISO 2022 и, следовательно, не является настоящим кодом EUC. (Он использует 8-битный ведущий байт, но различает второй байт с установленным старшим битом и один с очищенным старшим битом, и, следовательно, по структуре больше похож на Big5 не соответствующие ISO 2022. и другие DBCS, системы кодирования.) Часть кода 748, отличная от GB2312, содержит традиционные и гонконгские символы, а также другие глифы, используемые при наборе газет.
страницы IBM 1380, 1381, 1382 и 1383 Кодовые
Кодовая страница IBM 1381 ( CCSID 1381) состоит из однобайтовой кодовой страницы 1115 (CPGID 1115 как CCSID 1115) и двухбайтовой кодовой страницы 1380 (CPGID 1380 как CCSID 1380). [7] который кодирует GB 2312 так же, как EUC-CN, но отличается от структуры EUC, расширяя диапазон ведущих байтов обратно до 0x8C, добавляя 31 выбранный IBM символ в диапазонах от 0x8CE0 до 0x8CFE и добавляя 1880 пользовательских символов с ведущими байтами от 0x8D до 0xА0. [8]
Кодовая страница IBM 1383 (CCSID 1383) включает однобайтовую кодовую страницу 367 и двухбайтовую кодовую страницу 1382 (CPGID 1382 как CCSID 1382), [9] который отличается тем, что соответствует структуре EUC, добавляя вместо этого 31 выбранный IBM символ в диапазонах от 0xFEE0 до 0xFEFE и включая только 1360 определяемых пользователем символов, вкрапленных в позиции, не используемые в GB 2312. [10] Альтернативный CCSID 5479. [11] используется для чистой кодовой страницы EUC-CN: в качестве двухбайтового набора используется CCSID 9574, который использует CPGID 1382, но исключает символы, выбранные IBM и определяемые пользователем. [12]
ГБК и ГБ 18030 [ править ]
GBK является расширением GB 2312 . Он определяет расширенную форму кодировки EUC-CN, способную представлять больший массив символов CJK, полученных в основном из Unicode 1.1 , включая традиционные китайские символы и символы, используемые только в японском языке . Однако это не настоящий код EUC, поскольку байты ASCII могут отображаться как завершающие байты (а байты C1 , не ограничиваясь одиночными сдвигами, могут отображаться как начальные или завершающие байты) из-за того, что требуется большее пространство для кодирования.
Варианты GBK реализуются с помощью кодовой страницы Windows 936 ( Microsoft Windows кодовая страница для упрощенного китайского языка) и кодовой страницы IBM 1386.
на основе Unicode Кодировка символов GB 18030 определяет расширение GBK, способное кодировать весь Unicode . Однако Unicode, закодированный как GB 18030, представляет собой кодировку переменной длины , которая может использовать до четырех байтов на символ из-за того, что требуется еще большее пространство для кодирования. Будучи расширением GBK, он представляет собой надстройку EUC-CN, но сам по себе не является настоящим кодом EUC. Будучи кодировкой Unicode, ее репертуар идентичен репертуару других форматов преобразования Unicode, таких как UTF-8 .
Mac OS китайский упрощенный [ править ]
Другие варианты EUC-CN, отличающиеся от механизма EUC, включают упрощенный китайский сценарий Mac OS (известный как кодовая страница 10008 или x-mac-chinesesimp). [13] Он использует байты 0x80, 0x81, 0x82, 0xA0, 0xFD, 0xFE и 0xFF для U с умляутом (ü), двумя специальными символами метрики шрифта, неразрывным пробелом , знаком авторских прав (©), знаком товарного знака ( ™) и многоточие (…) соответственно. [6] Это отличается тем, что считается однобайтовым символом, по сравнению с первым байтом двухбайтового символа как из EUC (где 0xFD и 0xFE определены как ведущие байты), так и из GBK (где из них 0x81, 0x82, 0xFD и 0xFE определяются как ведущие байты).
Такое использование 0xA0, 0xFD, 0xFE и 0xFF соответствует варианту Apple Shift_JIS .
Помимо этих изменений в диапазоне ведущих байтов, другой отличительной особенностью двухбайтовой части Mac OS Chinese Simplified является включение двух расширений к базовому набору GB 2312-80 в строках 6 и 8. [6] Они считаются «стандартными расширениями GB 2312», ни одно из которых не является собственностью Apple: расширение строки 8 было взято из GB 6345.1 . [6] оба расширения включены в GB/T 12345 (традиционный китайский вариант GB 2312), [14] и оба расширения включены в GB 18030 (преемник GB 2312). [15]
EUC-JP [ править ]
 | |
| МИМ / IANA | EUC-JP |
|---|---|
| Псевдоним(а) | Unixized JIS (UJIS), csEUCPkdFmtЯпонский |
| Язык(и) | японский , английский , русский |
| Классификация | Расширенный ISO 646 , кодировка переменной длины , кодировка CJK , EUC |
| Расширяет | США-ASCII или ISO 646:JP |
| Преобразует/кодирует | ДЖИС С 0208 , ДЖИС С 0212 , ДЖИС С 0201 |
| Преемник | EUC-JISx0213 |
 | |
| Псевдоним(а) | EUC-JISx0213 |
|---|---|
| Язык(и) | японский , айнский , английский , русский |
| Стандартный | ДЖИС Х 0213 |
| Классификация | Расширенный ASCII , кодировка переменной длины , кодировка CJK , EUC |
| Расширяет | США-ASCII |
| Преобразует/кодирует | ДЖИС Х 0213 , ДЖИС Х 0201 (Кана) |
| Предшественник | EUC-JP |
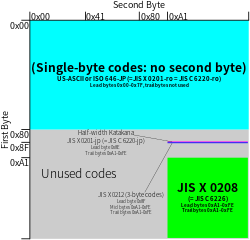
EUC-JP — это кодировка переменной длины, используемая для представления элементов трех японских стандартов набора символов , а именно JIS X 0208 , JIS X 0212 и JIS X 0201 . Другие названия этой кодировки включают Unixized JIS (или UJIS ) и AT&T JIS . [2] 0,1% всех веб-страниц используют EUC-JP с сентября 2022 года, [16] в то время как 3,0% веб-сайтов на японском языке используют эту кодировку [17] (реже используется, чем Shift JIS или UTF-8 ). называет ее кодовой страницей 954 . IBM [18] [19] У Microsoft есть два номера кодовых страниц для этой кодировки (51932 и 20932).
Эта схема кодирования позволяет легко смешивать 7-битный ASCII и 8-битный японский язык без необходимости использования escape-символов, используемых в ISO-2022-JP , который основан на тех же стандартах набора символов, и без появления байтов ASCII в качестве завершающих байтов. (в отличие от Shift JIS ).
Родственная и частично совместимая кодировка, называемая EUC-JISx0213 или EUC-JIS-2004 , кодирует JIS X 0201 и JIS X 0213. [20] (аналогично Shift_JISx0213 , его аналогу на основе Shift_JIS).
По сравнению с EUC-CN или EUC-KR, EUC-JP не получил такого широкого распространения на системах ПК и Macintosh в Японии, где использовался Shift JIS или его расширения ( кодовая страница Windows 932 в Microsoft Windows и MacJapanese в классической Mac OS ). , хотя он стал активно использоваться Unix или Unix-подобными операционными системами (за исключением HP-UX ). Поэтому то, используют ли японские веб-сайты EUC-JP или Shift_JIS, часто зависит от того, какую ОС использует автор.
Символы кодируются следующим образом:
- EUC/ ISO 2022 В кодировке, совместимой с , управляющие символы C0 , пробел и DEL представлены как в ASCII.
- Графический символ из ASCII (кодовый набор 0) представлен как его обычное однобайтовое представление в диапазоне 0x21 – 0x7E. Хотя некоторые варианты EUC-JP здесь кодируют нижнюю половину JIS X 0201 , большинство кодируют ASCII, [21] включая стандарт кодирования W3C/WHATWG, используемый HTML5 , [22] и EUC-JIS-2004 тоже. [20] Хотя это означает, что 0x5C обычно отображается в Unicode как U+005C REVERSE SOLIDUS ( обратная косая черта ASCII ), U+005C может отображаться как знак иены некоторыми шрифтами японской локали, например, в Microsoft Windows, для совместимости с нижней половиной JIS X 0201 . [23] [24]
- Символ из JIS X 0208 (кодовый набор 1) представлен двумя байтами, оба в диапазоне 0xA1 – 0xFE. Это отличается от представления ISO-2022-JP тем, что в нем установлен старший бит. Этот набор кодов также может содержать расширения поставщиков в некоторых вариантах EUC-JP. первая плоскость JIS X 0213 В EUC-JIS-2004 здесь закодирована , которая фактически является расширенным набором стандарта JIS X 0208 . [20]
- Символ из верхней половины JIS X 0201 ( кана половинной ширины , кодовый набор 2) представлен двумя байтами, первый из которых — 0x8E, второй — обычное представление JIS X 0201 в диапазоне 0xA1 — 0xDF. этот набор может содержать расширения поставщика IBM . В некоторых вариантах
- Символ из JIS X 0212 (кодовый набор 3) представлен в EUC-JP тремя байтами, первый из которых равен 0x8F, а следующие два находятся в диапазоне 0xA1–0xFE, т. е. с установленным старшим битом. В дополнение к стандарту JIS X 0212 , кодовый набор 3 некоторых вариантов EUC-JP может также содержать расширения в строках 83 и 84 для представления символов из расширений IBM Shift JIS, в которых отсутствуют стандартные сопоставления JIS X 0212, которые могут быть закодированы в любом из двух макеты, один из которых определяется самой IBM, а другой — OSF . [25] [26] вторая плоскость JIS X 0213 , В EUC-JIS-2004 здесь кодируется [20] который не конфликтует с выделенными строками в стандарте JIS X 0212 . [27] Некоторые реализации EUC-JIS-2004, такие как та, которая используется Python , допускают в этом наборе символы плоскости 2 как JIS X 0212 , так и JIS X 0213 . [27]
Расширения EUC-JP от поставщиков (например, от Open Software Foundation , IBM или NEC ) часто выделялись внутри отдельных наборов кодов. [25] [26] в отличие от использования недействительных последовательностей EUC (как в популярных расширениях EUC-CN и EUC-KR).
Однако некоторые кодировки, зависящие от поставщика, частично совместимы с EUC-JP из-за кодирования JIS X 0208 поверх GR, но не соответствуют упакованной структуре EUC. Часто они не включают использование одиночных смен из EUC-JP и, таким образом, не являются прямым продолжением EUC-JP, за исключением кандзи Super DEC.
DEC Кандзи [ править ]
Digital Equipment Corporation определяет два варианта EUC-JP, лишь частично соответствующие упакованному формату EUC, но также имеющие некоторое сходство с полным двухбайтовым форматом. Общий формат кодировки «DEC Kanji» в основном соответствует EUC фиксированной длины (полные два байта); однако кодовый набор 0 не обязательно дополняется слева нулевыми байтами (аналогично упакованному формату). [28] JIS X 0208, как обычно, используется для кодового набора 1; кодовый набор 2 (катакана половинной ширины) отсутствует; Кодовый набор 3 кодируется как двухбайтовый формат фиксированной ширины (т. е. без байта сдвига и с установленным только первым старшим битом), но используется для двухбайтовых символов, определяемых пользователем, а не указывается для JIS X 0212. [28] В базовой кодировке «DEC Kanji» только первые 31 строка кодового набора 3 используются для определяемых пользователем символов: строки с 32 по 94 зарезервированы, аналогично неиспользуемым строкам в кодовом наборе 1. [29]
Кодировка «Super DEC Kanji» принимает коды как из кодировки «DEC Kanji», так и из EUC упакованного формата, всего пять наборов кодов. [28] Это также позволяет использовать весь определяемый пользователем набор кодов и неиспользуемые строки на концах наборов кодов JIS X 0208 и JIS X 0212 (строки 85–94 и 78–94 соответственно) для символов, определяемых пользователем. [29]
НР-16 [ править ]
Hewlett-Packard определяет кодировку, называемую «HP-16». Это сопровождает их кодировку «HP-15», которая является вариантом Shift JIS . HP-16 кодирует JIS X 0208, используя те же байты, что и EUC-JP, но не использует коды с одним сдвигом (таким образом опуская наборы кодов 2 и 3) и добавляет три определяемые пользователем области, которые не соответствуют упакованному формату. Структура EUC: [28]
- Ведущие байты 0xA1–C2, завершающие байты 0x21–7E
- Ведущие байты 0xC3–E3, завершающие байты 0x21–3F
- Ведущие байты 0xC3–E1, завершающие байты 0x40–64.
ИКИС [ править ]
Кодировка IKIS (Интерактивная информационная система кандзи), используемая Data General, напоминает EUC-JP без одиночных сдвигов, т. е. только с наборами кодов 0 и 1. Вместо этого катакана половинной ширины включена в строку 8 JIS X 0208 (конфликт с полем- символы рисования, добавленные в стандарт в 1983 году). Строки с 9 по 12 JIS X 0208 используются для символов, определяемых пользователем. [28] [29]
EUC-JP Адаптации для EBCDIC
KEIS (расширенная информационная система обработки кандзи) — это кодировка EBCDIC, используемая Hitachi . [29] с двухбайтовыми символами (кодировка DBCS-Host), включенными с использованием последовательностей сдвига, что делает его кодировкой с отслеживанием состояния . В частности, последовательность 0x0A 0x41 переключается в однобайтовый режим и последовательность 0x0A 0x42 переключается в двухбайтовый режим. [б] Однако символы JIS X 0208 кодируются с использованием тех же последовательностей байтов, которые используются для их кодирования в EUC-JP. Это приводит к дублированию кодировок для идеографическое пространство — 0x4040 согласно структуре кода DBCS-Host и 0xA1A1, как в EUC-JP. Это отличается от кодировки IBM DBCS-Host для японского языка, структура которой основана на версиях, предшествующих JIS X 0208. Диапазон ведущих байтов расширен до 0x59, из которых ведущие байты 0x81–A0 предназначены для определяемых пользователем символов. [28] а остальные используются для корпоративных символов, включая как кандзи, так и не-кандзи. [29]
JEF (расширенная функция обработки на японском языке) [29] — это кодировка EBCDIC, используемая на мэйнфреймах Fujitsu FACOM, в отличие от FMR (вариант Shift JIS), используемого на ПК Fujitsu. Как и KEIS, JEF представляет собой кодировку с отслеживанием состояния, переключающуюся в двухбайтовый режим DBCS-Host с использованием последовательностей сдвига (где 0x29 переключается в однобайтовый режим и 0x28 переключается в двухбайтовый режим). [30] Также, как и в KEIS, коды JIS X 0208 представлены так же, как и в EUC-JP. [28] Диапазон ведущих байтов снова расширен до 0x41, при этом 0x80–0xA0 предназначены для определения пользователя; ведущим байтам 0x41–0x7F присвоены номера строк от 101 до 163 для целей кутен , хотя строка 162 (ведущий байт 0x7E) не используется. [28] [29] Строки с 101 по 148 используются для расширенных кандзи, а строки с 149 по 163 используются для расширенных некандзи. [29]
EUC-КР [ править ]
 Структура кода EUC-KR | |
| МИМ / IANA | EUC-КР |
|---|---|
| Псевдоним(а) | Вансунг, IBM-970 |
| Язык(и) | корейский , английский , русский |
| Стандартный | КС Х 2901 (КС С 5861) |
| Классификация | Расширенный ISO 646 , кодировка переменной длины , кодировка CJK , EUC |
| Расширяет | US-ASCII или ISO 646:KR |
| Расширения | Mac OS Корейский , IBM-949 , унифицированный код хангыль (Windows-949) |
| Преобразует/кодирует | КС Х 1001 |
| Преемник | Единый код хангыля (веб-стандарты) |
EUC-KR — это кодировка переменной длины для представления корейского текста с использованием двух кодированных наборов символов: KS X 1001 (ранее KS C 5601). [31] [32] и либо ISO 646 :KR ( KS X 1003 , ранее KS C 5636 ), либо US-ASCII , в зависимости от варианта. KS X 2901 (ранее KS C 5861 ) определяет кодировку и В RFC 1557 это обозначено как EUC-KR.
Символ, взятый из KS X 1001 (G1, кодовый набор 1), кодируется как два байта в GR (0xA1–0xFE), а символ из KS X 1003 или US-ASCII (G0, кодовый набор 0) занимает один байт в GL ( 0x21–0x7E).
Его обычно называют Вансон ( корейский : 완성 , латинизированный : Вансон , букв. «предварительно составленный») . [33] ') в Республике Корея . IBM называет двухбайтовый компонент кодовой страницей 971 . [34] и EUC-KR с ASCII в качестве кодовой страницы 970 . [35] [36] [37] Реализовано как кодовая страница 20949 («Корейский Вансон»). [38] [39] и кодовая страница 51949 («EUC Korean») от Microsoft. [38]
По состоянию на апрель 2024 г. [update], менее 0,08% всех веб-страниц в мире используют EUC-KR, [40] но 4,6% веб-страниц Южной Кореи используют EUC-KR, [41] Включая расширения, это наиболее широко используемая устаревшая кодировка символов в Корее на всех трех основных платформах ( macOS , других Unix-подобных ОС и Windows), но ее использование очень медленно переходит на UTF-8 по мере того, как она набирает популярность, особенно на Linux и MacOS.
Как и большинство других кодировок, UTF-8 теперь предпочтительнее для нового использования, поскольку решает проблемы согласованности между платформами и поставщиками.
Единый кодекс хангыля [ править ]
Распространенным расширением EUC-KR является кодекс хангыль ( Единый , Kodeu Tonghabhyeong Hangeul [42] или 통합 완성형 , Tonghab Wansunghyung ), которая является корейской кодовой страницей по умолчанию в Microsoft Windows. Microsoft присвоила ему номер кодовой страницы 949 и 1261. [43] или 1363 [44] компанией IBM. Кодовая страница IBM 949 — это другое, несвязанное расширение EUC-KR.
Единый код хангыля расширяет EUC-KR за счет использования кодов, которые не соответствуют структуре EUC, для включения дополнительных блоков слогов, дополняя охват составных блоков слогов, доступных в Johab и Unicode. Стандарт кодирования W3C / WHATWG , используемый HTML5, включает расширения Unified Hangul Code в определение EUC-KR. [45]
Mac OS Корейский (HangulTalk) [ править ]
Другие кодировки, включающие EUC-KR в качестве подмножества, включают корейский сценарий Mac OS (известный как кодовая страница 10003 или x-mac-korean), [13] который использовался HangulTalk (MacOS-KH), корейской локализацией классической Mac OS . Он был разработан компанией Elex Computer ( 일렉스 ), которая в то время была авторизованным дистрибьютором компьютеров Apple Macintosh в Южной Корее. [46] [29]
HangulTalk добавляет символы расширения с ведущими байтами между 0xA1 и 0xAD, как в неиспользуемом пространстве внутри плоскости EUC-KR GR (конечные байты 0xA1–0xFE), так и с использованием кодов, отличных от EUC, за ее пределами (конечные байты 0x41–0xA0). , независимые от стиля шрифта Некоторые из этих символов представляют собой стилизованные дингбаты . [29] Многие из этих символов не имеют точных сопоставлений Юникода, и программное обеспечение Apple по-разному отображает эти случаи: комбинирование последовательностей , аппроксимацию сопоставлений с добавленным символом частного использования в качестве модификатора для двусторонних целей или символы частного использования. [47]
Apple также использует определенные однобайтовые коды за пределами плоскости EUC-KR для дополнительных символов: 0x80 для обязательного пробела , 0x81 для знака победы (₩), 0x82 для тире ( –), 0x83 для знака авторского права (© ), 0x84 для широкого подчеркивания (_) и 0xFF для многоточия (…). [47] Хотя ни один из этих дополнительных однобайтовых кодов не находится в диапазоне ведущих байтов простого EUC-KR (в отличие от расширений Apple к EUC-CN, см. выше ), некоторые из них находятся в пределах диапазона ведущих байтов Unified Hangul Code (в частности, 0x81, 0x82). , 0x83 и 0x84).
EUC-КП [ править ]
Подобно KS X 1001, северокорейский стандарт KPS 9566 обычно используется в форме EUC; в этих контекстах его иногда называют EUC-КП. [48] В более поздних версиях стандарта представление EUC расширяется за счет символов, использующих двухбайтовые коды, не относящиеся к EUC, аналогично унифицированному коду хангыль. [49]
EUC-TH [ править ]
Хотя некоторые однобайтовые кодировки, такие как серия ISO/IEC 8859, технически соответствуют структуре EUC, они редко обозначаются как EUC. Однако, eucTH используется в Solaris в качестве метки для TIS-620 . [50]
EUC-TW [ править ]
EUC-TW — это кодировка переменной длины , которая поддерживает US-ASCII и 16 плоскостей CNS 11643 , каждая из которых имеет размер 94×94. Это редко используемая кодировка традиционных китайских иероглифов , используемых на Тайване . Варианты Big5 гораздо более распространены, чем EUC-TW, хотя Big5 кодирует только первые две плоскости CNS 11643 hanzi , тогда как UTF-8 становится все более распространенным.
- EUC/ ISO 2022 В кодировке управляющие символы C0 , пробел ASCII и DEL кодируются как в ASCII.
- Графический символ из US-ASCII (G0, кодовый набор 0) кодируется в GL как его обычное однобайтовое представление (0x21–0x7E).
- Символ из плоскости 1 CNS 11643 (кодовый набор 1) кодируется двумя байтами в GR (0xA1–0xFE).
- Символ в плоскостях с 1 по 16 CNS 11643 (кодовый набор 2) кодируется четырьмя байтами:
- Первый байт всегда равен 0x8E (одиночный сдвиг 2).
- Второй байт (0xA1–0xB0) указывает плоскость, номер которой получается вычитанием 0xA0 из этого байта.
- Третий и четвертый байты находятся в формате GR (0xA1–0xFE).
Обратите внимание, что плоскость 1 CNS 11643 кодируется дважды как кодовый набор 1 и часть кодового набора 2.
См. также [ править ]
Примечания [ править ]
- ^ Версии 7-битного кода ISO 2022, поддерживающие GB 2312, включают ISO-2022-CN (с кодами сдвига) и ISO-2022-JP-2 (без кодов сдвига), оба из которых также поддерживают другие наборы, отличные от ASCII.
- ^ Эти последовательности соответствуют шестнадцатеричным формам, указанным DEC. [30] и десятичные формы (
10 65и10 66) перечислено Лунде. [28] Лунде перечисляет шестнадцатеричные формы для обоих:0xA0 0x42, видимо, ошибка.
Ссылки [ править ]
- ↑ Перейти обратно: Перейти обратно: а б с д ИБМ . «Архитектура представления символьных данных (CDRA)» . ИБМ . стр. 157–162.
- ↑ Перейти обратно: Перейти обратно: а б с Лунде, Кен (2008). Обработка информации CJKV: китайские, японские, корейские и вьетнамские компьютеры . О'Рейли. стр. 242–244. ISBN 9780596800925 .
- ^ «Наборы символов» . ИАНА.
- ^ «4.2. Названия и метки» . Стандарт кодирования . ЧТОРГ.
- ^ Чжу, Хайфэн; Ху, Даоюань; Ван, Чжигуань; Као, Тянь-чеу; Чанг, Вэнь-чжун; Криспин, Марк (март 1996 г.). Кодировка китайских символов для интернет-сообщений . Сетевая рабочая группа. дои : 10.17487/RFC1922 . РФК 1922 . Информационный. сек. 2.1: CN-GB).
- ↑ Перейти обратно: Перейти обратно: а б с д «Сопоставление (внешняя версия) упрощенной китайской кодировки Mac OS с Unicode 3.0 и более поздних версий» . Apple, Inc.
- ^ «Смешанные данные S-Ch PC (IBM GB), включая 1880 UDC, 31 выбранный символ IBM и 5 символов SAA SB» . Глобализация IBM: идентификаторы кодированных наборов символов . ИБМ . Архивировано из оригинала 26 марта 2016 г.
- ^ «Набор упрощенных китайских графических символов IBM» (PDF) . ИБМ . 1993. CH 3-3220-130 1993-11.
- ^ «CCSID 1383: набор S-Ch EUC G0, набор ASCII G1, набор GB 2312-80 (1382)» . Глобализация IBM: идентификаторы кодированных наборов символов . ИБМ . Архивировано из оригинала 28 марта 2016 г.
- ^ «Набор упрощенных китайских графических символов IBM для расширенного кода UNIX (EUC)» (PDF) . ИБМ . 1994. CH 3-3220-132 1994-06.
- ^ «CCSID 5479: набор S-Ch EUC G0, набор ASCII G1, набор GB 2312-80 (5478)» . Глобализация IBM: идентификаторы кодированных наборов символов . ИБМ . Архивировано из оригинала 27 марта 2016 г.
- ^ «CCSID 9574: набор S-Ch DBCS PC GB 2312-80, за исключением 31 выбранного IBM и 1360 UDC. Также используется в T-Ch 2022-CN TCP» . Глобализация IBM: идентификаторы кодированных наборов символов . ИБМ . Архивировано из оригинала 27 марта 2016 г.
- ↑ Перейти обратно: Перейти обратно: а б «Свойство Encoding.WindowsCodePage — .NET Framework (текущая версия)» . MSDN . Майкрософт.
- ^ Лунде, Кен (1998). «Обработка информации CJKV». Приложение F: GB/T 12345 (PDF) . О'Рейли Медиа . ISBN 9781565922242 .
- ^ Управление стандартизации Китая (SAC) (18 ноября 2005 г.). GB 18030-2005: Информационные технологии — набор китайских кодированных символов .
- ^ «Исторические тенденции использования кодировок символов для веб-сайтов» . W3Techs.
- ^ «Распространение кодировок символов среди веб-сайтов, использующих японский язык» . w3techs.com . Проверено 1 ноября 2023 г.
- ^ «Информационный документ CCSID 954» . Архивировано из оригинала 27 марта 2016 г.
- ^ Международные компоненты для Unicode (ICU), ibm-954_P101-2007.ucm , 3 декабря 2002 г.
- ↑ Перейти обратно: Перейти обратно: а б с д «Таблицы сопоставления кодов JIS X 0213» . x0213.org.
- ^ «Неоднозначности при преобразовании японского EUC в Unicode (ненормативный)» . XML-профиль для Японии . W3C.
- ^ «Декодер EUC-JP» . Стандарт кодирования . ЧТОРГ. «Если байт является байтом ASCII, верните кодовую точку, значением которой является байт».
- ^ «3.1.1 Подробности проблем» . Проблемы и решения для символов Юникода и символов, определяемых пользователем/поставщиком . Открытая группа Японии. Архивировано из оригинала 3 февраля 1999 г. Проверено 14 августа 2019 г.
- ^ Каплан, Майкл С. (17 сентября 2005 г.). «Когда обратная косая черта не является обратной косой чертой?» .
- ↑ Перейти обратно: Перейти обратно: а б «4.2 Процесс проверки правил преобразования набора кодов между eucJP-open и UCS» . Проблемы и решения для символов Юникода и символов, определяемых пользователем/поставщиком . Открытая группа Японии. Архивировано из оригинала 3 февраля 1999 г. Проверено 14 августа 2019 г.
- ↑ Перейти обратно: Перейти обратно: а б Лунде, Кен (13 января 2009 г.). «Приложение J: Наборы японских символов» (PDF) . Обработка информации CJKV (2-е изд.). ISBN 978-0-596-51447-1 .
- ↑ Перейти обратно: Перейти обратно: а б Чанг, Хешик (8 декабря 2021 г.). «Readme для CJKCodecs» . cПитон . Фонд программного обеспечения Python.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г час я Лунде, Кен (13 января 2009 г.). «Приложение F: Методы кодирования поставщиков» (PDF) . Обработка информации CJKV (2-е изд.). ISBN 978-0-596-51447-1 .
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г час я дж Лунде, Кен (2009). «Приложение E: Стандарты набора символов поставщика» (PDF) . Обработка информации CJKV: китайские, японские, корейские и вьетнамские вычисления (2-е изд.). Севастополь, Калифорния : О'Рейли . ISBN 978-0-596-51447-1 .
- ↑ Перейти обратно: Перейти обратно: а б «2: Кодовые наборы и преобразование кодовых наборов» . Технический справочник DIGITAL UNIX по использованию японских функций . Корпорация цифрового оборудования , Compaq . [ мертвая ссылка ]
- ^ «КС Х 1001:1992» (PDF) .
- ^ Корейское бюро стандартов (1 октября 1988 г.). КС С 5601:1987 (PDF) . ITSCJ/ IPSJ . ИСО-ИК -149.
- ^ Лунде, Кен (2009). «Глава 3: Стандарты набора символов» . Обработка информации CJKV . «О'Рейли Медиа, Инк.». п. 146. ИСБН 978-0596514471 .
- ^ «Глобализация IBM — Идентификаторы кодированных наборов символов — CCSID 971» . Архивировано из оригинала 30 ноября 2014 г. Проверено 03 сентября 2021 г.
- ^ «CCSID 970» . IBM Глобализация . ИБМ. Архивировано из оригинала 1 декабря 2014 г.
- ^ "ibm-970_P110_P110-2006_U2 (псевдоним euc-kr)" . Converter Explorer — демонстрация ICU . Международные компоненты для Unicode.
- ^ Международные компоненты для Unicode (ICU), ibm-970_P110_P110-2006_U2.ucm , 3 декабря 2002 г.
- ↑ Перейти обратно: Перейти обратно: а б «Идентификаторы кодовых страниц» . Центр разработки Windows . Майкрософт. 7 января 2021 г.
- ^ Джульярд, Александр. «dump_krwansung_codepage: построить корейскую таблицу Wansung из файла KSX1001» . make_unicode: Генерировать файлы кодовой страницы .c из описаний ftp.unicode.org . Винный проект .
- ^ «Статистика использования и доля рынка EUC-KR для веб-сайтов, апрель 2024 г.» . w3techs.com . Проверено 9 апреля 2024 г.
- ^ «Распространение кодировок символов среди веб-сайтов, использующих .kr» . w3techs.com . Проверено 9 апреля 2024 г.
- ^ «О кодексе хангыль» (на корейском языке). W3C. Архивировано из оригинала 24 мая 2013 г. Проверено 7 января 2019 г.
- ^ В ucnv_lmb.cpp , файле, созданном IBM и включенном в дерево исходного кода International Components for Unicode , ведущий байт 0x11 комментируется как относящийся к «корейскому языку: ibm-1261» после определения
ULMBCS_GRP_KOи отображается в"windows-949"Кодек ICU вOptGroupByteToCPNameмассив позже в файле. - ^ «Идентификаторы кодированных наборов символов — CCSID 1363» , IBM Globalization , IBM, заархивировано из оригинала 29 ноября 2014 г.
- ^ «5. Индексы (§ индекс EUC-KR)» , Стандарт кодирования , WHATWG
- ^ Гил, Ходжин. «HangulTalk: де-факто стандартная среда Hangul для Mac» . Руководство по использованию хангыля на Macintosh .
- ↑ Перейти обратно: Перейти обратно: а б Яблоко (05 апреля 2005 г.). «Сопоставление (внешняя версия) корейской кодировки Mac OS с Unicode 3.2 и более поздних версий» . Консорциум Юникод .
- ^ Ким, Кёнсок (30 ноября 2002 г.). «Таблицы трехсторонних перекрестных ссылок — KS X 1001, KPS 9566 и UCS» (PDF) . ISO/IEC JTC 1/SC 2 /WG 2 N2564. [Примечание: обновленные ссылки на таблицы, сопровождающие документ: [1] [2] ]
- ^ Чунг, Джемин (05 января 2018 г.). «Информация о самой последней версии КПС 9566 (КПС 9566-2011?)» (PDF) . UTC Л2/18-011.
- ^ IBM (07 мая 2001 г.). "Солярис-eucTH-2.7" . icu-данные . Консорциум Unicode / Международные компоненты для Unicode .
Внешние ссылки [ править ]
- Таблица кодового набора EUC-JP (без ASCII и половинной ширины ) частей
- Идентификаторы кодовых страниц
- GB18030-2000 - Новый китайский национальный стандарт (с момента обновления до GB18030-2022 , который (немного) несовместим)
- Новое поколение программного обеспечения для допечатной подготовки в Китае - упоминается код 748.
- Описание кода EUC-TW (на китайском языке)
- Страница руководства EUC-JISX0213 в модуле Perl Encode
- Международный реестр наборов кодированных символов, которые будут использоваться с Escape-последовательностями - раздел 2.4 (стр. 14f.) с наборами кодированных символов Китая, Японии, Южной Кореи, Северной Кореи и Тайваня (ISO/IEC)
- Стандарты набора символов и системы кодирования китайского, японского и корейского языков.