Кодовая страница 949 (IBM)
 Макет кодовой страницы IBM-949 | |
| Псевдоним(а) |
|
|---|---|
| Язык(и) | корейский |
| Создано | ИБМ |
| Классификация | Расширенный ISO 646 , кодировка переменной ширины , кодировка CJK |
| Расширяет | EUC-КР |
| Предшественник | Кодовая страница 944 |
Кодовая страница IBM 949 (IBM-949) — это кодировка символов , которая использовалась IBM для представления текста на корейском языке на компьютерах. Это кодировка переменной ширины , которая представляет символы из кода Wansung, определенного южнокорейским стандартом KS X 1001, в формате, совместимом с EUC-KR , но добавляет расширения IBM для дополнительных ханджа , дополнительных заранее составленных слогов хангыль и пользовательских символов. персонажи .
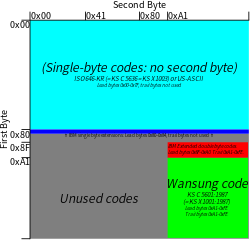
При предоставлении значений в шестнадцатеричном формате байты от 0x00 до 0x7F используются для однобайтовых символов KS X 1003 ( ISO 646 :KR), аналогичного набору ASCII, но со знаком выигрыша , а не обратной косой чертой. Байты с 0x80 по 0x84 используются для однобайтовых символов расширения IBM. Ведущие байты от 0x8F до 0xA0 используются для символов двухбайтового расширения IBM. Ведущие байты от 0xA1 до 0xFE используются для кода Wansung ( символы KS X 1001 в форме EUC-KR, двухбайтовые), но с некоторым неиспользуемым пространством, открытым для использования, определяемого пользователем.
Хотя оба иногда называются «cp949», IBM-949 отличается от кодовой страницы Windows 949 (IBM-1363), которая представляет собой унифицированный код хангыля Microsoft, другое расширение EUC-KR. Его также не следует путать с реализацией обычного EUC-KR ( IBM-970 ) от IBM. Кодовая страница 949 в OS/2 — это кодовая страница IBM; однако существует сторонний патч, позволяющий изменить это. [1]
Терминология и маркировка кодировок [ править ]
И IBM-949, и Unified Hangul Code (Windows-949) известны как «кодовая страница 949» (или «cp949»), хотя общим для них является только подмножество EUC-KR. Ни у одного из них нет стандартизированного зарегистрированного в IANA ярлыка для его идентификации. Хотя UHC включен в стандарт кодирования WHATWG , [2] с ярлыками, включая «windows-949», [3] IBM-949 нет. Поэтому IBM-949 не разрешен в HTML5 .
Хотя значение метки «ibm-949» (и наоборот «windows-949» и «ms949») однозначно там, где эти метки поддерживаются, интерпретация меток кодировки «949» и «cp949», следовательно, различается в зависимости от реализации. Например, в International Components for Unicode для обозначения IBM-949 используются «cp949», «949», «ibm-949» и «x-IBM949». [4] и, кроме того, метки «cp949c», «ibm-949c» и «x-IBM949C» обозначают вариант, в котором используются немодифицированные сопоставления ASCII для 0x20–7E (что приводит к дублированию сопоставлений для обратной косой черты), [5] в то время как (из меток, включающих номер кодовой страницы 949) только «ms949» и «windows-949» назначены UHC. [6] В этом отличие от Python , который распознает как «cp949», так и «949» (в дополнение к более явным «ms949» и «uhc», но не «windows-949») как метки для UHC и не включает Кодек IBM-949. [7] Кодовая страница 949, используемая версиями OS/2 на корейском языке , является кодовой страницей IBM; Чтобы добавить поддержку всего набора корейских слогов Unicode, существует сторонний патч, заменяющий его кодовой страницей Microsoft. [1]
IBM-949 — это кодировка переменной ширины, определяемая как комбинация двух кодовых страниц фиксированной ширины : однобайтовой кодовой страницы 1088 и двухбайтовой кодовой страницы 951 . [8] [9] [10]
История [ править ]
Версия кодовой страницы 951 (DBCS-PC, т.е. двухбайтовый код, не относящийся к EUC и не EBCDIC ), двухбайтовый компонент для IBM-949, определен в редакции IBM Corporate Specification CH 3-, выпущенной в сентябре 1992 года. 3220-125 вместе с кодовой страницей 834 (DBCS-Host, т. е. двухбайтовым кодом EBCDIC), которая является двухбайтовым компонентом кодовой страницы 933 . [11] В этой версии кодовой страницы 949/951 весь диапазон ведущих байтов 0x8F – A0 рассматривался как определяемая пользователем область и включал только стандартные назначения Wansung и определяемые пользователем области, таким образом не включая некоторые символы, включенные в кодовую страницу 933/834. [11] Некоторые более поздние версии, например, реализованные International Components for Unicode (ICU), сжимают определяемую пользователем область, чтобы включить эти символы в качестве расширений. [12]
| Язык(и) | корейский |
|---|---|
| Расширяет | N-байтовый код хангыля |
| Преобразует/кодирует | Кодовая страница 933 |
| Преемник | Кодовая страница IBM 949 |
В более ранней версии CH 3-3220-125, выпущенной в октябре 1989 года, вместо этого кодовая страница 926 определялась как код DBCS-PC, который кодировал те же символы, что и IBM-834, в макете, отличающемся как от IBM-951, так и от IBM-834, которые имели другой диапазон ведущих байтов и не был расширением EUC-KR. [11] IBM-926 был объединен с кодовой страницей 891 или кодовой страницей 1040 (соответственно 8-битный N-байтовый код хангыля и его расширение; сравните, как Shift JIS расширяет 8-битный JIS X 0201 ), чтобы сформировать IBM-934 или IBM-944 соответственно. . [13] [14]
Кодовая страница 944/926 теперь устарела в пользу IBM-949. В версии 1992 года кодовая страница 926 обозначена как «ограниченная» («ограниченная конкретной средой, для которой [она] зарегистрирована») и не приводится ее диаграмма или сопоставления с другими кодовыми страницами. [11] а CCSID 944 относится к категории «сосуществование и миграция». [14] (в отличие от CCSID 949, «совместимый»). [8] Международные компоненты для Unicode включают сопоставления Unicode для IBM-949. [4] [12] и IBM-933, но его отображение IBM-944 было удалено в 2001 году. [15]
Однобайтовые коды [ править ]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | А | Б | С | Д | И | Ф | |
| 0x | НУЛЕВОЙ | ┌ | ┐ | └ | ┘ | │ | ─ | • | ◘ | ○ | ◙ | ♂ | ♀ | ♪ | ♫ | ☼ |
| 1x | ┼ | ◄ | ↕ | ‼ | ¶ | ┴ | ┬ | ┤ | ↑ | ├ | → | ← | ∟ | ↔ | ▲ | ▼ |
| 2x | СП | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | А | Б | С | Д | И | Ф | Г | ЧАС | я | Дж | К | л | М | Н | ТО |
| 5x | П | вопрос | Р | С | Т | В | V | В | Х | И | С | [ | ₩ | ] | ^ | _ |
| 6x | ` | а | б | с | д | и | ж | г | час | я | дж | к | л | м | н | тот |
| 7x | п | д | р | с | т | в | v | В | х | и | С | { | | | } | ~ | ⌂ |
| 8x | ¢ | ¬ | \ | ‾ | ¦ | 8F | ||||||||||
| 9x | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 9А | 9Б | 9С | 9Д | 9Е | 9F |
| Топор | А0 | 1-_ | 2-_ | 3-_ | 4-_ | 5-_ | 6-_ | 7-_ | 8-_ | 9-_ | 10-_ | 11-_ | 12-_ | 13-_ | 14-_ | 15-_ |
| Бх | 16-_ | 17-_ | 18-_ | 19-_ | 20-_ | 21-_ | 22-_ | 23-_ | 24-_ | 25-_ | 26-_ | 27-_ | 28-_ | 29-_ | 30-_ | 31-_ |
| Сх | 32-_ | 33-_ | 34-_ | 35-_ | 36-_ | 37-_ | 38-_ | 39-_ | 40-_ | 41-_ | 42-_ | 43-_ | 44-_ | 45-_ | 46-_ | 47-_ |
| Дх | 48-_ | 49-_ | 50-_ | 51-_ | 52-_ | 53-_ | 54-_ | 55-_ | 56-_ | 57-_ | 58-_ | 59-_ | 60-_ | 61-_ | 62-_ | 63-_ |
| Бывший | 64-_ | 65-_ | 66-_ | 67-_ | 68-_ | 69-_ | 70-_ | 71-_ | 72-_ | 73-_ | 74-_ | 75-_ | 76-_ | 77-_ | 78-_ | 79-_ |
| Форекс | 80-_ | 81-_ | 82-_ | 83-_ | 84-_ | 85-_ | 86-_ | 87-_ | 88-_ | 89-_ | 90-_ | 91-_ | 92-_ | 93-_ | 94-_ |
Двухбайтовые коды [ править ]
Ведущие байты 0x8F–99, 0xC9, 0xFE (диапазоны, определяемые пользователем) [ править ]
IBM-949 предназначен для поддержки максимум 1880 UDC (определяемых пользователем символов), [8] включая определяемые пользователем строки (ведущие байты 0xC9 и 0xFE) плоскости Wansung и диапазоны за пределами плоскости Wansung. В этой версии ведущие байты 0x8F–A0 содержат максимум 1692 UDC, а ведущие байты 0xC9 и 0xFE содержат максимум 94 каждый (т. е. вместе с завершающими байтами 0xA1–FE). [11] расширения для поддержки всего двухбайтового репертуара IBM-933 , они используют ведущие байты 0x9A–A0, в результате чего для определения пользователя остается меньшее максимальное количество символов. Однако когда реализованы [4] [12]
При сопоставлении с Unicode 0xC9A1–C9FE (между диапазонами слогов и ханджа) сопоставляются с кодовыми точками области частного использования Unicode U+E000–E05D, а 0xFEA1–FEFE (между концом диапазона ханджа и концом плоскости). ) отображаются в U+E05E–E0BB. За пределами плоскости Wansung 0x8FA0–9AA5 (где второй байт находится в диапазоне 0xA1–FE) сопоставляются с кодовыми точками зоны частного использования U+E0BC–E4CA. [4] Последний из этих диапазонов врезается в начало строки 0x9A (показано ниже).
В совокупности эти диапазоны частного использования охватывают кодовые точки U + E000 – E4CA, что позволяет отображать 1227 UDC из IBM-949 в Unicode. [12] Отдельный диапазон областей частного использования U+F843–F86E используется IBM для сопоставления некоторых символов в расширенном диапазоне ханджа. [12] Это соответствует ранним рекомендациям Консорциума Unicode о том, что корпоративные символы должны располагаться начиная с U+F8FF, а определяемые пользователем символы — начиная с U+E000 и выше. [18] и является частью более крупной схемы корпоративных зон частного использования, которая определена внутри IBM и использует диапазон U + F83D – F8FF. [19] [20]
символы и Ведущие байты 0x9A–9D ( расширенные ханджа )
Согласно спецификации 1992 года, весь этот диапазон определяется пользователем. [11] Однако, как это реализовано в кодеке, предоставленном IBM для ICU, от 0x9AA1 до 0x9AA5 являются концом определяемого пользователем диапазона. Оставшаяся часть этого диапазона включает некоторые символы, не относящиеся к хангылю, включенные в кодовую страницу 933 , но не в код Wansung. Номера от 0x9AA6 до 0x9AAB содержат разные технические или математические символы. Остальная часть содержит ханджа, дополнительные к тем, которые включены в KS X 1001 , хотя некоторые из них сопоставлены IBM с областью частного использования. [12]
Ведущие байты 0x9E–A0 (расширенные слоги ханджа и хангыль) [ править ]
Согласно спецификации 1992 года, весь этот диапазон определяется пользователем. [11] Как реализовано в кодеке, предоставленном IBM для ICU, номера от 0x9EA1 до 0x9EAC содержат оставшуюся часть расширенного ханджи. Остальная часть диапазона содержит несколько дополнительных слогов хангыля , которые недоступны в предварительно составленной форме в чистом EUC-KR . В отличие от Единого кода хангыля, этого недостаточно для поддержки всех нечастных слогов Иохаб, отсутствующих в коде Вансунг. [12]
Среди них значимыми являются 뢔 (0x9EFC), 쌰 (0x9FE6), 쎼 (0x9FED), 쓔 (0x9FF3) и 쬬 (0xA0C1), которые соответствуют началу стандартных символов Wansung 뢨, 썅, 쏀, 쓩 и 쭁 соответственно. , при частичном вводе в редактор метода ввода .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | А | Б | С | Д | И | Ф | |
| 9EAx | вок | Ван | радостный | служанка | 哓 | нечеткий | шуметь | обезьяна | музыкальный инструмент | Синь | До | Цзе | К | 갰 | Вот и все | |
| 9EBx | Ух ты | Ух ты | сено | хорошо | Нарезать | Гуань | Ух ты | Хорошо | Ух ты | Хорошо | Пока | Ух ты | Хорошо | Ух ты | Длинный | Ух ты |
| 9ECx | Хорошо | Ух ты | Ух ты | ㅋ | Хорошо | Ух ты | Хорошо | Ух ты | Ух ты | Ух ты | Обманывать | Ух ты | Ух ты | Ух ты | 뀍 | 뀡 |
| 9EDx | Ух ты | Извини | зерно | Ням | Нет | Да | Да | 년 | Нёнг | Да | Ага | Нет | Нет | Ух ты | Ух ты | Ага |
| 9EEx | Ух ты | Ух ты | ура | Ух ты | Ух ты | Ух ты | Ух ты | Точка | 뀄 | Ух ты | Хорошо | ттеот | 뽕 | Ух ты | да | Ух ты |
| 9EFx | Глубокий | Вещь | Что | Где | Ух ты | Когда | группа | Ух ты | повернуться | Ух ты | Ух ты | Ух ты | Ух ты | ржу не могу | Ух ты | |
| 9Факс | Ух ты | Ух ты | Да | Мия | Ух ты | Ух ты | Мой | вместе | Ух ты | Мео | М-м-м | Ух ты | М-м-м | М-м-м | . | |
| 9FBx | Ух ты | Ага | Пока | Пока | Бем | Бем | Бев | Пока | ББ | Пока | Пока | Пока | Бу | Пока | Ух ты | Ух ты |
| 9FCx | Ух ты | Ух ты | Вычтено | Пока | Пффф | ручка | Ручка | Ух ты | Пока | Ух ты | Ух ты | Пока | Поп | Ух ты | Пока | Ух ты |
| 9FDx | Ух ты | Сладкий | Ух ты | Сладкий | Вздох | Приколоть | Ух ты | Суббота | Выстрелил | Шань | ша | Набор | Лист | Овца | притворство | Избегайте |
| 9ФЭкс | Закрыть | 쀀 | Новый | Ссссс | SS | Дерьмо | Ся | Ух ты | Ссам | Цк | ссссссссссссссссссссссссссссс | сентябрь | 젠 | 쎼 | Выстрелил | Ух ты |
| 9FFx | 콷 | Ух ты | Пффф | Ух ты | Ух ты | Ух ты | Ух ты | Ух ты | Ух ты | Ять | Ух ты | Ага | Да | да | Хорошо | |
| A0Ax | Ага | Ют | Ух ты | Ют | Ага | Ух ты | Ух ты | Хорошо | Джем | Джем | реактивный самолет | Чон | Молодой | Ух ты | Ух ты | |
| A0Bx | Ух ты | Ух ты | Джун | Ух ты | Ух ты | Джон | Да | 윅 | Ух ты | Ух ты | Ух ты | Ух ты | Цк | Джджом | Ух ты | Джим |
| A0Cx | гнаться | Хорошо | Ух ты | Цк | Цк | Ух ты | Нарезать | Много | Находить | ча | Дешевый | чан | Дешевый | Чеонг | Ух ты | Ух ты |
| A0Dx | 숣 | Перец | Ух ты | Ух ты | Ух ты | Фу | Кепп | Ух ты | Ух ты | Ух ты | Ух ты | шарлатан | Твитнуть | Ух ты | Тэн | Тэн |
| A0Ex | Хе-хе | Цк | Ух ты | Гудок | Твитнуть | Ух ты | Пффф | Ух ты | Пеп | Пеп | Ух ты | Хе-хе | Ух ты | Пфунг | Пффф | ударять |
| A0Fx | Пинг | Ух ты | Хе-хе | Хе-хе | Ух ты | Хе-хе | Хе-хе | Хе-хе | Хе-хе | Хе-хе | Ух ты | хм | Упс | Ух ты | Уф |
Ведущие байты 0xA1–C8, 0xCA–FD (стандарт Wansung) [ править ]
См. также [ править ]
Сноски [ править ]
- ^ Это не включено в поддержку IPA. Скорее, на кодовой странице 933 SO 0x4160 — это знак равенства, отображаемый с косой чертой, а SO 0x418D IBM-933 — с обратной косой чертой (т. е. =⃥). [11] Хотя это IBM-933 SO 0x4160, который сопоставлен с обычным идентификатором, не равным GCGID SA540080 ( полная ширина SA540000), это IBM-933 SO 0x418D, который сопоставлен с EUC-KR и IBM-949 0xA1C1, [11] из-за того, что в KS C 5601-1987 ссылочный символ для знака не равно также показан с обратной косой чертой. [23] Следовательно, U+2260, который отображается в EUC-KR и, следовательно, в IBM-949 0xA1C1, отображается в IBM-933 SO 0x418D, в результате чего IBM-933 SO 0x4160 (и, следовательно, IBM-949 0x9AA6) отображается в визуально аналогичный символ U+01C2. [24]
- ^ Соответствие IBM — U+5231刱, но глиф в документе IBM CH 3-3220-125 1992-09 ближе к U+5259 剙 (код хоста 62D5). [11]
Ссылки [ править ]
- ↑ Перейти обратно: Перейти обратно: а б Боргендейл, Кен. «Кодовая страница OS/2 и инструменты отображения клавиатуры» .
- ^ ван Кестерен, Энн , «5. Индексы (§ индекс EUC-KR)» , Стандарт кодирования , WHATWG.
Это соответствует стандарту KS X 1001 и унифицированному коду хангыля, более известному вместе как кодовая страница Windows 949.
- ^ ван Кестерен, Энн . «4.2. Названия и метки» . Стандарт кодирования . ЧТОРГ.
- ↑ Перейти обратно: Перейти обратно: а б с д и «Converter Explorer: ibm-949_P110-1999 (псевдоним x-IBM949)» , Международные компоненты для Unicode , Консорциум Unicode
- ↑ Перейти обратно: Перейти обратно: а б «Converter Explorer: ibm-949_P11A-1999 (псевдоним x-IBM949C)» , Международные компоненты для Unicode , Консорциум Unicode . Это версия IBM-949 на основе ASCII.
- ^ "windows-949-2000" , Converter Explorer , Международные компоненты для Unicode
- ^ «кодеки — реестр кодеков и базовые классы § Стандартные кодировки» . Документация Python 3.7.2 . Фонд программного обеспечения Python.
- ↑ Перейти обратно: Перейти обратно: а б с «Идентификаторы кодированных наборов символов: CCSID 949» . IBM Глобализация . ИБМ . Архивировано из оригинала 29 ноября 2014 г.
- ^ «Информационный документ CCSID 1088» . Архивировано из оригинала 26 марта 2016 г.
- ^ «Информационный документ с кодовой страницей 951» . Архивировано из оригинала 16 января 2017 г.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г час я дж к «Набор корейских графических символов IBM: DBCS-Host и DBCS-PC» (PDF) . ИБМ . 2001 [1992]. СН 3-3220-125 1992-09.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г час я дж Международные компоненты для Unicode (ICU), ibm-949_P110-1999.ucm , 3 декабря 2002 г.
- ^ «Идентификаторы кодированных наборов символов: CCSID 934» . IBM Глобализация . ИБМ . Архивировано из оригинала 2 декабря 2014 г.
- ↑ Перейти обратно: Перейти обратно: а б «Идентификаторы кодированных наборов символов: CCSID 944» . IBM Глобализация . ИБМ . Архивировано из оригинала 1 декабря 2014 г.
- ^ Вишванадха, Рам (1 ноября 2001 г.). «ICU-1281 Удалить ненужные файлы ucm» . Международные компоненты для Unicode .
- ^ Кодовая страница CPGID 01088 (pdf) (PDF) , IBM
- ^ Кодовая страница CPGID 01088 (txt) , IBM
- ^ «2.0: Изменения в Юникоде 1.0» (PDF) . Стандарт Юникод, версия 1.1 . Консорциум Юникод . стр. 3–4. УТР №4.
- ↑ Перейти обратно: Перейти обратно: а б «CPGID 01449: PUA IBM по умолчанию» . Глобализация IBM: идентификаторы кодовых страниц . ИБМ . Архивировано из оригинала 16 сентября 2015 г.
IBM определила 195 должностей от U+F83D до U+F8FF для использования в качестве корпоративной зоны IBM и намерена последовательно использовать их внутри IBM всякий раз, когда возникает необходимость поддерживать целостность символов IBM.
- ^ ИБМ (1997). unicode.nam: позволяет указывать символы Юникода, используя имена, подобные IBM или PostScript . (Входит в комплект Боргендейл, Кен, Инструменты кодовой страницы OS/2 и отображения клавиатуры )
- ^ "ibm-933_P110-1995.ucm" . Международные компоненты для Unicode .
- ^ Ханджа, отображенные на карте зоны частного использования, идентифицируются по таблицам кодов. В документе IBM CH 3-3220-125 1992-09 приведены кодовые таблицы для кодовых страниц, используемых в качестве двухбайтовых компонентов для кодовой страницы 933 и более старой версии кодовой страницы 949 без этих расширений; однако ханджа в этом разделе соответствуют (и находятся в том же порядке) подмножеству таблицы 7, для которого «код ПК» не указан. [11] Отображения корпоративных областей частного использования также координируются с другими кодовыми страницами. [19] включая кодовую страницу 933, [21] который можно использовать для получения «кода хоста» для данного сопоставления области корпоративного частного использования.
- ^ Корейское бюро стандартов (1 октября 1988 г.). Корейский набор графических символов для обмена информацией (PDF) . ITSCJ/ IPSJ . ИСО-ИК -149.
- ^ "ibm-933_P110-1995 (ведущие байты 0E41)" . Конвертер Проводник . Международные компоненты для Unicode .