Анализ данных
| Часть серии по статистике. |
| Визуализация данных и информации |
|---|
| Основные размеры |
| Важные цифры |
| Информационные графические типы |
|
| Связанные темы |
| Вычислительная физика |
|---|
 |
Анализ данных — это процесс проверки, очистки , преобразования и моделирования данных с целью обнаружения полезной информации, обоснования выводов и поддержки принятия решений. [1] Анализ данных имеет множество аспектов и подходов, охватывая различные методы под разными названиями, и используется в различных областях бизнеса, науки и социальных наук. [2] В современном деловом мире анализ данных играет важную роль в принятии более научных решений и помогает бизнесу работать более эффективно. [3]
Интеллектуальный анализ данных — это особый метод анализа данных, который фокусируется на статистическом моделировании и обнаружении знаний для прогнозных, а не чисто описательных целей, в то время как бизнес-аналитика охватывает анализ данных, который в значительной степени опирается на агрегирование, уделяя особое внимание бизнес-информации. [4] В статистических приложениях анализ данных можно разделить на описательную статистику , исследовательский анализ данных (EDA) и подтверждающий анализ данных (CDA). [5] EDA фокусируется на обнаружении новых особенностей данных, тогда как CDA фокусируется на подтверждении или опровержении существующих гипотез . [6] [7] Прогнозная аналитика фокусируется на применении статистических моделей для прогнозного прогнозирования или классификации, тогда как текстовая аналитика применяет статистические, лингвистические и структурные методы для извлечения и классификации информации из текстовых источников, разновидности неструктурированных данных . Все вышеперечисленное является разновидностями анализа данных. [8]
Интеграция данных является предшественником анализа данных, а анализ данных тесно связан с визуализацией и распространением данных. [9]
Процесс анализа данных [ править ]
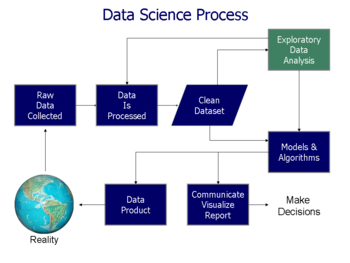
Анализ означает разделение целого на отдельные компоненты для индивидуального изучения. [10] Анализ данных — это процесс получения необработанных данных и последующего преобразования их в информацию, полезную для принятия решений пользователями. [1] Данные собираются и анализируются, чтобы ответить на вопросы, проверить гипотезы или опровергнуть теории. [11]
Статистик Джон Тьюки в 1961 году определил анализ данных как:
«Процедуры анализа данных, методы интерпретации результатов таких процедур, способы планирования сбора данных, чтобы сделать их анализ проще, точнее или точнее, а также все механизмы и результаты (математической) статистики, которые применяются для анализа данных. ." [12]
Можно выделить несколько этапов, описанных ниже. Этапы являются итеративными , поскольку обратная связь от более поздних этапов может привести к дополнительной работе на более ранних этапах. [13] Структура CRISP , используемая при интеллектуальном анализе данных , имеет аналогичные этапы.
Требования данным к
Данные необходимы в качестве входных данных для анализа, который определяется на основе требований тех, кто руководит аналитикой (или клиентов, которые будут использовать готовый продукт анализа). [14] [15] Общий тип объекта, о котором будут собираться данные, называется экспериментальной единицей (например, человек или популяция людей). Могут быть указаны и получены конкретные переменные, относящиеся к населению (например, возраст и доход). Данные могут быть числовыми или категориальными (т. е. текстовой меткой для чисел). [13]
Сбор данных [ править ]
Данные собираются из различных источников. [16] [17] Список источников данных доступен для изучения и исследования. Аналитики могут сообщать требования хранителям данных; например, персонал информационных технологий в организации. [18] Сбор данных или сбор данных — это процесс сбора и измерения информации о целевых переменных в установленной системе, который затем позволяет ответить на соответствующие вопросы и оценить результаты. Данные также могут быть собраны с датчиков окружающей среды, включая дорожные камеры, спутники, записывающие устройства и т. д. Их также можно получить посредством интервью, загрузки из онлайн-источников или чтения документации. [13]
Обработка данных [ править ]

Данные, первоначально полученные, должны быть обработаны или систематизированы для анализа. [19] [20] Например, это может включать размещение данных в строках и столбцах в формате таблицы ( известном как структурированные данные ) для дальнейшего анализа, часто с использованием электронных таблиц или статистического программного обеспечения. [13]
Очистка данных [ править ]
После обработки и систематизации данные могут быть неполными, содержать дубликаты или ошибки. [21] [22] Потребность в очистке данных возникает из-за проблем со способом ввода и хранения данных. [21] Очистка данных — это процесс предотвращения и исправления этих ошибок. Общие задачи включают сопоставление записей, выявление неточностей данных, общее качество существующих данных, дедупликацию и сегментацию столбцов. [23] Такие проблемы с данными также можно выявить с помощью различных аналитических методов. Например; Используя финансовую информацию, итоговые суммы по конкретным переменным можно сравнивать с отдельно опубликованными цифрами, которые считаются надежными. [24] [25] Необычные суммы, превышающие или ниже заранее определенных пороговых значений, также могут быть пересмотрены. Существует несколько типов очистки данных, которые зависят от типа данных в наборе; это могут быть номера телефонов, адреса электронной почты, работодатели или другие значения. [26] [27] Методы количественного анализа данных для обнаружения выбросов можно использовать, чтобы избавиться от данных, которые с большей вероятностью будут введены неправильно. [28] Средства проверки правописания текстовых данных можно использовать для уменьшения количества напечатанных слов. Однако труднее сказать, верны ли сами слова. [29]
данных Исследовательский анализ
После очистки наборов данных их можно проанализировать. Аналитики могут применять различные методы, называемые исследовательским анализом данных , чтобы начать понимать сообщения, содержащиеся в полученных данных. [30] Процесс исследования данных может привести к дополнительной очистке данных или дополнительным запросам данных; таким образом, инициализируется итеративные фазы, упомянутые в первом абзаце этого раздела. [31] Описательная статистика , такая как среднее значение или медиана, может быть создана для облегчения понимания данных. [32] [33] Визуализация данных также является используемым методом, при котором аналитик может исследовать данные в графическом формате, чтобы получить дополнительную информацию относительно сообщений в данных. [13]
Моделирование и алгоритмы [ править ]
Математические формулы или модели (также известные как алгоритмы ) могут применяться к данным для выявления взаимосвязей между переменными; например, используя корреляцию или причинно-следственную связь . [34] [35] В общих чертах, модели могут быть разработаны для оценки конкретной переменной на основе других переменных, содержащихся в наборе данных, с некоторой остаточной ошибкой, зависящей от точности реализованной модели ( например , Данные = Модель + Ошибка). [36] [11]
Инференциальная статистика включает в себя использование методов измерения взаимосвязей между конкретными переменными. [37] Например, регрессионный анализ можно использовать для моделирования того, дает ли изменение в рекламе ( независимая переменная X ) объяснение изменений в продажах ( зависимая переменная Y ). [38] С математической точки зрения Y (продажи) является функцией X (реклама). [39] Это можно описать как ( Y = aX + b + error), где модель разработана таким образом, что ( ) и ( b ) минимизируют ошибку, когда модель прогнозирует Y для заданного диапазона значений X. a [40] Аналитики также могут попытаться построить модели, описывающие данные, с целью упростить анализ и сообщить результаты. [11]
Информационный продукт [ править ]
Продукт данных — это компьютерное приложение, которое принимает входные данные и генерирует выходные данные , передавая их обратно в окружающую среду. [41] Оно может быть основано на модели или алгоритме. Например, приложение, которое анализирует данные об истории покупок клиента и использует результаты, чтобы рекомендовать другие покупки, которые могут понравиться клиенту. [42] [13]
Общение [ править ]
После анализа данных о них можно сообщить во многих форматах пользователям анализа для удовлетворения их требований. [44] Пользователи могут иметь обратную связь, что приводит к дополнительному анализу. Таким образом, большая часть аналитического цикла является итеративной. [13]
Определяя, как сообщить результаты, аналитик может рассмотреть возможность применения различных методов визуализации данных, чтобы помочь более четко и эффективно донести сообщение до аудитории. [45] Визуализация данных использует отображение информации (например, графику, таблицы и диаграммы), чтобы помочь передать ключевые сообщения, содержащиеся в данных. [46] Таблицы являются ценным инструментом, позволяющим пользователю запрашивать конкретные цифры и фокусироваться на них; в то время как диаграммы (например, гистограммы или линейные диаграммы) могут помочь объяснить количественные сообщения, содержащиеся в данных. [47]
сообщения Количественные
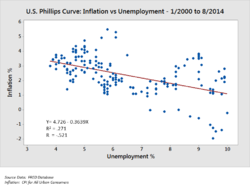
Стивен Фью описал восемь типов количественных сообщений, которые пользователи могут попытаться понять или передать на основе набора данных и связанных с ними графиков, используемых для передачи сообщения. [48] Заказчики, определяющие требования, и аналитики, выполняющие анализ данных, могут учитывать эти сообщения в ходе процесса. [49]
- Временные ряды: одна переменная фиксируется за определенный период времени, например, уровень безработицы за 10-летний период. линейный график . Для демонстрации тенденции можно использовать [50]
- Ранжирование: Категориальные подразделения ранжируются в порядке возрастания или убывания, например, рейтинг эффективности продаж (показатель ) продавцов ( категория , где каждый продавец имеет категориальное подразделение ) в течение одного периода. [51] гистограмму . Для сравнения продаж продавцов можно использовать [52]
- От части к целому: категориальные подразделения измеряются как отношение к целому (т. е. процент от 100%). Круговая . или гистограмма может отображать сравнение коэффициентов, например доли рынка, представленной конкурентами на рынке [53]
- Отклонение: категориальные подразделения сравниваются с эталоном, например, при сравнении фактических и бюджетных расходов нескольких подразделений бизнеса за определенный период времени. Гистограмма может показать сравнение фактической суммы с контрольной. [54]
- Распределение частот: показывает количество наблюдений конкретной переменной за заданный интервал, например, количество лет, в течение которых доходность фондового рынка находится между интервалами, такими как 0–10%, 11–20% и т. . д тип гистограммы, может использоваться для этого анализа. [55]
- Корреляция: сравнение наблюдений, представленных двумя переменными (X,Y), чтобы определить, имеют ли они тенденцию двигаться в одном или противоположных направлениях. Например, построение графика безработицы (X) и инфляции (Y) для выборки месяцев. диаграмма рассеяния . Для этого сообщения обычно используется [56]
- Номинальное сравнение: сравнение категориальных подразделений в произвольном порядке, например, объема продаж по коду продукта. Для этого сравнения можно использовать гистограмму. [57]
- Географические или геопространственные: сравнение переменных на карте или макете, например, уровень безработицы в штате или количество людей на разных этажах здания. Картограмма – это типичный используемый графический объект. [58] [59]
Методы анализа количественных данных [ править ]
Автор Джонатан Куми рекомендовал ряд лучших практик для понимания количественных данных. [60] К ним относятся:
- Проверьте исходные данные на наличие аномалий перед выполнением анализа;
- Повторно выполните важные вычисления, например проверку столбцов данных, основанных на формулах;
- Подтвердите, что основные итоги являются суммой промежуточных итогов;
- Проверьте отношения между числами, которые должны быть связаны предсказуемым образом, например, отношения во времени;
- Нормализуйте цифры, чтобы облегчить сравнение, например, анализируя суммы на душу населения или по отношению к ВВП, или как значение индекса по отношению к базовому году;
- Разбейте проблемы на составные части, проанализировав факторы, которые привели к результатам, например, анализ рентабельности капитала компании DuPont. [25]
Для исследуемых переменных аналитики обычно получают для них описательную статистику , такую как среднее значение (среднее), медиана и стандартное отклонение . [61] Они также могут проанализировать распределение ключевых переменных, чтобы увидеть, как отдельные значения группируются вокруг среднего значения. [62]

Консультанты McKinsey and Company назвали метод разделения количественной задачи на составные части принципом MECE . [63] Каждый слой можно разбить на компоненты; каждый из подкомпонентов должен быть взаимоисключающим друг друга и вместе составлять слой над ними. [64] Отношения называются «взаимоисключающими и коллективно исчерпывающими» или MECE. Например, прибыль по определению можно разбить на общий доход и общие затраты. [65] В свою очередь, общий доход может быть проанализирован по его компонентам, таким как доход подразделений A, B и C (которые являются взаимоисключающими друг друга) и должен прибавляться к общему доходу (в совокупности исчерпывающему). [66]
Аналитики могут использовать надежные статистические измерения для решения определенных аналитических задач. [67] Проверка гипотез используется, когда аналитик выдвигает конкретную гипотезу об истинном положении дел и собирает данные, чтобы определить, является ли это положение дел истинным или ложным. [68] [69] Например, гипотеза может заключаться в том, что «безработица не влияет на инфляцию», что связано с экономической концепцией, называемой кривой Филлипса . [70] Проверка гипотезы предполагает рассмотрение вероятности ошибок типа I и типа II , которые связаны с тем, поддерживают ли данные принятие или отклонение гипотезы. [71] [72]
Регрессионный анализ может использоваться, когда аналитик пытается определить степень, в которой независимая переменная X влияет на зависимую переменную Y (например, «В какой степени изменения уровня безработицы (X) влияют на уровень инфляции (Y)?»). [73] Это попытка смоделировать или подогнать к данным линию или кривую уравнения так, чтобы Y было функцией X. [74] [75]
Анализ необходимых условий (NCA) может использоваться, когда аналитик пытается определить степень, в которой независимая переменная X допускает переменную Y (например, «В какой степени определенный уровень безработицы (X) необходим для определенного уровня инфляции (Y)» ?"). [73] Принимая во внимание, что (множественный) регрессионный анализ использует аддитивную логику, где каждая X-переменная может давать результат, а X могут компенсировать друг друга (их достаточно, но не обязательно), [76] Анализ необходимых условий (NCA) использует логику необходимости, где одна или несколько X-переменных позволяют результату существовать, но могут не дать его (они необходимы, но недостаточны). Каждое необходимое условие должно присутствовать, и компенсация невозможна. [77]
пользователей Аналитическая деятельность данных
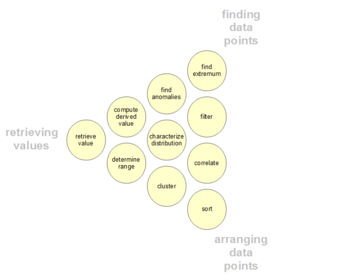
Пользователи могут иметь определенные точки данных, представляющие интерес в наборе данных, в отличие от общих сообщений, описанных выше. Такие низкоуровневые пользовательские аналитические действия представлены в следующей таблице. Таксономию также можно организовать по трем направлениям деятельности: получение значений, поиск точек данных и упорядочивание точек данных. [78] [79] [80] [81]
| # | Задача | Общий Описание | Про Форма Абстрактный | Примеры |
|---|---|---|---|---|
| 1 | Получить значение | Учитывая набор конкретных случаев, найдите атрибуты этих случаев. | Каковы значения атрибутов {X, Y, Z, ...} в случаях данных {A, B, C, ...}? | - Какой пробег на галлон у Форда Мондео? - Какова продолжительность фильма «Унесённые ветром»? |
| 2 | Фильтр | Учитывая некоторые конкретные условия для значений атрибутов, найдите случаи данных, удовлетворяющие этим условиям. | Какие случаи данных удовлетворяют условиям {A, B, C...}? | - Какие крупы Kellogg содержат много клетчатки? - Какие комедии получили награды? - Какие средства уступили СП-500? |
| 3 | Вычислить производное значение | Учитывая набор случаев данных, вычислите совокупное числовое представление этих случаев данных. | Каково значение функции агрегирования F для заданного набора S случаев данных? | - Какова средняя калорийность постных каш? - Каков валовой доход всех магазинов вместе взятых? - Сколько производителей автомобилей? |
| 4 | Найдите конец | Найдите случаи данных, имеющие экстремальное значение атрибута в его диапазоне в наборе данных. | Каковы N верхних/нижних случаев данных относительно атрибута A? | - Какая машина имеет самый высокий расход топлива? - Какой режиссер/фильм получил больше всего наград? - Какой фильм студии Marvel имеет самую последнюю дату выхода? |
| 5 | Сортировать | Учитывая набор случаев данных, ранжируйте их в соответствии с некоторой порядковой метрикой. | Каков порядок сортировки набора S случаев данных в соответствии с их значением атрибута A? | - Заказывайте автомобили по весу. - Расположите крупы по калорийности. |
| 6 | Определить диапазон | Учитывая набор случаев данных и интересующий атрибут, найдите диапазон значений в наборе. | Каков диапазон значений атрибута A в наборе S случаев данных? | - Каков диапазон продолжительности фильмов? - Каков диапазон мощности автомобиля? - Какие актрисы входят в набор данных? |
| 7 | Характеристика распределения | Учитывая набор случаев данных и интересующий количественный атрибут, охарактеризуйте распределение значений этого атрибута по набору. | Как распределяются значения атрибута A в наборе S случаев данных? | - Каково распределение углеводов в крупах? - Каково возрастное распределение покупателей? |
| 8 | Найдите аномалии | Выявите любые аномалии в заданном наборе случаев данных по отношению к заданным отношениям или ожиданиям, например, статистические выбросы. | Какие случаи данных в наборе S случаев данных имеют неожиданные/исключительные значения? | - Есть ли исключения из связи между мощностью и ускорением? - Есть ли выбросы по белку? |
| 9 | Кластер | Учитывая набор случаев данных, найдите кластеры схожих значений атрибутов. | Какие варианты данных в наборе S вариантов данных схожи по значению для атрибутов {X, Y, Z, ...}? | - Существуют ли группы круп с одинаковым содержанием жира/калорий/сахара? - Есть ли набор типичных длин фильмов? |
| 10 | Коррелировать | Учитывая набор случаев данных и два атрибута, определите полезные связи между значениями этих атрибутов. | Какова корреляция между атрибутами X и Y в заданном наборе S случаев данных? | - Есть ли корреляция между углеводами и жирами? - Есть ли корреляция между страной происхождения и MPG? - Есть ли у разных полов предпочтительный способ оплаты? - Есть ли тенденция увеличения продолжительности фильмов с годами? |
| 11 | Контекстуализация [81] | Учитывая набор случаев данных, найдите контекстную релевантность данных для пользователей. | Какие случаи данных из набора S случаев данных имеют отношение к контексту текущего пользователя? | - Существуют ли группы ресторанов, в которых есть продукты, рассчитанные на основе моего текущего потребления калорий? |
эффективного анализа на пути Барьеры
Барьеры для эффективного анализа могут существовать среди аналитиков, выполняющих анализ данных, или среди аудитории. Отличие фактов от мнений, когнитивные предубеждения и неумение считать — все это проблемы для качественного анализа данных. [82]
Сбивающий с толку факт и мнение [ править ]
Вы имеете право на собственное мнение, но не имеете права на собственные факты.
Эффективный анализ требует получения соответствующих фактов для ответа на вопросы, подтверждения вывода или формального мнения или проверки гипотез . [83] [84] Факты по определению неопровержимы, а это означает, что любой человек, участвующий в анализе, должен иметь возможность с ними согласиться. [85] Например, в августе 2010 года Бюджетное управление Конгресса (CBO) подсчитало, что продление снижения налогов Буша в 2001 и 2003 годах на период 2011–2020 годов увеличит государственный долг примерно на 3,3 триллиона долларов. [86] Каждый должен быть в состоянии согласиться с тем, что именно об этом сообщило CBO; все они могут изучить отчет. Это делает это фактом. Согласны или не согласны люди с CBO – это их собственное мнение. [87]
Другой пример: аудитор публичной компании должен прийти к официальному заключению о том, является ли финансовая отчетность публично торгуемых корпораций «достоверной во всех существенных отношениях». [88] Это требует обширного анализа фактических данных и доказательств, подтверждающих их мнение. При переходе от фактов к мнениям всегда существует вероятность того, что мнение ошибочно . [89]
предубеждения Когнитивные
Существует множество когнитивных искажений , которые могут отрицательно повлиять на анализ. Например, предвзятость подтверждения — это тенденция искать или интерпретировать информацию таким образом, чтобы подтвердить свои предубеждения. [90] Кроме того, отдельные лица могут дискредитировать информацию, которая не подтверждает их точку зрения. [91]
Аналитики могут быть специально обучены тому, чтобы осознавать эти предубеждения и способы их преодоления. [92] В своей книге «Психология анализа разведки » отставной аналитик ЦРУ Ричардс Хойер писал, что аналитики должны четко очертить свои предположения и цепочки умозаключений, а также указать степень и источник неопределенности, связанной с выводами. [93] Он подчеркнул важность процедур, помогающих выявить и обсудить альтернативные точки зрения. [94]
Несчёт [ править ]
Эффективные аналитики обычно владеют различными численными методами. Однако аудитория может не иметь такой грамотности в числах или счете ; Говорят, что они бесчисленны. [95] Лица, передающие данные, также могут пытаться ввести в заблуждение или дезинформировать, намеренно используя неверные численные методы. [96]
Например, то, растет или падает число, может не быть ключевым фактором. Более важным может быть число относительно другого числа, например, размера государственных доходов или расходов относительно размера экономики (ВВП) или суммы затрат относительно доходов в корпоративной финансовой отчетности. [97] Этот численный метод называется нормализацией. [25] или стандартного размера. Аналитики используют множество таких методов, будь то поправка на инфляцию (т. е. сравнение реальных и номинальных данных) или учет прироста населения, демографии и т. д. [98] Аналитики применяют различные методы для решения различных количественных сообщений, описанных в разделе выше. [99]
Аналитики также могут анализировать данные с использованием различных предположений или сценариев. Например, когда аналитики проводят анализ финансовой отчетности , они часто пересчитывают финансовую отчетность с учетом различных допущений, чтобы помочь получить оценку будущего денежного потока, который они затем дисконтируют до приведенной стоимости на основе некоторой процентной ставки, чтобы определить оценку компании или ее акций. [100] [101] Аналогичным образом, CBO анализирует влияние различных вариантов политики на государственные доходы, расходы и дефицит, создавая альтернативные сценарии будущего для ключевых мер. [102]
Другие темы [ править ]
Умные здания [ править ]
Подход к анализу данных можно использовать для прогнозирования энергопотребления в зданиях. [103] Различные этапы процесса анализа данных выполняются для реализации «умных» зданий, в которых операции по управлению и контролю здания, включая отопление, вентиляцию, кондиционирование воздуха, освещение и безопасность, реализуются автоматически путем имитации потребностей пользователей здания и оптимизации ресурсов. как энергия и время. [104]
Аналитика и бизнес-аналитика [ править ]
Аналитика — это «широкомасштабное использование данных, статистического и количественного анализа, объяснительных и прогнозирующих моделей, а также управления, основанного на фактах, для принятия решений и действий». Это подмножество бизнес-аналитики , которое представляет собой набор технологий и процессов, использующих данные для понимания и анализа эффективности бизнеса для принятия решений. [105]
Образование [ править ]
В сфере образования большинство преподавателей имеют доступ к системе данных для анализа данных учащихся. [106] Эти системы данных предоставляют данные преподавателям в формате , продаваемом без рецепта (встраивание этикеток, дополнительной документации и справочной системы, а также принятие ключевых решений по упаковке/отображению и содержанию) для повышения точности анализа данных преподавателями. [107]
Заметки практикующего врача [ править ]
Этот раздел содержит довольно технические пояснения, которые могут помочь практикам, но выходят за рамки типичного объема статьи в Википедии. [108]
Первоначальный анализ данных [ править ]
Наиболее важное различие между фазой начального анализа данных и фазой основного анализа заключается в том, что во время первоначального анализа данных воздерживаются от любого анализа, направленного на ответ на исходный вопрос исследования. [109] Фаза первоначального анализа данных определяется следующими четырьмя вопросами: [110]
Качество данных [ править ]
Качество данных следует проверять как можно раньше. Качество данных можно оценить несколькими способами, используя различные типы анализа: подсчет частот, описательную статистику (среднее значение, стандартное отклонение, медиана), нормальность (асимметрия, эксцесс, гистограммы частоты), нормальное вменение . требуется [111]
- Анализ крайних наблюдений : отдаленные наблюдения в данных анализируются, чтобы увидеть, не нарушают ли они распределение. [112]
- Сравнение и исправление различий в схемах кодирования: переменные сравниваются со схемами кодирования переменных, внешних по отношению к набору данных, и, возможно, корректируются, если схемы кодирования несопоставимы. [113]
- Проверка дисперсии общего метода .
Выбор анализа для оценки качества данных на начальном этапе анализа данных зависит от анализа, который будет проводиться на этапе основного анализа. [114]
Качество измерений [ править ]
Качество измерительных приборов следует проверять только на этапе первоначального анализа данных, если это не является целью или исследовательским вопросом исследования. [115] [116] Следует проверить, соответствует ли конструкция средств измерений конструкции, указанной в литературе.
Оценить качество измерений можно двумя способами:
- Подтверждающий факторный анализ
- Анализ однородности ( внутренней согласованности ), который дает представление о надежности средства измерений. [117] В ходе этого анализа проверяются дисперсии элементов и шкал, α Кронбаха шкал и изменение альфа Кронбаха, когда элемент будет удален из шкалы. [118]
Первоначальные преобразования [ править ]
После оценки качества данных и измерений можно решить приписать недостающие данные или выполнить первоначальные преобразования одной или нескольких переменных, хотя это также можно сделать на этапе основного анализа. [119]
Возможные преобразования переменных: [120]
- Преобразование квадратного корня (если распределение умеренно отличается от нормального)
- Лог-преобразование (если распределение существенно отличается от нормального)
- Обратное преобразование (если распределение сильно отличается от нормального)
- Сделать категориальным (порядковым/дихотомическим) (если распределение сильно отличается от нормального и никакие преобразования не помогают)
Соответствовала ли реализация исследования целям плана исследования? [ редактировать ]
Следует проверить успешность процедуры рандомизации , например, проверив, равномерно ли распределены фоновые и содержательные переменные внутри и между группами. [121]
Если исследование не требовало или не использовало процедуру рандомизации, следует проверить успешность неслучайной выборки, например, проверив, представлены ли в выборке все подгруппы интересующей популяции. [122]
Другие возможные искажения данных, которые следует проверить:
- отсев (это должно быть выявлено на этапе первоначального анализа данных)
- на вопрос Отсутствие ответа (независимо от того, является ли это случайным или нет, следует оценить на этапе первоначального анализа данных)
- Качество лечения (с использованием манипуляционных проверок ). [123]
Характеристики выборки данных [ править ]
В любом отчете или статье должна быть точно описана структура выборки. [124] [125] Особенно важно точно определить структуру выборки (и, в частности, размер подгрупп), когда анализ подгрупп будет проводиться на этапе основного анализа. [126]
Характеристики выборки данных можно оценить, рассмотрев:
- Базовая статистика важных переменных
- Диаграммы рассеяния
- Корреляции и ассоциации
- Перекрестные таблицы [127]
Завершающий этап первичного анализа данных [ править ]
На заключительном этапе результаты анализа исходных данных документируются и принимаются необходимые, предпочтительные и возможные корректирующие действия. [128]
Также первоначальный план основного анализа данных можно и нужно уточнить или переписать. [129] Для этого можно и нужно принять несколько решений относительно основного анализа данных:
- В случае ненормалей : следует ли преобразовывать переменные; сделать переменные категориальными (порядковыми/дихотомическими); адаптировать метод анализа?
- В случае отсутствия данных : следует ли игнорировать или приписывать недостающие данные; какой метод вменения следует использовать?
- В случае выбросов : следует ли использовать надежные методы анализа?
- В случае, если элементы не укладываются в шкалу: следует ли адаптировать измерительный прибор, опуская элементы, или, скорее, обеспечить сопоставимость с другими (применениями) измерительными приборами?
- В случае (слишком) маленьких подгрупп: следует ли отказаться от гипотезы о межгрупповых различиях или использовать методы небольших выборок, такие как точные тесты или бутстрэппинг ?
- В случае, если процедура рандомизации кажется дефектной: можно и нужно ли рассчитывать показатели склонности и включать их в качестве ковариат в основной анализ? [130]
Анализ [ править ]
На начальном этапе анализа данных можно использовать несколько видов анализа: [131]
- Одномерная статистика (одна переменная)
- Двумерные ассоциации (корреляции)
- Графические методы (диаграммы рассеяния)
При анализе важно учитывать уровни измерения переменных, поскольку для каждого уровня доступны специальные статистические методы: [132]
- Номинальные и порядковые переменные
- Частота подсчета (числа и проценты)
- Ассоциации
- обходы (перекрестные таблицы)
- иерархический логлинейный анализ (ограничено максимум 8 переменными)
- логлинейный анализ (для выявления соответствующих/важных переменных и возможных искажающих факторов)
- Точные тесты или начальная загрузка (в случае, если подгруппы небольшие)
- Вычисление новых переменных
- Непрерывные переменные
- Распределение
- Статистика (M, SD, дисперсия, асимметрия, эксцесс)
- Дисплеи в виде стеблей и листьев
- Коробочные графики
- Распределение
Нелинейный анализ [ править ]
Нелинейный анализ часто необходим, когда данные записываются из нелинейной системы . Нелинейные системы могут проявлять сложные динамические эффекты, включая бифуркации , хаос , гармоники и субгармоники , которые невозможно проанализировать с помощью простых линейных методов. Нелинейный анализ данных тесно связан с идентификацией нелинейных систем . [133]
основных Анализ данных
На этапе основного анализа проводится анализ, направленный на ответ на вопрос исследования, а также любой другой соответствующий анализ, необходимый для написания первого проекта отчета об исследовании. [134]
и Исследовательский подтверждающий подходы
На этапе основного анализа можно использовать либо исследовательский, либо подтверждающий подход. Обычно выбор подхода определяется до сбора данных. [135] При исследовательском анализе перед анализом данных не формулируется четкая гипотеза, и данные ищутся для моделей, которые хорошо описывают данные. [136] В подтверждающем анализе проверяются четкие гипотезы относительно данных. [137]
Исследовательский анализ данных следует интерпретировать осторожно. При одновременном тестировании нескольких моделей высока вероятность обнаружить хотя бы одну из них значимой, но это может быть связано с ошибкой 1-го рода . [138] Важно всегда корректировать уровень значимости при тестировании нескольких моделей, например, с поправкой Бонферрони . [139] Кроме того, не следует дополнять исследовательский анализ подтверждающим анализом в том же наборе данных. [140] Исследовательский анализ используется для поиска идей для теории, но не для проверки этой теории. [140] Когда в наборе данных обнаруживается исследовательская модель, то вслед за этим анализом следует провести подтверждающий анализ в том же наборе данных, что может просто означать, что результаты подтверждающего анализа обусловлены той же ошибкой первого типа , которая привела к появлению исследовательской модели в первом наборе данных. место. [140] Таким образом, подтверждающий анализ не будет более информативным, чем первоначальный исследовательский анализ. [141]
Стабильность результатов [ править ]
Важно получить некоторое представление о том, насколько обобщаемы результаты. [142] Хотя это часто трудно проверить, можно посмотреть на стабильность результатов. Являются ли результаты надежными и воспроизводимыми? Есть два основных способа сделать это. [143]
- Перекрестная проверка . Разделив данные на несколько частей, мы можем проверить, распространяется ли анализ (например, подобранная модель), основанный на одной части данных, на другую часть данных. [144] Однако перекрестная проверка, как правило, неуместна, если в данных имеются корреляции, например, с панельными данными . [145] Следовательно, иногда необходимо использовать другие методы проверки. Дополнительную информацию по этой теме см. в разделе «Проверка статистической модели» . [146]
- Анализ чувствительности . Процедура изучения поведения системы или модели при (систематическом) изменении глобальных параметров. Один из способов сделать это — через начальную загрузку . [147]
Бесплатное программное обеспечение для анализа данных [ править ]
Известные бесплатные программы для анализа данных включают:
- DevInfo – система баз данных, одобренная Группой развития ООН для мониторинга и анализа человеческого развития. [148]
- ELKI — среда интеллектуального анализа данных на Java с функциями визуализации, ориентированными на интеллектуальный анализ данных.
- KNIME — Konstanz Information Miner, удобная и комплексная платформа для анализа данных.
- Orange — инструмент визуального программирования, включающий интерактивную визуализацию данных и методы статистического анализа данных, интеллектуального анализа данных и машинного обучения .
- Pandas — библиотека Python для анализа данных.
- PAW — структура анализа данных FORTRAN/C, разработанная в CERN .
- R — язык программирования и программная среда для статистических вычислений и графики. [149]
- ROOT — среда анализа данных C++, разработанная в CERN .
- SciPy — библиотека Python для научных вычислений.
- Джулия – язык программирования, хорошо подходящий для численного анализа и вычислительной техники.
анализ Воспроизводимый
Типичный рабочий процесс анализа данных включает сбор данных, выполнение анализа с помощью различных сценариев, создание визуализаций и написание отчетов. Однако этот рабочий процесс сопряжен с проблемами, включая разделение сценариев анализа и данных, а также разрыв между анализом и документацией. Часто правильный порядок запуска сценариев описывается лишь неформально или хранится в памяти специалиста по обработке данных. Возможность потери этой информации создает проблемы с воспроизводимостью. Чтобы решить эти проблемы, важно иметь сценарии анализа, написанные для автоматизированных, воспроизводимых рабочих процессов. Кроме того, решающее значение имеет динамическая документация, предоставляющая отчеты, понятные как машинам, так и людям, обеспечивая точное представление рабочего процесса анализа даже по мере развития сценариев. [150]
анализу данных Международные по конкурсы
Различные компании или организации проводят конкурсы по анализу данных, чтобы побудить исследователей использовать свои данные или решить конкретный вопрос с помощью анализа данных. [151] [152] Вот несколько примеров известных международных конкурсов по анализу данных: [153]
- Конкурс Kaggle, который проводит компания Kaggle . [154]
- Конкурс анализа данных LTPP, проводимый FHWA и ASCE . [155] [156]
См. также [ править ]
- Актуарная наука
- Аналитика
- Дополненная аналитика
- Большие данные
- Бизнес-аналитика
- Цензура (статистика)
- Вычислительная физика
- Вычислительная наука
- Межотраслевой стандартный процесс интеллектуального анализа данных
- Сбор данных
- Смешение данных
- Управление данными
- Интеллектуальный анализ данных
- Архитектура представления данных
- Наука о данных
- Цифровая обработка сигналов
- Уменьшение размерности
- Ранняя оценка случая
- Исследовательский анализ данных
- Фурье-анализ
- Машинное обучение
- Мультилинейный PCA
- Мультилинейное обучение подпространству
- Многосторонний анализ данных
- Поиск ближайшего соседа
- Идентификация нелинейной системы
- Прогнозная аналитика
- Анализ главных компонентов
- Качественные исследования
- Анализ структурированных данных (статистика)
- Идентификация системы
- Метод испытания
- Анализ текста
- Неструктурированные данные
- Вейвлет
- Список компаний, занимающихся большими данными
- Список наборов данных для исследований в области машинного обучения
Ссылки [ править ]
Цитаты [ править ]
- ↑ Перейти обратно: Перейти обратно: а б «Преобразование неструктурированных данных в полезную информацию» , Большие данные, горное дело и аналитика , Auerbach Publications, стр. 227–246, 12 марта 2014 г., doi : 10.1201/b16666-14 , ISBN 978-0-429-09529-0 , получено 29 мая 2021 г.
- ^ «Множественные аспекты корреляционных функций» , Методы анализа данных для ученых-физиков , Cambridge University Press, стр. 526–576, 2017, doi : 10.1017/9781108241922.013 , ISBN 978-1-108-41678-8 , получено 29 мая 2021 г.
- ^ Ся, Б.С., и Гонг, П. (2015). Обзор бизнес-аналитики посредством анализа данных. Бенчмаркинг , 21 (2), 300-311. дои : 10.1108/BIJ-08-2012-0050
- ^ Изучение анализа данных
- ^ «Правила кодирования данных и исследовательского анализа (EDA) для статистических предположений кодирования данных исследовательского анализа данных (EDA)» , SPSS для промежуточной статистики , Routledge, стр. 42–67, 16 августа 2004 г., doi : 10.4324/9781410611420-6 , ISBN 978-1-4106-1142-0 , получено 29 мая 2021 г.
- ^ Шпион (01.10.2014). «Новый европейский конкурс в области ИКТ сосредоточен на PIC, лазерах и передаче данных» . СПИЭ Профессионал . дои : 10.1117/2.4201410.10 . ISSN 1994-4403 .
- ^ Самандар, Петерссон; Свантессон, София (2017). Создание доверия к eWOM: исследование влияния изображения профиля с гендерной точки зрения . Университет Евле, деловое администрирование. OCLC 1233454128 .
- ^ Спокойной ночи, Джеймс (13 января 2011 г.). «Прогноз для прогнозной аналитики: жарко и становится все жарче» . Статистический анализ и интеллектуальный анализ данных: журнал ASA Data Science Journal . 4 (1): 9–10. дои : 10.1002/sam.10106 . ISSN 1932-1864 гг . S2CID 38571193 .
- ^ Шерман, Рик (4 ноября 2014 г.). Путеводитель по бизнес-аналитике: от интеграции данных к аналитике . Амстердам. ISBN 978-0-12-411528-6 . OCLC 894555128 .
{{cite book}}: CS1 maint: отсутствует местоположение издателя ( ссылка ) - ^ Филд, Джон (2009), «Разделение прослушивания на компоненты» , «Аудирование в языковом классе », Кембридж: Cambridge University Press, стр. 96–109, doi : 10.1017/cbo9780511575945.008 , ISBN 978-0-511-57594-5 , получено 29 мая 2021 г.
- ↑ Перейти обратно: Перейти обратно: а б с Джадд, Чарльз; МакКлеланд, Гэри (1989). Анализ данных . Харкорт Брейс Йованович. ISBN 0-15-516765-0 .
- ^ Тьюки, Джон В. (март 1962 г.). «Джон Тьюки. Будущее анализа данных. Июль 1961 г.» . Анналы математической статистики . 33 (1): 1–67. дои : 10.1214/aoms/1177704711 . Архивировано из оригинала 26 января 2020 г. Проверено 1 января 2015 г.
- ↑ Перейти обратно: Перейти обратно: а б с д и ж г Шатт, Рэйчел; О'Нил, Кэти (2013). Занимаюсь наукой о данных . О'Рейли Медиа . ISBN 978-1-449-35865-5 .
- ^ «ИСПОЛЬЗОВАНИЕ ДАННЫХ» , Справочник по анализу нефтепродуктов , Хобокен, Нью-Джерси: John Wiley & Sons, Inc, стр. 296–303, 06 февраля 2015 г., doi : 10.1002/9781118986370.ch18 , ISBN 978-1-118-98637-0 , получено 29 мая 2021 г.
- ^ Эйнсворт, Пенне (20 мая 2019 г.). Введение в бухгалтерский учет: комплексный подход . Джон Уайли и сыновья. ISBN 978-1-119-60014-5 . OCLC 1097366032 .
- ^ Марго, Роберт А. (2000). Заработная плата и рынки труда в США, 1820-1860 гг . Издательство Чикагского университета. ISBN 0-226-50507-3 . OCLC 41285104 .
- ^ Олусола, Джонсон Адедеджи; Шот, Адебола Адекунле; Уигмане, Абделла; Исайфан, Рима Дж. (7 мая 2021 г.). «Таблица 1: Типы данных и источники данных, собранных для этого исследования» . ПерДж . 9 : е11387. дои : 10.7717/peerj.11387/таблица-1 .
- ^ Макферсон, Дерек (16 октября 2019 г.), «Перспективы аналитиков информационных технологий» , Стратегия данных в колледжах и университетах , Routledge, стр. 168–183, doi : 10.4324/9780429437564-12 , ISBN 978-0-429-43756-4 , S2CID 211738958 , получено 29 мая 2021 г.
- ^ Нельсон, Стивен Л. (2014). Анализ данных Excel для чайников . Уайли. ISBN 978-1-118-89810-9 . OCLC 877772392 .
- ^ «Рисунок 3—исходные данные 1. Необработанные и обработанные значения, полученные с помощью qPCR» . 30 августа 2017 г. doi : 10.7554/elife.28468.029 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ↑ Перейти обратно: Перейти обратно: а б Боханнон, Джон (24 февраля 2016 г.). «Многие опросы, примерно каждый пятый, могут содержать мошеннические данные» . Наука . doi : 10.1126/science.aaf4104 . ISSN 0036-8075 .
- ^ Джинни Скраггс, Гарбер; Гросс, Монти; Слоним, Энтони Д. (2010). Как избежать типичных сестринских ошибок . Wolters Kluwer Health/Lippincott Williams & Wilkins. ISBN 978-1-60547-087-0 . OCLC 338288678 .
- ^ «Очистка данных» . Исследования Майкрософт. Архивировано из оригинала 29 октября 2013 года . Проверено 26 октября 2013 г.
- ^ Хэнкок, РГВ; Картер, Тристан (февраль 2010 г.). «Насколько надежны наши опубликованные археометрические анализы? Влияние аналитических методов с течением времени на элементный анализ обсидианов» . Журнал археологической науки . 37 (2): 243–250. Бибкод : 2010JArSc..37..243H . дои : 10.1016/j.jas.2009.10.004 . ISSN 0305-4403 .
- ↑ Перейти обратно: Перейти обратно: а б с «Perceptual Edge — Джонатан Куми — Лучшие практики для понимания количественных данных — 14 февраля 2006 г.» (PDF) . Архивировано (PDF) из оригинала 5 октября 2014 г. Проверено 12 ноября 2014 г.
- ^ Пелег, Рони; Авдалимова, Анжелика; Фрейд, Тамар (23 марта 2011 г.). «Предоставление пациентам номеров мобильных телефонов и адресов электронной почты: взгляд врача» . Исследовательские заметки BMC . 4 (1): 76. дои : 10.1186/1756-0500-4-76 . ISSN 1756-0500 . ПМК 3076270 . ПМИД 21426591 .
- ^ Гудман, Ленн Эван (1998). Иудаизм, права человека и человеческие ценности . Издательство Оксфордского университета. ISBN 0-585-24568-1 . OCLC 45733915 .
- ^ Ханзо, Лайос. «Слепая совместная оценка канала максимального правдоподобия и обнаружение данных для систем с одним входом и множеством выходов» . дои : 10.1049/iet-tv.44.786 . Проверено 29 мая 2021 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Хеллерштейн, Джозеф (27 февраля 2008 г.). «Количественная очистка данных для больших баз данных» (PDF) . Отдел компьютерных наук EECS : 3. Архивировано (PDF) из оригинала 13 октября 2013 года . Проверено 26 октября 2013 г.
- ^ Дэвис, Стив; Петтенгилл, Джеймс Б.; Ло, Ян; Пейн, Джастин; Шпунтов, Ал; Рэнд, Хью; Штейн, Эррол (26 августа 2015 г.). «CFSAN SNP Pipeline: автоматизированный метод построения матриц SNP на основе данных последовательностей следующего поколения» . PeerJ Информатика . 1 : е20. doi : 10.7717/peerj-cs.20/supp-1 .
- ^ «ФТК запрашивает дополнительные данные» . Аналитик насосной отрасли . 1999 (48): 12 декабря 1999 г. doi : 10.1016/s1359-6128(99)90509-8 . ISSN 1359-6128 .
- ^ «Изучение ваших данных с помощью визуализации данных и описательной статистики: общая описательная статистика для количественных данных» . 2017. дои : 10.4135/9781529732795 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Мюррей, Дэниел Г. (2013). Таблицы ваших данных! : быстрый и простой визуальный анализ с помощью программного обеспечения Tableau . Дж. Уайли и сыновья. ISBN 978-1-118-61204-0 . OCLC 873810654 .
- ^ Бен-Ари, Мордехай (2012), «Логика первого порядка: формулы, модели, таблицы» , Математическая логика для информатики , Лондон: Springer London, стр. 131–154, doi : 10.1007/978-1-4471-4129 -7_7 , ISBN 978-1-4471-4128-0 , получено 31 мая 2021 г.
- ^ Соса, Эрнест (2011). Причинно-следственная связь . Оксфордский университет. Нажимать. ISBN 978-0-19-875094-9 . OCLC 767569031 .
- ^ Эванс, Мишель В.; Даллас, Тэд А.; Хан, Барбара А.; Мердок, Кортни С.; Дрейк, Джон М. (28 февраля 2017 г.). Брэди, Оливер (ред.). «Рисунок 2. Важность переменной по перестановке, в среднем по 25 моделям» . электронная жизнь . 6 : e22053. дои : 10.7554/elife.22053.004 .
- ^ Уотсон, Кевин; Гальперин, Израиль; Агилера-Кастельс, Джоан; Яконо, Антонио Делло (12 ноября 2020 г.). «Таблица 3: Описательная (среднее ± стандартное отклонение), логическая (95% ДИ) и качественная статистика (ES) всех переменных между самостоятельно выбранными и заранее определенными условиями» . ПерДж . 8 : е10361. doi : 10.7717/peerj.10361/table-3 .
- ^ Кортес-Молино, Альваро; Аулло-Маэстро, Изабель; Фернандес-Люке, Исмаэль; Флорес-Мойя, Антонио; Каррейра, Хосе А.; Сальво, А. Энрике (22 октября 2020 г.). «Таблица 3: Лучшие модели регрессии между данными LIDAR (независимая переменная) и полевыми данными Forestereo (зависимая переменная), используемые для картирования пространственного распределения основных переменных структуры леса» . ПерДж . 8 : е10158. дои : 10.7717/peerj.10158/таблица-3 .
- ^ Условия международных продаж , Beck/Hart, 2014, doi : 10.5040/9781472561671.ch-003 , ISBN 978-1-4725-6167-1 , получено 31 мая 2021 г.
- ^ Нвабуэзе, JC (21 мая 2008 г.). «Показатели оценок линейной модели с автокоррелируемыми погрешностями, когда независимая переменная является нормальной» . Журнал Нигерийской ассоциации математической физики . 9 (1). дои : 10.4314/jonamp.v9i1.40071 . ISSN 1116-4336 .
- ^ Конвей, Стив (4 июля 2012 г.). «Предупреждение о вводе данных и визуальном выводе при анализе социальных сетей» . Британский журнал менеджмента . 25 (1): 102–117. дои : 10.1111/j.1467-8551.2012.00835.x . hdl : 2381/36068 . ISSN 1045-3172 . S2CID 154347514 .
- ^ «Покупки клиентов и другие повторяющиеся события» , Анализ данных с использованием SQL и Excel® , Индианаполис, Индиана: John Wiley & Sons, Inc., стр. 367–420, 29 января 2016 г., doi : 10.1002/9781119183419.ch8 , ISBN 978-1-119-18341-9 , получено 31 мая 2021 г.
- ^ Гранжан, Мартин (2014). «Знания — это сеть» (PDF) . Цифровые ноутбуки . 10 (3): 37–54. дои : 10.3166/lcn.10.3.37-54 . Архивировано (PDF) из оригинала 27 сентября 2015 г. Проверено 5 мая 2015 г.
- ^ Требования к данным для полупроводникового кристалла. Форматы данных обмена и словарь данных , BSI British Standards, doi : 10.3403/02271298 , получено 31 мая 2021 г.
- ^ Йи, Д. (1 апреля 1985 г.). «Как эффективно донести свое сообщение до аудитории» . Геронтолог . 25 (2): 209. doi : 10.1093/geront/25.2.209 . ISSN 0016-9013 .
- ^ Бемовска-Калабун, Ольга; Вонзович, Павел; Напора-Рутковски, Лукаш; Новак-Жичинская, Зузанна; Вежбицкая, Малгожата (11 июня 2019 г.). «Дополнительная информация 1: Исходные данные для диаграмм и таблиц» . doi : 10.7287/peerj.preprints.27793v1/supp-1 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Визуализация данных о музеях Великобритании: гистограммы, линейные диаграммы и тепловые карты . 2021. дои : 10.4135/9781529768749 . ISBN 9781529768749 . S2CID 240967380 .
- ^ Тунки Нейра, Хосе Мануэль (19 сентября 2019 г.). «Спасибо за ваш отзыв. В прилагаемом PDF-файле вы найдете подробный ответ на поднятые вами вопросы» . дои : 10.5194/hess-2019-325-ac2 . S2CID 241041810 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Брэкетт, Джон В. (1989), «Выполнение курсов по проекту анализа требований для внешних заказчиков» , «Проблемы образования в области разработки программного обеспечения» , Нью-Йорк, штат Нью-Йорк: Springer New York, стр. 276–285, doi : 10.1007/978-1-4613 -9614-7_20 , ISBN 978-1-4613-9616-1 , получено 3 июня 2021 г.
- ^ Викхейс, Крис АГ; Вонгтим, Пророк; Рауф, Ауну; Танчароен, Анчана; Хеймпель, Джордж Э.; Ле, Нхунг Т.Т.; Фанани, Мухаммад Зайнал; Гурр, Джефф М.; Лундгрен, Джонатан Г.; Бурра, Дхарани Д.; Палао, Лео К.; Хайман, Гленн; Милостивый, Игнатий; Ле, Ви X.; Кок, Мэтью Дж.В.; Чхарнтке, Тея; Раттен, Стив Д.; Нгуен, Лием В.; Ты, Миншэн; Лу, Яньхуэй; Кетелаар, Джон В.; Гёрген, Георг; Нойеншвандер, Питер (19 октября 2018 г.). «Рисунок 2: Колебания численности мучнистого червеца каждые два месяца на юге Вьетнама за двухлетний период» . ПерДж . 6 : е5796. дои : 10.7717/peerj.5796/рис-2 .
- ^ Риль, Эмили (2014), «Выборка двухкатегорийных аспектов теории квазикатегорий» , Категорическая теория гомотопии , Кембридж: Cambridge University Press, стр. 318–336, doi : 10.1017/cbo9781107261457.019 , ISBN 978-1-107-26145-7 , получено 3 июня 2021 г.
- ^ «X-барная диаграмма». Энциклопедия производства и управления производством . 2000. с. 841. дои : 10.1007/1-4020-0612-8_1063 . ISBN 978-0-7923-8630-8 .
- ^ «Диаграмма C5.3. Процент молодых людей в возрасте 15–19 лет, не имеющих образования, по статусу на рынке труда (2012 г.)» . дои : 10.1787/888933119055 . Проверено 3 июня 2021 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ «Диаграмма 7: Домохозяйства: расходы на конечное потребление в сравнении с фактическим индивидуальным потреблением» . дои : 10.1787/665527077310 . Проверено 3 июня 2021 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Чао, Люк Х.; Чан, Джэбон; Джонсон, Адам; Нгуен, Энтони; Грей, Натаниэль С.; Ян, Присцилла Л.; Харрисон, Стивен К. (12 июля 2018 г.). Ян, Рейнхард; Шекман, Рэнди (ред.). «Рисунок 4. Частота гемифузии (измеренная как гашение флуоресценции DiD) в зависимости от количества связанных молекул Alexa-fluor-555/3-110-22» . электронная жизнь . 7 : е36461. дои : 10.7554/elife.36461.006 .
- ^ Гарнье, Элоди М.; Фуре, Настасья; Дескоэнс, Медерик (3 февраля 2020 г.). «Таблица 2: Сравнение графиков точечной диаграммы, диаграммы скрипки + рассеяния, тепловой карты и графика ViSiElse» . ПерДж . 8 : е8341. doi : 10.7717/peerj.8341/table-2 .
- ^ «Сравнительная таблица продуктов: носимые устройства» . Набор данных PsycEXTRA . 2009. doi : 10.1037/e539162010-006 . Проверено 3 июня 2021 г.
- ^ «Стивен Фью – Перцепционная грань – Выбор правильного графика для вашего сообщения – 2004» (PDF) . Архивировано (PDF) из оригинала 05 октября 2014 г. Проверено 29 октября 2014 г.
- ^ «Матрица выбора реберного графа Стивена Фью» (PDF) . Архивировано (PDF) из оригинала 05 октября 2014 г. Проверено 29 октября 2014 г.
- ^ «Рекомендуемые лучшие практики» . 01.10.2008. doi : 10.14217/9781848590151-8-en . Проверено 3 июня 2021 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Хобольд, Эдилсон; Пирес-Лопес, Витор; Гомес-Кампос, Россана; Арруда, Мигель де; Андруске, Синтия Ли; Пачеко-Каррильо, Хайме; Коссио-Боланьос, Марко Антонио (30 ноября 2017 г.). «Таблица 1: Описательная статистика (среднее ± стандартное отклонение) для соматических переменных и показателей физической подготовки для мужчин и женщин» . ПерДж . 5 : е4032. дои : 10.7717/peerj.4032/таблица-1 .
- ^ Аблин, Джейкоб Н.; Зохар, Ада Х.; Зарайя-Блюм, Реут; Бускила, Дэн (13 сентября 2016 г.). «Таблица 2: Кластерный анализ, представляющий средние значения психологических переменных для каждой кластерной группы» . ПерДж . 4 : е2421. дои : 10.7717/peerj.2421/таблица-2 .
- ^ «Консультанты, нанятые McKinsey & Company» , Organizational Behavior 5 , Routledge, стр. 77–82, 30 июля 2008 г., doi : 10.4324/9781315701974-15 , ISBN 978-1-315-70197-4 , получено 3 июня 2021 г.
- ^ Антифан (2007), Олсон, С. Дуглас (редактор), «Антифан H6 fr.172.1-4, из «Женщин, которые были похожи друг на друга, или мужчин, которые были похожи друг на друга» , « Сломанный смех: избранные фрагменты греческой комедии » , Оксфорд University Press, doi : 10.1093/oseo/instance.00232915 , ISBN 978-0-19-928785-7 , получено 3 июня 2021 г.
- ^ Кэри, Мэлаки (ноябрь 1981 г.). «О взаимоисключающих и коллективно исчерпывающих свойствах функций спроса» . Экономика . 48 (192): 407–415. дои : 10.2307/2553697 . ISSN 0013-0427 . JSTOR 2553697 .
- ^ «Общая сумма налоговых поступлений» . дои : 10.1787/352874835867 . Проверено 3 июня 2021 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ «Автомобиль двойного назначения может решить транспортные проблемы» . Архив новостей химической и инженерной промышленности . 46 (24): 44. 3 июня 1968 г. doi : 10.1021/cen-v046n024.p044 . ISSN 0009-2347 .
- ^ Хекман (1978). «Простые статистические модели для дискретных панельных данных, разработанные и примененные для проверки гипотезы истинной государственной зависимости против гипотезы ложной государственной зависимости» . Annales de l'inséé (30/31): 227–269. дои : 10.2307/20075292 . ISSN 0019-0209 . JSTOR 20075292 .
- ^ Кунц, Дин (2017). Ложная память . Заголовок Книгоиздание. ISBN 978-1-4722-4830-5 . OCLC 966253202 .
- ^ Мандей, Стивен CR (1996), «Безработица, инфляция и кривая Филлипса» , Current Developments in Economics , Лондон: Macmillan Education UK, стр. 186–218, doi : 10.1007/978-1-349-24986-2_11 , ISBN 978-0-333-64444-7 , получено 3 июня 2021 г.
- ^ Луанграт, Пол И. (2013). «Альфа- и бета-тесты для определения логических ошибок типа I и типа II при проверке гипотез» . Электронный журнал ССРН . дои : 10.2139/ssrn.2332756 . ISSN 1556-5068 .
- ^ Уолко, Энн М. (2006). Отказ от гипотезы второго поколения: сохранение эстонской этнической принадлежности в Лейквуде, штат Нью-Джерси . АМС Пресс. ISBN 0-404-19454-0 . OCLC 467107876 .
- ↑ Перейти обратно: Перейти обратно: а б Янамандра, Венкатарамана (сентябрь 2015 г.). «Изменения обменного курса и инфляция в Индии: какова степень влияния обменного курса на импорт?» . Экономический анализ и политика . 47 : 57–68. дои : 10.1016/j.eap.2015.07.004 . ISSN 0313-5926 .
- ^ Мудиянселаге, Наваратна; Наваратна, Пубуду Манодж. Характеристика эпигенетических изменений и их связь с аномалиями экспрессии генов при светлоклеточном почечно-клеточном раке . OCLC 1190697848 .
- ^ Морено Дельгадо, Дэвид; Мёллер, Тор С.; Стер, Жанна; Хиральдо, Хесус; Морел, Дэмиен; Ровира, Ксавьер; Шоллер, Полина; Цвир, Джурриан М.; Перрой, Джули; Дюрру, Тьерри; Тринкет, Эрик; Презо, Лоран; Рондар, Филипп; Пин, Жан-Филипп (29 июня 2017 г.). Чао, Моисей V (ред.). «Приложение 1 — рисунок 5. Данные кривой, включенные в Приложение 1 — таблица 4 (сплошные точки) и теоретическая кривая с использованием параметров уравнения Хилла из Приложения 1 — таблица 5 (кривая линия)» . электронная жизнь . 6 : е25233. дои : 10.7554/elife.25233.027 .
- ^ Фейнманн, Джейн. «Как инженеры и журналисты могут помочь друг другу?» (Видео). Институт инженерии и технологий. дои : 10.1049/iet-tv.48.859 . Проверено 3 июня 2021 г.
- ^ Дул, Январь (2015). «Анализ необходимых условий (NCA): логика и методология «необходимой, но недостаточной» причинности» . Электронный журнал ССРН . дои : 10.2139/ssrn.2588480 . hdl : 1765/77890 . ISSN 1556-5068 . S2CID 219380122 .
- ^ Роберт Амар, Джеймс Иган и Джон Стаско (2005) «Низкоуровневые компоненты аналитической деятельности в визуализации информации». Архивировано 13 февраля 2015 г. в Wayback Machine.
- ^ Уильям Ньюман (1994) «Предварительный анализ продуктов исследований HCI с использованием рефератов проформы». Архивировано 3 марта 2016 г. в Wayback Machine.
- ^ Мэри Шоу (2002) «Что делает исследования в области разработки программного обеспечения хорошими?» Архивировано 5 ноября 2018 г. в Wayback Machine.
- ↑ Перейти обратно: Перейти обратно: а б Явари, Али; Джаяраман, Прем Пракаш; Георгакопулос, Димитриос; Непал, Сурья (2017). ConTaaS: подход к контекстуализации в масштабе Интернета для разработки эффективных приложений Интернета вещей . Материалы 50-й Гавайской международной конференции по системным наукам (HICSS50 2017). Гавайский университет в Маноа. дои : 10.24251/HICSS.2017.715 . hdl : 10125/41879 . ISBN 9780998133102 .
- ^ «Инструмент подключения передает данные между базами данных и статистическими продуктами» . Вычислительная статистика и анализ данных . 8 (2): 224. Июль 1989 г. doi : 10.1016/0167-9473(89)90021-2 . ISSN 0167-9473 .
- ^ «Информация, относящаяся к вашей работе» , Получение информации для эффективного управления , Routledge, стр. 48–54, 11 июля 2007 г., doi : 10.4324/9780080544304-16 (неактивен 1 мая 2024 г.), ISBN 978-0-08-054430-4 , получено 3 июня 2021 г.
{{citation}}: CS1 maint: DOI неактивен по состоянию на май 2024 г. ( ссылка ) - ^ Леманн, Э.Л. (2010). Проверка статистических гипотез . Спрингер. ISBN 978-1-4419-3178-8 . OCLC 757477004 .
- ^ Филдинг, Генри (14 августа 2008 г.), «Состоящий частично из фактов, а частично из наблюдений над ними» , Том Джонс , Oxford University Press, doi : 10.1093/owc/9780199536993.003.0193 , ISBN 978-0-19-953699-3 , получено 3 июня 2021 г.
- ^ «Бюджетное управление Конгресса — Бюджет и экономический прогноз — август 2010 г. — Таблица 1.7 на странице 24» (PDF) . 18 августа 2010 г. Архивировано из оригинала 27 февраля 2012 г. Проверено 31 марта 2011 г.
- ^ «Чувство принадлежности студентов по иммигрантскому происхождению» . Результаты PISA 2015 (Том III) . ПИЗА. 19 апреля 2017 г. doi : 10.1787/9789264273856-table125-en . ISBN 9789264273818 . ISSN 1996-3777 .
- ^ Гордон, Роджер (март 1990 г.). «Действуют ли публично торгуемые корпорации в общественных интересах?» . Рабочие документы Национального бюро экономических исследований . Кембридж, Массачусетс. дои : 10.3386/w3303 .
- ^ Минарди, Марго (24 сентября 2010 г.), «Факты и мнения» , «Создание истории рабства » , Oxford University Press, стр. 13–42, doi : 10.1093/acprof:oso/9780195379372.003.0003 , ISBN 978-0-19-537937-2 , получено 3 июня 2021 г.
- ^ Ривард, Джиллиан Р. (2014). Предвзятость подтверждения при опросе свидетелей: могут ли интервьюеры игнорировать свои предубеждения? (Диссертация). Международный университет Флориды. дои : 10.25148/etd.fi14071109 .
- ^ Папино, Дэвид (1988), «Дискредитирует ли социология науки науку?» , Релятивизм и реализм в науке , Дордрехт: Springer Нидерланды, стр. 37–57, doi : 10.1007/978-94-009-2877-0_2 , ISBN 978-94-010-7795-8 , получено 3 июня 2021 г.
- ^ Бромме, Райнер; Гессен, Фридрих В.; Спада, Ганс, ред. (2005). Барьеры и предубеждения в компьютерной передаче знаний . дои : 10.1007/b105100 . ISBN 978-0-387-24317-7 .
- ^ Хойер, Ричардс (10 июня 2019 г.). Хойер, Ричардс Дж. (ред.). Количественные подходы к политической разведке . дои : 10.4324/9780429303647 . ISBN 9780429303647 . S2CID 145675822 .
- ^ «Введение» (PDF) . cia.gov . Архивировано (PDF) из оригинала 25 октября 2021 г. Проверено 25 октября 2021 г.
- ^ «Рисунок 6.7. Различия в показателях грамотности в странах ОЭСР в целом отражают различия в навыках счета» . дои : 10.1787/888934081549 . Проверено 3 июня 2021 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ «Блумберг – Барри Ритхольц – Плохая математика, которая сойдёт за понимание – 28 октября 2014 г.» . Архивировано из оригинала 29 октября 2014 г. Проверено 29 октября 2014 г.
- ^ Гуснайни, Нуриска; Андесто, Рони; Ермавати (15 декабря 2020 г.). «Влияние размера регионального правительства, законодательного размера, численности населения и межбюджетных доходов на раскрытие финансовой отчетности» . Европейский журнал исследований бизнеса и менеджмента . 5 (6). дои : 10.24018/ejbmr.2020.5.6.651 . ISSN 2507-1076 . S2CID 231675715 .
- ^ Линси, Джули С .; Беккер, Блейк (2011), «Эффективность методов брейнрайтинга: сравнение номинальных групп с реальными командами» , Design Creativity 2010 , Лондон: Springer London, стр. 165–171, doi : 10.1007/978-0-85729-224-7_22 , ISBN 978-0-85729-223-0 , получено 3 июня 2021 г.
- ^ Лион, Дж. (апрель 2006 г.). «Предполагаемый ответственный адрес в сообщениях электронной почты» . дои : 10.17487/rfc4407 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Сток, Евгений (10 июня 2017 г.). История церковно-миссионерского общества, его окружение, его люди и его работа . Ханзебукс ГмбХ. ISBN 978-3-337-18120-8 . OCLC 1189626777 .
- ^ Гросс, Уильям Х. (июль 1979 г.). «Оценка купонов и циклы процентных ставок» . Журнал финансовых аналитиков . 35 (4): 68–71. дои : 10.2469/faj.v35.n4.68 . ISSN 0015-198X .
- ^ «25. Общие государственные расходы» . дои : 10.1787/888932348795 . Проверено 3 июня 2021 г.
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Гонсалес-Видал, Аврора; Морено-Кано, Виктория (2016). «На пути к моделям интеллектуальных зданий энергоэффективности на основе интеллектуальной аналитики данных» . Procedia Информатика . 83 (Эльзевир): 994–999. дои : 10.1016/j.procs.2016.04.213 .
- ^ «Низкоэнергетическое кондиционирование воздуха и управление освещением» , Building Energy Management Systems , Routledge, стр. 406–439, 04 июля 2013 г., doi : 10.4324/9780203477342-18 (неактивен 1 мая 2024 г.), ISBN 978-0-203-47734-2 , получено 3 июня 2021 г.
{{citation}}: CS1 maint: DOI неактивен по состоянию на май 2024 г. ( ссылка ) - ^ Давенпорт, Томас; Харрис, Жанна (2007). Конкуренция в аналитике . О'Рейли. ISBN 978-1-4221-0332-6 .
- ^ Ааронс, Д. (2009). В докладе говорится, что штаты берут курс на создание систем данных об учениках. Неделя образования, 29 (13), 6.
- ^ Рэнкин, Дж. (28 марта 2013 г.). Как системы данных и отчеты могут бороться с эпидемией ошибок анализа данных или распространять ее, и чем могут помочь руководители преподавателей. Архивировано 26 марта 2019 г. на презентации Wayback Machine , проведенной в рамках школьного саммита технологического информационного центра административного лидерства (TICAL).
- ^ Бродерманн, Эккарт Дж. (2018), «Статья 2.2.1 (Сфера действия раздела)» , Коммерческое право , Nomos Verlagsgesellschaft mbH & Co. KG, стр. 525, номер домена : 10.5771/9783845276564-525 , ISBN 978-3-8452-7656-4 , получено 3 июня 2021 г.
- ^ Джех, Дж.Л. (21 апреля 1960 г.). «Анализ данных об искажении размеров исходных 24 трубок для сертификации качества» . дои : 10.2172/10170345 . S2CID 110058009 .
{{cite journal}}: Для цитирования журнала требуется|journal=( помощь ) - ^ Адер 2008a , с. 337.
- ^ Кьелл, Оскар Н.Э.; Томпсон, Сэм (19 декабря 2013 г.). «Описательная статистика, указывающая среднее значение, стандартное отклонение и частоту пропущенных значений для каждого условия (N = количество участников) и для зависимых переменных (DV)» . ПерДж . 1 : е231. doi : 10.7717/peerj.231/table-1 .
- ^ Практика работы с отдаленными наблюдениями , ASTM International, номер документа : 10.1520/e0178-16a , получено 3 июня 2021 г.
- ^ «Альтернативные схемы кодирования для фиктивных переменных» , Регрессия с фиктивными переменными , Ньюбери-Парк, Калифорния: SAGE Publications, Inc., стр. 64–75, 1993, doi : 10.4135/9781412985628.n5 , ISBN 978-0-8039-5128-0 , получено 3 июня 2021 г.
- ^ Адер 2008a , стр. 338–341.
- ^ Данилюк, ПМ (июль 1960 г.). «Расчет смещения исходного контура шестерен при их проверке шариками» . Методика измерения . 3 (7): 585–587. дои : 10.1007/bf00977716 . ISSN 0543-1972 . S2CID 121058145 .
- ^ Ньюман, Исадор (1998). Качественно-количественная методология исследования: изучение интерактивного континуума . Издательство Университета Южного Иллинойса. ISBN 0-585-17889-5 . OCLC 44962443 .
- ^ Тервиллигер, Джеймс С.; Леле, Каустуб (июнь 1979 г.). «Некоторые взаимосвязи между внутренней согласованностью, воспроизводимостью и однородностью» . Журнал образовательных измерений . 16 (2): 101–108. дои : 10.1111/j.1745-3984.1979.tb00091.x . ISSN 0022-0655 .
- ^ Адер 2008a , стр. 341–342.
- ^ Адер 2008a , с. 344.
- ^ Tabachnick & Fidell, 2007, p. 87-88.
- ^ Чакарова, Калина (октябрь 2020 г.). «2020/31 Сравнение должностных инструкций недостаточно для проверки одинаковой ценности работы (БГ)» . Европейские примеры трудового законодательства . 5 (3): 168–170. дои : 10.5553/eelc/187791072020005003006 . ISSN 1877-9107 . S2CID 229008899 .
- ^ Процедуры случайной выборки и рандомизации , Британские стандарты BSI, номер номера : 10.3403/30137438 , получено 3 июня 2021 г.
- ^ Адер 2008a , стр. 344–345.
- ^ Сандберг, Маргарета (июнь 2006 г.). «Процедуры акупунктуры должны быть точно описаны» . Акупунктура в медицине . 24 (2): 92–94. дои : 10.1136/аим.24.2.92 . ISSN 0964-5284 . ПМИД 16783285 . S2CID 30286074 .
- ^ Яарсма, К.Ф. Дорожное движение в сельской местности: наблюдения и анализ дорожного движения на юго-западе Фрисландии и разработка модели дорожного движения . OCLC 1016575584 .
- ^ Фот, Кристиан; Хедрик, Брэндон П.; Эскурра, Мартин Д. (18 января 2016 г.). «Рисунок 4: Регрессионный анализ размера центроида для основной выборки» . ПерДж . 4 : е1589. дои : 10.7717/peerj.1589/рис-4 .
- ^ Адер 2008a , с. 345.
- ^ «Последние годы (1975–84)» , «Дорога не пройдена» , Boydell & Brewer, стр. 853–922, 18 июня 2018 г., doi : 10.2307/j.ctv6cfncp.26 , ISBN 978-1-57647-332-0 , S2CID 242072487 , получено 3 июня 2021 г.
- ^ Фицморис, Кэтрин (17 марта 2015 г.). Судьба, переписанная . ХарперКоллинз. ISBN 978-0-06-162503-9 . OCLC 905090570 .
- ^ Адер 2008a , стр. 345–346.
- ^ Адер 2008a , стр. 346–347.
- ^ Адер 2008a , стр. 349–353.
- ^ Биллингс С.А. «Идентификация нелинейных систем: методы NARMAX во временной, частотной и пространственно-временной областях». Уайли, 2013 г.
- ^ Адер 2008b , с. 363.
- ^ «Исследовательский анализ данных» , Python® для пользователей R , Хобокен, Нью-Джерси, США: John Wiley & Sons, Inc., стр. 119–138, 13 октября 2017 г., doi : 10.1002/9781119126805.ch4 , hdl : 11380/ 971504 , ISBN 978-1-119-12680-5 , получено 3 июня 2021 г.
- ^ «Участие в исследовательском анализе данных, визуализации и проверке гипотез – исследовательский анализ данных, геовизуализация и данные» , Spatial Analysis , CRC Press, стр. 106–139, 28 июля 2015 г., doi : 10.1201/b18808-8 , ISBN 978-0-429-06936-9 , S2CID 133412598 , получено 3 июня 2021 г.
- ^ «Гипотезы о категориях» , «Начальная статистика: краткое и понятное руководство» , Лондон: SAGE Publications Ltd, стр. 138–151, 2010 г., doi : 10.4135/9781446287873.n14 , ISBN 978-1-84920-098-1 , получено 3 июня 2021 г.
- ^ Сордо, Рашель Дель; Сидони, Анджело (декабрь 2008 г.). «Реактивность клеточной мембраны MIB-1: открытие, которое следует интерпретировать осторожно» . Прикладная иммуногистохимия и молекулярная морфология . 16 (6): 568. doi : 10.1097/pai.0b013e31817af2cf . ISSN 1541-2016 . ПМИД 18800001 .
- ^ Лике, Бенуа; Риу, Жереми (8 июня 2013 г.). «Коррекция уровня значимости при попытке многократного преобразования объясняющей переменной в обобщенных линейных моделях» . Методология медицинских исследований BMC . 13 (1): 75. дои : 10.1186/1471-2288-13-75 . ISSN 1471-2288 . ПМК 3699399 . ПМИД 23758852 .
- ↑ Перейти обратно: Перейти обратно: а б с Маккардл, Джон Дж. (2008). «Некоторые этические проблемы подтверждающего и исследовательского анализа» . Набор данных PsycEXTRA . дои : 10.1037/e503312008-001 . Проверено 3 июня 2021 г.
- ^ Адер 2008b , стр. 361–362.
- ^ Адер 2008b , стр. 361–371.
- ^ Трусвелл IV, Уильям Х., изд. (2009), «3 Подтяжка лица: руководство по безопасным, надежным и воспроизводимым результатам» , Хирургическое омоложение лица , Штутгарт: Георг Тиме Верлаг, номер документа : 10.1055/b-0034-73436 , ISBN 978-1-58890-491-1 , получено 3 июня 2021 г.
- ^ Бенсон, Ной С; Винавер, Джонатан (декабрь 2018 г.). «Байесовский анализ ретинотопических карт» . электронная жизнь . 7 . дои : 10.7554/elife.40224 . ПМК 6340702 . ПМИД 30520736 . Дополнительный файл 1. Схема перекрестной проверки. два : 10.7554/elife.40224.014
- ^ Сяо, Ченг (2014), «Перекрестно-зависимые панельные данные» , Анализ панельных данных , Кембридж: Cambridge University Press, стр. 327–368, doi : 10.1017/cbo9781139839327.012 , ISBN 978-1-139-83932-7 , получено 3 июня 2021 г.
- ^ Хьорт, Дж. С. Урбан (19 октября 2017 г.), «Перекрестная проверка» , Компьютерные интенсивные статистические методы , Чепмен и Холл / CRC, стр. 24–56, doi : 10.1201/9781315140056-3 , ISBN 978-1-315-14005-6 , получено 3 июня 2021 г.
- ^ Шейхолеслами, Рази; Разави, Саман; Хагнегадар, Амин (10 октября 2019 г.). «Что нам делать, если модель выходит из строя? Рекомендации по глобальному анализу чувствительности моделей Земли и экологических систем» . Разработка геонаучной модели . 12 (10): 4275–4296. Бибкод : 2019GMD....12.4275S . doi : 10.5194/gmd-12-4275-2019 . ISSN 1991-9603 . S2CID 204900339 .
- ^ Программа развития ООН (2018). «Комплексные индексы человеческого развития». Индексы и индикаторы человеческого развития 2018 . Объединенные Нации. стр. 21–41. doi : 10.18356/ce6f8e92-en . S2CID 240207510 .
- ^ Уайли, Мэтт; Уайли, Джошуа Ф. (2019), «Многомерная визуализация данных» , Advanced R Statistical Programming and Data Models , Беркли, Калифорния: Apress, стр. 33–59, doi : 10.1007/978-1-4842-2872-2_2 , ISBN 978-1-4842-2871-5 , S2CID 86629516 , получено 3 июня 2021 г.
- ^ Майлунд, Томас (2022). Начало науки о данных в R 4: анализ данных, визуализация и моделирование для специалиста по данным (2-е изд.). ISBN 978-148428155-0 .
- ^ Ордуна-Малеа, Энрике; Алонсо-Арройо, Адольфо (2018), «Модель киберметрического анализа для измерения частных компаний» , Киберметрические методы оценки организаций, использующих веб-данные , Elsevier, стр. 63–76, doi : 10.1016/b978-0-08-101877 -4.00003-х , ISBN 978-0-08-101877-4 , получено 3 июня 2021 г.
- ^ Лин, А.Р. Потребитель в австрийской экономике и австрийский взгляд на потребительскую политику . Университет Вагенингена. ISBN 90-5808-102-8 . OCLC 1016689036 .
- ^ «Примеры анализа данных о выживании» , Статистические методы анализа данных о выживании , Серия Уайли по вероятности и статистике, Хобокен, Нью-Джерси, США: John Wiley & Sons, Inc., 30 июня 2003 г., стр. 19–63, doi : 10.1002/0471458546.ch3 , ISBN 978-0-471-45854-8 , получено 3 июня 2021 г.
- ^ «Сообщество машинного обучения бросает вызов Хиггсу» . Журнал «Симметрия» . 15 июля 2014 г. Архивировано из оригинала 16 апреля 2021 г. Проверено 14 января 2015 г.
- ^ Неме, Жан (29 сентября 2016 г.). «Международный конкурс по анализу данных LTPP» . Федеральное управление автомобильных дорог. Архивировано из оригинала 21 октября 2017 года . Проверено 22 октября 2017 г.
- ^ «Data.Gov:Долгосрочная эксплуатация дорожного покрытия (LTPP)» . 26 мая 2016. Архивировано из оригинала 1 ноября 2017 года . Проверено 10 ноября 2017 г.
Библиография [ править ]
- Адер, Герман Дж . (2008a). «Глава 14: Фазы и начальные шаги анализа данных». В Адере, Герман Дж.; Мелленберг, Гидеон Дж .; Хэнд, Дэвид Дж. (ред.). Консультирование по методам исследования: компаньон консультанта . Хейзен, Нидерланды: Паб Йоханнес ван Кессель. стр. 333–356. ISBN 9789079418015 . OCLC 905799857 .
- Адер, Герман Дж . (2008b). «Глава 15: Основной этап анализа». В Адере, Герман Дж.; Мелленберг, Гидеон Дж .; Хэнд, Дэвид Дж. (ред.). Консультирование по методам исследования: компаньон консультанта . Хейзен, Нидерланды: Паб Йоханнес ван Кессель. стр. 357–386. ISBN 9789079418015 . OCLC 905799857 .
- Табачник, Б.Г. и Фиделл, Л.С. (2007). Глава 4. Приведение себя в порядок. Данные скрининга перед анализом. В Б.Г. Табачнике и Л.С. Фиделле (ред.), Использование многомерной статистики, пятое издание (стр. 60–116). Бостон: Pearson Education, Inc. / Аллин и Бэкон.
Дальнейшее чтение [ править ]
- Адер, Х.Дж. и Мелленберг, Г.Дж. (при участии DJ Hand) (2008). Консультирование по методам исследования: помощник консультанта . Хейзен, Нидерланды: Издательство Йоханнеса ван Кесселя. ISBN 978-90-79418-01-5
- Чемберс, Джон М.; Кливленд, Уильям С.; Кляйнер, Бит; Тьюки, Пол А. (1983). Графические методы анализа данных , Wadsworth/Duxbury Press. ISBN 0-534-98052-X
- Фанданго, Армандо (2017). Анализ данных Python, 2-е издание . Издательство Packt. ISBN 978-1787127487
- Джуран, Джозеф М.; Годфри, А. Блэнтон (1999). Справочник Джурана по качеству, 5-е издание. Нью-Йорк: МакГроу Хилл. ISBN 0-07-034003-X
- Льюис-Бек, Майкл С. (1995). Анализ данных: введение , Sage Publications Inc, ISBN 0-8039-5772-6
- NIST/SEMATECH (2008) Справочник по статистическим методам ,
- Пыздек Т. (2003). Справочник по инженерному обеспечению качества , ISBN 0-8247-4614-7
- Ричард Верьярд (1984). Прагматический анализ данных . Оксфорд: Научные публикации Блэквелла. ISBN 0-632-01311-7
- Табачник, Б.Г.; Фиделл, Л.С. (2007). Использование многомерной статистики, 5-е издание . Бостон: Pearson Education, Inc. / Аллин и Бэкон, ISBN 978-0-205-45938-4
| Базы данных органов управления : Национальные |
|---|