Обратное распространение ошибки
Возможно, эту статью необходимо реорганизовать, чтобы она соответствовала рекомендациям Википедии по оформлению . Причина: непоследовательное использование имен переменных и терминологии без соответствующих изображений. ( Август 2022 г. ) |
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
В машинном обучении обратное распространение ошибки — это метод оценки градиента , используемый для обучения моделей нейронных сетей. Оценка градиента используется алгоритмом оптимизации сети для вычисления обновлений параметров .
Это эффективное применение правила цепочки к нейронным сетям. [1] Он также известен как обратный режим автоматического дифференцирования или обратного накопления благодаря Сеппо Линнаинмаа (1970). [2] [3] [4] [5] [6] [7] [8] Термин «коррекция ошибок обратного распространения ошибки» был введен в 1962 году Фрэнком Розенблаттом . [9] [1] но он не знал, как это реализовать, хотя у Генри Дж. Келли был постоянный предшественник обратного распространения ошибки [10] уже в 1960 году в контексте теории управления . [1]
Обратное распространение ошибки вычисляет градиент функции потерь относительно весов сети для одного примера ввода-вывода и делает это эффективно , вычисляя градиент по одному слою за раз, делая итерацию назад от последнего слоя, чтобы избежать избыточных вычислений промежуточных значений. термины в цепном правиле; это может быть получено посредством динамического программирования . [10] [11] [12] Градиентный спуск или такие варианты, как стохастический градиентный спуск . [13] обычно используются.
Строго говоря, термин обратное распространение ошибки относится только к алгоритму вычисления градиента, а не к тому, как градиент используется; но этот термин часто используется в широком смысле для обозначения всего алгоритма обучения, включая то, как используется градиент, например, стохастический градиентный спуск. [14] В 1986 году Дэвид Э. Румельхарт и др. опубликовал экспериментальный анализ метода. [15] Это способствовало популяризации обратного распространения ошибки и помогло начать активный период исследований многослойных перцептронов .
Обзор
[ редактировать ]Обратное распространение ошибки вычисляет градиент в весовом пространстве нейронной сети прямого распространения относительно функции потерь . Обозначим:
- : ввод (вектор признаков)
- : целевой результат
- Для классификации выходными данными будет вектор вероятностей классов (например, , а целевой результат — это конкретный класс, закодированный переменной one-hot / dummy (например, ).
- : функция потерь или «функция стоимости» [а]
- Для классификации это обычно перекрестная энтропия (XC, log loss ), а для регрессии — квадратичная потеря ошибки (SEL).
- : количество слоев
- : веса между слоями и , где это вес между -й узел в слое и -й узел в слое [б]
- : функции активации на уровне
- Для классификации последним слоем обычно является логистическая функция для бинарной классификации и softmax (softargmax) для многоклассовой классификации, тогда как для скрытых слоев это традиционно была сигмовидная функция (логистическая функция или другие) на каждом узле (координате), но сегодня более разнообразен, обычно используется выпрямитель ( рампа , ReLU ).
- : активация -й узел в слое .














При выводе обратного распространения ошибки используются другие промежуточные величины, вводя их по мере необходимости ниже. Члены смещения не рассматриваются специально, поскольку они соответствуют весу с фиксированным входным значением, равным 1. Для обратного распространения ошибки конкретная функция потерь и функции активации не имеют значения, если они и их производные могут быть эффективно оценены. Традиционные функции активации включают сигмовидную мышцу, tanh и ReLU . взмахнуть [16] Миш , [17] с тех пор были предложены и другие функции активации.
Общая сеть представляет собой комбинацию композиции функций и умножения матриц :

Для обучающего набора будет набор пар ввода-вывода, . Для каждой пары ввода-вывода в обучающем наборе потеря модели в этой паре — это стоимость разницы между прогнозируемыми выходными данными и целевой результат :





Обратите внимание на различие: во время оценки модели веса фиксируются, в то время как входные данные изменяются (а целевой выход может быть неизвестен), а сеть заканчивается выходным слоем (он не включает функцию потерь). Во время обучения модели пара ввода-вывода фиксируется, а веса меняются, и сеть заканчивается функцией потерь.
Обратное распространение ошибки вычисляет градиент для фиксированной пары ввода-вывода. , где веса может варьироваться. Каждый отдельный компонент градиента, может быть вычислено по цепному правилу; но делать это отдельно для каждого веса неэффективно. Обратное распространение ошибки эффективно вычисляет градиент, избегая дублирования вычислений и не вычисляя ненужные промежуточные значения, вычисляя градиент каждого слоя – в частности, градиент взвешенного входного сигнала каждого слоя, обозначаемый – сзади наперед.


Неофициально, ключевым моментом является то, что, поскольку единственный способ влияет на потери через свое влияние на следующий слой, и это происходит линейно , — единственные данные, которые вам нужны для вычисления градиентов весов на слое. , а затем можно вычислить предыдущий слой и повторяется рекурсивно. Это позволяет избежать неэффективности двумя способами. Во-первых, это позволяет избежать дублирования, поскольку при вычислении градиента на слое , нет необходимости пересчитывать все производные на более поздних слоях каждый раз. Во-вторых, он позволяет избежать ненужных промежуточных вычислений, поскольку на каждом этапе он напрямую вычисляет градиент весов относительно конечного результата (потери), а не без необходимости вычисляет производные значений скрытых слоев с учетом изменений весов. .




Обратное распространение ошибки может быть выражено для простых сетей прямого распространения в терминах матричного умножения или, в более общем смысле, в терминах присоединенного графа .
Умножение матрицы
[ редактировать ]В базовом случае сети с прямой связью, где узлы каждого уровня соединены только с узлами следующего слоя (без пропуска каких-либо слоев), и существует функция потерь, которая вычисляет скалярные потери для конечного результата, обратное распространение ошибки может быть понимается просто путем матричного умножения. [с] По сути, обратное распространение ошибки оценивает выражение производной функции стоимости как произведение производных между каждым слоем справа налево – «назад» – при этом градиент весов между каждым слоем представляет собой простую модификацию частичных произведений («обратное распространение ошибки»). ошибка обратного распространения»).
Учитывая пару ввода-вывода , потери составляют:


Чтобы вычислить это, нужно начать с ввода и работает вперед; обозначим взвешенный вход каждого скрытого слоя как и вывод скрытого слоя как активация . Для обратного распространения ошибки активация а также производные (оценено в ) должен быть кэширован для использования во время обратного прохода.



Производная потерь по входящим ресурсам определяется цепным правилом; обратите внимание, что каждый термин представляет собой полную производную , оцениваемую по значению сети (в каждом узле) на входе. :

где является диагональной матрицей.

Этими терминами являются: производная функции потерь; [д] производные функций активации; [и] и матрицы весов: [ф]

Градиент является транспонированием производной вывода через вход, поэтому матрицы транспонируются и порядок умножения меняется на обратный, но записи остаются теми же:


Тогда обратное распространение ошибки состоит, по существу, из вычисления этого выражения справа налево (что эквивалентно умножению предыдущего выражения для производной слева направо), вычисления градиента на каждом слое на пути; есть дополнительный шаг, потому что градиент весов — это не просто подвыражение: есть дополнительное умножение.
Вводя вспомогательную величину для частичных произведений (умножающихся справа налево), что интерпретируется как «ошибка на уровне " и определяется как градиент входных значений на уровне :

Обратите внимание, что - вектор длиной, равной количеству узлов на уровне ; каждый компонент интерпретируется как «стоимость, относящаяся к (стоимости) этого узла».
Градиент весов в слое тогда:

Фактор потому что веса между уровнями и уровень влияния пропорционально входам (активациям): входы фиксированы, веса меняются.

The можно легко вычислить рекурсивно, идя справа налево, как:

Таким образом, градиенты весов можно вычислить с помощью нескольких умножений матриц для каждого уровня; это обратное распространение ошибки.
По сравнению с простыми вычислениями вперед (с использованием для иллюстрации):

Есть два ключевых отличия от обратного распространения ошибки:
- Вычисление с точки зрения позволяет избежать очевидного дублирования умножения слоев и за его пределами.
- Умножение, начиная с – распространение ошибки назад – означает, что каждый шаг просто умножает вектор ( ) по матрицам весов и производные активаций . Напротив, умножение вперед, начиная с изменений на более раннем уровне, означает, что каждое умножение умножает матрицу на матрицу . Это намного дороже и соответствует отслеживанию всех возможных путей изменения на одном уровне. вперед к изменениям в слое (для умножения к , с дополнительными умножениями для производных активаций), который без необходимости вычисляет промежуточные величины того, как изменения веса влияют на значения скрытых узлов.






Сопряженный граф
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( ноябрь 2019 г. ) |
Для более общих графов и других расширенных вариантов обратное распространение ошибки можно понимать как автоматическое дифференцирование , где обратное распространение ошибки является частным случаем обратного накопления (или «обратного режима»). [8]
Интуиция
[ редактировать ]Мотивация
[ редактировать ]Цель любого алгоритма обучения с учителем — найти функцию, которая наилучшим образом сопоставляет набор входных данных с их правильными выходными данными. Мотивацией обратного распространения ошибки является обучение многоуровневой нейронной сети таким образом, чтобы она могла изучить соответствующие внутренние представления, позволяющие ей изучать любое произвольное сопоставление ввода и вывода. [18]
Обучение как задача оптимизации
[ редактировать ]Чтобы понять математический вывод алгоритма обратного распространения ошибки, необходимо сначала получить некоторое представление о взаимосвязи между фактическим выходным сигналом нейрона и правильным выходным сигналом для конкретного обучающего примера. Рассмотрим простую нейронную сеть с двумя входными блоками, одним выходным блоком и без скрытых блоков, в которой каждый нейрон использует линейный выход (в отличие от большинства работ по нейронным сетям, в которых отображение входных данных на выходные данные является нелинейным). [г] это взвешенная сумма его входных данных.

Изначально, перед тренировкой, веса будут установлены случайным образом. Затем нейрон обучается на обучающих примерах , которые в данном случае состоят из набора кортежей. где и — это входные данные для сети, а t — правильный результат (выход, который сеть должна выдавать с учетом этих входных данных после обучения). Исходная сеть, заданная и , вычислит выходной сигнал y , который, вероятно, отличается от t (с учетом случайных весов). Функция потерь используется для измерения расхождения между целевым выходом t и вычисленным выходом y . Для задач регрессионного анализа квадрат ошибки можно использовать как функцию потерь, для классификации категориальную перекрестную энтропию можно использовать .




В качестве примера рассмотрим задачу регрессии, использующую квадратичную ошибку в качестве потери:

где E – несоответствие или ошибка.
Рассмотрим сеть на одном обучающем примере: . Таким образом, вход и равны 1 и 1 соответственно, а правильный выходной сигнал t равен 0. Теперь, если построить график зависимости между выходным сигналом сети y на горизонтальной оси и ошибкой E на вертикальной оси, результатом будет парабола. Минимум который параболы , соответствует выходному сигналу y ошибку E. минимизирует Для одного обучающего случая минимум также касается горизонтальной оси, что означает, что ошибка будет равна нулю, и сеть может выдать результат y , который точно соответствует целевому выходу t . Следовательно, проблему сопоставления входных данных и выходных данных можно свести к задаче оптимизации поиска функции, которая будет давать минимальную ошибку.


Однако выходной сигнал нейрона зависит от взвешенной суммы всех его входных данных:

где и — это веса соединения между входными блоками и выходными блоками. Следовательно, ошибка также зависит от весов, поступающих в нейрон, что в конечном итоге и необходимо изменить в сети, чтобы обеспечить возможность обучения.


В этом примере после введения обучающих данных , функция потерь становится

Тогда функция потерь имеет форму параболического цилиндра с основанием, направленным вдоль . Поскольку все наборы весов, удовлетворяющие минимизировать функцию потерь, в этом случае для сходимости к единственному решению требуются дополнительные ограничения. Дополнительные ограничения могут быть созданы либо путем установки определенных условий для весов, либо путем введения дополнительных обучающих данных.


Одним из часто используемых алгоритмов для поиска набора весов, который минимизирует ошибку, является градиентный спуск . Путем обратного распространения ошибки вычисляется направление наибольшего крутого спуска функции потерь в зависимости от текущих синаптических весов. Затем веса можно изменить вдоль направления наибольшего спуска, и ошибка будет эффективно минимизирована.
Вывод
[ редактировать ]Метод градиентного спуска предполагает вычисление производной функции потерь по весам сети. Обычно это делается с помощью обратного распространения ошибки. Предполагая один выходной нейрон, [час] функция квадрата ошибки

где
- это потери на выходе и целевое значение ,
- — целевой результат обучающей выборки, а
- — это фактический выход выходного нейрона.

Для каждого нейрона , его выход определяется как


где функция активации дифференцируема нелинейна и . по области активации (ReLU не дифференцируема в одной точке) Исторически используемой функцией активации является логистическая функция :


который имеет удобную производную:

Вход для нейрона — это взвешенная сумма выходных сигналов предыдущих нейронов. Если нейрон находится в первом слое после входного, входного слоя — это просто входные данные в сеть. Число входных единиц нейрона равно . Переменная обозначает вес между нейроном предыдущего слоя и нейрона текущего слоя.





Нахождение производной ошибки
[ редактировать ]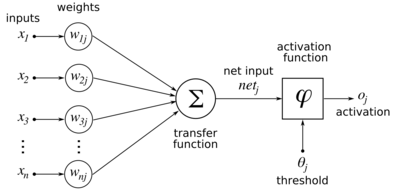
Вычисление частной производной ошибки по весу делается с использованием цепного правила дважды:

| ( Уравнение 1 ) |

В последнем множителе правой части вышеизложенного только одно слагаемое в сумме зависит от , так что
| ( уравнение 2 ) |

Если нейрон находится в первом слое после входного слоя, это просто .


Производная выхода нейрона по отношению к его входу является просто частной производной функции активации:
| ( уравнение 3 ) |

что для логистической функции активации

Именно по этой причине обратное распространение ошибки требует, чтобы функция активации была дифференцируемой . (Тем не менее, функция активации ReLU , недифференцируемая в 0, стала довольно популярной, например в AlexNet )
Первый фактор позволяет легко оценить, находится ли нейрон в выходном слое, потому что тогда и

| ( уравнение 4 ) |

Если половина квадратичной ошибки используется в качестве функции потерь, мы можем переписать ее как

Однако, если находится в произвольном внутреннем слое сети, находя производную относительно менее очевидно.
Учитывая как функция, входами которой являются все нейроны получение входных данных от нейрона ,


и взяв полную производную по , получается рекурсивное выражение для производной:
| ( уравнение 5 ) |

Поэтому производная по можно вычислить, если все производные по выходам следующего слоя – тех, которые ближе к выходному нейрону – известны. [Обратите внимание: если какой-либо из нейронов в наборе не были связаны с нейроном , они были бы независимы от и соответствующая частная производная при суммировании обратится в нуль.]

Подставив уравнение 2 , уравнение. 3 Уравнение 4 и уравнение. 5 в уравнении 1 получаем:


с

если – логистическая функция, а ошибка – квадратичная ошибка:

Чтобы обновить вес используя градиентный спуск, необходимо выбрать скорость обучения, . Изменение веса должно отражать влияние на увеличения или уменьшения . Если , увеличение увеличивается ; наоборот, если , увеличение уменьшается . Новый добавляется к старому весу и произведению скорости обучения и градиента, умноженному на гарантирует, что изменяется таким образом, что всегда уменьшается . Другими словами, в уравнении, приведенном непосредственно ниже, всегда меняется таким образом, что уменьшается:







Градиентный спуск второго порядка
[ редактировать ]Используя матрицу Гессе производных второго порядка функции ошибок, алгоритм Левенберга-Марквардта часто сходится быстрее, чем градиентный спуск первого порядка, особенно когда топология функции ошибок сложна. [19] [20] Он также может находить решения с меньшим количеством узлов, для которых другие методы могут не сходиться. [20] Гессиан можно аппроксимировать информационной матрицей Фишера . [21]
Функция потерь
[ редактировать ]Функция потерь — это функция, которая отображает значения одной или нескольких переменных в действительное число, интуитивно представляющее некоторую «стоимость», связанную с этими значениями. При обратном распространении функция потерь вычисляет разницу между выходными данными сети и ожидаемыми выходными данными после распространения обучающего примера по сети.
Предположения
[ редактировать ]Математическое выражение функции потерь должно удовлетворять двум условиям, чтобы его можно было использовать в обратном распространении ошибки. [22] Во-первых, его можно записать как среднее значение. над функциями ошибок , для индивидуальные примеры обучения, . Причина этого предположения заключается в том, что алгоритм обратного распространения ошибки вычисляет градиент функции ошибок для одного обучающего примера, который необходимо обобщить до общей функции ошибок. Второе предположение заключается в том, что его можно записать как функцию выходных данных нейронной сети.




Пример функции потерь
[ редактировать ]Позволять быть векторами в .


Выберите функцию ошибки измерение разницы между двумя выходными данными. Стандартный выбор — квадрат евклидова расстояния между векторами и : Функция ошибки закончилась Затем обучающие примеры можно записать как среднее значение потерь по отдельным примерам:




Ограничения
[ редактировать ]
- Градиентный спуск с обратным распространением ошибки не гарантирует нахождение глобального минимума функции ошибок, а только локального минимума; кроме того, у него есть проблемы с преодолением плато в ландшафте функций ошибок. Эта проблема, вызванная невыпуклостью функций ошибок в нейронных сетях, долгое время считалась серьезным недостатком, но Янн Лекун и др. утверждают, что во многих практических задачах это не так. [23]
- Обучение обратному распространению ошибки не требует нормализации входных векторов; однако нормализация может улучшить производительность. [24]
- Обратное распространение ошибки требует, чтобы производные функций активации были известны во время проектирования сети.
История
[ редактировать ]Прекурсоры
[ редактировать ]Обратное распространение ошибки выводилось неоднократно, поскольку, по сути, оно представляет собой эффективное применение правила цепочки (впервые записанного Готфридом Вильгельмом Лейбницем в 1676 году). [25] [26] ) в нейронные сети.
Терминология «коррекция ошибок с обратным распространением ошибки» была введена в 1962 году Фрэнком Розенблаттом , но он не знал, как это реализовать. [27] В любом случае он изучал только нейроны, выходные данные которых были дискретными уровнями, имеющими только нулевые производные, что делало обратное распространение ошибки невозможным.
Предшественники обратного распространения ошибки появились в теории оптимального управления с 1950-х годов. Янн Лекун и др. отдают должное работе Понтрягина и других 1950-х годов по теории оптимального управления, особенно методу сопряженного состояния , как версии обратного распространения ошибки с непрерывным временем. [28] Хехт-Нильсен [29] считает алгоритм Роббинса-Монро (1951) и » Артура Брайсона и Ю-Чи Хо ( «Прикладное оптимальное управление 1969) предвестниками обратного распространения ошибки. Другими предшественниками были Генри Дж. Келли (1960 г.), [10] и Артур Э. Брайсон (1961). [11] В 1962 году Стюарт Дрейфус опубликовал более простой вывод, основанный только на цепном правиле . [30] [31] [32] В 1973 году он адаптировал параметры контроллеров пропорционально градиентам ошибок. [33] В отличие от современного метода обратного распространения ошибки, эти предшественники использовали стандартные вычисления матрицы Якоби от одного этапа к предыдущему, не обращаясь ни к прямым связям между несколькими этапами, ни к потенциальному дополнительному повышению эффективности из-за разреженности сети. [1]
Алгоритм обучения ADALINE (1960) представлял собой градиентный спуск с квадратичной потерей ошибок для одного слоя. Первый многослойный перцептрон (MLP) с более чем одним слоем, обученный методом стохастического градиентного спуска. [13] был опубликован в 1967 году Шуничи Амари . [34] [1] MLP имел пять слоев, два из которых можно было изучить, и он научился классифицировать закономерности, которые не являются линейно разделимыми. [1]
Современное обратное распространение ошибки
[ редактировать ]Современное обратное распространение ошибки было впервые опубликовано Сеппо Линнаинмаа как «обратный режим автоматического дифференцирования » (1970). [2] для дискретных связных сетей вложенных дифференцируемых функций. [3] [4]
В 1982 году Пол Вербос применил обратное распространение ошибки к MLP способом, который стал стандартным. [35] [36] В интервью Вербос рассказал, как он разработал метод обратного распространения ошибки. В 1971 году, во время своей докторской диссертации, он разработал метод обратного распространения ошибки, чтобы математизировать . «поток психической энергии» Фрейда Он неоднократно сталкивался с трудностями при публикации работы, и ему это удалось только в 1981 году. [37]
Примерно в 1982 году [37] : 376 Дэвид Э. Румельхарт независимо разработал [38] : 252 обратное распространение ошибки и научил этому алгоритму других членов своего исследовательского круга. Он не цитировал предыдущие работы, поскольку не знал о них. Сначала он опубликовал алгоритм в статье 1985 года, затем в статье Nature 1986 года с экспериментальным анализом метода. [15] Эти статьи стали высоко цитируемыми, способствовали популяризации обратного распространения ошибки и совпали с возрождением исследовательского интереса к нейронным сетям в 1980-х годах. [18] [39] [40]
В 1985 году метод также описал Дэвид Паркер. [41] [42] Янн ЛеКун предложил альтернативную форму обратного распространения ошибки для нейронных сетей в своей докторской диссертации в 1987 году. [43]
Градиентный спуск потребовал значительного времени, чтобы добиться признания. Некоторые ранние возражения заключались в следующем: не было никаких гарантий того, что градиентный спуск может достичь глобального минимума, только локального минимума; Физиологам было «известно», что нейроны производят дискретные сигналы (0/1), а не непрерывные, а для дискретных сигналов не существует градиента. Смотрите интервью с Джеффри Хинтоном . [37]
Ранние успехи
[ редактировать ]Этому способствовало несколько приложений по обучению нейронных сетей посредством обратного распространения ошибки, которые иногда приобретали популярность за пределами исследовательских кругов.
В 1987 году NETtalk научился преобразовывать английский текст в произношение. Сейновский попробовал обучить его как с помощью обратного распространения ошибки, так и с помощью машины Больцмана, но обнаружил, что обратное распространение ошибки происходит значительно быстрее, поэтому он использовал его для финального выступления NETtalk. [37] : 324 Программа NETtalk имела популярный успех, появившись на Today шоу . [44]
В 1989 году Дин А. Померло опубликовал ALVINN — нейронную сеть, обученную автономному управлению с использованием обратного распространения ошибки. [45]
LeNet . был опубликован в 1989 году для распознавания рукописных почтовых индексов
В 1992 году TD-Gammon достигла высшего уровня игры в нарды. Это был агент обучения с подкреплением с двухслойной нейронной сетью, обученной методом обратного распространения ошибки. [46]
В 1993 году Эрик Ван выиграл международный конкурс по распознаванию образов с помощью обратного распространения ошибки. [6] [47]
После обратного распространения ошибки
[ редактировать ]В 2000-е годы он вышел из моды. [ нужна ссылка ] , но вернулся в 2010-х годах, воспользовавшись дешевыми и мощными вычислительными системами на базе графических процессоров . Это особенно заметно в распознавании речи , машинном зрении , обработке естественного языка и исследованиях изучения структуры языка (в которых оно использовалось для объяснения множества явлений, связанных с первым [48] и изучение второго языка. [49] ) [50]
Было предложено использовать обратное распространение ошибок для объяснения компонентов потенциала, связанных с событиями (ERP) человеческого мозга, таких как N400 и P600 . [51]
В 2023 году алгоритм обратного распространения ошибки был реализован на фотонном процессоре командой Стэнфордского университета . [52]
См. также
[ редактировать ]- Искусственная нейронная сеть
- Нейронная цепь
- Катастрофическое вмешательство
- Ансамблевое обучение
- АдаБуст
- Переобучение
- Нейронное обратное распространение ошибки
- Обратное распространение ошибки во времени
Примечания
[ редактировать ]- ^ Использование чтобы функция потерь позволяла используется для количества слоев
- ^ Это соответствует Нильсену (2015) и означает (слева) умножение на матрицу. соответствует преобразованию выходных значений слоя для ввода значений слоя : столбцы соответствуют входным координатам, строки соответствуют выходным координатам.
- ^ Этот раздел во многом следует за Nielsen (2015) и обобщает его .
- ^ Производная функции потерь — ковектор , поскольку функция потерь — скалярная функция нескольких переменных.
- ^ Функция активации применяется к каждому узлу отдельно, поэтому производная — это просто диагональная матрица производной на каждом узле. Это часто представляют как произведение Адамара с вектором производных, обозначаемым , который математически идентичен, но лучше соответствует внутреннему представлению производных в виде вектора, а не диагональной матрицы.
- ^ Поскольку умножение матриц линейное, производная от умножения на матрицу - это просто матрица: .
- ^ Можно заметить, что многослойные нейронные сети используют нелинейные функции активации, поэтому пример с линейными нейронами кажется неясным. Однако, хотя поверхность ошибок многослойных сетей гораздо сложнее, локально их можно аппроксимировать параболоидом. Поэтому для простоты и облегчения понимания используются линейные нейроны.
- ^ Выходных нейронов может быть несколько, и в этом случае ошибка равна квадрату нормы вектора разности.


Ссылки
[ редактировать ]- ^ Jump up to: а б с д и ж Шмидхубер, Юрген (2022). «Аннотированная история современного искусственного интеллекта и глубокого обучения». arXiv : 2212.11279 [ cs.NE ].
- ^ Jump up to: а б Линнаинмаа, Сеппо (1970). Представление совокупной ошибки округления алгоритма в виде разложения Тейлора локальных ошибок округления (Мастерс) (на финском языке). Университет Хельсинки. стр. 6–7.
- ^ Jump up to: а б Линнаинмаа, Сеппо (1976). «Разложение Тейлора накопленной ошибки округления». БИТ Численная математика . 16 (2): 146–160. дои : 10.1007/bf01931367 . S2CID 122357351 .
- ^ Jump up to: а б Гриванк, Андреас (2012). «Кто изобрел обратный способ дифференциации?». Истории оптимизации . Documenta Matematica, Дополнительный том ISMP. стр. 389–400. S2CID 15568746 .
- ^ Гриванк, Андреас; Вальтер, Андреа (2008). Оценка производных: принципы и методы алгоритмического дифференцирования, второе издание . СИАМ. ISBN 978-0-89871-776-1 .
- ^ Jump up to: а б Шмидхубер, Юрген (2015). «Глубокое обучение в нейронных сетях: обзор». Нейронные сети . 61 : 85–117. arXiv : 1404.7828 . дои : 10.1016/j.neunet.2014.09.003 . ПМИД 25462637 . S2CID 11715509 .
- ^ Шмидхубер, Юрген (2015). «Глубокое обучение» . Схоларпедия . 10 (11): 32832. Бибкод : 2015SchpJ..1032832S . doi : 10.4249/scholarpedia.32832 .
- ^ Jump up to: а б Гудфеллоу, Бенджио и Курвиль (2016 , стр. 217–218 ): «Описанный здесь алгоритм обратного распространения ошибки — это только один подход к автоматическому дифференцированию. Это частный случай более широкого класса методов, называемых накоплением в обратном режиме ».
- ^ Розенблатт, Франк (1962). Принципы нейродинамики: перцептроны и теория механизмов мозга Корнельская авиационная лаборатория. Номер отчета. Отчет VG-1196-G-8 (Корнельская авиационная лаборатория) . Спартанец. Стр. XIII Оглавление, стр. 292 «13.3 Процедуры исправления ошибок с обратным распространением ошибки», стр. 301 «рисунок 39 ЭКСПЕРИМЕНТЫ С ИСПРАВЛЕНИЕМ ОШИБОК С ОБРАТНЫМ РАСПРОСТРАНЕНИЕМ».
- ^ Jump up to: а б с Келли, Генри Дж. (1960). «Градиентная теория оптимальных траекторий полета». Журнал АРС . 30 (10): 947–954. дои : 10.2514/8.5282 .
- ^ Jump up to: а б Брайсон, Артур Э. (1962). «Градиентный метод оптимизации многоэтапных процессов распределения». Труды Гарвардского университета. Симпозиум по цифровым компьютерам и их приложениям, 3–6 апреля 1961 г. Кембридж: Издательство Гарвардского университета. OCLC 498866871 .
- ^ Гудфеллоу, Бенджио и Курвиль, 2016 , с. 214 : «Эту стратегию заполнения таблиц иногда называют динамическим программированием ».
- ^ Jump up to: а б Роббинс, Х .; Монро, С. (1951). «Метод стохастической аппроксимации» . Анналы математической статистики . 22 (3): 400. дои : 10.1214/aoms/1177729586 .
- ^ Гудфеллоу, Бенджио и Курвиль, 2016 , с. 200 : «Термин обратного распространения ошибки часто неправильно понимают как обозначающий весь алгоритм обучения многослойных нейронных сетей. Обратное распространение ошибки относится только к методу вычисления градиента, в то время как другие алгоритмы, такие как стохастический градиентный спуск, используются для выполнения обучения с использованием этого метода. градиент».
- ^ Jump up to: а б Румельхарт; Хинтон; Уильямс (1986). «Изучение представлений с помощью ошибок обратного распространения» (PDF) . Природа . 323 (6088): 533–536. Бибкод : 1986Natur.323..533R . дои : 10.1038/323533a0 . S2CID 205001834 .
- ^ Рамачандран, Праджит; Зоф, Баррет; Ле, Куок В. (27 октября 2017 г.). «Поиск функций активации». arXiv : 1710.05941 [ cs.NE ].
- ^ Мисра, Диганта (23 августа 2019 г.). «Миш: саморегуляризованная немонотонная функция активации». arXiv : 1908.08681 [ cs.LG ].
- ^ Jump up to: а б Румельхарт, Дэвид Э .; Хинтон, Джеффри Э .; Уильямс, Рональд Дж. (1986a). «Изучение представлений с помощью ошибок обратного распространения». Природа . 323 (6088): 533–536. Бибкод : 1986Natur.323..533R . дои : 10.1038/323533a0 . S2CID 205001834 .
- ^ Тан, Хун Хуэй; Лим, король Хан (2019). «Обзор методов оптимизации второго порядка в искусственных нейронных сетях обратного распространения ошибки» . Серия конференций IOP: Материаловедение и инженерия . 495 (1): 012003. Бибкод : 2019MS&E..495a2003T . дои : 10.1088/1757-899X/495/1/012003 . S2CID 208124487 .
- ^ Jump up to: а б Вильямовский, Богдан; Ю, Хао (июнь 2010 г.). «Улучшенные вычисления для обучения Левенберга – Марквардта» (PDF) . Транзакции IEEE в нейронных сетях и системах обучения . 21 (6).
- ^ Мартенс, Джеймс (август 2020 г.). «Новые идеи и перспективы метода естественного градиента». Журнал исследований машинного обучения (21). arXiv : 1412.1193 .
- ^ Нильсен (2015) : «[Какие] предположения нам нужно сделать в отношении нашей функции стоимости… чтобы можно было применить обратное распространение ошибки? Первое предположение, которое нам нужно, это то, что функцию стоимости можно записать как среднее значение. . по функциям стоимости... для отдельных примеров обучения... Второе предположение, которое мы делаем относительно стоимости, заключается в том, что ее можно записать как функцию выходных данных нейронной сети..."
- ^ ЛеКун, Янн; Бенджио, Йошуа; Хинтон, Джеффри (2015). «Глубокое обучение» (PDF) . Природа . 521 (7553): 436–444. Бибкод : 2015Natur.521..436L . дои : 10.1038/nature14539 . ПМИД 26017442 . S2CID 3074096 .
- ^ Бакленд, Мэтт; Коллинз, Марк (2002). Техники искусственного интеллекта для программирования игр . Бостон: Премьер Пресс. ISBN 1-931841-08-Х .
- ^ Лейбниц, Готфрид Вильгельм Фрайгер фон (1920). Ранние математические рукописи Лейбница: перевод с латинских текстов, опубликованных Карлом Иммануэлем Герхардтом с критическими и историческими примечаниями (Лейбниц опубликовал цепное правило в мемуарах 1676 года) . Издательство «Открытый суд». ISBN 9780598818461 .
- ^ Родригес, Омар Эрнандес; Лопес Фернандес, Хорхе М. (2010). «Семиотическое размышление о дидактике правила цепочки» . Любитель математики . 7 (2): 321–332. дои : 10.54870/1551-3440.1191 . S2CID 29739148 . Проверено 4 августа 2019 г.
- ^ Розенблатт, Франк (1962). Принципы нейродинамики . Спартан, Нью-Йорк. стр. 287–298.
- ^ ЛеКун, Янн и др. «Теоретическая основа обратного распространения ошибки». Материалы летней школы коннекционистских моделей 1988 года . Том. 1. 1988.
- ^ Хехт-Нильсен, Роберт (1990). Нейрокомпьютинг . Интернет-архив. Ридинг, Массачусетс: Паб Addison-Wesley. Ко, стр. 124–125. ISBN 978-0-201-09355-1 .
- ^ Дрейфус, Стюарт (1962). «Численное решение вариационных задач» . Журнал математического анализа и приложений . 5 (1): 30–45. дои : 10.1016/0022-247x(62)90004-5 .
- ^ Дрейфус, Стюарт Э. (1990). «Искусственные нейронные сети, обратное распространение ошибки и градиентная процедура Келли-Брайсона». Журнал руководства, контроля и динамики . 13 (5): 926–928. Бибкод : 1990JGCD...13..926D . дои : 10.2514/3.25422 .
- ^ Мизутани, Эйдзи; Дрейфус, Стюарт; Нисио, Кеничи (июль 2000 г.). «О выводе обратного распространения ошибки MLP из формулы градиента оптимального управления Келли-Брайсона и ее применении» (PDF) . Материалы Международной совместной конференции IEEE по нейронным сетям.
- ^ Дрейфус, Стюарт (1973). «Вычислительное решение задач оптимального управления с запаздыванием». Транзакции IEEE при автоматическом управлении . 18 (4): 383–385. дои : 10.1109/tac.1973.1100330 .
- ^ Амари, Шуничи (1967). «Теория адаптивного классификатора шаблонов». IEEE-транзакции . ЕС (16): 279–307.
- ^ Вербос, Пол (1982). «Применение достижений нелинейного анализа чувствительности» (PDF) . Системное моделирование и оптимизация . Спрингер. стр. 762–770. Архивировано (PDF) из оригинала 14 апреля 2016 года . Проверено 2 июля 2017 г.
- ^ Вербос, Пол Дж. (1994). Корни обратного распространения ошибки: от упорядоченных производных к нейронным сетям и политическому прогнозированию . Нью-Йорк: Джон Уайли и сыновья. ISBN 0-471-59897-6 .
- ^ Jump up to: а б с д Андерсон, Джеймс А.; Розенфельд, Эдвард, ред. (2000). Говорящие сети: устная история нейронных сетей . Массачусетский технологический институт Пресс. дои : 10.7551/mitpress/6626.003.0016 . ISBN 978-0-262-26715-1 .
- ^ Олазаран Родригес, Хосе Мигель. Историческая социология исследований нейронных сетей . Кандидатская диссертация. Эдинбургский университет, 1991.
- ^ Румельхарт, Дэвид Э .; Хинтон, Джеффри Э .; Уильямс, Рональд Дж. (1986b). «8. Изучение внутренних представлений путем распространения ошибок» . В Румельхарте, Дэвид Э .; Макклелланд, Джеймс Л. (ред.). Параллельная распределенная обработка: исследования микроструктуры познания . Том. 1: Фундаменты. Кембридж: MIT Press. ISBN 0-262-18120-7 .
- ^ Алпайдин, Этем (2010). Введение в машинное обучение . МТИ Пресс. ISBN 978-0-262-01243-0 .
- ^ Паркер, Д.Б. (1985). Изучение логики: отливка коры человеческого мозга в кремний. Центр вычислительных исследований в области экономики и управления (Отчет). Кембридж, Массачусетский технологический институт. Технический отчет ТР-47.
- ^ Герц, Джон (1991). Введение в теорию нейронных вычислений . Крог, Андерс., Палмер, Ричард Г. Редвуд-Сити, Калифорния: Аддисон-Уэсли. п. 8. ISBN 0-201-50395-6 . ОСЛК 21522159 .
- ^ Ле Кун, Янн (1987). Коннекционистские модели обучения (Государственная докторская диссертация). Париж, Франция: Университет Пьера и Марии Кюри.
- ^ Сейновски, Терренс Дж. (2018). Революция глубокого обучения . Кембридж, Массачусетс, Лондон, Англия: MIT Press. ISBN 978-0-262-03803-4 .
- ^ Померло, Дин А. (1988). «ЭЛВИНН: автономное наземное транспортное средство в нейронной сети» . Достижения в области нейронных систем обработки информации . 1 . Морган-Кауфманн.
- ^ Саттон, Ричард С.; Барто, Эндрю Г. (2018). «11.1 ТД-Окорок» . Обучение с подкреплением: Введение (2-е изд.). Кембридж, Массачусетс: MIT Press.
- ^ Ван, Эрик А. (1994). «Прогнозирование временных рядов с использованием коннекционистской сети с внутренними линиями задержки». В Вейгенде, Андреас С .; Гершенфельд, Нил А. (ред.). Прогнозирование временных рядов: прогнозирование будущего и понимание прошлого . Материалы семинара перспективных исследований НАТО по сравнительному анализу временных рядов. Том. 15. Чтение: Аддисон-Уэсли. стр. 195–217. ISBN 0-201-62601-2 . S2CID 12652643 .
- ^ Чанг, Франклин; Делл, Гэри С.; Бок, Кэтрин (2006). «Стать синтаксическим». Психологический обзор . 113 (2): 234–272. дои : 10.1037/0033-295x.113.2.234 . ПМИД 16637761 .
- ^ Янчаускас, Мариус; Чанг, Франклин (2018). «Вклад и возрастные различия в изучении второго языка: отчет коннекциониста» . Когнитивная наука . 42 (Приложение 2): 519–554. дои : 10.1111/cogs.12519 . ПМК 6001481 . ПМИД 28744901 .
- ^ «Расшифровка возможностей обратного распространения ошибки: глубокое погружение в передовые методы нейронных сетей» . janbasktraining.com . 30 января 2024 г.
- ^ Фитц, Хартмут; Чанг, Франклин (2019). «Языковые ERP отражают обучение посредством распространения ошибок прогнозирования». Когнитивная психология . 111 : 15–52. дои : 10.1016/j.cogpsych.2019.03.002 . hdl : 21.11116/0000-0003-474D-8 . ПМИД 30921626 . S2CID 85501792 .
- ^ «Фотонные чипы снижают энергетический аппетит обучения искусственного интеллекта — IEEE Spectrum» . ИИЭЭ . Проверено 25 мая 2023 г.
Дальнейшее чтение
[ редактировать ]- Гудфеллоу, Ян ; Бенджио, Йошуа ; Курвиль, Аарон (2016). «6.5 Обратное распространение ошибки и другие алгоритмы дифференцирования» . Глубокое обучение . МТИ Пресс. стр. 200–220. ISBN 9780262035613 .
- Нильсен, Майкл А. (2015). «Как работает алгоритм обратного распространения ошибки» . Нейронные сети и глубокое обучение . Определение Пресс.
- Маккаффри, Джеймс (октябрь 2012 г.). «Обратное распространение ошибки нейронной сети для программистов» . Журнал MSDN .
- Рохас, Рауль (1996). «Алгоритм обратного распространения ошибки» (PDF) . Нейронные сети: систематическое введение . Берлин: Шпрингер. ISBN 3-540-60505-3 .
Внешние ссылки
[ редактировать ]- Учебное пособие по нейронной сети обратного распространения ошибки в Викиверситете
- Бернацкий, Мариуш; Влодарчик, Пшемыслав (2004). «Принципы обучения многослойной нейронной сети с использованием обратного распространения ошибки» .
- Карпаты, Андрей (2016). «Лекция 4: Обратное распространение ошибки, нейронные сети 1» . CS231n . Стэнфордский университет. Архивировано из оригинала 12 декабря 2021 г. – на YouTube .
- «Что на самом деле делает обратное распространение ошибки?» . 3Синий1Коричневый . 3 ноября 2017 г. Архивировано из оригинала 12 декабря 2021 г. – на YouTube .
- Путта, Судип Раджа (2022). «Еще один вывод обратного распространения ошибки в матричной форме» .
Дифференцируемые вычисления |
|---|
| Базы данных органов управления : Национальные |
|---|