Рекуррентная нейронная сеть
| Часть серии о |
| Машинное обучение и интеллектуальный анализ данных |
|---|
Рекуррентные нейронные сети (RNN) — это класс искусственных нейронных сетей для последовательной обработки данных. В отличие от нейронных сетей прямого распространения , которые обрабатывают данные за один проход, RNN обрабатывают данные за несколько временных шагов, что делает их хорошо адаптированными для моделирования и обработки текста, речи и временных рядов . [1]
Фундаментальным строительным блоком RNN является рекуррентная единица. Этот блок поддерживает скрытое состояние, по сути, форму памяти, которая обновляется на каждом временном шаге на основе текущего ввода и предыдущего скрытого состояния. Этот цикл обратной связи позволяет сети учиться на прошлых входных данных и включать эти знания в свою текущую обработку.
Ранние RNN страдали от проблемы исчезающего градиента, ограничивавшей их способность изучать долгосрочные зависимости. Проблема была решена благодаря изобретению сетей с длинной краткосрочной памятью (LSTM) в 1997 году, которые стали стандартной архитектурой для RNN.
Они применялись для таких задач, как несегментированное, связанное распознавание рукописного ввода , [2] распознавание речи , [3] [4] обработка естественного языка и нейронный машинный перевод . [5] [6]
История
[ редактировать ]До ЛСТМ
[ редактировать ]Одним из источников RNN была статистическая механика . Модель Изинга разработал Вильгельм Ленц. [7] и Эрнст Изинг [8] в 1920-х годах [9] как простая статистико-механическая модель магнитов, находящихся в равновесии. Глаубер в 1963 году изучил модель Изинга, развивающуюся во времени, как процесс достижения равновесия ( динамика Глаубера ), добавив компонент времени. [10] Шуничи Амари в 1972 году предложил изменить веса модели Изинга с помощью правила обучения Хебба как модели ассоциативной памяти, добавив компонент обучения. [11] Ее также называли сетью Хопфилда (1982). [12]
Еще одним источником возникновения RNN стала нейробиология. Слово «рекуррентный» используется для описания петлеобразных структур в анатомии. В 1933 году Лоренте де Но открыл «рекуррентные реципрокные связи» с помощью метода Гольджи и предположил, что возбуждающие петли объясняют определенные аспекты вестибулоокулярного рефлекса . [13] [14] В 1940-х годах несколько человек предположили существование обратной связи в мозге, что контрастировало с предыдущим пониманием нервной системы как структуры исключительно прямой связи. Хебб рассматривал «реверберирующий контур» как объяснение кратковременной памяти. [15] В статье Маккаллоха и Питтса (1943), в которой была предложена модель нейронов Маккаллоха-Питтса , рассматривались сети, содержащие циклы. На текущую деятельность таких сетей может влиять деятельность в неопределенно далеком прошлом. [16] Их обоих интересовали замкнутые циклы как возможные объяснения, например, эпилепсии и каузалгии . [17] [18] Рекуррентное торможение было предложено в 1946 году как механизм отрицательной обратной связи в двигательном контроле. [19] реверберационная схема См. [20] за обширный обзор моделей рекуррентных нейронных сетей в нейробиологии.
Двумя ранними влиятельными работами были сеть Джордана (1986) и сеть Элмана (1990), которые применили RNN для изучения когнитивной психологии . В 1993 году система сжатия нейронной истории решила задачу «очень глубокого обучения», которая требовала более 1000 последующих слоев в RNN, развернутой во времени. [21]
ЛСТМ
[ редактировать ]Сети с длинной краткосрочной памятью (LSTM) были изобретены Хохрайтером и Шмидхубером в 1997 году и установили рекорды точности во многих областях применения. [22] Он стал выбором по умолчанию для архитектуры RNN.
Примерно в 2007 году LSTM начал производить революцию в распознавании речи , превосходя традиционные модели в некоторых речевых приложениях. [23] [24] В 2009 году сеть LSTM, обученная коннекционистской временной классификации (CTC), стала первой сетью RNN, выигравшей конкурсы по распознаванию образов, когда она выиграла несколько соревнований по связанному распознаванию рукописного ввода . [25] [26] В 2014 году китайская компания Baidu использовала RNN, обученные CTC, для взлома набора данных распознавания речи 2S09 Switchboard Hub5'00. [27] эталонный тест без использования каких-либо традиционных методов обработки речи. [28]
LSTM также улучшил распознавание речи с большим словарным запасом. [3] [4] и текста в речь синтез [29] и использовался в Google Android . [25] [30] Сообщается, что в 2015 году производительность системы распознавания речи Google резко выросла на 49%. [ нужна ссылка ] через LSTM, обученный CTC. [31]
LSTM побил рекорды по улучшению машинного перевода , [32] Языковое моделирование [33] и многоязычная языковая обработка. [34] LSTM в сочетании со сверточными нейронными сетями (CNN) улучшили автоматическое создание подписей к изображениям . [35]
Конфигурации
[ редактировать ]Модель на основе RNN можно разделить на две части: конфигурацию и архитектуру. Несколько RNN могут быть объединены в поток данных, а сам поток данных является конфигурацией. Сама каждая RNN может иметь любую архитектуру, включая LSTM, GRU и т.д.
Стандартный
[ редактировать ]
RNN существуют во многих вариантах. Говоря абстрактно, RNN — это функция типа , где


- : входной вектор;
- : скрытый вектор;
- : выходной вектор;
- : параметры нейронной сети.




Проще говоря, это нейронная сеть, которая отображает входные данные. в вывод , со скрытым вектором играющий роль «памяти», частичной записи всех предыдущих пар ввода-вывода. На каждом этапе он преобразует входные данные в выходные и изменяет свою «память», чтобы лучше выполнять будущую обработку.
Иллюстрация справа может ввести многих в заблуждение, поскольку практические топологии нейронных сетей часто организованы в «слои», и на рисунке именно такой вид и создается. Однако то, что кажется слоями , на самом деле представляет собой различные этапы во времени, «развернутые» для создания видимости слоев .
Сложенный RNN
[ редактировать ]
Составная RNN, или глубокая RNN, состоит из нескольких RNN, расположенных друг над другом. Абстрактно это структурировано следующим образом.
- Слой 1 имеет скрытый вектор , параметры и карты .
- Слой 2 имеет скрытый вектор , параметры и карты .
- ...
- Слой имеет скрытый вектор , параметры и карты .










Каждый уровень работает как автономная RNN, а выходная последовательность каждого уровня используется в качестве входной последовательности для слоя выше. Высота RNN не ограничена.
Двунаправленный
[ редактировать ]
Двунаправленная RNN состоит из двух RNN, одна из которых обрабатывает входную последовательность в одном направлении, а другая — в противоположном. Абстрактно он структурирован следующим образом:
- Прямой RNN обрабатывает в одном направлении:
- Обратный RNN выполняет процессы в противоположном направлении:


Затем две выходные последовательности объединяются, чтобы получить общий результат: .

Двунаправленный RNN позволяет модели обрабатывать токен как в контексте того, что было до него, так и в контексте того, что было после него. Объединив несколько двунаправленных RNN вместе, модель может обрабатывать токен все более контекстуально. Модель ELMo (2018) [36] представляет собой сложенный двунаправленный LSTM , который принимает на входе уровень символов и создает встраивания на уровне слов.
Кодер-декодер
[ редактировать ]

Два RNN могут работать последовательно в конфигурации кодер-декодер. Кодер RNN преобразует входную последовательность в последовательность скрытых векторов, а декодер RNN преобразует последовательность скрытых векторов в выходную последовательность с дополнительным механизмом внимания . В период с 2014 по 2017 год это использовалось для создания современных нейронных машинных переводчиков. Это стало важным шагом на пути к разработке трансформеров . [37]
ПиксельRNN
[ редактировать ]RNN может обрабатывать данные более чем с одним измерением. PixelRNN обрабатывает двумерные данные во многих возможных направлениях. [38] Например, построчное направление обрабатывает сетка векторов в следующем порядке: Диагональный BiLSTM использует два LSTM для обработки одной и той же сетки. Его обрабатывают из верхнего левого угла в правый нижний, так что он обрабатывает в зависимости от его скрытого состояния и состояния ячейки сверху и слева: и . Другой обрабатывает его из правого верхнего угла в левый нижний.





Архитектуры
[ редактировать ]Полностью рецидивирующий
[ редактировать ]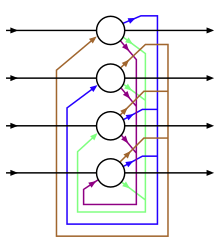
Полностью рекуррентные нейронные сети (FRNN) соединяют выходы всех нейронов со входами всех нейронов. Другими словами, это полностью подключенная сеть . Это наиболее общая топология нейронной сети, поскольку все остальные топологии можно представить, установив для некоторых весов соединений нулевое значение, чтобы имитировать отсутствие связей между этими нейронами.


Хопфилд
[ редактировать ]Сеть Хопфилда — это RNN, в которой все соединения между уровнями имеют одинаковый размер. Он требует стационарных входных данных и, следовательно, не является общей RNN, поскольку не обрабатывает последовательности шаблонов. Однако это гарантирует, что оно сойдется. Если соединения обучаются с использованием обучения Хебба , то сеть Хопфилда может работать как надежная память с адресацией по содержимому , устойчивая к изменению соединения.
Сети Элмана и сети Джордана
[ редактировать ]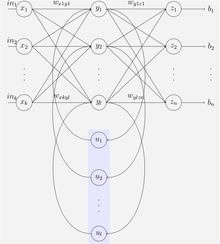
Сеть Элмана — это трехслойная сеть (расположенная горизонтально как x , y и z на рисунке) с добавлением набора контекстных единиц ( u на рисунке). Средний (скрытый) уровень связан с этими единицами контекста, имеющими вес, равный единице. [39] На каждом временном шаге входные данные передаются вперед и правило обучения применяется . Фиксированные обратные соединения сохраняют копию предыдущих значений скрытых модулей в модулях контекста (поскольку они распространяются по соединениям до применения правила обучения). Таким образом, сеть может поддерживать своего рода состояние, позволяющее ей выполнять такие задачи, как прогнозирование последовательности, которые выходят за рамки возможностей стандартного многослойного перцептрона .
Сети Джордана аналогичны сетям Элмана. Единицы контекста подаются из выходного слоя, а не из скрытого слоя. Единицы контекста в сети Иордании также называются уровнем состояния. У них есть постоянная связь с самим собой. [39]
Сети Элмана и Джордана также известны как «Простые рекуррентные сети» (SRN).


Переменные и функции
- : входной вектор
- : вектор скрытого слоя
- : выходной вектор
- , и : матрицы параметров и вектор
- и : Функции активации





Длинная кратковременная память
[ редактировать ]
Долговременная краткосрочная память (LSTM) является наиболее широко используемой архитектурой RNN. Он был разработан для решения проблемы исчезающего градиента. LSTM обычно дополняется повторяющимися воротами, называемыми «воротами забывания». [42] LSTM предотвращает исчезновение или взрывной рост ошибок обратного распространения ошибки. [43] Вместо этого ошибки могут течь назад через неограниченное количество виртуальных слоев, развернутых в пространстве. То есть LSTM может изучать задачи [25] которые требуют воспоминаний о событиях, произошедших на тысячи или даже миллионы дискретных временных шагов ранее. Топологии, подобные LSTM, могут быть разработаны для конкретных задач. [44] LSTM работает даже при длительных задержках между важными событиями и может обрабатывать сигналы, в которых смешаны низкочастотные и высокочастотные компоненты.
Многие приложения используют стеки LSTM RNN. [45] и обучать их с помощью коннекционистской временной классификации (CTC) [46] найти весовую матрицу RNN, которая максимизирует вероятность последовательностей меток в обучающем наборе, учитывая соответствующие входные последовательности. CTC достигает как согласованности, так и признания.
LSTM может научиться распознавать контекстно-зависимые языки в отличие от предыдущих моделей, основанных на скрытых моделях Маркова (HMM) и подобных концепциях. [47]
Закрытый рекуррентный блок
[ редактировать ]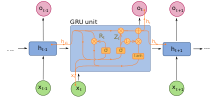
Закрытый рекуррентный блок (GRU), представленный в 2014 году, был разработан как упрощение LSTM. Они используются в полной форме и в нескольких более упрощенных вариантах. [48] [49] У них меньше параметров, чем у LSTM, так как у них нет выходного вентиля. [50]
Было обнаружено, что их эффективность при моделировании полифонической музыки и речевых сигналов аналогична эффективности долговременной кратковременной памяти. [51] Особой разницы в производительности между LSTM и GRU не наблюдается. [51] [52]
Двунаправленная ассоциативная память
[ редактировать ]Представлено Бартом Коско, [53] Сеть двунаправленной ассоциативной памяти (BAM) — это вариант сети Хопфилда, в которой ассоциативные данные хранятся в виде вектора. Двунаправленность возникает в результате передачи информации через матрицу и ее транспонирования . Обычно биполярное кодирование предпочтительнее двоичного кодирования ассоциативных пар. Недавно стохастические модели BAM, использующие степпинг Маркова, были оптимизированы для повышения стабильности сети и соответствия реальным приложениям. [54]
Сеть BAM имеет два уровня, каждый из которых может использоваться в качестве входных данных для вызова ассоциации и создания выходных данных на другом уровне. [55]
Состояние эха
[ редактировать ]Сети состояний эха (ESN) имеют редко связанный случайный скрытый слой. Веса выходных нейронов — единственная часть сети, которая может изменяться (обучаться). ESN хорошо воспроизводят определенные временные ряды . [56] Вариант импульсных нейронов известен как машина с жидким состоянием . [57]
Рекурсивный
[ редактировать ]Рекурсивная нейронная сеть [58] создается путем рекурсивного применения одного и того же набора весов к дифференцируемой графоподобной структуре путем обхода структуры в топологическом порядке . Такие сети обычно также обучаются с помощью обратного режима автоматического дифференцирования . [59] [60] Они могут обрабатывать распределенные представления структуры, такие как логические термины . Частным случаем рекурсивных нейронных сетей являются RNN, структура которых соответствует линейной цепочке. Рекурсивные нейронные сети применяются для обработки естественного языка . [61] Рекурсивная нейронная тензорная сеть использует тензорную функцию композиции для всех узлов дерева. [62]
Нейронные машины Тьюринга
[ редактировать ]Нейронные машины Тьюринга (НТМ) — это метод расширения рекуррентных нейронных сетей путем подключения их к ресурсам внешней памяти, с которыми они взаимодействуют. Комбинированная система аналогична машине Тьюринга или архитектуре фон Неймана, но является дифференцируемой сквозной , что позволяет эффективно обучать ее с помощью градиентного спуска . [63]
Дифференцируемые нейронные компьютеры (ДНК) являются расширением нейронных машин Тьюринга, позволяющим использовать нечеткие количества каждого адреса памяти и запись хронологии. [64]
Автоматы с выталкиванием нейронной сети (NNPDA) похожи на NTM, но ленты заменены аналоговыми стеками, которые дифференцируются и обучаются. В этом смысле они по сложности аналогичны распознавателям контекстно-свободных грамматик (CFG). [65]
Рекуррентные нейронные сети являются полными по Тьюрингу и могут запускать произвольные программы для обработки произвольных последовательностей входных данных. [66]
Другие архитектуры
[ редактировать ]Самостоятельно РНН (ИндРНН)
[ редактировать ]Независимая рекуррентная нейронная сеть (IndRNN) [67] решает проблемы исчезновения и взрыва градиента в традиционной полностью связной RNN. Каждый нейрон в одном слое получает только свое прошлое состояние в качестве контекстной информации (вместо полной связи со всеми другими нейронами в этом слое), и, таким образом, нейроны независимы от истории друг друга. Обратное распространение градиента можно регулировать, чтобы избежать исчезновения и взрыва градиента, чтобы сохранить долговременную или краткосрочную память. Информация о перекрестных нейронах исследуется на следующих уровнях. IndRNN можно надежно обучить с помощью ненасыщенных нелинейных функций, таких как ReLU. Глубокие сети можно обучать, используя пропущенные соединения.
Компрессор нейронной истории
[ редактировать ]Компрессор нейронной истории представляет собой неконтролируемый набор RNN. [68] На уровне ввода он учится прогнозировать следующий ввод на основе предыдущих входных данных. Только непредсказуемые входные данные некоторых RNN в иерархии становятся входными данными для RNN следующего более высокого уровня, который, следовательно, лишь изредка пересчитывает свое внутреннее состояние. Таким образом, каждая RNN более высокого уровня изучает сжатое представление информации в расположенной ниже RNN. Это делается для того, чтобы входную последовательность можно было точно восстановить по представлению на самом высоком уровне.
Система эффективно минимизирует длину описания или отрицательный логарифм вероятности данных. [69] Учитывая большую предсказуемость входящей последовательности данных, RNN самого высокого уровня может использовать контролируемое обучение, чтобы легко классифицировать даже глубокие последовательности с длинными интервалами между важными событиями.
Иерархию RNN можно разделить на две RNN: «сознательный» блокировщик (более высокий уровень) и «подсознательный» автоматизатор (нижний уровень). [68] Как только блокировщик научится предсказывать и сжимать входные данные, которые непредсказуемы для автоматизатора, автоматизатор может быть вынужден на следующем этапе обучения предсказывать или имитировать с помощью дополнительных блоков скрытые блоки более медленно меняющегося блокатора. Это позволяет автоматизатору легко запоминать подходящие, редко меняющиеся воспоминания на протяжении длительных интервалов времени. В свою очередь, это помогает автоматизатору сделать многие из некогда непредсказуемых входных данных предсказуемыми, так что блокировщик может сосредоточиться на оставшихся непредсказуемых событиях. [68]
Генеративная модель частично решила проблему исчезновения градиента [43] или автоматического дифференцирования обратного распространения ошибки в нейронных сетях в 1992 году. В 1993 году такая система решила задачу «очень глубокого обучения», которая требовала более 1000 последующих слоев в RNN, развернутой во времени. [21]
РНС второго порядка
[ редактировать ]RNN второго порядка используют веса более высокого порядка. вместо стандартного веса и состояния могут быть продуктом. Это позволяет напрямую отображать конечный автомат как при обучении, так и при стабильности и представлении. [70] [71] Длинная кратковременная память является примером этого, но не имеет таких формальных отображений или доказательств стабильности.


Иерархическая рекуррентная нейронная сеть
[ редактировать ]Иерархические рекуррентные нейронные сети (HRNN) соединяют свои нейроны различными способами, чтобы разложить иерархическое поведение на полезные подпрограммы. [68] [72] Такие иерархические структуры познания присутствуют в теориях памяти, представленных философом Анри Бергсоном , чьи философские взгляды вдохновили на создание иерархических моделей. [73]
Иерархические рекуррентные нейронные сети полезны при прогнозировании , помогая прогнозировать дезагрегированные инфляционные компоненты индекса потребительских цен (ИПЦ). Модель HRNN использует информацию с более высоких уровней иерархии ИПЦ для улучшения прогнозов на более низком уровне. Оценка значительного набора данных по индексу CPI-U в США демонстрирует превосходную эффективность модели HRNN по сравнению с различными признанными методами прогнозирования инфляции . [74]
Рекуррентная многослойная сеть перцептрона
[ редактировать ]Как правило, рекуррентная многоуровневая сеть перцептрона (сеть RMLP) состоит из каскадных подсетей, каждая из которых содержит несколько уровней узлов. Каждая подсеть является прямой, за исключением последнего уровня, который может иметь соединения обратной связи. Каждая из этих подсетей соединена только прямыми соединениями. [75]
Модель с несколькими временными масштабами
[ редактировать ]Рекуррентная нейронная сеть с несколькими временными масштабами (MTRNN) — это вычислительная модель на основе нейронов, которая может моделировать функциональную иерархию мозга посредством самоорганизации в зависимости от пространственной связи между нейронами и от различных типов активности нейронов, каждый из которых имеет разные временные свойства. [76] [77] При такой разнообразной активности нейронов непрерывные последовательности любого набора действий сегментируются на многократно используемые примитивы, которые, в свою очередь, гибко интегрируются в различные последовательные модели поведения. Биологическое одобрение такого типа иерархии обсуждалось в теории прогнозирования функций мозга Хокинсом в его книге «Об интеллекте» . [ нужна ссылка ] Такая иерархия также согласуется с теориями памяти, выдвинутыми философом Анри Бергсоном , которые были включены в модель MTRNN. [73] [78]
Мемристивные сети
[ редактировать ]Грег Снайдер из HP Labs описывает систему корковых вычислений с использованием мемристивных наноустройств. [79] Мемристоры . (резисторы памяти) выполнены из тонкопленочных материалов, сопротивление которых электрически настраивается за счет транспорта ионов или кислородных вакансий внутри пленки DARPA Проект SyNAPSE профинансировал исследования IBM и лаборатории HP в сотрудничестве с факультетом когнитивных и нейронных систем (CNS) Бостонского университета для разработки нейроморфных архитектур, которые могут быть основаны на мемристивных системах. Мемристивные сети — это особый тип физической нейронной сети , свойства которой очень похожи на сети (Литтла) Хопфилда, поскольку они имеют непрерывную динамику, ограниченный объем памяти и естественную релаксацию посредством минимизации функции, которая асимптотична модели Изинга . В этом смысле динамика мемристивной схемы имеет преимущество по сравнению с сетью резистор-конденсатор, поскольку имеет более интересное нелинейное поведение. С этой точки зрения инженерные аналоговые мемристивные сети представляют собой своеобразный тип нейроморфной инженерии , в котором поведение устройства зависит от схемы подключения или топологии. Эволюцию этих сетей можно изучать аналитически, используя вариации Уравнение Каравелли – Траверсы – Ди Вентры . [80]
Псевдокод
[ редактировать ]Учитывая временной ряд x длины sequence_length.
В рекуррентной нейронной сети есть цикл, обрабатывающий все записи временного ряда. x через слои neural_network один за другим. Они имеют возвращаемое значение на каждом временном шаге. i оба предсказания y_pred[i] и обновленное скрытое состояние hidden, который имеет длину hidden_size. В результате после цикла сбор всех прогнозов y_pred возвращается.
Следующий псевдокод (на основе языка программирования Python ) иллюстрирует функциональность рекуррентной нейронной сети. [81]
def RNN_forward(x, sequence_length, neural_network, hidden_size):
hidden = zeros(size=hidden_size) # initialize with zeros for each independent time series separately
y_pred = zeros(size=sequence_length)
for i in range(sequence_length):
y_pred[i], hidden = neural_network(x[i], hidden) # update hidden state
return y_pred
Современные библиотеки предоставляют реализации вышеупомянутых функций, оптимизированные во время выполнения, или позволяют ускорить медленный цикл за счет своевременной компиляции .
Обучение
[ редактировать ]Учитель заставляет
[ редактировать ]RNN можно обучить условно генеративной модели последовательностей, известной как авторегрессия .
Конкретно рассмотрим задачу машинного перевода, то есть задана последовательность английских слов, модель состоит в том, чтобы создать последовательность французских слов. Эту проблему необходимо решить с помощью модели seq2seq .


Теперь во время обучения половина модели кодировщика сначала будет принимать , то половина декодера начнет генерировать последовательность . Проблема в том, что если модель допускает ошибку на раннем этапе, скажем, на , то последующие токены, скорее всего, также будут ошибками. Это делает получение модели обучающего сигнала неэффективным, поскольку модель в основном будет учиться сдвигать к , но не остальные.



Принуждение учителя позволяет декодеру использовать правильную выходную последовательность для генерации следующей записи в последовательности. Так, например, он увидит для того, чтобы генерировать .


Градиентный спуск
[ редактировать ]Градиентный спуск — это первого порядка итеративный оптимизации алгоритм для поиска минимума функции. что нелинейные функции активации дифференцируемы В нейронных сетях его можно использовать для минимизации ошибки путем изменения каждого веса пропорционально производной ошибки по этому весу, при условии , . Различные методы для этого были разработаны в 1980-х и начале 1990-х годов Вербосом , Уильямсом , Робинсоном , Шмидхубером , Хохрайтером , Перлмуттером и другими.
Стандартный метод называется « обратным распространением ошибки во времени » или BPTT и представляет собой обобщение обратного распространения ошибки для сетей с прямой связью. [82] [83] Как и этот метод, он является примером автоматического дифференцирования в режиме обратного накопления принципа минимума Понтрягина . Более затратный в вычислительном отношении онлайн-вариант называется «Рекуррентное обучение в реальном времени» или RTRL. [84] [85] что является примером автоматического дифференцирования в режиме прямого накопления со сложенными касательными векторами. В отличие от BPTT, этот алгоритм является локальным во времени, но не локальным в пространстве.
В этом контексте локальность в пространстве означает, что весовой вектор единицы может быть обновлен с использованием только информации, хранящейся в подключенных единицах и самой единице, так что сложность обновления одной единицы является линейной по размерности весового вектора. Локальное по времени означает, что обновления происходят постоянно (онлайн) и зависят только от самого последнего временного шага, а не от нескольких временных шагов в пределах заданного временного горизонта, как в BPTT. Биологические нейронные сети кажутся локальными как во времени, так и в пространстве. [86] [87]
Для рекурсивного вычисления частных производных RTRL имеет временную сложность O (количество скрытых x весов) на временной шаг для вычисления матриц Якоби , в то время как BPTT принимает только O (количество весов) на временной шаг, за счет сохранения всех активных активаций в течение заданного временного интервала. [88] Существует онлайн-гибрид между BPTT и RTRL промежуточной сложности. [89] [90] наряду с вариантами для непрерывного времени. [91]
Основная проблема градиентного спуска для стандартных архитектур RNN заключается в том, что градиенты ошибок исчезают экспоненциально быстро с увеличением временного лага между важными событиями. [43] [92] LSTM в сочетании с гибридным методом обучения BPTT/RTRL пытается преодолеть эти проблемы. [22] Эта задача также решается в независимо рекуррентной нейронной сети (IndRNN). [67] путем сведения контекста нейрона к его собственному прошлому состоянию, и затем межнейронную информацию можно исследовать на следующих уровнях. Воспоминания разных диапазонов, включая долговременную память, можно изучить без проблемы исчезновения и взрыва градиента.
Онлайн-алгоритм, называемый причинно-рекурсивным обратным распространением ошибки (CRBP), реализует и объединяет парадигмы BPTT и RTRL для локально рекуррентных сетей. [93] Он работает с наиболее распространенными локально-рекуррентными сетями. Алгоритм CRBP может минимизировать глобальную ошибку. Этот факт повышает стабильность алгоритма, обеспечивая единое представление о методах расчета градиента для рекуррентных сетей с локальной обратной связью.
Один из подходов к вычислению градиентной информации в RNN с произвольной архитектурой основан на построении диаграмм графов потока сигналов. [94] Он использует пакетный алгоритм BPTT, основанный на теореме Ли для расчета чувствительности сети. [95] Его предложили Ван и Бофейс, а его быструю онлайн-версию предложили Камполуччи, Унчини и Пьяцца. [95]
Методы глобальной оптимизации
[ редактировать ]Обучение весов в нейронной сети можно смоделировать как задачу нелинейной глобальной оптимизации . Целевую функцию можно сформировать для оценки пригодности или ошибки конкретного вектора весов следующим образом: во-первых, веса в сети устанавливаются в соответствии с вектором весов. Затем сеть оценивается по обучающей последовательности. Обычно разница суммы квадратов между прогнозами и целевыми значениями, указанными в обучающей последовательности, используется для представления ошибки текущего весового вектора. Затем для минимизации этой целевой функции можно использовать произвольные методы глобальной оптимизации.
Наиболее распространенным методом глобальной оптимизации для обучения RNN являются генетические алгоритмы , особенно в неструктурированных сетях. [96] [97] [98]
Первоначально генетический алгоритм кодируется с помощью весов нейронной сети заранее определенным образом, где один ген в хромосоме представляет одно весовое звено. Вся сеть представлена в виде одной хромосомы. Функция приспособленности оценивается следующим образом:
- Каждый вес, закодированный в хромосоме, присваивается соответствующему весовому звену сети.
- Обучающий набор предоставляется сети, которая распространяет входные сигналы вперед.
- Среднеквадратическая ошибка возвращается в функцию фитнеса.
- Эта функция управляет процессом генетического отбора.
Многие хромосомы составляют популяцию; поэтому развивается множество различных нейронных сетей до тех пор, пока не будет выполнен критерий остановки. Распространенная схема остановки:
- Когда нейронная сеть изучила определенный процент обучающих данных или
- Когда минимальное значение среднеквадратической ошибки удовлетворяется или
- Когда достигнуто максимальное количество обучающих поколений.
Функция пригодности оценивает критерий остановки, поскольку она получает среднеквадратическую ошибку, обратную от каждой сети во время обучения. Следовательно, цель генетического алгоритма — максимизировать функцию приспособленности, уменьшив среднеквадратическую ошибку.
Для поиска хорошего набора весов можно использовать другие методы глобальной (и/или эволюционной) оптимизации, такие как моделирование отжига или оптимизация роя частиц .
Непрерывное время
[ редактировать ]Рекуррентная нейронная сеть непрерывного времени (CTRNN) использует систему обыкновенных дифференциальных уравнений для моделирования воздействия на нейрон входящих входных данных. Они обычно анализируются теорией динамических систем . Многие модели RNN в нейробиологии работают в непрерывном времени. [20]
Для нейрона в сети с активацией , скорость изменения активации определяется выражением:



Где:
- : Постоянная времени постсинаптического узла
- : Активация постсинаптического узла.
- : Скорость изменения активации постсинаптического узла.
- : Вес соединения от пре- к постсинаптическому узлу.
- : Сигмовидная часть x, например .
- : Активация пресинаптического узла.
- : Смещение пресинаптического узла
- : Ввод (если есть) в узел








CTRNN были применены в эволюционной робототехнике , где они использовались для решения проблем зрения, [99] сотрудничество, [100] и минимальное когнитивное поведение. [101]
Обратите внимание, что согласно теореме выборки Шеннона рекуррентные нейронные сети с дискретным временем можно рассматривать как рекуррентные нейронные сети с непрерывным временем, в которых дифференциальные уравнения преобразуются в эквивалентные разностные уравнения . [102] Эту трансформацию можно рассматривать как происходящую после активации постсинаптического узла. были подвергнуты низкочастотной фильтрации, но до отбора проб.

На самом деле это рекурсивные нейронные сети с особой структурой: линейной цепочкой. В то время как рекурсивные нейронные сети работают с любой иерархической структурой, объединяя дочерние представления с родительскими представлениями, рекуррентные нейронные сети работают с линейной прогрессией времени, объединяя предыдущий временной шаг и скрытое представление в представление для текущего временного шага.
С точки зрения временных рядов, RNN могут выглядеть как нелинейные версии фильтров с конечной импульсной характеристикой и фильтрами с бесконечной импульсной характеристикой , а также как нелинейная авторегрессионная экзогенная модель (NARX). [103] RNN имеет бесконечную импульсную характеристику, тогда как сверточные нейронные сети имеют конечную импульсную характеристику. Оба класса сетей демонстрируют временное динамическое поведение . [104] Конечная импульсная рекуррентная сеть представляет собой направленный ациклический граф , который можно развернуть и заменить нейронной сетью строго прямого распространения, тогда как бесконечная импульсная рекуррентная сеть представляет собой ориентированный циклический граф , который не может быть развернут.
Эффект обучения на основе памяти для распознавания последовательностей также может быть реализован с помощью более биологической модели, которая использует механизм молчания, проявляющийся в нейронах с относительно высокочастотной пиковой активностью. [105]
Дополнительные сохраненные состояния и хранилище под непосредственным управлением сети могут быть добавлены как в бесконечно-импульсные , так и в конечно-импульсные сети. Другая сеть или граф также может заменить хранилище, если оно включает временные задержки или петли обратной связи. Такие контролируемые состояния называются вентильными состояниями или вентилируемой памятью и являются частью сетей долгосрочной краткосрочной памяти (LSTM) и вентилируемых рекуррентных единиц . Это также называется нейронной сетью обратной связи (FNN).
Библиотеки
[ редактировать ]- Апач Синга
- Кафе : создано Центром видения и обучения Беркли (BVLC). Он поддерживает как процессор, так и графический процессор. Разработан на C++ и имеет Python и MATLAB . оболочки
- Chainer : полностью на Python, производственная поддержка процессоров, графических процессоров, распределенное обучение.
- Deeplearning4j : глубокое обучение Java и Scala с поддержкой нескольких графических процессоров в Spark .
- Flux : включает интерфейсы для RNN, включая GRU и LSTM, написанные на Julia .
- Keras : API высокого уровня, предоставляющий оболочку для многих других библиотек глубокого обучения.
- Когнитивный инструментарий Microsoft
- MXNet : платформа глубокого обучения с открытым исходным кодом, используемая для обучения и развертывания глубоких нейронных сетей.
- PyTorch : тензоры и динамические нейронные сети на Python с ускорением на графическом процессоре.
- TensorFlow Google : Theano-подобная библиотека под лицензией Apache 2.0 с поддержкой CPU, GPU и фирменного TPU . [106] мобильный
- Theano : библиотека глубокого обучения для Python с API, в значительной степени совместимым с библиотекой NumPy .
- Torch : среда научных вычислений с поддержкой алгоритмов машинного обучения, написанная на C и Lua .
Приложения
[ редактировать ]Приложения рекуррентных нейронных сетей включают:
- Машинный перевод [32]
- Управление роботом [107]
- Прогнозирование временных рядов [108] [109] [110]
- Распознавание речи [111] [24] [112]
- Синтез речи [113]
- Интерфейсы мозг-компьютер [114]
- Обнаружение аномалий временных рядов [115]
- Модель преобразования текста в видео [116]
- Обучение ритму [117]
- Музыкальная композиция [118]
- Изучение грамматики [119] [47] [120]
- Распознавание рукописного ввода [121] [122]
- Распознавание действий человека [123]
- Обнаружение гомологии белков [124]
- Прогнозирование субклеточной локализации белков [125]
- Некоторые задачи прогнозирования в области управления бизнес-процессами [126]
- Прогнозирование в путях оказания медицинской помощи [127]
- Прогнозы разрушения термоядерной плазмы в реакторах (код Fusion Recurrent Neural Network (FRNN)) [128]
Ссылки
[ редактировать ]- ^ Тилаб, Ахмед (01 декабря 2018 г.). «Прогнозирование временных рядов с использованием методологий искусственных нейронных сетей: систематический обзор» . Журнал будущих вычислений и информатики . 3 (2): 334–340. дои : 10.1016/j.fcij.2018.10.003 . ISSN 2314-7288 .
- ^ Грейвс, Алекс ; Ливицкий, Маркус; Фернандес, Сантьяго; Бертолами, Роман; Бунке, Хорст; Шмидхубер, Юрген (2009). «Новая коннекционистская система для улучшения неограниченного распознавания рукописного текста» (PDF) . Транзакции IEEE по анализу шаблонов и машинному интеллекту . 31 (5): 855–868. CiteSeerX 10.1.1.139.4502 . дои : 10.1109/tpami.2008.137 . ПМИД 19299860 . S2CID 14635907 .
- ^ Jump up to: а б Сак, Хашим; Старший, Эндрю; Бофе, Франсуаза (2014). «Архитектуры рекуррентных нейронных сетей с долгосрочной кратковременной памятью для крупномасштабного акустического моделирования» (PDF) . Google Исследования.
- ^ Jump up to: а б Ли, Сянган; У, Сихун (15 октября 2014 г.). «Построение глубоких рекуррентных нейронных сетей на основе долговременной памяти для распознавания речи с большим словарным запасом». arXiv : 1410.4281 [ cs.CL ].
- ^ Дюпон, Сэмюэл (2019). «Тщательный обзор текущего развития структур нейронных сетей» . Ежегодные обзоры под контролем . 14 : 200–230.
- ^ Абиодун, Олударе Исаак; Джантан, Аман; Омолара, Абиодун Эстер; Дада, Кеми Виктория; Мохамед, Нахаат Абделатиф; Аршад, Хумайра (01 ноября 2018 г.). «Современное состояние приложений искусственных нейронных сетей: обзор» . Гелион . 4 (11): e00938. Бибкод : 2018Heliy...400938A . doi : 10.1016/j.heliyon.2018.e00938 . ISSN 2405-8440 . ПМК 6260436 . ПМИД 30519653 .
- ^ Ленц, В. (1920), «Вклад в понимание магнитных свойств твердых тел», Physical Journal , 21 : 613–615.
- ^ Изинг, Э. (1925), «Вклад в теорию ферромагнетизма», Z. Phys. , 31 (1): 253–258, Bibcode : 1925ZPhy...31..253I , doi : 10.1007/BF02980577 , S2CID 122157319
- ^ Браш, Стивен Г. (1967). «История модели Ленца-Изинга». Обзоры современной физики . 39 (4): 883–893. Бибкод : 1967РвМП...39..883Б . дои : 10.1103/RevModPhys.39.883 .
- ^ Глаубер, Рой Дж. (февраль 1963 г.). «Рой Дж. Глаубер «Зависящая от времени статистика модели Изинга» » . Журнал математической физики . 4 (2): 294–307. дои : 10.1063/1.1703954 . Проверено 21 марта 2021 г.
- ^ Амари, Сюн-Ичи (1972). «Обучение шаблонам и последовательностям шаблонов с помощью самоорганизующихся сетей пороговых элементов». IEEE-транзакции . С (21): 1197–1206.
- ^ Шмидхубер, Юрген (2022). «Аннотированная история современного искусственного интеллекта и глубокого обучения». arXiv : 2212.11279 [ cs.NE ].
- ^ де Но, Р. Лоренте (1 августа 1933). «Вестибулоокулярная рефлекторная дуга» . Архив неврологии и психиатрии . 30 (2): 245. doi : 10.1001/archneurpsyc.1933.02240140009001 . ISSN 0096-6754 .
- ^ Ларрива-Сад, Хорхе А. (3 декабря 2014 г.). «Некоторые предсказания Рафаэля Лоренте де Но 80 лет спустя» . Границы нейроанатомии . 8 : 147. дои : 10.3389/fnana.2014.00147 . ISSN 1662-5129 . ПМЦ 4253658 . ПМИД 25520630 .
- ^ «реверберирующий контур» . Оксфордский справочник . Проверено 27 июля 2024 г.
- ^ Маккалок, Уоррен С.; Питтс, Уолтер (декабрь 1943 г.). «Логическое исчисление идей, имманентных нервной деятельности» . Вестник математической биофизики . 5 (4): 115–133. дои : 10.1007/BF02478259 . ISSN 0007-4985 .
- ^ Морено-Диас, Роберто; Морено-Диас, Арминда (апрель 2007 г.). «О наследии У. С. Маккаллоха» . Биосистемы . 88 (3): 185–190. Бибкод : 2007BiSys..88..185M . doi : 10.1016/j.biosystems.2006.08.010 .
- ^ Арбиб, Майкл А. (декабрь 2000 г.). «В поисках логики нервной системы Уоррена Маккалока» . Перспективы биологии и медицины . 43 (2): 193–216. дои : 10.1353/pbm.2000.0001 . ISSN 1529-8795 . ПМИД 10804585 .
- ^ Реншоу, Бердси (1 мая 1946 г.). «Центральные эффекты центростремительных импульсов в аксонах спинномозговых вентральных корешков» . Журнал нейрофизиологии . 9 (3): 191–204. дои : 10.1152/jn.1946.9.3.191 . ISSN 0022-3077 . ПМИД 21028162 .
- ^ Jump up to: а б Гроссберг, Стивен (22 февраля 2013 г.). «Рекуррентные нейронные сети» . Схоларпедия . 8 (2): 1888. Бибкод : 2013SchpJ...8.1888G . doi : 10.4249/scholarpedia.1888 . ISSN 1941-6016 .
- ^ Jump up to: а б Шмидхубер, Юрген (1993). Кандидатская диссертация: Системное моделирование и оптимизация (PDF) . [ постоянная мертвая ссылка ] Страница 150 и далее демонстрирует присвоение кредитов по эквиваленту 1200 слоев в развернутой RNN.
- ^ Jump up to: а б Хохрайтер, Зепп ; Шмидхубер, Юрген (1 ноября 1997 г.). «Долгая кратковременная память». Нейронные вычисления . 9 (8): 1735–1780. дои : 10.1162/neco.1997.9.8.1735 . ПМИД 9377276 . S2CID 1915014 .
- ^ Грейвс, Алекс; Шмидхубер, Юрген (1 июля 2005 г.). «Кадровая классификация фонем с помощью двунаправленного LSTM и других архитектур нейронных сетей». Нейронные сети . IJCNN 2005. 18 (5): 602–610. CiteSeerX 10.1.1.331.5800 . дои : 10.1016/j.neunet.2005.06.042 . ПМИД 16112549 . S2CID 1856462 .
- ^ Jump up to: а б Фернандес, Сантьяго; Грейвс, Алекс; Шмидхубер, Юрген (2007). «Применение рекуррентных нейронных сетей для распознавания ключевых слов» . Материалы 17-й Международной конференции по искусственным нейронным сетям . ICANN'07. Берлин, Гейдельберг: Springer-Verlag. стр. 220–229. ISBN 978-3-540-74693-5 .
- ^ Jump up to: а б с Шмидхубер, Юрген (январь 2015 г.). «Глубокое обучение в нейронных сетях: обзор». Нейронные сети . 61 : 85–117. arXiv : 1404.7828 . дои : 10.1016/j.neunet.2014.09.003 . ПМИД 25462637 . S2CID 11715509 .
- ^ Грейвс, Алекс; Шмидхубер, Юрген (2009). «Офлайн-распознавание рукописного ввода с помощью многомерных рекуррентных нейронных сетей» . В Коллере, Д.; Шурманс, Д .; Бенджио, Ю .; Ботту, Л. (ред.). Достижения в области нейронных систем обработки информации . Том. 21. Фонд нейронных систем обработки информации (NIPS). стр. 545–552.
- ^ «Оценочная речь HUB5 по английскому языку 2000 года — Консорциум лингвистических данных» . каталог.ldc.upenn.edu .
- ^ Ханнун, Ауни; Кейс, Карл; Каспер, Джаред; Катандзаро, Брайан; Диамос, Грег; Элсен, Эрих; Пренгер, Райан; Сатиш, Санджив; Сенгупта, Шубхо (17 декабря 2014 г.). «Глубокая речь: расширение сквозного распознавания речи». arXiv : 1412.5567 [ cs.CL ].
- ^ Фан, Бо; Ван, Лицзюань; Сунг, Фрэнк К.; Се, Лэй (2015). «Фотореалистичная говорящая голова с глубоким двунаправленным LSTM». Материалы Международной конференции IEEE ICASSP 2015 по акустике, речи и обработке сигналов . стр. 4884–8. дои : 10.1109/ICASSP.2015.7178899 . ISBN 978-1-4673-6997-8 .
- ^ Дзен, Хейга; Сак, Хашим (2015). «Однонаправленная рекуррентная нейронная сеть с долговременной краткосрочной памятью и рекуррентным выходным слоем для синтеза речи с малой задержкой» (PDF) . Материалы Международной конференции IEEE ICASSP 2015 по акустике, речи и обработке сигналов . стр. 4470–4. дои : 10.1109/ICASSP.2015.7178816 . ISBN 978-1-4673-6997-8 .
- ^ Сак, Хашим; Старший, Эндрю; Рао, Канишка; Бофе, Франсуаза; Шалквик, Йохан (сентябрь 2015 г.). «Голосовой поиск Google: быстрее и точнее» .
- ^ Jump up to: а б Суцкевер, Илья; Виньялс, Ориол; Ле, Куок В. (2014). «Последовательное обучение с помощью нейронных сетей» (PDF) . Электронные материалы конференции по нейронным системам обработки информации . 27 : 5346. arXiv : 1409.3215 . Бибкод : 2014arXiv1409.3215S .
- ^ Йозефович, Рафаль; Виньялс, Ориол; Шустер, Майк; Шазир, Ноам; Ву, Юнхуэй (07 февраля 2016 г.). «Изучение пределов языкового моделирования». arXiv : 1602.02410 [ cs.CL ].
- ^ Гиллик, Дэн; Бранк, Клифф; Виньялс, Ориол; Субраманья, Амарнаг (30 ноября 2015 г.). «Многоязычная языковая обработка из байтов». arXiv : 1512.00103 [ cs.CL ].
- ^ Виньялс, Ориол; Тошев, Александр; Бенджио, Сами; Эрхан, Дмитрий (17 ноября 2014 г.). «Покажи и расскажи: нейронный генератор подписей к изображениям». arXiv : 1411.4555 [ cs.CV ].
- ^ Петерс М.Е., Нейман М., Айер М., Гарднер М., Кларк С., Ли К., Зеттлмойер Л. (2018). «Глубокие контекстуализированные представления слов». arXiv : 1802.05365 [ cs.CL ].
- ^ Васван, Ашиш; Шазир, Ноам; Пармар, Ник; Ушкорейт, Джейкоб; Джонс, Лион; Гомес, Эйдан Н; Кайзер, Лукаш; Полосухин, Илья (2017). «Внимание – это все, что вам нужно » Достижения в области нейронных систем обработки информации . 30 . Карран Ассошиэйтс, Инк.
- ^ Оорд, Аарон ван ден; Кальхбреннер, Нал; Кавукчуоглу, Корай (11 июня 2016 г.). «Пиксельные рекуррентные нейронные сети» . Материалы 33-й Международной конференции по машинному обучению . ПМЛР: 1747–1756.
- ^ Jump up to: а б Круз, Холк; Нейронные сети как кибернетические системы , 2-е и исправленное издание.
- ^ Элман, Джеффри Л. (1990). «Нахождение структуры во времени» . Когнитивная наука . 14 (2): 179–211. дои : 10.1016/0364-0213(90)90002-E .
- ^ Джордан, Майкл И. (1 января 1997 г.). «Последовательный заказ: подход к параллельной распределенной обработке». Нейросетевые модели познания — биоповеденческие основы . Достижения психологии. Том. 121. стр. 471–495. дои : 10.1016/s0166-4115(97)80111-2 . ISBN 978-0-444-81931-4 . S2CID 15375627 .
- ^ Герс, Феликс А.; Шраудольф, Никол Н.; Шмидхубер, Юрген (2002). «Изучение точного времени с помощью рекуррентных сетей LSTM» (PDF) . Журнал исследований машинного обучения . 3 : 115–143 . Проверено 13 июня 2017 г.
- ^ Jump up to: а б с Хохрейтер, Зепп (1991). Исследования по динамическим нейронным сетям (PDF) (Диплом). Институт компьютерных наук Мюнхенского технического университета.
- ^ Байер, Джастин; Виерстра, Даан; Тогелиус, Джулиан; Шмидхубер, Юрген (14 сентября 2009 г.). «Развитие структур ячеек памяти для последовательного обучения». Искусственные нейронные сети — ICANN 2009 (PDF) . Конспекты лекций по информатике. Том. 5769. Берлин, Гейдельберг: Springer. стр. 755–764. дои : 10.1007/978-3-642-04277-5_76 . ISBN 978-3-642-04276-8 .
- ^ Фернандес, Сантьяго; Грейвс, Алекс; Шмидхубер, Юрген (2007). «Разметка последовательностей в структурированных доменах с помощью иерархических рекуррентных нейронных сетей» (PDF) . Материалы 20-й Международной совместной конференции по искусственному интеллекту, Иджай, 2007 г. стр. 774–9. CiteSeerX 10.1.1.79.1887 .
- ^ Грейвс, Алекс; Фернандес, Сантьяго; Гомес, Фаустино Дж. (2006). «Временная классификация коннекционистов: маркировка данных несегментированных последовательностей с помощью рекуррентных нейронных сетей» (PDF) . Материалы международной конференции по машинному обучению . стр. 369–376. CiteSeerX 10.1.1.75.6306 . дои : 10.1145/1143844.1143891 . ISBN 1-59593-383-2 .
- ^ Jump up to: а б Герс, Феликс А.; Шмидхубер, Юрген (2001). «Рекуррентные сети LSTM изучают простые контекстно-свободные и контекстно-зависимые языки» (PDF) . Транзакции IEEE в нейронных сетях . 12 (6): 1333–40. дои : 10.1109/72.963769 . ПМИД 18249962 . S2CID 10192330 . Архивировано из оригинала (PDF) 10 июля 2020 г. Проверено 12 декабря 2017 г.
- ^ Черт возьми, Джоэл; Салем, Фатхи М. (12 января 2017 г.). «Упрощенные минимальные варианты вентильных единиц для рекуррентных нейронных сетей». arXiv : 1701.03452 [ cs.NE ].
- ^ Дей, Рахул; Салем, Фатхи М. (20 января 2017 г.). «Варианты вентильных нейронных сетей с закрытыми рекуррентными единицами (GRU)». arXiv : 1701.05923 [ cs.NE ].
- ^ Бритц, Денни (27 октября 2015 г.). «Учебное пособие по рекуррентной нейронной сети, часть 4. Реализация GRU/LSTM RNN с помощью Python и Theano – WildML» . Wildml.com . Проверено 18 мая 2016 г.
- ^ Jump up to: а б Чунг, Джунён; Гульчере, Чаглар; Чо, КёнХён; Бенджио, Йошуа (2014). «Эмпирическая оценка вентилируемых рекуррентных нейронных сетей при моделировании последовательностей». arXiv : 1412.3555 [ cs.NE ].
- ^ Грубер, Н.; Йокиш, А. (2020), «Являются ли клетки GRU более специфичными, а клетки LSTM более чувствительными при классификации текста по мотивам?», Frontiers in Artificial Intelligence , 3 : 40, doi : 10.3389/frai.2020.00040 , PMC 7861254 , PMID 33733157 , S2CID 220252321
- ^ Коско, Барт (1988). «Двунаправленные ассоциативные воспоминания». Транзакции IEEE по системам, человеку и кибернетике . 18 (1): 49–60. дои : 10.1109/21.87054 . S2CID 59875735 .
- ^ Раккиаппан, Раджан; Чандрасекар, Аруначалам; Лакшманан, Субраманиан; Пак, Джу Х. (2 января 2015 г.). «Экспоненциальная устойчивость марковских прыгающих стохастических нейронных сетей BAM с зависящими от режима вероятностными изменяющимися во времени задержками и импульсным управлением». Сложность . 20 (3): 39–65. Бибкод : 2015Cmplx..20c..39R . дои : 10.1002/cplx.21503 .
- ^ Рохас, Рауль (1996). Нейронные сети: систематическое введение . Спрингер. п. 336. ИСБН 978-3-540-60505-8 .
- ^ Джагер, Герберт; Хаас, Харальд (2 апреля 2004 г.). «Использование нелинейности: прогнозирование хаотических систем и экономия энергии в беспроводной связи». Наука . 304 (5667): 78–80. Бибкод : 2004Sci...304...78J . CiteSeerX 10.1.1.719.2301 . дои : 10.1126/science.1091277 . ПМИД 15064413 . S2CID 2184251 .
- ^ Маасс, Вольфганг; Натшлегер, Томас; Маркрам, Генри (2002). «Вычисления в реальном времени без стабильных состояний: новая основа нейронных вычислений на основе возмущений» (PDF) . Нейронные вычисления . 14 (11): 2531–2560. дои : 10.1162/089976602760407955 . ПМИД 12433288 . S2CID 1045112 .
- ^ Голлер, Кристоф; Кюхлер, Андреас (1996). «Изучение распределенных представлений, зависящих от задачи, путем обратного распространения ошибки через структуру». Материалы Международной конференции по нейронным сетям (ICNN'96) . Том. 1. п. 347. CiteSeerX 10.1.1.52.4759 . дои : 10.1109/ICNN.1996.548916 . ISBN 978-0-7803-3210-2 . S2CID 6536466 .
- ^ Линнаинмаа, Сеппо (1970). Представление совокупной ошибки округления алгоритма в виде разложения Тейлора локальных ошибок округления (MSc) (на финском языке). Университет Хельсинки.
- ^ Гриванк, Андреас; Вальтер, Андреа (2008). Оценка производных: принципы и методы алгоритмического дифференцирования (второе изд.). СИАМ. ISBN 978-0-89871-776-1 .
- ^ Сошер, Ричард; Лин, Клифф; Нг, Эндрю Ю.; Мэннинг, Кристофер Д., «Разбор естественных сцен и естественного языка с помощью рекурсивных нейронных сетей» (PDF) , 28-я Международная конференция по машинному обучению (ICML 2011)
- ^ Сошер, Ричард; Перелыгин, Алексей; Ву, Джин Ю.; Чуанг, Джейсон; Мэннинг, Кристофер Д.; Нг, Эндрю Ю.; Поттс, Кристофер. «Рекурсивные глубокие модели семантической композиционности в древовидном банке настроений» (PDF) . Эмнлп 2013 .
- ^ Грейвс, Алекс; Уэйн, Грег; Дэниелс, Иво (2014). «Нейронные машины Тьюринга». arXiv : 1410.5401 [ cs.NE ].
- ^ Грейвс, Алекс; Уэйн, Грег; Рейнольдс, Малькольм; Харли, Тим; Данигелька, Иво; Грабская-Барвинская, Агнешка; Кольменарехо, Серхио Гомес; Грефенштетт, Эдвард; Рамальо, Тьяго (12 октября 2016 г.). «Гибридные вычисления с использованием нейронной сети с динамической внешней памятью» . Природа . 538 (7626): 471–476. Бибкод : 2016Natur.538..471G . дои : 10.1038/nature20101 . ISSN 1476-4687 . ПМИД 27732574 . S2CID 205251479 .
- ^ Сунь, Го-Чжэн; Джайлз, К. Ли; Чен, Син-Хен (1998). «Автомат опускания нейронной сети: архитектура, динамика и обучение». В Джайлзе, К. Ли; Гори, Марко (ред.). Адаптивная обработка последовательностей и структур данных . Конспекты лекций по информатике. Берлин, Гейдельберг: Springer. стр. 296–345. CiteSeerX 10.1.1.56.8723 . дои : 10.1007/bfb0054003 . ISBN 978-3-540-64341-8 .
- ^ Хётыниеми, Хейкки (1996). «Машины Тьюринга — это рекуррентные нейронные сети». Труды STeP '96/Публикации Финского общества искусственного интеллекта : 13–24.
- ^ Jump up to: а б Ли, Шуай; Ли, Ваньцин; Кук, Крис; Чжу, Се; Янбо, Гао (2018). «Независимо рекуррентная нейронная сеть (IndRNN): построение более длинной и глубокой RNN». arXiv : 1803.04831 [ cs.CV ].
- ^ Jump up to: а б с д Шмидхубер, Юрген (1992). «Изучение сложных, расширенных последовательностей с использованием принципа сжатия истории» (PDF) . Нейронные вычисления . 4 (2): 234–242. дои : 10.1162/neco.1992.4.2.234 . S2CID 18271205 . [ постоянная мертвая ссылка ]
- ^ Шмидхубер, Юрген (2015). «Глубокое обучение» . Схоларпедия . 10 (11): 32832. Бибкод : 2015SchpJ..1032832S . doi : 10.4249/scholarpedia.32832 .
- ^ Джайлз, К. Ли; Миллер, Клиффорд Б.; Чен, Донг; Чен, Син-Хен; Сунь, Го-Чжэн; Ли, Йи-Чун (1992). «Изучение и извлечение конечных автоматов с помощью рекуррентных нейронных сетей второго порядка» (PDF) . Нейронные вычисления . 4 (3): 393–405. дои : 10.1162/neco.1992.4.3.393 . S2CID 19666035 .
- ^ Омлин, Кристиан В.; Джайлз, К. Ли (1996). «Построение детерминированных конечных автоматов в рекуррентных нейронных сетях». Журнал АКМ . 45 (6): 937–972. CiteSeerX 10.1.1.32.2364 . дои : 10.1145/235809.235811 . S2CID 228941 .
- ^ Пейн, Райнер В.; Тани, июнь (01 сентября 2005 г.). «Как иерархическое управление самоорганизуется в искусственных адаптивных системах». Адаптивное поведение . 13 (3): 211–225. дои : 10.1177/105971230501300303 . S2CID 9932565 .
- ^ Jump up to: а б «Бернс, Бенюро, Тани (2018) Адаптивная постоянная времени, вдохновленная Бергсоном, для модели рекуррентной нейронной сети с множеством временных масштабов. JNNS» .
- ^ Баркан, Орен; Бенчимол, Джонатан; Каспи, Итамар; Коэн, Элия; Хаммер, Аллон; Кенигштейн, Ноам (2023). «Прогнозирование компонентов инфляции ИПЦ с помощью иерархических рекуррентных нейронных сетей». Международный журнал прогнозирования . 39 (3): 1145–1162. arXiv : 2011.07920 . doi : 10.1016/j.ijforecast.2022.04.009 .
- ^ Тучку, Курт (июнь 1995 г.). Рекуррентные многослойные перцептроны для идентификации и контроля: путь к приложениям . Отчет Института компьютерных наук. Том. 118. Вюрцбургский университет-ам-Хубланд. CiteSeerX 10.1.1.45.3527 .
- ^ Ямасита, Юичи; Тани, июнь (07 ноября 2008 г.). «Появление функциональной иерархии в модели нейронной сети с множеством временных масштабов: эксперимент с роботом-гуманоидом» . PLOS Вычислительная биология . 4 (11): е1000220. Бибкод : 2008PLSCB...4E0220Y . дои : 10.1371/journal.pcbi.1000220 . ПМК 2570613 . ПМИД 18989398 .
- ^ Альнаджар, Фади; Ямасита, Юичи; Тани, июнь (2013). «Иерархическая и функциональная связность когнитивных механизмов высшего порядка: нейророботическая модель для исследования стабильности и гибкости рабочей памяти» . Границы нейроробототехники . 7 :2. дои : 10.3389/fnbot.2013.00002 . ПМК 3575058 . ПМИД 23423881 .
- ^ «Материалы 28-й ежегодной конференции Японского общества нейронных сетей (октябрь 2018 г.)» (PDF) .
- ^ Снайдер, Грег (2008), «Корковые вычисления с мемристивными наноустройствами» , Sci-DAC Review , 10 : 58–65, заархивировано из оригинала 16 мая 2016 г. , получено 6 сентября 2019 г.
- ^ Каравелли, Франческо; Траверса, Фабио Лоренцо; Ди Вентра, Массимилиано (2017). «Сложная динамика мемристивных цепей: аналитические результаты и универсальная медленная релаксация». Физический обзор E . 95 (2): 022140.arXiv : 1608.08651 . Бибкод : 2017PhRvE..95b2140C . дои : 10.1103/PhysRevE.95.022140 . ПМИД 28297937 . S2CID 6758362 .
- ^ Шолле, Франсуа; Калиновский, Томаш; Аллер, Джей-Джей (13 сентября 2022 г.). Глубокое обучение с помощью R, второе издание . Саймон и Шустер. ISBN 978-1-63835-078-1 .
- ^ Вербос, Пол Дж. (1988). «Обобщение обратного распространения ошибки с применением к рекуррентной модели газового рынка» . Нейронные сети . 1 (4): 339–356. дои : 10.1016/0893-6080(88)90007-x . S2CID 205001834 .
- ^ Румельхарт, Дэвид Э. (1985). Изучение внутренних представлений путем распространения ошибок . Сан-Диего (Калифорния): Институт когнитивных наук Калифорнийского университета.
- ^ Робинсон, Энтони Дж.; Фоллсайд, Фрэнк (1987). Сеть динамического распространения ошибок, управляемая утилитой . Технический отчет CUED/F-INFENG/TR.1. Инженерный факультет Кембриджского университета.
- ^ Уильямс, Рональд Дж.; Зипсер, Д. (1 февраля 2013 г.). «Алгоритмы градиентного обучения для рекуррентных сетей и их вычислительная сложность». В Шовене, Ив; Румельхарт, Дэвид Э. (ред.). Обратное распространение ошибки: теория, архитектура и приложения . Психология Пресс. ISBN 978-1-134-77581-1 .
- ^ Шмидхубер, Юрген (1 января 1989 г.). «Алгоритм локального обучения для динамических сетей прямой связи и рекуррентных сетей». Наука о связях . 1 (4): 403–412. дои : 10.1080/09540098908915650 . S2CID 18721007 .
- ^ Принсипи, Хосе К.; Эулиано, Нил Р.; Лефевр, В. Курт (2000). Нейронные и адаптивные системы: основы посредством моделирования . Уайли. ISBN 978-0-471-35167-2 .
- ^ Янн, Оливье; Таллек, Корантен; Шарпиа, Гийом (28 июля 2015 г.). «Обучение рекуррентных сетей онлайн без возврата». arXiv : 1507.07680 [ cs.NE ].
- ^ Шмидхубер, Юрген (1 марта 1992 г.). «Алгоритм обучения временной сложности хранилища фиксированного размера O (n3) для полностью рекуррентных, непрерывно работающих сетей». Нейронные вычисления . 4 (2): 243–248. дои : 10.1162/neco.1992.4.2.243 . S2CID 11761172 .
- ^ Уильямс, Рональд Дж. (1989). Сложность алгоритмов точного вычисления градиента для рекуррентных нейронных сетей (Отчет). Технический отчет NU-CCS-89-27. Бостон (Массачусетс): Северо-Восточный университет, Колледж компьютерных наук. Архивировано из оригинала 20 октября 2017 г. Проверено 2 июля 2017 г.
- ^ Перлмуттер, Барак А. (1 июня 1989 г.). «Изучение пространственных траекторий состояний в рекуррентных нейронных сетях» . Нейронные вычисления . 1 (2): 263–269. дои : 10.1162/neco.1989.1.2.263 . S2CID 16813485 .
- ^ Хохрейтер, Зепп; и др. (15 января 2001 г.). «Градиентный поток в рекуррентных сетях: сложность изучения долгосрочных зависимостей» . В Колене, Джон Ф.; Кремер, Стефан К. (ред.). Полевое руководство по динамическим рекуррентным сетям . Джон Уайли и сыновья. ISBN 978-0-7803-5369-5 .
- ^ Камполуччи, Паоло; Унчини, Аурелио; Пьяцца, Франческо; Рао, Бхаскар Д. (1999). «Алгоритмы онлайн-обучения для локально рекуррентных нейронных сетей». Транзакции IEEE в нейронных сетях . 10 (2): 253–271. CiteSeerX 10.1.1.33.7550 . дои : 10.1109/72.750549 . ПМИД 18252525 .
- ^ Ван, Эрик А.; Бофе, Франсуаза (1996). «Диаграмматический вывод градиентных алгоритмов для нейронных сетей». Нейронные вычисления . 8 : 182–201. дои : 10.1162/neco.1996.8.1.182 . S2CID 15512077 .
- ^ Jump up to: а б Камполуччи, Паоло; Унчини, Аурелио; Пьяцца, Франческо (2000). «Подход к онлайн-расчету градиента на основе графика потока сигналов». Нейронные вычисления . 12 (8): 1901–1927. CiteSeerX 10.1.1.212.5406 . дои : 10.1162/089976600300015196 . ПМИД 10953244 . S2CID 15090951 .
- ^ Гомес, Фаустино Дж.; Мииккулайнен, Ристо (1999), «Решение немарковских задач управления с помощью нейроэволюции» (PDF) , IJCAI 99 , Морган Кауфманн , получено 5 августа 2017 г.
- ^ Сайед, Омар (май 1995 г.). Применение генетических алгоритмов к рекуррентным нейронным сетям для изучения параметров и архитектуры сети (MSc). Факультет электротехники Университета Кейс Вестерн Резерв.
- ^ Гомес, Фаустино Дж.; Шмидхубер, Юрген; Мииккулайнен, Ристо (июнь 2008 г.). «Ускоренная нервная эволюция посредством совместно развившихся синапсов» (PDF) . Журнал исследований машинного обучения . 9 : 937–965.
- ^ Харви, Инман; Мужья, Фил; Клифф, Дэйв (1994), «Видеть свет: искусственная эволюция, реальное видение» , 3-я международная конференция по моделированию адаптивного поведения: от животных к животным 3 , стр. 392–401.
- ^ Куинн, Мэтт (2001). «Развитие коммуникации без выделенных каналов связи». Достижения в области искусственной жизни: 6-я Европейская конференция, ECAL 2001 . стр. 357–366. дои : 10.1007/3-540-44811-X_38 . ISBN 978-3-540-42567-0 .
- ^ Бир, Рэндалл Д. (1997). «Динамика адаптивного поведения: программа исследований». Робототехника и автономные системы . 20 (2–4): 257–289. дои : 10.1016/S0921-8890(96)00063-2 .
- ^ Шерстинский, Алекс (07.12.2018). Блум-Редди, Бенджамин; Пейдж, Брукс; Куснер, Мэтт; Каруана, Рич; Рейнфорт, Том; Да, Йи Уай (ред.). Получение определения рекуррентной нейронной сети и развертывание RNN с использованием обработки сигналов . Мастер-класс «Критика и коррекция тенденций в машинном обучении» на NeurIPS-2018 .
- ^ Сигельманн, Хава Т.; Хорн, Билл Г.; Джайлз, К. Ли (1995). «Вычислительные возможности рекуррентных нейронных сетей NARX» . Транзакции IEEE о системах, человеке и кибернетике. Часть B: Кибернетика . 27 (2): 208–15. CiteSeerX 10.1.1.48.7468 . дои : 10.1109/3477.558801 . ПМИД 18255858 .
- ^ Мильянович, Милош (февраль – март 2012 г.). «Сравнительный анализ нейронных сетей с рекуррентным и конечным импульсным откликом в прогнозировании временных рядов» (PDF) . Индийский журнал компьютеров и техники . 3 (1).
- ^ Ходассман, Шири; Меир, Юваль; Кисос, Карин; Бен-Ноам, Итамар; Тугендхафт, Яэль; Голденталь, Амир; Варди, Рони; Кантер, Идо (29 сентября 2022 г.). «Механизм подавления нейронов, вдохновленный мозгом, обеспечивает надежную идентификацию последовательностей» . Научные отчеты . 12 (1): 16003. arXiv : 2203.13028 . Бибкод : 2022NatSR..1216003H . дои : 10.1038/s41598-022-20337-x . ISSN 2045-2322 . ПМЦ 9523036 . ПМИД 36175466 .
- ^ Мец, Кейд (18 мая 2016 г.). «Google создала собственные чипы для работы своих ботов с искусственным интеллектом» . Проводной .
- ^ Майер, Герман; Гомес, Фаустино Дж.; Виерстра, Дэн; Надь, Иштван; Нолл, Алоис; Шмидхубер, Юрген (октябрь 2006 г.). «Система для роботизированной кардиохирургии, которая учится завязывать узлы с помощью рекуррентных нейронных сетей». 2006 Международная конференция IEEE/RSJ по интеллектуальным роботам и системам . стр. 100-1 543–548. CiteSeerX 10.1.1.218.3399 . дои : 10.1109/IROS.2006.282190 . ISBN 978-1-4244-0258-8 . S2CID 12284900 .
- ^ Виерстра, Даан; Шмидхубер, Юрген; Гомес, Фаустино Дж. (2005). «Эволино: гибридная нейроэволюция/оптимальный линейный поиск для последовательного обучения» . Материалы 19-й Международной совместной конференции по искусственному интеллекту (IJCAI), Эдинбург . стр. 853–8. OCLC 62330637 .
- ^ Петнехази, Габор (01 января 2019 г.). «Рекуррентные нейронные сети для прогнозирования временных рядов». arXiv : 1901.00069 [ cs.LG ].
- ^ Хевамалагэ, Хансика; Бергмейр, Кристоф; Бандара, Касун (2020). «Рекуррентные нейронные сети для прогнозирования временных рядов: текущий статус и будущие направления». Международный журнал прогнозирования . 37 : 388–427. arXiv : 1909.00590 . doi : 10.1016/j.ijforecast.2020.06.008 . S2CID 202540863 .
- ^ Грейвс, Алекс; Шмидхубер, Юрген (2005). «Кадровая классификация фонем с помощью двунаправленного LSTM и других архитектур нейронных сетей». Нейронные сети . 18 (5–6): 602–610. CiteSeerX 10.1.1.331.5800 . дои : 10.1016/j.neunet.2005.06.042 . ПМИД 16112549 . S2CID 1856462 .
- ^ Грейвс, Алекс; Мохамед, Абдель-Рахман; Хинтон, Джеффри Э. (2013). «Распознавание речи с помощью глубоких рекуррентных нейронных сетей». Международная конференция IEEE 2013 по акустике, речи и обработке сигналов . стр. 6645–9. arXiv : 1303.5778 . Бибкод : 2013arXiv1303.5778G . дои : 10.1109/ICASSP.2013.6638947 . ISBN 978-1-4799-0356-6 . S2CID 206741496 .
- ^ Чанг, Эдвард Ф.; Чартье, Джош; Ануманчипалли, Гопала К. (24 апреля 2019 г.). «Синтез речи на основе нейронного декодирования произнесенных предложений» . Природа . 568 (7753): 493–8. Бибкод : 2019Natur.568..493A . дои : 10.1038/s41586-019-1119-1 . ISSN 1476-4687 . ПМЦ 9714519 . ПМИД 31019317 . S2CID 129946122 .
- ^ Моисей, Дэвид А.; Мецгер, Шон Л.; Лю, Джесси Р.; Ануманчипалли, Гопала К.; Макин, Джозеф Г.; Сунь, Пэнфэй Ф.; Чартье, Джош; Догерти, Максимилиан Э.; Лю, Патрисия М.; Абрамс, Гэри М.; Ту-Чан, Аделин; Гангулы, Карунеш; Чанг, Эдвард Ф. (15 июля 2021 г.). «Нейропротез для декодирования речи у парализованного человека с анартрией» . Медицинский журнал Новой Англии . 385 (3): 217–227. дои : 10.1056/NEJMoa2027540 . ПМЦ 8972947 . ПМИД 34260835 .
- ^ Малхотра, Панкадж; Виг, Лавкеш; Шрофф, Гаутам; Агарвал, Пунит (апрель 2015 г.). «Сети долговременной памяти для обнаружения аномалий во временных рядах» . Европейский симпозиум по искусственным нейронным сетям, вычислительному интеллекту и машинному обучению – ESANN 2015 . Чако. стр. 89–94. ISBN 978-2-87587-015-5 .
- ^ «Документы с кодом — DeepHS-HDRVideo: глубокая высокоскоростная реконструкция видео с широким динамическим диапазоном» . paperswithcode.com . Проверено 13 октября 2022 г.
- ^ Герс, Феликс А.; Шраудольф, Никол Н.; Шмидхубер, Юрген (2002). «Изучение точного времени с помощью рекуррентных сетей LSTM» (PDF) . Журнал исследований машинного обучения . 3 : 115–143.
- ^ Эк, Дуглас; Шмидхубер, Юрген (28 августа 2002 г.). «Изучение долгосрочной структуры блюза». Искусственные нейронные сети — ICANN 2002 . Конспекты лекций по информатике. Том. 2415. Берлин, Гейдельберг: Springer. стр. 284–289. CiteSeerX 10.1.1.116.3620 . дои : 10.1007/3-540-46084-5_47 . ISBN 978-3-540-46084-8 .
- ^ Шмидхубер, Юрген; Герс, Феликс А.; Эк, Дуглас (2002). «Изучение нерегулярных языков: сравнение простых рекуррентных сетей и LSTM». Нейронные вычисления . 14 (9): 2039–2041. CiteSeerX 10.1.1.11.7369 . дои : 10.1162/089976602320263980 . ПМИД 12184841 . S2CID 30459046 .
- ^ Перес-Ортис, Хуан Антонио; Герс, Феликс А.; Эк, Дуглас; Шмидхубер, Юрген (2003). «Фильтры Калмана улучшают производительность сети LSTM в задачах, неразрешимых традиционными рекуррентными сетями». Нейронные сети . 16 (2): 241–250. CiteSeerX 10.1.1.381.1992 . дои : 10.1016/s0893-6080(02)00219-8 . ПМИД 12628609 .
- ^ Грейвс, Алекс; Шмидхубер, Юрген (2009). «Офлайн-распознавание рукописного текста с помощью многомерных рекуррентных нейронных сетей» (PDF) . Достижения в области нейронных систем обработки информации . Том. 22, НИПС'22. МТИ Пресс. стр. 545–552.
- ^ Грейвс, Алекс; Фернандес, Сантьяго; Ливицкий, Маркус; Бунке, Хорст; Шмидхубер, Юрген (2007). «Неограниченное онлайн-распознавание рукописного текста с помощью рекуррентных нейронных сетей» . Материалы 20-й Международной конференции по нейронным системам обработки информации . Карран Ассошиэйтс. стр. 577–584. ISBN 978-1-60560-352-0 .
- ^ Баккуш, Моэз; Мамалет, Франк; Вольф, Кристиан; Гарсия, Кристоф; Баскурт, Атилла (2011). «Последовательное глубокое обучение для распознавания действий человека». В Салахе Альберт Али; Лепри, Бруно (ред.). Понимание человеческого поведения . Конспекты лекций по информатике. Том. 7065. Амстердам, Нидерланды: Springer. стр. 29–39. дои : 10.1007/978-3-642-25446-8_4 . ISBN 978-3-642-25445-1 .
- ^ Хохрейтер, Зепп; Хойзель, Мартин; Обермайер, Клаус (2007). «Быстрое обнаружение гомологии белков на основе моделей без выравнивания» . Биоинформатика . 23 (14): 1728–1736. doi : 10.1093/биоинформатика/btm247 . ПМИД 17488755 .
- ^ Тиреу, Триас; Речко, Мартин (июль 2007 г.). «Двунаправленные сети долговременной краткосрочной памяти для прогнозирования субклеточной локализации эукариотических белков». Транзакции IEEE/ACM по вычислительной биологии и биоинформатике . 4 (3): 441–446. дои : 10.1109/tcbb.2007.1015 . ПМИД 17666763 . S2CID 11787259 .
- ^ Налог, Ник; Веренич, Илья; Ла Роза, Марчелло; Дюма, Марлон (2017). «Прогнозирующий мониторинг бизнес-процессов с помощью нейронных сетей LSTM». Инженерия передовых информационных систем . Конспекты лекций по информатике. Том. 10253. стр. 477–492. arXiv : 1612.02130 . дои : 10.1007/978-3-319-59536-8_30 . ISBN 978-3-319-59535-1 . S2CID 2192354 .
- ^ Чой, Эдвард; Бахадори, Мохаммад Таха; Шуец, Энди; Стюарт, Уолтер Ф.; Сунь, Джимэн (2016). «Доктор ИИ: прогнозирование клинических событий с помощью рекуррентных нейронных сетей» . Материалы семинара и конференции JMLR . 56 : 301–318. arXiv : 1511.05942 . Бибкод : 2015arXiv151105942C . ПМК 5341604 . ПМИД 28286600 .
- ^ «Искусственный интеллект помогает ускорить прогресс в направлении эффективных термоядерных реакций» . Принстонский университет . Проверено 12 июня 2023 г.
Дальнейшее чтение
[ редактировать ]- Мандич, Данило П.; Чемберс, Джонатон А. (2001). Рекуррентные нейронные сети для прогнозирования: алгоритмы обучения, архитектура и стабильность . Уайли. ISBN 978-0-471-49517-8 .
- Гроссберг, Стивен (22 февраля 2013 г.). «Рекуррентные нейронные сети» . Схоларпедия . 8 (2): 1888. Бибкод : 2013SchpJ...8.1888G . doi : 10.4249/scholarpedia.1888 . ISSN 1941-6016 .
- Рекуррентные нейронные сети с более чем 60 статьями RNN Юргена Шмидхубера группы в Институте исследований искусственного интеллекта Далле Молле.
Дифференцируемые вычисления |
|---|
| Базы данных органов управления : Национальные |
|---|