Центральный процессор


Центральный процессор ( ЦП ), также называемый центральным процессором , основным процессором или просто процессором , является наиболее важным процессором в данном компьютере . [1] [2] Его электронная схема выполняет инструкции , компьютерной программы такие как арифметические , логические, управляющие операции и операции ввода/вывода (I/O). [3] [4] [5] Эта роль контрастирует с ролью внешних компонентов, таких как основная память и схемы ввода-вывода. [6] и специализированные сопроцессоры , такие как графические процессоры (GPU).
Форма, конструкция и реализация процессоров со временем изменились, но их основные принципы работы остались практически неизменными. [7] Основные компоненты ЦП включают арифметико-логическое устройство (АЛУ), выполняющее арифметические и логические операции , регистры процессора , которые передают операнды в АЛУ и сохраняют результаты операций АЛУ, а также блок управления , который организует выборку (из памяти) . декодирование и выполнение (инструкций) путем управления согласованными операциями АЛУ, регистров и других компонентов. В современных процессорах большая часть полупроводниковой памяти отводится кэшам и параллелизму на уровне команд для повышения производительности, а также режимам процессора для поддержки операционных систем и виртуализации .
Большинство современных ЦП реализованы на с интегральными схемами (ИС) микропроцессорах , с одним или несколькими ЦП на одном кристалле ИС. Микропроцессорные микросхемы с несколькими процессорами называются многоядерными процессорами . [8] Отдельные физические процессоры, называемые ядрами процессора , также могут быть многопоточными для поддержки многопоточности на уровне процессора. [9]
Микросхема, содержащая ЦП, может также содержать память , периферийные интерфейсы и другие компоненты компьютера; [10] такие интегрированные устройства по-разному называются микроконтроллерами или системами на кристалле (SoC).
История
[ редактировать ]
Ранние компьютеры, такие как ENIAC, нужно было физически перемонтировать для выполнения различных задач, из-за чего эти машины стали называть «компьютерами с фиксированной программой». [11] Термин «центральный процессор» используется еще с 1955 года. [12] [13] Поскольку термин «ЦП» обычно определяется как устройство для выполнения программного обеспечения (компьютерной программы), самые ранние устройства, которые можно было бы по праву назвать ЦП, появились с появлением компьютера с хранимой программой .
Идея компьютера с хранимой программой уже присутствовала в проекте Дж. Преспера Эккерта и Джона Уильяма Мочли , ENIAC но первоначально от нее отказались, чтобы ENIAC можно было закончить раньше. [14] 30 июня 1945 года, еще до создания ENIAC, математик Джон фон Нейман распространил статью, озаглавленную « Первый проект отчета о EDVAC» . Это был набросок компьютера с хранимой программой, который в конечном итоге будет завершен в августе 1949 года. [15] EDVAC был разработан для выполнения определенного количества инструкций (или операций) различных типов. Примечательно, что программы, написанные для EDVAC, должны были храниться в высокоскоростной памяти компьютера, а не определяться физической проводкой компьютера. [16] Это позволило преодолеть серьезное ограничение ENIAC, которое требовало значительного времени и усилий для перенастройки компьютера для выполнения новой задачи. [17] Согласно замыслу фон Неймана, программу, которую запускал EDVAC, можно было изменить, просто изменив содержимое памяти. EDVAC не был первым компьютером с хранимой программой; Manchester Baby , небольшой экспериментальный компьютер с хранимой программой, запустил свою первую программу 21 июня 1948 года. [18] и Manchester Mark 1 выполнил свою первую программу в ночь с 16 на 17 июня 1949 года. [19]
Ранние процессоры представляли собой нестандартную конструкцию, используемую как часть более крупного, а иногда и уникального компьютера. [20] Однако этот метод проектирования специальных процессоров для конкретного приложения во многом уступил место разработке многоцелевых процессоров, производимых в больших количествах. Эта стандартизация началась в эпоху дискретных транзисторных мэйнфреймов и миникомпьютеров и быстро ускорилась с популяризацией интегральных схем (ИС). ИС позволили проектировать и производить все более сложные процессоры с допусками порядка нанометров . [21] Как миниатюризация, так и стандартизация процессоров расширили присутствие цифровых устройств в современной жизни, выйдя далеко за рамки ограниченного применения специализированных вычислительных машин. Современные микропроцессоры появляются в электронных устройствах, начиная от автомобилей [22] на мобильные телефоны, [23] а иногда даже в игрушках. [24] [25]
Хотя фон Нейману чаще всего приписывают разработку компьютера с хранимой программой из-за его конструкции EDVAC, и эта конструкция стала известна как архитектура фон Неймана , другие до него, такие как Конрад Цузе , предлагали и реализовывали аналогичные идеи. [26] Так называемая Гарвардская архитектура Harvard Mark I , которая была завершена до EDVAC, [27] [28] также использовал конструкцию с сохраненной программой с использованием перфоленты, а не электронной памяти. [29] Ключевое различие между архитектурой фон Неймана и Гарвардской архитектурой заключается в том, что последняя разделяет хранение и обработку инструкций и данных ЦП, тогда как первая использует одно и то же пространство памяти для обеих. [30] Большинство современных ЦП в основном имеют дизайн фон Неймана, но встречаются и ЦП с гарвардской архитектурой, особенно во встроенных приложениях; например, микроконтроллеры Atmel AVR представляют собой процессоры с гарвардской архитектурой. [31]
реле и электронные лампы (термоэлектронные трубки); В качестве переключающих элементов обычно использовались [32] [33] полезный компьютер требует тысяч или десятков тысяч коммутационных устройств. Общая скорость системы зависит от скорости коммутаторов. Ламповые компьютеры, такие как EDVAC, имели тенденцию работать в среднем восемь часов между сбоями, тогда как релейные компьютеры, такие как более медленный, но более ранний Harvard Mark I, выходили из строя очень редко. [13] В конце концов, ламповые процессоры стали доминировать, поскольку значительное преимущество в скорости обычно перевешивало проблемы с надежностью. Большинство из этих ранних синхронных процессоров работали с низкой тактовой частотой по сравнению с современными микроэлектронными разработками. Частоты тактового сигнала в диапазоне от 100 кГц до 4 МГц были очень распространены в то время и во многом ограничивались скоростью переключающих устройств, с которыми они были построены. [34]
Транзисторные процессоры
[ редактировать ]
Сложность конструкции процессоров возрастала по мере того, как различные технологии облегчали создание меньших по размеру и более надежных электронных устройств. Первое такое улучшение произошло с появлением транзистора . Транзисторные процессоры в 1950-х и 1960-х годах больше не приходилось изготавливать из громоздких, ненадежных и хрупких переключающих элементов, таких как электронные лампы и реле . [35] Благодаря этому усовершенствованию более сложные и надежные процессоры были построены на одной или нескольких печатных платах, содержащих дискретные (индивидуальные) компоненты.
В 1964 году IBM представила свою компьютерную архитектуру IBM System/360 , которая использовалась в серии компьютеров, способных запускать одни и те же программы с разной скоростью и производительностью. [36] Это было важно в то время, когда большинство электронных компьютеров были несовместимы друг с другом, даже если они производились одним и тем же производителем. Чтобы облегчить это улучшение, IBM использовала концепцию микропрограммы (часто называемой «микрокодом»), которая до сих пор широко используется в современных процессорах. [37] Архитектура System/360 была настолько популярна, что на протяжении десятилетий доминировала на рынке мейнфреймов и оставила наследие, которое продолжают аналогичные современные компьютеры, такие как IBM zSeries . [38] [39] В 1965 году компания Digital Equipment Corporation (DEC) представила еще один влиятельный компьютер, ориентированный на научные и исследовательские рынки, — PDP-8 . [40]

Компьютеры на основе транзисторов имели несколько явных преимуществ перед своими предшественниками. Помимо повышения надежности и снижения энергопотребления, транзисторы также позволяли процессорам работать на гораздо более высоких скоростях из-за короткого времени переключения транзистора по сравнению с лампой или реле. [41] Повышенная надежность и резко возросшее быстродействие переключающих элементов, которые к этому времени представляли собой почти исключительно транзисторы; В этот период можно было легко получить тактовую частоту процессора в десятки мегагерц. [42] новые высокопроизводительные конструкции, такие как с одной командой и несколькими данными (SIMD) . векторные процессоры Кроме того, в то время как дискретные транзисторы и процессоры IC интенсивно использовались, начали появляться [43] Эти ранние экспериментальные разработки позже положили начало эпохе специализированных суперкомпьютеров, подобных тем, которые были созданы Cray Inc и Fujitsu Ltd. [43]
Малые интеграционные процессоры
[ редактировать ]
В этот период был разработан метод производства множества взаимосвязанных транзисторов в компактном пространстве. Интегральная схема (ИС) позволяла изготавливать большое количество транзисторов на одном или « полупроводниковом кристалле чипе». только самые простые неспециализированные цифровые схемы, такие как вентили ИЛИ-НЕ . Поначалу в микросхемы миниатюризировались [44] Процессоры, основанные на этих микросхемах «строительных блоков», обычно называются устройствами «малой интеграции» (SSI). Микросхемы SSI, подобные тем, которые используются в навигационном компьютере Apollo , обычно содержали до нескольких десятков транзисторов. Чтобы построить целый процессор из микросхем SSI, требовались тысячи отдельных микросхем, но при этом они потребляли гораздо меньше места и энергии, чем более ранние конструкции дискретных транзисторов. [45]
В системе IBM System/370 , последовавшей за System/360, использовались микросхемы SSI, а не Solid Logic Technology . модули дискретных транзисторов [46] [47] компании DEC PDP-8 /I и KI10 PDP-10 также перешли с отдельных транзисторов, используемых в PDP-8 и PDP-10, на микросхемы SSI. [48] и их чрезвычайно популярная линейка PDP-11 изначально была построена на микросхемах SSI, но в конечном итоге была реализована с использованием компонентов LSI, когда они стали практичными.
Крупномасштабные интеграционные процессоры
[ редактировать ]Ли Бойсел опубликовал влиятельные статьи, в том числе «манифест» 1967 года, в котором описывалось, как построить эквивалент 32-битного мэйнфрейма из относительно небольшого количества крупномасштабных интегральных схем (LSI). [49] [50] Единственный способ создать чипы LSI, которые представляют собой чипы с сотней и более вентилей, заключался в их создании с использованием металл-оксид-полупроводник (МОП) процесса производства полупроводников (либо логика PMOS , логика NMOS или логика CMOS ). Однако некоторые компании продолжали создавать процессоры на основе микросхем биполярной транзисторно-транзисторной логики (TTL), поскольку транзисторы с биполярным переходом были быстрее, чем МОП-чипы, вплоть до 1970-х годов (некоторые компании, такие как Datapoint, продолжали создавать процессоры на основе TTL-чипов до начала 1970-х годов). 1980-е годы). [50] В 1960-х годах МОП-ИС были медленнее и первоначально считались полезными только в приложениях, требующих малой мощности. [51] [52] После разработки с кремниевым затвором из Fairchild Semiconductor в 1968 году технологии МОП Федерико Фаггином МОП-ИС в значительной степени заменили биполярную ТТЛ в качестве стандартной технологии микросхем в начале 1970-х годов. [53]
По мере развития микроэлектронных технологий на микросхемах размещалось все большее количество транзисторов, что уменьшало количество отдельных микросхем, необходимых для полноценного ЦП. Микросхемы MSI и LSI увеличили количество транзисторов до сотен, а затем и до тысяч. К 1968 году количество микросхем, необходимых для создания полноценного процессора, сократилось до 24 микросхем восьми различных типов, каждая из которых содержала примерно 1000 МОП-транзисторов. [54] В отличие от своих предшественников SSI и MSI, первая реализация LSI PDP-11 содержала процессор, состоящий всего из четырех интегральных схем LSI. [55]
Микропроцессоры
[ редактировать ]


С тех пор, как микропроцессоры были впервые представлены, они почти полностью вытеснили все другие методы реализации центральных процессоров. Первым коммерчески доступным микропроцессором, выпущенным в 1971 году, был Intel 4004 , а первым широко используемым микропроцессором, выпущенным в 1974 году, был Intel 8080 . Производители мэйнфреймов и миникомпьютеров того времени запустили собственные программы разработки микросхем для модернизации своих старых компьютерных архитектур и в конечном итоге создали микропроцессоры, совместимые с набором команд , которые были обратно совместимы со старым аппаратным и программным обеспечением. В сочетании с появлением и возможным успехом повсеместного распространения персональных компьютеров термин «ЦП» теперь применяется почти исключительно [а] к микропроцессорам. Несколько процессоров (обозначаются ядрами ) могут быть объединены в один процессорный чип. [56]
Предыдущие поколения процессоров были реализованы в виде дискретных компонентов и множества малых интегральных схем (ИС) на одной или нескольких печатных платах. [57] С другой стороны, микропроцессоры представляют собой ЦП, изготовленные на очень небольшом количестве микросхем; обычно только один. [58] Общий меньший размер ЦП в результате реализации на одном кристалле означает более быстрое время переключения из-за физических факторов, таких как уменьшение паразитной емкости затвора . [59] [60] Это позволило синхронным микропроцессорам иметь тактовую частоту от десятков мегагерц до нескольких гигагерц. Кроме того, возможность создавать на микросхемах чрезвычайно маленькие транзисторы во много раз увеличила сложность и количество транзисторов в одном процессоре. Эта широко наблюдаемая тенденция описывается законом Мура , который оказался достаточно точным предсказателем роста сложности ЦП (и других ИС) до 2016 года. [61] [62]
Хотя сложность, размер, конструкция и общая форма процессоров сильно изменились с 1950 года, [63] базовый дизайн и функции практически не изменились. Почти все распространенные сегодня процессоры можно очень точно описать как машины с хранимой программой фон Неймана. [64] [б] Поскольку закон Мура больше не действует, возникли опасения по поводу ограничений технологии транзисторов на интегральных схемах. Чрезвычайная миниатюризация электронных затворов приводит к тому, что эффекты таких явлений, как электромиграция и подпороговая утечка, становятся гораздо более значительными. [66] [67] Эти новые проблемы являются одними из многих факторов, побуждающих исследователей исследовать новые методы вычислений, такие как квантовый компьютер , а также расширять использование параллелизма и других методов, которые расширяют полезность классической модели фон Неймана.
Операция
[ редактировать ]Основная операция большинства процессоров, независимо от их физической формы, заключается в выполнении последовательности сохраненных инструкций , называемой программой. Инструкции, которые необходимо выполнить, хранятся в некоторой компьютерной памяти . Почти все процессоры в своей работе выполняют этапы выборки, декодирования и выполнения, которые вместе называются циклом команд .
После выполнения инструкции весь процесс повторяется, при этом следующий цикл инструкции обычно выбирает следующую по порядку инструкцию из-за увеличенного значения в программном счетчике . Если была выполнена инструкция перехода, счетчик программы будет изменен и будет содержать адрес инструкции, к которой был выполнен переход, и выполнение программы продолжится обычным образом. В более сложных процессорах несколько инструкций могут быть выбраны, декодированы и выполнены одновременно. В этом разделе описывается то, что обычно называют « классическим RISC-конвейером », который довольно распространен среди простых процессоров, используемых во многих электронных устройствах (часто называемых микроконтроллерами). Он в значительной степени игнорирует важную роль кэша ЦП и, следовательно, этапа доступа к конвейеру.
Некоторые инструкции манипулируют программным счетчиком, а не непосредственно выдают данные результата; такие инструкции обычно называются «переходами» и облегчают поведение программы, такое как циклы , условное выполнение программы (посредством использования условного перехода) и существование функций . [с] В некоторых процессорах некоторые другие инструкции изменяют состояние битов в регистре «флагов» . Эти флаги можно использовать для влияния на поведение программы, поскольку они часто указывают на результат различных операций. Например, в таких процессорах команда «сравнения» оценивает два значения и устанавливает или очищает биты в регистре флагов, чтобы указать, какое из них больше или равны ли они; один из этих флагов затем может быть использован последующей инструкцией перехода для определения хода выполнения программы.
Принести
[ редактировать ]Выборка включает в себя извлечение инструкции (которая представлена числом или последовательностью чисел) из памяти программы. Местоположение инструкции (адрес) в памяти программы определяется программным счетчиком называется «указателем инструкций» (ПК; в микропроцессорах Intel x86 ), который хранит число, идентифицирующее адрес следующей команды, которую нужно выбрать. После выборки инструкции длина PC увеличивается на длину инструкции, чтобы она содержала адрес следующей инструкции в последовательности. [д] Часто команду, которую нужно извлечь, приходится извлекать из относительно медленной памяти, что приводит к остановке ЦП в ожидании возврата инструкции. В современных процессорах эта проблема в основном решается с помощью кэшей и конвейерной архитектуры (см. ниже).
Декодировать
[ редактировать ]Инструкция, которую ЦП извлекает из памяти, определяет, что будет делать ЦП. На этапе декодирования, выполняемом схемой двоичного декодера, известной как декодер инструкций , инструкция преобразуется в сигналы, которые управляют другими частями ЦП.
Способ интерпретации инструкции определяется архитектурой набора команд ЦП (ISA). [и] Часто одна группа битов (то есть «поле») внутри инструкции, называемая кодом операции, указывает, какую операцию следует выполнить, в то время как остальные поля обычно предоставляют дополнительную информацию, необходимую для операции, например операнды. Эти операнды могут быть указаны как постоянное значение (называемое непосредственным значением) или как местоположение значения, которое может быть регистром процессора или адресом памяти, в зависимости от определенного режима адресации .
В некоторых конструкциях ЦП декодер команд реализован как проводная неизменяемая схема двоичного декодера. В других случаях микропрограмма используется для перевода инструкций в наборы сигналов конфигурации ЦП, которые применяются последовательно в течение нескольких тактовых импульсов. В некоторых случаях память, в которой хранится микропрограмма, является перезаписываемой, что позволяет изменить способ декодирования инструкций ЦП.
Выполнять
[ редактировать ]После шагов выборки и декодирования выполняется этап выполнения. В зависимости от архитектуры ЦП это может состоять из одного действия или последовательности действий. Во время каждого действия управляющие сигналы электрически включают или отключают различные части ЦП, чтобы они могли выполнить всю или часть желаемой операции. Затем действие завершается, обычно в ответ на тактовый импульс. Очень часто результаты записываются во внутренний регистр ЦП для быстрого доступа к ним последующих инструкций. В других случаях результаты могут быть записаны в более медленную, но менее дорогую и большую оперативную память .
Например, если должна быть выполнена инструкция, выполняющая сложение, активируются регистры, содержащие операнды (числа, подлежащие суммированию), а также части арифметико-логического устройства (АЛУ), выполняющие сложение. При возникновении тактового импульса операнды поступают из регистров-источников в АЛУ, и на его выходе появляется сумма. При последующих тактовых импульсах другие компоненты включаются (и отключаются) для перемещения вывода (суммы операции) в хранилище (например, регистр или память). Если полученная сумма слишком велика (т. е. превышает размер выходного слова АЛУ), будет установлен флаг арифметического переполнения, влияющий на следующую операцию.
Структура и реализация
[ редактировать ]
В схему ЦП встроен набор основных операций, которые он может выполнять, называемый набором команд . Такие операции могут включать, например, сложение или вычитание двух чисел, сравнение двух чисел или переход к другой части программы. Каждая инструкция представлена уникальной комбинацией битов машинного языка , известной как код операции . При обработке инструкции ЦП декодирует код операции (через двоичный декодер ) в управляющие сигналы, которые управляют поведением ЦП. Полная инструкция машинного языка состоит из кода операции и, во многих случаях, дополнительных битов, определяющих аргументы операции (например, числа, подлежащие суммированию в случае операции сложения). По шкале сложности программа на машинном языке представляет собой набор инструкций машинного языка, которые выполняет ЦП.
Фактическая математическая операция для каждой инструкции выполняется комбинационной логической схемой внутри процессора ЦП, известной как арифметико-логическое устройство или АЛУ. Как правило, ЦП выполняет инструкцию, извлекая ее из памяти, используя свое АЛУ для выполнения операции, а затем сохраняя результат в памяти. Помимо инструкций для целочисленной математики и логических операций, существуют различные другие машинные инструкции, например, для загрузки данных из памяти и их обратного сохранения, операций ветвления и математических операций над числами с плавающей запятой, выполняемых блоком операций с плавающей запятой ЦП (FPU). ). [68]
Блок управления
[ редактировать ]Блок управления (CU) — это компонент ЦП, который управляет работой процессора. Он сообщает памяти компьютера, арифметическому и логическому устройству, а также устройствам ввода и вывода, как реагировать на инструкции, отправленные процессору.
Он управляет работой других блоков, обеспечивая сигналы синхронизации и управления. Большинство компьютерных ресурсов управляются CU. Он направляет поток данных между процессором и другими устройствами. Джон фон Нейман включил блок управления как часть архитектуры фон Неймана . В современных компьютерных конструкциях блок управления обычно является внутренней частью ЦП, его общая роль и работа не изменились с момента его появления. [69]
Арифметико-логический блок
[ редактировать ]
Арифметико-логическое устройство (АЛУ) — это цифровая схема внутри процессора, выполняющая целочисленные арифметические и побитовые логические операции. Входными данными для АЛУ являются слова данных, над которыми нужно работать (называемые операндами ), информация о состоянии предыдущих операций и код от блока управления, указывающий, какую операцию выполнить. В зависимости от выполняемой инструкции операнды могут поступать из внутренних регистров ЦП , внешней памяти или констант, генерируемых самим АЛУ.
Когда все входные сигналы стабилизировались и прошли через схему АЛУ, результат выполненной операции появляется на выходах АЛУ. Результат состоит как из слова данных, которое может храниться в регистре или памяти, так и из информации о состоянии, которая обычно хранится в специальном внутреннем регистре ЦП, зарезервированном для этой цели.
Современные процессоры обычно содержат более одного ALU для повышения производительности.
Блок генерации адреса
[ редактировать ]Блок генерации адреса (AGU), иногда также называемый блоком вычисления адреса (ACU), [70] — это исполнительный блок внутри ЦП, который вычисляет адреса, используемые ЦП для доступа к основной памяти . количество циклов ЦП, необходимых для выполнения различных машинных инструкций Благодаря тому, что вычисления адреса выполняются отдельной схемой, которая работает параллельно с остальной частью ЦП, можно уменьшить , что приведет к повышению производительности.
При выполнении различных операций процессорам необходимо вычислять адреса памяти, необходимые для извлечения данных из памяти; например, позиции элементов массива в памяти должны быть вычислены, прежде чем ЦП сможет извлечь данные из реальных ячеек памяти. Эти вычисления по генерации адреса включают в себя различные арифметические операции с целыми числами , такие как сложение, вычитание, операции по модулю или сдвиг битов . Часто вычисление адреса памяти включает в себя более одной машинной инструкции общего назначения, которые не обязательно декодируются и выполняются быстро. Путем включения AGU в конструкцию ЦП, а также введения специализированных инструкций, использующих AGU, различные вычисления по генерации адреса могут быть разгружены от остальной части ЦП и часто могут выполняться быстро за один цикл ЦП.
Возможности AGU зависят от конкретного процессора и его архитектуры . Таким образом, некоторые AGU реализуют и предоставляют больше операций вычисления адреса, а некоторые также включают более сложные специализированные инструкции, которые могут работать с несколькими операндами одновременно. Некоторые архитектуры ЦП включают несколько AGU, поэтому одновременно может выполняться более одной операции вычисления адреса, что приводит к дальнейшему повышению производительности благодаря суперскалярной природе усовершенствованных конструкций ЦП. Например, Intel включает несколько AGU в свои Sandy Bridge и Haswell микроархитектуры , которые увеличивают пропускную способность подсистемы памяти ЦП, позволяя параллельно выполнять несколько инструкций доступа к памяти.
Блок управления памятью (MMU)
[ редактировать ]Многие микропроцессоры (в смартфонах и настольных компьютерах, ноутбуках, серверных компьютерах) имеют блок управления памятью, преобразующий логические адреса в адреса физического ОЗУ, обеспечивающий защиту памяти и возможности подкачки , полезные для виртуальной памяти . Более простые процессоры, особенно микроконтроллеры , обычно не содержат MMU.
Кэш
[ редактировать ]процессора Кэш [71] — это аппаратный кэш, используемый центральным процессором (ЦП) компьютера для снижения средних затрат (времени или энергии) на доступ к данным из основной памяти . Кэш — это меньшая по размеру и более быстрая память, расположенная ближе к ядру процессора , в которой хранятся копии данных из часто используемых ячеек основной памяти . Большинство процессоров имеют различные независимые кэши, включая кэши инструкций и данных , где кэш данных обычно организован в виде иерархии большего количества уровней кэша (L1, L2, L3, L4 и т. д.).
Все современные (быстрые) процессоры (за некоторыми специализированными исключениями) [ф] ) имеют несколько уровней кэша ЦП. Первые процессоры, использовавшие кеш, имели только один уровень кеша; в отличие от более поздних кэшей уровня 1, он не был разделен на L1d (для данных) и L1i (для инструкций). Почти все современные процессоры с кэшем имеют разделенный кэш L1. У них также есть кэши L2, а для более крупных процессоров — кэши L3. Кэш L2 обычно не разделен и действует как общий репозиторий для уже разделенного кеша L1. Каждое ядро многоядерного процессора имеет выделенный кэш L2, который обычно не используется совместно ядрами. Кэш L3 и кэши более высокого уровня распределяются между ядрами и не разделяются. Кэш L4 в настоящее время встречается редко и обычно находится в динамической памяти с произвольным доступом (DRAM), а не в статической памяти с произвольным доступом (SRAM), на отдельном кристалле или кристалле. Исторически так же было и с L1, хотя более крупные чипы позволяли интегрировать его и вообще все уровни кэша, за возможным исключением последнего уровня. Каждый дополнительный уровень кэша имеет тенденцию быть больше и оптимизирован по-разному.
Существуют и другие типы кешей (которые не учитываются в «размере кеша» наиболее важных кешей, упомянутых выше), например, резервный буфер трансляции (TLB), который является частью блока управления памятью (MMU), который имеется у большинства процессоров.
Размер кэшей обычно определяется степенями двойки: 2, 8, 16 и т. д. КиБ или МиБ (для больших размеров, не относящихся к L1), хотя IBM z13 имеет кэш инструкций L1 объемом 96 КиБ. [72]
Тактовая частота
[ редактировать ]Большинство процессоров представляют собой синхронные схемы , что означает, что они используют тактовый сигнал для управления своими последовательными операциями. Тактовый сигнал генерируется внешним генератором , который каждую секунду генерирует постоянное количество импульсов в форме периодической прямоугольной волны . Частота тактовых импульсов определяет скорость, с которой ЦП выполняет инструкции, и, следовательно, чем быстрее такт, тем больше инструкций ЦП будет выполнять каждую секунду.
Чтобы обеспечить правильную работу ЦП, период тактирования превышает максимальное время, необходимое для распространения (перемещения) всех сигналов через ЦП. Установив период тактового сигнала на значение, значительно превышающее задержку распространения в наихудшем случае , можно спроектировать весь ЦП и способ его перемещения данных по «краям» нарастающего и падающего тактового сигнала. Преимущество этого заключается в значительном упрощении ЦП как с точки зрения дизайна, так и с точки зрения количества компонентов. Однако у него также есть тот недостаток, что весь ЦП должен ожидать обработки своих самых медленных элементов, хотя некоторые его части работают намного быстрее. Это ограничение в значительной степени компенсируется различными методами увеличения параллелизма ЦП (см. Ниже).
Однако одни лишь архитектурные улучшения не решают всех недостатков глобально синхронных процессоров. Например, тактовый сигнал подвержен задержкам любого другого электрического сигнала. Более высокие тактовые частоты во все более сложных процессорах затрудняют поддержание синфазности (синхронизации) тактового сигнала во всем устройстве. Это привело к тому, что многие современные процессоры требуют подачи нескольких одинаковых тактовых сигналов, чтобы избежать значительной задержки одного сигнала, которая может привести к неисправности процессора. Еще одной серьезной проблемой, связанной с резким увеличением тактовой частоты, является количество тепла, рассеиваемого процессором . Постоянно меняющиеся часы заставляют многие компоненты переключаться независимо от того, используются ли они в данный момент. В общем, переключающийся компонент потребляет больше энергии, чем элемент в статическом состоянии. Таким образом, по мере увеличения тактовой частоты растет и энергопотребление, в результате чего процессору требуется больше рассеивания тепла в виде решений для охлаждения процессора .
Один из методов борьбы с переключением ненужных компонентов называется тактовым стробированием , который предполагает отключение тактового сигнала на ненужные компоненты (фактически их отключение). Однако это часто считается трудным для реализации и поэтому не находит широкого применения за пределами конструкций с очень низким энергопотреблением. IBM PowerPC, на базе Одним из примечательных недавних проектов ЦП, в котором используется обширное стробирование тактовой частоты, является Xenon используемый в Xbox 360 ; это снижает требования к питанию Xbox 360. [73]
Безтактовые процессоры
[ редактировать ]Другим методом решения некоторых проблем с глобальным тактовым сигналом является полное удаление тактового сигнала. Хотя удаление глобального тактового сигнала значительно усложняет процесс проектирования во многих отношениях, асинхронные (или безтактовые) конструкции имеют заметные преимущества в энергопотреблении и рассеивании тепла по сравнению с аналогичными синхронными конструкциями. Хотя это и необычно, но целые асинхронные процессоры создаются без использования глобального тактового сигнала. Двумя яркими примерами этого являются ARM совместимый с AMULET, , и MiniMIPS, совместимый с MIPS R3000. [74]
Вместо полного удаления тактового сигнала некоторые конструкции ЦП позволяют определенным частям устройства работать асинхронно, например, используя асинхронные ALU в сочетании с суперскалярной конвейерной обработкой для достижения некоторого повышения производительности арифметических операций. Хотя не совсем ясно, могут ли полностью асинхронные проекты работать на сопоставимом или лучшем уровне, чем их синхронные аналоги, очевидно, что они, по крайней мере, преуспевают в более простых математических операциях. Это, в сочетании с отличными характеристиками энергопотребления и рассеивания тепла, делает их очень подходящими для встраиваемых компьютеров . [75]
Модуль регулятора напряжения
[ редактировать ]Многие современные процессоры имеют встроенный в кристалл модуль управления питанием, который по требованию регулирует подачу напряжения на схему процессора, позволяя поддерживать баланс между производительностью и энергопотреблением.
Целочисленный диапазон
[ редактировать ]Каждый процессор представляет числовые значения определенным образом. Например, некоторые ранние цифровые компьютеры представляли числа в виде знакомой десятичной (по основанию 10) значений системы счисления , а другие использовали более необычные представления, такие как троичная (по основанию три). Почти все современные процессоры представляют числа в двоичной форме, где каждая цифра представлена некоторой двузначной физической величиной, такой как «высокое» или «низкое» напряжение . [г]

С числовым представлением связаны размер и точность целых чисел, которые может представлять ЦП. В случае двоичного ЦП это измеряется количеством битов (значащих цифр двоичного целого числа), которые ЦП может обработать за одну операцию, которую обычно называют размером слова , битовой шириной , шириной пути данных , целочисленной точностью. или целочисленный размер . Целочисленный размер ЦП определяет диапазон целочисленных значений, с которыми он может напрямую работать. [час] Например, 8-битный ЦП может напрямую манипулировать целыми числами, представленными восемью битами, которые имеют диапазон 256 (2 8 ) дискретные целочисленные значения.
Целочисленный диапазон также может влиять на количество ячеек памяти, к которым процессор может напрямую обращаться (адрес — это целое значение, представляющее определенную ячейку памяти). Например, если двоичный процессор использует 32 бита для представления адреса памяти, то он может напрямую адресовать 2. 32 места памяти. Чтобы обойти это ограничение и по ряду других причин, некоторые ЦП используют механизмы (например, переключение банков ), которые позволяют адресовать дополнительную память.
Процессоры с большими размерами слов требуют больше схем и, следовательно, физически больше, стоят дороже и потребляют больше энергии (и, следовательно, выделяют больше тепла). В результате в современных приложениях обычно используются 4- или 8-битные микроконтроллеры меньшего размера , хотя доступны процессоры с гораздо большими размерами слов (например, 16, 32, 64 и даже 128-битные). Однако когда требуется более высокая производительность, преимущества большего размера слова (большие диапазоны данных и адресные пространства) могут перевесить недостатки. ЦП может иметь внутренние пути данных короче размера слова, чтобы уменьшить размер и стоимость. Например, несмотря на то, что IBM System/360 архитектура набора команд представляла собой 32-битный набор команд, модели System/360 Model 30 и Model 40 имели 8-битные пути данных в арифметико-логическом блоке, так что требовалось 32-битное сложение. четыре цикла, по одному на каждые 8 бит операндов, и, хотя набор команд серии Motorola 68000 был 32-битным, у Motorola 68000 и Motorola 68010 были 16-битные пути данных в арифметико-логическом блоке, так что 32-битное сложение потребовало двух циклов.
Чтобы получить некоторые преимущества, предоставляемые как меньшей, так и большей длиной бит, многие наборы команд имеют разную разрядность для целочисленных данных и данных с плавающей запятой, что позволяет процессорам, реализующим этот набор команд, иметь разную разрядность для разных частей устройства. Например, набор инструкций IBM System/360 в основном был 32-битным, но поддерживал 64-битные значения с плавающей запятой , чтобы обеспечить большую точность и диапазон чисел с плавающей запятой. [37] Модель System/360 Model 65 имела 8-битный сумматор для десятичной и двоичной арифметики с фиксированной запятой и 60-битный сумматор для арифметики с плавающей запятой. [76] Многие более поздние конструкции ЦП используют аналогичную смешанную разрядность, особенно когда процессор предназначен для использования общего назначения, где требуется разумный баланс возможностей целых чисел и операций с плавающей запятой.
Параллелизм
[ редактировать ]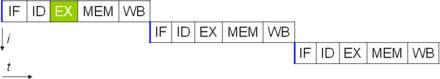
Описание основных операций ЦП, предложенное в предыдущем разделе, описывает простейшую форму, которую может принимать ЦП. Этот тип ЦП, обычно называемый субскалярным , работает и выполняет одну инструкцию с одним или двумя фрагментами данных одновременно, что составляет менее одной инструкции за такт ( IPC < 1 ).
Этот процесс приводит к присущей субскалярным процессорам неэффективности. Поскольку одновременно выполняется только одна инструкция, весь процессор должен дождаться завершения этой инструкции, прежде чем перейти к следующей инструкции. В результате субскалярный ЦП «зависает» на инструкциях, выполнение которых занимает более одного такта. Даже добавление второго исполнительного блока (см. ниже) не сильно повышает производительность; вместо того, чтобы подвешивать один канал, теперь подвешиваются два канала и увеличивается количество неиспользуемых транзисторов. Эта конструкция, в которой исполнительные ресурсы ЦП могут работать только с одной инструкцией за раз, может достигать только скалярной производительности (одна инструкция за такт, IPC = 1 ). Однако производительность почти всегда субскалярная (менее одной инструкции за такт, IPC < 1 ).
Попытки добиться скалярности и повышения производительности привели к появлению множества методологий проектирования, которые заставляют ЦП вести себя менее линейно и более параллельно. Говоря о параллелизме в процессорах, для классификации этих методов проектирования обычно используются два термина:
- параллелизм на уровне инструкций (ILP), целью которого является увеличение скорости выполнения инструкций внутри ЦП (то есть увеличение использования ресурсов выполнения на кристалле);
- параллелизм на уровне задач (TLP), целью которого является увеличение количества потоков или процессов , которые ЦП может выполнять одновременно.
Каждая методология отличается как способами их реализации, так и относительной эффективностью, которую они обеспечивают в увеличении производительности ЦП для приложения. [я]
Параллелизм на уровне инструкций
[ редактировать ]
Один из самых простых способов повышения параллелизма — начать первые шаги выборки и декодирования инструкций до того, как закончится выполнение предыдущей инструкции. Это метод, известный как конвейерная обработка инструкций , и он используется почти во всех современных процессорах общего назначения. Конвейерная обработка позволяет одновременно выполнять несколько инструкций, разбивая путь выполнения на дискретные этапы. Это разделение можно сравнить со сборочной линией, на которой инструкция становится более полной на каждом этапе, пока она не выйдет из конвейера выполнения и не будет удалена.
Однако конвейеризация создает возможность ситуации, когда результат предыдущей операции необходим для завершения следующей операции; состояние, которое часто называют конфликтом зависимости данных. Следовательно, конвейерные процессоры должны проверять подобные условия и при необходимости задерживать часть конвейера. Конвейерный процессор может стать почти скалярным, чему препятствуют только остановки конвейера (инструкция, затрачивающая более одного тактового цикла на этап).

Улучшения в конвейерной обработке инструкций привели к дальнейшему сокращению времени простоя компонентов ЦП. Конструкции, которые называются суперскалярными, включают длинный конвейер команд и несколько идентичных исполнительных блоков , таких как блоки загрузки-сохранения , арифметико-логические блоки , блоки с плавающей запятой и блоки генерации адреса . [77] В суперскалярном конвейере инструкции считываются и передаются диспетчеру, который решает, могут ли инструкции выполняться параллельно (одновременно). Если это так, они передаются исполнительным модулям, что приводит к их одновременному выполнению. В общем, количество инструкций, которые суперскалярный ЦП выполнит за цикл, зависит от количества инструкций, которые он может одновременно отправить исполнительным модулям.
Основная сложность проектирования суперскалярной архитектуры ЦП заключается в создании эффективного диспетчера. Диспетчер должен иметь возможность быстро определять, могут ли инструкции выполняться параллельно, а также распределять их таким образом, чтобы задействовать как можно больше исполнительных блоков. Это требует, чтобы конвейер инструкций заполнялся как можно чаще, и требует значительных объемов кэша ЦП . Это также делает опасностей такие методы предотвращения , как предсказание ветвей , спекулятивное выполнение , переименование регистров , выполнение вне очереди и транзакционную память, решающими для поддержания высокого уровня производительности. Пытаясь предсказать, по какой ветке (или пути) пойдет условная инструкция, ЦП может минимизировать количество раз, которое весь конвейер должен ждать до завершения условной инструкции. Спекулятивное выполнение часто обеспечивает небольшое увеличение производительности за счет выполнения частей кода, которые могут оказаться ненужными после завершения условной операции. Выполнение вне порядка несколько меняет порядок выполнения инструкций, чтобы уменьшить задержки из-за зависимостей данных. Также в случае один поток инструкций, несколько потоков данных , случай, когда необходимо обработать много данных одного типа, современные процессоры могут отключать части конвейера, так что при многократном выполнении одной инструкции ЦП пропускает выборку и декодирование фаз и, таким образом, в определенных случаях значительно увеличивает производительность, особенно в очень монотонных программных движках, таких как программное обеспечение для создания видео и обработки фотографий.
Когда часть ЦП является суперскалярной, та часть, которая не является суперскалярной, испытывает снижение производительности из-за остановок планирования. Intel P5 Pentium имел два суперскалярных ALU, каждый из которых мог принимать одну инструкцию за такт, а его FPU - нет. Таким образом, P5 был целочисленным суперскаляром, но не суперскаляром с плавающей запятой. Преемник архитектуры P5 от Intel, P6 , добавил суперскалярные возможности к своим функциям с плавающей запятой.
Простая конвейерная обработка и суперскалярная конструкция увеличивают ILP процессора, позволяя ему выполнять инструкции со скоростью, превышающей одну инструкцию за такт. Большинство современных процессоров являются, по крайней мере, в некоторой степени суперскалярными, и почти все процессоры общего назначения, разработанные за последнее десятилетие, являются суперскалярными. В последующие годы часть внимания при разработке компьютеров с высоким ILP была перенесена с аппаратного обеспечения ЦП на его программный интерфейс или архитектуру набора команд (ISA). Стратегия очень длинного командного слова (VLIW) приводит к тому, что часть ILP становится подразумеваемой непосредственно программным обеспечением, что сокращает работу ЦП по усилению ILP и тем самым снижает сложность конструкции.
Параллелизм на уровне задач
[ редактировать ]Другая стратегия достижения производительности — выполнение нескольких потоков или процессов параллельное . Эта область исследований известна как параллельные вычисления . [78] В таксономии Флинна эта стратегия известна как множественный поток инструкций, множественный поток данных (MIMD). [79]
Одной из технологий, используемых для этой цели, является многопроцессорная обработка (MP). [80] Первоначальный тип этой технологии известен как симметричная многопроцессорная обработка (SMP), при которой небольшое количество процессоров совместно используют согласованное представление своей системы памяти. В этой схеме каждый ЦП имеет дополнительное оборудование для постоянного поддержания актуального состояния памяти. Избегая устаревшего представления памяти, процессоры могут совместно работать над одной и той же программой, а программы могут мигрировать с одного процессора на другой. Чтобы увеличить количество взаимодействующих процессоров сверх горстки, такие схемы, как неоднородный доступ к памяти (NUMA) и протоколы согласованности на основе каталогов в 1990-х годах были введены . Системы SMP ограничены небольшим количеством процессоров, тогда как системы NUMA построены на тысячах процессоров. Первоначально многопроцессорная обработка была построена с использованием нескольких дискретных процессоров и плат для реализации взаимодействия между процессорами. Когда все процессоры и их соединения реализованы на одном кристалле, эта технология называется многопроцессорной обработкой на уровне кристалла (CMP), а один чип — многоядерным процессором .
Позже было признано, что более тонкий параллелизм существует в одной программе. Одна программа может иметь несколько потоков (или функций), которые могут выполняться отдельно или параллельно. Некоторые из самых ранних примеров этой технологии реализовывали обработку ввода/вывода , такую как прямой доступ к памяти, в виде отдельного потока от потока вычислений. Более общий подход к этой технологии был представлен в 1970-х годах, когда были разработаны системы для параллельного выполнения нескольких вычислительных потоков. Эта технология известна как многопоточность (MT). Этот подход считается более экономичным, чем многопроцессорная обработка, поскольку для поддержки MT реплицируется лишь небольшое количество компонентов внутри ЦП, а не весь ЦП в случае MP. В MT исполнительные блоки и система памяти, включая кэши, совместно используются несколькими потоками. Обратной стороной MT является то, что аппаратная поддержка многопоточности более заметна для программного обеспечения, чем поддержка MP, и поэтому программное обеспечение супервизора, такое как операционные системы, должно претерпевать большие изменения для поддержки MT. Один из реализованных типов MT известен как временная многопоточность , при которой один поток выполняется до тех пор, пока он не остановится в ожидании возврата данных из внешней памяти. В этой схеме ЦП затем быстро переключается на другой поток, который готов к работе, причем переключение часто выполняется за один такт ЦП, например, UltraSPARC T1 . Другой тип MT — одновременная многопоточность , при которой инструкции из нескольких потоков выполняются параллельно в течение одного такта процессора.
В течение нескольких десятилетий, с 1970-х по начало 2000-х годов, основное внимание при разработке высокопроизводительных процессоров общего назначения уделялось в основном достижению высокого уровня ILP за счет таких технологий, как конвейерная обработка, кэширование, суперскалярное выполнение, выполнение вне очереди и т. д. Кульминацией этой тенденции стали крупные , энергоемкие процессоры, такие как Intel Pentium 4 . К началу 2000-х годов разработчики ЦП не смогли добиться более высокой производительности с помощью методов ILP из-за растущего несоответствия между рабочими частотами ЦП и рабочими частотами основной памяти, а также из-за увеличения рассеиваемой мощности ЦП из-за более эзотерических методов ILP.
Затем разработчики процессоров позаимствовали идеи с рынков коммерческих вычислений, таких как обработка транзакций , где совокупная производительность нескольких программ, также известная как пропускная способность вычислений, была более важной, чем производительность одного потока или процесса.
Об этом изменении акцентов свидетельствует распространение двухъядерных и более ядерных процессоров и, в частности, новые разработки Intel, напоминающие менее суперскалярную архитектуру P6 . Поздние разработки в нескольких семействах процессоров демонстрируют CMP, включая x86-64 Opteron и Athlon 64 X2 , SPARC UltraSPARC T1 , IBM POWER4 и POWER5 , а также несколько для игровых консолей, процессоров 360 таких как трехъядерный PowerPC Xbox . и PlayStation 3 7-ядерный микропроцессор Cell .
Параллелизм данных
[ редактировать ]Менее распространенная, но все более важная парадигма процессоров (да и вычислений в целом) связана с параллелизмом данных. Все процессоры, обсуждавшиеся ранее, называются скалярными устройствами определенного типа. [Дж] Как следует из названия, векторные процессоры обрабатывают несколько фрагментов данных в контексте одной инструкции. В этом отличие от скалярных процессоров, которые обрабатывают один фрагмент данных для каждой инструкции. Используя таксономию Флинна , эти две схемы работы с данными обычно называются команд «один поток , множественный поток данных» ( SIMD ) и инструкций «один поток , один поток данных » ( SISD ) соответственно. одной и той же операции (например, суммирования или скалярного произведения Большая полезность создания процессоров, работающих с векторами данных, заключается в оптимизации задач, которые, как правило, требуют выполнения ) над большим набором данных. Некоторые классические примеры задач такого типа включают мультимедийные приложения (изображения, видео и звук), а также многие типы научных и инженерных задач. В то время как скалярный процессор должен завершить весь процесс выборки, декодирования и выполнения каждой инструкции и значения в наборе данных, векторный процессор может выполнить одну операцию над сравнительно большим набором данных с помощью одной инструкции. Это возможно только в том случае, если приложению требуется много шагов, которые применяют одну операцию к большому набору данных.
Большинство ранних векторных процессоров, таких как Cray-1 , были связаны почти исключительно с научными исследованиями и криптографическими приложениями. Однако, поскольку мультимедиа в значительной степени перешла на цифровые носители, потребность в той или иной форме SIMD в процессорах общего назначения стала значительной. Вскоре после того, как включение модулей с плавающей запятой стало обычным явлением в процессорах общего назначения, спецификации и реализации исполнительных блоков SIMD также начали появляться для процессоров общего назначения. [ когда? ] Некоторые из этих ранних спецификаций SIMD, например, HP Multimedia Acceleration eXtensions (MAX) и Intel MMX , были только целочисленными. Это оказалось серьезным препятствием для некоторых разработчиков программного обеспечения, поскольку многие приложения, использующие SIMD, в основном работают с числами с плавающей запятой . Постепенно разработчики усовершенствовали и переделали эти ранние разработки в некоторые из распространенных современных спецификаций SIMD, которые обычно связаны с архитектурой одного набора команд (ISA). Некоторые известные современные примеры включают Intel Streaming SIMD Extensions связанный с PowerPC (SSE) и AltiVec, (также известный как VMX). [к]
Аппаратный счетчик производительности
[ редактировать ]Многие современные архитектуры (в том числе встроенные) часто включают в себя аппаратные счетчики производительности (HPC), которые позволяют осуществлять низкоуровневый (на уровне инструкций) сбор, тестирование производительности , отладку или анализ показателей запущенного программного обеспечения. [81] [82] HPC также может использоваться для обнаружения и анализа необычной или подозрительной активности программного обеспечения, такой как возвратно-ориентированного программирования (ROP) или sigreturn-ориентированного программирования (SROP) и т. д. эксплойты [83] Обычно это делают группы по безопасности программного обеспечения для оценки и обнаружения вредоносных двоичных программ. [84]
Многие крупные поставщики (такие как IBM , Intel , AMD и Arm ЦП ) предоставляют программные интерфейсы (обычно написанные на C/C++), которые можно использовать для сбора данных из регистров с целью получения показателей. [85] Поставщики операционных систем также предоставляют такое программное обеспечение, как perf (Linux) для записи, тестирования или отслеживания событий ЦП, запускающих ядра и приложения.
Аппаратные счетчики обеспечивают малозатратный метод сбора комплексных показателей производительности, связанных с основными элементами ЦП (функциональными блоками, кэшами, основной памятью и т. д.), что является значительным преимуществом перед программными профилировщиками. [86] Кроме того, они обычно устраняют необходимость изменять исходный код программы. [87] [88] Поскольку конструкции аппаратного обеспечения различаются в зависимости от архитектуры, конкретные типы и интерпретации аппаратных счетчиков также изменятся.
Привилегированные режимы
[ редактировать ]Большинство современных процессоров имеют привилегированные режимы для поддержки операционных систем и виртуализации.
Облачные вычисления могут использовать виртуализацию для предоставления виртуальных центральных процессоров. [89] ( vCPU ) для отдельных пользователей. [90]
Хост — это виртуальный эквивалент физической машины, на которой работает виртуальная система. [91] Когда несколько физических машин работают в тандеме и управляются как единое целое, сгруппированные вычислительные ресурсы и ресурсы памяти образуют кластер . В некоторых системах можно динамически добавлять и удалять кластер. Ресурсы, доступные на уровне хоста и кластера, можно разделить на пулы ресурсов с высокой степенью детализации .
Производительность
[ редактировать ]Производительность ) или скорость процессора зависит, среди многих других факторов, от тактовой частоты (обычно измеряемой в герцах и количества инструкций за такт (IPC), которые вместе являются факторами для количества инструкций в секунду (IPS), которые ЦП может работать. [92] Многие заявленные значения IPS представляют собой «пиковую» скорость выполнения искусственных последовательностей инструкций с небольшим количеством ветвей, тогда как реалистичные рабочие нагрузки состоят из смеси инструкций и приложений, выполнение некоторых из которых занимает больше времени, чем других. Производительность иерархии памяти также сильно влияет на производительность процессора, и эта проблема почти не учитывается при расчетах IPS. Из-за этих проблем были разработаны различные стандартизированные тесты, часто называемые для этой цели «эталонными тестами» , такие как SPECint , чтобы попытаться измерить реальную эффективную производительность в часто используемых приложениях.
Производительность обработки компьютеров увеличивается за счет использования многоядерных процессоров , что по сути означает подключение двух или более отдельных процессоров ( называемых ядрами ) в одну интегральную схему. в этом смысле [93] В идеале двухъядерный процессор должен быть почти в два раза мощнее одноядерного. На практике прирост производительности гораздо меньше, всего около 50%, из-за несовершенства программных алгоритмов и реализации. [94] Увеличение количества ядер в процессоре (т. е. двухъядерных, четырехъядерных и т. д.) увеличивает рабочую нагрузку, с которой можно справиться. Это означает, что процессор теперь может обрабатывать многочисленные асинхронные события, прерывания и т. д., которые могут нанести ущерб процессору при перегрузке. Эти ядра можно рассматривать как разные этажи перерабатывающего завода, где каждый этаж выполняет свою задачу. Иногда эти ядра будут выполнять те же задачи, что и соседние с ними ядра, если одного ядра недостаточно для обработки информации. Многоядерные процессоры расширяют возможности компьютера одновременно выполнять несколько задач, обеспечивая дополнительную вычислительную мощность. Однако прирост скорости не прямо пропорционален количеству добавленных ядер. Это связано с тем, что ядрам необходимо взаимодействовать через определенные каналы, и эта связь между ядрами потребляет часть доступной скорости обработки. [95]
Из-за специфических возможностей современных процессоров, таких как одновременная многопоточность и uncore , которые предполагают совместное использование реальных ресурсов процессора с целью повышения их использования, мониторинг уровней производительности и использования оборудования постепенно стал более сложной задачей. [96] В ответ некоторые ЦП реализуют дополнительную аппаратную логику, которая отслеживает фактическое использование различных частей ЦП и предоставляет различные счетчики, доступные программному обеспечению; примером является технология Intel Performance Counter Monitor . [9]
См. также
[ редактировать ]- Режим адресации
- Ускоренный процессор AMD
- Компьютер со сложным набором команд
- Компьютерный автобус
- Компьютерная инженерия
- Напряжение ядра процессора
- разъем процессора
- Блок обработки данных
- Цифровой сигнальный процессор
- Графический процессор
- Сравнение архитектур наборов команд
- Защитное кольцо
- Компьютер с сокращенным набором команд
- Потоковая обработка
- Истинный индекс производительности
- Тензорный процессор
- Состояние ожидания
Примечания
[ редактировать ]- ^ Интегральные схемы теперь используются для реализации всех процессоров, за исключением нескольких машин, предназначенных для выдерживания сильных электромагнитных импульсов, например, от ядерного оружия.
- ↑ В так называемой записке «фон Неймана» изложена идея хранимых программ. [65] которые, например, могут храниться на перфокартах , бумажной или магнитной ленте.
- ^ Некоторые ранние компьютеры, такие как Harvard Mark I, не поддерживали никаких инструкций «перехода», что эффективно ограничивало сложность программ, которые они могли запускать. Во многом по этой причине часто считается, что эти компьютеры не содержат полноценного ЦП, несмотря на их близкое сходство с компьютерами с хранимыми программами.
- ^ Поскольку счетчик программ считает адреса памяти , а не инструкции , он увеличивается на количество единиц памяти, содержащихся в командном слове. В случае простых командных слов фиксированной длины ISA это всегда один и тот же номер. Например, 32-битное командное слово ISA фиксированной длины, использующее 8-битные слова памяти, всегда будет увеличивать PC на четыре (за исключением случаев переходов). ISA, которые используют командные слова переменной длины, увеличивают ПК на количество слов памяти, соответствующее длине последней инструкции.
- ^ Поскольку архитектура набора команд ЦП имеет основополагающее значение для его интерфейса и использования, она часто используется для классификации «типа» ЦП. Например, «ЦП PowerPC» использует некоторый вариант PowerPC ISA. Система может выполнять другую ISA, запустив эмулятор.
- ^ Некоторые специализированные процессоры, ускорители или микроконтроллеры не имеют кэша. Чтобы быть быстрыми, если это необходимо/желательно, у них все еще есть встроенная блокнотная память, которая имеет аналогичную функцию, хотя и управляется программным обеспечением. Например, в микроконтроллерах для жесткого использования в режиме реального времени может быть лучше иметь такой кэш или, по крайней мере, не иметь его, поскольку при одном уровне памяти задержки при загрузке предсказуемы.
- ^ Физическая концепция напряжения по своей природе является аналоговой и практически имеет бесконечный диапазон возможных значений. Для физического представления двоичных чисел определены два конкретных диапазона напряжений: один для логического «0», а другой для логической «1». Эти диапазоны продиктованы конструктивными соображениями, такими как запас шума и характеристики устройств, используемых для создания ЦП.
- ^ Хотя целочисленный размер ЦП устанавливает ограничение на целочисленные диапазоны, это можно (и часто) преодолеть с помощью комбинации программных и аппаратных методов. Используя дополнительную память, программное обеспечение может представлять целые числа, во много раз превышающие возможности ЦП. ЦП Иногда набор инструкций даже облегчает операции с целыми числами, большими, чем он может представить изначально, предоставляя инструкции для относительно быстрого выполнения арифметических операций с большими целыми числами. Этот метод работы с большими целыми числами медленнее, чем использование ЦП с большим размером целых чисел, но является разумным компромиссом в тех случаях, когда нативная поддержка полного необходимого диапазона целых чисел была бы непомерно затратной. см. в разделе Арифметика произвольной точности . Дополнительные сведения о целых числах произвольного размера, поддерживаемых программным обеспечением,
- ^ Ни ILP , ни TLP по своей сути не превосходят друг друга; это просто разные средства повышения параллелизма ЦП. Таким образом, у них обоих есть преимущества и недостатки, которые часто определяются типом программного обеспечения, для работы которого предназначен процессор. Процессоры с высоким уровнем TLP часто используются в приложениях, которые хорошо поддаются разбиению на множество более мелких приложений, в так называемых « затруднительно параллельных задачах». Часто вычислительная задача, которую можно быстро решить с помощью стратегий проектирования с высоким уровнем TLP, таких как симметричная многопроцессорная обработка, требует значительно больше времени на устройствах с высоким уровнем ILP, таких как суперскалярные процессоры, и наоборот.
- ^ Ранее термин скаляр использовался для сравнения количества IPC, полученного различными методами ILP. Здесь этот термин используется в строго математическом смысле, в отличие от векторов. См. скаляр (математика) и вектор (геометрический) .
- ^ Хотя SSE/SSE2/SSE3 заменили MMX в процессорах Intel общего назначения, более поздние конструкции IA-32 по-прежнему поддерживают MMX. Обычно это достигается путем предоставления большей части функций MMX на том же оборудовании, которое поддерживает гораздо более обширные наборы инструкций SSE.
Ссылки
[ редактировать ]- ^ Команда, Эксперт YCT. Инженерный чертеж и фундаментальная наука . Время молодежных соревнований. п. 425.
- ^ Нагпал, ДП (2008). Основы компьютера . Издательство С. Чанд. п. 33. ISBN 978-81-219-2388-0 .
- ^ «Что такое процессор (ЦП)? Определение с сайта WhatIs.com» . Что такое . Проверено 15 марта 2024 г.
- ^ Чесалов, Александр (12 апреля 2023 г.). Глоссарий четвертой промышленной революции: более 1500 самых популярных терминов, которые вы будете использовать, чтобы создавать будущее . Литры. ISBN 978-5-04-541163-9 .
- ^ Джагаре, Ульрика (19 апреля 2022 г.). Управление искусственным интеллектом: преодоление разрыва между технологиями и бизнесом . Джон Уайли и сыновья. ISBN 978-1-119-83321-5 .
- ^ Кук, Дэвид (1978). Компьютеры и вычисления, Том 1 . John Wiley & Sons, Inc. с. 12. ISBN 978-0471027164 .
- ^ Прабхат, команда (13 апреля 2023 г.). Полное руководство по комбинированным предварительным и основным экзаменам SSC CGL для выпускников уровней Tier-I и Tier II (с последними решенными вопросами) Путеводитель на английском языке: книга-бестселлер от Team Prabhat: Полное руководство по комбинированным отборочным экзаменам SSC CGL для выпускников уровней Tier-I и Tier II и Сеть (с последними решенными вопросами) Путеводитель на английском языке . Прабхат Пракашан. п. 95. ИСБН 978-93-5488-527-3 .
- ^ «Что такое многоядерный процессор и как он работает?» . Дата-центр . Проверено 15 марта 2024 г.
- ^ Перейти обратно: а б Уиллхальм, Томас; Дементьев Роман; Фэй, Патрик (18 декабря 2014 г.). «Intel Performance Counter Monitor — лучший способ измерения загрузки ЦП» . программное обеспечение.intel.com . Архивировано из оригинала 22 февраля 2017 года . Проверено 17 февраля 2015 г.
- ^ Херрес, Дэвид (06 октября 2020 г.). Осциллографы: Руководство для студентов, инженеров и ученых . Спрингер Природа. п. 130. ИСБН 978-3-030-53885-9 .
- ^ Риган, Джерард (2008). Краткая история вычислений . Спрингер. п. 66. ИСБН 978-1848000834 . Проверено 26 ноября 2014 г.
- ^ Вейк, Мартин Х. (1955). «Обзор отечественных электронных цифровых вычислительных систем» . Лаборатория баллистических исследований . Архивировано из оригинала 26 января 2021 г. Проверено 15 ноября 2020 г.
- ^ Перейти обратно: а б Вейк, Мартин Х. (1961). «Третий обзор отечественных электронных цифровых вычислительных систем» . Веб-сайт Nike Missile Эда Телена . Лаборатория баллистических исследований . Архивировано из оригинала 11 сентября 2017 г. Проверено 16 декабря 2005 г.
- ^ «По крупицам» . Хаверфордский колледж. Архивировано из оригинала 13 октября 2012 года . Проверено 1 августа 2015 г.
- ^ Первый проект отчета о EDVAC (PDF) (Технический отчет). электротехники Мура Школа Пенсильванского университета . 1945. Архивировано (PDF) из оригинала 9 марта 2021 г. Проверено 31 марта 2018 г.
- ^ Стэнфордский университет. «Современная история вычислительной техники» . Стэнфордская энциклопедия философии . Проверено 25 сентября 2015 г.
- ^ «День рождения ЭНИАКа» . Массачусетский технологический институт Пресс. 9 февраля 2016. Архивировано из оригинала 17 октября 2018 года . Проверено 17 октября 2018 г.
- ^ Энтикнап, Николас (лето 1998 г.), «Золотой юбилей компьютеров» , Resurrection (20), The Computer Conservation Society, ISSN 0958-7403 , заархивировано из оригинала 17 марта 2019 г. , получено 26 июня 2019 г.
- ^ «Манчестер Марк 1» . Манчестерский университет . Архивировано из оригинала 25 января 2015 года . Проверено 25 сентября 2015 г.
- ^ «Первое поколение» . Музей истории компьютеров. Архивировано из оригинала 22 ноября 2016 года . Проверено 29 сентября 2015 г.
- ^ «История интегральной схемы» . Нобелевская премия.org . Архивировано из оригинала 22 мая 2022 года . Проверено 17 июля 2022 г.
- ^ Терли, Джим (11 августа 2003 г.). «Автомобилестроение с микропроцессорами» . Встроенный. Архивировано из оригинала 14 октября 2022 года . Проверено 26 декабря 2022 г.
- ^ «Руководство по мобильным процессорам – лето 2013 г.» . Android-авторитет. 25 июня 2013 г. Архивировано из оригинала 17 ноября 2015 г. Проверено 15 ноября 2015 г.
- ^ «Раздел 250: Микропроцессоры и игрушки: введение в вычислительные системы» . Мичиганский университет. Архивировано из оригинала 13 апреля 2021 года . Проверено 9 октября 2018 г.
- ^ «Процессор ARM946» . РУКА. Архивировано из оригинала 17 ноября 2015 года.
- ^ «Конрад Цузе» . Музей истории компьютеров. Архивировано из оригинала 3 октября 2016 года . Проверено 29 сентября 2015 г.
- ^ «Хронология компьютерной истории: компьютеры» . Музей истории компьютеров. Архивировано из оригинала 29 декабря 2017 года . Проверено 21 ноября 2015 г.
- ^ Уайт, Стивен. «Краткая история вычислительной техники – компьютеры первого поколения» . Архивировано из оригинала 2 января 2018 года . Проверено 21 ноября 2015 г.
- ^ «Дырокол для бумажной ленты Mark I Гарвардского университета» . Музей истории компьютеров. Архивировано из оригинала 22 ноября 2015 года . Проверено 21 ноября 2015 г.
- ^ «В чем разница между архитектурой фон Неймана и архитектурой Гарварда?» . РУКА. Архивировано из оригинала 18 ноября 2015 года . Проверено 22 ноября 2015 г.
- ^ «Передовая архитектура оптимизирует процессор Atmel AVR» . Атмел. Архивировано из оригинала 14 ноября 2015 года . Проверено 22 ноября 2015 г.
- ^ «Переключатели, транзисторы и реле» . Би-би-си. Архивировано из оригинала 5 декабря 2016 года.
- ^ «Представляем вакуумный транзистор: устройство, сделанное из ничего» . IEEE-спектр . 23 июня 2014 г. Архивировано из оригинала 23 марта 2018 г. Проверено 27 января 2019 г.
- ^ Что такое производительность компьютера? . Пресса национальных академий. 2011. дои : 10.17226/12980 . ISBN 978-0-309-15951-7 . Архивировано из оригинала 5 июня 2016 года . Проверено 16 мая 2016 г.
- ^ «1953: Появление транзисторных компьютеров» . Музей истории компьютеров . Архивировано из оригинала 1 июня 2016 года . Проверено 3 июня 2016 г.
- ^ «Даты и характеристики IBM System/360» . ИБМ. 23 января 2003 г. Архивировано из оригинала 21 ноября 2017 г. Проверено 13 января 2016 г.
- ^ Перейти обратно: а б Амдал, генеральный директор ; Блаув, Джорджия ; Брукс, Ф.П. младший (апрель 1964 г.). «Архитектура IBM System/360». Журнал исследований и разработок IBM . 8 (2). ИБМ : 87–101. дои : 10.1147/rd.82.0087 . ISSN 0018-8646 .
- ^ Бродкин, Джон (7 апреля 2014 г.). «50 лет назад IBM создала мэйнфрейм, который помог отправить людей на Луну» . Арс Техника . Архивировано из оригинала 8 апреля 2016 года . Проверено 9 апреля 2016 г.
- ^ Кларк, Гэвин. «Почему вы не умрете? IBM S/360 и ее наследие в 50 лет» . Регистр . Архивировано из оригинала 24 апреля 2016 года . Проверено 9 апреля 2016 г.
- ^ «Интернет-домашняя страница PDP-8, запуск PDP-8» . ПРП8 . Архивировано из оригинала 11 августа 2015 года . Проверено 25 сентября 2015 г.
- ^ «Транзисторы, реле и управление сильноточными нагрузками» . Нью-Йоркский университет . ITP Физические вычисления. Архивировано из оригинала 21 апреля 2016 года . Проверено 9 апреля 2016 г.
- ^ Лилли, Пол (14 апреля 2009 г.). «Краткая история процессоров: 31 потрясающий год x86» . ПК-геймер . Архивировано из оригинала 13 июня 2016 г. Проверено 15 июня 2016 г.
- ^ Перейти обратно: а б Паттерсон, Дэвид А.; Хеннесси, Джон Л.; Ларус, Джеймс Р. (1999). Компьютерная организация и дизайн: аппаратно-программный интерфейс (3-е издание 2-го изд.). Сан-Франциско, Калифорния: Кауфманн. п. 751 . ISBN 978-1558604285 .
- ^ «1962: Аэрокосмические системы — первые приложения для микросхем в компьютерах» . Музей истории компьютеров . Архивировано из оригинала 5 октября 2018 года . Проверено 9 октября 2018 г.
- ^ «Интегральные схемы в программе пилотируемой посадки на Луну «Аполлон»» . Национальное управление по аэронавтике и исследованию космического пространства. Архивировано из оригинала 21 июля 2019 года . Проверено 9 октября 2018 г.
- ^ «Объявление системы/370» . Архивы IBM . 23 января 2003 г. Архивировано из оригинала 20 августа 2018 г. Проверено 25 октября 2017 г.
- ^ «Система/370, модель 155 (продолжение)» . Архивы IBM . 23 января 2003 г. Архивировано из оригинала 20 июля 2016 г. Проверено 25 октября 2017 г.
- ^ «Модели и опции» . Корпорация цифрового оборудования PDP-8. Архивировано из оригинала 26 июня 2018 года . Проверено 15 июня 2018 г.
- ^ Бассетт, Росс Нокс (2007). В эпоху цифровых технологий: исследовательские лаборатории, стартапы и развитие MOS-технологий . Издательство Университета Джонса Хопкинса . стр. 127–128, 256 и 314. ISBN. 978-0-8018-6809-2 .
- ^ Перейти обратно: а б Ширрифф, Кен. «Texas Instruments TMX 1795: первый, забытый микропроцессор» . Архивировано из оригинала 26 января 2021 г.
- ^ «Скорость и мощность в логических семействах» . Архивировано из оригинала 26 июля 2017 г. Проверено 2 августа 2017 г. .
- ^ Стонхэм, Ти Джей (1996). Методы цифровой логики: принципы и практика . Тейлор и Фрэнсис. п. 174. ИСБН 9780412549700 .
- ^ «1968: Разработана технология кремниевых затворов для микросхем» . Музей истории компьютеров . Архивировано из оригинала 29 июля 2020 г. Проверено 16 августа 2019 г.
- ^ Бухер, РК (1968). Компьютер MOS GP (PDF) . Международный семинар по управлению знаниями в области требований. АФИПС . п. 877. дои : 10.1109/AFIPS.1968.126 . Архивировано (PDF) из оригинала 14 июля 2017 г.
- ^ «Описание модуля LSI-11». Руководство пользователя LSI-11, PDP-11/03 (PDF) (2-е изд.). Мейнард, Массачусетс: Корпорация цифрового оборудования . Ноябрь 1975 г. с. 4-3. Архивировано (PDF) из оригинала 10 октября 2021 г. Проверено 20 февраля 2015 г.
- ^ Бигелоу, Стивен Дж. (март 2022 г.). «Что такое многоядерный процессор и как он работает?» . ТехТаржет. Архивировано из оригинала 11 июля 2022 года . Проверено 17 июля 2022 г.
- ^ Биркби, Ричард. «Краткая история микропроцессора» . www.computermuseum.li . Архивировано из оригинала 23 сентября 2015 года . Проверено 13 октября 2015 г.
- ^ Осборн, Адам (1980). Введение в микрокомпьютеры . Том. 1: Основные понятия (2-е изд.). Беркли, Калифорния: Осборн-МакГроу Хилл. ISBN 978-0-931988-34-9 .
- ^ Жислина, Виктория (19 февраля 2014 г.). «Почему частота процессора перестала расти?» . Интел. Архивировано из оригинала 21 июня 2017 г. Проверено 14 октября 2015 г.
- ^ «МОП-транзистор – электротехника и информатика» (PDF) . Калифорнийский университет. Архивировано (PDF) из оригинала 9 октября 2022 г. Проверено 14 октября 2015 г.
- ^ Симонит, Том. «Закон Мура мертв. Что теперь?» . Обзор технологий Массачусетского технологического института . Архивировано из оригинала 22 августа 2018 г. Проверено 24 августа 2018 г.
- ^ Мур, Гордон (2005). «Отрывки из разговора с Гордоном Муром: закон Мура» (PDF) (интервью). Интел. Архивировано из оригинала (PDF) 29 октября 2012 г. Проверено 25 июля 2012 г.
- ^ «Подробная история процессора» . Технический наркоман. 15 декабря 2016 года. Архивировано из оригинала 14 августа 2019 года . Проверено 14 августа 2019 г.
- ^ Эйгенманн, Рудольф; Лилья, Дэвид (1998). «Компьютеры фон Неймана». Энциклопедия электротехники и электроники Wiley . дои : 10.1002/047134608X.W1704 . ISBN 047134608X . S2CID 8197337 .
- ^ Эспрей, Уильям (сентябрь 1990 г.). «Концепция хранимой программы». IEEE-спектр . Том. 27, нет. 9. с. 51. дои : 10.1109/6.58457 .
- ^ Сарасват, Кришна. «Тенденции в технологии интегральных микросхем» (PDF) . Архивировано из оригинала (PDF) 24 июля 2015 г. Проверено 15 июня 2018 г.
- ^ «Электромиграция» . Ближневосточный технический университет. Архивировано из оригинала 31 июля 2017 года . Проверено 15 июня 2018 г.
- ^ Винанд, Ян (3 сентября 2013 г.). «Информатика снизу вверх, Глава 3. Компьютерная архитектура» (PDF) . Botuppcs.com . Архивировано (PDF) из оригинала 6 февраля 2016 г. Проверено 7 января 2015 г.
- ^ «Введение в блок управления и его конструкция» . Гики для Гиков . 24 сентября 2018 г. Архивировано из оригинала 15 января 2021 г. Проверено 12 января 2021 г.
- ^ Ван Беркель, Корнелис; Мейвиссен, Патрик (12 января 2006 г.). «Блок генерации адреса для процессора (заявка на патент США 2006010255 А1)» . гугл.com . Архивировано из оригинала 18 апреля 2016 года . Проверено 8 декабря 2014 г. [ нужна проверка ]
- ^ Торрес, Габриэль (12 сентября 2007 г.). «Как работает кэш-память» . Аппаратные секреты . Проверено 29 января 2023 г.
- ^ «Техническое введение IBM z13 и IBM z13s» (PDF) . ИБМ . Март 2016. с. 20. Архивировано (PDF) из оригинала 9 октября 2022 г. [ нужна проверка ]
- ^ Браун, Джеффри (2005). «Разработка процессора, адаптированная к приложениям» . IBM DeveloperWorks. Архивировано из оригинала 12 февраля 2006 г. Проверено 17 декабря 2005 г.
- ^ Мартин, Эй Джей; Нистром, М.; Вонг, CG (ноябрь 2003 г.). «Три поколения асинхронных микропроцессоров» . IEEE Проектирование и тестирование компьютеров . 20 (6): 9–17. дои : 10.1109/MDT.2003.1246159 . ISSN 0740-7475 . S2CID 15164301 . Архивировано из оригинала 3 декабря 2021 г. Проверено 5 января 2022 г.
- ^ Гарсайд, доктор медицинских наук; Фурбер, С.Б.; Чунг, С.Х. (1999). «Раскрытие AMULET3» . Труды Пятого международного симпозиума по перспективным исследованиям в области асинхронных цепей и систем . Манчестерского университета Факультет компьютерных наук . дои : 10.1109/ASYNC.1999.761522 . Архивировано из оригинала 10 декабря 2005 года.
- ^ Функциональные характеристики IBM System/360 Model 65 (PDF) . ИБМ . Сентябрь 1968. стр. 8–9. А22-6884-3. Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Хьюнь, Джек (2003). «Процессор AMD Athlon XP с кэшем второго уровня объемом 512 КБ» (PDF) . Урбана-Шампейн, Иллинойс: Университет Иллинойса. стр. 6–11. Архивировано из оригинала (PDF) 28 ноября 2007 г. Проверено 6 октября 2007 г.
- ^ Готлиб, Аллан; Алмаси, Джордж С. (1989). Высокопараллельные вычисления . Редвуд-Сити, Калифорния: Бенджамин/Каммингс. ISBN 978-0-8053-0177-9 . Архивировано из оригинала 07.11.2018 . Проверено 25 апреля 2016 г.
- ^ Флинн, MJ (сентябрь 1972 г.). «Некоторые компьютерные организации и их эффективность». Транзакции IEEE на компьютерах . С-21 (9): 948–960. дои : 10.1109/TC.1972.5009071 . S2CID 18573685 .
- ^ Лу, Н.-П.; Чунг, К.-П. (1998). «Использование параллелизма в суперскалярной многопроцессорной обработке». Труды IEE - Компьютеры и цифровая техника . 145 (4): 255. doi : 10.1049/ip-cdt:19981955 .
- ^ Усадел, Лейф; Жорж, Энди; Вербауведе, Ингрид (август 2008 г.). Использование аппаратных счетчиков производительности . 2008 г. 5-й семинар по диагностике ошибок и устойчивости в криптографии. стр. 59–67. дои : 10.1109/FDTC.2008.19 . ISBN 978-0-7695-3314-8 . S2CID 1897883 . Архивировано из оригинала 30 декабря 2021 г. Проверено 30 декабря 2021 г.
- ^ Роху, Эрвен (сентябрь 2012 г.). Tiptop: счетчики производительности оборудования для масс . 2012 г. 41-я Международная конференция по параллельной обработке. стр. 404–413. дои : 10.1109/ICPPW.2012.58 . ISBN 978-1-4673-2509-7 . S2CID 16160098 . Архивировано из оригинала 30 декабря 2021 г. Проверено 30 декабря 2021 г.
- ^ Герат, Нишад; Фог, Андерс (2015). «Счетчики производительности оборудования ЦП для обеспечения безопасности» (PDF) . США: Блэк Хэт. Архивировано (PDF) из оригинала 5 сентября 2015 г.
- ^ Ёсанг, Аудун (21 июня 2018 г.). ECCWS 2018 17-я Европейская конференция по кибервойне и безопасности V2 . Научные конференции и публикации ограничены. ISBN 978-1-911218-86-9 .
- ^ ДеРоуз, Луис А. (2001), Сакеллариу, Ризос; Гурд, Джон; Фриман, Лен; Кин, Джон (ред.), «Набор инструментов для мониторинга производительности оборудования» , Параллельная обработка Euro-Par 2001 , Конспекты лекций по информатике, том. 2150, Берлин, Гейдельберг: Springer Berlin Heidelberg, стр. 122–132, doi : 10.1007/3-540-44681-8_19 , ISBN 978-3-540-42495-6 , заархивировано из оригинала 1 марта 2023 г. , получено 30 декабря 2021 г.
- ^ «К ЭТАЛОНУ ДЛЯ ОЦЕНКИ ПРОИЗВОДИТЕЛЬНОСТИ И ЭНЕРГОПОТРЕБЛЕНИЯ ИНТЕРФЕЙСОВ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ» (PDF) (на вьетнамском языке) . Проверено 15 марта 2024 г.
- ^ «Открытый исходный код: что это значит, как это работает, пример» . Инвестопедия . Проверено 15 марта 2024 г.
- ^ Чаудхури, Тарун Кумар; Банерджи, Джоянта; Гупта, Випул; Поддар, Дебопам (04 марта 2024 г.). Освоение безопасных приложений Java: управление безопасностью в облаке и микросервисах для Java (английское издание). Публикации БПБ. п. 117. ИСБН 978-93-5551-884-2 .
- ^
Анджум, Бушра; Перрос, Гарри Г. (2015). «1: Разделение бюджета сквозного QoS на домены» . Распределение полосы пропускания для видео при ограничениях качества обслуживания . Серия «Фокус». Джон Уайли и сыновья. п. 3. ISBN 9781848217461 . Проверено 21 сентября 2016 г.
[...] в облачных вычислениях, где несколько программных компонентов работают в виртуальной среде на одном и том же блейде, по одному компоненту на виртуальную машину (ВМ). Каждой виртуальной машине выделяется виртуальный центральный процессор [...], который составляет часть ЦП блейда.
- ^
Файфилд, Том; Флеминг, Дайан; Нежно, Энн; Хохштейн, Лорин; Пру, Джонатан; Тэйвс, Эверетт; Топджиан, Джо (2014). «Глоссарий» . Руководство по работе с OpenStack . Пекин: O'Reilly Media, Inc., с. 286. ИСБН 9781491906309 . Проверено 20 сентября 2016 г.
Виртуальный центральный процессор (vCPU)[:] Разделяет физические процессоры. Затем экземпляры могут использовать эти подразделения.
- ^ «Обзор архитектуры инфраструктуры VMware — технический документ» (PDF) . ВМваре . 2006. Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ «Частота процессора» . Мировой глоссарий процессоров . Мир процессоров. 25 марта 2008 г. Архивировано из оригинала 9 февраля 2010 г. Проверено 1 января 2010 г.
- ^ «Что такое многоядерный процессор?» . Определения центров обработки данных . SearchDataCenter.com. Архивировано из оригинала 5 августа 2010 года . Проверено 8 августа 2016 г.
- ^ Мблевинс (8 апреля 2010 г.). «Четырехъядерный против двухъядерного» . Технический дух . Архивировано из оригинала 4 июля 2019 года . Проверено 7 ноября 2019 г.
- ^ Марцин, Вецлав (12 января 2022 г.). «Факторы, влияющие на производительность многоядерных процессоров» . ПКСайт .
- ^ Тегтмайер, Мартин. «Объяснение использования ЦП в многопоточных архитектурах» . Оракул. Архивировано из оригинала 18 июля 2022 года . Проверено 17 июля 2022 г.