Оценка максимального расстояния
В статистике — оценка максимального интервала ( MSE или MSP ) или максимальный продукт оценки интервала (MPS) это метод оценки параметров одномерной статистической модели . [1] Этот метод требует максимизации среднего геометрического расстояний в данных, которые представляют собой разности между значениями кумулятивной функции распределения в соседних точках данных.
Концепция, лежащая в основе метода, основана на преобразовании интеграла вероятности , заключающемся в том, что набор независимых случайных выборок, полученных из любой случайной величины, должен в среднем быть равномерно распределен относительно кумулятивной функции распределения случайной величины. Метод MPS выбирает значения параметров, которые делают наблюдаемые данные максимально однородными, в соответствии с конкретной количественной мерой однородности.
Один из наиболее распространенных методов оценки параметров распределения по данным, метод максимального правдоподобия (MLE), может выйти из строя в различных случаях, например, при использовании определенных смесей непрерывных распределений. [2] В этих случаях может оказаться успешным метод оценки максимального расстояния.
Помимо использования в чистой математике и статистике, сообщалось о пробном применении этого метода с использованием данных из таких областей, как гидрология , [3] эконометрика , [4] магнитно-резонансная томография , [5] и другие. [6]
История и использование
[ редактировать ]Метод MSE был независимо разработан Расселом Ченгом и Ником Амином из Института науки и технологий Уэльского университета и Бо Раннеби из Шведского университета сельскохозяйственных наук . [2] Авторы объяснили, что из-за преобразования интеграла вероятности при истинном параметре «интервал» между каждым наблюдением должен быть равномерно распределен. Это означало бы, что разность значений кумулятивной функции распределения при последовательных наблюдениях должна быть одинаковой. Это тот случай, когда максимизирует среднее геометрическое таких расстояний, поэтому решение параметров, которые максимизируют среднее геометрическое, позволит достичь «наилучшего» соответствия, определенного таким образом. Раннеби (1984) обосновал этот метод, продемонстрировав, что он является оценкой расхождения Кульбака-Лейблера , аналогичной оценке максимального правдоподобия , но с более устойчивыми свойствами для некоторых классов задач.
Существуют определенные распределения, особенно с тремя или более параметрами, вероятность которых может стать бесконечной на определенных путях в пространстве параметров . Использование максимального правдоподобия для оценки этих параметров часто дает сбой: один параметр стремится к определенному значению, из-за чего вероятность становится бесконечной, что делает другие параметры несогласованными. Однако метод максимальных расстояний, поскольку он зависит от разницы между точками кумулятивной функции распределения, а не от отдельных точек правдоподобия, не имеет этой проблемы и будет возвращать действительные результаты в гораздо более широком массиве распределений. [1]
Распределения, которые имеют тенденцию иметь проблемы с правдоподобием, часто используются для моделирования физических явлений. Холл и др. (2004) стремятся проанализировать методы смягчения последствий наводнений, что требует точных моделей последствий речных паводков. Все распределения, которые лучше моделируют эти эффекты, представляют собой трехпараметрические модели, которые страдают от описанной выше проблемы бесконечного правдоподобия, что привело к исследованию Холлом процедуры максимального интервала. Вонг и Ли (2006) при сравнении метода с максимальным правдоподобием использовали различные наборы данных, начиная от набора самых старых возрастов смерти в Швеции между 1905 и 1958 годами и заканчивая набором, содержащим годовые максимальные скорости ветра.
Определение
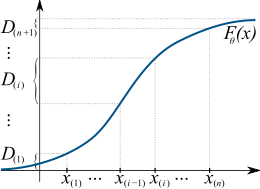
[ редактировать ]Учитывая iid случайную выборку { x 1 , ..., x n } размера n из одномерного распределения с непрерывной кумулятивной функцией распределения F ( x ; θ 0 ), где θ 0 ∈ Θ - неизвестный параметр, который нужно оценить , пусть { x (1) , ..., x ( n ) } — соответствующая упорядоченная выборка, то есть результат сортировки всех наблюдений от наименьшего к наибольшему. Для удобства также обозначим x (0) = −∞ и x ( n +1) = +∞.
Определим расстояния как «промежутки» между значениями функции распределения в соседних упорядоченных точках: [7]

Тогда оценка максимального расстояния θ логарифм 0 определяется как значение, которое максимизирует среднего расстояния геометрического между образцами:
![{\displaystyle {\hat {\theta }}={\underset {\theta \in \Theta }{\operatorname {arg\,max} }}\;S_{n}(\theta),\quad {\text {где }}\ S_{n}(\theta )=\ln \!\!{\sqrt[{n+1}]{D_{1}D_{2}\cdots D_{n+1}}}= {\frac {1}{n+1}}\sum _{i=1}^{n+1}\ln {D_{i}}(\theta ).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a31b5ecd6b17eba0ab4543bd2d844d706d1f573)
В силу неравенства средних арифметических и геометрических функция Sn +1), и ( θ ) ограничена сверху величиной −ln( n , таким образом, максимум должен существовать по крайней мере в смысле супремума .
что некоторые авторы определяют функцию Sn Заметим , ( θ ) несколько иначе. В частности, Раннеби (1984) умножает каждое D i на коэффициент ( n +1), тогда как Ченг и Стивенс (1989) опускают 1 ⁄ n +1 Перед суммой умножьте множитель и добавьте знак «-», чтобы превратить максимизацию в минимизацию. Поскольку это константы по отношению к θ положение максимума функции Sn , модификации не изменяют .
Примеры
[ редактировать ]В этом разделе представлены два примера расчета оценки максимального расстояния.
Пример 1
[ редактировать ]
Предположим, что два значения x (1) = 2, x (2) = 4 были выбраны из экспоненциального распределения F ( x ; λ ) = 1 − e − хλ , x ≥ 0 с неизвестным параметром λ > 0. Чтобы построить СКО, нам нужно сначала найти расстояния:
| я | F ( Икс ( я ) ) | F ( Икс ( я -1) ) | D я знак равно F ( Икс ( я ) ) - F ( Икс ( я -1) ) |
|---|---|---|---|
| 1 | 1 - и −2 мин. | 0 | 1 - и −2 мин. |
| 2 | 1 - и -4 мин. | 1 - и −2 мин. | и −2 мин. − и -4 мин. |
| 3 | 1 | 1 - и -4 мин. | и -4 мин. |
Процесс продолжается поиском λ , который максимизирует среднее геометрическое столбца «разности». Используя соглашение, которое игнорирует взятие корня ( n +1), это превращается в максимизацию следующего произведения: (1 − e −2 мин. ) · (и −2 мин. − и -4 мин. ) · (и -4 мин. ). Полагая µ = e −2 мин. , проблема заключается в нахождении максимума µ 5 -2 м 4 + м 3 . Дифференцируя, µ должен удовлетворять 5 µ 4 -8 м 3 +3 м 2 = 0. Это уравнение имеет корни 0, 0,6 и 1. Поскольку µ на самом деле равно e −2 мин. , оно должно быть больше нуля, но меньше единицы. Поэтому единственным приемлемым решением является что соответствует экспоненциальному распределению со средним значением 1 ⁄ λ ≈ 3,915. Для сравнения: оценка максимального правдоподобия λ является обратной выборочной средней, равной 3, поэтому λ MLE = ⅓ ≈ 0,333.

Пример 2
[ редактировать ]Предположим, { x (1) , ..., x ( n ) } — упорядоченная выборка из равномерного распределения U ( a , b ) с неизвестными конечными точками a и b . Кумулятивная функция распределения равна F ( x ; a , b ) = ( x - a )/( b - a ), когда x ∈ [ a , b ]. Таким образом, отдельные расстояния определяются выражением

Вычислив среднее геометрическое и затем логарифмировав, статистика S n будет равна Здесь только три слагаемых зависят от параметров a и b . Дифференцируя по этим параметрам и решая полученную линейную систему, максимальные оценки расстояния будут равны


Известно, что это несмещенные оценки с равномерно минимальной дисперсией (UMVU) для непрерывного равномерного распределения. [1] Для сравнения, оценки максимального правдоподобия для этой задачи и являются предвзятыми и имеют более высокую среднеквадратическую ошибку .


Характеристики
[ редактировать ]Последовательность и эффективность
[ редактировать ]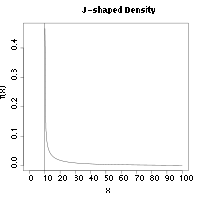

Оценка максимального интервала является последовательной оценкой в том смысле, что она сходится по вероятности к истинному значению параметра θ 0 , когда размер выборки увеличивается до бесконечности. [2] Согласованность оценки максимального расстояния сохраняется при гораздо более общих условиях, чем для оценок максимального правдоподобия . В частности, в случаях, когда базовое распределение имеет J-образную форму, метод максимальной вероятности не будет работать там, где MSE преуспевает. [1] Примером J-образной плотности является распределение Вейбулла , в частности , сдвинутое распределение Вейбулла с параметром формы меньше 1. Плотность будет стремиться к бесконечности по мере того, как x приближается к параметру местоположения, что делает оценки других параметров несогласованными.
Оценщики максимального расстояния также, по крайней мере, так же асимптотически эффективны , как и оценки максимального правдоподобия, если последние существуют. Однако MSE могут существовать в тех случаях, когда MLE отсутствуют. [1]
Чувствительность
[ редактировать ]Оценщики максимального расстояния чувствительны к близко расположенным наблюдениям и особенно к связям. [8] Данный мы получаем


Если связи обусловлены множественными наблюдениями, повторяющиеся интервалы (те, которые в противном случае были бы равны нулю) должны быть заменены соответствующей вероятностью. [1] То есть следует заменить для , как с .




Когда связи возникают из-за ошибки округления, Ченг и Стивенс (1989) предлагают другой метод устранения последствий. [примечание 1] Учитывая r связанных наблюдений от x i до x i + r −1 , пусть δ представляет ошибку округления . Тогда все истинные значения должны попадать в диапазон . Соответствующие точки распределения теперь должны находиться между и . Ченг и Стивенс предлагают предположить, что округленные значения равномерно распределены в этом интервале, определив




Метод MSE также чувствителен к вторичной кластеризации. [8] Одним из примеров этого явления является ситуация, когда считается, что набор наблюдений происходит из одного нормального распределения , но на самом деле он представляет собой смесь нормалей с разными средними значениями. Второй пример – когда считается, что данные поступают из экспоненциального распределения , но на самом деле они происходят из гамма-распределения . В последнем случае в нижнем хвосте могут возникнуть меньшие зазоры. Высокое значение M ( θ ) указывает на этот вторичный эффект кластеризации и предполагает необходимость более внимательного изучения данных. [8]
тест Морана
[ редактировать ]Статистика S n ( θ ) также является формой статистики Морана или Морана-Дарлинга, M ( θ ), которую можно использовать для проверки согласия . [примечание 2] Было показано, что статистика, определяемая как является асимптотически нормальным , и что приближение хи-квадрат существует для небольших выборок. [8] В случае, когда мы знаем истинный параметр , Ченг и Стивенс (1989) показывают, что статистика имеет нормальное распределение с где γ — постоянная Эйлера–Машерони , равная примерно 0,57722. [примечание 3]




Распределение также можно аппроксимировать распределением , где ,в котором и где следует распределению хи-квадрат с степени свободы . Поэтому для проверки гипотезы что случайная выборка значения происходят из распределения , статистика можно рассчитать. Затем следует отвергнуть со значением если значение больше критического значения соответствующего распределения хи-квадрат. [8]









Где θ 0 оценивается по формуле , Ченг и Стивенс (1989) показали, что имеет то же асимптотическое среднее и дисперсию, что и в известном случае. Однако используемая тестовая статистика требует добавления поправки на поправку и выглядит следующим образом: где — количество параметров в оценке.




Обобщенный максимальный интервал
[ редактировать ]Альтернативные размеры и интервалы
[ редактировать ]Раннеби и Экстрем (1997) обобщили метод MSE для аппроксимации других мер, помимо меры Кульбака – Лейблера. Экстрем (1997) еще больше расширил метод для исследования свойств оценщиков с использованием интервалов более высокого порядка, где интервал m -порядка будет определяться как .

Многомерные распределения
[ редактировать ]Раннеби и др. (2005) обсуждают расширенные методы максимального расстояния для многомерного случая. Поскольку не существует естественного порядка , они обсуждают два альтернативных подхода: геометрический подход, основанный на ячейках Дирихле , и вероятностный подход, основанный на метрике «шара ближайшего соседа».

См. также
[ редактировать ]Примечания
[ редактировать ]- ↑ Судя по всему, в статье есть небольшие опечатки. Например, в разделе 4.2 уравнение (4.1), замена округления для , не должно иметь термина журнала. В разделе 1 уравнение (1.2) определяется как само расстояние, и представляет собой отрицательную сумму журналов . Если регистрируется на этом этапе, результат всегда ≤ 0, поскольку разница между двумя соседними точками в кумулятивном распределении всегда ≤ 1 и строго < 1, если только на концах книг нет только двух точек. Также в разделе 4.3 на стр. 392 расчет показывает, что это дисперсия который имеет оценку MPS 6,87, а не стандартное отклонение . – Редактор
- ^ В литературе соответствующие статистические данные называются статистикой Морана или статистикой Морана-Дарлинга. Например, Ченг и Стивенс (1989) анализируют форму где определяется, как указано выше. Вонг и Ли (2006) также используют ту же форму. Однако Бейрлант и др. (2001) использует форму , с дополнительным коэффициентом внутри зарегистрированного суммирования. Дополнительные факторы будут иметь значение с точки зрения ожидаемого среднего значения и дисперсии статистики. Для единообразия в этой статье по-прежнему будет использоваться форма Ченг и Амин/Вонг и Ли. -- Редактор
- ^ Вонг и Ли (2006) исключили из своего описания константу Эйлера-Машерони . -- Редактор








Ссылки
[ редактировать ]Цитаты
[ редактировать ]Цитируемые работы
[ редактировать ]- Анатольев Станислав; Косенок, Григорий (2005). «Альтернатива максимальной вероятности на основе расстояний» (PDF) . Эконометрическая теория . 21 (2): 472–476. CiteSeerX 10.1.1.494.7340 . дои : 10.1017/S0266466605050255 . S2CID 123004317 . Проверено 21 января 2009 г.
- Бейрлант, Дж.; Дудевич, Э.Дж.; Дьерфи, Л.; ван дер Мейлен, ЕС (1997). «Непараметрическая оценка энтропии: обзор» (PDF) . Международный журнал математических и статистических наук . 6 (1): 17–40. ISSN 1055-7490 . Архивировано из оригинала (PDF) 5 мая 2005 г. Проверено 31 декабря 2008 г. Примечание: связанный документ представляет собой обновленную версию 2001 года.
- Ченг, RCH; Амин, НАК (1983). «Оценка параметров в непрерывных одномерных распределениях со смещенным началом». Журнал Королевского статистического общества, серия B. 45 (3): 394–403. дои : 10.1111/j.2517-6161.1983.tb01268.x . ISSN 0035-9246 . JSTOR 2345411 .
- Ченг, RCH; Стивенс, Массачусетс (1989). «Тест согласия с использованием статистики Морана с оценочными параметрами». Биометрика . 76 (2): 386–392. дои : 10.1093/biomet/76.2.385 .
- Экстрем, Магнус (1997). «Обобщенные оценки максимального расстояния» . Университет Умео, математический факультет . 6 . ISSN 0345-3928 . Архивировано из оригинала 14 февраля 2007 года . Проверено 30 декабря 2008 г.
- Холл, MJ; ван ден Бугаард, HFP; Фернандо, RC; Минетт, А.Е. (2004). «Построение доверительных интервалов для частотного анализа с использованием методов повторной выборки» . Гидрология и науки о системе Земли . 8 (2): 235–246. дои : 10.5194/hess-8-235-2004 . ISSN 1027-5606 .
- Печяк, Томаш (2014). Оценка максимального пространственного шума в данных фоновой МРТ с одной катушкой (PDF) . Международная конференция IEEE по обработке изображений. Париж. стр. 1743–1747 . Проверено 7 июля 2015 г.
- Пайк, Рональд (1965). «Пространства». Журнал Королевского статистического общества, серия B. 27 (3): 395–449. дои : 10.1111/j.2517-6161.1965.tb00602.x . ISSN 0035-9246 . JSTOR 2345793 .
- Раннеби, Бо (1984). «Метод максимального интервала. Метод оценки, связанный с методом максимального правдоподобия». Скандинавский статистический журнал . 11 (2): 93–112. ISSN 0303-6898 . JSTOR 4615946 .
- Раннеби, Бо; Экстрем, Магнус (1997). «Оценки максимального расстояния на основе различных показателей» . Университет Умео, математический факультет . 5 . ISSN 0345-3928 . Архивировано из оригинала 14 февраля 2007 года . Проверено 30 декабря 2008 г.
- Раннеби, Бо; Джаммаламадакаб, С. Рао; Тетеруковский, Алексей (2005). «Оценка максимального расстояния для многомерных наблюдений» (PDF) . Журнал статистического планирования и выводов . 129 (1–2): 427–446. дои : 10.1016/j.jspi.2004.06.059 . Проверено 31 декабря 2008 г.
- Вонг, ТСТ; Ли, В.К. (2006). «Примечание об оценке распределений экстремальных значений с использованием максимального произведения расстояний». Временные ряды и сопутствующие темы: памяти Чинг-Цун Вэя . Конспект лекций Института математической статистики – Серия монографий. Бичвуд, Огайо: Институт математической статистики. стр. 272–283. arXiv : math/0702830v1 . дои : 10.1214/074921706000001102 . ISBN 978-0-940600-68-3 . S2CID 88516426 .