Statistical hypothesis test, mostly using multiple restrictions
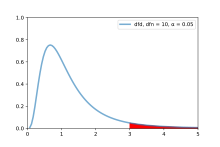
PDF-файл f-теста с d1 и d2 = 10, при уровне значимости 0,05. (Область, заштрихованная красным, указывает на критическую область)
F - тест — это любой статистический тест, используемый для сравнения дисперсий двух выборок или отношения дисперсий между несколькими выборками. Тестовая статистика , случайная величина F, используется для определения того, имеют ли тестируемые данные F -распределение при истинной нулевой гипотезе и истинных обычных предположениях об ошибке (ε). [1] Чаще всего его используют при сравнении статистических моделей , подогнанных к набору данных , чтобы определить модель, которая лучше всего соответствует совокупности , из которой были отобраны данные. Точные « F -тесты» в основном возникают, когда модели аппроксимируются данными с использованием метода наименьших квадратов . Название было придумано Джорджем Снедекором в честь Рональда Фишера . Первоначально Фишер разработал эту статистику как коэффициент дисперсии в 1920-х годах. [2]
Распространенные примеры использования F -тестов включают изучение следующих случаев
Таблица одностороннего дисперсионного анализа с 3 случайными группами, каждая из которых имеет 30 наблюдений. Значение F рассчитывается в предпоследнем столбце Гипотеза о том, что средние значения данного набора нормально распределенных совокупностей, имеющих одинаковое стандартное отклонение , равны. Это, пожалуй, самый известный F -тест, играющий важную роль в дисперсионном анализе (ANOVA).
Гипотеза о том, что набор данных в регрессионном анализе соответствует более простой из двух предложенных линейных моделей, вложенных друг в друга.
Тестирование множественного сравнения проводится с использованием необходимых данных в уже выполненном F-тесте, если F-тест приводит к отклонению нулевой гипотезы и исследуемый фактор оказывает влияние на зависимую переменную. [1]
Большинство F -тестов возникают при рассмотрении разложения изменчивости набора данных по суммам квадратов . Статистика теста в F -тесте представляет собой соотношение двух масштабированных сумм квадратов, отражающих разные источники изменчивости. Эти суммы квадратов построены таким образом, что статистика имеет тенденцию к увеличению, когда нулевая гипотеза неверна. Чтобы статистика соответствовала F -распределению при нулевой гипотезе, суммы квадратов должны быть статистически независимыми , и каждая из них должна соответствовать масштабированному χ²-распределению . Последнее условие гарантируется, если значения данных независимы и нормально распределены с общей дисперсией .
«Объяснимая дисперсия» или «межгрупповая изменчивость»
где обозначает выборочное среднее в i -й группе, — количество наблюдений в i -й группе, обозначает общее среднее значение данных, а обозначает количество групп.
«Необъяснимая дисперсия» или «внутригрупповая изменчивость»
где это Дж й наблюдение в i й из группы и общий размер выборки. Эта F -статистика следует F -распределению со степенями свободы. и при нулевой гипотезе. Статистика будет большой, если межгрупповая изменчивость велика по сравнению с внутригрупповой изменчивостью, что маловероятно, если генеральные средние группы имеют одинаковое значение.
Таблица F: Уровень 5% Критические значения, содержащие степени свободы как для знаменателя, так и для числителя в диапазоне от 1 до 20.
Результат теста F можно определить путем сравнения расчетного значения F и критического значения F с определенным уровнем значимости (например, 5%). Таблица F служит справочным руководством, содержащим критические значения F для распределения F-статистики при предположении истинной нулевой гипотезы. Он разработан, чтобы помочь определить порог, за которым ожидается, что статистика F превысит контролируемый процент времени (например, 5%), когда нулевая гипотеза точна. Чтобы найти критическое значение F в таблице F, необходимо использовать соответствующие степени свободы. Это предполагает определение соответствующей строки и столбца в таблице F, которые соответствуют проверяемому уровню значимости (например, 5%). [6]
Как использовать критические значения F:
Если статистика F < критического значения F
Не удалось отвергнуть нулевую гипотезу
Отклонить альтернативную гипотезу
Между средними выборками существенных различий нет.
Наблюдаемые различия между средними значениями выборки могут быть обоснованно вызваны самой случайностью.
Результат не является статистически значимым
Если статистика F > критического значения F
Примите альтернативную гипотезу
Отклонить нулевую гипотезу
Между средними выборками наблюдаются значительные различия
Наблюдаемые различия между средними значениями выборки не могут быть обоснованно вызваны случайностью как таковой.
Результат статистически значим
Обратите внимание, что если для одностороннего F -теста ANOVA есть только две группы, где t — студенческий статистика .
Эффективность сравнения нескольких групп: облегчение одновременного сравнения нескольких групп, повышение эффективности, особенно в ситуациях с участием более двух групп.
Ясность в сравнении дисперсий: предлагает прямую интерпретацию дисперсионных различий между группами, что способствует четкому пониманию наблюдаемых закономерностей данных.
Универсальность в разных дисциплинах: демонстрация широкой применимости в различных областях, включая социальные науки, естественные науки и инженерию.
Чувствительность к предположениям. F-тест очень чувствителен к определенным предположениям, таким как однородность дисперсии и нормальность, которые могут повлиять на точность результатов теста.
Ограниченная область применения для групповых сравнений. F-критерий предназначен для сравнения различий между группами, что делает его менее подходящим для анализа, выходящего за рамки этой конкретной области.
Проблемы интерпретации: F-тест не выявляет конкретные пары групп с явными отклонениями. Необходима тщательная интерпретация, а дополнительные апостериорные тесты часто необходимы для более детального понимания групповых различий.
F - тест в однофакторном дисперсионном анализе ( ANOVA ) используется для оценки того, отличаются ли друг от друга ожидаемые значения количественной переменной в пределах нескольких заранее определенных групп. Например, предположим, что в медицинском исследовании сравниваются четыре метода лечения. -тест ANOVA F можно использовать для оценки того, превосходит или уступает какой-либо из методов лечения другие в сравнении с нулевой гипотезой о том, что все четыре метода лечения дают одинаковый средний ответ. Это пример «омнибусного» теста, означающего, что один тест выполняется для обнаружения любого из нескольких возможных различий. В качестве альтернативы мы могли бы провести попарные тесты среди методов лечения (например, в примере медицинского исследования с четырьмя методами лечения мы могли бы провести шесть тестов среди пар методов лечения). Преимущество F -теста ANOVA состоит в том, что нам не нужно заранее указывать, какие методы лечения следует сравнивать, и нам не нужно делать поправку для проведения множественных сравнений . Недостатком F -теста ANOVA является то, что если мы отклоним При нулевой гипотезе мы не знаем, какие методы лечения, можно сказать, значительно отличаются от других, а также, если F -тест выполняется на уровне α, мы не можем утверждать, что пара методов лечения с наибольшей средней разницей значительно отличается на уровне α.
Рассмотрим две модели, 1 и 2, где модель 1 «вложена» в модель 2. Модель 1 — это ограниченная модель, а модель 2 — неограниченная. То есть модель 1 имеет параметры p 1 , а модель 2 имеет параметры p 2 , где p 1 < p 2 , и для любого выбора параметров в модели 1 одна и та же кривая регрессии может быть получена путем некоторого выбора параметров модели. 2.
Одним из распространенных контекстов в этом отношении является принятие решения о том, соответствует ли модель данным значительно лучше, чем это делает наивная модель, в которой единственным пояснительным термином является термин-перехват, так что все прогнозируемые значения для зависимой переменной устанавливаются равными значению этой переменной. выборочное среднее. Наивная модель является ограниченной моделью, поскольку коэффициенты всех потенциальных объясняющих переменных ограничены равными нулю.
Другим распространенным контекстом является принятие решения о наличии структурного разрыва в данных: здесь ограниченная модель использует все данные в одной регрессии, тогда как неограниченная модель использует отдельные регрессии для двух разных подмножеств данных. Такое использование F-теста известно как тест Чоу .
Модель с большим количеством параметров всегда сможет соответствовать данным как минимум так же, как и модель с меньшим количеством параметров. Таким образом, обычно модель 2 обеспечивает лучшее соответствие данных (т.е. меньшую ошибку), чем модель 1. Но часто хочется определить, дает ли модель 2 значительно лучшее соответствие данным. Одним из подходов к этой проблеме является использование F -теста.
Если есть n точек данных для оценки параметров обеих моделей, то можно вычислить статистику F , определяемую формулой
где RSS i — остаточная сумма квадратов модели i . Если модель регрессии была рассчитана с весами, замените RSS i на χ 2 , взвешенная сумма квадратов остатков. При нулевой гипотезе, что модель 2 не обеспечивает значительно лучшего соответствия, чем модель 1, F будет иметь распределение F со ( p 2 - p 1 , n - p 2 ) степенями свободы . Нулевая гипотеза отклоняется, если F, рассчитанное на основе данных, превышает критическое значение F -распределения для некоторой желаемой вероятности ложного отклонения (например, 0,05). Поскольку F является монотонной функцией статистики отношения правдоподобия, F -тест является тестом отношения правдоподобия .
Arc.Ask3.Ru Номер скриншота №: b6b7a427b10106a9b4c497a2ec1dbc3b__1704442200 URL1:https://arc.ask3.ru/arc/aa/b6/3b/b6b7a427b10106a9b4c497a2ec1dbc3b.html Заголовок, (Title) документа по адресу, URL1: F-test - Wikipedia
Данный printscreen веб страницы (снимок веб страницы, скриншот веб страницы), визуально-программная копия документа расположенного по адресу URL1 и сохраненная в файл, имеет: квалифицированную, усовершенствованную (подтверждены: метки времени, валидность сертификата), открепленную ЭЦП (приложена к данному файлу), что может быть использовано для подтверждения содержания и факта существования документа в этот момент времени. Права на данный скриншот принадлежат администрации Ask3.ru, использование в качестве доказательства только с письменного разрешения правообладателя скриншота. Администрация Ask3.ru не несет ответственности за информацию размещенную на данном скриншоте. Права на прочие зарегистрированные элементы любого права, изображенные на снимках принадлежат их владельцам. Качество перевода предоставляется как есть. Любые претензии, иски не могут быть предъявлены. Если вы не согласны с любым пунктом перечисленным выше, вы не можете использовать данный сайт и информация размещенную на нем (сайте/странице), немедленно покиньте данный сайт. В случае нарушения любого пункта перечисленного выше, штраф 55! (Пятьдесят пять факториал, Денежную единицу (имеющую самостоятельную стоимость) можете выбрать самостоятельно, выплаичвается товарами в течение 7 дней с момента нарушения.)