Начальная загрузка (статистика)
Начальная загрузка — это любой тест или метрика, в которых используется случайная выборка с заменой (например, имитация процесса выборки) и подпадает под более широкий класс методов повторной выборки . Бутстрэппинг назначает меры точности ( смещение , дисперсия, доверительные интервалы , ошибка прогноза и т. д.) выборочным оценкам. [1] [2] Этот метод позволяет оценить выборочное распределение практически любой статистики с использованием методов случайной выборки. [3] [4]
Бутстрэппинг оценивает свойства оценки ( например, ее дисперсию ) путем измерения этих свойств при выборке из аппроксимирующего распределения. Одним из стандартных вариантов аппроксимирующего распределения является эмпирическая функция распределения наблюдаемых данных. В случае, когда можно предположить, что набор наблюдений принадлежит независимой и одинаково распределенной совокупности, это можно реализовать путем построения ряда повторных выборок с заменой наблюдаемого набора данных (и равного размера наблюдаемому набору данных). .
Его также можно использовать для построения тестов гипотез . [5] Его часто используют как альтернативу статистическому выводу, основанному на предположении о параметрической модели, когда это предположение вызывает сомнение или когда параметрический вывод невозможен или требует сложных формул для расчета стандартных ошибок .
История [ править ]
Бутстрап был опубликован Брэдли Эфроном в книге «Методы бутстрапа: еще один взгляд на складной нож» (1979). [6] [7] [8] вдохновлен более ранними работами над складным ножом . [9] [10] [11] Усовершенствованные оценки дисперсии были разработаны позже. [12] [13] Байесовское расширение было разработано в 1981 году. [14] Скорректированное и ускоренное смещение ( ) бутстрап был разработан Эфроном в 1987 году, [15] и приблизительный доверительный интервал начальной загрузки (ABC или приблизительный ) процедура в 1992 году. [16] Другими названиями, которые коллеги Эфрона предложили для метода «бутстрепа», были: «Швейцарский армейский нож» , «Мясной топор» , «Лебедь-нырок» , «Джек-кролик» и «Дробовик» . [8]

Подход [ править ]


Основная идея начальной загрузки заключается в том, что выводы о совокупности на основе данных выборки (выборка → популяция) можно смоделировать путем повторной выборки данных выборки и выполнения вывода о выборке на основе повторной выборки данных (повторная выборка → выборка). [17] Поскольку популяция неизвестна, истинная ошибка выборочной статистики относительно ее значения популяции неизвестна. В бутстрап-ресэмплах «популяция» на самом деле является выборкой, и это известно; следовательно, качество вывода «истинной» выборки из данных повторной выборки (повторная выборка → выборка) поддается измерению.
Более формально, бутстреп работает, рассматривая вывод истинного распределения вероятностей J с учетом исходных данных как аналог вывода эмпирического распределения Ĵ с учетом повторной выборки данных. Точность выводов относительно « использования повторной выборки данных» можно оценить, поскольку мы знаем « . Если Ĵ является разумным приближением к J о качестве вывода о J. , то, в свою очередь, можно сделать вывод
В качестве примера предположим, что нас интересует средний (или средний ) рост людей во всем мире. Мы не можем измерить всех людей в мировом населении, поэтому вместо этого мы отбираем лишь крошечную его часть и измеряем ее. Предположим, что размер выборки N ; то есть мы измеряем рост N особей. Из этой единственной выборки можно получить только одну оценку среднего значения. Чтобы рассуждать о численности населения, нам нужно некоторое представление об изменчивости вычисленного нами среднего значения. Самый простой метод начальной загрузки предполагает получение исходного набора данных о высотах и с помощью компьютера выборку из него для формирования новой выборки (называемой «повторной выборкой» или начальной выборкой), которая также имеет размер N . Начальная выборка берется из оригинала с использованием выборки с заменой (например, мы можем «повторить выборку» 5 раз из [1,2,3,4,5] и получить [2,5,4,4,1]), поэтому , предполагая, что N достаточно велико, для всех практических целей существует практически нулевая вероятность того, что он будет идентичен исходному «реальному» образцу. Этот процесс повторяется большое количество раз (обычно 1000 или 10 000 раз), и для каждой из этих бутстрап-выборок мы вычисляем ее среднее значение (каждый из них называется «начальной оценкой»). Теперь мы можем создать гистограмму средств начальной загрузки. Эта гистограмма дает оценку формы распределения выборочного среднего значения, исходя из которой мы можем ответить на вопросы о том, насколько среднее значение варьируется в разных выборках. (Метод, описанный здесь для среднего значения, можно применить практически к любому другому статистика или оценка .)
Обсуждение [ править ]
Этот раздел включает в себя список использованной литературы , связанную литературу или внешние ссылки , но его источники остаются неясными, поскольку в нем отсутствуют встроенные цитаты . ( июнь 2012 г. ) |
Преимущества [ править ]
Большим преимуществом начальной загрузки является ее простота. Это простой способ получить оценки стандартных ошибок и доверительных интервалов для сложных оценок распределения, таких как процентные точки, пропорции, отношение шансов и коэффициенты корреляции. Однако, несмотря на свою простоту, бутстреппинг может применяться к сложным схемам выборки (например, для совокупности, разделенной на s слоев с n s наблюдениями в каждой страте, бутстрэппинг может применяться для каждой страты). [18] Bootstrap также является подходящим способом контроля и проверки стабильности результатов. Хотя для большинства задач невозможно узнать истинный доверительный интервал, бутстреп асимптотически более точен, чем стандартные интервалы, полученные с использованием выборочной дисперсии и предположений о нормальности. [19] Начальная загрузка также является удобным методом, который позволяет избежать затрат на повторение эксперимента для получения других групп выборочных данных.
Недостатки [ править ]
Начальная загрузка во многом зависит от используемого средства оценки, и, хотя она и проста, но наивна, использование начальной загрузки не всегда дает асимптотически достоверные результаты и может привести к несогласованности. [20] Хотя бутстрэппинг (при некоторых условиях) асимптотически непротиворечив , он не обеспечивает общих гарантий конечной выборки. Результат может зависеть от репрезентативной выборки. За кажущейся простотой может скрываться тот факт, что при проведении бутстреп-анализа делаются важные допущения (например, независимость выборок или достаточно большой размер выборки), тогда как в других подходах они были бы сформулированы более формально. Кроме того, начальная загрузка может занять много времени, а доступного программного обеспечения для начальной загрузки не так много, поскольку ее сложно автоматизировать с использованием традиционных статистических компьютерных пакетов. [18]
Рекомендации [ править ]
Ученые рекомендовали больше образцов начальной загрузки, поскольку доступная вычислительная мощность увеличилась. Если результаты могут иметь существенные последствия для реальной жизни, следует использовать столько образцов, сколько это разумно, учитывая доступную вычислительную мощность и время. Увеличение количества выборок не может увеличить объем информации в исходных данных; он может только уменьшить влияние ошибок случайной выборки, которые могут возникнуть в самой процедуре начальной загрузки. Более того, есть свидетельства того, что количество выборок, превышающее 100, приводит к незначительному улучшению оценки стандартных ошибок. [21] Фактически, по словам первоначального разработчика метода начальной загрузки, даже установка количества выборок, равного 50, скорее всего, приведет к довольно хорошим оценкам стандартной ошибки. [22]
Адер и др. рекомендуем процедуру начальной загрузки для следующих ситуаций: [23]
- Когда теоретическое распределение интересующей статистики сложно или неизвестно. Поскольку процедура начальной загрузки не зависит от распределения, она обеспечивает косвенный метод оценки свойств распределения, лежащего в основе выборки, и интересующих параметров, полученных из этого распределения.
- Когда размер выборки недостаточен для простого статистического вывода. Если основное распределение хорошо известно, бутстрэппинг дает возможность учесть искажения, вызванные конкретной выборкой, которая может не быть полностью репрезентативной для генеральной совокупности.
- Когда расчеты мощности необходимо выполнить и доступен небольшой пилотный образец. Большинство расчетов мощности и размера выборки сильно зависят от стандартного отклонения интересующей статистики. Если использованная оценка неверна, требуемый размер выборки также будет неправильным. Один из способов получить представление об изменении статистики — использовать небольшую пилотную выборку и выполнить на ней начальную загрузку, чтобы получить представление об дисперсии.
Однако Атрея показала [24] что если кто-то выполняет наивный бутстреп для выборочного среднего, когда базовая совокупность не имеет конечной дисперсии (например, степенное распределение ), то бутстреп-распределение не будет сходиться к тому же пределу, что и выборочное среднее. В результате доверительные интервалы, полученные на основе Монте-Карло, моделирования бутстрапа методом могут вводить в заблуждение. Атрея утверждает, что «если нет достаточной уверенности в том, что базовое распределение не является тяжелохвостым , следует колебаться в использовании наивной начальной загрузки».
Типы схем начальной загрузки [ править ]
Этот раздел включает в себя список использованной литературы , связанную литературу или внешние ссылки , но его источники остаются неясными, поскольку в нем отсутствуют встроенные цитаты . ( июнь 2012 г. ) |
В одномерных задачах обычно приемлемо выполнить повторную выборку отдельных наблюдений с заменой («повторная выборка случая» ниже) в отличие от подвыборки , в которой повторная выборка осуществляется без замены и действительна при гораздо более слабых условиях по сравнению с бутстрапом. В небольших выборках может быть предпочтительнее параметрический подход. Для других проблем, плавная загрузка скорее всего, предпочтительнее будет .
Для задач регрессии доступны различные другие альтернативы. [1]
Повторная выборка регистра [ править ]
Бутстрап обычно полезен для оценки распределения статистики (например, среднего значения, дисперсии) без использования предположений о нормальности (как это требуется, например, для z-статистики или t-статистики). В частности, бутстрап полезен, когда нет аналитической формы или асимптотической теории (например, применимой центральной предельной теоремы ), чтобы помочь оценить распределение интересующей статистики. Это связано с тем, что методы начальной загрузки могут применяться к большинству случайных величин, например, к отношению дисперсии и среднего значения. Существует как минимум два способа выполнения повторной выборки регистра.
- Алгоритм Монте-Карло для повторной выборки случаев довольно прост. Сначала мы выполняем повторную выборку данных с заменой, причем размер повторной выборки должен быть равен размеру исходного набора данных. Затем интересующая статистика вычисляется на основе повторной выборки с первого шага. Мы повторяем эту процедуру много раз, чтобы получить более точную оценку распределения статистики Bootstrap. [1]
- «Точная» версия повторной выборки случаев аналогична, но мы исчерпывающе перечисляем все возможные повторные выборки набора данных. Это может быть затратно в вычислительном отношении, поскольку всего существует различные повторные выборки, где n — размер набора данных. Таким образом, для n = 5, 10, 20, 30 имеется 126, 92378, 6,89 × 10. 10 и 5,91 × 10 16 разные ресэмплы соответственно. [25]

Оценка распределения выборочного среднего [ править ]
Рассмотрим эксперимент с подбрасыванием монеты. Мы подбрасываем монету и фиксируем, выпадет ли она орлом или решкой. Пусть X = x 1 , x 2 , …, x 10 — 10 наблюдений из эксперимента. x i = 1 , если при i-м броске выпадает орел, и 0 в противном случае. Принимая во внимание предположение, что среднее значение подбрасываний монеты нормально распределено, мы можем использовать t-статистику для оценки распределения выборочного среднего значения:

Такое предположение о нормальности может быть оправдано либо как приближение распределения каждого отдельного подбрасывания монеты, либо как приближение распределения среднего значения большого количества подбрасываний монеты. Первое — плохое приближение, поскольку истинное распределение подбрасываний монеты — бернуллиевское , а не нормальное. Последнее является допустимым приближением в бесконечно больших выборках благодаря центральной предельной теореме .
Однако, если мы не готовы дать такое обоснование, то вместо этого мы можем использовать бутстрап. Используя повторную выборку случаев, мы можем получить распределение . Сначала мы повторно дискретизируем данные, чтобы получить загрузочную повторную выборку . Пример первой повторной выборки может выглядеть так: X 1 * = x 2 , x 1 , x 10 , x 10 , x 3 , x 4 , x 6 , x 7 , x 1 , x 9 . Есть несколько дубликатов, поскольку повторная выборка начальной загрузки происходит из выборки с заменой данных. Кроме того, количество точек данных в начальной повторной выборке равно количеству точек данных в наших исходных наблюдениях. Затем мы вычисляем среднее значение этой повторной выборки и получаем первое среднее значение начальной загрузки : µ 1 *. Мы повторяем этот процесс, чтобы получить вторую передискретизацию X 2 * и вычислить второе среднее бутстрапа µ 2 *. Если повторить это 100 раз, то имеем µ 1 *, µ 2 *, ..., µ 100 *. Это представляет собой эмпирическое бутстреп-распределение выборочного среднего значения. Из этого эмпирического распределения можно вывести доверительный интервал начальной загрузки для проверки гипотез.

Регрессия [ править ]
В задачах регрессии повторная выборка случаев относится к простой схеме повторной выборки отдельных случаев – часто строк набора данных . Для задач регрессии, если набор данных достаточно велик, эта простая схема часто приемлема. [26] [27] [28] Однако метод открыт для критики. [ нужна ссылка ] . [18]
В задачах регрессии объясняющие переменные часто фиксируются или, по крайней мере, наблюдаются с большим контролем, чем переменная ответа. Кроме того, диапазон объясняющих переменных определяет информацию, доступную от них. Таким образом, повторная выборка случаев означает, что каждая начальная выборка потеряет некоторую информацию. Таким образом, следует рассмотреть альтернативные процедуры начальной загрузки.
Байесовский бутстрап [ править ]
Начальную загрузку можно интерпретировать в рамках байесовской схемы, используя схему, которая создает новые наборы данных путем изменения веса исходных данных. Учитывая набор точки данных, вес, присвоенный точке данных в новом наборе данных является , где представляет собой упорядоченный список от низкого к высокому равномерно распределенные случайные числа на , которому предшествует 0 и за которым следует 1. Распределения параметра, полученные в результате рассмотрения многих таких наборов данных затем интерпретируются как апостериорные распределения по этому параметру. [29]






![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)
Гладкая начальная загрузка [ править ]
В соответствии с этой схемой к каждому повторному наблюдению добавляется небольшое количество (обычно нормально распределенного) случайного шума с нулевым центром. Это эквивалентно выборке из оценки плотности ядра данных. Предположим, что K — симметричная функция плотности ядра с единичной дисперсией. Стандартный оценщик ядра из является



где — параметр сглаживания. И соответствующая оценка функции распределения является



Параметрический бутстрап [ править ]
Основываясь на предположении, что исходный набор данных представляет собой реализацию случайной выборки из распределения определенного параметрического типа, в этом случае параметрическая модель аппроксимируется параметром θ, часто по максимальному правдоподобию , а выборки случайных чисел извлекаются из эта пригнанная модель. Обычно полученная выборка имеет тот же размер, что и исходные данные. Тогда оценку исходной функции F можно записать в виде . Этот процесс выборки повторяется много раз, как и для других методов начальной загрузки. Учитывая центрированное выборочное среднее в этом случае, исходная функция распределения случайной выборки заменяется бутстрап-случайной выборкой с функцией и вероятностей распределение аппроксимируется , где , что является ожиданием, соответствующим . [31] Использование параметрической модели на этапе выборки методологии начальной загрузки приводит к процедурам, которые отличаются от процедур, полученных путем применения базовой статистической теории к выводу для той же модели.






Повторная выборка остатков [ править ]
Другой подход к начальной загрузке в задачах регрессии заключается в повторной выборке остатков . Способ осуществляется следующим образом.
- Подберите модель и сохраните подобранные значения и остатки .
- Для каждой пары ( x i , y i ), в которой x i является объясняющей переменной (возможно, многомерной), добавьте случайно перевыбранный остаток, , до установленного значения . Другими словами, создайте синтетические переменные отклика. где j выбирается случайным образом из списка (1,..., n ) для каждого i .
- Переоборудуйте модель, используя вымышленные переменные отклика. и сохранить интересующие величины (часто параметры, , оцененный по синтетическому ).
- Повторите шаги 2 и 3 большое количество раз.






Преимущество этой схемы состоит в том, что она сохраняет информацию в независимых переменных. Однако возникает вопрос, какие остатки следует передискретизировать. Необработанные остатки являются одним из вариантов; другой — стьюдентизированные остатки (в линейной регрессии). Хотя есть аргументы в пользу использования стьюдентизированных остатков; на практике это часто не имеет большого значения, и результаты обеих схем легко сравнить.
Бутстрап регрессии гауссовского процесса [ править ]
Когда данные коррелированы во времени, простая начальная загрузка разрушает присущие корреляции. Этот метод использует регрессию гауссовского процесса (GPR) для соответствия вероятностной модели, из которой затем можно извлечь реплики. Георадар — это метод байесовской нелинейной регрессии. Гауссов процесс (ГП) — это совокупность случайных величин, любое конечное число которых имеет совместное гауссово (нормальное) распределение. GP определяется средней функцией и функцией ковариации, которые определяют средние векторы и ковариационные матрицы для каждого конечного набора случайных величин. [32]
Регрессионная модель:
- это шумовой термин.


Гауссов процесс до:
Для любого конечного набора переменных x 1 , ..., x n функция выводит совместно распределяются в соответствии с многомерной гауссианой со средним значением и ковариационная матрица

![{\displaystyle m=[m(x_{1}),\ldots ,m(x_{n})]^{\intercal }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1ac3abe6a55b4d0a9df7db10e0c36a58453121a5)

Предполагать Затем ,


где , и — стандартная дельта-функция Кронекера. [32]


Гауссов процесс сзади:
По словам терапевта, мы можем получить
- ,
![{\displaystyle [y(x_{1}),\ldots ,y(x_{r})]\sim {\mathcal {N}}(m_{0},K_{0})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a44b791e07518721a4bf8b6b0c3df9a90e24e47e)
где и
![{\displaystyle m_{0}=[m(x_{1}),\ldots ,m(x_{r})]^{\intercal }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a7d40a77e82bd278ecea9d13421f38a71ff88bbf)

Пусть х 1 * ,...,х с * быть еще одним конечным набором переменных, очевидно, что
- ,
![{\displaystyle [y(x_{1}),\ldots,y(x_{r}),f(x_{1}^{*}),\ldots,f(x_{s}^{*})] ^{\intercal }\sim {\mathcal {N}}({\binom {m_{0}}{m_{*}}}{\begin{pmatrix}K_{0}&K_{*}\\K_{* }^{\intercal }&K_{**}\end{pmatrix}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0664dc735f8ff5cc3b0f33671b1d0a2bdbb163db)
где , ,
![{\displaystyle m_{*}=[m(x_{1}^{*}),\ldots ,m(x_{s}^{*})]^{\intercal }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f24edcf8081b605823994e85e6c746c87d75a911)


Согласно приведенным выше уравнениям, выходные данные y также совместно распределяются в соответствии с многомерной гауссианой. Таким образом,
![{\displaystyle [f(x_{1}^{*}),\ldots ,f(x_{s}^{*})]^{\intercal }\mid ([y(x)]^{\intercal } =y)\sim {\mathcal {N}}(m_{\text{post}},K_{\text{post}}),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8f2dac075f685480962738fefb076bdf3fee90a4)
где , , , и является идентификационная матрица. [32]
![{\displaystyle y=[y_{1},...,y_{r}]^{\intercal }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc7e5927b40b3dc44746d2f644d0534278b268da)




Дикий бутстрап [ править ]
«Дикий бутстрап», первоначально предложенный Ву (1986), [33] подходит, когда модель демонстрирует гетероскедастичность . Идея состоит в том, чтобы, как и в случае с остаточным бутстрапом, оставить регрессоры с их выборочным значением, но выполнить повторную выборку переменной ответа на основе значений остатков. То есть для каждого повтора вычисляется новый на основе


поэтому остатки случайным образом умножаются на случайную величину со средним значением 0 и дисперсией 1. Для большинства распределений (но не метод Маммена), этот метод предполагает, что «истинное» распределение остатков симметрично и может иметь преимущества перед простой остаточной выборкой для выборок меньшего размера. Для случайной величины используются разные формы , такой как

- Стандартное нормальное распределение
- Распределение, предложенное Мамменом (1993). [34]

- Примерно распределение Маммена таково:

- Или более простое распределение, связанное с распределением Радемахера :

Блокировать начальную загрузку [ править ]
Блочная загрузка используется, когда данные или ошибки в модели коррелируют. В этом случае простой случай или остаточная повторная выборка потерпят неудачу, поскольку не смогут воспроизвести корреляцию в данных. Блоковая загрузка пытается воспроизвести корреляцию путем повторной выборки внутри блоков данных (см. Блокировка (статистика) ). Блочная загрузка использовалась в основном с данными, коррелированными во времени (т.е. временными рядами), но также может использоваться с данными, коррелированными в пространстве или между группами (так называемые кластерные данные).
Временной ряд: простой блочный бутстрап [ править ]
В (простом) блочном бутстрапе интересующая переменная разбивается на непересекающиеся блоки.
: начальная загрузка движущегося Временной ряд блока
В бутстрапе движущегося блока, предложенном Кюншем (1989), [35] данные разбиваются на n − b + 1 перекрывающиеся блоки длины b : наблюдения от 1 до b будут блоком 1, наблюдения от 2 до b + 1 будут блоком 2 и т. д. Затем из этих n − b + 1 блоков получится n / b. блоки будут рисоваться случайным образом с заменой. Затем выравнивание этих n/b блоков в том порядке, в котором они были выбраны, даст бутстрап-наблюдения.
Этот бутстрап работает с зависимыми данными, однако бутстреп-наблюдения больше не будут стационарными по своей конструкции. Однако было показано, что случайное изменение длины блока позволяет избежать этой проблемы. [36] Этот метод известен как стационарный бутстрап. Другими связанными модификациями бутстрапа с подвижным блоком являются марковский бутстрап и метод стационарного бутстрапа, который сопоставляет последующие блоки на основе сопоставления стандартного отклонения.
Временной ряд: энтропии максимальной бутстрап
Винод (2006), [37] представляет метод, который загружает данные временных рядов с использованием принципов максимальной энтропии, удовлетворяющих эргодической теореме, с ограничениями, сохраняющими среднее и сохраняющее массу. Есть пакет R, meboot , [38] в котором используется метод, который находит применение в эконометрике и информатике.
Данные кластера: блок начальной загрузки [ править ]
Данные кластера описывают данные, в которых наблюдается множество наблюдений на единицу. Это может быть наблюдение за многими фирмами во многих штатах или наблюдение за студентами во многих классах. В таких случаях структура корреляции упрощается, и обычно делается предположение, что данные коррелируют внутри группы/кластера, но независимы между группами/кластерами. Легко получить структуру блочного бутстрапа (где блок просто соответствует группе), и обычно передискретизация выполняется только для групп, а наблюдения внутри групп остаются неизменными. Кэмерон и др. (2008) обсуждает это для кластерных ошибок в линейной регрессии. [39]
Методы повышения эффективности вычислений [ править ]
Начальная загрузка — это мощный метод, хотя он может потребовать значительных вычислительных ресурсов как по времени, так и по памяти. Для уменьшения этого бремени были разработаны некоторые методы. Как правило, их можно комбинировать со многими различными типами схем Bootstrap и различными вариантами статистики.
Пуассоновский бутстрап [ править ]
Обычный бутстрап требует случайного выбора n элементов из списка, что эквивалентно выборке из биномиального распределения. Это может потребовать большого количества проходов по данным, и параллельное выполнение этих вычислений затруднительно. Для больших значений n загрузка Пуассона является эффективным методом создания наборов данных с начальной загрузкой. [40] При создании одной бутстреп-выборки вместо случайного извлечения данных из выборки с заменой каждой точке данных присваивается случайный вес, распределенный в соответствии с распределением Пуассона с . Для данных большой выборки это будет приближаться к случайной выборке с заменой. Это связано со следующим приближением:


Этот метод также хорошо подходит для потоковой передачи данных и увеличения наборов данных, поскольку общее количество выборок не обязательно должно быть известно до начала отбора бутстрап-выборок.
Для достаточно большого n результаты относительно аналогичны первоначальным бутстреп-оценкам. [41]
Способ улучшения пуассоновской начальной загрузки, называемый «последовательной начальной загрузкой», состоит в том, чтобы взять первые выборки так, чтобы доля уникальных значений составляла ≈0,632 от исходного размера выборки n. Это обеспечивает распределение, в котором основные эмпирические характеристики находятся на расстоянии . [42] Эмпирические исследования показали, что этот метод может дать хорошие результаты. [43] Это связано с методом сокращенной начальной загрузки. [44]

Сумка с маленькими ботинками [ править ]
Для больших наборов данных часто бывает невозможно с вычислительной точки зрения хранить все выборочные данные в памяти и выполнять повторную выборку из выборочных данных. Сумка с маленькими ботинками (BLB) [45] предоставляет метод предварительного агрегирования данных перед начальной загрузкой, чтобы уменьшить вычислительные ограничения. Это работает путем разделения набора данных на сегменты одинакового размера и агрегирование данных внутри каждого сегмента. Этот предварительно агрегированный набор данных становится новыми данными выборки, на основе которых строятся выборки с заменой. Этот метод похож на Block Bootstrap, но мотивы и определения блоков сильно различаются. При определенных предположениях распределение выборки должно приближаться к сценарию полной начальной загрузки. Одним из ограничений является количество сегментов. где и авторы рекомендуют использовать как общее решение.


![{\displaystyle \gamma \in [0,5,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb6affd7567b75316994441dd287a68607d2c844)

Выбор статистики [ править ]
Бутстреп-распределение точечной оценки параметра совокупности использовалось для создания бутстрепированного доверительного интервала для истинного значения параметра, если параметр можно записать как функцию распределения совокупности .
Параметры популяции оцениваются с помощью многих точечных оценок . Популярные семейства точечных оценок включают несмещенные по среднему оценки с минимальной дисперсией , несмещенные по медиане оценки , байесовские оценки (например, апостериорного распределения , режим медиана , среднее ) и оценки максимального правдоподобия .
, байесовская точечная оценка и оценка максимального правдоподобия имеют хорошие характеристики, когда размер выборки бесконечен Согласно асимптотической теории . Для практических задач с конечными выборками другие средства оценки могут быть предпочтительнее. Асимптотическая теория предлагает методы, которые часто улучшают производительность самонастраивающихся оценок; начальную загрузку оценки максимального правдоподобия часто можно улучшить с помощью преобразований, связанных с основными величинами . [46]
Получение доверительных интервалов из бутстрап-распределения [ править ]
Бутстреп-распределение средства оценки параметра использовалось для расчета доверительных интервалов для его параметра совокупности. [1]
Смещение, асимметрия интервалы и доверительные
- Смещение : бутстреп-распределение и выборка могут систематически не расходиться, и в этом случае может возникнуть смещение .
- Если бутстреп-распределение оценщика симметрично, то часто используется процентильный доверительный интервал; такие интервалы особенно подходят для несмещенных по медиане оценок минимального риска (относительно функции абсолютных потерь ). Смещение в бутстреп-распределении приведет к смещению доверительного интервала.
- В противном случае, если бутстреп-распределение несимметрично, процентильные доверительные интервалы часто не подходят.
Методы определения доверительных интервалов начальной загрузки [ править ]
Существует несколько методов построения доверительных интервалов на основе бутстреп-распределения реального параметра:
- Базовый бутстрап , [46] также известный как обратный процентильный интервал . [47] Базовый бутстрап представляет собой простую схему построения доверительного интервала: просто берут эмпирические квантили из бутстреп-распределения параметра (см. Дэвисон и Хинкли 1997, уравнение 5.6, стр. 194):
- где обозначает процентиль бутстрепированных коэффициентов .




- Процентильный бутстрап . Перцентильный бутстрап работает аналогично базовому бутстрапу, используя процентили бутстрап-распределения, но с другой формулой (обратите внимание на инверсию левого и правого квантилей):
- где обозначает процентиль бутстрепированных коэффициентов .
- См. Дэвисон и Хинкли (1997, эквивалент 5.18, стр. 203) и Эфрон и Тибширани (1993, эквивалент 13,5, стр. 171).
- Этот метод можно применить к любой статистике. Это будет хорошо работать в случаях, когда бутстрап-распределение симметрично и сосредоточено на наблюдаемой статистике. [48] и где выборочная статистика несмещена по медиане и имеет максимальную концентрацию (или минимальный риск относительно функции потери абсолютного значения). При работе с небольшими размерами выборки (т. е. менее 50) базовый/обратный процентиль и доверительные интервалы процентиля для (например) статистики дисперсии будут слишком узкими. Таким образом, при выборке из 20 точек 90% доверительный интервал будет включать истинную дисперсию только в 78% случаев. [49] Базовые/обратные процентильные доверительные интервалы легче обосновать математически. [50] [47] но в целом они менее точны, чем процентильные доверительные интервалы, и некоторые авторы не рекомендуют их использовать. [47]

- Студенческий бутстрап . Стьюдентизированный бутстрап, также называемый бутстрап-t , рассчитывается аналогично стандартному доверительному интервалу, но заменяет квантили из нормального приближения или аппроксимации Стьюдента квантилями из бутстрап-распределения t-критерия Стьюдента (см. Дэвисон и Хинкли, 1997, уравнение .5.7 стр. 194 и Эфрон и Тибширани 1993 equ 12.22, стр. 160):
- где обозначает процентиль бутстрепированного t-критерия Стьюдента , и — предполагаемая стандартная ошибка коэффициента исходной модели.




- Стьюдентизированный тест обладает оптимальными свойствами, поскольку загружаемая статистика является ключевой (т. е. она не зависит от мешающих параметров , поскольку t-критерий асимптотически следует распределению N(0,1)), в отличие от процентильного бутстрепа.
- Бутстрап с коррекцией смещения – корректирует смещение в распределении начальной загрузки.
- Ускоренный бутстрап - бутстрап с коррекцией смещения и ускорением (BCa), Эфрон (1987), [15] корректирует как смещение, так и асимметрию в бутстреп-распределении. Этот подход точен в самых разных условиях, требует разумных вычислений и дает достаточно узкие интервалы. [15]
проверка гипотез Бутстрап -
Эту статью может потребовать очистки Википедии , чтобы она соответствовала стандартам качества . Конкретная проблема заключается в следующем: существуют и другие бутстрап-тесты. ( Июль 2023 г. ) |
Эфрон и Тибширани [1] предложите следующий алгоритм сравнения средних двух независимых выборок:Позволять быть случайной выборкой из распределения F со средним значением выборки и выборочная дисперсия . Позволять быть другой независимой случайной выборкой из распределения G со средним значением и дисперсия





- Посчитать статистику теста
- Создайте два новых набора данных, значения которых и где является средним значением объединенной выборки.
- Сделайте случайную выборку ( ) размера с заменой от и еще одна случайная выборка ( ) размера с заменой от .
- Посчитать статистику теста
- Повторите 3 и 4 раз (например ) собирать значения тестовой статистики.
- Оцените значение p как где когда условие истинно и 0 в противном случае.














Примеры приложений [ править ]
Этот раздел включает в себя список использованной литературы , связанную литературу или внешние ссылки , но его источники остаются неясными, поскольку в нем отсутствуют встроенные цитаты . ( июнь 2012 г. ) |
Сглаженный бутстрап [ править ]
В 1878 году Саймон Ньюкомб провел наблюдения за скоростью света . [51] Набор данных содержит два выброса , которые сильно влияют на выборочное среднее значение . (Выборочное среднее не обязательно должно быть согласованной оценкой для любого среднего значения генеральной совокупности не должно существовать никакого среднего значения , поскольку для распределения с тяжелым хвостом .) Четко определенной и надежной статистикой для центральной тенденции является выборочная медиана, которая является последовательной и медианной. -несмещенный для медианы населения.
Распределение начальной загрузки данных Newcomb показано ниже. Мы можем уменьшить дискретность бутстреп-распределения, добавив небольшое количество случайного шума к каждой бутстреп-выборке. Обычный выбор — добавить шум со стандартным отклонением для размера выборки n ; этот шум часто извлекается из распределения Стьюдента с n-1 степенями свободы. [52] Это приводит к приблизительно несмещенной оценке дисперсии выборочного среднего значения. [53] Это означает, что выборки, взятые из бутстреп-распределения, будут иметь дисперсию, которая в среднем равна дисперсии всей совокупности.

Гистограммы бутстреп-распределения и плавного бутстреп-распределения показаны ниже. Бутстреп-распределение выборочной медианы имеет лишь небольшое количество значений. Сглаженный бутстрап-дистрибутив имеет более богатую поддержку . Однако обратите внимание, что выбор сглаженной или стандартной процедуры начальной загрузки является благоприятным в каждом конкретном случае и зависит как от базовой функции распределения, так и от оцениваемой величины. [54]
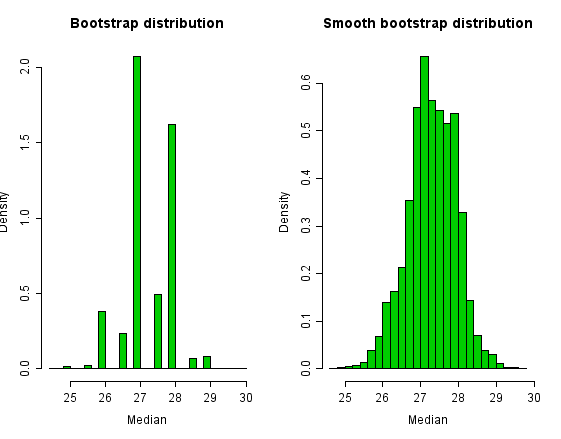
В этом примере 95%-ный (процентиль) доверительный интервал для медианы генеральной совокупности равен (26, 28,5), что близко к интервалу для (25,98, 28,46) для сглаженного бутстрепа.
с другими подходами выводу Связь к
Связь с другими методами передискретизации [ править ]
Бутстрап отличается от:
- процедура складного ножа , используемая для оценки систематических ошибок выборочной статистики и оценки дисперсий, и
- перекрестная проверка , при которой параметры (например, веса регрессии, факторные нагрузки), оцененные в одной подвыборке, применяются к другой подвыборке.
Более подробную информацию см. в разделе передискретизация .
Бутстрап-агрегирование (пакетирование) — это метаалгоритм, основанный на усреднении прогнозов модели, полученных на основе моделей, обученных на нескольких бутстрап-выборках.
U-статистика [ править ]
В ситуациях, когда можно разработать очевидную статистику для измерения требуемой характеристики с использованием лишь небольшого числа r элементов данных, можно сформулировать соответствующую статистику на основе всей выборки. Учитывая статистику r -выборки, можно создать статистику n -выборки с помощью чего-то похожего на начальную загрузку (взяв среднее значение статистики по всем подвыборкам размера r ). Известно, что эта процедура имеет определенные хорошие свойства, и результатом является U-статистика . Выборочное среднее и выборочная дисперсия имеют такую форму для r = 1 и r = 2.
доказательства согласованности бутстрап - оценок Методы
Можно использовать центральную предельную теорему , чтобы показать непротиворечивость бутстреп-процедуры для оценки распределения выборочного среднего.
В частности, рассмотрим независимые одинаково распределенные случайные величины с и для каждого . Позволять . Кроме того, для каждого , при условии , позволять быть независимыми случайными величинами с распределением, равным эмпирическому распределению . Это последовательность образцов начальной загрузки.

![{\displaystyle \mathbb {E} [X_{n1}]=\mu }](https://wikimedia.org/api/rest_v1/media/math/render/svg/16616fa7aae5c68ea292668e1be4b09912511b2b)
![{\displaystyle {\text{Var}}[X_{n1}]=\sigma ^{2}<\infty }](https://wikimedia.org/api/rest_v1/media/math/render/svg/608b3ef8f9245a4ee21895f709c8366fba074e17)



Тогда можно показать, что




Чтобы увидеть это, обратите внимание, что удовлетворяет условию Линдеберга , поэтому CLT выполняется. [55]

Теорема Гливенко – Кантелли обеспечивает теоретическую основу метода бутстрепа.
См. также [ править ]
- Точность и точность
- Бутстрап-агрегирование
- Начальная загрузка
- Эмпирическая вероятность
- Вменение (статистика)
- Надежность (статистика)
- Воспроизводимость
- Передискретизация
Ссылки [ править ]
- ^ Jump up to: Перейти обратно: а б с д и Эфрон, Б .; Тибширани, Р. (1993). Введение в Bootstrap . Бока-Ратон, Флорида: Chapman & Hall/CRC. ISBN 0-412-04231-2 . программное обеспечение. Архивировано 12 июля 2012 г. на archive.today.
- ^ Вторая мысль о бутстрепе - Брэдли Эфрон, 2003 г.
- ^ Вариан, Х. (2005). «Учебник по начальной загрузке». Журнал Mathematica , 9, 768–775.
- ^ Вайсштейн, Эрик В. «Методы начальной загрузки». Из MathWorld — веб-ресурса Wolfram. http://mathworld.wolfram.com/BootstrapMethods.html
- ^ Леманн Э.Л. (1992) «Введение в Неймана и Пирсона (1933) К проблеме наиболее эффективных проверок статистических гипотез». В: Прорывы в статистике, Том 1 (Эдс Коц, С., Джонсон, Н.Л.), Springer-Verlag. ISBN 0-387-94037-5 (с последующим переизданием статьи).
- ^ Примечания к самым ранним известным использованиям некоторых математических слов: Bootstrap (Джон Олдрич)
- ^ Самые ранние известные варианты использования некоторых математических слов (B) (Джефф Миллер)
- ^ Jump up to: Перейти обратно: а б Эфрон, Б. (1979). «Методы начальной загрузки: еще один взгляд на складной нож» . Анналы статистики . 7 (1): 1–26. дои : 10.1214/aos/1176344552 .
- ^ Кенуй М (1949) Приблизительные тесты корреляции во временных рядах. Джей Рой Статист Soc Ser B 11 68–84
- ^ Тьюки Дж. (1958) Предвзятость и уверенность в не совсем больших выборках (аннотация). Энн Математик-статистик 29 614
- ^ Джекель Л. (1972) Бесконечно малый складной нож. Меморандум MM72-1215-11, Bell Lab
- ^ Бикель П., Фриман Д. (1981) Некоторые асимптотические теории бутстрепа. Энн Статист 9 1196–1217 гг.
- ^ Сингх К. (1981) Об асимптотической точности бутстрапа Эфрона . Энн Статист 9 1187–1195 гг.
- ^ Рубин Д (1981). Байесовский бутстрап. Энн Статист 9 130–134
- ^ Jump up to: Перейти обратно: а б с Эфрон, Б. (1987). «Лучшие доверительные интервалы начальной загрузки». Журнал Американской статистической ассоциации . 82 (397). Журнал Американской статистической ассоциации, Vol. 82, № 397: 171–185. дои : 10.2307/2289144 . JSTOR 2289144 .
- ^ Дичичио, Томас; Эфрон, Брэдли (1 июня 1992 г.). «Более точные доверительные интервалы в экспоненциальных семействах» . Биометрика . стр. 231–245. дои : 10.2307/2336835 . ISSN 0006-3444 . OCLC 5545447518 . Проверено 31 января 2024 г.
- ^ Гуд, П. (2006) Методы повторной выборки. 3-е изд. Биркгаузер.
- ^ Jump up to: Перейти обратно: а б с «21 модель регрессии начальной загрузки» (PDF) . Архивировано (PDF) из оригинала 24 июля 2015 г.
- ^ DiCiccio TJ, Efron B (1996) Начальные доверительные интервалы (сОбсуждение). Статистическая наука 11: 189–228.
- ^ Хинкли, Дэвид (1 августа 1994 г.). «[Bootstrap: Больше, чем удар в темноте?]: Комментарий» . Статистическая наука . 9 (3). дои : 10.1214/ss/1177010387 . ISSN 0883-4237 .
- ^ Гудхью, Д.Л., Льюис, В., и Томпсон, Р. (2012). Имеет ли PLS преимущества для небольшого размера выборки или ненормальных данных? MIS Quarterly, 36 (3), 981–1001.
- ^ Эфрон Б., Рогоса Д. и Тибширани Р. (2004). Методы повторной выборки оценки. В Нью-Джерси Смелзере и П. Б. Балтесе (ред.). Международная энциклопедия социальных и поведенческих наук (стр. 13216–13220). Нью-Йорк, штат Нью-Йорк: Эльзевир.
- ^ Адер, HJ , Мелленберг GJ и Хэнд, DJ (2008). Консультирование по методам исследования: Спутник консультанта . Хейзен, Нидерланды: Издательство Йоханнеса ван Кесселя. ISBN 978-90-79418-01-5 .
- ^ Бутстрап среднего значения в случае бесконечной дисперсии Athreya, KB Ann Stats vol 15 (2) 1987 724–731
- ^ «Сколько существует различных образцов начальной загрузки? Statweb.stanford.edu» . Архивировано из оригинала 14 сентября 2019 г. Проверено 9 декабря 2019 г.
- ^ Дженкинс, Дэвид Г.; Кинтана-Асенсио, Педро Ф. (21 февраля 2020 г.). «Решение минимального размера выборки для регрессий» . ПЛОС ОДИН . 15 (2): e0229345. Бибкод : 2020PLoSO..1529345J . дои : 10.1371/journal.pone.0229345 . ISSN 1932-6203 . ПМК 7034864 . ПМИД 32084211 .
- ^ Ламли, Томас (2002). «Важность предположения о нормальности в больших наборах данных общественного здравоохранения» . Ежегодный обзор общественного здравоохранения . 23 : 151–169. doi : 10.1146/annurev.publhealth.23.100901.140546 . ПМИД 11910059 .
- ^ Ли, Сян; Вонг, Ванлин; Ламуре, Экосс Л.; Вонг, Тьен Ю. (01 мая 2012 г.). «Подходят ли методы линейной регрессии для анализа, когда зависимая (результат) переменная не имеет нормального распределения?» . Исследовательская офтальмология и визуальные науки . 53 (6): 3082–3083. дои : 10.1167/iovs.12-9967 . ISSN 1552-5783 . ПМИД 22618757 .
- ^ Рубин, Д.Б. (1981). «Байесовский бутстрап». Анналы статистики , 9, 130.
- ^ Jump up to: Перейти обратно: а б ВАН, СУОДЖИН (1995). «Оптимизация сглаженного бутстрапа». Энн. Инст. Статист. Математика . 47 : 65–80. дои : 10.1007/BF00773412 . S2CID 122041565 .
- ^ Современное введение в вероятность и статистику: понимание почему и как . Деккинг, Мишель (1946 г.р.). Лондон: Спрингер. 2005. ISBN 978-1-85233-896-1 . OCLC 262680588 .
{{cite book}}: CS1 maint: другие ( ссылка ) - ^ Jump up to: Перейти обратно: а б с Кирк, Пол (2009). «Загрузка регрессии гауссовского процесса: изучение последствий неопределенности в данных о динамике времени» . Биоинформатика . 25 (10): 1300–1306. doi : 10.1093/биоинформатика/btp139 . ПМЦ 2677737 . ПМИД 19289448 .
- ^ Ву, CFJ (1986). «Складной нож, бутстрап и другие методы повторной выборки в регрессионном анализе (с обсуждениями)» (PDF) . Анналы статистики . 14 : 1261–1350. дои : 10.1214/aos/1176350142 .
- ^ Маммен, Э. (март 1993 г.). «Бутстрап и дикий бутстрап для линейных моделей большого размера» . Анналы статистики . 21 (1): 255–285. дои : 10.1214/aos/1176349025 .
- ^ Кюнш, HR (1989). «Складной нож и ботинок для общих стационарных наблюдений» . Анналы статистики . 17 (3): 1217–1241. дои : 10.1214/aos/1176347265 .
- ^ Политис, Д.Н.; Романо, JP (1994). «Стационарный бутстрап». Журнал Американской статистической ассоциации . 89 (428): 1303–1313. дои : 10.1080/01621459.1994.10476870 . hdl : 10983/25607 .
- ^ Винод, HD (2006). «Ансамбли максимальной энтропии для вывода временных рядов в экономике». Журнал азиатской экономики . 17 (6): 955–978. doi : 10.1016/j.asieco.2006.09.001 .
- ^ Винод, Хришикеш; Лопес-де-Лакаль, Хавьер (2009). «Максимальная энтропийная загрузка для временных рядов: пакет meboot R» . Журнал статистического программного обеспечения . 29 (5): 1–19. дои : 10.18637/jss.v029.i05 .
- ^ Кэмерон, AC; Гельбах, Дж.Б.; Миллер, Д.Л. (2008). «Усовершенствования на основе начальной загрузки для вывода кластерных ошибок» (PDF) . Обзор экономики и статистики . 90 (3): 414–427. дои : 10.1162/rest.90.3.414 .
- ^ Шаманди, Н; Муралидхаран, О; Наджми, А; Найду, С (2012). «Оценка неопределенности для больших потоков данных» .
- ^ Хэнли, Джеймс А. и Бренда МакГиббон. «Создание непараметрических выборок начальной загрузки с использованием частот Пуассона». компьютерные методы и программы в биомедицине 83.1 (2006): 57-62. PDF
- ^ Бабу, Г. Джогеш, П.К. Патхак и Ч.Р. Рао. «Правильность второго порядка бутстрепа Пуассона». Анналы статистики 27.5 (1999): 1666–1683. связь
- ^ Шумейкер, Оуэн Дж. и П.К. Патак. «Последовательный бутстрап: сравнение с обычным бутстрапом». Коммуникации в теории статистики и методах 30.8-9 (2001): 1661-1674. связь
- ^ Хименес-Гамеро, Мария Долорес, Хоакин Муньос-Гарсия и Рафаэль Пино-Мехиас. «Уменьшенная начальная загрузка для медианы». Статистика Синика (2004): 1179–1198. связь
- ^ Кляйнер, А; Талвалкар, А; Саркар, П; Джордан, Мичиган (2014). «Масштабируемая начальная загрузка для больших данных». Журнал Королевского статистического общества, серия B (статистическая методология) . 76 (4): 795–816. arXiv : 1112.5016 . дои : 10.1111/rssb.12050 . ISSN 1369-7412 . S2CID 3064206 .
- ^ Jump up to: Перейти обратно: а б Дэвисон, AC ; Хинкли, Д.В. (1997). Методы начальной загрузки и их применение . Кембриджская серия по статистической и вероятностной математике. Издательство Кембриджского университета. ISBN 0-521-57391-2 . программное обеспечение .
- ^ Jump up to: Перейти обратно: а б с Хестерберг, Тим С. (2014). «Что учителя должны знать о начальной загрузке: повторная выборка в учебной программе по статистике бакалавриата». arXiv : 1411.5279 [ стат.ОТ ].
- ^ Эфрон, Б. (1982). Складной нож, бутстрап и другие планы повторной выборки . Том. 38. Монографии Общества промышленной и прикладной математики CBMS-NSF. ISBN 0-89871-179-7 .
- ^ Шайнер, С. (1998). Планирование и анализ экологических экспериментов . ЦРК Пресс. ISBN 0412035618 . Гл13, стр300
- ^ Райс, Джон. Математическая статистика и анализ данных (2-е изд.). п. 272. «Хотя это прямое уравнение квантилей распределения бутстреп-выборки с доверительными пределами может поначалу показаться привлекательным, его обоснование несколько неясно».
- ^ Данные из примеров в байесовском анализе данных.
- ^ Чихара, Лаура; Хестерберг, Тим (3 августа 2018 г.). Математическая статистика с повторной выборкой и R (2-е изд.). John Wiley & Sons, Inc., номер телефона : 10.1002/9781119505969 . ISBN 9781119416548 . S2CID 60138121 .
- ^ Воинов, Василий [Г.]; Никулин, Михаил [С.] (1993). Несмещенные оценки и их приложения. Том. 1: Одномерный случай. Дордрект: Kluwer Academic Publishers. ISBN 0-7923-2382-3.
- ^ Янг, Джорджия (июль 1990 г.). «Альтернативные сглаженные бутстрапы» . Журнал Королевского статистического общества, серия B (методологический) . 52 (3): 477–484. дои : 10.1111/j.2517-6161.1990.tb01801.x . ISSN 0035-9246 .
- ^ Грегори, Карл (29 декабря 2023 г.). «Некоторые результаты, основанные на центральной предельной теореме Линдеберга» (PDF) . Проверено 29 декабря 2023 г.
Дальнейшее чтение [ править ]
- Диаконис, П. ; Эфрон, Б. (май 1983 г.). «Компьютерные методы в статистике» (PDF) . Научный американец . 248 (5): 116–130. Бибкод : 1983SciAm.248e.116D . doi : 10.1038/scientificamerican0583-116 . Архивировано из оригинала (PDF) 13 марта 2016 г. Проверено 19 января 2016 г. научно-популярный
- Эфрон, Б. (1981). «Непараметрические оценки стандартной ошибки: складной нож, бутстрап и другие методы». Биометрика . 68 (3): 589–599. дои : 10.1093/biomet/68.3.589 .
- Хестерберг, TC; Д.С. Мур ; С. Монаган; А. Клипсон и Р. Эпштейн (2005). «Методы начальной загрузки и тесты перестановок» (PDF) . В Дэвиде С. Муре и Джордже Маккейбе (ред.). Введение в практику статистики . программное обеспечение . Архивировано из оригинала (PDF) 15 февраля 2006 г. Проверено 23 марта 2007 г.
- Эфрон, Брэдли (1979). «Методы начальной загрузки: еще один взгляд на складной нож» . Анналы статистики . 7 :1–26. дои : 10.1214/aos/1176344552 .
- Эфрон, Брэдли (1981). «Непараметрические оценки стандартной ошибки: складной нож, бутстрап и другие методы». Биометрика . 68 (3): 589–599. дои : 10.2307/2335441 . JSTOR 2335441 .
- Эфрон, Брэдли (1982). Складной нож, бутстрап и другие планы повторной выборки , В монографиях Общества промышленной и прикладной математики CBMS-NSF , 38.
- Диаконис, П. ; Эфрон, Брэдли (1983), «Компьютерные методы в статистике», Scientific American , май, 116–130.
- Эфрон, Брэдли ; Тибширани, Роберт Дж. (1993). Введение в бутстрап , Нью-Йорк: Chapman & Hall , программное обеспечение .
- Дэвисон, А.С. и Хинкли, Д.В. (1997): Методы начальной загрузки и их применение, программное обеспечение .
- Муни, Чехия, и Дюваль, Р.Д. (1993). Начальная загрузка. Непараметрический подход к статистическому выводу. Серия статей Университета Сейджа о количественных приложениях в социальных науках, 07-095. Ньюбери-Парк, Калифорния: Сейдж .
- Саймон, Дж. Л. (1997): Передискретизация: новая статистика .
- Райт Д.Б., Лондон К., Филд А.П. Использование бутстрап-оценки и принципа подключаемого модуля для данных клинической психологии. 2011 Textrum Ltd. Онлайн: https://www.researchgate.net/publication/236647074_Using_Bootstrap_Estimation_and_the_Plug-in_Principle_for_Clinical_Psychology_Data . Проверено 25.04.2016.
- Введение в бутстрап. Монографии по статистике и прикладной вероятности 57. Chapman&Hall/CHC. 1998. Интернет https://books.google.com/books?id=gLlpIUxRntoC&q=plug+in+principle.&pg=PA35 Проверено 25 апреля 2016 г.
- Гейл Гонг (1986) Перекрестная проверка, складной нож и бутстрап: оценка избыточной ошибки в прямой логистической регрессии, Журнал Американской статистической ассоциации, 81:393, 108–113, DOI: 10.1080/01621459.1986.10478245
Внешние ссылки [ править ]
- Учебное пособие по выборке начальной загрузки с использованием MS Excel
- Пример начальной загрузки для моделирования цен на акции с помощью MS Excel
- руководство по начальной загрузке
- Что такое бутстрап?
Программное обеспечение [ править ]
- Статистика101: Передискретизация, Bootstrap, программа моделирования Монте-Карло. Бесплатная программа, написанная на Java и работающая в любой операционной системе.
| |||||||||||||||||||||||||||