Регрессия к среднему значению


В статистике . регрессия к среднему значению (также называемая регрессией к среднему значению , возвратом к среднему значению и возвратом к посредственности ) — это явление, при котором, если одна выборка является случайной величины экстремальной , следующая выборка той же случайной величины, скорее всего, окажется экстремальной быть ближе к своему среднему значению . [2] [3] [4] Более того, когда отбирается множество случайных величин и намеренно выбираются наиболее экстремальные результаты, это означает, что (во многих случаях) вторая выборка этих выбранных переменных приведет к «менее экстремальным» результатам, более близким к начальное среднее значение всех переменных.
Математически сила этого эффекта «регрессии» зависит от того, все ли случайные величины взяты из одного и того же распределения или же существуют реальные различия в основных распределениях для каждой случайной величины. В первом случае эффект «регрессии» статистически вероятен, но во втором случае он может проявляться менее сильно или не проявляться вообще.
Таким образом, регрессия к среднему значению является полезной концепцией, которую следует учитывать при планировании любого научного эксперимента, анализа данных или теста, в которых намеренно выбираются наиболее экстремальные события. Это указывает на то, что последующие проверки могут быть полезны, чтобы избежать поспешных выводов о эти события; это могут быть настоящие экстремальные события, совершенно бессмысленная выборка из-за статистического шума или смесь этих двух случаев. [5]
Концептуальные примеры
[ редактировать ]Простой пример: студенты сдают тест
[ редактировать ]Рассмотрим класс учащихся, сдающих тест из 100 вопросов «верно/неверно» по определенному предмету. Предположим, что все студенты выбирают случайным образом по всем вопросам. Тогда оценка каждого учащегося будет реализацией одной из множества независимых и одинаково распределенных случайных величин с ожидаемым средним значением 50. Естественно, некоторые учащиеся наберут существенно больше 50, а некоторые существенно ниже 50 просто случайно. Если выбрать только 10% учащихся, набравших наибольшее количество баллов, и дать им второй тест, в котором они снова будут выбирать случайным образом по всем пунктам, ожидается, что средний балл снова будет близок к 50. Таким образом, средний балл этих учащихся будет «регрессировать». " вплоть до среднего значения всех учащихся, сдавших первоначальный тест. Независимо от того, какой балл учащийся набрал в исходном тесте, лучший прогноз его результата во втором тесте — 50.
Если бы выбор ответов на вопросы теста не был случайным (т. е. если бы в ответах учащихся не было случайности (хорошей или плохой) или случайного угадывания), то можно было бы ожидать, что все учащиеся наберут на втором тесте одинаковые баллы, как и они. набрали баллы в исходном тесте, и регресса к среднему значению не будет.
Большинство реальных ситуаций находятся между этими двумя крайностями: например, можно рассматривать результаты экзаменов как комбинацию навыков и удачи . В этом случае подгруппа студентов, набравших баллы выше среднего, будет состоять из тех, кто обладает навыками и не особенно везет, а также тех, кто не имеет квалификации, но чрезвычайно удачлив. При повторном тестировании этого подмножества неквалифицированным участникам вряд ли удастся повторить удачный случай, в то время как у опытных будет второй шанс на неудачу. Следовательно, те, кто преуспел в прошлом, вряд ли преуспеют во втором тесте, даже если оригинал невозможно воспроизвести.
Ниже приведен пример второго вида регрессии к среднему значению. Класс учащихся сдает два варианта одного и того же теста в течение двух дней подряд. Часто наблюдалось, что худшие результаты в первый день будут иметь тенденцию улучшать свои результаты во второй день, а лучшие результаты в первый день будут иметь тенденцию ухудшаться во второй день. Этот феномен возникает потому, что оценки учащихся частично определяются базовыми способностями, а частично случайностью. В первом тесте некоторым повезет, и они наберут больше, чем их способности, а некоторым не повезет, и они наберут меньше, чем их способности. Некоторым из счастливчиков на первом тесте повезет снова на втором тесте, но большинство из них будут иметь (для них) средние или ниже среднего баллы. Таким образом, учащийся, которому повезло и который превзошел свои способности на первом тесте, с большей вероятностью получит худший результат на втором тесте, чем лучший результат. Точно так же учащиеся, которые, к несчастью, набрали меньше своих способностей на первом тесте, как правило, увидят, что их баллы на втором тесте возрастут. Чем больше влияние удачи на возникновение экстремального события, тем меньше вероятность того, что удача повторится в нескольких событиях.
Другие примеры
[ редактировать ]Если ваша любимая спортивная команда выиграла чемпионат в прошлом году, как это повлияет на ее шансы на победу в следующем сезоне? В той степени, в которой этот результат обусловлен мастерством (команда в хорошей форме, с топ-тренером и т. д.), их победа сигнализирует о том, что с большей вероятностью они снова выиграют в следующем году. Но чем в большей степени это связано с везением (другие команды были втянуты в наркоскандал, выгодная ничья, результативные драфт-пики и т. д.), тем меньше вероятность, что они снова выиграют в следующем году. [6]
Если у бизнес-организации был очень прибыльный квартал, несмотря на то, что основные причины ее результатов не изменились, в следующем квартале ее дела, скорее всего, будут менее успешными. [7]
Бейсболисты, которые хорошо добились успеха в своем дебютном сезоне, скорее всего, выступят хуже во втором сезоне; « второкурсный спад ». Точно так же регрессия к среднему значению является объяснением Sports Illustrated проклятия обложки : периоды исключительных результатов, которые приводят к появлению статьи на обложке, вероятно, будут сопровождаться периодами более посредственных результатов, создавая впечатление, что появление на обложке приводит к упадку спортсмена. . [8]
История
[ редактировать ]Открытие
[ редактировать ]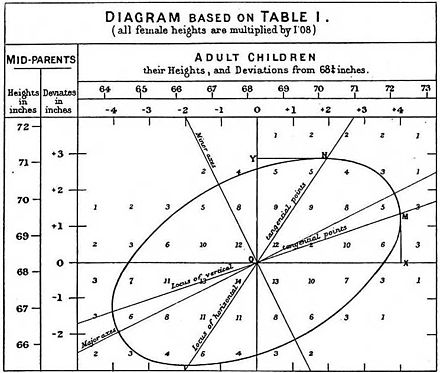
Концепция регрессии пришла из генетики и была популяризирована сэром Фрэнсисом Гальтоном в конце 19 века после публикации книги «Регрессия к посредственности в наследственном состоянии» . [9] Гальтон заметил, что крайние характеристики (например, рост) родителей не передаются полностью их потомству. Скорее, характеристики потомства регрессируют в сторону посредственной точки (точки, которая с тех пор была определена как средняя). Измерив рост сотен людей, он смог количественно оценить регрессию к среднему значению и оценить величину эффекта. Гальтон писал, что «средняя регрессия потомства представляет собой постоянную долю соответствующих средних родительских отклонений». Это означает, что разница между ребенком и его родителями по какому-то признаку пропорциональна отклонению его родителей от типичных людей в популяции. Если каждый из его родителей на два дюйма выше, чем в среднем для мужчин и женщин, то в среднем потомство будет ниже своих родителей на некоторый коэффициент (который сегодня мы бы назвали единицей минус коэффициент регрессии ), умноженный на два дюйма. Что касается роста, Гальтон оценил этот коэффициент примерно в 2/3: рост человека будет измеряться примерно средней точкой, что составляет две трети отклонения родителей от среднего показателя по популяции.
Гальтон также опубликовал эти результаты. [10] используя более простой пример падения гранул через доску Гальтона , чтобы сформировать нормальное распределение с центром непосредственно под их точкой входа. Эти гранулы затем могут быть выпущены во вторую галерею, соответствующую второму измерению. Затем Гальтон задал обратный вопрос: «Откуда взялись эти гранулы?»
Ответ не был « в среднем прямо выше » . Скорее, это было « в среднем больше к середине » по той простой причине, что над ним, к середине, было больше гранул, которые могли перемещаться влево, чем в левом крайнем положении, которые могли перемещаться вправо, внутрь. [11]
Развитие использования термина
[ редактировать ]Гальтон ввел термин «регрессия», чтобы описать наблюдаемый факт наследования многофакторных количественных генетических признаков: а именно, что черты потомства родителей, которые лежат в хвостах распределения, часто имеют тенденцию лежать ближе к центру, среднему значению. , распределения. Он количественно оценил эту тенденцию и тем самым изобрел линейный регрессионный анализ, заложив тем самым основу для большей части современного статистического моделирования. С тех пор термин «регрессия» использовался в других контекстах, и современные статистики могут использовать его для описания таких явлений, как систематическая ошибка выборки , которые имеют мало общего с первоначальными наблюдениями Гальтона в области генетики.
Объяснение Гальтоном наблюдаемого им в биологии явления регрессии было сформулировано следующим образом: «Ребенок наследует частично от своих родителей, частично от своих предков. Вообще говоря, чем дальше уходит в прошлое его генеалогия, тем более многочисленной и разнообразной будет его родословная, пока они перестают отличаться от любой столь же многочисленной выборки, случайно взятой у расы в целом». [9] Утверждение Гальтона требует некоторых пояснений в свете знаний генетики: дети получают генетический материал от своих родителей, но наследственная информация (например, значения унаследованных признаков) от более ранних предков может передаваться через их родителей (и, возможно, не была выражена в их родителях). . Среднее значение признака может быть неслучайным и определяться давлением отбора, но распределение значений вокруг среднего отражает нормальное статистическое распределение.
Популяционно -генетический феномен, изучаемый Гальтоном, представляет собой частный случай «регрессии к среднему значению»; этот термин часто используется для описания многих статистических явлений, в которых данные имеют нормальное распределение вокруг среднего значения.
Важность
[ редактировать ]Этот раздел нуждается в дополнительных цитатах для проверки . ( ноябрь 2016 г. ) |
Регрессия к среднему значению является важным фактором при планировании экспериментов .
Возьмем гипотетический пример 1000 человек одного и того же возраста, которые были обследованы и оценены по риску сердечного приступа. Статистические данные можно использовать для измерения успеха вмешательства среди 50 человек, которые были отнесены к группе наибольшего риска, что было измерено с помощью теста с определенной степенью неопределенности. Вмешательство может заключаться в изменении диеты, физических упражнений или медикаментозном лечении. Даже если вмешательства бесполезны, ожидается, что тестовая группа продемонстрирует улучшение на следующем медицинском осмотре из-за регрессии к среднему значению. Лучший способ борьбы с этим эффектом — случайное разделение группы на группу лечения, которая получает лечение, и группу, которая его не получает. В этом случае лечение будет считаться эффективным только в том случае, если в группе лечения улучшение будет больше, чем в группе, не получающей лечения.
В качестве альтернативы можно провести тестирование группы детей из неблагополучных семей , чтобы выявить тех, у кого наибольший потенциал в поступлении в колледж. Можно выделить 1% самых богатых людей, которым будут предоставлены специальные курсы повышения квалификации, репетиторство, консультирование и компьютеры. Даже если программа эффективна, их средние баллы вполне могут оказаться меньше, если тест будет повторен через год. Однако в этих обстоятельствах может быть сочтено неэтичным иметь контрольную группу детей из неблагополучных семей, особые потребности которых игнорируются. Математический расчет усадки может скорректировать этот эффект, хотя он не будет таким надежным, как метод контрольной группы (см. также пример Штейна ).
Этот эффект также можно использовать для общих выводов и оценок. В самом жарком месте страны сегодня завтра скорее всего будет прохладнее, чем жарче по сравнению с сегодняшним днем. Самый эффективный взаимный фонд за последние три года, скорее всего, увидит относительное снижение показателей, а не улучшение в течение следующих трех лет. Самый успешный голливудский актер этого года, скорее всего, получит меньше сборов за свой следующий фильм, чем больше. Бейсболист с самым высоким средним показателем к перерыву на Матч звезд с большей вероятностью будет иметь более низкий средний показатель, чем более высокий средний показатель во второй половине сезона.
Недоразумения
[ редактировать ]Концепцию регрессии к среднему значению можно очень легко использовать неправильно.
В приведенном выше примере студенческого теста неявно предполагалось, что измеряемое значение не изменилось между двумя измерениями. Предположим, однако, что курс был пройден/не пройден, и для прохождения студентам необходимо было набрать более 70 баллов по обоим тестам. Тогда у студентов, набравших меньше 70 баллов в первый раз, не будет стимула к хорошей успеваемости, и во второй раз они могут получить в среднем хуже. С другой стороны, у студентов старше 70 лет будет сильный стимул учиться и концентрироваться во время сдачи теста. В этом случае можно увидеть движение от 70: значения ниже этого значения становятся ниже, а значения выше него - выше. Изменения между периодами измерения могут усиливать, компенсировать или обращать вспять статистическую тенденцию регресса к среднему значению.
Статистическая регрессия к среднему значению не является причинным явлением. Студент с худшим результатом на тесте в первый день не обязательно существенно увеличит свой результат на второй день из-за эффекта. В среднем результаты худших бомбардиров улучшаются, но это верно только потому, что худшим бомбардирам скорее не повезло, чем повезло. Это явление будет иметь эффект в той степени, в которой оценка определяется случайным образом или что она имеет случайные вариации или ошибки, а не определяется академическими способностями учащегося или является «истинным значением». Классическая ошибка в этом отношении была в образовании. Было замечено, что учащиеся, получившие похвалу за хорошую работу, показали худшие результаты по следующему показателю, а ученики, которых наказали за плохую работу, показали лучшие результаты по следующему показателю. Воспитатели решили перестать хвалить и продолжить наказывать на этом основании. [12] Такое решение было ошибкой, поскольку регрессия к среднему значению основана не на причине и следствии, а скорее на случайной ошибке в естественном распределении вокруг среднего значения.
Хотя крайние отдельные измерения регрессируют к среднему значению, вторая выборка измерений не будет ближе к среднему значению, чем первая. Рассмотрим еще раз студентов. Предположим, что крайние люди склонны регрессировать на 10% к среднему значению , что студент, набравший 100 баллов в первый день, наберет 80, поэтому ожидается 98 баллов во второй день, а студент, набравший 70 баллов в первый день, как ожидается, наберет 98 баллов в первый день. оценка 71 во второй день. Эти ожидания ближе к среднему значению, чем результаты первого дня. Но результаты второго дня будут варьироваться в зависимости от их ожиданий; кто-то будет выше, кто-то ниже. Для экстремальных людей мы ожидаем, что второй балл будет ближе к среднему значению, чем первый балл, но для всех людей мы ожидаем, что распределение расстояний от среднего значения будет одинаковым для обоих наборов измерений.
Что касается вышеизложенного, регрессия к среднему значению работает одинаково хорошо в обоих направлениях. Мы ожидаем, что учащийся с самым высоким результатом теста во второй день справится хуже в первый день. И если мы сравним лучшего ученика в первый день с лучшим учеником во второй день, независимо от того, тот же самый человек или нет, то не будет тенденции к регрессу к среднему значению в любом направлении. Мы ожидаем, что лучшие результаты в оба дня будут одинаково далеки от среднего.
Заблуждения регрессии
[ редактировать ]Многие явления имеют тенденцию объясняться неверными причинами, если не принимать во внимание регрессию к среднему значению.
Крайним примером является книга Горация Секриста « 1933 года Триумф посредственности в бизнесе» , в которой профессор статистики собрал горы данных, чтобы доказать, что нормы прибыли конкурирующих предприятий с течением времени имеют тенденцию к среднему значению. На самом деле такого эффекта нет; изменчивость норм прибыли практически постоянна во времени. секрист лишь описал обычную регрессию к среднему значению. Один разгневанный рецензент, Гарольд Хотеллинг , сравнил книгу с «доказательством таблицы умножения, расставив слонов в ряды и столбцы, а затем проделав то же самое для множества других видов животных». [13]
Расчет и интерпретация «баллов улучшения» по стандартизированным образовательным тестам в Массачусетсе, вероятно, являются еще одним примером ошибки регрессии. [ нужна ссылка ] В 1999 году школам были поставлены цели по улучшению. Для каждой школы Министерство образования составило таблицу разницы в средних баллах, полученных учащимися в 1999 и 2000 годах. Быстро было отмечено, что большинство школ с худшими показателями достигли своих целей, что Министерство образования восприняло как подтверждение разумность их политики. Однако было также отмечено, что многие из предположительно лучших школ Содружества, такие как Средняя школа Бруклина (с 18 финалистами Национальной стипендии за заслуги), были объявлены несостоявшимися. Как и во многих случаях, связанных со статистикой и государственной политикой, этот вопрос обсуждается, но «показатели улучшения» не объявлялись в последующие годы, и полученные результаты, похоже, представляют собой случай регресса к среднему значению.
Психолог Дэниел Канеман , лауреат Нобелевской премии по экономике 2002 года , отметил, что регрессия к среднему значению может объяснить, почему упреки могут улучшить производительность, а похвала, похоже, имеет неприятные последствия. [14]
Самый приятный опыт работы с «Эврикой» в моей карьере я получил, когда пытался научить летных инструкторов тому, что похвала более эффективна, чем наказание за содействие обучению навыкам. Когда я закончил свою восторженную речь, один из самых опытных преподавателей в аудитории поднял руку и произнес собственную короткую речь, которая началась с признания того, что положительное подкрепление может быть полезно для птиц, но затем отрицало, что оно оптимально. для летных курсантов. Он сказал: «Я неоднократно хвалил курсантов за чистое выполнение некоторых фигур высшего пилотажа, и вообще, когда они пробуют это снова, у них получается хуже. С другой стороны, я часто кричал на курсантов за плохое выполнение, и в в общем, в следующий раз они справятся лучше. Поэтому, пожалуйста, не говорите нам, что подкрепление работает, а наказание — нет, потому что на самом деле все наоборот». Это был радостный момент, когда я понял важную истину о мире: поскольку мы склонны вознаграждать других, когда они поступают хорошо, и наказывать их, когда они поступают плохо, и поскольку существует регресс к среднему, это часть человеческого поведения. при условии, что нас статистически наказывают за вознаграждение других и вознаграждают за их наказание. Я тут же устроил демонстрацию, в которой каждый участник без всякой обратной связи бросал две монеты в мишень за спиной. Мы измерили расстояния от цели и увидели, что те, кто показал лучшие результаты с первого раза, в основном ухудшились во второй попытке, и наоборот. Но я знал, что эта демонстрация не устранит последствия постоянного воздействия извращенных обстоятельств.
Ошибка регрессии также объясняется в Рольфа Добелли книге «Искусство мыслить ясно» .
Политика правоохранительных органов Великобритании поощряет размещение статических или мобильных камер контроля скорости в местах аварийных ситуаций на видном месте . Эта политика была оправдана представлением о соответствующем уменьшении количества серьезных дорожно-транспортных происшествий после установки камеры. Однако статистики отмечают, что, хотя чистая выгода в виде спасенных жизней существует, неспособность принять во внимание эффекты регрессии к среднему значению приводит к преувеличению положительных эффектов. [15] [16] [17]
Статистические аналитики уже давно признали эффект регрессии к среднему значению в спорте; у них даже есть специальное название для этого: « спад второкурсников ». Например, Кармело Энтони из НБА » «Денвер Наггетс провел выдающийся сезон новичка в 2004 году. Он был настолько выдающимся, что от него нельзя было ожидать его повторения: в 2005 году показатели Энтони упали по сравнению с его сезоном новичка. Причин для «спада второкурсников» предостаточно, поскольку спорт полагается на корректировку и контрадаптацию, но успех новичка, основанный на удаче, является такой же веской причиной, как и любая другая. Регрессия к среднему значению спортивных результатов может также объяснить очевидное « Sports Illustrated проклятие на обложке журнала » и « безумное проклятие ». У Джона Холлингера есть альтернативное название явления регрессии к среднему: «правило случайности». [ нужна ссылка ] , а Билл Джеймс называет это «принципом оргстекла». [ нужна ссылка ]
Поскольку популярная теория фокусируется на регрессии к среднему значению как объяснении снижения результатов спортсменов от сезона к сезону, она обычно упускает из виду тот факт, что такая регрессия может также объяснять улучшение результатов. Например, если посмотреть на средний результат игроков Высшей лиги бейсбола за один сезон, то те, чей средний результат был выше среднего по лиге, имеют тенденцию регрессировать вниз к среднему значению в следующем году, в то время как те, чей средний результат был ниже среднего, имеют тенденцию прогресс вверх к среднему значению в следующем году. [18]
Другие статистические явления
[ редактировать ]Регрессия к среднему значению просто говорит о том, что после экстремального случайного события следующее случайное событие, вероятно, будет менее экстремальным. Будущее событие ни в коем случае не «компенсирует» или «выравнивает» предыдущее событие, хотя это и предполагается ошибкой игрока (и вариантным законом средних чисел ). Точно так же закон больших чисел утверждает, что в долгосрочной перспективе среднее значение будет стремиться к ожидаемому значению, но ничего не говорит об отдельных испытаниях. Например, после выпадения 10 орлов при подбрасывании честной монеты (редкое, экстремальное событие) регрессия к среднему значению утверждает, что следующая серия орлов, вероятно, будет меньше 10, в то время как закон больших чисел утверждает, что в долгосрочной перспективе это событие, скорее всего, усреднится, и средняя доля орлов будет стремиться к 1/2. Напротив, ошибка игрока ошибочно предполагает, что монета теперь «должна» уравновеситься выпадением решки.
Противоположным эффектом является регрессия к хвосту, возникающая в результате распределения с ненулевой плотностью вероятности к бесконечности. [19]
Определение простой линейной регрессии точек данных
[ редактировать ]Это определение регрессии к среднему значению, которое близко соответствует сэра Фрэнсиса Гальтона . первоначальному использованию [9]
Предположим, что имеется n точек данных { y i , x i }, где i = 1, 2, ..., n . Мы хотим найти уравнение линии регрессии , то есть прямой линии

который обеспечит наилучшее соответствие точкам данных. (Прямая линия может не быть подходящей кривой регрессии для данных точек данных.) Здесь лучше всего будет пониматься, как и в подходе наименьших квадратов : такая линия, которая минимизирует сумму квадратов остатков модели линейной регрессии. Другими словами, числа α и β решают следующую задачу минимизации:
- Находить , где


Используя математический анализ, можно показать, что значения α и β , которые минимизируют целевую функцию Q, равны
![{\displaystyle {\begin{aligned}&{\hat {\beta }}={\frac {\sum _{i=1}^{n}(x_{i}-{\bar {x}})( y_{i}-{\bar {y}})}{\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}}}={\ frac {{\overline {xy}}-{\bar {x}}{\bar {y}}}{{\overline {x^{2}}}-{\bar {x}}^{2}} }={\frac {\operatorname {Cov} [x,y]}{\operatorname {Var} [x]}}=r_{xy}{\frac {s_{y}}{s_{x}}}, \\&{\hat {\alpha }}={\bar {y}}-{\hat {\beta }}\,{\bar {x}},\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4ceb26f542d9dec173923b43d3e9589fef9f36f)
где r xy — коэффициент корреляции между x и y , s x — стандартное отклонение x y , а s y — соответственно стандартное отклонение выборочный . Горизонтальная черта над переменной означает выборочное среднее этой переменной. Например:

Подставив приведенные выше выражения на и в дает подходящие значения



что дает

Это показывает роль r xy в линии регрессии стандартизированных точек данных.
Если −1 < r xy < 1, то мы говорим, что точки данных демонстрируют регрессию к среднему значению. Другими словами, если линейная регрессия является подходящей моделью для набора точек данных, коэффициент корреляции выборки которых не идеален, то существует регрессия к среднему значению. Прогнозируемое (или подобранное) стандартизированное значение y ближе к своему среднему значению, чем стандартизованное значение x к своему среднему значению.
Определения двумерного распределения с идентичными маргинальными распределениями
[ редактировать ]Ограничительное определение
[ редактировать ]Пусть X 1 , X 2 будут случайными величинами с одинаковыми маргинальными распределениями со средним значением µ . В этой формализации , что двумерное распределение X 1 и X 2 демонстрирует говорят регрессию к среднему значению , если для каждого числа c > µ мы имеем
- ц ≤ Е[ Икс 2 | Икс 1 знак равно с ] < с ,
причем обратные неравенства выполняются при c < µ . [20] [21]
Ниже приводится неформальное описание приведенного выше определения. Рассмотрим популяцию виджетов . Каждый виджет имеет два числа: X 1 и X 2 (скажем, его левый ( X 1 ) диапазон ) и правый ( X 2 ). Предположим, что распределения вероятностей X 1 и X 2 в популяции идентичны и что средние значения X 1 и X 2 равны µ . Теперь мы возьмем случайный виджет из совокупности и обозначим его X 1 значение через c . ( c может быть больше, равно или меньше μ .) У нас пока нет доступа к значению X 2 этого виджета . Пусть d обозначает ожидаемое значение X 2 этого конкретного виджета. ( т.е. пусть d обозначает среднее значение X 2 всех виджетов в популяции с X 1 = c .) Если верно следующее условие:
- Каким бы ни было значение c , d лежит между µ и c ( т.е. d ближе к µ, чем c ),
тогда мы говорим, что X 1 и X 2 демонстрируют регрессию к среднему значению .
Это определение тесно согласуется с нынешним общепринятым использованием термина «регрессия к среднему», произошедшим от первоначального использования Гальтоном. Оно является «ограничительным» в том смысле, что не каждое двумерное распределение с идентичными маргинальными распределениями демонстрирует регрессию к среднему значению (согласно этому определению). [21]
Теорема
[ редактировать ]Если пара ( X , Y ) случайных величин следует двумерному нормальному распределению , то условное среднее E( Y | X является линейной функцией от X. ) Коэффициент корреляции r между X и Y , а также предельные средние значения и дисперсии X и Y , определяет эту линейную зависимость:
![{\displaystyle {\frac {E(Y\mid X)-E[Y]}{\sigma _{y}}}=r{\frac {XE[X]}{\sigma _{x}}}, }](https://wikimedia.org/api/rest_v1/media/math/render/svg/1139b41de03b98d327888dc8a7f0a2c9ab867375)
где E[X] и E[Y] — ожидаемые значения X и Y соответственно, а σ x и σ y — стандартные отклонения X и Y соответственно.
Следовательно, условное ожидаемое значение Y , учитывая, что X на t стандартных отклонений выше своего среднего значения (и это включает в себя случай, когда оно ниже своего среднего значения, когда t < 0), представляет собой rt стандартных отклонений выше среднего значения Y . Поскольку | р | ≤ 1, Y находится не дальше от среднего значения, чем X , если судить по количеству стандартных отклонений. [22]
Следовательно, если 0 ≤ r <1, то ( X , Y ) показывает регрессию к среднему значению (согласно этому определению).
Общее определение
[ редактировать ]Следующее определение возврата к среднему значению было предложено Сэмюэлсом в качестве альтернативы более строгому определению регрессии к среднему значению, приведенному выше. [20]
Пусть X 1 , X 2 будут случайными величинами с одинаковыми маргинальными распределениями со средним значением µ . В этой формализации к возврат среднему значению , если для говорят, что двумерное распределение X 1 и X 2 демонстрирует каждого числа c мы имеем
- ц ≤ Е[ Икс 2 | Икс 1 > с ] < Е[ Икс 1 | X 1 > c ], и
- μ ≥ E [ Икс 1 < с ] [ Е > x1 < с ]
Это определение является «общим» в том смысле, что каждое двумерное распределение с идентичными маргинальными распределениями демонстрирует возврат к среднему значению при условии, что выполняются некоторые слабые критерии (невырожденность и слабая положительная зависимость, как описано в статье Сэмюэлса). [20] ).
Альтернативное определение в финансовом использовании
[ редактировать ]Джереми Сигел использует термин «доходность к среднему значению» для описания финансового временного ряда , в котором « доходность может быть очень нестабильной в краткосрочной перспективе, но очень стабильной в долгосрочной перспективе». В более количественном отношении это тот, при котором стандартное отклонение среднегодовой доходности снижается быстрее, чем обратное значение периода владения, подразумевая, что этот процесс не является случайным блужданием , а что периоды более низкой доходности систематически сменяются компенсирующими периодами более высокой доходности. , как, например, во многих сезонных предприятиях. [23]
См. также
[ редактировать ]- Принцип Харди – Вайнберга
- Внутренняя валидность
- Закон больших чисел
- Мартингейл (теория вероятностей)
- Разбавление регрессии
- Предвзятость выбора
Ссылки
[ редактировать ]- ^ Гальтон, Фрэнсис (1901-1902). Научно-популярный ежемесячный том 60 , «Возможное улучшение человеческой породы в существующих условиях закона и настроений», стр. 224
- ^ Эверитт, бакалавр наук (12 августа 2002 г.). Кембриджский статистический словарь (2-е изд.). Издательство Кембриджского университета . ISBN 978-0521810999 .
- ^ Аптон, Грэм; Кук, Ян (21 августа 2008 г.). Оксфордский статистический словарь . Издательство Оксфордского университета . ISBN 978-0-19-954145-4 .
- ^ Стиглер, Стивен М. (1997). «Регрессия к среднему значению, с исторической точки зрения» . Статистические методы в медицинских исследованиях . 6 (2): 103–114. дои : 10.1191/096228097676361431 . ПМИД 9261910 .
- ^ Чиолеро, А; Паради, Дж; Рич, Б; Хэнли, Дж.А. (2013). «Оценка взаимосвязи между базовым значением непрерывной переменной и последующим изменением с течением времени» . Границы общественного здравоохранения . 1 : 29. дои : 10.3389/fpubh.2013.00029 . ПМЦ 3854983 . ПМИД 24350198 .
- ^ «Статистический обзор книги Дэниела Канемана «Думай быстро и медленно»» . Статистика Бернса . 11 ноября 2013 года . Проверено 1 января 2022 г.
- ^ «Что такое регрессия к среднему? Определение и примеры» . концептуально.орг . Проверено 25 октября 2017 г.
- ^ Голдакр, Бен (4 апреля 2009 г.). Плохая наука . Четвертая власть. п. 39. ИСБН 978-0007284870 .
- ^ Jump up to: а б с д Гальтон, Ф. (1886). «Регрессия к посредственности в наследственном статусе» . Журнал Антропологического института Великобритании и Ирландии . 15 : 246–263. дои : 10.2307/2841583 . JSTOR 2841583 .
- ^ Гальтон, Фрэнсис (1889). Естественное наследование . Лондон: Макмиллан .
- ^ Стиглер, Стивен М. (17 июня 2010 г.). «Дарвин, Гальтон и статистическое просвещение». Журнал Королевского статистического общества, серия A. 173 (3): 469–482, 477. doi : 10.1111/j.1467-985X.2010.00643.x . ISSN 1467-985X . S2CID 53333238 .
- ^ Канеман, Дэниел (1 октября 2011 г.). Думать быстро и медленно . Фаррар, Штраус и Жиру . ISBN 978-0-374-27563-1 .
- ^ Секрист, Гораций; Хотеллинг, Гарольд; Рорти, MC; Джини, Коррада; Кинг, Уилфорд И. (июнь 1934 г.). «Открытые письма» . Журнал Американской статистической ассоциации . 29 (186): 196–205. дои : 10.1080/01621459.1934.10502711 . JSTOR 2278295 .
- ^ Дефулио, Энтони (2012). «Цитата: Канеман о непредвиденных обстоятельствах» . Журнал экспериментального анализа поведения . 97 (2): 182. doi : 10.1901/jeab.2012.97-182 . ПМЦ 3292229 .
- ^ Вебстер, Бен (16 декабря 2005 г.). «Преимущества камеры контроля скорости переоценены» . Таймс . Проверено 1 января 2022 г. (требуется подписка)
- ^ Маунтин, Л. (2006). «Камеры безопасности: налог на скрытность или спасатели?». Значение . 3 (3): 111–113. дои : 10.1111/j.1740-9713.2006.00179.x .
- ^ Махер, Майк; Гора, Линда (2009). «Чувствительность оценок регрессии к среднему значению». Анализ и предотвращение несчастных случаев . 41 (4): 861–8. дои : 10.1016/j.aap.2009.04.020 . ПМИД 19540977 .
- ^ Иллюстрацию см. Нейт Сильвер , «Случайность: подхватите лихорадку!» , Бейсбольный проспект , 14 мая 2003 г.
- ^ Фливбьерг, Бент (5 октября 2020 г.). «Закон регрессии к хвосту: как пережить Covid-19, климатический кризис и другие катастрофы» . Экологическая наука и политика . 114 : 614–618. дои : 10.1016/j.envsci.2020.08.013 . ISSN 1462-9011 . ПМЦ 7533687 . ПМИД 33041651 .
- ^ Jump up to: а б с Сэмюэлс, Майра Л. (ноябрь 1991 г.). «Статистический возврат к среднему: более универсальный, чем регресс к среднему». Американский статистик . 45 (4): 344–346. дои : 10.2307/2684474 . JSTOR 2684474 . .
- ^ Jump up to: а б Шмиттлейн, Дэвид С. (август 1989 г.). «Удивительные выводы из неудивительных наблюдений: действительно ли условные ожидания возвращаются к среднему значению?» . Американский статистик . 43 (3): 176–183. дои : 10.2307/2685070 . JSTOR 2685070 .
- ^ Черник, Майкл Р.; Фриис, Роберт Х. (17 марта 2003 г.). Вводная биостатистика для медицинских наук . Уайли-Интерсайенс . п. 272. ИСБН 978-0-471-41137-6 .
- ^ Сигел, Джереми (27 ноября 2007 г.). Акции на долгосрочную перспективу (4-е изд.). МакГроу-Хилл. стр. 13, 28–29. ISBN 978-0071494700 .
Дальнейшее чтение
[ редактировать ]- Дж. М. Бланд и Д. Г. Альтман (июнь 1994 г.). «Статистические примечания: регрессия к среднему значению» . Британский медицинский журнал . 308 (6942): 1499. doi : 10.1136/bmj.308.6942.1499 . ПМК 2540330 . ПМИД 8019287 . Статья, включая диаграмму исходных данных Гальтона.
- Эдвард Дж. Дудевич и Сатья Н. Мишра (1988). «Раздел 14.1: Оценка параметров регрессии; Линейные модели». Современная математическая статистика . Джон Уайли и сыновья . ISBN 978-0-471-81472-6 .
- Фрэнсис Гальтон (1886). «Регрессия к посредственности в наследственном росте» (PDF) . Журнал Антропологического института Великобритании и Ирландии . 15 : 246–263. дои : 10.2307/2841583 . JSTOR 2841583 .
- Дональд Ф. Моррисон (1967). «Глава 3: Выборки из многомерной нормальной популяции». Многомерные статистические методы . МакГроу-Хилл . ISBN 978-0-534-38778-5 .
- Стивен М. Стиглер (1999). «Глава 9». Статистика в таблице . Издательство Гарвардского университета .
- Майра Л. Сэмюэлс (ноябрь 1991 г.). «Статистический возврат к среднему: более универсальный, чем регресс к среднему». Американский статистик . 45 (4): 344–346. дои : 10.2307/2684474 . JSTOR 2684474 .
- Стивен Сенн. Регрессия: новый способ старого значения , Американский статистик , Том 44, № 2 (май 1990 г.), стр. 181–183.
- Регрессия к среднему и изучение изменений , Психологический бюллетень
- Нематематическое объяснение регрессии к среднему значению.
- Моделирование регрессии к среднему значению.
- Аманда Ваксмут, Лиланд Уилкинсон, Джерард Э. Даллал. Изгиб Гальтона: необнаруженная нелинейность в данных регрессии роста семьи Гальтона и вероятное объяснение, основанное на данных о росте Пирсона и Ли (современный взгляд на анализ Гальтона).
- Результаты стандартизированных тестов штата Массачусетс, интерпретированные статистиками как пример регрессии: см. обсуждение на сайте sci.stat.edu и его продолжение .
- Гэри Смит , «Какая удача: удивительная роль случая в нашей повседневной жизни», Нью-Йорк: Оверлук, Лондон: Дакворт. ISBN 978-1-4683-1375-8 .
Внешние ссылки
[ редактировать ] СМИ, связанные с регрессией к среднему значению, на Викискладе?
СМИ, связанные с регрессией к среднему значению, на Викискладе?