верстка


Набор текста — это составление текста для публикации, отображения или распространения посредством расположения физического типа (или сортировки ) в механических системах или глифов в цифровых системах, представляющих символы (буквы и другие символы). [1] языка Сохраненные типы извлекаются и упорядочиваются в соответствии с орфографией для визуального отображения. Для набора текста требуется один или несколько шрифтов (которые часто, но ошибочно путают и заменяют гарнитурами ). Одним из существенных эффектов набора текста было то, что авторство произведений можно было легче определить, что затрудняло работу копировальных аппаратов, не получивших разрешения. [2]
Доцифровая эпоха
[ редактировать ]Ручной набор текста
[ редактировать ]На протяжении большей части эпохи высокой печати подвижный шрифт составлялся вручную для каждой страницы рабочими, называемыми наборщиками . Лоток со множеством разделителей, называемый футляром, содержал экземпляры из литого металла , на каждом из которых была одна буква или символ, но наоборот (чтобы они печатались правильно). Наборщик собирал эти виды в слова, затем в строки, затем в страницы текста, которые затем плотно связывались рамкой, образуя форму или страницу. Если все было сделано правильно, все буквы были одинаковой высоты и создавалась плоская поверхность текста. Форму помещали в пресс и красили, а затем печатали (создавали оттиск) на бумаге. [3] Металлический шрифт читался задом наперед, справа налево, и ключевым навыком наборщика была способность читать этот текст задом наперед.
До того, как были изобретены компьютеры и, следовательно, компьютеризированный (или цифровой) набор текста, размеры шрифтов менялись путем замены символов шрифтом другого размера. При высокой печати отдельные буквы и знаки препинания отливались на небольших металлических блоках, известных как «сорта», а затем располагались так, чтобы формировать текст на странице. Размер шрифта определялся размером символа на лицевой стороне шрифта. Чтобы изменить размер шрифта, наборщику потребуется физически поменять виды на другой размер.
Во время набора отдельные сорта выбираются из набора правой рукой и складываются слева направо в составную палочку, которую удерживают в левой руке, и наборщику кажется, что они перевернуты. Как видно на фотографии составной палочки, строчная буква «q» выглядит как «d», строчная «b» выглядит как «p», строчная «p» выглядит как «b» и a. строчная буква «d» выглядит как «q». Считается, что отсюда произошло выражение «следите за своими p и q». С таким же успехом это могло бы быть «следите за своими четверками и четверками». [3]
Забытая, но важная часть процесса происходила после печати: после очистки растворителем дорогие сорта необходимо было перераспределить в наборный корпус – это называется сортировкой или диссингом – чтобы они были готовы к повторному использованию. Ошибки при сортировке впоследствии могли привести к опечаткам, если, скажем, ap был помещен в отсек b.
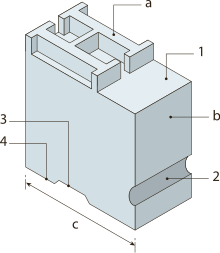
На диаграмме справа показан сорт литого металла: лицевая сторона , b корпус или хвостовик, c размер точки , 1 плечо, 2 насечки, 3 канавка, 4 ножка. Деревянные печатные формы использовались на протяжении веков в сочетании с металлическими. Не показано, и больше всего литейщика беспокоит «набор» или ширина каждого сорта. Ширина комплекта, как и размер тела, измеряется в пунктах.
Чтобы продлить срок службы шрифта и учесть ограниченность типов шрифта, копии форм отливались перед последующей печатью текста, освобождая дорогостоящий шрифт для другой работы. Это было особенно распространено в книжной и газетной работе, где ротационным печатным машинам требовались печатные формы для упаковки в печатный цилиндр, а не для установки в станину пресса. В этом процессе, называемом стереотипированием , вся форма прессуется в тонкую матрицу, например, из гипса или папье-маше, чтобы создать флонг отливается положительная форма , из которого из шрифтового металла .
Такие достижения, как пишущая машинка и компьютер, продвинут современный уровень техники еще дальше. Тем не менее, ручная композиция и высокая печать не вышли из употребления полностью, и с момента появления цифровой верстки они возродились как ремесленное занятие. Однако это небольшая ниша на более крупном рынке наборного текста.
Набор текста горячим металлом
[ редактировать ]Время и усилия, необходимые для составления текста вручную, привели к тому, что в XIX веке было предпринято несколько попыток механического набора текста. Хотя некоторые из них, такие как наборщик Пейджа , имели ограниченный успех, к концу XIX века было разработано несколько методов, с помощью которых оператор, работающий на клавиатуре или других устройствах, мог создавать желаемый текст. Большинство успешных систем предполагало литье используемого шрифта собственными силами, поэтому их называют набором «горячим металлом». Линотипная машина , изобретенная в 1884 году, использовала клавиатуру для сборки матриц и отливала целую строку текста за раз (отсюда и ее название). В системе монотипии клавиатура использовалась для перфорации бумажной ленты , которая затем подавалась для управления литейной машиной. В типографе Ладлоу использовались матрицы ручной настройки, но в остальном использовался горячий металл. К началу 20 века различные системы были почти универсальными в крупных газетах и издательствах.
Фотонабор
[ редактировать ]
Системы фотонабора или «холодного типа» впервые появились в начале 1960-х годов и быстро вытеснили машины непрерывного литья заготовок. Эти устройства состояли из стеклянных или пленочных дисков или полосок (по одному на каждый шрифт ), которые вращались перед источником света, чтобы выборочно экспонировать символы на светочувствительной бумаге. Первоначально они приводились в движение предварительно перфорированными бумажными лентами . Позже они были подключены к компьютерным интерфейсам.
Одна из первых систем электронной фотокомпозиции была представлена компанией Fairchild Semiconductor . Наборщик набрал строку текста на клавиатуре Fairchild, у которой не было дисплея. Для проверки правильности содержания строки она была набрана второй раз. Если две строки были идентичны, раздавался звонок, и машина производила перфоленту, соответствующую тексту. После завершения блока строк наборщик подавал соответствующие бумажные ленты в фотонаборное устройство, которое механически устанавливало контуры шрифта, напечатанные на стеклянных листах, на место для экспонирования на негативной пленке . Светочувствительная бумага подвергалась воздействию света через негативную пленку, в результате чего на белой бумаге образовывалась колонка черного шрифта или гранка . Затем гранку разрезали и использовали для создания механического рисунка или вставки целой страницы. Большой пленочный негатив страницы снимается и используется для изготовления пластин для офсетной печати .
цифровая эра
[ редактировать ]Следующим поколением фотонаборных машин были те, которые генерировали символы на дисплее с электронно-лучевой трубкой . Типичными для этого типа были буквенно-цифровой APS2 (1963 г.), [4] IBM 2680 (1967), III VideoComp (1973?), Autologic APS5 (1975), [5] и Линотрон 202 (1978). [6] Эти машины были основой фотонабора на протяжении большей части 1970-х и 1980-х годов. Такие машины могли «управляться онлайн» с помощью компьютерной интерфейсной системы или получать данные с магнитной ленты. Шрифты хранились в цифровом виде на обычных магнитных дисках.
Компьютеры превосходно справляются с автоматической версткой и исправлением документов. [7] Посимвольный компьютерный фотонабор, в свою очередь, быстро устарел в 1980-х годах из-за полностью цифровых систем, использующих процессор растровых изображений для преобразования всей страницы в одно цифровое изображение высокого разрешения , теперь известное как набор изображений.
Первым коммерчески успешным устройством лазерной печати изображений, способным использовать процессор растровых изображений, был Monotype Lasercomp. ECRM, Compugraphic (позже приобретенная Agfa ) и другие быстро последовали этому примеру, выпустив собственные машины.
Раннее программное обеспечение для набора текста на базе мини-компьютеров, представленное в 1970-х и начале 1980-х годов, такое как Datalogics Pager, Penta, Atex , Miles 33, Xyvision, troff от Bell Labs и продукт IBM Script с ЭЛТ-терминалами, было лучше способно управлять этими электромеханическими устройствами. текстовой и использовали языки разметки для описания типа и другой информации о форматировании страницы. Потомками этих языков текстовой разметки являются SGML , XML и HTML .
Миникомпьютерные системы выводили столбцы текста на пленку для вставки и в конечном итоге создавали целые страницы и подписи на 4, 8, 16 или более страницах, используя программное обеспечение для спуска полос израильского производства на таких устройствах, как Scitex Dolev . Поток данных, используемый этими системами для управления макетом страницы на принтерах и устройствах фотонабора, часто являющийся собственностью или специфичный для производителя или устройства, стимулировал разработку обобщенных языков управления принтером, таких как Adobe Systems от PostScript и Hewlett-Packard от PCL .

Компьютеризированный набор текста был настолько редок, что журнал BYTE (сравнивающий себя с «пресловутыми детьми сапожника, которые ходили босиком») не использовал компьютеры в производстве до тех пор, пока в его выпуске в августе 1979 года не использовалась система Compugraphics для набора текста и верстки страниц. Журнал еще не принимал статьи на дискетах, но надеялся сделать это «по мере развития событий». [8] До 1980-х годов практически весь набор текста для издателей и рекламодателей выполнялся специализированными наборными компаниями. Эти компании занимались набором клавиатуры, редактированием и производством бумажной или кинопродукции и составляли значительную часть индустрии полиграфии. В Соединенных Штатах эти компании располагались в сельской местности Пенсильвании, Новой Англии или Среднего Запада, где рабочая сила была дешевой, а бумага производилась поблизости, но все же в пределах нескольких часов езды от основных издательских центров.
В 1985 году с появлением новой концепции WYSIWYG (что видишь, то и получаешь) в редактировании текста и обработке текстов на персональных компьютерах настольные издательские системы стали доступны , начиная с Apple Macintosh , Aldus PageMaker (а позже QuarkXPress ) и PostScript и на платформе ПК с помощью Xerox Ventura Publisher под DOS, а также Pagemaker под Windows. Улучшения в программном и аппаратном обеспечении, а также быстрое снижение затрат способствовали популяризации настольных издательских систем и позволили очень точно контролировать результаты набора текста с гораздо меньшими затратами, чем специализированные мини-компьютеры. В то же время системы обработки текста, такие как Wang , WordPerfect и Microsoft Word , произвели революцию в офисных документах. Однако у них не было типографских способностей или гибкости, необходимых для сложной верстки книг, графики, математики или продвинутых правил расстановки переносов и выравнивания ( H и J ).
К 2000 году этот сегмент отрасли сократился, поскольку издатели теперь могли интегрировать набор текста и графический дизайн на своих собственных компьютерах. Многие обнаружили, что затраты на поддержание высоких стандартов типографского дизайна и технических навыков делают более экономичным привлечение фрилансеров и специалистов по графическому дизайну.
Доступность дешевых или бесплатных шрифтов облегчила переход к самостоятельному использованию, но также открыла разрыв между опытными дизайнерами и любителями. Появление PostScript, дополненного форматом файлов PDF , предоставило универсальный метод проверки проектов и макетов, читаемый на основных компьютерах и операционных системах.
QuarkXPress занимал 95% рынка в 1990-х годах, но уступил свое доминирование Adobe InDesign . с середины 2000-х [9]
Варианты СКРИПТА
[ редактировать ]
IBM создала и вдохновила семейство языков набора текста с названиями, производными от слова «SCRIPT». Более поздние версии SCRIPT включали расширенные функции, такие как автоматическое создание оглавления и указателя, многоколоночный макет страницы, сноски, поля, автоматическая расстановка переносов и проверка орфографии. [10]
NSCRIPT представлял собой порт SCRIPT для ОС и TSO из CP-67/CMS SCRIPT. [11]
Сценарий Ватерлоо был создан позже в Университете Ватерлоо (UW). [12] Одна версия SCRIPT была создана в Массачусетском технологическом институте, а AA/CS в UW взялась за разработку проекта в 1974 году. Впервые программа была использована в UW в 1975 году. В 1970-х годах SCRIPT был единственным практическим способом обработки текста и форматирования документов с использованием компьютер. К концу 1980-х годов система SCRIPT была расширена за счет различных обновлений. [13]
Первоначальное внедрение SCRIPT в UW было задокументировано в майском выпуске информационного бюллетеня вычислительного центра за 1975 год, в котором отмечались некоторые преимущества использования SCRIPT:
- Он легко обрабатывает сноски.
- Номера страниц могут быть арабскими или римскими цифрами и могут располагаться вверху или внизу страницы, в центре, слева или справа или слева для четных страниц и справа для нечетных. пронумерованные страницы.
- Подчеркивание или перечеркивание можно сделать функцией SCRIPT, что упрощает работу редактора.
- Файлы SCRIPT представляют собой обычные наборы данных ОС или файлы CMS.
- Вывод можно получить на принтере или на терминале…
В статье также указывалось, что SCRIPT имеет более 100 команд для форматирования документов, хотя от 8 до 10 из этих команд было достаточно для выполнения большинства заданий по форматированию. Таким образом, SCRIPT обладал многими возможностями, которые пользователи компьютеров обычно ассоциируют с современными текстовыми процессорами. [14]
SCRIPT/VS — вариант SCRIPT, разработанный в IBM в 1980-х годах.
DWScript — это версия SCRIPT для MS-DOS, названная в честь ее автора Д.Д. Уильямса. [15] но никогда не публиковался и использовался IBM только внутри компании.
Сценарий по-прежнему доступен у IBM как часть средства составления документов для операционной системы z/OS . [16]
Системы SGML и XML
[ редактировать ]Стандартный обобщенный язык разметки ( SGML ) был основан на IBM Generalized Markup Language (GML). GML представлял собой набор макросов поверх IBM Script. DSSSL — это международный стандарт, разработанный для предоставления таблиц стилей для документов SGML.
XML является преемником SGML. XSL-FO чаще всего используется для создания файлов PDF из файлов XML.
Появление SGML/XML в качестве модели документа сделало популярными другие механизмы набора текста.К таким механизмам относятся Datalogics Pager, Penta, OASYS от Miles 33, XML Professional Publisher от Xyvision , FrameMaker и Arbortext . XSL-FO-совместимые механизмы включают Apache FOP , Antenna House Formatter и RenderX от XEP .Эти продукты позволяют пользователям программировать процесс набора текста SGML/XML с помощью языков сценариев.
от YesLogic Prince — еще один, основанный на CSS Paged Media.
Трофф и преемники
[ редактировать ]В середине 1970-х годов Джо Оссанна , работавший в Bell Laboratories , написал программу набора текста troff для работы фотонаборной машины Wang C/A/T , принадлежащей Labs; усовершенствовал его Позже Брайан Керниган для поддержки вывода на различное оборудование, например лазерные принтеры . Хотя его использование сократилось, он по-прежнему включен в ряд Unix и Unix-подобных систем и использовался для набора текста ряда известных технических и компьютерных книг. Некоторые версии, а также GNU аналог под названием groff теперь имеют открытый исходный код .
ТеХ и Латекс
[ редактировать ]
Система TeX , разработанная Дональдом Э. Кнутом в конце 1970-х годов, представляет собой еще одну широко распространенную и мощную автоматизированную систему набора текста, установившую высокие стандарты, особенно в области математики набора текста. LuaTeX и LuaLaTeX — это варианты TeX и LaTeX, доступные для сценариев в Lua . TeX считается довольно сложным для изучения сам по себе, и он больше касается внешнего вида, чем структуры. Пакет макросов LaTeX, написанный Лесли Лэмпортом в начале 1980-х годов, предлагал более простой интерфейс и более простой способ систематического кодирования структуры документа. Разметка LaTeX широко используется в академических кругах для опубликованных статей и книг. Хотя стандартный TeX не предоставляет никакого интерфейса, существуют программы, которые его предоставляют. Эти программы включают Scientific Workplace и LyX , которые являются графическими/интерактивными редакторами; TeXmacs , будучи независимой системой набора текста, также может помочь в подготовке документов TeX благодаря своим возможностям экспорта.
Другие форматировщики текста
[ редактировать ]GNU TeXmacs (название которого представляет собой комбинацию TeX и Emacs , хотя оно не зависит от обеих этих программ) — это система набора текста, которая в то же время является WYSIWYG текстовым процессором .
SILE заимствует некоторые алгоритмы из TeX и опирается на другие библиотеки, такие как HarfBuzz и ICU , с расширяемым ядром, разработанным на Lua . [17] [18] По умолчанию входные документы SILE могут быть составлены в специальной разметке на основе LaTeX (SIL) или в формате XML. Благодаря добавлению сторонних модулей композиция в Markdown или Djot . также возможна [19]
Новая система набора текста Typst пытается объединить простую разметку ввода и возможность использования общих программных конструкций с высоким типографским качеством вывода. Эта система находится в стадии бета-тестирования с марта 2023 года. [20] [21] [22] и был представлен в июле 2023 года на конференции Tex Users Group (TUG) 2023. [23]
Существует несколько других пакетов программного обеспечения для форматирования текста, в частности Lout, Patoline, Pollen и Ant, но они широко не используются.
См. также
[ редактировать ]- Дингбат
- Редактор формул
- История западной типографики
- Лигатура (типографика)
- Длинный короткий путь
- Точка (типографика)
- Допечатная подготовка
- Печать
- Печатный станок
- Сортировка (набор текста)
- Распорка (верстка)
- Символы — полный список типографских символов.
- Техническое письмо
Ссылки
[ редактировать ]- ^ Dictionary.com без сокращений. Random House, Inc., 23 декабря 2009 г. Dictionary.reference.com
- ^ Мюррей, Стюарт А., Библиотека: иллюстрированная история , издание ALA, Skyhorse, 2009, стр. 131
- ^ Jump up to: Перейти обратно: а б Лайонс, М. (2001). Книги: Живая история. (стр. 59–61).
- ^ Энциклопедия компьютерных наук и технологий , 1976 г.
- ^ Энциклопедия компьютерных наук и технологий
- ^ История линотипа
- ^ Петру-Иоан Бечеру (октябрь 2011 г.). «Исправление ошибок в наборе румынского языка с помощью регулярных выражений» . Ан. унив. Спиру Харет — сер. математ.-информ. 7 (2): 31–36. ISSN 1841-7833 . 83. Архивировано из оригинала 15 апреля 2020 г. Проверено 9 апреля 2012 г. (на веб-странице есть кнопка перевода)
- ^ Хелмерс, Карл (август 1979 г.). «Заметки о появлении BYTE...» BYTE . стр. 158–159.
- ^ «Как QuarkXPress стал второстепенной мыслью в издательском деле» . Арс Техника . 14 января 2014 г. Проверено 7 августа 2022 г.
- ^ U01-0547, «Введение в SCRIPT», архивировано 6 июня 2009 г. на Wayback Machine , доступно через PRTDOC.
- ^ Руководство по внедрению SCRIPT 90.1 , 6 июня 1990 г.
- ^ CSG.uwaterloo.ca
- ^ Хронология вычислений в Университете Ватерлоо
- ^ Глоссарий вычислительной хронологии Университета Ватерлоо
- ^ DWScript - Средство составления документов для обновлений персонального компьютера IBM версии 4.6, DW-04167, 8 ноября 1985 г.
- ^ Средство составления документов IBM (DCF)
- ^ «Сайт СИЛЕ» . Проверено 1 августа 2023 г.
- ^ Саймон Козенс (2017). «SILE, Новая система набора текста» (PDF) . БУКСИР, Том 38 (2017), №1 . Проверено 1 августа 2023 г.
- ^ «Markdown и Djot в PDF с помощью SILE» . Гитхаб . Проверено 14 июля 2023 г.
- ^ «Typst. Новая система набора текста на основе разметки, мощная и простая в освоении» . Гитхаб . Проверено 14 июля 2023 г.
- ^ «Типичный сайт» . Проверено 14 июля 2023 г.
- ^ Лауренц Мэдже (2022). «Typst. Программируемый язык разметки для набора текста. Магистерская диссертация» (PDF) . Технический университет Берлина . Проверено 14 июля 2023 г.
- ^ Эберхард В. Лиссе (2023). «Введение в Typst» (PDF) . Конференция «БУКСИР 2023» . Проверено 14 июля 2023 г.
