Выборка (статистика)
В статистике , обеспечении качества и опросов методологии выборка — это отбор подмножества или статистической выборки ( называемой выборкой сокращенно ) отдельных лиц из статистической совокупности для оценки характеристик всей совокупности. Подмножество предназначено для отражения всего населения, и статистики пытаются собрать образцы, репрезентативные для населения. Выборка требует меньших затрат и более быстрого сбора данных по сравнению с записью данных от всей совокупности, и, таким образом, она может дать ценную информацию в тех случаях, когда невозможно измерить всю совокупность.
Каждое наблюдение измеряет одно или несколько свойств (таких как вес, местоположение, цвет или масса) независимых объектов или людей. При выборке обследования к данным могут быть применены веса для корректировки структуры выборки, особенно при стратифицированной выборке . [ 1 ] результаты теории вероятностей и статистической теории Для руководства практикой используются . В деловых и медицинских исследованиях выборка широко используется для сбора информации о населении. [ 2 ] Приемочный отбор используется для определения того, соответствует ли производственная партия материала нормативным спецификациям .
История
[ редактировать ]Случайная выборка жребием — старая идея, несколько раз упомянутая в Библии. В 1786 году Пьер Симон Лаплас оценил население Франции, используя выборку и оценщик соотношений . Он также рассчитал вероятностные оценки ошибки. Они были выражены не в виде современных доверительных интервалов , а в виде размера выборки, который потребуется для достижения определенной верхней границы ошибки выборки с вероятностью 1000/1001. В его оценках использовалась теорема Байеса с равномерной априорной вероятностью и предполагалось, что его выборка была случайной. Александр Иванович Чупров ввел выборочные обследования в императорской России в 1870-х годах. [ 3 ]
В США прогноз «Литературного дайджеста» 1936 года о победе республиканцев на президентских выборах сильно ошибся из-за серьезной предвзятости [1] . Более двух миллионов человек ответили на исследование, указав свои имена, полученные из списков подписки на журналы и телефонных справочников. Не было оценено, что эти списки были сильно предвзяты в пользу республиканцев, и полученная выборка, хотя и очень большая, была глубоко ошибочной. [ 4 ] [ 5 ]
На выборах в Сингапуре эта практика была принята после выборов 2015 года , также известная как выборочный подсчет, тогда как, по данным Избирательного департамента (ELD), избирательной комиссии страны, выборочный подсчет помогает уменьшить спекуляции и дезинформацию, одновременно помогая сотрудникам избирательных комиссий проверять соответствие результат выборов по данному избирательному округу. Сообщенный подсчет образцов дает довольно точный ориентировочный результат с доверительным интервалом 95% и погрешностью в пределах 4-5%; ELD напомнил общественности, что подсчет проб не связан с официальными результатами, и только ответственный за подсчет голосов объявит официальные результаты после завершения подсчета голосов. [ 6 ] [ 7 ]
Определение населения
[ редактировать ]Успешная статистическая практика основана на целенаправленном определении проблемы. При выборке это включает в себя определение « населения », из которого формируется наша выборка. Популяцию можно определить как включающую всех людей или предметы с характеристиками, которые человек хочет понять. Поскольку очень редко бывает достаточно времени или денег для сбора информации от всех или обо всем в популяции, целью становится поиск репрезентативной выборки (или подгруппы) этой популяции.
Иногда то, что определяет популяцию, очевидно. Например, производителю необходимо решить, имеет ли партия произведенного материала достаточно высокое качество для передачи потребителю, или ее следует списать или переработать из-за низкого качества. В данном случае партия — это популяция.
Хотя интересующая совокупность часто состоит из физических объектов, иногда необходимо осуществлять выборку во времени, пространстве или некоторой комбинации этих измерений. Например, исследование штата супермаркетов могло бы изучить длину очередей на кассах в разное время, а исследование находящихся под угрозой исчезновения пингвинов могло бы быть направлено на то, чтобы понять, как они используют различные охотничьи угодья с течением времени. Что касается временного измерения, внимание может быть сосредоточено на периодах или отдельных событиях.
В других случаях исследуемая «популяция» может быть еще менее ощутимой. Например, Джозеф Джаггер изучал поведение колес рулетки в казино Монте-Карло и использовал это для выявления смещенного колеса. В этом случае «популяция», которую Джаггер хотел исследовать, представляла собой общее поведение колеса (т.е. распределение вероятностей его результатов по бесконечному множеству испытаний), в то время как его «выборка» была сформирована на основе наблюдаемых результатов этого колеса. Аналогичные соображения возникают при повторных измерениях свойств материалов, электропроводности меди например .
Такая ситуация часто возникает при поиске знаний о системе причин которой является наблюдаемая , результатом популяция. В таких случаях теория выборки может рассматривать наблюдаемую популяцию как выборку из более крупной «суперпопуляции». Например, исследователь может изучить уровень успеха новой программы по отказу от курения на тестовой группе из 100 пациентов, чтобы предсказать последствия программы, если она будет доступна по всей стране. Здесь суперпопуляция – это «все в стране, которым предоставлен доступ к этому лечению» – группа, которой еще не существует, поскольку программа еще не доступна для всех.
Популяция, из которой формируется выборка, может не совпадать с совокупностью, информацию о которой требуется получить. Часто между этими двумя группами наблюдается большое, но не полное совпадение из-за проблем с рамками и т. д. (см. ниже). Иногда они могут быть совершенно отдельными — например, можно изучать крыс, чтобы лучше понять здоровье человека, или можно изучать записи людей, родившихся в 2008 году, чтобы делать прогнозы о людях, родившихся в 2009 году.
Время, затраченное на уточнение выборочной совокупности и рассматриваемой популяции, часто тратится не зря, поскольку возникает множество проблем, неясностей и вопросов, которые в противном случае были бы упущены из виду на этом этапе.
Основа выборки
[ редактировать ]В самом простом случае, таком как отбор проб партии материала с производства (приемочная выборка партиями), было бы наиболее желательно идентифицировать и измерить каждый отдельный элемент генеральной совокупности и включить любой из них в нашу выборку. Однако в более общем случае это обычно невозможно или практически невозможно. Невозможно идентифицировать всех крыс в наборе всех крыс. Если голосование не является обязательным, невозможно определить, какие люди будут голосовать на предстоящих выборах (до выборов). Эти неточные совокупности не поддаются выборке ни одним из описанных ниже способов, к которым мы могли бы применить статистическую теорию.
В качестве решения проблемы мы ищем основу выборки , которая обладает свойством, позволяющим идентифицировать каждый отдельный элемент и включить любой из них в нашу выборку. [ 8 ] [ 9 ] [ 10 ] [ 11 ] Самый простой тип структуры — это список элементов совокупности (предпочтительно всего населения) с соответствующей контактной информацией. Например, при опросе общественного мнения возможные рамки выборки включают список избирателей и телефонный справочник .
Вероятностная выборка — это выборка, в которой каждая единица генеральной совокупности имеет шанс (больше нуля) попасть в выборку, и эта вероятность может быть точно определена. Комбинация этих характеристик позволяет производить несмещенные оценки общей численности населения путем взвешивания единиц выборки в соответствии с вероятностью их отбора.
Пример: мы хотим оценить общий доход взрослых, живущих на данной улице. Мы посещаем каждое домохозяйство на этой улице, выявляем всех взрослых, живущих там, и случайным образом выбираем по одному взрослому из каждого домохозяйства. (Например, мы можем присвоить каждому человеку случайное число, полученное в результате равномерного распределения от 0 до 1, и выбрать человека с наибольшим номером в каждом домохозяйстве). Затем мы проводим собеседование с выбранным человеком и определяем его доход.
Люди, живущие самостоятельно, обязательно будут выбраны, поэтому мы просто добавляем их доход к нашей оценке общей суммы. Но человек, живущий в семье из двух взрослых, имеет только один шанс из двух. Чтобы отразить это, когда мы приходим к такому домохозяйству, мы дважды учитываем доход выбранного человека в общей сумме. (Человека, выбранного из этого домохозяйства, можно условно рассматривать как представителя человека, который не выбран.)
В приведенном выше примере не все имеют одинаковую вероятность выбора; Вероятностной выборкой ее делает тот факт, что известна вероятность каждого человека. Когда каждый элемент популяции имеет одинаковую вероятность выбора, это известно как план «равной вероятности выбора» (EPS). Такие планы также называются «самовзвешенными», поскольку всем единицам выборки присваивается одинаковый вес.
Вероятностная выборка включает в себя: простую случайную выборку , систематическую выборку , стратифицированную выборку , выборку, пропорциональную вероятности размеру, и кластерную или многоступенчатую выборку . Эти различные способы вероятностной выборки имеют две общие черты:
- Каждый элемент имеет известную ненулевую вероятность быть выбранным и
- предполагает случайный выбор в какой-то момент.
Невероятностная выборка
[ редактировать ]Невероятностная выборка — это любой метод выборки, при котором некоторые элементы генеральной совокупности не имеют шансов на отбор (их иногда называют «вне охвата»/«недостаточно охваченных») или при котором вероятность отбора не может быть точно определена. Он включает в себя выбор элементов на основе предположений относительно интересующей совокупности, которая формирует критерии отбора. Следовательно, поскольку выбор элементов неслучайен, невероятностная выборка не позволяет оценить ошибки выборки. Эти условия приводят к систематической ошибке исключения , устанавливающей ограничения на объем информации, которую выборка может предоставить о совокупности. Информация о взаимосвязи между выборкой и генеральной совокупностью ограничена, что затрудняет экстраполяцию выборки на генеральную совокупность.
Пример: мы посещаем каждое домохозяйство на определенной улице и беседуем с первым человеком, который откроет дверь. В любом домохозяйстве, в котором проживают более одного человека, это невероятностная выборка, поскольку некоторые люди с большей вероятностью откроют дверь (например, безработный, который проводит большую часть своего времени дома, с большей вероятностью ответит, чем работающий сосед по дому, который может быть на работе, когда звонит интервьюер) и рассчитывать эти вероятности непрактично.
Методы невероятностной выборки включают выборку для удобства , выборку по квоте и целевую выборку . Кроме того, эффекты отсутствия ответа могут превратить любой вероятностный план в невероятностный план, если характеристики отсутствия ответа недостаточно понятны, поскольку отсутствие ответа эффективно изменяет вероятность попадания в выборку каждого элемента.
Методы отбора проб
[ редактировать ]В рамках любого из типов совокупностей, указанных выше, можно использовать различные методы выборки по отдельности или в сочетании. Факторы, обычно влияющие на выбор между этими конструкциями, включают:
- Характер и качество кадра
- Наличие вспомогательной информации об объектах на кадре
- Требования к точности и необходимость измерения точности
- Ожидается ли подробный анализ образца
- Проблемы стоимости/эксплуатации
Простая случайная выборка
[ редактировать ]В простой случайной выборке (SRS) заданного размера все подмножества выборки имеют равную вероятность быть выбранными. Таким образом, каждый элемент кадра имеет равную вероятность выбора: кадр не подразделяется и не разделяется. Более того, любая данная пара элементов имеет такой же шанс выбора, как и любая другая такая пара (аналогично для троек и т. д.). Это сводит к минимуму систематическую ошибку и упрощает анализ результатов. В частности, дисперсия между отдельными результатами внутри выборки является хорошим индикатором дисперсии в генеральной совокупности, что позволяет относительно легко оценить точность результатов.
Простая случайная выборка может быть уязвима для ошибок выборки, поскольку случайность выбора может привести к тому, что выборка не будет отражать состав генеральной совокупности. Например, простая случайная выборка из десяти человек из данной страны в среднем даст пять мужчин и пять женщин, но в любом конкретном исследовании, скорее всего, будет избыточно представлен один пол и недостаточно представлен другой. Систематические и стратифицированные методы пытаются решить эту проблему, «используя информацию о населении» для выбора более «репрезентативной» выборки.
Кроме того, простая случайная выборка может оказаться обременительной и утомительной при выборке из большой целевой совокупности. В некоторых случаях следователей интересуют вопросы исследования, специфичные для подгрупп населения. Например, исследователям может быть интересно выяснить, одинаково ли применимы когнитивные способности как предиктор производительности труда в разных расовых группах. Простая случайная выборка не может удовлетворить потребности исследователей в этой ситуации, поскольку она не обеспечивает подвыборку генеральной совокупности, и вместо нее можно использовать другие стратегии выборки, такие как стратифицированная выборка.
Систематический отбор проб
[ редактировать ]
Систематическая выборка (также известная как интервальная выборка) основана на расположении исследуемой совокупности в соответствии с некоторой схемой упорядочения и последующем выборе элементов через регулярные промежутки времени из этого упорядоченного списка. Систематическая выборка предполагает случайное начало, а затем продолжается выбор каждого k -го элемента. В данном случае k = (размер популяции/размер выборки). Важно, чтобы отправная точка не была автоматически первой в списке, а выбиралась случайным образом от первого до k -го элемента в списке. Простым примером может быть выбор каждого 10-го имени из телефонного справочника («выборка каждого 10-го имени», также называемая «выборкой с пропуском 10»).
Пока отправная точка рандомизирована , систематическая выборка является разновидностью вероятностной выборки . Его легко реализовать, а вызванная стратификация может сделать его эффективным, если переменная, по которой упорядочивается список, коррелирует с интересующей переменной. Выборка «каждая 10-я» особенно полезна для эффективной выборки из баз данных .
Например, предположим, что мы хотим выбрать людей с длинной улицы, которая начинается в бедном районе (дом № 1) и заканчивается в дорогом районе (дом № 1000). Простой случайный выбор адресов с этой улицы может легко привести к тому, что в результате окажется слишком много адресов из верхнего сегмента и слишком мало из нижнего (или наоборот), что приведет к нерепрезентативной выборке. Выбор (например) каждого 10-го номера улицы вдоль улицы гарантирует, что выборка будет равномерно распределена по длине улицы, представляя все эти районы. (Если мы всегда начинаем с дома №1 и заканчиваем на №991, выборка слегка смещается в сторону нижнего предела; случайным выбором начала между №1 и №10 это смещение устраняется.)
Однако систематическая выборка особенно уязвима из-за периодичности в списке. Если присутствует периодичность и период кратен или кратен используемому интервалу, особенно вероятно, что выборка будет нерепрезентативной для всей совокупности, что сделает схему менее точной, чем простая случайная выборка.
Например, рассмотрим улицу, на которой все дома с нечетными номерами находятся на северной (дорогой) стороне дороги, а все дома с четными номерами — на южной (дешевой) стороне. При приведенной выше схеме выборки невозможно получить репрезентативную выборку; отобранные дома будут либо все с нечетной и дорогой стороны, либо все они будут с четной и дешевой стороны, если только исследователь заранее не знает об этой предвзятости и не избегает ее, используя пропуск, который обеспечивает прыжки. между двумя сторонами (любой пропуск с нечетным номером).
Еще одним недостатком систематической выборки является то, что даже в тех сценариях, где она более точна, чем SRS, ее теоретические свойства затрудняют количественную оценку этой точности. (В двух примерах систематической выборки, приведенных выше, большая часть потенциальной ошибки выборки связана с различиями между соседними домами, но поскольку этот метод никогда не выбирает два соседних дома, выборка не даст нам никакой информации об этих различиях.)
Как описано выше, систематическая выборка является методом EPS, поскольку все элементы имеют одинаковую вероятность отбора (в приведенном примере — одна из десяти). Это не «простая случайная выборка», поскольку разные подмножества одного и того же размера имеют разные вероятности выбора – например, набор {4,14,24,...,994} имеет вероятность выбора один из десяти, но набор {4,13,24,34,...} имеет нулевую вероятность выбора.
Систематический отбор проб также может быть адаптирован к подходу, не связанному с САП; пример см. в обсуждении образцов PPS ниже.
Стратифицированная выборка
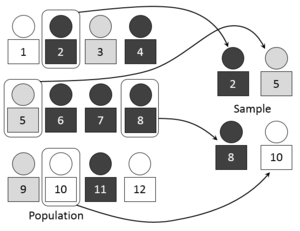
[ редактировать ]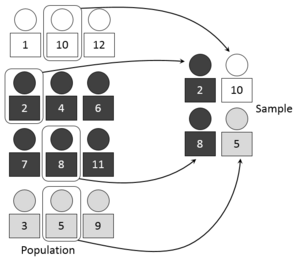
Когда совокупность включает в себя несколько отдельных категорий, совокупность может быть организована по этим категориям в отдельные «страты». Затем каждая страта отбирается как независимая подгруппа, из которой случайным образом выбираются отдельные элементы. [ 8 ] Отношение размера этой случайной выборки (или выборки) к размеру генеральной совокупности называется долей выборки . [ 12 ] У стратифицированной выборки есть несколько потенциальных преимуществ. [ 12 ]
Во-первых, разделение населения на отдельные, независимые слои может позволить исследователям сделать выводы о конкретных подгруппах, которые могут быть потеряны в более обобщенной случайной выборке.
Во-вторых, использование метода стратифицированной выборки может привести к более эффективным статистическим оценкам (при условии, что страты отбираются на основе соответствия рассматриваемому критерию, а не на основе наличия выборок). Даже если подход стратифицированной выборки не приведет к повышению статистической эффективности, такая тактика не приведет к меньшей эффективности, чем простая случайная выборка, при условии, что каждая страта пропорциональна размеру группы в совокупности.
В-третьих, иногда бывает так, что данные более доступны по отдельным, уже существовавшим слоям населения, чем по населению в целом; в таких случаях использование стратифицированной выборки может быть более удобным, чем агрегирование данных по группам (хотя потенциально это может противоречить ранее отмеченной важности использования страт, релевантных критериям).
Наконец, поскольку каждая страта рассматривается как независимая совокупность, к разным слоям могут применяться разные подходы к выборке, что потенциально позволяет исследователям использовать подход, который лучше всего подходит (или наиболее экономически эффективен) для каждой выявленной подгруппы внутри совокупности.
Однако существуют некоторые потенциальные недостатки использования стратифицированной выборки. Во-первых, выявление слоев и внедрение такого подхода может увеличить стоимость и сложность отбора выборки, а также привести к увеличению сложности оценок численности населения. Во-вторых, при изучении нескольких критериев стратифицирующие переменные могут быть связаны с одними, но не с другими, что еще больше усложняет дизайн и потенциально снижает полезность страт. Наконец, в некоторых случаях (например, в планах с большим количеством страт или с указанным минимальным размером выборки на группу) стратифицированная выборка потенциально может потребовать большей выборки, чем другие методы (хотя в большинстве случаев требуемый размер выборки будет не больше, чем потребовалось бы для простой случайной выборки).
- Подход стратифицированной выборки наиболее эффективен при соблюдении трех условий.
- Вариабельность внутри слоев сведена к минимуму
- Вариативность между слоями максимальна
- Переменные, по которым стратифицируется совокупность, сильно коррелируют с желаемой зависимой переменной.
- Преимущества перед другими методами отбора проб
- Фокусируется на важных субпопуляциях и игнорирует ненужные.
- Позволяет использовать различные методы выборки для разных подгрупп населения.
- Повышает точность/эффективность оценки.
- Позволяет лучше сбалансировать статистическую мощность тестов на различия между стратами за счет выборки равного числа из страт, сильно различающихся по размеру.
- Недостатки
- Требуется выбор соответствующих переменных стратификации, что может оказаться затруднительным.
- Бесполезно, если нет однородных подгрупп.
- Может оказаться дорогостоящим в реализации.
- Постстратификация
Стратификация иногда вводится после фазы выборки в процессе, называемом «постстратификация». [ 8 ] Этот подход обычно реализуется из-за отсутствия предварительных знаний о соответствующей стратифицирующей переменной или когда экспериментатору не хватает необходимой информации для создания стратифицирующей переменной на этапе выборки. Хотя этот метод подвержен недостаткам постфактум-подходов, в правильной ситуации он может дать несколько преимуществ. Реализация обычно следует простой случайной выборке. Помимо возможности стратификации по вспомогательной переменной, постстратификация может использоваться для взвешивания, что может повысить точность оценок выборки. [ 8 ]
- Передискретизация
Выборка на основе выбора является одной из стратегий стратифицированной выборки. При выборке на основе выбора [ 13 ] данные стратифицируются по целевому объекту, и из каждой страты берется выборка, чтобы редкий целевой класс был более представлен в выборке. Затем модель строится на основе этой смещенной выборки . Влияние входных переменных на цель часто оценивается с большей точностью с помощью выборки, основанной на выборе, даже если общий размер выборки меньший по сравнению со случайной выборкой. Результаты обычно необходимо корректировать, чтобы исправить передискретизацию.
Выборка, пропорциональная вероятности размера
[ редактировать ]В некоторых случаях составитель выборки имеет доступ к «вспомогательной переменной» или «показателю размера», которая, как полагают, коррелирует с интересующей переменной для каждого элемента генеральной совокупности. Эти данные можно использовать для повышения точности планирования выборки. Один из вариантов — использовать вспомогательную переменную в качестве основы для стратификации, как обсуждалось выше.
Другим вариантом является выборка с вероятностью, пропорциональной размеру (PPS), при которой вероятность выбора для каждого элемента устанавливается пропорциональной его размеру, максимум до 1. В простой схеме PPS эти вероятности выбора могут затем использоваться в качестве основы для выборки по Пуассону . Однако у этого метода есть недостаток: размер выборки варьируется, и различные части генеральной совокупности могут по-прежнему быть пере- или недопредставлены из-за случайных изменений в выборке.
Теорию систематической выборки можно использовать для создания вероятности, пропорциональной размеру выборки. Это достигается путем обработки каждого значения переменной размера как одной единицы выборки. Затем образцы идентифицируются путем выбора этих значений через равные промежутки времени в переменной размера. Этот метод иногда называют PPS-последовательной выборкой или выборкой денежных единиц в случае аудита или судебно-медицинской экспертизы.
Пример: предположим, что у нас есть шесть школ с населением 150, 180, 200, 220, 260 и 490 учащихся соответственно (всего 1500 учащихся), и мы хотим использовать численность учащихся в качестве основы для выборки PPS третьего размера. Для этого мы могли бы присвоить первой школе номера от 1 до 150, второй школе — от 151 до 330 (= 150 + 180), третьей школе — от 331 до 530 и так далее до последней школы (с 1011 по 1500). Затем мы генерируем случайное начало от 1 до 500 (равное 1500/3) и подсчитываем численность школ, кратную 500. Если бы наше случайное начало было 137, мы бы выбрали школы, которым были присвоены номера 137, 637 и 1137, то есть первая, четвертая и шестая школы.
Подход PPS может повысить точность для заданного размера выборки за счет концентрации выборки на крупных элементах, которые оказывают наибольшее влияние на оценки совокупности. Выборка PPS обычно используется для обследований предприятий, где размер элементов сильно различается и часто доступна вспомогательная информация - например, в опросе, пытающемся измерить количество ночей, проведенных гостями в отелях, в качестве вспомогательной переменной может использоваться количество номеров в каждом отеле. . В некоторых случаях более старые измерения интересующей переменной могут использоваться в качестве вспомогательной переменной при попытке получить более текущие оценки. [ 14 ]
Кластерная выборка
[ редактировать ]
Иногда более рентабельно отбирать респондентов в группах («кластерах»). Выборка часто группируется по географическому признаку или по периодам времени. (Почти все выборки в некотором смысле «кластеризованы» во времени – хотя это редко учитывается при анализе.) Например, при обследовании домохозяйств внутри города мы могли бы выбрать 100 городских кварталов, а затем опросить каждое домохозяйство в пределах города. выбранные блоки.
Кластеризация может сократить командировочные и административные расходы. В приведенном выше примере интервьюер может совершить одну поездку, чтобы посетить несколько домохозяйств в одном квартале, вместо того, чтобы ехать в отдельный квартал для каждого домохозяйства.
Это также означает, что не требуется основа выборки , включающая все элементы целевой совокупности. Вместо этого кластеры можно выбирать из фрейма уровня кластера, при этом фрейм уровня элемента создается только для выбранных кластеров. В приведенном выше примере для первоначального выбора требуется только карта города на уровне квартала, а затем карта уровня домохозяйства из 100 выбранных кварталов, а не карта всего города на уровне домохозяйства.
Кластерная выборка (также известная как кластерная выборка) обычно увеличивает вариативность оценок выборки по сравнению с простой случайной выборкой, в зависимости от того, насколько кластеры отличаются друг от друга по сравнению с вариацией внутри кластера. По этой причине для достижения того же уровня точности кластерная выборка требует большей выборки, чем SRS, но экономия средств за счет кластеризации все равно может сделать этот вариант более дешевым.
Кластерная выборка обычно реализуется как многоэтапная выборка . Это сложная форма кластерной выборки, при которой два или более уровней единиц встроены друг в друга. Первый этап состоит из построения кластеров, из которых будет осуществляться выборка. На втором этапе из каждого кластера случайным образом выбирается выборка первичных единиц (вместо использования всех единиц, содержащихся во всех выбранных кластерах). На следующих этапах в каждом из этих выбранных кластеров отбираются дополнительные образцы единиц и так далее. Затем обследуются все конечные единицы (например, отдельные лица), выбранные на последнем этапе этой процедуры. Таким образом, этот метод по сути представляет собой процесс взятия случайных подвыборок из предыдущих случайных выборок.
Многоэтапная выборка может существенно снизить затраты на выборку, поскольку необходимо составить полный список населения (прежде чем можно будет применять другие методы выборки). Устраняя работу по описанию невыбранных кластеров, многоэтапная выборка может снизить большие затраты, связанные с традиционной кластерной выборкой. [ 14 ] Однако каждая выборка не может быть полным представителем всей совокупности.
Квотная выборка
[ редактировать ]При квотной выборке население сначала сегментируется на взаимоисключающие подгруппы, как и при стратифицированной выборке . Затем используется суждение для выбора предметов или единиц из каждого сегмента на основе заданной пропорции. Например, интервьюеру может быть предложено выбрать 200 женщин и 300 мужчин в возрасте от 45 до 60 лет.
Именно этот второй шаг делает этот метод методом невероятностной выборки. При квотной выборке выборка формируется неслучайно . Например, у интервьюеров может возникнуть соблазн взять интервью у тех, кто выглядит наиболее полезным. Проблема в том, что эти выборки могут быть предвзятыми, поскольку не у всех есть шанс выбраться. Этот случайный элемент является его самой большой слабостью, а соотношение квоты и вероятности было предметом споров в течение нескольких лет.
Минимаксная выборка
[ редактировать ]В несбалансированных наборах данных, где коэффициент выборки не соответствует статистике населения, можно выполнить повторную выборку набора данных консервативным способом, называемым минимаксной выборкой . Минимаксная выборка берет свое начало в минимаксном коэффициенте Андерсона, значение которого, как доказано, равно 0,5: в бинарной классификации размеры классовой выборки должны выбираться одинаково. Можно доказать, что это соотношение является минимаксным отношением только в предположении, что классификатор LDA имеет гауссово распределение. Понятие минимаксной выборки недавно было разработано для общего класса правил классификации, называемых поклассовыми интеллектуальными классификаторами. В этом случае соотношение выборки классов выбирается таким образом, чтобы наихудшая ошибка классификатора по всей возможной статистике совокупности для априорных вероятностей классов была бы наилучшей. [ 12 ]
Случайный отбор проб
[ редактировать ]Случайная выборка (иногда известная как выборка по принципу «захвата» , «выборка по удобству» или «выборка по возможности» ) — это тип невероятностной выборки, при которой выборка формируется из той части генеральной совокупности, которая находится под рукой. То есть популяция выбирается потому, что она легко доступна и удобна. Это может быть путем знакомства с человеком или включения человека в выборку при знакомстве или выбора путем нахождения его с помощью технологических средств, таких как Интернет или телефон. Исследователь, использующий такую выборку, не может с научной точки зрения сделать обобщения об общей численности населения на основе этой выборки, поскольку она не будет достаточно репрезентативной. Например, если бы интервьюер провел такой опрос в торговом центре рано утром в определенный день, люди, с которыми он мог бы опросить, были бы ограничены теми, кто находился там в этот данный момент времени, что не отражало бы взгляды других членов общества на такой территории, если опрос будет проводиться в разное время суток и несколько раз в неделю. Этот тип выборки наиболее полезен для пилотного тестирования. Несколько важных соображений для исследователей, использующих удобные образцы, включают:
- Существуют ли в рамках плана исследования или эксперимента средства контроля, которые могут помочь уменьшить влияние неслучайной удобной выборки, гарантируя тем самым, что результаты будут более репрезентативными для генеральной совокупности?
- Есть ли веские основания полагать, что конкретная удобная выборка будет или должна реагировать или вести себя иначе, чем случайная выборка из той же совокупности?
- Можно ли адекватно ответить на вопрос, заданный в ходе исследования, используя удобную выборку?
В исследованиях в области социальных наук выборка «снежный ком» представляет собой аналогичный метод, при котором существующие субъекты исследования используются для набора большего количества субъектов в выборку. Некоторые варианты выборки «снежным комом», такие как выборка по инициативе респондентов, позволяют рассчитывать вероятности отбора и представляют собой методы вероятностной выборки при определенных условиях.
Добровольный отбор проб
[ редактировать ]Метод добровольной выборки представляет собой разновидность невероятностной выборки. Добровольцы решили пройти опрос.
Волонтёров можно пригласить через рекламу в социальных сетях. [ 15 ] Целевую аудиторию для рекламы можно выбрать по таким характеристикам, как местоположение, возраст, пол, доход, род занятий, образование или интересы, используя инструменты, предоставляемые социальной средой. Реклама может включать сообщение об исследовании и ссылку на опрос. Перейдя по ссылке и заполнив опрос, волонтер отправляет данные для включения в выборку. Этот метод может охватить население всего мира, но его возможности ограничены бюджетом кампании. В выборку также могут быть включены волонтеры, не входящие в приглашаемую группу населения.
На основе этой выборки трудно делать обобщения, поскольку она может не отражать всю совокупность населения. Зачастую волонтеры проявляют сильный интерес к основной теме опроса.
Выборка перехвата линии
[ редактировать ]Выборка методом пересечения линии — это метод выборки элементов в регионе, при котором выборка элемента производится, если выбранный сегмент линии, называемый «трансектом», пересекает элемент.
Панельный отбор проб
[ редактировать ]Панельная выборка — это метод, при котором сначала выбирают группу участников методом случайной выборки, а затем запрашивают у этой группы (потенциально одну и ту же) информацию несколько раз в течение определенного периода времени. Таким образом, каждый участник опрашивается в два или более момента времени; каждый период сбора данных называется «волной». Метод был разработан социологом Полом Лазарсфельдом в 1938 году как средство изучения политических кампаний . [ 16 ] Этот метод продольной выборки позволяет оценить изменения в популяции, например, в отношении хронических заболеваний, стресса на работе и еженедельных расходов на питание. Панельную выборку также можно использовать для информирования исследователей об изменениях в состоянии здоровья человека в зависимости от возраста или для объяснения изменений в непрерывных зависимых переменных, таких как супружеское взаимодействие. [ 17 ] Было предложено несколько методов анализа панельных данных , включая MANOVA , кривые роста и моделирование структурными уравнениями с запаздывающими эффектами.
Выборка снежного кома
[ редактировать ]Выборка «снежный ком» предполагает поиск небольшой группы первоначальных респондентов и использование ее для набора большего количества респондентов. Это особенно полезно в тех случаях, когда население скрыто или его сложно подсчитать.
Теоретическая выборка
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( июль 2015 г. ) |
Теоретическая выборка [ 18 ] происходит, когда образцы отбираются на основе результатов собранных к настоящему времени данных с целью более глубокого понимания области или разработки теорий. Могут быть выбраны крайние или очень специфические случаи, чтобы максимизировать вероятность того, что явление действительно будет наблюдаемо.
Активная выборка
[ редактировать ]При активной выборке выборки, которые используются для обучения алгоритма машинного обучения, активно отбираются, а также сравниваются при активном обучении (машинном обучении) .
Судебный выбор
[ редактировать ]Случайный отбор проб
[ редактировать ]Этот раздел нуждается в расширении . Вы можете помочь, добавив к нему . ( июль 2024 г. ) |
Замена выбранных агрегатов
[ редактировать ]Схемы выборки могут быть без замены («WOR» – ни один элемент не может быть выбран более одного раза в одной выборке) или с заменой («WR» – элемент может появляться в одной выборке несколько раз). Например, если мы ловим рыбу, измеряем ее и немедленно возвращаем в воду, прежде чем продолжить отбор проб, это схема WR, потому что в конечном итоге нам придется ловить и измерять одну и ту же рыбу более одного раза. Однако, если мы не возвращаем рыбу в воду или не маркируем и не отпускаем каждую рыбу после ее поимки, это становится проектом WOR.
Определение размера выборки
[ редактировать ]Формулы, таблицы и диаграммы степенных функций — это хорошо известные подходы к определению размера выборки.
Шаги по использованию таблиц размеров выборки:
- Постулируйте интересующую величину эффекта α и β.
- Проверьте таблицу размеров выборки [ 19 ]
- Выберите таблицу, соответствующую выбранному α
- Найдите строку, соответствующую желаемой мощности.
- Найдите столбец, соответствующий предполагаемому размеру эффекта.
- Пересечение столбца и строки представляет собой минимальный требуемый размер выборки.
Отбор проб и сбор данных
[ редактировать ]Хороший сбор данных включает в себя:
- Следование установленному процессу отбора проб
- Хранение данных во времени
- Отслеживание комментариев и других контекстуальных событий
- Регистрация отсутствия ответов
Применение отбора проб
[ редактировать ]Выборка позволяет выбрать правильные точки данных из более крупного набора данных для оценки характеристик всей совокупности. Например, каждый день создается около 600 миллионов твитов. Нет необходимости просматривать их все, чтобы определить темы, обсуждаемые в течение дня, также нет необходимости просматривать все твиты, чтобы определить настроения по каждой из тем. Была разработана теоретическая формулировка выборки данных Twitter. [ 20 ]
При производстве различные типы сенсорных данных, таких как акустика, вибрация, давление, ток, напряжение и данные контроллера, доступны через короткие промежутки времени. Чтобы спрогнозировать время простоя, возможно, нет необходимости просматривать все данные, но выборки может быть достаточно.
Ошибки в выборочных опросах
[ редактировать ]Результаты опроса обычно содержат некоторые ошибки. Общие ошибки можно разделить на ошибки выборки и ошибки, не связанные с выборкой. Термин «ошибка» здесь включает систематические отклонения, а также случайные ошибки.
Ошибки выборки и систематические ошибки
[ редактировать ]Ошибки и систематические ошибки выборки вызваны структурой выборки. Они включают в себя:
- Смещение выбора : когда истинные вероятности выбора отличаются от предполагаемых при расчете результатов.
- Случайная ошибка выборки : случайное изменение результатов из-за того, что элементы выборки выбираются случайным образом.
Ошибка, не связанная с выборкой
[ редактировать ]Ошибки, не связанные с выборкой, – это другие ошибки, которые могут повлиять на окончательные оценки обследования, вызванные проблемами в сборе, обработке или планировании выборки. К таким ошибкам могут относиться:
- Чрезмерный охват: включение данных, полученных за пределами населения
- Недостаточный охват: основа выборки не включает элементы генеральной совокупности.
- Ошибка измерения: например, когда респонденты неправильно понимают вопрос или затрудняются ответить.
- Ошибка обработки: ошибки в кодировании данных
- Неответ или систематическая ошибка участия : невозможность получить полные данные от всех выбранных лиц.
После отбора проб проводится проверка точного процесса отбора проб, а не запланированного, с целью изучения любых последствий, которые любые расхождения могут оказать на последующий анализ.
Особая проблема связана с отсутствием ответа . Существуют два основных типа отсутствия ответов: [ 21 ] [ 22 ]
- единица неполучения ответов (незаполнение какой-либо части опроса)
- отсутствие ответа по пункту (отправка или участие в опросе, но неспособность ответить на один или несколько компонентов/вопросов опроса)
В выборке обследования многие из лиц, включенных в выборку, могут не захотеть участвовать, у них не будет времени для участия ( альтернативные издержки ), [ 23 ] или администраторы опроса, возможно, не смогли с ними связаться. В этом случае существует риск различий между респондентами и нереспондентами, что приведет к необъективным оценкам параметров совокупности. Эту проблему часто решают путем улучшения структуры опроса, предложения стимулов и проведения последующих исследований, в ходе которых предпринимаются неоднократные попытки связаться с теми, кто не отвечает, и охарактеризовать их сходства и различия с остальной частью выборки. [ 24 ] Эффекты также можно смягчить путем взвешивания данных (при наличии контрольных показателей населения) или путем условного расчета данных на основе ответов на другие вопросы. Отсутствие ответов представляет собой особую проблему при интернет-выборке. Причинами этой проблемы могут быть неправильно разработанные опросы, [ 22 ] чрезмерная съемка (или усталость от съемки), [ 17 ] [ 25 ] [ нужна цитата для проверки ] и тот факт, что потенциальные участники могут иметь несколько адресов электронной почты, которые они больше не используют или не проверяют регулярно.
Вес опроса
[ редактировать ]Во многих ситуациях доля выборки может варьироваться в зависимости от страты, и данные необходимо будет взвешивать, чтобы правильно представить генеральную совокупность. Так, например, простая случайная выборка лиц в Соединенном Королевстве может не включать некоторых жителей отдаленных шотландских островов, выборка которых будет стоить непомерно дорого. Более дешевым методом было бы использование стратифицированной выборки с городскими и сельскими слоями. Сельская выборка может быть недостаточно представлена в выборке, но ей будет присвоен соответствующий вес в анализе, чтобы компенсировать это.
В более общем плане данные обычно следует взвешивать, если структура выборки не дает каждому человеку равных шансов быть выбранным. Например, когда домохозяйства имеют равные вероятности выбора, но в каждом домохозяйстве опрашивается один человек, это дает людям из больших домохозяйств меньшие шансы на собеседование. Это можно учесть с помощью весов опроса. Аналогичным образом, домохозяйства, имеющие более одной телефонной линии, имеют больше шансов быть выбранными в выборке случайного набора номеров, и с учетом этого можно корректировать веса.
Веса могут также служить и другим целям, например, помочь скорректировать отсутствие ответов.
Методы создания случайных выборок
[ редактировать ]- Таблица случайных чисел
- Математические алгоритмы генераторов псевдослучайных чисел
- Физические устройства рандомизации, такие как монеты, игральные карты или сложные устройства, такие как ERNIE.
См. также
[ редактировать ]- Сбор данных
- Эффект дизайна
- Теория оценки
- Теория выборки Гая
- Проблема немецкого танка
- Оценщик Хорвица – Томпсона
- Официальная статистика
- Оценщик соотношения
- Репликация (статистика)
- Механизм случайной выборки
- Повторная выборка (статистика)
- Выборка псевдослучайных чисел
- Определение размера выборки
- Выборка (тематические исследования)
- Смещение выборки
- Выборочное распределение
- Ошибка выборки
- Жеребьевка
- Выборка опроса
Примечания
[ редактировать ]В учебнике Гроувса и других представлен обзор методологии опроса, включая недавнюю литературу по разработке анкет (на основе когнитивной психологии ):
- Роберт Гроувс и др. Методика опроса (2-е изд. 2010 г. [2004 г.]) ISBN 0-471-48348-6 .
Другие книги посвящены статистической теории выборки обследований и требуют некоторых знаний базовой статистики, как описано в следующих учебниках:
- Дэвид С. Мур и Джордж П. Маккейб (февраль 2005 г.). « Введение в практику статистики » (5-е издание). WH Фриман и компания. ISBN 0-7167-6282-X .
- Фридман, Дэвид ; Смолл, Роберт; Первс, Роджер (2007). Статистика (4-е изд.). Нью-Йорк: Нортон . ISBN 978-0-393-92972-0 .
В элементарной книге Шеффера и других используются квадратные уравнения из школьной алгебры:
- Шеффер, Ричард Л., Уильям Менденхал и Р. Лайман Отт. Выборка элементарного обследования , пятое издание. Бельмонт: Даксбери Пресс, 1996.
Для Лора, Сярндаля и других и Кокрана требуется дополнительная математическая статистика: [ 26 ]
- Кокран, Уильям Г. (1977). Методы отбора проб (Третье изд.). Уайли. ISBN 978-0-471-16240-7 .
- Лор, Шэрон Л. (1999). Отбор проб: проектирование и анализ . Даксбери. ISBN 978-0-534-35361-2 .
- Сярндал, Карл-Эрик ; Свенсон, Бенгт; Ретман, Ян (1992). Выборка обследования с помощью модели . Спрингер Верлаг. ISBN 978-0-387-40620-6 .
Исторически важные книги Деминга и Киша остаются ценными для социологов (особенно о переписи населения США и Институте социальных исследований ) Мичиганского университета :
- Деминг, В. Эдвардс (1966). Немного теории выборки . Дуврские публикации . ISBN 978-0-486-64684-8 . OCLC 166526 .
- Киш, Лесли (1995) Выборка опроса , Уайли, ISBN 0-471-10949-5
Ссылки
[ редактировать ]- ^ Лэнс, П.; Хаттори, А. (2016). Выборка и оценка . Интернет: Оценка MEASURE. стр. 6–8, 62–64.
- ^ Салант, Присцилла, И. Диллман и А. Дон. Как провести собственный опрос . № 300.723 С3. 1994.
- ^ Сенета, Э. (1985). «Очерк истории опросной выборки в России» . Журнал Королевского статистического общества. Серия А (Общая) . 148 (2): 118–125. дои : 10.2307/2981944 . JSTOR 2981944 .
- ^ Дэвид С. Мур и Джордж П. Маккейб. « Введение в практику статистики ».
- ^ Фридман, Дэвид ; Пизани, Роберт; Первс, Роджер. Статистика .
- ^ «ПРИМЕРНЫЙ ПОДСЧЕТ — Департамент выборов Сингапура» (PDF) . Проверено 3 сентября 2023 г.
- ^ Хо, Тимоти (1 сентября 2023 г.). «Президентские выборы 2023 года: насколько точным будет подсчет выборок сегодня вечером?» . DollarsAndSense.sg . Проверено 3 сентября 2023 г.
- ^ Jump up to: а б с д Роберт М. Гроувс; и др. (2009). Методика опроса . ISBN 978-0470465462 .
- ^ Лор, Шэрон Л. Отбор проб: проектирование и анализ .
- ^ Сярндал, Карл-Эрик; Свенсон, Бенгт; Ретман, Ян. Выборка опроса с помощью модели .
- ^ Шеффер, Ричард Л.; Уильям Менденхал; Р. Лайман Отт. (2006). Выборка элементарного обследования .
- ^ Jump up to: а б с Шахрох Исфахани, Мохаммед; Догерти, Эдвард (2014). «Влияние раздельной выборки на точность классификации» . Биоинформатика . 30 (2): 242–250. doi : 10.1093/биоинформатика/btt662 . ПМИД 24257187 .
- ^ Скотт, Эй Джей; Уайлд, CJ (1986). «Подбор логистических моделей под случай-контроль или выборку на основе выбора». Журнал Королевского статистического общества, серия B. 48 (2): 170–182. дои : 10.1111/j.2517-6161.1986.tb01400.x . JSTOR 2345712 .
- ^ Jump up to: а б
- Лор, Шэрон Л. Отбор проб: планирование и анализ .
- Сярндал, Карл-Эрик; Свенсон, Бенгт; Ретман, Ян. Выборка опроса с помощью модели .
- ^ Арияратне, Буддика (30 июля 2017 г.). «Метод добровольной выборки в сочетании с рекламой в социальных сетях» . heel-info.blogspot.com . Информатика здравоохранения . Проверено 18 декабря 2018 г. [ ненадежный источник? ]
- ^ Лазарсфельд П. и Фиске М. (1938). «Панель» как новый инструмент измерения мнений. Ежеквартальный журнал «Общественное мнение», 2 (4), 596–612.
- ^ Jump up to: а б Гровс и др. Методология опроса
- ^ «Примеры методов отбора проб» (PDF) .
- ^ Коэн, 1988
- ^ Дипан Палгуна; Викас Джоши; Венкатесан Чакараварти; Рави Котари; Л.В. Субраманиам (2015). Анализ алгоритмов выборки для Twitter . Международная совместная конференция по искусственному интеллекту .
- ^ Беринский, AJ (2008). «Отказ от ответа на опрос». В: В. Донсбах и М.В. Трауготт (ред.), Справочник Sage по исследованию общественного мнения (стр. 309–321). Таузенд-Оукс, Калифорния: Публикации Sage.
- ^ Jump up to: а б Диллман Д.А., Элтинг Дж.Л., Гровс Р.М. и Литтл RJA (2002). «Отсутствие ответов на опросы при разработке, сборе и анализе данных». В: Р.М. Гроувс, Д.А. Диллман, Дж.Л. Элтинг и Р.Дж.А. Литтл (ред.), отсутствие ответов на опросы (стр. 3–26). Нью-Йорк: Джон Уайли и сыновья.
- ^ Диллман, Д.А., Смит, Дж.Д., и Кристиан, Л.М. (2009). Интернет, почта и смешанные опросы: метод индивидуального проектирования. Сан-Франциско: Джосси-Басс.
- ^ Веховар В., Батагель З., Манфреда К.Л. и Залетел М. (2002). «Отсутствие ответов в веб-опросах». В: Р.М. Гроувс, Д.А. Диллман, Дж.Л. Элтинг и Р.Дж.А. Литтл (ред.), Отсутствие ответов на опросы (стр. 229–242). Нью-Йорк: Джон Уайли и сыновья.
- ^ Портье; Уиткомб; Вайцер (2004). «Множественные опросы студентов и усталость от опросов». В Портере, Стивен Р. (ред.). Преодоление проблем опросного исследования . Новые направления институциональных исследований. Сан-Франциско: Джосси-Басс. стр. 63–74. ISBN 9780787974770 . Проверено 15 июля 2019 г.
- ^ Кокран, Уильям Г. (1 января 1977 г.). Методы отбора проб, 3-е издание (3-е изд.). Нью-Йорк, штат Нью-Йорк: Джон Уайли и сыновья. ISBN 978-0-471-16240-7 .
Дальнейшее чтение
[ редактировать ]- Сингх, Г.Н., Джайсвал, А.К. и Панди А.К. (2021), Улучшенные методы вменения недостающих данных при двухкратной последовательной выборке, Коммуникации в статистике: теория и методы. DOI:10.1080/03610926.2021.1944211
- Чемберс, Р.Л., и Скиннер, С.Дж. (редакторы) (2003), Анализ данных опроса , Уайли, ISBN 0-471-89987-9
- Деминг, В. Эдвардс (1975) О вероятности как основе действий, Американский статистик , 29 (4), стр. 146–152.
- Гай, П. (2012) Отбор проб гетерогенных и динамических материальных систем: теории неоднородности, отбор проб и гомогенизация , Elsevier Science, ISBN 978-0444556066
- Корн Э.Л. и Граубард Б.И. (1999) Анализ обследований здоровья , Wiley, ISBN 0-471-13773-1
- Лукас, Сэмюэл Р. (2012). doi : 10.1007%2Fs11135-012-9775-3 «За пределами доказательства существования: онтологические условия, эпистемологические последствия и углубленное исследование в ходе интервью».], Качество и количество , два : 10.1007/s11135-012-9775-3 .
- Стюарт, Алан (1962) Основные идеи научного отбора проб , издательство Hafner Publishing Company, Нью-Йорк. [ ISBN отсутствует ]
- Смит, ТМФ (1984). «Текущая позиция и потенциальное развитие: некоторые личные взгляды: примеры опросов». Журнал Королевского статистического общества, серия A. 147 (150-летие Королевского статистического общества, номер 2): 208–221. дои : 10.2307/2981677 . JSTOR 2981677 .
- Смит, ТМФ (1993). «Популяции и отбор: ограничения статистики (послание президента)». Журнал Королевского статистического общества, серия A. 156 (2): 144–166. дои : 10.2307/2982726 . JSTOR 2982726 . (Портрет ТМФ Смита на стр. 144)
- Смит, ТМФ (2001). «Столетие: Выборочные опросы». Биометрика . 88 (1): 167–243. дои : 10.1093/biomet/88.1.167 .
- Смит, ТМФ (2001). «Столетие биометрики: Выборочные исследования». В Д.М. Титтерингтоне и Д.Р. Коксе (ред.). Биометрика : сто лет . Издательство Оксфордского университета. стр. 165–194. ISBN 978-0-19-850993-6 .
- Уиттл, П. (май 1954 г.). «Оптимальный профилактический отбор проб». Журнал Американского общества исследования операций . 2 (2): 197–203. дои : 10.1287/опре.2.2.197 . JSTOR 166605 .
Стандарты
[ редактировать ]ИСО
[ редактировать ]- Серия ISO 2859
- Серия ИСО 3951
АСТМ
[ редактировать ]- Стандартная практика ASTM E105 для вероятностного отбора проб материалов
- Стандартная практика ASTM E122 для расчета размера выборки для оценки с заданной допустимой погрешностью среднего значения характеристики партии или процесса
- Стандартная практика ASTM E141 по принятию доказательств, основанных на результатах вероятностной выборки
- Стандартная терминология ASTM E1402, касающаяся отбора проб
- Стандартная практика ASTM E1994 для использования процессно-ориентированных планов выборочного контроля AOQL и LTPD
- Стандартная практика ASTM E2234 для отбора проб потока продукции по атрибутам, индексируемым AQL
АНСИ, АСК
[ редактировать ]- АНСИ/АСК Z1.4
Федеральные и военные стандарты США
[ редактировать ]- МИЛ-СТД-105
- MIL-STD-1916
Внешние ссылки
[ редактировать ] СМИ, связанные с выборкой (статистикой) на Викискладе?
СМИ, связанные с выборкой (статистикой) на Викискладе?