Персонажи универсального набора символов

Консорциум Unicode и ISO/IEC JTC 1/SC 2 / WG 2 совместно работают над списком символов в универсальном кодированном наборе символов . Универсальный набор кодированных символов, чаще всего называемый универсальным набором символов ( сокр. UCS, официальное обозначение: ISO / IEC 10646), представляет собой международный стандарт для отображения символов , дискретных символов, используемых в естественном языке , математике , музыке и других областях. к уникальным машиночитаемым значениям данных. Создавая такое сопоставление, UCS позволяет поставщикам компьютерного программного обеспечения взаимодействовать в и передавать (обменивать) текстовые строки UCS, , закодированные друг другу. Поскольку это универсальная карта, ее можно использовать для одновременного представления нескольких языков. Это позволяет избежать путаницы, связанной с использованием нескольких устаревших кодировок символов , что может привести к тому, что одна и та же последовательность кодов будет иметь несколько интерпретаций в зависимости от используемой кодировки символов, что приведет к моджибаке, если будет выбрана неправильная кодировка.
UCS имеет потенциальную емкость более 1 миллиона символов. Каждый символ UCS абстрактно представлен кодовой точкой — целым числом от 0 до 1 114 111 (1 114 112 = 2). 20 + 2 16 или 17 × 2 16 = 0x 110000 кодовых точек ), используемый для представления каждого символа во внутренней логике программного обеспечения для обработки текста . По состоянию на Unicode 15.1, выпущенную в сентябре 2023 года, 293 792 (26%) этих кодовых точек выделены, 149 878 (13%) присвоены символы, 137 468 (12%) зарезервированы для частного использования , 2048 используются для включения механизма. суррогатов . , а 66 обозначены как несимволы , оставляя оставшиеся 820 320 (74%) нераспределенными Количество закодированных символов формируется следующим образом:
- 149 641 графический символ (некоторые из которых не имеют видимого глифа , но все равно считаются графическими)
- 237 символов специального назначения для управления и форматирования .
ISO поддерживает базовое сопоставление символов от имени символа до кодовой точки. Часто термины «символ» и «кодовая точка» используются как взаимозаменяемые. Однако, когда проводится различие, кодовая точка относится к целому числу символа: то, что можно назвать его адресом. Между тем, символ в ISO/IEC 10646 включает комбинацию кодовой точки и его имени, а Unicode добавляет множество других полезных свойств к набору символов , таких как блок , категория, сценарий и направленность .
В дополнение к UCS, дополнительный стандарт Unicode (не совместный проект с ISO, а скорее публикация Консорциума Unicode) предоставляет другие детали реализации, такие как:
- сопоставления между UCS и другими наборами символов
- разные сопоставления символов и строк символов для разных языков
- алгоритм расположения двунаправленного текста (« алгоритм BiDi »), при котором текст в одной строке может сдвигаться между слева направо («LTR») и справа налево («RTL»).
- регистра свертывания алгоритм
компьютерного программного обеспечения Конечные пользователи вводят эти символы в программы с помощью различных методов ввода , например, с помощью физической клавиатуры или виртуальной палитры символов .
ПСК можно разделить различными способами, например по плоскости , блоку, категории символов или свойствам символов . [1]
Обзор ссылок на персонажей [ править ]
XML ссылается Ссылка на числовой символ HTML или на символ по его кодовой точке универсального набора символов /Юникода и использует формат
&#нннн;
или
&#xхххх;
где nnnn — это кодовая точка в десятичной форме, а hhhh — это кодовая точка в шестнадцатеричной форме. В документах XML x должен быть в нижнем регистре. nnnn могут состоять из или hhhh любого количества цифр и могут включать ведущие нули. В hhhh могут сочетаться прописные и строчные буквы, хотя обычно используется верхний регистр.
Напротив, ссылка на символьную сущность относится к символу по имени сущности , которая имеет желаемый символ в качестве замещающего текста . Сущность должна быть либо предопределена (встроена в язык разметки), либо явно объявлена в определении типа документа (DTD). Формат такой же, как и для любой ссылки на объект:
&имя;
где name — это имя объекта с учетом регистра. Точка с запятой обязательна.
Самолеты [ править ]
Unicode и ISO делят набор кодовых точек на 17 плоскостей, каждая из которых может содержать 65 536 различных символов или всего 1 114 112 символов. По состоянию на 2023 год (Unicode 15.1) ISO и Консорциум Unicode выделили символы и блоки только в семи из 17 плоскостей. Остальные остаются пустыми и зарезервированы для использования в будущем.
Большинство символов в настоящее время отнесены к первому уровню: базовому многоязычному уровню . Это сделано для того, чтобы облегчить переход на устаревшее программное обеспечение, поскольку базовая многоязычная плоскость адресуется всего двумя октетами . Персонажи за пределами первого плана обычно используются очень специализированно или редко.
Каждая плоскость соответствует значению одной или двух шестнадцатеричных цифр (0–9, A–F), предшествующих четырем последним: следовательно, U + 24321 находится в плоскости 2, U + 4321 находится в плоскости 0 (неявно читается как U + 04321). ), а U+10A200 будет в плоскости 16 (шестнадцатеричное 10 = десятичное 16). В пределах одной плоскости диапазон кодовых точек находится в шестнадцатеричном формате от 0000 до FFFF, что дает максимум 65536 кодовых точек. Плоскости ограничивают кодовые точки подмножеством этого диапазона.
Блоки [ править ]
Unicode добавляет в UCS свойство блока, которое дополнительно делит каждую плоскость на отдельные блоки. Каждый блок представляет собой группу символов по их использованию, например «математические операторы» или «символы еврейского алфавита». При назначении символов ранее не назначенным кодовым точкам Консорциум обычно выделяет целые блоки похожих символов: например, все символы, принадлежащие одному и тому же сценарию, или все символы аналогичного назначения назначаются одному блоку. Блоки также могут сохранять неназначенные или зарезервированные кодовые точки, когда Консорциум ожидает, что блок потребует дополнительных присвоений.
Первые 256 кодовых точек в UCS соответствуют кодам ISO 8859-1 , самой популярной 8-битной кодировки символов в западном мире . В результате первые 128 символов также идентичны ASCII . Хотя Unicode называет их блоками латинского алфавита, эти два блока содержат множество символов, которые обычно используются за пределами латинского алфавита. В общем, не все символы в данном блоке обязательно должны принадлежать одному и тому же сценарию, и один и тот же сценарий может встречаться в нескольких разных блоках.
Категории [ править ]
Unicode присваивает каждому символу UCS общую категорию и подкатегорию. Общие категории: буква, знак, цифра, пунктуация, символ или элемент управления (другими словами, символ форматирования или неграфический символ).
Типы включают в себя:
- Современные, исторические и древние письменности . По состоянию на 2023 год (Юникод 15.1) UCS идентифицирует 161 алфавит, которые используются или использовались во всем мире. Многие другие находятся на различных стадиях утверждения для будущего включения UCS. [2]
- Международный фонетический алфавит . UCS отводит несколько блоков (более 300 символов) символам Международного фонетического алфавита .
- Объединение диакритических знаков . Важным достижением Unicode в разработке UCS и связанных с ним алгоритмов обработки текста стало введение комбинирования диакритических знаков. Предоставляя акценты, которые могут сочетаться с любым буквенным символом, Unicode и UCS значительно сокращают количество необходимых символов. Хотя UCS также включает в себя заранее составленные символы, они были включены в первую очередь для облегчения поддержки в UCS систем обработки текста, не поддерживающих Unicode.
- Пунктуация . Наряду с унификацией диакритических знаков UCS также стремился унифицировать пунктуацию во всех алфавитах. Однако многие сценарии также содержат знаки препинания, если они не имеют аналогичной семантики в других сценариях.
- Символы . В ПСК включено множество математических, технических, геометрических и других символов. Это обеспечивает отдельные символы со своей собственной кодовой точкой или символом вместо того, чтобы полагаться на переключение шрифтов для создания символических глифов.
- Валюта .
- Буквенное . Эти символы выглядят как комбинации многих распространенных букв латинского алфавита, таких как ℅ . Юникод обычно обозначает многие буквоподобные символы как символы совместимости, потому что они могут быть в простом тексте путем замены глифов на составную последовательность символов: например, замена глифа ℅ на составную последовательность символов c/o .
- Числовые формы . Формы чисел в основном состоят из заранее составленных дробей и римских цифр. Как и другие области составления последовательностей символов, подход Unicode отдает предпочтение гибкости составления дробей путем объединения символов. В этом случае для создания дробей числа объединяются с символом косой черты дроби (U+2044). В качестве примера гибкости, которую обеспечивает этот подход, в UCS включено девятнадцать заранее составленных символов дробей. Однако существует бесконечное количество возможных дробей. При использовании составных символов бесконечность дробей обрабатывается 11 символами (0–9 и косая черта). Ни один набор символов не может включать кодовые точки для каждой предварительно составленной дроби. В идеале текстовая система должна представлять одни и те же глифы для дробей, будь то одна из заранее составленных дробей (например, ⅓ ) или составная последовательность символов (например, 1/3 ). Однако веб-браузеры обычно не настолько сложны в работе с Unicode и обработкой текста. Это гарантирует, что предварительно составленные дроби и дроби комбинированной последовательности будут выглядеть совместимыми рядом друг с другом.
- Стрелки .
- Математический .
- Геометрические фигуры .
- Унаследованные вычисления .
- Управляющие изображения Графическое представление многих управляющих символов.
- Рисунок коробки .
- Блок-элементы .
- Узоры Брайля .
- Оптическое распознавание символов .
- Технический .
- DingbatsДингбаты
- Разные символы .
- Смайлики .
- Символы и пиктограммы .
- Алхимические символы .
- Игровые фигуры (шахматы, шашки, го, кости, домино, маджонг, игральные карты и многие другие).
- Шахматные символы
- Тай Сюань Цзин .
- Символы гексаграммы Ицзин .
- CJK . Посвящается иероглифам и другим символам для поддержки языков Китая, Японии, Кореи (CJK), Тайваня, Вьетнама и Таиланда.
- Радикалы и удары .
- Идеографии . Безусловно, большая часть UCS посвящена иероглифам, используемым в языках Восточной Азии. Хотя глифическое представление этих иероглифов различается в языках, которые их используют, UCS объединяет эти символы хань в то, что в Юникоде называется Unihan (от Unified Han). В Unihan программное обеспечение для верстки текста должно работать вместе с доступными шрифтами и символами Юникода, чтобы создать соответствующий глиф для соответствующего языка. Несмотря на объединение этих символов, UCS по-прежнему включает более 97 000 иероглифов Unihan.
- Музыкальная нотация .
- Дуплоянские сокращения .
- Саттон SignWriting .
- Совместимость персонажей . Несколько блоков в UCS почти полностью посвящены символам совместимости. Символы совместимости — это символы, включенные для поддержки устаревших систем обработки текста, которые не делают различия между символами и глифами, как это делает Unicode. Например, многие арабские буквы представлены разными глифами, когда буква появляется в конце слова, а не когда буква появляется в начале слова. Подход Unicode предпочитает сопоставлять эти буквы одному и тому же символу для упрощения внутренней обработки и хранения машинного текста. В дополнение к этому подходу текстовое программное обеспечение должно выбирать различные варианты глифа для отображения символа в зависимости от его контекста. По соображениям совместимости включено более 4000 символов.
- Управляющие персонажи .
- Суррогаты . UCS включает 2048 кодовых точек в базовой многоязычной плоскости (BMP) для пар суррогатных кодовых точек. Вместе эти суррогатные коды позволяют обращаться к любой кодовой точке в шестнадцати других плоскостях с помощью двух суррогатных кодовых точек. Это обеспечивает простой встроенный метод кодирования 20,1-битной UCS в 16-битной кодировке, например UTF-16. Таким образом, UTF-16 может представлять любой символ в BMP одним 16-битным словом. Символы вне BMP затем кодируются с использованием двух 16-битных слов (всего 4 октета или байта) с использованием суррогатных пар.
- Частное использование . Консорциум предоставляет несколько блоков и плоскостей для частного использования, которым можно назначать символы в рамках различных сообществ, а также поставщиков операционных систем и шрифтов.
- Неперсонажи . Консорциум гарантирует, что определенным кодовым точкам никогда не будут присвоены символы, и называет эти несимвольные кодовые точки. К ним относятся диапазон U+FDD0..U+FDEF и две последние кодовые точки каждой плоскости (оканчивающиеся шестнадцатеричными цифрами FFFE и FFFF). [3]
Символы специального назначения [ править ]
Юникод кодирует более ста тысяч символов. Большинство из них представляют собой графемы для обработки в виде линейного текста. Некоторые, однако, либо не представляют собой графемы, либо, как графемы, требуют особого обращения. [4] [5] В отличие от управляющих символов ASCII и других символов, включенных в устаревшие возможности двустороннего обмена, эти другие символы специального назначения наделяют простой текст важной семантикой.
Некоторые специальные символы могут изменять макет текста, например, соединитель нулевой ширины и необъединяющий элемент нулевой ширины , в то время как другие вообще не влияют на макет текста, а вместо этого влияют на способ сопоставления, сопоставления или иной обработки текстовых строк. Другие символы специального назначения, такие как математические невидимые символы , обычно не влияют на рендеринг текста, хотя сложное программное обеспечение для верстки текста может слегка регулировать расстояние вокруг них.
Юникод не определяет разделение труда между шрифтом и программным обеспечением для верстки текста (или «движком») при рендеринге текста в Юникоде. Поскольку более сложные форматы шрифтов, такие как OpenType или Apple Advanced Typography , обеспечивают контекстную замену и позиционирование глифов, простой механизм компоновки текста может полностью полагаться на шрифт при принятии всех решений по выбору и размещению глифов. В той же ситуации более сложный движок может комбинировать информацию шрифта со своими собственными правилами для достижения собственной идеи наилучшего рендеринга. Для реализации всех рекомендаций спецификации Unicode текстовый движок должен быть готов к работе со шрифтами любого уровня сложности, поскольку правила контекстной подстановки и позиционирования не существуют в некоторых форматах шрифтов и являются необязательными в остальных. Примером может служить дробная косая черта : сложные шрифты могут предоставлять или не предоставлять правила позиционирования при наличии дробного символа косой черты для создания дроби, тогда как шрифты в простых форматах не могут этого сделать.
Знак порядка байтов [ править ]
Появляясь в начале текстового файла или потока, знак порядка байтов (BOM) U+FEFF намекает на форму кодирования и порядок ее байтов.
Если первый байт потока — 0xFE, а второй — 0xFF, то текст потока вряд ли будет закодирован в UTF-8 , поскольку эти байты недопустимы в UTF-8. Также маловероятно, что это будет UTF-16 с прямым порядком байтов, поскольку 0xFE, 0xFF, прочитанные как 16-битное слово с прямым порядком байтов, будут иметь вид U+FFFE, что бессмысленно. Последовательность также не имеет значения ни при каком варианте кодировки UTF-32 , поэтому, вкратце, она служит достаточно надежным индикатором того, что текстовый поток закодирован как UTF-16 в порядке байтов с обратным порядком байтов. И наоборот, если первые два байта — 0xFF, 0xFE, то можно предположить, что текстовый поток закодирован как UTF-16LE, поскольку при чтении как 16-битного значения с прямым порядком байтов байты дают ожидаемую метку порядка байтов 0xFEFF. Однако это предположение становится сомнительным, если оба следующих двух байта равны 0x00; либо текст начинается с нулевого символа (U+0000), либо на самом деле правильной кодировкой является UTF-32LE, в которой полная 4-байтовая последовательность FF FE 00 00 представляет собой один символ, спецификацию.
Последовательность UTF-8, соответствующая U+FEFF, — это 0xEF, 0xBB, 0xBF. Эта последовательность не имеет значения в других формах кодировки Unicode, поэтому она может указывать на то, что этот поток закодирован как UTF-8.
Спецификация Unicode не требует использования знаков порядка байтов в текстовых потоках. Далее говорится, что их не следует использовать в ситуациях, когда уже используется какой-либо другой метод сигнализации формы кодирования.
Математические невидимки [ править ]
Невидимый разделитель (U+2063) в первую очередь предназначен для математики и обеспечивает разделитель между символами, в которых знаки препинания или пробелы могут быть опущены, например, в двумерном индексе, таком как i?j. Невидимые времена (U+2062) и Применение функции (U+2061) полезны в математическом тексте, где умножение терминов или применение функции подразумевается без каких-либо символов, обозначающих операцию. В Unicode 5.1 также вводится символ «Математический невидимый плюс» (U+2064), который может указывать на то, что целое число, за которым следует дробь, должно обозначать их сумму, но не их произведение.
Дробная косая черта [ править ]
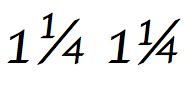

Символ дробной косой черты (U+2044) имеет особое поведение в стандарте Unicode: [6] (раздел 6.2, Другая пунктуация)
Стандартная форма дроби, построенной с использованием косой черты, определяется следующим образом: любая последовательность из одной или нескольких десятичных цифр (общая категория = Nd), за которой следует косая черта, за которой следует любая последовательность из одной или нескольких десятичных цифр. Такая дробь должна отображаться в виде единицы, например ¾ . Если программное обеспечение для отображения неспособно сопоставить дробь с единицей измерения, то ее также можно отобразить в виде простой линейной последовательности в качестве запасного варианта (например, 3/4). Если дробь необходимо отделить от предыдущего числа, то можно использовать пробел, выбрав соответствующую ширину (обычная, тонкая, нулевая ширина и т. д.). Например, 1 + ПРОБЕЛ НУЛЕВОЙ ШИРИНЫ + 3 + ДРОБНАЯ косая черта + 4 отображается как 1¾ .
Следуя этой рекомендации Unicode, системы обработки текста создают сложные символы из простого текста. Здесь наличие символа дробной косой черты указывает механизму компоновки синтезировать дробь из всех последовательных цифр, предшествующих и следующих за косой чертой. На практике результаты различаются из-за сложного взаимодействия между шрифтами и механизмами компоновки. Простые механизмы компоновки текста, как правило, вообще не синтезируют дроби, а вместо этого рисуют глифы в виде линейной последовательности, как описано в резервной схеме Unicode.
Более сложные механизмы компоновки сталкиваются с двумя практическими вариантами: они могут следовать рекомендациям Unicode или полагаться на собственные инструкции шрифта для синтеза дробей. Игнорируя инструкции шрифта, механизм компоновки может гарантировать рекомендуемое Unicode поведение. Следуя инструкциям шрифта, механизм компоновки может улучшить типографику , поскольку размещение и форма цифр будут настроены на этот конкретный шрифт и в этом конкретном размере.
Проблема с следованием инструкциям шрифта заключается в том, что в более простых форматах шрифтов нет возможности указать поведение синтеза дробей. Между тем, более сложные форматы не требуют, чтобы шрифт определял поведение синтеза дробей, и поэтому многие из них этого не делают. Большинство шрифтов сложных форматов могут указать механизму компоновки заменить последовательность простого текста, например 1/2, заранее составленным глифом ½ . Но поскольку многие из них не выдают инструкции по синтезу дробей, простая текстовая строка, такая как 221/225, вполне может отображаться как 22½25 (при этом ½ является замененной предварительно составленной дробью, а не синтезированной). Перед лицом подобных проблем тем, кто хочет полагаться на рекомендуемое поведение Unicode, следует выбирать шрифты, которые, как известно, синтезируют дроби, или программное обеспечение для верстки текста, которое, как известно, обеспечивает рекомендуемое поведение Unicode независимо от шрифта.
Двунаправленное нейтральное форматирование [ править ]
Направление письма — это направление, в котором глифы размещаются на странице относительно продвижения символов в строке Юникода. Английский и другие языки латиницы имеют направление письма слева направо. Некоторые основные сценарии письма, такие как арабский и иврит , имеют направление письма справа налево. Спецификация Unicode присваивает каждому символу тип направления , чтобы информировать текстовые процессоры о том, как следует упорядочивать последовательности символов на странице.
Хотя лексические символы (то есть буквы) обычно относятся к одному письменному алфавиту, некоторые символы и знаки препинания используются во многих письменных сценариях. Unicode мог бы создать в репертуаре повторяющиеся символы, которые различаются только типом направления, но вместо этого решил унифицировать их и присвоить им нейтральный тип направления. Они получают направление во время рендеринга от соседних символов. Некоторые из этих символов также имеют свойство bidi-mirrored , указывающее, что глиф должен отображаться в зеркальном отображении при использовании в тексте с письмом справа налево.
Тип направления нейтрального символа во время рендеринга может оставаться неоднозначным, если метка размещается на границе между изменениями направления. Чтобы решить эту проблему, в Unicode включены символы, которые имеют сильную направленность, не имеют связанных с ними глифов и игнорируются системами, которые не обрабатывают двунаправленный текст:
- Знак арабской буквы (U+061C)
- Метка слева направо (U+200E)
- Метка справа налево (U+200F)
Окружение двунаправленно нейтрального символа меткой слева направо заставит символ вести себя как символ с направлением слева направо, а окружение его меткой справа налево заставит его вести себя как символ с направлением справа налево. характер. Поведение этих символов подробно описано в двунаправленном алгоритме Unicode.
Двунаправленное общее форматирование [ править ]
Хотя Unicode предназначен для обработки нескольких языков, нескольких систем письма и даже текста, который движется либо слева направо, либо справа налево с минимальным вмешательством автора, существуют особые обстоятельства, когда сочетание двунаправленного текста может стать сложным, требующим большего авторский контроль. В этих обстоятельствах Юникод включает пять других символов для управления сложным встраиванием текста с письмом слева направо в текст с письмом справа налево и наоборот:
- Встраивание слева направо (U+202A)
- Встраивание справа налево (U+202B)
- Поп-направленное форматирование (U+202C)
- Переопределение слева направо (U + 202D)
- Переопределение справа налево (U + 202E)
- Изолировать слева направо (U + 2066)
- Изолировать справа налево (U + 2067)
- Первый сильный изолят (U+2068)
- Поп-направленный изолятор (U + 2069)
Символы подстрочных аннотаций [ править ]
- Привязка подстрочной аннотации (U+FFF9)
- Разделитель подстрочных аннотаций (U+FFFA)
- Терминатор подстрочной аннотации (U+FFFB)
Зависит от сценария [ править ]
- Управление префиксным форматом
- Знак арабской цифры (U+0600)
- Арабский знак Сана (U+0601)
- Маркер сноски на арабском языке (U + 0602)
- Арабский знак Сафха (U+0603)
- Арабский знак Самват (U+0604)
- Знак арабской цифры вверху (U+0605)
- Арабский конец аята (U + 06DD)
- Сирийская аббревиатура (U + 070F)
- Марка арабского фунта выше (U + 0890)
- Марка арабского пиастра вверху (U + 0891)
- Цифровой знак Кайти (U + 110BD)
- Знак номера Кайти вверху (U + 110CD)
- Египетские иероглифы
- Вертикальный столяр египетских иероглифов (U + 13430)
- Горизонтальный столяр египетских иероглифов (U + 13431)
- Вставка египетских иероглифов в верхнем начале (U + 13432)
- Вставка египетского иероглифа в начале внизу (U + 13433)
- Вставка египетского иероглифа в верхнем конце (U + 13434)
- Вставка египетского иероглифа в нижней части (U + 13435)
- Наложение египетских иероглифов в середине (U + 13436)
- Начало сегмента египетского иероглифа (U + 13437)
- Конечный сегмент египетского иероглифа (U + 13438)
- Вставка египетского иероглифа посередине (U + 13439)
- Вставка египетского иероглифа вверху (U+1343A)
- Вставка египетских иероглифов внизу (U+1343B)
- Египетский иероглиф в начале приложения (U + 1343C)
- Концевой корпус с египетскими иероглифами (U+1343D)
- Египетский иероглиф. Начало огражденного ограждения (U + 1343E)
- Корпус с торцевыми стенками египетского иероглифа (U+1343F)
- Брахми
- Столяр номеров Брахми (U + 1107F)
- Формирование мертвых символов письма, происходящего от брахми ( Вирама и подобные диакритические знаки)
- Знак Деванагари Вирама (U + 094D)
- Бенгальский знак Вирама (U + 09CD)
- Знак Гурмухи Вирама (U+0A4D)
- Гуджаратский знак Вирама (U+0ACD)
- Ория Знак Вирама (U + 0B4D)
- Тамильский знак Вирама (U+0BCD)
- Телугуский знак Вирама (U + 0C4D)
- Каннада Знак Вирама (U+0CCD)
- Знак малаялам с вертикальной полосой Вирама (U + 0D3B)
- Круглый знак малаялама Вирама (U + 0D3C)
- Малаяламский знак Вирама (U + 0D4D)
- Сингальский знак Аль-Лакуна (U+0DCA)
- Тайский персонаж Пхинту (U + 0E3A)
- Тайский персонаж Ямаккан (U + 0E4E)
- Лаосский знак Пали Вирама (U+0EBA)
- Знак Мьянмы Вирама (U + 1039)
- Тагальский знак Вирама (U + 1714)
- Тагальский знак Памудпод (U + 1715)
- Знак Хануно Памудпод (U + 1734)
- Кхмерский знак Вириам (U + 17D1)
- Кхмерский знак Коенг (U+17D2)
- Тай Там Знак Сакот (U + 1A60)
- Тай Там Син Ра Хаам (U + 1A7A)
- Балийский Адег Адег (U+1B44)
- Суданский знак Памаа (U + 1BAA)
- Суданский знак Вирама (U+1BAB)
- Батак Панголат (U+1BF2)
- Панонгонан Батак (U+1BF3)
- Силоти Нагри Знак Хасанта (U + A806)
- Силоти Нагри подписывает альтернативную Хасанту (U + A82C)
- Знак Саураштры Вирама (U+A8C4)
- Реджанг Вирама (U+A953)
- Яванский пангкон (U+A9C0)
- Встречайте Майека Вираму (U+AAF6)
- Харошти Вирама (U+10A3F)
- Брахми Вирама (U+11046)
- Знак Брахми Старая тамильская Вирама (U + 11070)
- Кайти Знак Вирама (U + 110B9)
- Чакма Вирама (U+11133)
- Знак Шарада Вирама (U+111C0)
- Хойки Знак Вирама (U+11235)
- Худавади Знак Вирама (U + 112EA)
- Грантха Знак Вирама (U + 1134D)
- Новый знак Вирама (U+11442)
- Знак Тирхуты Вирама (U + 114C2)
- Сиддхам Знак Вирама (U + 115BF)
- Моди Знак Вирама (U + 1163F)
- Такри Знак Вирама (U + 116B6)
- Убийца знаков Ахома (U + 1172B)
- Догра Знак Вирама (U + 11839)
- Дайвс Акуру Знак Халанта (U + 1193D)
- Дайвс Акуру Вирама (U+1193E)
- Знак Нандинагари Вирама (U+119E0)
- Знак Вирама на площади Занабазар (U + 11A34)
- Соединитель площади Занабазар (U + 11A47)
- Сойомбо Субъединитель (U + 11A99)
- Бхайксуки Знак Вирама (U + 11C3F)
- Масарам Гонди подписывает Халанту (U + 11D44)
- Масарам Гонди Вирама (U+11D45)
- Гунджала Гонди Вирама (U + 11D97)
- Кави Убийца Знаков (U + 11F41)
- Кави Конджойнер (U+11F42)
- Исторические Вирамы с другими функциями
- Тибетец Марк Халанта (U+0F84)
- Мьянма Знак Асат (U + 103A)
- Лимбу Знак Са-I (U + 193B)
- Знакомьтесь, Майек Апун Айек (U+ABED)
- Чакма Маайя (U+11134)
- Селекторы монгольских вариантов
- Селектор свободных вариантов монгольского языка, один (U + 180B)
- Второй вариант монгольского свободного варианта (U + 180C)
- Третий селектор свободных вариантов монгольского языка (U + 180D)
- Разделитель монгольских гласных (U+180E)
- Общие селекторы вариантов
- Селектор вариантов от 1 до -16 (U+FE00–U+FE0F)
- Селектор вариантов от -17 до -256 (U+E0100–U+E01EF)
- Символы тегов (U+E0001 и U+E0020–U+E007F)
- Тифинаг
- Соединитель согласных Тифинаг (U + 2D7F)
- Огам
- Космическая метка Огама (U + 1680)
- Идеографический
- Индикатор идеографических вариаций (U+303E)
- Идеографическое описание (U+2FF0–U+2FFB)
- Управление музыкальным форматом
- Музыкальный символ «Начало луча» (U + 1D173)
- Концевая балка музыкального символа (U + 1D174)
- Музыкальный символ «Начало галстука» (U + 1D175)
- Конец музыкального символа (U + 1D176)
- Музыкальный символ: Начало оскорбления (U + 1D177)
- Музыкальный символ в конце (U + 1D178)
- Музыкальный символ: начальная фраза (U + 1D179)
- Конечная фраза музыкального символа (U + 1D17A)
- Сокращенное управление форматом
- Перекрытие букв сокращенного формата (U+1BCA0)
- Сокращенный формат с постоянным перекрытием (U+1BCA1)
- Сокращенный формат шага вниз (U+1BCA2)
- Шаг повышения сокращенного формата (U+1BCA3)
- Устаревшее альтернативное форматирование
- Запретить симметричную замену (U+206A)
- Активировать симметричный обмен (U+206B)
- Запретить формирование арабской формы (U+206C)
- Активировать формирование арабской формы (U + 206D)
- Национальные формы цифр (U + 206E)
- Форма номинальных цифр (U+206F)
Другие [ править ]
- Символ замены объекта (U+FFFC)
- Символ замены (U+FFFD)
Символы против кодовых точек [ править ]
Термин «характер» не имеет четкого определения, и большую часть времени мы имеем в виду графему . Графема визуально представлена ее глифом . Используемый шрифт шрифтом (часто ошибочно называемый ) может отображать визуальные вариации одного и того же символа. Вполне возможно, что две разные графемы могут иметь один и тот же глиф или визуально настолько близки, что средний читатель не сможет их отличить.
Графема почти всегда представлена одной кодовой точкой, например, ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A представлена только кодовой точкой U+0041.
Графема ЛАТИНСКАЯ ЗАГЛАВНАЯ A С ДИАРЕЗИСОМ Ä является примером того, как символ может быть представлен более чем одной кодовой точкой. Это может быть U+00C4 или U+0041U+0308. U+0041 — это знакомая буква A, а U+0308 — это ОБЪЕДИНЕННЫЙ ДИАРЕЗИС , объединяющий диакритический знак .
Когда объединяющий знак примыкает к кодовой точке необъединяющего знака, приложения рендеринга текста должны накладывать объединяющий знак на глиф, представленный другой кодовой точкой, чтобы сформировать графему в соответствии с набором правил. [7]
Таким образом, слово BÄM будет состоять из трех графем. Он может состоять из трех или более кодовых точек, в зависимости от того, как на самом деле составлены символы.
Пробелы, соединения и разделители [ править ]
Unicode предоставляет список символов, которые он считает пробелами, для поддержки совместимости. Реализации программного обеспечения и другие стандарты могут использовать этот термин для обозначения немного другого набора символов. Например, Java не учитывает U+00A0 ПРОСТРАНСТВО БЕЗ РАЗРЫВА или U+0085 <control-0085> (СЛЕДУЮЩАЯ СТРОКА) будет пробелом, хотя Unicode это делает. Пробельные символы — это символы, обычно предназначенные для сред программирования. Часто они не имеют синтаксического значения в таких средах программирования и игнорируются машинными интерпретаторами. Юникод обозначает устаревшие управляющие символы от U+0009 до U+000D и U+0085 как символы пробела, а также все символы, значением свойства «Общая категория» которых является «Разделитель». Всего в Unicode 15.1 имеется 25 пробельных символов.
Соединяющие и не соединяющие графемы [ править ]
Соединитель нулевой ширины (U+200D) и необъединитель нулевой ширины (U+200C) управляют объединением и лигированием глифов. Соединитель не заставляет символы, которые в противном случае не могли бы соединяться или сшиваться, делать это, но в сочетании с несоединяющим элементом эти символы можно использовать для управления свойствами соединения и лигирования окружающих двух соединяющихся или лигирующих символов. Объединение объединенных графем (U+034F) используется для различения двух базовых символов как одной общей основы или орграфа, в основном для базовой обработки текста, сопоставления строк, свертывания регистра и т. д.
Соединители и разделители слов [ править ]
Самый распространенный разделитель слов — пробел (U+0020). Однако существуют и другие средства объединения слов и разделители, которые также указывают разрыв между словами и участвуют в алгоритмах разрыва строк. Пробел без разрыва (U+00A0) также обеспечивает перемещение по базовой линии без глифа, но запрещает, а не разрешает разрыв строки. Пробел нулевой ширины (U+200B) допускает разрыв строки, но не оставляет пробела: в некотором смысле объединяет, а не разделяет два слова. Наконец, Word Joiner (U+2060) блокирует разрывы строк, а также не включает пробелы, образующиеся при перемещении базовой линии.
| Базовый прогресс | Без базового прогресса | |
|---|---|---|
| Разрешить перенос строки (Сепараторы) | Космос U+0020 | Пространство нулевой ширины U+200B |
| Запретить перенос строки (столяры) | Неразрывный пробел U+00A0 | Столяр слов U + 2060 |
Другие разделители [ править ]
- Разделитель строк (U+2028)
- Разделитель абзацев (U+2029)
Они предоставляют Unicode собственные разделители абзацев и строк, независимые от устаревших управляющих символов ASCII, таких как возврат каретки (U+000A), перевод строки (U+000D) и следующая строка (U+0085). Unicode не предусматривает других управляющих символов форматирования ASCII, которые, по-видимому, не являются частью модели обработки простого текста Unicode. К этим устаревшим символам управления форматированием относятся табуляция (U+0009), строковая табуляция или вертикальная табуляция (U+000B) и перевод страницы (U+000C), который также считается разрывом страницы.
Пространства [ править ]
Символ пробела (U+0020), который обычно вводится с помощью клавиши пробела на клавиатуре, семантически служит разделителем слов во многих языках. По причинам, связанным с наследием, ПСК также включает пробелы разных размеров, которые являются эквивалентами совместимости для символа пробела. Хотя эти пространства различной ширины важны в типографике, модель обработки Unicode требует, чтобы такие визуальные эффекты обрабатывались с помощью форматированного текста, разметки и других подобных протоколов. Они включены в репертуар Unicode в первую очередь для обработки двустороннего транскодирования без потерь из других кодировок набора символов. Эти помещения включают в себя:
- И четверка (U+2000)
- Эм Квад (U + 2001)
- В космосе (U + 2002)
- Эм Пространство (U + 2003)
- Пространство «три пера» (U + 2004)
- Пространство четырех пер-эм (U + 2005)
- Пространство Six-Per-Em (U + 2006)
- Фигурное пространство (U + 2007)
- Пунктуационный пробел (U+2008)
- Тонкое пространство (U + 2009)
- Пространство для волос (U + 200A)
- Среднее математическое пространство (U+205F)
За исключением исходного пробела ASCII, все остальные пробелы являются символами совместимости. В данном контексте это означает, что они фактически не добавляют к тексту семантического содержания, а вместо этого обеспечивают контроль над стилем. В Unicode этот несемантический элемент управления стилем часто называют форматированным текстом и выходит за рамки целей Unicode. Вместо использования разных пространств в разных контекстах этот стиль следует обрабатывать с помощью интеллектуального программного обеспечения для верстки текста.
Три других разделителя слов, специфичных для системы письма:
- Разделитель монгольских гласных (U+180E)
- Идеографическое пространство (U+3000): действует как идеографический разделитель и обычно отображается как пробел той же ширины, что и иероглиф.
- Знак пробела Огама (U + 1680): этот символ иногда отображается с глифом, а иногда - только с пробелом.
Управляющие символы разрыва строки [ править ]
Некоторые символы созданы для того, чтобы помочь контролировать разрывы строк, либо препятствуя их использованию (символы без разрывов), либо предлагая разрывы строк, например мягкий дефис (U+00AD) (иногда называемый «застенчивым дефисом»). Такие символы, хотя и предназначены для стилизации, вероятно, незаменимы для сложных типов переноса строк, которые они делают возможными.
- Запрет на разрыв
- Неразрывный дефис (U+2011)
- Неразрывный пробел (U+00A0)
- Тибетский разделитель знака Tsheg Bstar (U+0F0C)
- Узкое сплошное пространство (U+202F)
Символы, запрещающие разрыв, должны быть эквивалентны последовательности символов, заключенной в Word Joiner U+2060. Однако Word Joiner может быть добавлен до или после любого символа, который позволяет разрыву строки запретить такой разрыв строки.
- Включение перерыва
- Мягкий дефис (U+00AD)
- Межсложный тибетский знак (U+0F0B)
- Пространство нулевой ширины (U+200B)
Как символы, запрещающие разрыв, так и символы, разрешающие разрыв, взаимодействуют с другими символами пунктуации и пробелов, позволяя системам обработки текста определять разрывы строк в рамках алгоритма разрыва строк Unicode. [8]
Типы кодовых точек [ править ]
Все кодовые точки, имеющие какое-либо назначение или использование, считаются обозначенными кодовыми точками. Из них им могут быть присвоены абстрактные символы или иным образом назначены для какой-либо другой цели.
Назначенные персонажи [ править ]
Большинство кодовых точек при фактическом использовании присвоены абстрактным символам. Сюда входят символы частного использования, которые, хотя формально и не обозначены стандартом Unicode для конкретной цели, требуют, чтобы отправитель и получатель заранее договорились о том, как их следует интерпретировать для значимого обмена информацией осуществления .
Персонажи частного использования [ править ]
UCS включает 137 468 символов частного использования, которые представляют собой кодовые точки для частного использования, распределенные по трем различным блокам, каждый из которых называется областью частного использования (PUA). Стандарт Unicode распознает кодовые точки внутри PUA как допустимые коды символов Unicode, но не присваивает им никаких (абстрактных) символов. Вместо этого отдельные лица, организации, поставщики программного обеспечения, поставщики операционных систем, поставщики шрифтов и сообщества конечных пользователей могут свободно использовать их по своему усмотрению. В закрытых системах символы PUA могут работать однозначно, что позволяет таким системам представлять символы или глифы, не определенные в Unicode. [9] В общедоступных системах их использование более проблематично, поскольку нет реестра и нет возможности помешать нескольким организациям использовать одни и те же кодовые элементы для разных целей. Одним из примеров такого конфликта является Apple использование U+F8FF для логотипа Apple , в то время как реестр Unicode ConScript использует U+F8FF в качестве Клингонский символ мумификации клингонским письмом . [10]
Базовая многоязычная плоскость (Плоскость 0) содержит 6400 символов частного пользователя в одноименной области частного использования PUA , которая находится в диапазоне от U+E000 до U+F8FF. Самолеты частного использования , Plane 15 и Plane 16, каждый имеют свои собственные PUA из 65 534 символов частного использования (при этом последние две кодовые точки каждого самолета не являются символами). Это дополнительная зона частного использования-A , которая находится в диапазоне от U+F0000 до U+FFFFD, и дополнительная зона частного использования-B , которая находится в диапазоне от U+100000 до U+10FFFD.
PUA — это концепция, унаследованная от некоторых азиатских систем кодирования. В этих системах были области частного использования для кодирования того, что японцы называют гайдзи (редкие символы, обычно не встречающиеся в шрифтах), способами, специфичными для конкретного приложения.
Суррогаты [ править ]
UCS использует суррогаты для обращения к символам за пределами исходной базовой многоязычной плоскости, не прибегая к представлениям слов длиной более 16 бит. [11] Существует 1024 «высоких» суррогата (D800–DBFF) и 1024 «низких» суррогата (DC00–DFFF). Комбинируя пару суррогатов, можно адресовать оставшиеся символы во всех остальных плоскостях (1024 × 1024 = 1048576 кодовых точек в остальных 16 плоскостях). В UTF-16 они всегда должны появляться парами: старший суррогат, за которым следует младший суррогат, таким образом, для обозначения одной кодовой точки используются 32 бита.
Суррогатная пара обозначает кодовую точку
- 10000 16 + ( H - D800 16 ) × 400 16 + ( L - DC00 16 )
где H и L — числовые значения старшего и младшего суррогатов соответственно. [12]
Поскольку высокие суррогатные значения в диапазоне DB80–DBFF всегда создают значения в плоскостях частного использования, верхний суррогатный диапазон можно далее разделить на (нормальные) высокие суррогатные значения (D800–DB7F) и «суррогатные с высоким уровнем частного использования» (DB80–DBFF). .
Изолированные суррогатные кодовые точки не имеют общей интерпретации; следовательно, для этого диапазона не предоставляются таблицы кодов символов или списки имен. В языке программирования Python отдельные суррогатные коды используются для встраивания недекодируемых байтов в строки Юникода. [13]
Неперсонажи [ править ]
Термин «бессимвольный» без дефиса относится к 66 кодовым точкам (обозначенным <not a character>) постоянно зарезервирован для внутреннего использования и, следовательно, гарантированно никогда не будет назначен персонажу. [14] Каждая из 17 плоскостей имеет две конечные кодовые точки, отведенные как несимволы. Таким образом, несимволами являются: U+FFFE и U+FFFF на BMP, U+1FFFE и U+1FFFF на плоскости 1 и так далее, вплоть до U+10FFFE и U+10FFFF на плоскости 16, всего 34 кода. точки. Кроме того, в BMP имеется непрерывный диапазон из еще 32 несимвольных кодовых точек: U+FDD0..U+FDEF. Реализации программного обеспечения могут свободно использовать эти кодовые точки для внутреннего использования. Одним из особенно полезных примеров несимвольного символа является кодовая точка U+FFFE. Эта кодовая точка имеет обратную последовательность байтов UTF-16/UCS-2 метки порядка байтов (U+FEFF). Если поток текста содержит этот несимвол, это хороший признак того, что текст был интерпретирован с неправильным порядком байтов .
Версии стандарта Unicode с 3.1.0 по 6.3.0 утверждали, что несимволы «никогда не следует менять местами». В исправлении № 9 стандарта позже говорилось, что это привело к «неуместному чрезмерному отклонению», поясняя, что «[Несимволы] не являются незаконными при обмене и не вызывают неправильного формата текста в Юникоде», и удаляя исходное утверждение.
Зарезервированные кодовые точки [ править ]
Все остальные кодовые точки, если они не обозначены, называются зарезервированными. Эти кодовые точки могут быть назначены для конкретного использования в будущих версиях стандарта Unicode.
Символы, группы графем и глифы [ править ]
В то время как многие другие наборы символов назначают символ для каждого возможного глифового представления символа, Unicode стремится обрабатывать символы отдельно от глифов. Это различие не всегда однозначно; однако несколько примеров помогут проиллюстрировать это различие. Часто два символа могут быть объединены типографски, чтобы улучшить читаемость текста. Например, трехбуквенную последовательность «ffi» можно рассматривать как один глиф. Другие наборы символов часто присваивают этому глифу кодовую точку в дополнение к отдельным буквам: «f» и «i».
Кроме того, в Юникоде модифицированные диакритические буквы рассматриваются как отдельные символы, которые при отображении становятся одним глифом. Например, «о» с диарезисом : « ö ». Традиционно другим наборам символов присваивался уникальный код символа для каждой измененной диакритической буквы, используемой в каждом языке. Unicode стремится создать более гибкий подход, позволяя комбинировать диакритические символы с любой буквой. Это потенциально может значительно сократить количество активных кодовых точек, необходимых для набора символов. В качестве примера рассмотрим язык, в котором используется латиница и сочетаются диэрезис с прописными и строчными буквами «а», «о» и «у». При использовании подхода Unicode к набору символов для использования с латинскими буквами необходимо добавить только диакритический символ диарезиса: «a», «A», «o», «O», «u» и «U»: всего семь персонажей. В устаревшие наборы символов необходимо добавить шесть заранее составленных букв с диарезисом в дополнение к шести кодовым точкам, которые он использует для букв без диарезиса: всего двенадцать кодовых точек символов.
Совместимость символов [ править ]
UCS включает тысячи символов, которые Unicode обозначает как символы совместимости. Это символы, которые были включены в UCS, чтобы обеспечить отдельные кодовые точки для символов, которые различаются другими наборами символов, но не будут различаться в подходе Unicode к символам.
Основная причина такого различия заключалась в том, что Unicode проводит различие между символами и глифами. Например, при написании английского курсивом буква «i» может принимать разные формы, независимо от того, появляется ли она в начале слова, в конце слова, в середине слова или изолированно. Такие языки, как арабский , написанные арабской вязью, всегда написаны курсивом. Каждая буква имеет множество различных форм. UCS включает 730 символов арабской формы, которые распадаются всего на 88 уникальных арабских символов. Однако эти дополнительные арабские символы включены для того, чтобы программное обеспечение для обработки текста могло переводить текст из других наборов символов в UCS и обратно без какой-либо потери информации, важной для программного обеспечения, не поддерживающего Юникод.
Однако, в частности, для UCS и Unicode предпочтительным подходом является всегда кодировать или сопоставлять эту букву с одним и тем же символом, независимо от того, где она встречается в слове. Затем различные формы каждой буквы определяются методами программного обеспечения для шрифта и компоновки текста. Таким образом, внутренняя память для символов остается одинаковой независимо от того, где символ появляется в слове. Это значительно упрощает поиск, сортировку и другие операции по обработке текста.
Свойства персонажа [ править ]
Каждый символ в Юникоде определяется большим и постоянно растущим набором свойств. Большинство этих свойств не являются частью универсального набора символов. Свойства облегчают обработку текста, включая сопоставление или сортировку текста, идентификацию слов, предложений и графем, рендеринг или отображение текста и т. д. Ниже приведен список некоторых основных свойств. В базе данных символов Юникода задокументировано множество других символов. [15]
| Свойство | Пример | Подробности |
|---|---|---|
| Имя | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А | Это постоянное имя, присвоенное в результате совместного сотрудничества Unicode и ISO UCS. Несколько известных, неудачно выбранных названий существуют и признаны (например, ФОРМА ПРЕДСТАВЛЕНИЯ U+FE18 ДЛЯ ВЕРТИКАЛЬНОЙ ПРАВОЙ БЕЛОЙ ЛЕНТИКУЛЯРНОЙ СКОБКИ, которая написана с ошибкой – должна быть СКОБКА), но не будут изменены, чтобы обеспечить стабильность спецификации. [16] |
| Кодовая точка | U + 0041 | Кодовая точка Юникода — это номер, который также постоянно назначается вместе со свойством «Имя» и включается в сопутствующую UCS. Обычно кодовую точку представляют в виде шестнадцатеричного числа с префиксом «U+» впереди. |
| Представитель Глиф | Репрезентативные глифы представлены в таблицах кодов. [18] | |
| Общая категория | Прописная буква | Общая категория [19] выражается в виде двухбуквенной последовательности, например «Lu» для заглавных букв или «Nd» для десятичных цифр. |
| Объединение классов | Не_переупорядочено (0) | Поскольку диакритические знаки и другие знаки объединения могут быть выражены с помощью нескольких символов в Юникоде, свойство «Класс объединения» позволяет различать символы по типу объединяемого символа, который он представляет. Комбинирующий класс может быть выражен целым числом от 0 до 255 или именованным значением. Целочисленные значения позволяют переупорядочить метки объединения в канонический порядок, чтобы сделать возможным сравнение идентичных строк. |
| Двунаправленная категория | Влево_Вправо | Указывает тип символа для применения двунаправленного алгоритма Юникода. |
| Двунаправленный зеркальный | нет | Указывает, что глиф персонажа должен быть перевернут или зеркально отображен в рамках двунаправленного алгоритма. Зеркальные глифы могут быть предоставлены создателями шрифтов, извлечены из других символов, связанных с помощью свойства «Двунаправленный зеркальный глиф», или синтезированы системой рендеринга текста. |
| Глиф двунаправленного зеркалирования | Н/Д | Это свойство указывает кодовую точку другого символа, глиф которого может служить зеркальным глифом для текущего символа при зеркальном отображении в рамках двунаправленного алгоритма. |
| Десятичное числовое значение | НЭН | Для цифр это свойство указывает числовое значение символа. Для десятичных цифр всем трем значениям присвоено одно и то же значение, для символов совместимости с форматированным текстом и других арабско-индийских недесятичных цифр обычно только два последних свойства имеют числовое значение символа, в то время как цифры, не связанные с арабскими индийскими цифрами, такие как Римские цифры или цифры Ханьчжоу/Сучжоу обычно имеют только указанное «числовое значение». |
| Цифровое значение | НЭН | |
| Числовое значение | НЭН | |
| Идеографический | ЛОЖЬ | Указывает, что символ является иероглифом CJK : логотипом письма Хань . [20] |
| По умолчанию игнорируется | ЛОЖЬ | Указывает, что символ игнорируется для реализаций и что глиф, глиф последней инстанции или символ замены не требуется отображать. |
| Устарело | ЛОЖЬ | Unicode никогда не удаляет символы из репертуара, но иногда Unicode объявляет устаревшим небольшое количество символов. |
Unicode предоставляет онлайн-базу данных [21] для интерактивного запроса всего набора символов Юникода по различным свойствам.
См. также [ править ]
Ссылки [ править ]
- ^ «Стандарт Юникод» . Консорциум Юникод . Проверено 9 августа 2016 г.
- ^ «Дорожные карты для Unicode» . Консорциум Юникод . Проверено 15 сентября 2021 г.
- ^ «Часто задаваемые вопросы — персонажи, неперсонажи и стражи для частного использования» . www.unicode.org . Проверено 24 октября 2023 г.
- ^ «Раздел 2.13: Специальные символы» (PDF) . Стандарт Юникод . Консорциум Юникод. Сентябрь 2022.
- ^ «Раздел 4.12: Персонажи с необычными свойствами» (PDF) . Стандарт Юникод . Консорциум Юникод. Сентябрь 2022.
- ^ «Раздел 6.2: Общая пунктуация» (PDF) . Стандарт Юникод . Консорциум Юникод. Сентябрь 2022.
- ^ «UTN № 2: Общий метод отображения комбинированных знаков» . www.unicode.org . Проверено 16 декабря 2020 г.
- ^ «UAX # 14: Алгоритм разрыва строки в Юникоде» . Консорциум Юникод. 01.06.2016 . Проверено 9 августа 2016 г.
- ^ «Раздел 23.5: Символы частного использования» (PDF) . Стандарт Юникод . Консорциум Юникод. Сентябрь 2022.
- ^ Майкл Эверсон (15 января 2004 г.). «Клингонский: U+F8D0 — U+F8FF» .
- ^ «Раздел 23.6: Зона суррогатов» (PDF) . Стандарт Юникод . Консорциум Юникод. Сентябрь 2022.
- ^ Каплан, Майкл. «Суррогатная поддержка в продуктах Microsoft» .
- ^ против Лёвиса, Мартина (22 апреля 2009 г.). «Недекодируемые байты в интерфейсах системных символов» . Предложения по улучшению Python . ПЭП 383 . Проверено 9 августа 2016 г.
- ^ «Раздел 23.7: Несимволы» (PDF) . Стандарт Юникод . Консорциум Юникод. Сентябрь 2022.
- ^ «База данных символов Юникода» . Консорциум Юникод . Проверено 9 августа 2016 г.
- ^ Фрейтаг, Асмус; Макгоуэн, Рик; Уистлер, Кен. «Техническое примечание Unicode № 27 — Известные аномалии в именах символов Unicode» . Консорциум Юникод.
- ^ Не официальный представительный глиф Unicode, а просто репрезентативный глиф. Чтобы увидеть официальный представитель Unicode, см. таблицы кодов .
- ^ «Таблицы кодов символов» . Консорциум Юникод . Проверено 9 августа 2016 г.
- ^ «UAX № 44: База данных символов Юникода» . Общие значения категорий . Консорциум Юникод. 05.06.2014 . Проверено 9 августа 2016 г.
- ^ Дэвис, Марк; Янку, Лаурентиу; Уистлер, Кен. «Таблица 9. Таблица свойств § PropList.txt» . Приложение № 44 к стандарту Юникода — База данных символов Юникода . Консорциум Юникод.
- ^ «Утилиты Unicode: Индекс свойств символов» . Консорциум Юникод . Проверено 9 июня 2015 г.
Внешние ссылки [ править ]
- Консорциум Юникод
- decodeunicode.org Unicode Wiki со всеми 98884 графическими символами Unicode 5.0 в формате gif, полнотекстовый поиск
- Символы Юникода по свойствам