Limbu script
| Limbu ᤕᤰᤌᤢᤱ ᤐᤠᤴ | |
|---|---|
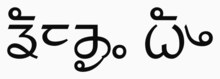 | |
| Script type | |
Time period | c. 1740–present |
| Direction | Left-to-right |
| Region | Nepal and Northeastern India |
| Languages | Limbu |
| Related scripts | |
Parent systems | |
| ISO 15924 | |
| ISO 15924 | Limb (336), Limbu |
| Unicode | |
Unicode alias | Limbu |
| U+1900–U+194F | |
[a] The Semitic origin of the Brahmic scripts is not universally agreed upon. | |
| Brahmic scripts |
|---|
| The Brahmi script and its descendants |
The Limbu script (also Sirijanga script)[1] is used to write the Limbu language. It is a Brahmic type abugida.[2]
History[edit]
According to traditional histories, the Limbu script was first invented in the late 9th century by Limbu King Sirijunga Hang and then fell out of use, only to be reintroduced in the 18th century by Limbu scholar Te-ongsi Sirijunga Xin Thebe as during that time the teaching of the Limbu script was outlawed in Limbuwan and Sikkim.
Accounts with Sirijunga[edit]
The Limbu language is one of the few Sino-Tibetan languages of the Central Himalayas to possess their own scripts.[3][4] tells us that the Limbu or Sirijunga script was devised during the period of Buddhist expansion in Sikkim in the early 18th century when Limbuwan still constituted part of Sikkimese territory. The Limbu script was probably composed at roughly the same time as the Lepcha script which was created by the third King of Sikkim, Chakdor Namgyal (ca. 1700–1717). The Limbu script is ascribed to the Limbu hero, Te-ongsi Sirijunga Xin Thebe.
Structure[edit]
The Limbu script is an abugida, which means that a basic letter represents both a consonant and an inherent, or default, vowel. In Limbu, the inherent vowel is /ɔ/, as in Bengali–Assamese and Odia scripts. To start a syllable with a vowel, the appropriate vowel diacritic is added to the vowel-carrierᤀ. A vowel-carrier with no diacritic represents the sound /ɔ/.
ᤁ ko IPA: /kɔ/ | ᤂ kho IPA: /kʰɔ/ | ᤃ go IPA: /ɡɔ/ | ᤄ gho IPA: /ɡʱɔ/ | ᤅ ngo IPA: /ŋɔ/ | ᤆ co IPA: /t͡ɕɔ/ | ᤇ cho IPA: /t͡ɕʰɔ/ | ᤈ jo IPA: /d͡ʑɔ/ | ᤉ jho IPA: /d͡ʑʱɔ/ | ᤊ nyo IPA: /ɲɔ/ |
ᤋ to IPA: /tɔ/ | ᤌ tho IPA: /tʰɔ/ | ᤍ do IPA: /dɔ/ | ᤎ dho IPA: /dʱɔ/ | ᤏ no IPA: /nɔ/ | ᤐ po IPA: /pɔ/ | ᤑ pho IPA: /pʰɔ/ | ᤒ bo IPA: /bɔ/ | ᤓ bho IPA: /bʱɔ/ | ᤔ mo IPA: /mɔ/ |
ᤕ yo IPA: /jɔ/ | ᤖ ro IPA: /rɔ/ | ᤗ lo IPA: /lɔ/ | ᤘ\ wo IPA: /wɔ/ | ᤙ sho IPA: /ʃɔ/ | ᤚ sso IPA: /ʂɔ/ | ᤛ so IPA: /sɔ/ | ᤜ ho IPA: /ɦɔ/ |
- ^ Jump up to: Jump up to: a b c The letters ᤊ, ᤚ and ᤉ are not used in modern Limbu.
ᤠ a IPA: /a/ | ᤡ i IPA: /i/ | ᤢ u IPA: /u/ | ᤣ ee IPA: /e/ | ᤤ ai IPA: /ai/ | ᤥ oo IPA: /o/ | ᤦ au IPA: /au/ | ᤧ e IPA: /ɛ/ | ᤨ o IPA: /ɔ/ |
z + ᤠ ᤁᤠ IPA: /ka/ | z + ᤡ ᤁᤡ IPA: /ki/ | z + ᤢ ᤁᤢ IPA: /ku/ | z + ᤣ ᤁᤣ IPA: /ke/ | z + ᤤ ᤁᤤ IPA: /kai/ | z + ᤥ ᤁᤥ IPA: /ko/ | z + ᤦ ᤁᤦ IPA: /kau/ | z + ᤧ ᤁᤧ IPA: /kɛ/ | z + ᤨ ᤁᤨ IPA: /kɔ/ |
- ^ Jump up to: Jump up to: a b The diacritic ᤨ represents the vowel /ɔ/, which is the same as a consonant's inherent /ɔ/ vowel. So, ᤁᤨ and ᤁ represent the same syllable, /kɔ/.Some writers avoid this diacritic entirely, considering it redundant.
Initial consonant clusters are written with small marks following the main consonant:
ᤩ y IPA: /j/ | ᤪ r IPA: /r/ | ᤫ w IPA: /w/ |
ᤁ + ᤩ ᤁᤩ IPA: /kjɔ/ | ᤁ + ᤪ ᤁᤪ IPA: /krɔ/ | ᤁ + ᤫ ᤁᤫ IPA: /kwɔ/ |
Final consonants after short vowels are written with another set of marks, except for some final consonants occurring only in loanwords. They follow the marks for consonant clusters, if any.
ᤰ -k IPA: /k/ | ᤱ -ng IPA: /ŋ/ | ᤳ -t IPA: /t/ | ᤴ -n IPA: /n/ | ᤵ -p IPA: /p/ | ᤶ -m IPA: /m/ | ᤷ -r IPA: /r/ | ᤸ -l IPA: /l/ |
ᤁᤰ IPA: /kɔk/ | ᤁᤱ IPA: /kɔŋ/ | ᤁᤳ IPA: /kɔt/ | ᤁᤴ IPA: /kɔn/ | ᤁᤵ IPA: /kɔp/ | ᤁᤶ IPA: /kɔm/ | ᤁᤷ IPA: /kɔr/ | ᤁᤸ IPA: /kɔl/ |
Long vowels without a following final consonant are written with a diacritic called kemphreng ⟨᤺⟩, for example, ⟨ᤁ᤺⟩, /kɔː/.
There are two methods for writing long vowels with syllable-final consonants:
- With a kemphreng diacritic and the final consonant, such as ⟨ᤁ᤺ᤰ⟩, /kɔːk/.
- By replacing the final consonant with the corresponding full consonant and adding an underscore-like diacritic mark ⟨᤻⟩. This indicates that the consonant has no following vowel and that the preceding vowel is lengthened, example, ⟨ᤁᤁ᤻⟩, /kɔːk/. The same diacritic may be used to mark final consonants in loanwords that do not have final forms in Limbu, regardless of the length of the vowel.
The first method is widely used in Sikkim; the second method is advocated by certain writers in Nepal.[2]
Glottalization is marked by a sign called mukphreng ⟨᤹ ⟩, for example, ⟨ᤁ᤹ ⟩, /kɔʔ/.
Sample text[edit]
ᤛᤧᤘᤠᤖᤥ᥄ ᤀᤠᤍᤠᤱᤒᤠ ᤜᤠᤍᤠᤱᤔᤠᤛᤣ ᤗᤠᤶᤎᤡᤱᤃᤥ ᤗᤠᤶᤎᤰ ᤕᤠᤰᤌᤢᤱᤐᤠᤴ ᤖᤧ ᤘᤡᤁᤡᤐᤡᤍᤡᤕᤠ ᤀᤥ ॥ᤛᤧᤘᤠᤖᤥ᥄ ᤀᤠᤍᤠᤏᤠᤒᤠ ᤀᤠᤍᤠᤏᤠᤔ ᤀᤠᤛᤧ ᤗᤠᤶᤎ ᤀᤡᤏᤠᤃ ᤗᤠᤶᤎᤠᤁᤠ ᤕᤠᤰᤌᤢᤱ ᤐᤠᤏᤠ ᤖᤧ ᤘᤡᤁᤡᤐᤧᤍᤤ ᤀ।ᤗᤡᤶᤒᤢ ᤓᤠᤙᤠᤁᤥ ᤘᤡᤁᤡᤐᤡ᤺ᤍᤡᤕᤠᤔᤠ ᤛᤫᤠᤃᤋ ᤇ।ᤗᤡᤶᤒᤢ ᤓᤠᤛᤠᤁᤨ ᤘᤡᤁᤡᤐᤡᤍᤡᤕᤠ ᤀᤜᤡᤗᤧ ᤀᤡᤴᤁᤢᤒᤧᤛᤠᤏᤠ (ᤐᤠᤖᤣᤰᤙᤠᤏ ᤘᤡᤁᤡ) ᤀᤷᤌᤠᤳ ᤁᤨᤁᤨᤔᤠ ᤇᤠ।ᤕᤛᤗᤠᤀᤡ᤺ ᤀᤃᤠᤍᤡ ᤒᤎᤠᤀᤢᤏᤠᤁᤠ ᤗᤠᤃᤡ ᤁᤠᤶᤋᤡᤔᤠ ᥈ ᤛᤠᤕᤠ ᤗᤧᤰ ᤗᤡᤶᤒᤢ ᤓᤠᤙᤠᤔᤠ ᤜᤢᤏᤠ ᤈᤠᤖᤥᤖᤣ ᤇᤠ। ᤋᤩᤛᤁᤠᤖᤏ ᤗᤡᤶᤒᤢ ᤓᤠᤙᤠᤔᤠ ᤗᤧᤂᤠᤜᤠᤖᤢ ᤗᤧᤰᤏᤠ ᤛᤢᤖᤢᤃᤠᤷᤏᤠ ᤛᤠᤒᤤ ᤗᤡᤶᤒᤢᤓᤠᤙᤡ ᤔᤡᤳᤖᤜᤠᤖᤢᤔᤠ ᤜᤠᤷᤍᤡᤰ ᤀᤠᤏᤢᤖᤨᤎ ᤇᤠ।
Obsolete characters[edit]
Three additional letters were used in early versions of the modern script:[2]
- ᤉ /d͡ʑʱɔ/
- ᤊ /ɲɔ/
- ᤚ /ʂɔ/
Two ligatures were used for Nepali consonant conjuncts:[5]
- ᤝ jña (for Devanagari ज्ञ)
- ᤞ tra (for Devanagari त्र)
Nineteenth-century texts used a small anusvara (ᤲ) to mark nasalization. This was used interchangeably with ᤱ /ŋ/.
The sign ᥀ was used for the exclamatory particle ᤗᤥ (/lo/).[2]
Punctuation[edit]
The main punctuation mark used in Limbu is the Devanagari double danda (॥).[2] It has its own exclamation mark (᥄) and question mark (᥅).
Digits[edit]
0 ᥆ | 1 ᥇ | 2 ᥈ | 3 ᥉ | 4 ᥊ | 5 ᥋ | 6 ᥌ | 7 ᥍ | 8 ᥎ | 9 ᥏ |
Unicode[edit]
Limbu script was added to the Unicode Standard in April, 2003 with the release of version 4.0.
The Unicode block for Limbu is U+1900–U+194F:
| Limbu[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+190x | ᤀ | ᤁ | ᤂ | ᤃ | ᤄ | ᤅ | ᤆ | ᤇ | ᤈ | ᤉ | ᤊ | ᤋ | ᤌ | ᤍ | ᤎ | ᤏ |
| U+191x | ᤐ | ᤑ | ᤒ | ᤓ | ᤔ | ᤕ | ᤖ | ᤗ | ᤘ | ᤙ | ᤚ | ᤛ | ᤜ | ᤝ | ᤞ | |
| U+192x | ᤠ | ᤡ | ᤢ | ᤣ | ᤤ | ᤥ | ᤦ | ᤧ | ᤨ | ᤩ | ᤪ | ᤫ | ||||
| U+193x | ᤰ | ᤱ | ᤲ | ᤳ | ᤴ | ᤵ | ᤶ | ᤷ | ᤸ | ᤹ | ᤺ | ᤻ | ||||
| U+194x | ᥀ | ᥄ | ᥅ | ᥆ | ᥇ | ᥈ | ᥉ | ᥊ | ᥋ | ᥌ | ᥍ | ᥎ | ᥏ | |||
| Notes | ||||||||||||||||
References[edit]
- ^ "ScriptSource: Limbu". Retrieved 20 July 2020.
- ^ Jump up to: Jump up to: a b c d e Michailovsky, Boyd; Everson, Michael (2002-02-05). "L2/02-055: Revised proposal to encode the Limbu script in the UCS" (PDF).
- ^ Sprigg, R. K. (1959). "Limbu books in the Kiranti Script". Akten des vierundzwanzigsten Internationalen Orientalisten-Kongresses München 28. Deutsche Morgenländische Gesellschaft, in Kommission bei Franz Steiner Verlag. pp. 590–592.
- ^ Sprigg, R. K. (1998). Original and sophisticated features of the Lepcha and Limbu scripts. pp. 1–18.
- ^ Pandey, Anshuman (2011-01-14). "L2/11-008: Proposal to Encode the Letters GYAN and TRA for Limbu in the UCS" (PDF).