Универсальные символы символов

Консорциум Unicode и ISO/IEC JTC 1/SC 2 / WG 2 совместно сотрудничают в списке символов в универсальном наборе символов . Универсальный кодированный набор символов, чаще всего называемый универсальным набором символов ( ABBR. UCS, Официальное обозначение: ISO / IEC 10646), является международным стандартом карты символов , дискретные символы, используемые на естественном языке , математике , музыке и других доменах, к уникальным машиночитаемым значениям данных. Создавая это отображение, UCS позволяет поставщикам компьютерного программного обеспечения взаимодействовать обмен и передавать- - UCS -кодируемые текстовые строки от одного к другому. Поскольку это универсальная карта, ее можно использовать для представления нескольких языков одновременно. Это позволяет избежать путаницы с использованием нескольких кодировки унаследованных символов , что может привести к одной и той же последовательности кодов, имеющих несколько интерпретаций, в зависимости от кодирования символов, что приводит к моджибаке , если выбран неправильный.
UCS имеет потенциальную мощность более 1 миллиона символов. Каждый символ UCS абстрактно представлен кодовой точкой , целое число между 0 и 1114,111 (1114,112 = 2 20 + 2 16 или 17 × 2 16 = 0x 110000 кодовые точки ), используемые для представления каждого символа в внутренней логике программного обеспечения для обработки текстовой обработки . По состоянию на Unicode 16.0, выпущенная в сентябре 2024 года, было выделено 299 056 (27%) из этих кодовых точек, 155 063 (14%) были назначены символы, 137 468 (12%) зарезервированы для частного использования , для получения механизма используются 2048. суррогатов . и 66 обозначены как нехарактерные лица , оставляя оставшиеся 815 056 (73%) Количество закодированных символов состоит следующим образом:
- 149,641 графические символы (некоторые из которых не имеют видимого глифа , но все еще считаются графическими)
- 237 Специальные символы для контроля и форматирования .
ISO поддерживает базовое отображение символов от имени символа в код точку. Часто термины символа и кодовая точка будут использоваться взаимозаменяемо. Однако, когда проводится различие, кодовая точка относится к целому числу персонажа: что можно подумать как его адрес. Между тем, символ в ISO/IEC 10646 включает в себя комбинацию кодовой точки и его имени, Unicode добавляет многие другие полезные свойства в набор символов, такие как блок , категория, сценарий и направление .
В дополнение к UCS, дополнительный стандарт Unicode , (не совместный проект с ISO, а скорее публикация консорциума Unicode) предоставляет другие детали реализации, такие как:
- Опоры между UC и другими наборами символов
- Различные коллекции персонажей и строк персонажей для разных языков
- Алгоритм для изготовления двунаправленного текста (« Алгоритм BIDI »), где текст на той же строке может переключаться между левой к правой («LTR») и справа налево («RTL»)
- Алгоритм дела смещения
компьютерного программного обеспечения Конечные пользователи вводят эти символы в программы с помощью различных методов ввода , например, физических клавиатур или виртуальных символов .
UCS можно разделить различными способами, например, на плоскость , блок, категория символов или свойство символов . [ 1 ]
Обзор ссылки на символ
[ редактировать ]Ссылка на числовые символы HTML или XML относится к символу с его универсальным набором символов /точкой кода Unicode и использует формат
&#ННН;
или
&#xххххх;
где nnnn является кодовой точкой в десятичной форме, а HHHH является кодовой точкой в шестнадцатеричной форме. X . должен быть строчным в документах XML NNNN . или HHHH могут быть любым количеством цифр и могут включать в себя ведущие нули HHHH может смешать верхний и нижний регистр, хотя верхний регистр - обычный стиль.
Напротив, ссылка на символ объекта символа относится к символу по имени сущности , которая имеет желаемый символ в качестве замены текста . Сущность должна быть предопределена (встроена в язык разметки), либо явно объявлено в определении типа документа (DTD). Формат такой же, как и для любого ссылки на объект:
&имя;
где имя чувствительно к случаю имени сущности. Полуолон требуется.
Самолеты
[ редактировать ]Unicode и ISO делят набор кодовых точек на 17 плоскостей, каждый из которых способен содержать 65536 различных символов или 114,112. По состоянию на 2024 (Unicode 16.0) ISO и консорциум Unicode имеют только только символы и блоки в семи из 17 плоскостей. Другие остаются пустыми и зарезервированными для будущего использования.
Большинство символов в настоящее время присваиваются первой плоскости: основной многоязычной плоскости . Это должно помочь облегчить переход для устаревшего программного обеспечения, поскольку основная многоязычная плоскость адресован всего с двумя октетами . Персонажи за пределами первого самолета обычно имеют очень специализированное или редкое использование.
Каждая плоскость соответствует значению одной или двух шестнадцатеричных цифр (0—9, a - f), предшествующих четырем окончательным: следовательно, U+24321 находится в плоскости 2, U+4321 находится в плоскости 0 (неявно считывается U+04321 ), а U+10A200 будет в плоскости 16 (HEX 10 = десятичный децимал 16). В пределах одной плоскости диапазон кодовых точек - шестнадцатеричный 0000 - FFFF, что дает максимум 65536 кодовых точек. Самолеты ограничивают код указывают на подмножество этого диапазона.
Блоки
[ редактировать ]Unicode добавляет свойство блока в UCS, которое дополнительно делит каждую плоскость на отдельные блоки. Каждый блок представляет собой группировку символов по их использованию, такими как «математические операторы» или «символы иврита». При назначении символов ранее незнашиваемым кодовым точкам консорциум обычно выделяет целые блоки схожих символов: например, все символы, принадлежащие к одному сценарию, или все аналогичные символы назначаются одному блоку. Блоки могут также поддерживать неподготовленные или зарезервированные кодовые точки, когда консорциум ожидает, что блок потребует дополнительных назначений.
Первые 256 кодовых точек в UCS соответствуют точкам ISO 8859-1 , самым популярным 8-битным персонажам, кодирующим в западном мире . В результате первые 128 символов также идентичны ASCII . Хотя Unicode называет их блоком латинского сценария, эти два блока содержат много символов, которые обычно полезны за пределами латинского сценария. В общем, не все символы в данном блоке должны быть одинакового сценария, и данный сценарий может происходить в нескольких разных блоках.
Категории
[ редактировать ]Unicode назначает каждому символу UCS общую категорию и подкатегорию. Общие категории: буква, марка, номер, пунктуация, символ или контроль (другими словами форматирование или нерафический характер).
Типы включают:
- Современные, исторические и древние сценарии . По состоянию на 2024 (Unicode 16.0) UCS идентифицирует 168 сценариев, которые используются или используются во всем мире. Многие другие находятся на различных этапах утверждения для будущего включения UCS. [ 2 ]
- Международный фонетический алфавит . UCS посвящает несколько блоков (более 300 символов) символам для международного фонетического алфавита .
- Объединение диаклитических знаков . Важным прогрессом, задуманным Unicode при разработке UCS и связанных с ними алгоритмов для обработки текста, было введение комбинирования диаклитических знаков. Предоставляя акценты, которые могут сочетаться с любым буквенным символом, Unicode и UCS значительно уменьшают количество необходимых символов. В то время как UCS также включает предварительные символы, они были включены в основном для облегчения поддержки в UCS для систем обработки текста, не являющихся Unicode.
- Пунктуация . Наряду с объединяющими диакритическими метками, UCS также стремился объединить пунктуацию в сценариях. Однако многие сценарии также содержат пунктуацию, когда эта пунктуация не имеет аналогичной семантики в других сценариях.
- Символы . Многие математики, технические, геометрические и другие символы включены в UCS. Это обеспечивает различные символы с их собственной точкой или символом кода, а не полагается на переключение шрифтов для обеспечения символических глифов.
- Валюта .
- Буква . Эти символы выглядят как комбинации многих общих латинских сценариев, таких как ℅ . Unicode обозначает многие буквенные символы как символы совместимости, как правило, потому, что они могут быть в простом тексте, заменяя глифы на сочиняющую последовательность символов: например, заменить глиф ℅ на составленную последовательность символов c/o .
- Числовые формы . Количество формирует в первую очередь из предварительных фракций и римских цифр. Как и другие области сочинения последовательностей символов, подход Unicode предпочитает гибкость сочинения фракций путем объединения символов. В этом случае, чтобы создать фракции, один сочетает в себе числа с символом фракции (U+2044). В качестве примера гибкости, который обеспечивает этот подход, существует девятнадцать предварительно сочиненных фракционных символов, включенных в UCS. Тем не менее, существует бесконечность возможных фракций. Используя композиционные символы, бесконечность фракций обрабатывается 11 символами (0-9 и фракционная черта). Ни один набор символов не может включать кодовые точки для каждой предварительно сочиненной фракции. В идеале текстовая система должна представлять одни и те же глифы для фракции, будь то одна из предварительно сочиненных фракций (таких как ⅓ ) или последовательность сочинения символов (например, 1–3 ). Тем не менее, веб -браузеры, как правило, не являются сложными с помощью Unicode и обработки текста. Это гарантирует, что предварительные фракции и комбинирование фракций последовательности будут выглядеть совместимы рядом друг с другом.
- Стрелы .
- Математический .
- Геометрические формы .
- Устаревшие вычисления .
- Управление изображениями графические представления многих контрольных символов.
- Коробка рисунок .
- Блокировать элементы .
- Брайль Образцы .
- Оптическое распознавание персонажа .
- Технический
- Дингбаты .
- Разные символы .
- Смайлики .
- Символы и пиктограммы .
- Алхимические символы .
- Игровые произведения (шахматы, шашки, Go, кости, домино, маджонг, играющие карты и многие другие).
- Шахматные символы
- Тай Сюань Цзин .
- Yijing Hexagram символы .
- CJK . Посвящен идеографам и другим персонажам для поддержки языков в Китае, Японии, Кореи (CJK), Тайване, Вьетнаме и Таиланде.
- Радикалы и удары .
- Идеографы . Безусловно, самая большая часть UCS посвящена идеографам, используемым на языках Восточной Азии. В то время как представление о глифе этих идеографов расходилось на языках, которые их используют, UCS объединяет этих персонажей HAN в том, что Unicode называет Unihan (для Unified Han). С Unihan программное обеспечение для макета текста должно работать вместе с доступными шрифтами и этими символами Unicode для создания соответствующего глифа для соответствующего языка. Несмотря на объединение этих персонажей, UCS по -прежнему включает в себя более 97 000 идеографий Unihan.
- Музыкальная нотация .
- Dupuplan Shorthands .
- Sutton Signwriting .
- Символы совместимости . Несколько блоков в UCS почти полностью посвящены символам совместимости. Символы совместимости - это те, которые включены для поддержки устаревших систем обработки текста, которые не проводят различие между символом и глифом, как это делает Unicode. Например, многие арабские буквы представлены другим глифом, когда буква появляется в конце слова, чем когда буква появляется в начале слова. Подход Unicode предпочитает, чтобы эти буквы были сопоставлены с тем же символом для простоты внутренней обработки текста и хранения текста. Чтобы дополнить этот подход, текстовое программное обеспечение должно выбирать различные варианты глифа для отображения символа на основе его контекста. Более 4000 символов включены по таким причинам совместимости.
- Управляющие символы .
- Суррогаты . UCS включает в себя 2048 кодовых точек в основной многоязычной плоскости (BMP) для суррогатных пар точек кода. Вместе эти суррогаты позволяют решать любую точку кода в шестнадцати других плоскостях с помощью двух суррогатных кодовых точек. Это обеспечивает простой встроенный метод для кодирования 20,1-битного UCS в 16-битном кодировании, таких как UTF-16. Таким образом, UTF-16 может представлять любой символ в BMP с одним 16-битным словом. Символы за пределами BMP затем кодируются с использованием двух 16-битных слов (4 октета или байта) с использованием суррогатных пар.
- Частное использование . Консорциум предоставляет несколько частных блоков использования и самолетов, которые могут быть назначены символами в различных сообществах, а также операционную систему и поставщики шрифтов.
- Нехарактерные лица . Консорциум гарантирует, что определенные кодовые точки никогда не будут назначены символом и вызовыт эти нехарактерные точки кода. К ним относятся диапазон u+fdd0..u+fdef, и две последние кодовые точки каждой плоскости (заканчиваясь шестнадцатеричными цифрами FFFE и FFFF). [ 3 ]
Специальные персонажи
[ редактировать ]Unicode кодифицирует более ста тысяч символов. Большинство из них представляют графы для обработки в виде линейного текста. Некоторые, однако, либо не представляют графы, либо, как графства, требуют исключительной обработки. [ 4 ] [ 5 ] В отличие от контрольных персонажей ASCII и других персонажей, включенных для устаревших возможностей об обратном пути, эти другие персонажи специального назначения наделяют простой текст важной семантикой.
Некоторые специальные символы могут изменить макет текста, такой как столярный заряд с нулевой шириной и неоткрытие с нулевой шириной , в то время как другие вообще не влияют на макет текста, а вместо этого влияют на то, как сопоставлены строки текста, сопоставлены или обрабатываются иным образом. Другие специальные символы, такие как математические невидимые , обычно не влияют на рендеринг текста, хотя сложное программное обеспечение для макета текста может решить тонко регулировать расстояние вокруг них.
Unicode не указывает разделение рабочей силы между программным обеспечением для макета текста (или «двигателем») при рендеринге текста Unicode. Поскольку более сложные форматы шрифтов, такие как Opentype или Apple Advanced Typography , обеспечивают контекстную замену и позиционирование глифов, простой двигатель с макетом текста может полностью полагаться на шрифт для всех решений по выбору и размещению глифа. В той же ситуации более сложный двигатель может объединить информацию из шрифта с собственными правилами для достижения собственной идеи лучшего рендеринга. Чтобы реализовать все рекомендации спецификации Unicode, необходимо готово текстовый двигатель для работы с шрифтами любого уровня сложности, поскольку контекстуальные правила замещения и позиционирования не существуют в некоторых форматах шрифтов и являются необязательными в остальных. является Пример фракции примером: сложные шрифты могут или не могут обеспечивать правила позиционирования в присутствии символа фракции, чтобы создать фракцию, в то время как шрифты в простых форматах не могут.
Байтовый заказа Марка
[ редактировать ]При появлении в головке текстового файла или потока байт -отметка (BOM) U+FEFF намекает на форму кодирования и его байт -заказ.
Если первый байт потока составляет 0xfe и второй 0xff, то текст потока вряд ли будет кодируется в UTF-8 , поскольку эти байты недействительны в UTF-8. Также вряд ли будет UTF-16 в матч-эндэндианском байтовом порядке, потому что 0xfe, 0xff читать как 16-битное маленькое эндианское слово было бы U+Fffe, что является бессмысленным. Последовательность также не имеет никакого значения ни в каком расположении кодирования UTF-32 , поэтому, в итоге, она служит довольно надежным признаком того, что текстовый поток закодирован как UTF-16 в порядок Big-Endian Byte. И наоборот, если первые два байта составляют 0xff, 0xfe, то текстовый поток может предположить, что он кодируется как UTF-16LE, поскольку, читая как 16-битное значение маленького эндэдиана, байты дают ожидаемую отметку заказа 0xFeff Byte. Это предположение становится сомнительным, однако, если следующие два байта составляют 0x00; Либо текст начинается с нулевого символа (U+0000), либо правильное кодирование на самом деле UTF-32LE, в котором полная 4-байтовая последовательность FF Fe 00 00-один из символов, капля.
Последовательность UTF-8, соответствующая U+Feff, составляет 0xef, 0xbb, 0xbf. Эта последовательность не имеет значения в других формах кодирования Unicode, поэтому она может показать, что этот поток кодируется как UTF-8.
Спецификация Unicode не требует использования байтовых отметок в текстовых потоках. Далее утверждается, что они не должны использоваться в ситуациях, когда какой -то другой метод сигнализации формы кодирования уже используется.
Математические невидимые
[ редактировать ]В первую очередь для математики, невидимый сепаратор (U+2063) обеспечивает разделитель между символами, где пунктуация или пространство может быть пропущено, например, в двухмерном индексе, как ij. Невидимое время (U+2062) и приложение функционального приложения (U+2061) полезны в математическом тексте, где умножение терминов или применение функции подразумевается без какого -либо глифа, указывающего на операцию. Unicode 5.1 вводит также математический невидимый символ плюс (U+2064), который может указывать на то, что интегральное число, за которым следует дробь, должно обозначать их сумму, но не их продукт.
Фракционная черта
[ редактировать ]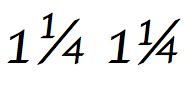

Символ фракции SLASH (U+2044) имеет особое поведение в стандарте Unicode: [ 6 ] (Раздел 6.2, Другая пунктуация)
Стандартная форма фракции, построенной с использованием фракции, определяется следующим образом: любая последовательность одной или нескольких десятичных цифр (общая категория = ND), за которой следует черта фракции, за которой следует любая последовательность одной или нескольких десятичных цифр. Такая фракция должна отображаться в виде единицы, например, ¾ . Если программное обеспечение отображения не способно отображать фракцию с устройством, то его также можно отобразить в виде простой линейной последовательности в качестве запасного (например, 3/4). Если фракция должна быть отделена от предыдущего числа, то можно использовать пространство, выбрав подходящую ширину (нормальная, тонкая, нулевая ширина и т. Д.). Например, 1 + Zero Shidty Space + 3 + Fract Fraction Slash + 4 отображается как 1¾ .
Следуя этой рекомендации Unicode, системы обработки текста дают сложные символы только из простого текста. Здесь присутствие символа снесения фракции инструктирует двигатель макета синтезировать фракцию от всех последовательных цифр, предшествующих и после удара. На практике результаты варьируются из -за сложного взаимодействия между шрифтами и макетами. Простые двигатели с макетом текста, как правило, вообще не синтезируют фракции и вместо этого нарисуют глифы в виде линейной последовательности, как описано в схеме резервного периода Unicode.
Более сложные двигатели макета сталкиваются с двумя практическими вариантами: они могут следовать рекомендации Unicode, или они могут полагаться на собственные инструкции шрифта по синтезированию фракций. Игнорируя инструкции шрифта, двигатель макета может гарантировать рекомендуемое поведение Unicode. Следуя инструкциям шрифта, двигатель макета может достичь лучшей типографии , потому что размещение и формирование цифр будут настроены на этот конкретный шрифт в этом конкретном размере.
Проблема с выполнением инструкций шрифта заключается в том, что более простые форматы шрифтов не могут указать поведение синтеза фракции. Между тем, более сложные форматы не требуют, чтобы шрифт указывал поведение синтеза фракции, и поэтому многие этого не делают. Большинство шрифтов сложных форматов могут инструктировать двигатель макета заменить простую текстовую последовательность, такую как 1–2, на предварительно сочиненный ½ глиф. Но поскольку многие из них не будут выпускать инструкции по синтезу фракций, простая текстовая строка, такая как 221–225, вполне может отображаться как 22½25 (при этом ½ представляет собой замещенную предварительную фракцию, а не синтезированную). Перед лицом подобных проблем те, кто хочет полагаться на рекомендуемое поведение Unicode, должны выбирать шрифты, которые, как известно, синтезируют фракции или программное обеспечение для макета текста, известное для создания рекомендуемого поведения Unicode независимо от шрифта.
Двунаправленное нейтральное форматирование
[ редактировать ]Направление написания - это направление, глифы размещены на странице по отношению к прямому прогрессии символов в строке Unicode. Английский и другие языки латинского сценария имеют направление письма с правой. Несколько крупных письменных сценариев, таких как арабский язык и иврит , имеют направление письма сразу на пол. Спецификация Unicode присваивает тип направления каждому символу, чтобы информировать текстовые процессоры, как последовательности символов следует упорядочить на странице.
В то время как лексические символы (то есть буквы), как правило, специфичны для одного сценария письма, некоторые символы и знаки препинания используются во многих сценариях письма. Unicode мог бы создать дублирующиеся символы в репертуаре, которые отличаются только по направлению, но вместо этого решили объединить их и назначить им нейтральный направленный тип. Они приобретают направление при рендеринге от соседних персонажей. Некоторые из этих символов также имеют свойство , смягченное бить, указывающее на то, что глиф должен отображаться в зеркальном изображении при использовании в тексте с правого на лето.
Тип направленного временного визуализации нейтрального символа может оставаться неоднозначным, когда отметка помещается на границу между изменениями направления. Чтобы решить эту проблему, Unicode включает в себя символы, которые имеют сильную направленность, не связаны с глифом с ними и игнорируют системы, которые не обрабатывают двунаправленный текст:
- Арабский письменный знак (U+061C)
- Марк слева направо (U+200E)
- Право на пол (U+200f)
Окружение двунаправленного нейтрального персонажа слева-правой отметиной заставит персонажа вести себя как правый персонаж, окружая его правой к лебрюской отмеби характер. Поведение этих символов подробно описано в двухнамерном алгоритме Unicode.
Двунаправленное общее форматирование
[ редактировать ]В то время как Unicode предназначен для обработки нескольких языков, нескольких систем письма и даже текста, который течет либо слева направо, либо справа налево с минимальным вмешательством автора, существуют особые обстоятельства, когда сочетание двунаправленного текста может стать сложным-реквизитное больше Автор контроль. Для этих обстоятельств Unicode включает в себя пять других символов для управления сложным внедрением текста слева направо в текст правого на лето и наоборот:
- Всаждение слева направо (U+202a)
- Встроение справа на лето (U+202b)
- Форматирование направления POP (U+202C)
- Переопределение слева направо (U+202d)
- Право на пол (U+202E)
- Изолят слева направо (U+2066)
- Изолят справа налево (U+2067)
- Первый сильный изолят (U+2068)
- Изолат направленного попса (U+2069)
Интернетальные аннотация персонажей
[ редактировать ]- Межлинейная аннотационная якорь (U+FFF9)
- Межлинейный сепаратор аннотации (U+FFFA)
- Межлинейный аннотационный терминатор (U+FFFB)
Скрипт-специфический
[ редактировать ]- Префикс контроль формата
- Знак арабского номера (U+0600)
- Арабский знак Санах (U+0601)
- Маркер арабской сноски (U+0602)
- Арабский знак SAFHA (U+0603)
- Арабский знак Samvat (U+0604)
- Арабская номера отмечена выше (U+0605)
- Арабский конец айа (U+06dd)
- Syriac Abbreviation Mark (U+070F)
- Арабский фунт отметка выше (U+0890)
- Арабская отметка Пиастра выше (U+0891)
- Знак номера Kaithi (U+110BD)
- Знак номера Kaithi выше (U+110CD)
- Египетские иероглифы
- Египетский иероглиф вертикальный столяр (U+13430)
- Египетский иероглиф горизонтальный столяр (U+13431)
- Египетская иероглифная вставка в верхнем старте (U+13432)
- Египетская иероглифная вставка внизу (U+13433)
- Египетская иероглифная вставка в верхнем конце (U+13434)
- Египетская иероглифная вставка в нижней части (U+13435)
- Египетское иероглифное наложение среднего (U+13436)
- Египетский иероглиф начальный сегмент (U+13437)
- Египетский конечный сегмент иероглиф (U+13438)
- Египетская иероглифная вставка в середине (U+13439)
- Египетская иероглифная вставка на вершине (U+1343a)
- Египетская иероглифная вставка в дно (U+1343b)
- Египетский иероглиф начал корпус (U+1343c)
- Египетский иероглиф конечный корпус (U+1343d)
- Египетский иероглиф начинается на стенах
- Египетский иероглиф в конце концов (U+1343f)
- Брахми
- Номер Брахми Сторян (U+1107F)
- Формирование сценария, полученное из брахми, ( вирама и аналогичная диакритика)
- Деванагари подписывает Вираму (U+094d)
- Бенгальский знак вируса (U+09CD)
- Гурмухи подписывает Вираму (U+0A4D)
- Гуджарати подписывает Вираму (U+0ACD)
- Орайя подписать вирус (U+0B4D)
- Тамильский знак вируса (u+0bcd)
- Телугу подписать вирус (u+0c4d)
- Каннада подписать вирус (U+0CCD)
- Малаялам знак вертикальной полосы вируса (u+0d3b)
- Малайалам Знак Циркуляр Вирама (U+0D3C)
- Малаялам знак вируса (u+0d4d)
- Sinha Sign Alkun Alkuna (U+0
- Тайский персонаж Финту (U+0E3A)
- Тайский персонаж Ямаккан (U+0E4E)
- Lao Sign Pali Virama (u+0ba)
- Мьянма подписывает Вираму (U+1039)
- Тагальский знак Virama (U+1714)
- Тагальский знак хлопок (U+1715)
- Знак Хануноо Памудпод (U+1734)
- Придет знак кхмер (U+17D1)
- Кхмер Знак Coeng (U+17d2)
- U+1A60
- Тай Там знак Рай Хаам (U+1A7A)
- Балийцы в момент времени (U+1B44)
- Сунданский знак Pamaaeh (U+1Baa)
- Сунданский знак вируса (u+1bab)
- Batak Relivering (U+1BF2)
- Корпоративная летучая мышь (U + 1BF3)
- Syloti Nagri Sign Hasanta (U+A806)
- Syloti Nagri Sign Alternate Hasanta (U+A82C)
- Saurashtra подписать вирус (U+A8C4)
- Rejang Virama (U+A953)
- Javanese Pangkon (U+A9C0)
- Meetei Mayek Virama (U+AAF6)
- Харошти Вирама (U+10A3F)
- Брахми Вирама (U+11046)
- Брахми подписывает старую тамильскую вирусу (U+11070)
- Kaithi подписывает вирус (U+110B9)
- Чакма Вирама (U+11133)
- Шарада подписать вирус (U+111C0)
- Ходжки подписывает Вираму (U+11235)
- Худавади подписывает Вираму (U+112EA)
- Гранта подписывает Вираму (U+1134d)
- Тулу-тигалари подписывает вирус (U+113ce)
- Знак Тулу-Тигалари зациклена вирама (U+113CF)
- Tulu-Tigalari Conciner (U+113D0)
- Newa Sign Virama (U+11442)
- Тирхута подписывает Вираму (U+114C2)
- Siddham Sign Virama (U+115bf)
- Моди подписать вирус (U+1163f)
- Такри подписывает вирус (U+116B6)
- Убийца знака Ахома (U+1172b)
- Дора знак Вирамса (U+11839)
- Погружения Акуру знак Халанта (U+1193d)
- Погружения Акуру Вирама (U+1193E)
- Нандинагари подписывает вирус (U+119E0)
- Занабазар Площадь Знак Вирама (U + 11A34)
- Субъектор площади Занабазара (U+11A47)
- Soyombo subjoiner (U+11A99)
- Bhaiksuki подписывает вирус (U+11c3f)
- Масарам Гонди знак Халанта (U+11d44)
- Масарам Гонди Вирама (U+11D45)
- Gunjala Gondi Virama (U+11d97)
- Один из убийцы знака (U+11F41)
- Kawi Consiner (U+11F42)
- Знак Гурунг Хема Толхома (U + 1612f)
- Кират Рай подписывает Вираму (U+16D6B)
- Знак Koror SAT (U+16D6C)
- Исторические вирамы с другими функциями
- Тибетская Марка Халанта (U+0F84)
- Знак Мьянмы Асат (U+103A)
- Знак конечности si-i (u+193b)
- Встреча Mayek Apun Iyek (u+abed)
- Чакма Маайя (U+11134)
- Монгольские селекторы вариации
- Монгольский селектор свободных вариаций One (U+180b)
- Монгольский селектор свободных вариаций два (U+180c)
- Монгольский селектор свободных вариаций три (U+180d)
- Монгольский гласный сепаратор (U+180e)
- Общие селекторы вариации
- Variation Selecter -1 до -16 (U+Fe00 -U+FE0F)
- Селектор вариации с -256 (U+E0100 -U+E01EF)
- Символы тегов (U+E0001 и U+E0020 - U+E007F)
- Тифина
- Согласный тифинаглян (U+2D7F)
- Огхам
- Space Mark Ogham (U+1680)
- Идеографический
- Идеографический индикатор вариации (U+303E)
- Идеографическое описание (U+2ff0 - U+2FFB)
- Музыкальный формат контроль
- Музыкальный символ Begin Beam (U+1D173)
- Музыкальный символ конечный луч (U+1D174)
- Музыкальный символ начинается галстук (u+1d175)
- Музыкальный символ конец галстука (U+1D176)
- Музыкальный символ начинается сплав (U+1D177)
- Музыкальный символ конечный шляп (U+1D178)
- Музыкальный символ начинается фраза (U+1D179)
- Музыкальный символ конечная фраза (u+1d17a)
- Контроль формата сокращения
- Шорт -формат буквы перекрытия (U+1BCA0)
- Шорт -форма, проведенный перекрытие (U+1BCA1)
- Шорт -формат вниз (U+1BCA2)
- Шарфуд -форматирование шага (u+1bca3)
- Устаревшего альтернативного форматирования
- Ингибируйте симметричный замена (U+206a)
- Активировать симметричный замена (U+206b)
- Ингибирование формирования арабской формы (U+206c)
- Активировать форму арабской формы (U+206d)
- Национальные цифровые формы (U+206E)
- Номинальные цифры формы (U+206F)
Другие
[ редактировать ]- Символ замены объекта (U+FFFC)
- Замена символов (U+FFFD)
Символы против кодовых точек
[ редактировать ]Термин «символ» не очень определен, и то, на что мы имеем в виду большую часть времени, это графема . Графема визуально представлена его глифом . Используемый шрифт шрифтом (часто ошибочно называемый ) может изображать визуальные изменения одного и того же символа. Вполне возможно, что два разных графема могут иметь одинаковый глиф или визуально настолько близко, что средний читатель не может их отделить.
Графема почти всегда представлена одной кодовой точкой, например, буква A Latin Capital Letter A представлена только кодовой точкой U+0041.
Графический латинский капитал A с Dieresis ä является примером, когда символ может быть представлен более чем одной кодовой точкой. Это может быть U+00C4 или U+0041U+0308. U+0041 - это знакомый A и U+0308 - это комбинирующий диарезис ̈ , комбинированная диаклитическая метка .
Когда сочетание отметки примыкает к некомбинирующей точке кода марки, приложения для рендеринга текста должны нагрузить сочетание отметки на глиф, представленную другой точкой кода, чтобы сформировать графему в соответствии с набором правил. [ 7 ]
Слово Bäm, следовательно, будет тремя графемами. Он может быть составлен из трех кодовых точек или более в зависимости от того, как на самом деле составлены символы.
Пробелы, столяры и сепараторы
[ редактировать ]Unicode предоставляет список символов, которые он считает персонажами пробела для поддержки совместимости. Реализации программного обеспечения и другие стандарты могут использовать термин для обозначения немного другого набора символов. Например, Java не учитывает U+00A0 не нарушение места или U+0085 <control-0085> (следующая строка) будет пробелом, хотя Unicode делает. Материалы пробелов - это символы, обычно обозначенные для среды программирования. Часто они не имеют синтаксического значения в таких средах программирования и игнорируются интерпретаторами машины. Unicode обозначает устаревшие элементы управления U+0009 через U+000D и U+0085 в качестве персонажей пробелов, а также всех символов, чьи общие значения свойства категории - разделение. На сфере Unicode 16.0 насчитывается 25 персонажей общего пробела.
Grapheme aniters и не младшие
[ редактировать ]Сборника с нулевой шириной (U+200D) и неотъемлемые не-Joiner (U+200C) контролируют соединение и лигирование глифов. Столярь не вызывает символов, которые иначе не присоединятся к этому, и не лигатируют это, но в сочетании с не-младшим, эти символы могут использоваться для управления соединением и лигированием свойств окружающих два соединения или лигирования символов. Комбинирующий графический стопорт (U+034F) используется для различения двух базовых символов в качестве одного общего основания или диграфа, в основном для базовой обработки текста, сопоставления строк, складывания корпусов и так далее.
Слово столяры и сепараторы
[ редактировать ]Наиболее распространенным сепаратором слова является пространство (U+0020). Тем не менее, есть и другие слова и сепараторы, которые также указывают на разрыв между словами и участвуют в алгоритмах разрушения линии. Пространство без разрыва (U+00A0) также дает базовый прогресс без глифа, но ингибирует, а не включает в себя линейный разрыв. Пространство нулевой ширины (U+200b) допускает разрыв в линии, но не дает места: в некотором смысле соединение, а не разделяет два слова. Наконец, слово «Слово» (U+2060) ингибирует разрывы линии, а также не включает в себя ни одно из белого пространства, создаваемого базовым продвижением.
| Базовый прогресс | Нет базового продвижения | |
|---|---|---|
| Разрешить линии (Разделители) |
Пространство U+0020 | Ноль ширина пространство u+200b |
| Подавлять линейные перерывы (Столяры) |
Пространство без разрыва U+00A0 | Слово столяр U+2060 |
Другие разделители
[ редактировать ]- Сепаратор линии (U+2028)
- Разделитель абзаца (U+2029)
Они обеспечивают Unicode с нативными абзацами и сепараторами линейных сепаратов, независимых от устаревших контрольных символов ASCII, таких как возврат перевозки (U+000A), LineFeed (U+000D) и следующая строка (U+0085). Unicode не предусматривает другие элементы управления форматирования форматирования ASCII, которые, по -видимому, не являются частью модели обработки простого текста Unicode. Эти устаревшие элементы управления форматированием включают вкладку (U+0009), таблицу линии или вертикальную вкладку (U+000B) и подачу формы (U+000C), которая также рассматривается как разрыв страницы.
Пробелы
[ редактировать ]Космический символ (U+0020), как правило, вводится с помощью космической панели на клавиатуре, семантически служит сепаратором слов на многих языках. По установлению причин, UCS также включает в себя места различных размеров, которые являются эквивалентами совместимости для космического символа. В то время как эти пространства различной ширины важны в типографике, модель обработки Unicode требует, чтобы такие визуальные эффекты были обработаны богатым текстом, разметкой и другими подобными протоколами. Они включены в репертуар Unicode, в основном для обработки транскодирования об обратном перерыве, из других кодировки набора символов. Эти пространства включают в себя:
- И Quad (U+2000)
- В Quad (U+2001)
- В космосе (U+2002)
- EM Space (U+2003)
- Пространство с тремя за Эм (U+2004)
- Пространство с четырьмя за Эм (U+2005)
- Пространство шести за Эм (U+2006)
- Пространство рисунка (U+2007)
- Пространство пунктуации (U+2008)
- Тонкое пространство (U+2009)
- Пространство для волос (U+200A)
- Среднее математическое пространство (U+205f)
Помимо оригинального пространства ASCII, другие пространства являются символами совместимости. В этом контексте это означает, что они эффективно не добавляют семантического контента в текст, но вместо этого обеспечивают управление стилем. В Unicode этот несемантический контроль стиля часто называют богатым текстом и выходит за рамки целей Unicode. Вместо того, чтобы использовать разные пространства в разных контекстах, вместо этого следует обрабатывать этот стиль с помощью интеллектуального программного обеспечения для макета текста.
Три других специфичных для письменной системы:
- Монгольский гласный сепаратор (U+180e)
- Идеографическое пространство (U+3000): ведет себя как идеографический сепаратор и, как правило, выпускается в виде белого пространства той же ширины, что и идеограф.
- Space Mark Ogham (U+1680): этот символ иногда отображается с глифом, а в других случаях - только белое пространство.
Символы управления линейным перерывом
[ редактировать ]Несколько символов предназначены для того, чтобы помочь контролировать линейные разрывы, либо отказавшись от них (символы без разрыва), либо предложив разрывы строк, такие как мягкий дефис (U+00AD) (иногда называемый «застенчивый дефис»). Такие персонажи, хотя и предназначены для стиля, вероятно, являются необходимыми для сложных типов разрыва линий, которые они делают возможными.
- Перерыв задержание
- Не разрушающий дефис (U+2011)
- Пространство без разрыва (U+00A0)
- Тибетский Марк Делимитер Делистин BSTAR (U + 0F0C)
- Узкое пространство без разрыва (U+202f)
Символы, препятствующие перерыву, предназначены для эквивалента последовательности символов, завернутой в слово oiner u+2060. Однако слово «Слово» может быть добавлен до или после любого персонажа, который позволил бы разрыв в линии препятствовать такому разрушению линий.
- Перерыв включает в себя
- Мягкий дефис (U+00AD)
- Тибетский марк межсиллабический попдл (u + 0f0b)
- Пространство с нулевой шириной (U+200B)
И разрыв, ингибирующий, так и разрыв, позволяющие символам участвовать с другими знаками препинания и пробелов, чтобы позволить систему текстовой визуализации определять разрывы линии в алгоритме разрыва линии Unicode. [ 8 ]
Типы кодовой точки
[ редактировать ]Все кодовые точки, учитывающие какую -то цель или использование, считаются обозначенными кодовыми точками. Из них они могут быть назначены абстрактному персонажу или иным образом назначены для какой -либо другой цели.
Назначенные символы
[ редактировать ]Большинство кодовых точек в реальном использовании были назначены абстрактным символам. Это включает в себя символы частного использования, которые, хотя и официально обозначены стандартом Unicode для определенной цели, требуют, чтобы отправитель и получатель заранее согласились с тем, как их следует интерпретировать для имеющего значение для имеющего значение.
Персонажи частного использования
[ редактировать ]UCS включает в себя 137 468 символов частного использования, которые представляют собой кодовые точки для частного использования в трех разных блоках, каждый из которых называется частной областью использования (PUA). Стандарт Unicode распознает кодовые точки в PUA в качестве законных кодов символов Unicode, но не назначает им никакого (абстрактного) символа. Вместо этого частные лица, организации, поставщики программного обеспечения, поставщики операционной системы, поставщики шрифтов и сообщества конечных пользователей могут свободно использовать их по своему усмотрению. Внутри закрытых систем символы в PUA могут однозначно работать, позволяя таким системам представлять символы или глифы, не определенные в Unicode. [ 9 ] В публичных системах их использование является более проблематичным, поскольку реестра нет и нет способа предотвратить принятие нескольких организаций в разных точках кода для разных целей. Одним из примеров такого конфликта является Apple использование U+F8FF для логотипа Apple , в сравнении с реестра Unicode Призывчика U+F8FF как использованием Глиф мумификации Клингона в сценарии клингона . [ 10 ]
Основная многоязычная плоскость (плоскость 0) содержит 6400 персонажей частного пользователя в одноильно названной области PUA Private Rea , которая варьируется от U+E000 до U+F8FF. Самолеты частного использования , плоскость 15 и плоскость 16, каждый из которых имеет свои собственные PUA по 65 534 персонажам частного использования (с последними двумя точками кода каждого плоскости, не являющиеся характерами). Это дополнительная зона частного использования , которая варьируется от U+F0000 до U+FFFFD, и дополнительный частное использование зоны B , которая варьируется от U+100000 до U+10FFFD.
PUA - это концепция, унаследованная от определенных азиатских систем кодирования. Эти системы имели частные области использования, чтобы кодировать то, что японцы называют Гайджи (редкие символы, которые обычно не встречаются в шрифтах), специфичными для приложения.
Суррогаты
[ редактировать ]UCS использует суррогаты для обращения за персонажами за пределами начальной основной многоязычной плоскости, не прибегая к более чем 16-разловым словам. [ 11 ] Есть 1024 суррогатов 1024 «высокого» (D800 - DBFF) и 1024 "низких" суррогатов (DC00 - DFFF). Объединяя пару суррогатов, оставшиеся символы во всех других плоскостях могут быть рассмотрены (1024 × 1024 = 1048576 кодовых точек в остальных 16 плоскостях). В UTF-16 они всегда должны появляться в парах, как высокий суррогат, за которым следует низкий суррогат, используя 32 бита для обозначения одной кодовой точки.
Суррогатная пара обозначает кодовую точку
- 10000 16 + ( H - D800 16 ) × 400 16 + ( L - DC00 16 )
где H и L являются числовыми значениями высоких и низких суррогатов соответственно. [ 12 ]
Поскольку высокие суррогатные значения в диапазоне DB80 -DBFF всегда производят значения в плоскостях частного использования, высокий диапазон суррогата может быть дополнительно разделен на (нормальные) высокие суррогаты (D800 -DB7F) и «суррогаты высокого частного использования» (DB80 -DBFF) Полем
Изолированные суррогатные точки кода не имеют общего толкования; Следовательно, для этого диапазона не предусмотрены никаких диаграмм кода символов. На языке программирования Python отдельные суррогатные коды используются для внедрения некалируемых байтов в строки Unicode. [ 13 ]
Нехарактерные лица
[ редактировать ]Неучиткий термин «нехарактер» относится к 66 кодовым точкам (помеченный <not a character>) постоянно зарезервировано для внутреннего использования и, следовательно, гарантированно никогда не будет назначено символом. [ 14 ] Каждый из 17 плоскостей имеет две точки окончания кода, выделенные как нехарактерные лица. Итак, нехарактеры: U+FFFE и U+FFFF на BMP, U+1FFFE и U+1FFFF на плоскости 1 и т. Д., До U+10FFFE и U+10FFFF на плоскости 16, в общей сложности 34 кода точки Кроме того, существует смежный диапазон еще 32 нехарактерных точек в BMP: U+FDD0..U+FDEF. Реализации программного обеспечения могут бесплатно использовать эти кодовые точки для внутреннего использования. Одним из особенно полезных примеров нехарактера является кодовая точка u+fffe. Эта кодовая точка имеет обратную последовательность байтов UTF-16/UCS-2 байтового знака (U+FEFF). Если поток текста содержит этот нехарактер, это является хорошим признаком того, что текст был интерпретирован с неверной эндозостью .
Версии стандарта Unicode от 3,1,0 до 6.3.0 утверждали, что нехарактер «никогда не должны меняться». Corrigendum № 9 стандарта позже заявил, что это привело к «неуместному переопределению», разъясняя, что «[нехарактер] не являются незаконными в обмене и не вызывают плохо сформированный текст Unicode» и удаляют первоначальное требование.
Зарезервированные точки кода
[ редактировать ]Все остальные кодовые точки, которые не назначены, называются зарезервированными. Эти кодовые точки могут быть назначены для конкретного использования в будущих версиях стандарта Unicode.
Символы, графемные кластеры и глифы
[ редактировать ]Принимая во внимание, что многие другие наборы символов назначают символ для каждого возможного представления персонажа, Unicode стремится лечить символы отдельно от глифов. Это различие не всегда однозначно; Тем не менее, несколько примеров помогут проиллюстрировать различие. Часто два символа могут быть комбинированы типографски для улучшения читаемости текста. Например, трех букв «FFI» может рассматриваться как один глиф. Другие наборы символов часто назначали кодовую точку этому глифу в дополнение к отдельным буквам: «F» и «i».
Кроме того, Unicode приближается к диакритическим модифицированным буквам в виде отдельных символов, которые при отображении становятся единственным глифом. Например, «O» с диарезом : « ö ». Традиционно другие наборы символов присваивали уникальную точку кода символа для каждой диакритической модифицированной буквы, используемой на каждом языке. Unicode стремится создать более гибкий подход, позволяя объединять диаклитические символы для объединения с любой буквой. Это может значительно уменьшить количество активных кодовых точек, необходимых для набора символов. В качестве примера рассмотрим язык, который использует латинский сценарий и объединяет диарезис с буквами верхнего и нижнего часа «A», «O» и «U». При подходе Unicode только диакретический символ диарезиса должен быть добавлен к набору символов для использования с латинскими буквами: «A», «a», «O», «O», «U» и «U»: Семь персонажей в целом. Наборы устаревших символов должны добавить шесть предварительных букв с диарезом в дополнение к шести кодовым точкам, которые он использует для букв без диарезиса: в общей сложности двенадцать кодовых точек символа.
Символы совместимости
[ редактировать ]UCS включает в себя тысячи символов, которые Unicode назначает символами совместимости. Это символы, которые были включены в UCS, чтобы предоставить различные кодовые точки для символов, которые дифференцируют другие символы, но не будут дифференцированы в подходе Unicode к символам.
Главной причиной этого дифференциации было то, что Unicode проводит различие между символами и глифами. Например, при написании английского языка в курсивом стиле буква «я» может принимать разные формы, появляется ли она в начале слова, конец слова, середина слова или изоляции. Такие языки, как арабский , написанный в арабском сценарии, всегда курсируют. Каждая буква имеет много разных форм. UCS включает в себя 730 арабских персонажей, которые разлагаются до 88 уникальных арабских персонажей. Тем не менее, эти дополнительные арабские символы включены таким образом, чтобы программное обеспечение для обработки текстовой обработки могло перевести текст из других наборов символов в UCS и обратно без какой-либо потери информации, имеющей решающую роль для программного обеспечения для не Unicode.
Однако для UCS и Unicode, в частности, предпочтительным подходом является всегда кодировать или отображать эту букву с одним и тем же символом, где бы он ни появлялся в словах. Затем отдельные формы каждой буквы определяются методами программного обеспечения для макета текста. Таким образом, внутренняя память для символов остается идентичной, независимо от того, где символ появляется в слове. Это значительно упрощает поиск, сортировку и другие операции обработки текста.
Свойства характера
[ редактировать ]Каждый символ в Unicode определяется большим и растущим набором свойств. Большинство из этих свойств не являются частью универсального набора символов. Свойства облегчают обработку текста, включая сортировку или сортировку текста, идентификацию слов, предложений и графем, рендеринг или текста визуализации и так далее. Ниже приведен список некоторых основных свойств. В базе данных символов Unicode есть много других. [ 15 ]
| Свойство | Пример | Подробности |
|---|---|---|
| Имя | Латинская столичная буква А | Это постоянное имя, назначенное совместным сотрудничеством Unicode и ISO UCS. Несколько известных плохо выбранных имен существуют и признаны (например, форма презентации U+FE18 для вертикального правого белоснечного лин1 -линзоката, который сформулирован с ошибкой - должен быть скобк), но не будет изменен, чтобы обеспечить статичность спецификации. [ 16 ] |
| Кодовая точка | В+0041 | Кодовая точка Unicode - это число, также навсегда назначенное вместе со свойством «Имя» и включенным в Companion UCS. Обычный пользователь - представлять кодовую точку как шестнадцатеричное число с префиксом «U+» впереди. |
| Репрезентативный глиф | Репрезентативные глифы представлены в кодовых диаграммах. [ 18 ] | |
| Общая категория | Прописная буква | Общая категория [ 19 ] экспрессируется как двухбуквенная последовательность, такая как «lu» для верхней буквы или «ND», для десятичной цифры. |
| Объединение класса | Не_Резатор (0) | Поскольку диакритика и другие комбинированные оценки могут быть выражены с несколькими символами в Unicode, свойство «Комбинирование класса» позволяет дифференцировать символы по типу комбинированного символа, который он представляет. Комбинирующий класс может быть выражен как целое число между 0 и 255 или в качестве названного значения. Целостные значения позволяют переупорядочить комбинированные знаки в канонический порядок, чтобы сделать сравнение строк идентичных строк. |
| Двунаправленная категория | LEATE_TO_RIGHT | Указывает тип символа для применения двунаправленного алгоритма Unicode. |
| Двунаправленное зеркальное зеркало | нет | Указывает, что глиф персонажа должен быть изменен или отражен в двухнамерном алгоритме. Зеркальные глифы могут быть предоставлены производителями шрифтов, извлеченными из других символов, связанных с свойством «двунаправленного зеркального глифа» или синтезированного системой рендеринга текста. |
| Двунаправленное зеркальное глиф | N/a | Это свойство указывает на кодовую точку другого персонажа, чей глиф может служить зеркальным глифом для настоящего персонажа при зеркальном зеркальном режиме в двунаправленном алгоритме. |
| Десятичная цифровая стоимость | В | Для цифр это свойство указывает числовое значение символа. Десятичные цифры имеют все три значения, установленные на одно и то же значение: символы совместимости с презентационными текстами и другие арабские индикальные цифры, как правило Римские цифры или цифры Ханчжоу/Сучжоу, как правило, имеют только «числовое значение». |
| Значение цифры | В | |
| Числовое значение | В | |
| Идеографический | ЛОЖЬ | Указывает, что персонаж - идеограф CJK : логограф в сценарии Хан . [ 20 ] |
| По умолчанию игнорируется | ЛОЖЬ | Указывает, что персонаж игнорируется для реализаций, и что не требуется отображение глифа, последнего глифа или запасного символа. |
| Устарел | ЛОЖЬ | Unicode никогда не удаляет символы из репертуара, но иногда Unicode установил небольшое количество символов. |
Unicode предоставляет онлайн -базу данных [ 21 ] интерактивно запросить весь репертуар символов Unicode различными свойствами.
Смотрите также
[ редактировать ]Ссылки
[ редактировать ]- ^ "Стандарт Unicode" . Консорциум Юникода . Получено 2016-08-09 .
- ^ «Дорожные карты до Юникода» . Консорциум Юникода . Получено 2024-09-12 .
- ^ «FAQ - персонажи частного использования, нехарактерные и стражи» . www.unicode.org . Получено 2023-10-24 .
- ^ «Раздел 2.13: Специальные символы» . Стандарт Unicode . Консорциум Юникода. Сентябрь 2024 года.
- ^ «Раздел 4.12: символы с необычными свойствами» . Стандарт Unicode . Консорциум Юникода. Сентябрь 2024 года.
- ^ «Раздел 6.2: Общая пунктуация» . Стандарт Unicode . Консорциум Юникода. Сентябрь 2024 года.
- ^ «UTN #2: общий метод для рендеринга, объединяющий отметки» . www.unicode.org . Получено 2020-12-16 .
- ^ «UAX #14: Алгоритм разрыва линии Unicode» . Консорциум Юникода. 2016-06-01 . Получено 2016-08-09 .
- ^ «Раздел 23.5: персонажи частного использования» (PDF) . Стандарт Unicode . Консорциум Юникода. Сентябрь 2022 года.
- ^ Майкл Эверсон (2004-01-15). "Клингон: u+f8d0 - u+f8ff" .
- ^ «Раздел 23.6: зона суррогатов» (PDF) . Стандарт Unicode . Консорциум Юникода. Сентябрь 2022 года.
- ^ Каплан, Майкл. «Суррогатная поддержка в продуктах Microsoft» .
- ^ v. Löwis, Martin (2009-04-22). «Неуделеваемые байты в системных интерфейсах символов» . Предложения по улучшению питона . PEP 383 . Получено 2016-08-09 .
- ^ «Раздел 23.7: нехарактер» (PDF) . Стандарт Unicode . Консорциум Юникода. Сентябрь 2022 года.
- ^ «База данных символов Unicode» . Консорциум Юникода . Получено 2016-08-09 .
- ^ Фрейтаг, Асмус; МакГоуэн, Рик; Уистлер, Кен. «Техническая примечание Unicode #27 - известные аномалии в именах символов Unicode» . Консорциум Unicode.
- ^ Не официальный представитель Unicode Glyph, а просто представительный глиф. Чтобы увидеть официальный представитель Unicode Glyph, см. Кодовые диаграммы .
- ^ "Код символов" . Консорциум Юникода . Получено 2016-08-09 .
- ^ «UAX #44: база данных символов Unicode» . Общие значения категории . Консорциум Юникода. 2014-06-05 . Получено 2016-08-09 .
- ^ Дэвис, Марк; Янку, ЛоренțIU; Уистлер, Кен. «Таблица 9. Таблица собственности § proplist.txt» . Стандартное приложение Unicode #44 - База данных символов Unicode . Консорциум Unicode.
- ^ «Утилиты Unicode: индекс свойств символа» . Консорциум Юникода . Получено 2015-06-09 .
Внешние ссылки
[ редактировать ]- Консорциум Unicode
- decodeunicode.org unicode wiki со всеми графическими символами 98884 Unicode 5.0 в виде GIF, полный текстовый поиск
- Символы Unicode по собственности