Стьюдента t -тест
Стьюдента T -критерий — это статистический тест, используемый для проверки того, является ли разница между ответами двух групп статистически значимой или нет. Это любая проверка статистической гипотезы , в которой статистика теста соответствует Стьюдента t -распределению при нулевой гипотезе . Чаще всего он применяется, когда статистика теста следовала бы нормальному распределению , если бы значение члена масштабирования в статистике теста было известно (обычно член масштабирования неизвестен и, следовательно, является неприятным параметром ). Когда коэффициент масштабирования оценивается на основе данных распределению Стьюдента , статистика теста — при определенных условиях — соответствует t- . - теста Наиболее распространенное применение t — проверить, существенно ли различаются средние значения двух совокупностей. Во многих случаях Z-тест дает результаты, очень похожие на t -тест, поскольку последний сходится к первому по мере увеличения размера набора данных.
История
[ редактировать ]
Термин « t -статистика» является сокращением от «статистика проверки гипотез». [1] В статистике t -распределение было впервые получено как апостериорное распределение в 1876 году Гельмертом. [2] [3] [4] и Люрот . [5] [6] [7] - распределение t также появилось в более общей форме как распределение Пирсона типа IV в статье Карла Пирсона 1895 года. [8] Однако t -распределение, также известное как Стьюдента t -распределение , получило свое название от Уильяма Сили Госсета , который впервые опубликовал его на английском языке в 1908 году в научном журнале « Биометрика» под псевдонимом «Студент». [9] [10] потому что его работодатель предпочитал, чтобы сотрудники использовали псевдонимы при публикации научных статей. [11] Госсет работал на пивоварне Guinness Brewery в Дублине , Ирландия , и интересовался проблемами небольших образцов — например, химическими свойствами ячменя при небольших размерах образцов. Следовательно, вторая версия этимологии термина «Студент» заключается в том, что компания Guinness не хотела, чтобы их конкуренты знали, что они используют t -тест для определения качества сырья. Хотя термин «Студент» был написан в честь Уильяма Госсета, на самом деле именно благодаря работе Рональда Фишера это распределение стало широко известно как «распределение Стьюдента». [12] -тест Стьюдента и « Т ».
Госсет разработал t -тест как экономичный способ контроля качества стаута . Работа по t -тесту была представлена и принята в журнал «Биометрика» и опубликована в 1908 году. [9]
В книге «Гиннесс» существовала политика, позволяющая техническому персоналу отправляться на учебу (так называемый «учебный отпуск»), которую Госсет использовал в течение первых двух семестров 1906–1907 учебного года в профессора Карла Пирсона биометрической лаборатории в Университетском колледже Лондона . [13] Личность Госсета тогда была известна коллегам-статистикам и главному редактору Карлу Пирсону. [14]
Использование
[ редактировать ]
Одновыборочный t -критерий
[ редактировать ]Одновыборочный Стьюдента t -критерий — это тест местоположения , позволяющий определить, имеет ли среднее значение генеральной совокупности значение, указанное в нулевой гипотезе . При проверке нулевой гипотезы о том, что среднее значение совокупности равно заданному значению μ 0 , используется статистика

где — выборочное среднее, s — стандартное отклонение выборки , а n — размер выборки. В этом тесте используются степени свободы n − 1 . Хотя родительская популяция не обязательно должна быть распределена нормально, распределение выборочной совокупности означает предполагается нормальным.

По центральной предельной теореме , если наблюдения независимы и существует второй момент, то будет примерно нормально .


Двухвыборочные t -критерии
[ редактировать ]

Проверка двух выборок нулевой гипотезы с использованием , при которой средние значения двух популяций равны. Все такие тесты обычно называются Стьюдента t -критериями , хотя, строго говоря, это название следует использовать только в том случае, если дисперсии двух совокупностей также предполагаются равными; форму теста, используемого при отказе от этого предположения, иногда называют Уэлча t -тестом . Эти тесты часто называют -критериями непарных или независимых выборок t , поскольку они обычно применяются, когда статистические единицы, лежащие в основе двух сравниваемых выборок, не перекрываются. [15]
Двухвыборочные t -критерии для определения разницы средних включают независимые выборки (непарные выборки) или парные выборки . Парные t -тесты являются формой блокировки и имеют большую мощность (вероятность избежать ошибки типа II, также известной как ложноотрицательный результат), чем непарные тесты, когда парные единицы схожи с точки зрения «факторов шума» (см. искажающие факторы ). которые не зависят от принадлежности к двум сравниваемым группам. [16] В другом контексте парные t -тесты можно использовать для уменьшения влияния мешающих факторов в обсервационном исследовании .
Независимые (неспарные) выборки
[ редактировать ]-критерий независимых выборок t используется, когда получаются два отдельных набора независимых и одинаково распределенных выборок и сравнивается одна переменная из каждой из двух совокупностей. Например, предположим, что мы оцениваем эффект медицинского лечения и включаем 100 субъектов в наше исследование, затем случайным образом распределяем 50 субъектов в группу лечения и 50 субъектов в контрольную группу. В этом случае у нас есть две независимые выборки, и мы будем использовать непарную форму t -критерия.
Парные образцы
[ редактировать ]Парные выборки t -тестов обычно состоят из выборки совпадающих пар схожих единиц или одной группы единиц, которая была протестирована дважды ( t -критерий «повторяющихся измерений»).
Типичным примером t -теста с повторными измерениями может служить случай, когда субъектов проверяют перед лечением, скажем, на высокое кровяное давление, и тех же самых субъектов проверяют снова после лечения лекарствами, снижающими кровяное давление. Сравнивая количество одних и тех же пациентов до и после лечения, мы эффективно используем каждого пациента в качестве собственного контроля. Таким образом, правильное отклонение нулевой гипотезы (здесь: отсутствие разницы в результате лечения) может стать гораздо более вероятным, а статистическая мощность увеличится просто потому, что случайные различия между пациентами теперь устранены. Однако за увеличение статистической мощности приходится платить: требуется больше тестов, причем каждого испытуемого приходится тестировать дважды. Поскольку половина выборки теперь зависит от другой половины, парная версия t -критерия Стьюдента имеет только n / 2 − 1 степени свободы (где n — общее количество наблюдений). Пары становятся отдельными тестовыми единицами, и для достижения того же числа степеней свободы образец необходимо удвоить. Обычно существует n - 1 степеней свободы (где n — общее количество наблюдений). [17]
-критерий для парных выборок, T основанный на «выборке совпадающих пар», получается на основе непарной выборки, которая впоследствии используется для формирования парной выборки с использованием дополнительных переменных, которые измерялись вместе с интересующей переменной. [18] Сопоставление осуществляется путем выявления пар значений, состоящих из одного наблюдения из каждой из двух выборок, где пара аналогична по другим измеряемым переменным. Этот подход иногда используется в наблюдательных исследованиях для уменьшения или устранения влияния мешающих факторов.
-критерии парных выборок t часто называют « t -критериями зависимых выборок».
Предположения
[ редактировать ][ сомнительно – обсудить ]
Большинство тестовых статистических данных имеют форму t = Z / s , где Z и s — функции данных.
Z может быть чувствителен к альтернативной гипотезе (т. е. его величина имеет тенденцию быть больше, когда альтернативная гипотеза верна), тогда как s является параметром масштабирования распределение t , который позволяет определить .
Например, в одновыборочном t -тесте

где — выборочное среднее из выборки X 1 , X 2 , …, X n размера n , s — стандартная ошибка среднего значения , — оценка стандартного отклонения генеральной совокупности, а μ — среднее генеральное значение .


Предположения, лежащие в основе t -теста в простейшей форме, приведенной выше, заключаются в следующем:
- X соответствует нормальному распределению со средним значением µ и дисперсией σ 2 / н .
- с 2 ( п - 1)/ п 2 следует за х 2 распределение с n - 1 степенями свободы . Это предположение выполняется, когда наблюдения, используемые для оценки s 2 происходят из нормального распределения (и iid для каждой группы).
- Z и s независимы .
В t -тесте, сравнивающем средние значения двух независимых выборок, должны соблюдаться следующие допущения:
- Средние значения двух сравниваемых популяций должны соответствовать нормальному распределению . При слабых предположениях это следует в больших выборках из центральной предельной теоремы , даже когда распределение наблюдений в каждой группе ненормально. [19]
- -критерия Стьюдента При использовании исходного определения t две сравниваемые популяции должны иметь одинаковую дисперсию (проверяемую с помощью F -критерия , теста Левена , теста Бартлетта или теста Брауна-Форсайта ; или оцениваемую графически с использованием графика Q-Q). ). Если размеры выборок в двух сравниваемых группах равны, исходный t -критерий Стьюдента очень устойчив к наличию неравных дисперсий. [20] Уэлча t -критерий нечувствителен к равенству дисперсий независимо от того, одинаковы ли размеры выборки.
- Данные, используемые для проведения теста, должны быть выбраны независимо от двух сравниваемых популяций или быть полностью парными. Как правило, это невозможно проверить на основе данных, но если известно, что данные являются зависимыми (например, в сочетании с дизайном теста), необходимо применить зависимый тест. Для частично парных данных классические независимые t -критерии могут давать неверные результаты, поскольку статистика теста может не соответствовать t- распределению, тогда как зависимый t -критерий неоптимален, поскольку он отбрасывает непарные данные. [21]
Большинство двухвыборочных t -тестов устойчивы ко всем отклонениям от предположений, кроме больших. [22]
Для точности - критерий t и Z -критерий требуют нормальности выборочных средних, а t -критерий дополнительно требует, чтобы выборочная дисперсия соответствовала масштабированному χ 2 распределение и чтобы выборочное среднее и выборочная дисперсия были статистически независимыми . Нормальность отдельных значений данных не требуется, если эти условия выполняются. Согласно центральной предельной теореме выборочные средние выборки умеренно больших размеров часто хорошо аппроксимируются нормальным распределением, даже если данные не имеют нормального распределения. Однако размер выборки, необходимый для приближения выборочных средних к нормальному состоянию, зависит от асимметрии распределения исходных данных. Выборка может варьироваться от 30 до 100 и более значений в зависимости от асимметрии. [23] [24] Ф
Для ненормальных данных распределение выборочной дисперсии может существенно отклоняться от χ 2 распределение.
Однако если размер выборки велик, теорема Слуцкого предполагает, что распределение выборочной дисперсии мало влияет на распределение тестовой статистики. То есть размер выборки увеличивается:

- согласно центральной предельной теореме ,
- по закону больших чисел ,
- .



Расчеты
[ редактировать ]явные выражения, которые можно использовать для проведения различных t Ниже приведены формула для тестовой статистики, которая либо точно соответствует, либо близко приближается к t -тестов. В каждом случае дается соответствующие степени свободы -распределению при нулевой гипотезе. Кроме того, в каждом случае даны . Каждую из этих статистических данных можно использовать для проведения одностороннего или двустороннего теста .
После t определения значения p и степеней свободы значение можно найти с помощью Стьюдента таблицы значений из t -распределения . Если рассчитанное значение p ниже порога, выбранного для статистической значимости (обычно уровень 0,10, 0,05 или 0,01), то нулевая гипотеза отклоняется в пользу альтернативной гипотезы.
Наклон линии регрессии
[ редактировать ]Предположим, что кто-то соответствует модели

где x известен, α и β неизвестны, ε — нормально распределенная случайная величина со средним значением 0 и неизвестной дисперсией σ. 2 , а Y — интересующий результат. Мы хотим проверить нулевую гипотезу о том, что наклон β равен некоторому заданному значению β 0 (часто принимается равным 0, и в этом случае нулевая гипотеза заключается в том, что x и y не коррелируют).
Позволять

Затем

имеет t -распределение с n - 2 степенями свободы, если нулевая гипотеза верна. Стандартная ошибка коэффициента наклона :

можно записать через остатки. Позволять

Тогда t- оценка определяется выражением

Другой способ определить t - показатель :

где r – коэффициент корреляции Пирсона .
Показатель t , перехват можно определить по показателю t , наклон :

где с х 2 — выборочная дисперсия.
Независимый двухвыборочный t -критерий
[ редактировать ]Равные размеры выборки и дисперсия
[ редактировать ]Учитывая две группы (1, 2), этот тест применим только в том случае, если:
- два размера выборки равны,
- можно предположить, что оба распределения имеют одинаковую дисперсию.
Нарушения этих предположений обсуждаются ниже.
Статистику t , позволяющую проверить, различны ли средние значения, можно рассчитать следующим образом:

где

Здесь s p — объединенное стандартное отклонение для n = n 1 = n 2 , а s 2
Х 1 и с 2
X 2 являются несмещенными оценками дисперсии генеральной совокупности. Знаменатель t — это стандартная ошибка разницы между двумя средними значениями.
Для проверки значимости степени свободы для этого теста составляют 2 n − 2 , где n — размер выборки.
Равные или неравные размеры выборки, схожие отклонения ( 1 / 2 < s X 1 / s X 2 < 2)
[ редактировать ]Этот тест используется только тогда, когда можно предположить, что два распределения имеют одинаковую дисперсию (когда это предположение нарушается, см. ниже). Предыдущие формулы являются частным случаем приведенных ниже формул. Они восстанавливаются, когда обе выборки имеют одинаковый размер: n = n 1 = n 2 .
Статистику t , позволяющую проверить, различны ли средние значения, можно рассчитать следующим образом:

где

— это объединенное стандартное отклонение двух выборок: оно определяется таким образом, что его квадрат является несмещенной оценкой общей дисперсии, независимо от того, одинаковы ли средние значения генеральной совокупности. В этих формулах n i − 1 — это количество степеней свободы для каждой группы, а общий размер выборки минус два (то есть n 1 + n 2 — 2 ) — это общее количество степеней свободы, которое используется в тестировании значимости.
Равные или неравные размеры выборки, неравные дисперсии ( s X 1 > 2 s X 2 или s X 2 > 2 s X 1 )
[ редактировать ]-критерий Уэлча Этот критерий, также известный как t , используется только в том случае, когда две генеральные дисперсии не предполагаются равными (два размера выборки могут быть равными, а могут и не быть равными) и, следовательно, должны оцениваться отдельно. Статистика t , позволяющая проверить, различны ли средние значения совокупности, рассчитывается как

где

Здесь и там 2 — это несмещенная оценка дисперсии = каждой из двух выборок с n i количеством участников в группе i ( i = 1 или 2). В этом случае не является объединенной дисперсией. Для использования при проверке значимости распределение статистики теста аппроксимируется как обычное t -распределение Стьюдента со степенями свободы, рассчитанными по формуле


Это известно как уравнение Уэлча-Саттертуэйта . Истинное распределение тестовой статистики на самом деле зависит (слегка) от двух неизвестных генеральных дисперсий (см. проблему Беренса-Фишера ).
Точный метод для неравных дисперсий и размеров выборки
[ редактировать ]Тест [25] имеет дело со знаменитой проблемой Беренса-Фишера , то есть сравнением разницы между средними значениями двух нормально распределенных популяций, когда дисперсии двух популяций не предполагаются равными, на основе двух независимых выборок.
Тест разработан как точный тест , который учитывает неравные размеры выборок и неравные дисперсии двух совокупностей. Это свойство по-прежнему сохраняется даже при очень малых и несбалансированных размерах выборки (например, ).

Статистические данные, позволяющие проверить, различны ли средние значения, можно рассчитать следующим образом:
Позволять и быть выборочными векторами iid ( ) от и отдельно.
![{\displaystyle X=[X_{1},X_{2},\ldots,X_{m}]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a0f37f25b326e4b6229a7f0be5283ace07d1a97f)
![{\displaystyle Y=[Y_{1},Y_{2},\ldots ,Y_{n}]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a81b49d1f74f1a3c22759407966c63524eac1d2e)



Позволять быть ортогональная матрица, все элементы первой строки которой являются , аналогично, пусть быть первыми n строками ортогональная матрица (все элементы первой строки которой являются ).






Затем — n-мерный нормальный случайный вектор.


Из приведенного выше распределения мы видим, что





Зависимый t -критерий для парных выборок
[ редактировать ]Этот тест используется, когда выборки являются зависимыми; то есть, когда имеется только один образец, который был протестирован дважды (повторяющиеся измерения), или когда есть два образца, которые были сопоставлены или «спарены». Это пример теста парных разностей . статистика t- рассчитывается как

где и — среднее и стандартное отклонение разностей между всеми парами. Пары представляют собой, например, баллы одного человека до и после теста, или пары людей, объединенных в значимые группы (например, взятые из одной семьи или возрастной группы: см. таблицу). Константа µ 0 равна нулю, если мы хотим проверить, существенно ли отличается среднее значение разницы. Используемая степень свободы равна n − 1 , где n представляет количество пар.


Пример подобранных пар Пара Имя Возраст Тест 1 Джон 35 250 1 Джейн 36 340 2 Джимми 22 460 2 Джесси 21 200 Пример повторных измерений Число Имя Тест 1 Тест 2 1 Майк 35% 67% 2 Мелани 50% 46% 3 Мелисса 90% 86% 4 Митчелл 78% 91% Работающие примеры
[ редактировать ] Возможно, в этой статье потребуется краткое изложение соответствующей основной статьи в лучшем качестве .
Возможно, в этой статье потребуется краткое изложение соответствующей основной статьи в лучшем качестве .Пусть A 1 обозначает набор, полученный путем составления случайной выборки из шести измерений:
и пусть A 2 обозначает второй набор, полученный аналогично:
Это может быть, например, вес винтов, изготовленных на двух разных станках.
Мы проведем проверку нулевой гипотезы о том, что средние значения популяций, из которых были взяты две выборки, равны.
Разница между двумя выборочными средними значениями, каждое из которых обозначается X i , которая появляется в числителе для всех рассмотренных выше подходов к двухвыборочному тестированию, равна
выборки Стандартные отклонения для двух образцов составляют примерно 0,05 и 0,11 соответственно. Для таких небольших выборок проверка равенства между двумя генеральными дисперсиями не будет очень эффективной. Поскольку размеры выборки равны, две формы двухвыборочного t -теста в этом примере будут работать одинаково.
Неравные отклонения
[ редактировать ]Если следовать подходу для неравных дисперсий (обсужденному выше), результаты будут следующими:
и степени свободы
-значение двустороннего теста Статистика теста составляет примерно 1,959, что дает p 0,09077.
Равные отклонения
[ редактировать ]Если следовать подходу равных дисперсий (обсужденному выше), результаты будут следующими:
и степени свободы
Статистика теста приблизительно равна 1,959, что дает двустороннее значение p , равное 0,07857.
Связанные статистические тесты
[ редактировать ]Альтернативы t -тесту для проблем с местоположением
[ редактировать ]T - тест обеспечивает точный тест на равенство средних значений двух нормальных популяций с неизвестными, но равными дисперсиями. ( Уэлча Т -критерий является почти точным тестом для случая, когда данные нормальны, но дисперсии могут различаться.) Для умеренно больших выборок и одностороннего критерия Ст -критерий относительно устойчив к умеренным нарушениям предположения о нормальности. [26] В достаточно больших выборках t -тест асимптотически приближается к z -тесту и становится устойчивым даже к большим отклонениям от нормальности. [19]
Если данные существенно ненормальны и размер выборки мал, t -критерий может дать ошибочные результаты. См. Тест местоположения для распределений смеси гауссовского масштаба, чтобы узнать о некоторой теории, связанной с одним конкретным семейством ненормальных распределений.
Когда предположение о нормальности не выполняется, непараметрическая альтернатива t -критерию может иметь лучшую статистическую мощность . Однако, когда данные не являются нормальными и имеют разные дисперсии между группами, t -критерий может иметь лучший контроль ошибок 1-го типа , чем некоторые непараметрические альтернативы. [27] Кроме того, непараметрические методы, такие как U-критерий Манна-Уитни , обсуждаемый ниже, обычно не проверяют разницу средних, поэтому их следует использовать с осторожностью, если разница средних представляет основной научный интерес. [19] Например, U-критерий Манна-Уитни сохранит ошибку типа 1 на желаемом уровне альфа, если обе группы имеют одинаковое распределение. Он также сможет обнаружить альтернативу, согласно которой группа B имеет то же распределение, что и A, но после некоторого сдвига на константу (в этом случае действительно будет разница в средних значениях двух групп). Однако могут быть случаи, когда группы A и B будут иметь разные распределения, но с одинаковыми средними значениями (например, два распределения, одно с положительной асимметрией, а другое с отрицательной асимметрией, но сдвинутыми так, чтобы иметь одинаковые средние значения). В таких случаях MW может иметь больше власти, чем альфа-уровень, при отклонении нулевой гипотезы, но приписывать интерпретацию разницы в средних значениях такому результату было бы неправильно.
При наличии выброса - критерий t не является устойчивым. Например, для двух независимых выборок, когда распределения данных асимметричны (то есть распределения перекошены ) или распределения имеют большие хвосты, тогда критерий суммы рангов Уилкоксона (также известный как Манна-Уитни U- критерий ) может иметь три в четыре раза выше мощности, чем t -тест. [26] [28] [29] Непараметрическим аналогом t -критерия для парных выборок является критерий знакового ранга Уилкоксона для парных выборок. Обсуждение выбора между t -тестом и непараметрическими альтернативами см. в Lumley, et al. (2002). [19]
Односторонний дисперсионный анализ (ANOVA) обобщает двухвыборочный t -критерий, когда данные принадлежат более чем двум группам.
План, включающий как парные, так и независимые наблюдения.
[ редактировать ]Когда в двухпланах выборки присутствуют как парные наблюдения, так и независимые наблюдения, предполагая, что данные отсутствуют полностью случайным образом (MCAR), парные наблюдения или независимые наблюдения могут быть отброшены, чтобы продолжить стандартные тесты, описанные выше. В качестве альтернативы, используя все доступные данные, предполагая нормальность и MCAR, обобщенный t -критерий частично перекрывающихся выборок. можно использовать [30]
Многовариантное тестирование
[ редактировать ]статистики Стьюдента Обобщение t- , называемое Хотеллинга t -квадратной статистикой , позволяет проверять гипотезы по нескольким (часто коррелирующим) показателям в пределах одной и той же выборки. Например, исследователь может подвергнуть ряд субъектов личностному тесту, состоящему из нескольких шкал личности (например, Миннесотский многофазный личностный опросник ). Поскольку показатели этого типа обычно положительно коррелируют, не рекомендуется проводить отдельные одномерные t -тесты для проверки гипотез, так как они пренебрегают ковариацией между показателями и увеличивают вероятность ложного отклонения хотя бы одной гипотезы ( ошибка I типа ). В этом случае для проверки гипотез предпочтительнее использовать один многомерный тест. Одним из них является метод Фишера для объединения нескольких тестов с уменьшением альфа для положительной корреляции между тестами. Другой - Hotelling's T. 2 статистика следует за T 2 распределение. Однако на практике распределение используется редко, поскольку табличные значения T 2 их трудно найти. Обычно Т 2 вместо этого преобразуется в F. статистику
Для одновыборочного многомерного теста гипотеза состоит в том, что средний вектор ( µ ) равен заданному вектору ( µ 0 ). Тестовая статистика представляет собой Хотеллинга . t 2 :
где n — размер выборки, x — вектор средних значений столбца, а S — m × m выборочная ковариационная матрица размера .
) двух Для многомерного теста с двумя выборками гипотеза состоит в том, что средние векторы ( 1 выборок равны , 2 . Тестовая статистика представляет собой двухвыборочный t Хотеллинга. 2 :
Двухвыборочный t -критерий представляет собой частный случай простой линейной регрессии.
[ редактировать ]Двухвыборочный t -критерий представляет собой частный случай простой линейной регрессии , как показано в следующем примере.
В клиническом исследовании принимают участие 6 пациентов, принимавших препарат или плацебо. Три (3) пациента получают 0 единиц препарата (группа плацебо). Три (3) пациента получают 1 единицу препарата (группа активного лечения). В конце лечения исследователи измеряют изменение по сравнению с исходным уровнем количества слов, которые каждый пациент может вспомнить, с помощью теста памяти.

Ниже представлена таблица запоминаемости слов пациентами и значений доз препарата.
Пациент препарат.доза слово.отзыв 1 0 1 2 0 2 3 0 3 4 1 5 5 1 6 6 1 7 Данные и код предоставлены для анализа с использованием языка программирования R с расширением
t.testиlmфункции для t-теста и линейной регрессии. Вот те же (вымышленные) данные, сгенерированные в R.> word.recall.data=data.frame(drug.dose=c(0,0,0,1,1,1), word.recall=c(1,2,3,5,6,7))
Выполните t -тест. Обратите внимание, что предположение о равной дисперсии
var.equal=T, необходимо, чтобы анализ был точно эквивалентен простой линейной регрессии.> with(word.recall.data, t.test(word.recall~drug.dose, var.equal=T))
Запуск кода R дает следующие результаты.
- Среднее слово «запоминание» в группе «0 препарат — доза» равно 2.
- Среднее слово.вспоминание в группе 1 препарат.доза составляет 6.
- Разница между группами лечения по среднему слову «припоминание» составляет 6 – 2 = 4.
- Разница в запоминаемости слов между дозами препарата значительна (р=0,00805).
Выполните линейную регрессию тех же данных. Расчеты могут быть выполнены с использованием функции R
lm()для линейной модели.> word.recall.data.lm = lm(word.recall~drug.dose, data=word.recall.data) > summary(word.recall.data.lm)
Линейная регрессия предоставляет таблицу коэффициентов и значений p.
Коэффициент Оценивать Стандарт. Ошибка значение t P-значение Перехват 2 0.5774 3.464 0.02572 препарат.доза 4 0.8165 4.899 0.000805 Таблица коэффициентов дает следующие результаты.
- Оценочное значение 2 для перехвата представляет собой среднее значение отзыва слова, когда доза препарата равна 0.
- Оценочное значение 4 для дозы препарата указывает на то, что при изменении дозы препарата на 1 единицу (от 0 до 1) происходит изменение среднего запоминания слова на 4 единицы (от 2 до 6). Это наклон линии, соединяющей два групповых средства.
- Значение p, при котором наклон 4 отличается от 0, равно p = 0,00805.
Коэффициенты линейной регрессии определяют наклон и точку пересечения линии, соединяющей средние значения двух групп, как показано на графике. Пересечение — 2, наклон — 4.
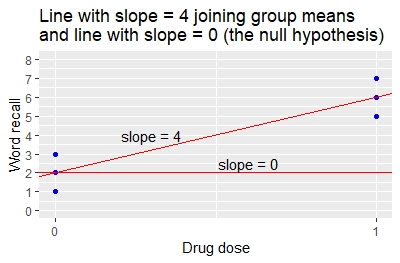
Сравните результат линейной регрессии с результатом t -теста.
- Согласно t -критерию, разница между средними значениями группы составляет 6-2=4.
- Судя по регрессии, наклон также равен 4, что указывает на то, что изменение дозы лекарства на 1 единицу (от 0 до 1) приводит к изменению среднего запоминания слов на 4 единицы (от 2 до 6).
- Значение для t -теста p для разницы средних значений и значение p для регрессии для наклона равны 0,00805. Методы дают одинаковые результаты.
Этот пример показывает, что в частном случае простой линейной регрессии, когда существует одна переменная x со значениями 0 и 1, t -критерий дает те же результаты, что и линейная регрессия. Связь также можно показать алгебраически.
Признание этой взаимосвязи между t -тестом и линейной регрессией облегчает использование множественной линейной регрессии и многофакторного дисперсионного анализа . Эти альтернативы t -тестам позволяют включать дополнительные объясняющие переменные , связанные с ответом. Включение таких дополнительных объясняющих переменных с использованием регрессии или ановы уменьшает необъяснимую дисперсию и обычно дает большую возможность обнаружить различия, чем двухвыборочные t -критерии.
Реализации программного обеспечения
[ редактировать ]Многие программы для работы с электронными таблицами и статистические пакеты, такие как QtiPlot , LibreOffice Calc , Microsoft Excel , SAS , SPSS , Stata , DAP , gretl , R , Python , PSPP , Wolfram Mathematica , MATLAB и Minitab -теста Стьюдента , включают реализации t .
Язык/Программа Функция Примечания Microsoft Excel до 2010 г. TTEST(array1, array2, tails, type)См . [1] Microsoft Excel 2010 и более поздние версии T.TEST(array1, array2, tails, type)См . [2] Apple Числа TTEST(sample-1-values, sample-2-values, tails, test-type)См . [3] LibreOffice Calc TTEST(Data1; Data2; Mode; Type)См . [4] Google Таблицы TTEST(range1, range2, tails, type)См . [5] Питон scipy.stats.ttest_ind(a, b, equal_var=True)См . [6] МАТЛАБ ttest(data1, data2)См . [7] Математика TTest[{data1,data2}]См . [8] Р t.test(data1, data2, var.equal=TRUE)См . [9] САС PROC TTESTСм . [10] Ява tTest(sample1, sample2)См . [11] Юлия EqualVarianceTTest(sample1, sample2)См . [12] Был ttest data1 == data2См . [13] См. также
[ редактировать ]- Модель условного изменения
- F -тест - проверка статистической гипотезы, в основном с использованием нескольких ограничений.
- Нецентральное t -распределение в анализе мощности – Распределение вероятностей
- Стьюдента t -статистика — соотношение в статистике.
- Z -тест – Статистический тест
- Манна – Уитни U -критерий - непараметрический тест нулевой гипотезы.
- Поправка Шидака для t -критерия – Статистический метод
- Уэлча T -критерий - Статистический тест того, имеют ли две популяции равные средние значения.
- Дисперсионный анализ – Сбор статистических моделей (ANOVA)
Ссылки
[ редактировать ]- ^ Микробиом в здоровье и болезни . Академическая пресса. 2020-05-29. п. 397. ИСБН 978-0-12-820001-8 .
- ^ Сабо, Иштван (2003). «Системы, состоящие из конечного числа твердых тел». Введение в техническую механику (на немецком языке). Шпрингер Берлин Гейдельберг. стр. 196–199. doi : 10.1007/978-3-642-61925-0_16 (неактивен 28 июня 2024 г.). ISBN 978-3-540-13293-6 .
{{cite book}}: CS1 maint: DOI неактивен по состоянию на июнь 2024 г. ( ссылка ) - ^ Шливич, Б. (октябрь 1937 г.). «Исследования анастомотического канала между чревной и верхней брыжеечной артериями и связанные с этим вопросы». Журнал анатомии и истории эволюции (на немецком языке). 107 (6): 709–737. дои : 10.1007/bf02118337 . ISSN 0340-2061 . S2CID 27311567 .
- ^ Гельмерт (1876 г.). «Точность формулы Петерса для расчета вероятной ошибки наблюдения прямых наблюдений равной точности» . Астрономические новости (на немецком языке). 88 (8–9): 113–131. Бибкод : 1876AN.....88..113H . дои : 10.1002/asna.18760880802 .
- ^ Люрот, Дж. (1876). «Сравнение двух значений вероятной погрешности» . Астрономические новости (на немецком языке). 87 (14): 209–220. Бибкод : 1876AN.....87..209L . дои : 10.1002/asna.18760871402 .
- ^ Пфанзагль, Дж. (1996). «Исследования по истории вероятности и статистике XLIV. Предшественник t -распределения». Биометрика . 83 (4): 891–898. дои : 10.1093/biomet/83.4.891 . МР 1766040 .
- ^ Шейнин, Оскар (1995). «Работа Гельмерта по теории ошибок». Архив истории точных наук . 49 (1): 73–104. дои : 10.1007/BF00374700 . ISSN 0003-9519 . S2CID 121241599 .
- ^ Пирсон, Карл (1895). «X. Вклад в математическую теорию эволюции. — II. Асимметрия в однородном материале» . Философские труды Лондонского королевского общества А. 186 : 343–414. Бибкод : 1895RSPTA.186..343P . дои : 10.1098/rsta.1895.0010 .
- ^ Jump up to: а б Студент (1908). «Вероятная ошибка среднего» (PDF) . Биометрика . 6 (1): 1–25. дои : 10.1093/биомет/6.1.1 . hdl : 10338.dmlcz/143545 . Проверено 24 июля 2016 г.
- ^ «Т-таблица» .
- ^ Вендл, Майкл К. (2016). «Псевдонимная слава». Наука . 351 (6280): 1406. doi : 10.1126/science.351.6280.1406 . ПМИД 27013722 .
- ^ Уолпол, Рональд Э. (2006). Вероятность и статистика для инженеров и ученых . Майерс, Х. Рэймонд (7-е изд.). Нью-Дели: Пирсон. ISBN 81-7758-404-9 . OCLC 818811849 .
- ^ Раджу, Теннесси (2005). «Уильям Сили Госсет и Уильям А. Сильверман: два« студента науки »». Педиатрия . 116 (3): 732–735. дои : 10.1542/пед.2005-1134 . ПМИД 16140715 . S2CID 32745754 .
- ^ Додж, Ядола (2008). Краткая энциклопедия статистики . Springer Science & Business Media. стр. 234–235. ISBN 978-0-387-31742-7 .
- ^ Фадем, Барбара (2008). Высокопроизводительная поведенческая наука . Высокодоходная серия. Хагерстаун, Мэриленд: Липпинкотт Уильямс и Уилкинс. ISBN 9781451130300 .
- ^ Райс, Джон А. (2006). Математическая статистика и анализ данных (3-е изд.). Даксбери Продвинутый. [ ISBN отсутствует ]
- ^ Вайсштейн, Эрик. -Распределение Стьюдента « Т » . mathworld.wolfram.com .
- ^ Дэвид, HA; Ганнинк, Джейсон Л. (1997). «Парный t- тест при искусственном спаривании». Американский статистик . 51 (1): 9–12. дои : 10.2307/2684684 . JSTOR 2684684 .
- ^ Jump up to: а б с д Ламли, Томас; Дир, Паула ; Эмерсон, Скотт; Чен, Лу (май 2002 г.). «Важность предположения о нормальности в больших наборах данных общественного здравоохранения» . Ежегодный обзор общественного здравоохранения . 23 (1): 151–169. doi : 10.1146/annurev.publhealth.23.100901.140546 . ISSN 0163-7525 . ПМИД 11910059 .
- ^ Марковски, Кэрол А.; Марковски, Эдвард П. (1990). «Условия эффективности предварительного дисперсионного теста». Американский статистик . 44 (4): 322–326. дои : 10.2307/2684360 . JSTOR 2684360 .
- ^ Го, Бэйбэй; Юань, Ин (2017). «Сравнительный обзор методов сравнения средних с использованием частично парных данных». Статистические методы в медицинских исследованиях . 26 (3): 1323–1340. дои : 10.1177/0962280215577111 . ПМИД 25834090 . S2CID 46598415 .
- ^ Бланд, Мартин (1995). Введение в медицинскую статистику . Издательство Оксфордского университета. п. 168. ИСБН 978-0-19-262428-4 .
- ^ «Центральная предельная теорема и предположение нормальности > Нормальность > Непрерывные распределения > Распределение > Статистическое справочное руководство | Документация Analyse-it® 6.15» . analyse-it.com . Проверено 17 мая 2024 г.
- ^ ДЕМИР, Сулейман (26 июня 2022 г.). «Сравнение тестов на нормальность по размерам выборки при различных коэффициентах асимметрии и эксцесса» . Международный журнал инструментов оценки в образовании . 9 (2): 397–409. дои : 10.21449/ijate.1101295 . ISSN 2148-7456 .
- ^ Ван, Чанг; Цзя, Цзиньчжу (2022). «Те-тест: новый неасимптотический Т-тест для задач Беренса-Фишера». arXiv : 2210.16473 [ math.ST ].
- ^ Jump up to: а б Савиловский, Шломо С.; Блэр, Р. Клиффорд (1992). «Более реалистичный взгляд на устойчивость и свойства ошибок типа II t -теста на отклонения от нормальности населения». Психологический вестник . 111 (2): 352–360. дои : 10.1037/0033-2909.111.2.352 .
- ^ Циммерман, Дональд В. (январь 1998 г.). «Аннулирование параметрических и непараметрических статистических тестов одновременным нарушением двух предположений». Журнал экспериментального образования . 67 (1): 55–68. дои : 10.1080/00220979809598344 . ISSN 0022-0973 .
- ^ Блэр, Р. Клиффорд; Хиггинс, Джеймс Дж. (1980). «Сравнение мощности статистики ранговой суммы Уилкоксона со статистикой t Стьюдента при различных ненормальных распределениях». Журнал образовательной статистики . 5 (4): 309–335. дои : 10.2307/1164905 . JSTOR 1164905 .
- ^ Фэй, Майкл П.; Прощан, Майкл А. (2010). «Уилкоксона – Манна – Уитни или t -критерий? О предположениях для проверки гипотез и множественных интерпретациях правил принятия решений» . Статистические опросы . 4 : 1–39. дои : 10.1214/09-SS051 . ПМЦ 2857732 . ПМИД 20414472 .
- ^ Деррик, Б; Тохер, Д; Уайт, П. (2017). «Как сравнить средние значения двух выборок, включающих парные наблюдения и независимые наблюдения: компаньон Деррика, Расса, Тохера и Уайта (2017)» (PDF) . Количественные методы в психологии . 13 (2): 120–126. дои : 10.20982/tqmp.13.2.p120 .
Источники
[ редактировать ]- О'Махони, Майкл (1986). Сенсорная оценка продуктов питания: статистические методы и процедуры . ЦРК Пресс . п. 487. ИСБН 0-82477337-3 .
- Пресс, Уильям Х.; Теукольский, Саул А.; Веттерлинг, Уильям Т.; Фланнери, Брайан П. (1992). Численные рецепты в C: Искусство научных вычислений . Издательство Кембриджского университета . п. 616 . ISBN 0-521-43108-5 .
Дальнейшее чтение
[ редактировать ]- Боно, К. Алан (1960). «Последствия нарушения предположений, лежащих в основе t- теста». Психологический вестник . 57 (1): 49–64. дои : 10.1037/h0041412 . ПМИД 13802482 .
- Эджелл, Стивен Э.; Полдень, Шейла М. (1984). «Влияние нарушения нормальности на t -критерий коэффициента корреляции». Психологический вестник . 95 (3): 576–583. дои : 10.1037/0033-2909.95.3.576 .
Внешние ссылки
[ редактировать ] В Викиверситете есть учебные ресурсы по t-тесту
В Викиверситете есть учебные ресурсы по t-тесту В Wikisource есть оригинальный текст, относящийся к этой статье:
В Wikisource есть оригинальный текст, относящийся к этой статье:- «Студенческий тест» . Энциклопедия математики . ЭМС Пресс . 2001 [1994].
- Трохим, Уильям М.К. « Т-тест », База знаний по методам исследования , conjoint.ly
- Лекция по эконометрике (тема: проверка гипотез) на YouTube Марка Тома
Статистическая теория Частотный вывод Оценка баллов Интервальная оценка Проверка гипотез Параметрические тесты Специальные тесты Хорошая посадка Статистика рейтингов Байесовский вывод Базы данных органов управления : Национальные










