Биостатистика
Биостатистика (также известная как биометрия ) — это раздел статистики , который применяет статистические методы к широкому кругу вопросов биологии . Он включает в себя планирование биологических экспериментов , сбор и анализ данных этих экспериментов и интерпретацию результатов.
История
[ редактировать ]Биостатистика и генетика
[ редактировать ]Биостатистическое моделирование составляет важную часть многих современных биологических теорий. Генетические исследования с самого начала использовали статистические концепции для понимания наблюдаемых экспериментальных результатов. Некоторые ученые-генетики даже внесли свой вклад в развитие статистики, разработав методы и инструменты. Грегор Мендель начал генетические исследования, изучающие закономерности генетической сегрегации в семействах гороха, и использовал статистику для объяснения собранных данных. В начале 1900-х годов, после повторного открытия работ Менделя по менделевскому наследованию, возникли пробелы в понимании между генетикой и эволюционным дарвинизмом. Фрэнсис Гальтон попытался расширить открытия Менделя человеческими данными и предложил другую модель, в которой доли наследственности, исходящие от каждого предка, составляют бесконечную серию. Он назвал это теорией « Закона наследственности ». С его идеями категорически не согласился Уильям Бейтсон , который следовал выводам Менделя о том, что генетическое наследование передается исключительно от родителей, половина от каждого из них. Это привело к бурным дебатам между биометристами, которые поддержали идеи Гальтона, поскольку Рафаэль Уэлдон , Артур Дукинфилд Дарбишир и Карл Пирсон , а также менделисты, которые поддерживали идеи Бейтсона (и Менделя), такие как Чарльз Давенпорт и Вильгельм Йохансен . Позже биометрики не смогли воспроизвести выводы Гальтона в различных экспериментах, и возобладали идеи Менделя. К 1930-м годам модели, построенные на статистических рассуждениях, помогли разрешить эти различия и создать неодарвинистский современный эволюционный синтез .
Решение этих различий также позволило определить концепцию популяционной генетики и объединить генетику и эволюцию. Все три ведущие фигуры в создании популяционной генетики и этого синтеза опирались на статистику и развивали ее использование в биологии.
- Рональд Фишер работал вместе со статистиком Бетти Аллан, разрабатывая несколько основных статистических методов в поддержку своей работы по изучению экспериментов с сельскохозяйственными культурами в Rothamsted Research , опубликованных в книгах Фишера «Статистические методы для научных работников» (1925) и «Генетическая теория естественного отбора » (1930). как научные работы Аллана. [1] Фишер внес большой вклад в генетику и статистику. Некоторые из них включают ANOVA , p-значения концепции , точный критерий Фишера и уравнение Фишера для динамики численности населения . Ему приписывают предложение «Естественный отбор - это механизм создания чрезвычайно высокой степени невероятности». [2]
- Сьюэлл Дж. Райт разработал F -статистику и методы ее расчета, определил коэффициент инбридинга .
- Дж.Б.С. Холдейна Книга «Причины эволюции » восстановила естественный отбор как главный механизм эволюции, объяснив его с точки зрения математических следствий менделевской генетики. Он также разработал теорию первобытного супа .
Эти и другие специалисты по биостатистике, биологи-математики и генетики, склонные к статистике, помогли объединить эволюционную биологию и генетику в единое, последовательное целое, которое можно было начать количественно моделировать.
Параллельно с этим общим развитием новаторская работа Д'Арси Томпсона «О росте и форме» также помогла добавить количественную дисциплину в биологические исследования.
Несмотря на фундаментальную важность и частую необходимость статистических рассуждений, среди биологов, тем не менее, могла существовать тенденция не доверять или обесценивать результаты, которые не являются качественно очевидными. В одном анекдоте рассказывается, как Томас Хант Морган запретил калькулятор Фридена на своем факультете в Калифорнийском технологическом институте , заявив: «Ну, я похож на парня, который ищет золото на берегу реки Сакраменто в 1849 году. Проявив немного ума, я могу дотянуться до земли и собирать большие самородки золота. И пока я могу это делать, я не позволю никому в моем отделе тратить скудные ресурсы на добычу россыпей ». [3]
Планирование исследований
[ редактировать ]Любое исследование в области наук о жизни призвано ответить на научный вопрос , который может у нас возникнуть. Чтобы ответить на этот вопрос с высокой уверенностью, нам нужны точные результаты. Правильное определение основной гипотезы и плана исследования уменьшит ошибки при принятии решения в понимании явления. План исследования может включать вопрос исследования, проверяемую гипотезу, план эксперимента , сбора данных методы , перспективы анализа данных и соответствующие затраты. Крайне важно проводить исследование на основе трех основных принципов экспериментальной статистики: рандомизации , репликации и локального контроля.
Вопрос исследования
[ редактировать ]Вопрос исследования определит цель исследования. Исследование будет возглавляться вопросом, поэтому оно должно быть кратким и в то же время сосредоточено на интересных и новых темах, которые могут улучшить науку и знания в этой области. Чтобы определить способ постановки научного вопроса исчерпывающий обзор литературы , может потребоваться . Таким образом, исследование может быть полезным и повысить ценность научного сообщества . [4]
Определение гипотезы
[ редактировать ]Как только цель исследования определена, можно предложить возможные ответы на вопрос исследования, превратив этот вопрос в гипотезу . Основное предложение называется нулевой гипотезой (H 0 ) и обычно основано на постоянном знании темы или очевидном возникновении явления, подтвержденном глубоким обзором литературы. Можно сказать, что это стандартный ожидаемый ответ для данных в тестируемой ситуации . В целом, HO предполагает отсутствие связи между методами лечения . С другой стороны, альтернативной гипотезой является отрицание НО . Предполагается некоторая степень связи между лечением и результатом. Тем не менее, гипотеза подтверждается исследованием вопросов и ожидаемыми и неожиданными ответами. [4]
В качестве примера рассмотрим группы схожих животных (например, мышей) с двумя разными системами питания. Вопрос исследования будет звучать так: какая диета самая лучшая? В этом случае H 0 будет заключаться в том, что между двумя диетами нет разницы в метаболизме мышей (H 0 : μ 1 = μ 2 ), а альтернативная гипотеза будет заключаться в том, что диеты оказывают различное влияние на метаболизм животных (H 1 : μ 1 ≠ мкм 2 ).
Гипотеза . определяется исследователем в соответствии с его интересами в ответе на главный вопрос Кроме того, альтернативной гипотезой может быть более одной гипотезы. Он может предполагать не только различия между наблюдаемыми параметрами, но и степень их различий ( т.е. выше или короче).
Выборка
[ редактировать ]Обычно исследование направлено на понимание влияния того или иного явления на популяцию . В биологии популяция , обитающие на определенной территории определяется как все особи данного вида в данное время. В биостатистике это понятие распространяется на множество коллекций, которые можно изучать. Хотя в биостатистике популяция — это не только особи, а совокупность одного конкретного компонента их организмов , как весь геном , или все сперматозоиды , для животных, или общая площадь листьев, например, для растения. .
Невозможно провести измерения по всем элементам популяции . По этой причине процесс выборки очень важен для статистических выводов . Выборка определяется как случайное получение репрезентативной части всей совокупности для того, чтобы сделать апостериорные выводы о совокупности. Таким образом, выборка может уловить наибольшую изменчивость среди населения. [5] Размер выборки определяется несколькими факторами, начиная с объема исследования и доступных ресурсов. В клинических исследованиях тип исследования, а именно неполноценность , эквивалентность и превосходство, является ключевым фактором при определении размера выборки . [4]
Экспериментальный дизайн
[ редактировать ]Экспериментальные планы поддерживают эти основные принципы экспериментальной статистики . Существует три основных экспериментальных плана для случайного распределения на всех участках эксперимента обработок . Это полностью рандомизированный план , рандомизированный блочный план и факторный план . В рамках эксперимента лечение можно организовать разными способами. В сельском хозяйстве правильный план эксперимента является основой хорошего исследования, и организация методов лечения в рамках исследования имеет важное значение, поскольку окружающая среда в значительной степени влияет на участки ( растения , домашний скот , микроорганизмы ). Эти основные устройства можно встретить в литературе под названиями « решетки », «неполные блоки», « расщепленный участок », «дополненные блоки» и многие другие. Все планы могут включать в себя контрольные графики , определенные исследователем, чтобы обеспечить оценку ошибки во время вывода .
В клинических исследованиях образцы влияние обычно меньше, чем в других биологических исследованиях, и в большинстве случаев окружающей среды можно контролировать или измерять. Обычно используются рандомизированные контролируемые клинические исследования , результаты которых обычно сравниваются с дизайнами наблюдательных исследований, таких как случай-контроль или когортное исследование . [6]
Сбор данных
[ редактировать ]Методы сбора данных необходимо учитывать при планировании исследований, поскольку они сильно влияют на размер выборки и план эксперимента.
Сбор данных варьируется в зависимости от типа данных. может Сбор качественных данных осуществляться с помощью структурированных вопросников или путем наблюдения, учитывая наличие или интенсивность заболевания, используя критерий оценки для классификации уровней заболеваемости. [7] Сбор количественных данных осуществляется путем измерения числовой информации с помощью инструментов.
В исследованиях в области сельского хозяйства и биологии данные об урожайности и ее компонентах можно получить с помощью метрических мер . Однако повреждения растений вредителями и болезнями определяются путем наблюдения с учетом шкалы оценок уровней повреждения. В частности, в генетических исследованиях следует учитывать современные методы сбора данных в полевых и лабораторных условиях как высокопроизводительные платформы для фенотипирования и генотипирования. Эти инструменты позволяют проводить более масштабные эксперименты, а также позволяют оценить множество графиков за меньшее время, чем метод сбора данных, основанный только на участии человека.Наконец, все собранные представляющие интерес данные должны храниться в организованном фрейме данных для дальнейшего анализа.
Анализ и интерпретация данных
[ редактировать ]Описательные инструменты
[ редактировать ]Данные могут быть представлены в виде таблиц или графических представлений, таких как линейные диаграммы, гистограммы, гистограммы, диаграммы рассеяния. Кроме того, показатели центральной тенденции и изменчивости могут быть очень полезны для описания обзора данных. Следуйте некоторым примерам:
Таблицы частот
[ редактировать ]Одним из типов таблиц является таблица частот , которая состоит из данных, расположенных в строках и столбцах, где частота — это количество вхождений или повторений данных. Частота может быть: [8]
Абсолютное : представляет количество раз, когда определенное значение появляется;

Относительный : получается путем деления абсолютной частоты на общее число;

В следующем примере мы имеем количество генов в десяти оперонах одного и того же организма.
- Гены = {2,3,3,4,5,3,3,3,3,4}
| Количество генов | Абсолютная частота | Относительная частота |
|---|---|---|
| 1 | 0 | 0 |
| 2 | 1 | 0.1 |
| 3 | 6 | 0.6 |
| 4 | 2 | 0.2 |
| 5 | 1 | 0.1 |
Линейный график
[ редактировать ]
Линейные графики представляют собой изменение значения по другому показателю, например времени. Обычно значения представлены на вертикальной оси, а изменение во времени — на горизонтальной оси. [10]
Гистограмма
[ редактировать ]Гистограмма — это график , на котором категориальные данные показаны в виде столбцов, представляющих высоту (вертикальную полосу) или ширину (горизонтальная полоса), пропорциональную представлению значений. Гистограммы предоставляют изображение, которое также можно представить в табличном формате. [10]
В примере гистограммы у нас есть уровень рождаемости в Бразилии за декабрьские месяцы с 2010 по 2016 год. [9] в декабре 2016 года отражает вспышку вируса Зика Резкое падение рождаемости в Бразилии .
Гистограммы
[ редактировать ]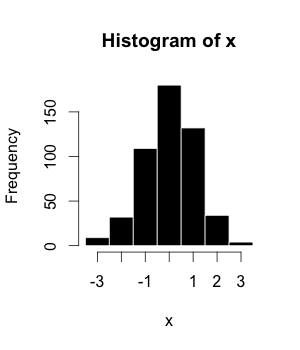
Гистограмма (или распределение частот) — это графическое представление набора данных , сведенное в таблицу и разделенное на однородные или неоднородные классы. Впервые он был представлен Карлом Пирсоном . [11]
График рассеяния
[ редактировать ]Диаграмма рассеяния — это математическая диаграмма, которая использует декартовы координаты для отображения значений набора данных. Диаграмма рассеяния показывает данные в виде набора точек, каждая из которых представляет значение одной переменной, определяющей положение на горизонтальной оси, и другой переменной на вертикальной оси. [12] Их также называют диаграммой рассеяния , диаграммой рассеяния , диаграммой рассеяния или диаграммой рассеяния . [13]
Иметь в виду
[ редактировать ]— Среднее арифметическое это сумма совокупности значений ( ) разделить на количество элементов этой коллекции ( ).



медиана
[ редактировать ]Медиана — это значение в середине набора данных.
Режим
[ редактировать ]Режим — это значение набора данных, которое появляется чаще всего. [14]
| Тип | Пример | Результат |
|---|---|---|
| Иметь в виду | ( 2 + 3 + 3 + 3 + 3 + 3 + 4 + 4 + 11 ) / 9 | 4 |
| медиана | 2, 3, 3, 3, 3 , 3, 4, 4, 11 | 3 |
| Режим | 2, 3, 3, 3, 3, 3 , 4, 4, 11 | 3 |
Коробочный сюжет
[ редактировать ]Ящичная диаграмма — это метод графического изображения групп числовых данных. Максимальные и минимальные значения представлены линиями, а межквартильный размах (IQR) представляет 25–75% данных. Выбросы могут быть изображены в виде кругов.
Коэффициенты корреляции
[ редактировать ]Хотя корреляции между двумя различными типами данных можно определить с помощью графиков, таких как диаграмма рассеяния, необходимо проверить эту информацию с помощью числовой информации. По этой причине коэффициенты корреляции необходимы . Они предоставляют числовое значение, которое отражает силу связи. [10]
Коэффициент корреляции Пирсона
[ редактировать ]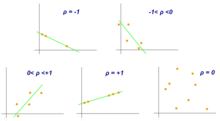
Коэффициент корреляции Пирсона является мерой связи между двумя переменными, X и Y. Этот коэффициент, обычно представленный ρ (rho) для совокупности и r для выборки, принимает значения от –1 до 1, где ρ = 1 представляет собой идеальный положительная корреляция, ρ = −1 представляет собой идеальную отрицательную корреляцию, а ρ = 0 не является линейной корреляцией. [10]
Инференциальная статистика
[ редактировать ]Используется для умозаключений [15] о неизвестной популяции, путем оценки и/или проверки гипотез. Другими словами, желательно получить параметры для описания интересующей совокупности, но поскольку данные ограничены, для их оценки необходимо использовать репрезентативную выборку. Благодаря этому можно проверить ранее определенные гипотезы и применить выводы ко всей популяции. Стандартная ошибка среднего — это мера изменчивости, которая имеет решающее значение для вывода. [5]
Проверка гипотез необходима для того, чтобы сделать выводы о группах населения, стремящихся ответить на вопросы исследования, как указано в разделе «Планирование исследований». Авторы определили четыре шага, которые необходимо установить: [5]
- Гипотеза, подлежащая проверке : как говорилось ранее, нам предстоит работать с определением нулевой гипотезы (H 0 ), которую предстоит проверить, и альтернативной гипотезы . Но они должны быть определены до реализации эксперимента.
- Уровень значимости и правило принятия решения . Правило принятия решения зависит от уровня значимости или, другими словами, приемлемой частоты ошибок (α). Легче думать, что мы определяем критическое значение , которое определяет статистическую значимость при тестовой статистики сравнении с ним . Таким образом, α также необходимо заранее определить перед экспериментом.
- Эксперимент и статистический анализ : это когда эксперимент действительно проводится в соответствии с соответствующей экспериментальной схемой , собираются данные и оцениваются наиболее подходящие статистические тесты.
- Вывод : делается, когда нулевая гипотеза отвергается или не отвергается, на основе доказательств, которые дает сравнение значений p и α. Указывается, что неспособность отвергнуть H 0 означает лишь отсутствие достаточных доказательств в поддержку ее отклонения, но не то, что эта гипотеза верна.
Доверительный интервал — это диапазон значений, который может содержать истинное значение реального параметра при определенном уровне уверенности. Первым шагом является оценка наилучшей несмещенной оценки параметра совокупности. Верхнее значение интервала получается суммой этой оценки с умножением стандартной ошибки среднего значения на уровень достоверности. Расчет нижнего значения аналогичен, но вместо суммы необходимо применить вычитание. [5]
Статистические соображения
[ редактировать ]Мощность и статистическая погрешность
[ редактировать ]При проверке гипотезы возможны два типа статистических ошибок: ошибка I рода и ошибка II рода .
- Ошибка типа I или ложноположительный результат — это неправильное отклонение истинной нулевой гипотезы.
- Ошибка типа II или ложноотрицательный результат — это неспособность отвергнуть ложную нулевую гипотезу .
Уровень значимости , обозначаемый α, представляет собой частоту ошибок типа I, и его следует выбирать перед выполнением теста. Коэффициент ошибок типа II обозначается β, а статистическая мощность теста равна 1 − β.
p-значение
[ редактировать ]Значение p — это вероятность получения результатов, столь же экстремальных, как и наблюдаемые, или даже более экстремальных, чем наблюдаемые, при условии, что нулевая гипотеза (H 0 ) верна. Ее еще называют расчетной вероятностью. Часто путают значение p с уровнем значимости (α) , но α — это заранее определенный порог для определения значимых результатов. Если p меньше α, нулевая гипотеза (H 0 ) отклоняется. [16]
Множественное тестирование
[ редактировать ]При множественных проверках одной и той же гипотезы вероятность возникновения ложноположительных результатов (частота семейных ошибок) увеличивается, и для контроля этого возникновения используется некоторая стратегия. Обычно это достигается за счет использования более строгого порога для отклонения нулевых гипотез. Поправка Бонферрони определяет приемлемый глобальный уровень значимости, обозначаемый α*, и каждый тест индивидуально сравнивается со значением α = α*/m. Это гарантирует, что коэффициент семейных ошибок во всех m тестах будет меньше или равен α*. Когда m велико, поправка Бонферрони может быть чрезмерно консервативной. Альтернативой поправке Бонферрони является контроль уровня ложных обнаружений (FDR) . FDR контролирует ожидаемую долю отвергнутых нулевых гипотез (так называемых открытий), которые являются ложными (неверными отклонениями). Эта процедура гарантирует, что для независимых тестов частота ложных обнаружений не превышает q*. Таким образом, FDR менее консервативен, чем коррекция Бонферрони, и имеет больше власти за счет большего количества ложных срабатываний. [17]
Проверка неправильных спецификаций и надежности
[ редактировать ]Основная проверяемая гипотеза (например, отсутствие связи между лечением и результатами) часто сопровождается другими техническими предположениями (например, о форме распределения вероятностей результатов), которые также являются частью нулевой гипотезы. Когда технические предположения на практике нарушаются, нулевое значение часто может быть отвергнуто, даже если основная гипотеза верна. Говорят, что такие отклонения происходят из-за неправильной спецификации модели. [18] Проверка того, не меняются ли результаты статистического теста при незначительном изменении технических предположений (так называемые проверки устойчивости), является основным способом борьбы с неверными спецификациями.
Критерии выбора модели
[ редактировать ]Выбор критериев модели позволит выбрать или смоделировать наиболее приближенную к истинной модели. Информационный критерий Акаике (AIC) и Байесовский информационный критерий (BIC) являются примерами асимптотически эффективных критериев.
Разработки и большие данные
[ редактировать ]Этот раздел нуждается в дополнительных цитатах для проверки . ( декабрь 2016 г. ) |
Последние разработки оказали большое влияние на биостатистику. Двумя важными изменениями стали возможность собирать данные с высокой пропускной способностью и возможность выполнять гораздо более сложный анализ с использованием вычислительных методов. Это происходит благодаря развитию таких областей, как секвенирования технологии , биоинформатика и машинное обучение ( машинное обучение в биоинформатике ).
Использование в данных с высокой пропускной способностью
[ редактировать ]Новые биомедицинские технологии, такие как микрочипы , секвенаторы нового поколения (для геномики) и масс-спектрометрия (для протеомики), генерируют огромные объемы данных, позволяя проводить множество тестов одновременно. [19] Чтобы отделить сигнал от шума, необходим тщательный анализ с помощью биостатистических методов. Например, микроматрицу можно использовать для одновременного измерения многих тысяч генов и определения того, какие из них имеют разную экспрессию в больных клетках по сравнению с нормальными клетками. Однако только часть генов будет экспрессироваться дифференциально. [20]
Мультиколлинеарность часто возникает в биостатистических условиях с высокой пропускной способностью. Из-за высокой взаимной корреляции между предикторами (например, уровнями экспрессии генов ) информация одного предиктора может содержаться в другом. Возможно, только 5% предикторов ответственны за 90% вариабельности ответа. В таком случае можно применить биостатистический метод уменьшения размерности (например, с помощью анализа главных компонент). Классические статистические методы, такие как линейная или логистическая регрессия и линейный дискриминантный анализ, не работают хорошо для данных большой размерности (т.е. когда количество наблюдений n меньше количества признаков или предикторов p: n < p). На самом деле, можно получить довольно высокий R 2 -значения, несмотря на очень низкую предсказательную силу статистической модели. Эти классические статистические методы (особенно линейная регрессия по методу наименьших квадратов ) были разработаны для данных малой размерности (т.е. когда количество наблюдений n намного больше, чем количество предикторов p: n >> p). В случаях высокой размерности всегда следует учитывать независимый набор проверочных тестов и соответствующую остаточную сумму квадратов (RSS) и R. 2 набора проверочных тестов, а не набора обучающих тестов.
Часто бывает полезно объединить информацию от нескольких предикторов. Например, анализ обогащения набора генов (GSEA) учитывает возмущения целых (функционально связанных) наборов генов, а не отдельных генов. [21] Эти наборы генов могут представлять собой известные биохимические пути или иным образом функционально связанные гены. Преимущество этого подхода в том, что он более надежен: более вероятно, что окажется ложно нарушенным один ген, чем ложно нарушен весь путь. , можно интегрировать накопленные знания о биохимических путях (таких как сигнальный путь JAK-STAT Кроме того, используя этот подход ).
Достижения биоинформатики в области баз данных, интеллектуального анализа данных и биологической интерпретации.
[ редактировать ]Развитие биологических баз данных обеспечивает возможность хранения и управления биологическими данными с возможностью обеспечения доступа для пользователей по всему миру. Они полезны для исследователей, которые размещают данные, извлекают информацию и файлы (необработанные или обработанные), полученные в результате других экспериментов, или индексируют научные статьи, как PubMed . Другая возможность — поиск по нужному термину (ген, белок, заболевание, организм и т. д.) и проверка всех результатов, связанных с этим поиском. Существуют базы данных, посвященные SNP ( dbSNP ), знаниям о характеристиках генов и их путях ( KEGG ), а также описанию функций генов, классифицирующих их по клеточным компонентам, молекулярным функциям и биологическим процессам ( Gene Ontology ). [22] Помимо баз данных, содержащих конкретную молекулярную информацию, существуют и другие, обширные в том смысле, что они хранят информацию об организме или группе организмов. Примером базы данных, ориентированной только на один организм, но содержащей много данных о нем, может служить Arabidopsis thaliana – TAIR. генетическая и молекулярная база данных [23] фитосома, [24] в свою очередь, хранит сборки и файлы аннотаций десятков геномов растений, а также содержит инструменты визуализации и анализа. Более того, существует взаимосвязь между некоторыми базами данных в процессе обмена информацией, и важной инициативой стало Международное сотрудничество по базам данных нуклеотидных последовательностей (INSDC). [25] который связывает данные из DDBJ, [26] ЭМБЛ-ЭБИ, [27] и NCBI. [28]
В настоящее время увеличение размера и сложности наборов молекулярных данных приводит к использованию мощных статистических методов, предоставляемых алгоритмами информатики, разработанными в области машинного обучения . Таким образом, интеллектуальный анализ данных и машинное обучение позволяют обнаруживать закономерности в данных со сложной структурой, например биологические, используя, методы контролируемого и неконтролируемого обучения , регрессии, обнаружения кластеров и интеллектуального анализа правил ассоциации . среди прочего, [22] Чтобы указать на некоторые из них, самоорганизующиеся карты и k -средние являются примерами кластерных алгоритмов; Реализация нейронных сетей и модели опорных векторных машин являются примерами распространенных алгоритмов машинного обучения.
Совместная работа молекулярных биологов, биоинформатиков, статистиков и ученых-компьютерщиков важна для правильного проведения эксперимента, начиная от планирования, генерации и анализа данных и заканчивая биологической интерпретацией результатов. [22]
Использование вычислительно интенсивных методов
[ редактировать ]С другой стороны, появление современных компьютерных технологий и относительно дешевых вычислительных ресурсов позволило использовать компьютероемкие биостатистические методы, такие как методы начальной загрузки и повторной выборки .
В последнее время случайные леса приобрели популярность как метод статистической классификации . Методы случайного леса создают панель деревьев решений. Преимущество деревьев решений заключается в том, что вы можете их рисовать и интерпретировать (даже имея базовые знания математики и статистики). Таким образом, случайные леса использовались для систем поддержки клинических решений. [ нужна ссылка ]
Приложения
[ редактировать ]Общественное здравоохранение
[ редактировать ]Общественное здравоохранение , включая эпидемиологию , исследования в области здравоохранения , питание , гигиену окружающей среды , политику и управление здравоохранением. В описании лекарственных препаратов важно учитывать дизайн и анализ клинических исследований . В качестве примера можно привести оценку тяжести состояния больного с прогнозом исхода заболевания.
Благодаря новым технологиям и знаниям в области генетики биостатистика теперь также используется в системной медицине , которая представляет собой более персонализированную медицину. Для этого осуществляется интеграция данных из разных источников, включая традиционные данные пациентов, клинико-патологические параметры, молекулярные и генетические данные, а также данные, полученные с помощью дополнительных технологий новой омики. [29]
Количественная генетика
[ редактировать ]Изучение популяционной и статистической генетики с целью связать изменчивость генотипа с изменчивостью фенотипа . Другими словами, желательно обнаружить генетическую основу измеримого признака, количественного признака, находящегося под полигенным контролем. Область генома, отвечающая за непрерывный признак, называется локусом количественного признака (QTL). Изучение QTL становится возможным благодаря использованию молекулярных маркеров и измерению признаков в популяциях, но для их картирования необходимо получение популяции в результате экспериментального скрещивания, такого как F2, или рекомбинантных инбредных штаммов /линий (RIL). Для сканирования областей QTL в геноме карту генов необходимо построить , основанную на сцеплении. Некоторые из наиболее известных алгоритмов картирования QTL — это картирование интервалов, картирование составных интервалов и картирование нескольких интервалов. [30]
Однако разрешение картирования QTL ухудшается из-за количества анализируемой рекомбинации, что является проблемой для видов, у которых трудно получить большое потомство. Более того, разнообразие аллелей ограничено особями, происходящими от контрастирующих родителей, что ограничивает исследования разнообразия аллелей, когда у нас есть панель особей, представляющих естественную популяцию. [31] По этой причине было предложено полногеномное исследование ассоциации с целью идентификации QTL на основе неравновесия по сцеплению , то есть неслучайной ассоциации между признаками и молекулярными маркерами. Этому способствовала разработка высокопроизводительного генотипирования SNP . [32]
В селекции животных и растений использование маркеров в селекционной селекции, преимущественно молекулярных, сопутствовало развитию маркерно-ассистированной селекции . Хотя картирование QTL имеет ограниченное разрешение, GWAS не обладает достаточной мощностью при редких вариантах небольшого эффекта, на которые также влияет окружающая среда. Итак, концепция геномного отбора (GS) возникает для того, чтобы использовать в отборе все молекулярные маркеры и позволить прогнозировать показатели кандидатов в этом отборе. Предложение состоит в том, чтобы генотипировать и фенотипировать обучающую популяцию, разработать модель, которая может получить геномную оценку племенной ценности (GEBV) особей, принадлежащих к генотипу, но не к фенотипической популяции, называемую тестируемой популяцией. [33] Этот вид исследования также может включать в себя популяцию проверки, используя концепцию перекрестной проверки , в которой реальные результаты фенотипа, измеренные в этой популяции, сравниваются с результатами фенотипа, основанными на прогнозе, что используется для проверки точности модели. .
Подводя итог, отметим некоторые моменты применения количественной генетики:
- Это использовалось в сельском хозяйстве для улучшения сельскохозяйственных культур ( Растениеводство ) и животноводства ( Животноводство ).
- В биомедицинских исследованиях эта работа может помочь в поиске генов- аллелей кандидатов , которые могут вызывать или влиять на предрасположенность к заболеваниям в генетике человека.
Данные выражения
[ редактировать ]Исследования дифференциальной экспрессии генов на основе данных RNA-Seq , как и для RT-qPCR и микрочипов , требуют сравнения условий. Цель состоит в том, чтобы идентифицировать гены, численность которых значительно меняется в зависимости от различных условий. Затем эксперименты планируются соответствующим образом с повторами для каждого состояния/лечения, рандомизацией и блокировкой, когда это необходимо. В RNA-Seq для количественной оценки экспрессии используется информация картированных прочтений, которые суммируются в некоторой генетической единице, например экзонах , которые являются частью последовательности гена. Поскольку результаты микрочипов можно аппроксимировать нормальным распределением, данные подсчета RNA-Seq лучше объясняются другими распределениями. Первым использованным распределением было распределение Пуассона , но оно недооценивало ошибку выборки, что приводило к ложноположительным результатам. В настоящее время биологическая изменчивость рассматривается методами, оценивающими параметр дисперсии отрицательного биномиального распределения . Обобщенные линейные модели используются для выполнения тестов на статистическую значимость, и, поскольку количество генов велико, необходимо учитывать коррекцию нескольких тестов. [34] Некоторые примеры другого анализа данных геномики взяты из экспериментов на микрочипах или протеомике . [35] [36] Часто относительно заболеваний или стадий заболевания. [37]
Другие исследования
[ редактировать ]- Экология , экологическое прогнозирование
- биологической последовательности Анализ [38]
- Системная биология для вывода генных сетей или анализа путей. [39]
- Клинические исследования и фармацевтические разработки
- Динамика численности населения , особенно в отношении науки о рыболовстве .
- Филогенетика и эволюция
- Фармакодинамика
- Фармакокинетика
- Нейровизуализация
Инструменты
[ редактировать ]Существует множество инструментов, которые можно использовать для статистического анализа биологических данных. Большинство из них полезны в других областях знаний, охватывая большое количество приложений (по алфавиту). Вот краткие описания некоторых из них:
- ASReml : еще одно программное обеспечение, разработанное VSNi. [40] который также можно использовать в среде R в виде пакета. Он разработан для оценки компонентов дисперсии в рамках общей линейной смешанной модели с использованием ограниченного максимального правдоподобия (REML). Допускаются модели с фиксированными эффектами и случайными эффектами, а также вложенные или скрещенные. Дает возможность исследовать различные структуры дисперсионно-ковариационной матрицы.
- ЦиклДизайнN: [41] Компьютерный пакет, разработанный VSNi. [40] это помогает исследователям создавать экспериментальные проекты и анализировать данные, полученные из проекта, присутствующего в одном из трех классов, обрабатываемых CycDesigN. К этим классам относятся разрешимые, неразрешимые, частично реплицируемые и перекрестные конструкции . Он включает в себя менее используемые латинизированные конструкции, такие как t-латинизированный дизайн. [42]
- Оранжевый : программный интерфейс для высокоуровневой обработки данных, интеллектуального анализа данных и визуализации данных. Включите инструменты для экспрессии генов и геномики. [22]
- R : Среда с открытым исходным кодом и язык программирования, предназначенные для статистических вычислений и графики. Это реализация языка S , поддерживаемая CRAN. [43] Помимо функций чтения таблиц данных, сбора описательной статистики, разработки и оценки моделей, его репозиторий содержит пакеты, разработанные исследователями со всего мира. Это позволяет разрабатывать функции, предназначенные для статистического анализа данных, поступающих из конкретных приложений. [44] Например, в случае с биоинформатикой есть пакеты, расположенные в основном репозитории (CRAN), а в других — как Bioconductor . Также можно использовать разрабатываемые пакеты, которые доступны в хостинг-сервисах как GitHub .
- SAS : широко используемое программное обеспечение для анализа данных, используемое в университетах, сфере услуг и промышленности. Разработанный одноименной компанией ( SAS Institute ), он использует язык SAS для программирования.
- НОАК 3.0: [45] Это программное обеспечение для биостатистического анализа для регулируемых сред (например, тестирование на наркотики), которое поддерживает анализы количественного ответа (параллельные линии, параллельная логистика, коэффициент наклона) и дихотомические анализы (квантовый ответ, бинарные анализы). Он также поддерживает методы взвешивания для комбинированных расчетов и автоматическое агрегирование данных независимых анализов.
- Weka : программное обеспечение Java для машинного обучения и интеллектуального анализа данных , включая инструменты и методы для визуализации, кластеризации, регрессии, правил ассоциации и классификации. Есть инструменты для перекрестной проверки, начальной загрузки и модуль сравнения алгоритмов. Weka также можно запускать на других языках программирования, таких как Perl или R. [22]
- Анализ изображений Python (язык программирования) , глубокое обучение, машинное обучение
- SQL Базы данных
- NoSQL
- NumPy Числовой питон
- SciPy
- SageMath
- ЛАПАКА Линейная алгебра
- МАТЛАБ
- Апач Хадуп
- Апач Спарк
- Веб-сервисы Amazon
Объем и программы обучения
[ редактировать ]Почти все образовательные программы по биостатистике проводятся на последипломном уровне. Их чаще всего можно найти в школах общественного здравоохранения, школах медицины, лесного хозяйства или сельского хозяйства или в качестве предмета применения на факультетах статистики.
В Соединенных Штатах, где в нескольких университетах есть специализированные кафедры биостатистики, многие другие ведущие университеты объединяют факультеты биостатистики со статистическими или другими факультетами, такими как эпидемиология . Таким образом, кафедры, носящие название «биостатистика», могут существовать в совершенно разных структурах. Например, были созданы относительно новые кафедры биостатистики с упором на биоинформатику и вычислительную биологию , тогда как более старые кафедры, обычно связанные со школами общественного здравоохранения , будут иметь более традиционные направления исследований, включающие эпидемиологические исследования и клинические испытания , а также биоинформатику. В более крупных университетах по всему миру, где существуют факультеты статистики и биостатистики, степень интеграции между двумя факультетами может варьироваться от минимального до очень тесного сотрудничества. В целом, разница между статистической программой и программой биостатистики двоякая: (i) отделы статистики часто проводят теоретические/методологические исследования, которые менее распространены в программах биостатистики, и (ii) отделы статистики имеют направления исследований, которые могут включать биомедицинские приложения. но и другие области, такие как промышленность ( контроль качества ), бизнес и экономика и биологические области помимо медицины.
Специализированные журналы
[ редактировать ]- Биостатистика [46]
- Международный журнал биостатистики [47]
- Журнал эпидемиологии и биостатистики [48]
- Биостатистика и общественное здравоохранение [49]
- Биометрия [50]
- Биометрия [51]
- Биометрический журнал [52]
- Коммуникации в биометрии и растениеводстве [53]
- Статистические приложения в генетике и молекулярной биологии [54]
- Статистические методы в медицинских исследованиях [55]
- Фармацевтическая статистика [56]
- Статистика в медицине [57]
См. также
[ редактировать ]- Биоинформатика
- Эпидемиологический метод
- Эпидемиология
- Меры размера группы
- Индикатор здоровья
- Математическая и теоретическая биология
Ссылки
[ редактировать ]- ^ Центр трансформационных инноваций Технологического университета Суинберна. «Аллан, Фрэнсис Элизабет (Бетти) - Личность - Энциклопедия австралийской науки и инноваций» . www.eoas.info . Проверено 26 октября 2022 г.
- ^ Гюнтер, Крис (10 декабря 2008 г.). «Количественная генетика» . Природа . 456 (7223): 719. Бибкод : 2008Natur.456..719G . дои : 10.1038/456719а . ПМИД 19079046 .
- ^ Чарльз Т. Мангер (3 октября 2003 г.). «Академическая экономика: сильные и слабые стороны после учета междисциплинарных потребностей» (PDF) . Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Перейти обратно: а б с Низамуддин, Сара Л.; Низамуддин, Джунаид; Мюллер, Ариэль; Рамакришна, Хариш; Шахул, Саджид С. (октябрь 2017 г.). «Разработка гипотезы и статистическое планирование». Журнал кардиоторакальной и сосудистой анестезии . 31 (5): 1878–1882. дои : 10.1053/j.jvca.2017.04.020 . ПМИД 28778775 .
- ^ Перейти обратно: а б с д Оверхолсер, Брайан Р.; Совински, Кевин М (2017). «Букварь по биостатистике: Часть I». Питание в клинической практике . 22 (6): 629–35. дои : 10.1177/0115426507022006629 . ПМИД 18042950 .
- ^ Щех, Линда Энн; Коладонато, Джозеф А.; Оуэн, Уильям Ф. (4 октября 2002 г.). «Ключевые понятия биостатистики: использование статистики для ответа на вопрос «Есть ли разница?» ». Семинары по диализу . 15 (5): 347–351. дои : 10.1046/j.1525-139X.2002.00085.x . ПМИД 12358639 . S2CID 30875225 .
- ^ Санделовски, Маргарет (2000). «Сочетание качественного и количественного отбора проб, сбора данных и методов анализа в исследованиях смешанными методами». Исследования в области сестринского дела и здоровья . 23 (3): 246–255. CiteSeerX 10.1.1.472.7825 . doi : 10.1002/1098-240X(200006)23:3<246::AID-NUR9>3.0.CO;2-H . ПМИД 10871540 . S2CID 10733556 .
- ^ Математика, Сангаку. «Абсолютная, относительная, накопленная частота и статистические таблицы – Вероятность и статистика» . www.sangakoo.com . Проверено 10 апреля 2018 г.
- ^ Перейти обратно: а б «DATASUS: TabNet Win32 3.0: Живорождение – Бразилия» . DATASUS: Информационные технологии на службе SUS .
- ^ Перейти обратно: а б с д Фортофер, Рональд Н.; Ли, Ын Соль (1995). Введение в биостатистику. Руководство по проектированию, анализу и открытиям . Академическая пресса. ISBN 978-0-12-262270-0 .
- ^ Пирсон, Карл (1 января 1895 г.). «X. Вклад в математическую теорию эволюции. — II. Асимметрия в однородном материале» . Фил. Пер. Р. Сок. Лонд. А. 186 : 343–414. Бибкод : 1895RSPTA.186..343P . дои : 10.1098/rsta.1895.0010 . ISSN 0264-3820 .
- ^ Уттс, Джессика М. (2005). Видеть сквозь статистику (3-е изд.). Бельмонт, Калифорния: Томсон, Брукс/Коул. ISBN 978-0534394028 . OCLC 56568530 .
- ^ Джаррелл, Стивен Б. (1994). Базовая статистика . Дубьюк, Айова: Wm. Паб C. Brown. ISBN 978-0697215956 . ОСЛК 30301196 .
- ^ Гуджарати, Дамодар Н. (2006). Эконометрика . МакГроу-Хилл Ирвин.
- ^ Уотсон, Линдси (2009). «Основы биостатистики в общественном здравоохранении и рабочая тетрадь по основам биостатистики: статистические вычисления с использованием Excel» . Австралийский и новозеландский журнал общественного здравоохранения . 33 (2): 196–197. дои : 10.1111/j.1753-6405.2009.00372.x . ISSN 1326-0200 .
- ^ Бейкер, Моня (2016). «Статистики предупреждают о неправильном использовании значений P» . Природа . 531 (7593): 151. Бибкод : 2016Natur.531..151B . дои : 10.1038/nature.2016.19503 . ПМИД 26961635 .
- ^ Бенджамини, Ю. и Хохберг, Ю. Контроль частоты ложных обнаружений: практичный и мощный подход к множественному тестированию. Журнал Королевского статистического общества. Серия Б (Методическая) 57, 289–300 (1995).
- ^ «Нулевая гипотеза» . www.statlect.com . Проверено 8 мая 2018 г.
- ^ Хайден, Эрика Чек (8 февраля 2012 г.). «Биостатистика: показательный анализ» . Природа . 482 (7384): 263–265. дои : 10.1038/nj7384-263a . ПМИД 22329008 .
- ^ Эфрон, Брэдли (февраль 2008 г.). «Микрочипы, эмпирический Байес и модель двух групп». Статистическая наука . 23 (1): 1–22. arXiv : 0808.0572 . дои : 10.1214/07-STS236 . S2CID 8417479 .
- ^ Субраманиан, А.; Тамайо, П.; Моота, В.К.; Мукерджи, С.; Эберт, БЛ; Джилетт, Массачусетс; Павлович А.; Помрой, СЛ; Голуб, ТР; Ландер, ЕС; Месиров, Дж. П. (30 сентября 2005 г.). «Анализ обогащения генного набора: основанный на знаниях подход к интерпретации профилей экспрессии в масштабах всего генома» . Труды Национальной академии наук . 102 (43): 15545–15550. Бибкод : 2005PNAS..10215545S . дои : 10.1073/pnas.0506580102 . ПМЦ 1239896 . ПМИД 16199517 .
- ^ Перейти обратно: а б с д и Мур, Джейсон Х (2007). «Биоинформатика» . Журнал клеточной физиологии . 213 (2): 365–9. дои : 10.1002/jcp.21218 . ПМИД 17654500 . S2CID 221831488 .
- ^ «ТАИР - Домашняя страница» . www.arabidopsis.org .
- ^ «Фитозом» . phytozome.jgi.doe.gov .
- ^ «Международное сотрудничество в области баз данных нуклеотидных последовательностей - INSDC» . www.insdc.org .
- ^ "Вершина" . www.ddbj.nig.ac.jp. 11 января 2024 г.
- ^ «Европейский институт биоинформатики <EMBL-EBI» . www.ebi.ac.uk.
- ^ «Национальный центр биотехнологической информации» . www.ncbi.nlm.nih.gov . Национальная медицинская библиотека США –.
- ^ Апвайлер, Рольф; и др. (2018). «Где системная медицина?» . Экспериментальная и молекулярная медицина . 50 (3): е453. дои : 10.1038/emm.2017.290 . ПМЦ 5898894 . ПМИД 29497170 .
- ^ Цзэн, Чжао-Банг (2005). «Картирование QTL и генетическая основа адаптации: последние разработки». Генетика . 123 (1–2): 25–37. дои : 10.1007/s10709-004-2705-0 . ПМИД 15881678 . S2CID 1094152 .
- ^ Корте, Артур; Фарлоу, Эшли (2013). «Преимущества и ограничения анализа признаков с помощью GWAS: обзор» . Растительные методы . 9:29 . дои : 10.1186/1746-4811-9-29 . ПМК 3750305 . ПМИД 23876160 .
- ^ Чжу, Чэнсонг; Гор, Майкл; Баклер, Эдвард С; Ю, Цзяньмин (2008). «Состояние и перспективы ассоциативного картирования у растений» . Геном растения . 1 :5–20. doi : 10.3835/plantgenome2008.02.0089 .
- ^ Кросса, Джозеф; Перес-Родригес, Паулино; Куэвас, Хайме; Монтесинос-Лопес, Осваль; Харкин, Диего; «О полях», Густаво; Буржуа, Джон; Гонсалес-Камачо, Хуан М; Перес-Элисальде, Серхио; Бейене, Джозеф; Дрейзигакер, Сюзанна; Сингх, Рави; Чжан, Сюэцай; Гауда, Мандже; Руркивал, Маниш; Руткоски, Джессика; Варшни, Раджив К. (2017). «Геномная селекция в селекции растений: методы, модели и перспективы» (PDF) . Тенденции в науке о растениях . 22 (11): 961–975. Бибкод : 2017TPS....22..961C . doi : 10.1016/j.tplants.2017.08.011 . ПМИД 28965742 . Архивировано (PDF) из оригинала 9 октября 2022 г.
- ^ Ошлак, Алисия; Робинсон, Марк Д; Янг, Мэтью Д. (2010). «От считываний РНК-секвенирования к результатам дифференциальной экспрессии» . Геномная биология . 11 (12): 220. doi : 10.1186/gb-2010-11-12-220 . ПМК 3046478 . ПМИД 21176179 .
- ^ Хелен Костон; Джон Квакенбуш; Алвис Бразма (2003). Статистический анализ данных микрочипов по экспрессии генов . Уайли-Блэквелл.
- ^ Терри Спид (2003). Анализ данных экспрессии генов на микрочипах: руководство для начинающих . Чепмен и Холл/CRC.
- ^ Франк Эммерт-Страйб; Маттиас Демер (2010). Медицинская биостатистика сложных заболеваний . Уайли-Блэквелл. ISBN 978-3-527-32585-6 .
- ^ Уоррен Дж. Юэнс; Грегори Р. Грант (2004). Статистические методы в биоинформатике: введение . Спрингер.
- ^ Маттиас Демер; Франк Эммерт-Страйб; Армин Грабер; Арминдо Сальвадор (2011). Прикладная статистика для сетевой биологии: методы системной биологии . Уайли-Блэквелл. ISBN 978-3-527-32750-8 .
- ^ Перейти обратно: а б «Главная — ВСН Интернешнл» . www.vsni.co.uk.
- ^ «CycDesignN — ВСН Интернешнл» . www.vsni.co.uk.
- ^ Пьефо, Ханс-Петер; Уильямс, Эмлин Р.; Мишель, Волкер (2015). «За пределами латинских квадратов: краткий обзор конструкций строк и столбцов». Агрономический журнал . 107 (6): 2263. Бибкод : 2015AgrJ..107.2263P . дои : 10.2134/agronj15.0144 .
- ^ «Комплексная сеть архивов R» . cran.r-project.org .
- ^ Ренганатан V (2021 г.). Биостатистика, изучаемая с помощью программного обеспечения R: обзор . Винайтеэртан Ренганатан. ISBN 9789354936586 .
- ^ Стегманн, доктор Ральф (01 июля 2019 г.). «ПЛА 3.0» . PLA 3.0 – Программное обеспечение для биостатистического анализа . Проверено 02 июля 2019 г.
- ^ «Биостатистика — Оксфорд Академик» . ОУП Академический .
- ^ «Международный журнал биостатистики» .
- ^ «Журналы PubMed будут закрыты» . 15 июня 2018 г.
- ^ https://ebph.it/ Эпидемиология
- ^ «Биометрия» . onlinelibrary.wiley.com . дои : 10.1111/(ISSN) 1541-0420 .
- ^ «Биометрика – Оксфорд Академик» . ОУП Академический .
- ^ «Биометрический журнал» . onlinelibrary.wiley.com . дои : 10.1002/(ISSN) 1521-4036 .
- ^ «Коммуникации в биометрии и растениеводстве» . agrobiol.sggw.waw.pl .
- ^ «Статистические приложения в генетике и молекулярной биологии» . www.degruyter.com . 1 мая 2002 г.
- ^ «Статистические методы в медицинских исследованиях» . Журналы SAGE .
- ^ «Фармацевтическая статистика» . onlinelibrary.wiley.com .
- ^ «Статистика в медицине» . onlinelibrary.wiley.com . дои : 10.1002/(ISSN) 1097-0258 .
Внешние ссылки
[ редактировать ]![]() СМИ, связанные с биостатистикой, на Викискладе?
СМИ, связанные с биостатистикой, на Викискладе?
- Международное биометрическое общество
- Коллекция архива биостатистических исследований
- Руководство по биостатистике (MedPageToday.com). Архивировано 22 мая 2012 г. в Wayback Machine.
- Биомедицинская статистика
| Базы данных органов управления : Национальные |
|---|