Нормальное распределение
Функция плотности вероятности 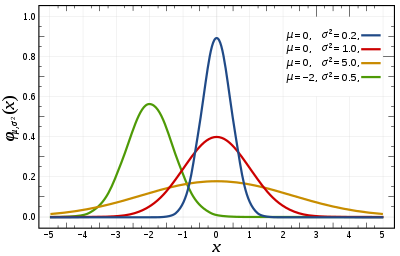 Красная кривая — стандартное нормальное распределение . | |||
Кумулятивная функция распределения 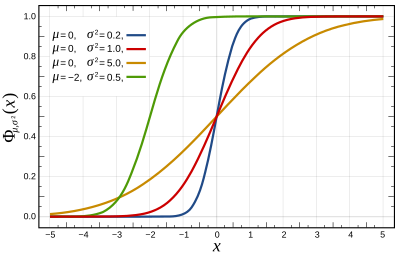 | |||
| Обозначения | |||
|---|---|---|---|
| Параметры | = среднее ( местоположение ) = дисперсия (квадратичная шкала ) | ||
| Поддерживать | |||
| CDF | |||
| Квантиль | |||
| Иметь в виду | |||
| медиана | |||
| Режим | |||
| Дисперсия | |||
| БЕЗУМНЫЙ | |||
| асимметрия | |||
| Избыточный эксцесс | |||
| Энтропия | |||
| МГФ | |||
| CF | |||
| Информация о Фишере | |||
| Расхождение Кульбака – Лейблера | |||
| Ожидаемый дефицит | [1] | ||





![{\displaystyle \Phi \left({\frac {x-\mu }{\sigma }}\right)={\frac {1}{2}}\left[1+\operatorname {erf} \left({ \frac {x-\mu }{\sigma {\sqrt {2}}}}\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0fed43e25966344745178c406f04b15d0fa3783)












| Часть серии по статистике. |
| Теория вероятностей |
|---|
 |
В теории вероятностей и статистике нормальное распределение или распределение Гаусса — это тип непрерывного распределения вероятностей для вещественной случайной величины . Общий вид его функции плотности вероятности : Параметр — среднее или математическое ожидание распределения (а также его медиана и мода ), а параметр это дисперсия . Стандартное отклонение распределения равно . Случайная величина с распределением Гаусса называется нормально распределенной и называется нормальным отклонением .




Нормальные распределения важны в статистике и часто используются в естественных и социальных науках для представления действительных случайных величин , распределение которых неизвестно. [2] [3] Их важность частично обусловлена центральной предельной теоремой . Он утверждает, что при некоторых условиях среднее значение многих выборок (наблюдений) случайной величины с конечным средним значением и дисперсией само по себе является случайной величиной, распределение которой сходится к нормальному распределению по мере увеличения количества выборок. Следовательно, физические величины, которые, как ожидается, будут суммой многих независимых процессов, таких как ошибки измерения , часто имеют распределение, близкое к нормальному. [4]
Более того, гауссовы распределения обладают некоторыми уникальными свойствами, которые ценны в аналитических исследованиях. Например, любая линейная комбинация фиксированного набора независимых нормальных отклонений является нормальным отклонением. Многие результаты и методы, такие как распространение неопределенности и метод наименьших квадратов. [5] подгонка параметров может быть получена аналитически в явной форме, когда соответствующие переменные имеют нормальное распределение.
Нормальное распределение иногда неофициально называют колоколообразной кривой . [6] Однако многие другие распределения имеют колоколообразную форму (например, распределение Коши , Стьюдента распределение и логистическое распределение). Другие имена см. в разделе «Именование» .
Одномерное распределение вероятностей обобщено для векторов многомерного нормального распределения и для матриц матричного нормального распределения .
Определения
[ редактировать ]Стандартное нормальное распределение
[ редактировать ]Простейший случай нормального распределения известен как стандартное нормальное распределение или единичное нормальное распределение . Это особый случай, когда и , и он описывается этой функцией плотности вероятности (или плотностью): Переменная имеет среднее значение 0, а дисперсию и стандартное отклонение 1. Плотность имеет свой пик в и точки перегиба в и .









Хотя приведенная выше плотность чаще всего известна как стандартное нормальное распределение, некоторые авторы использовали этот термин для описания других версий нормального распределения. Карл Фридрих Гаусс , например, однажды определил стандартную норму как который имеет дисперсию 1/2, и Стивен Стиглер [7] однажды определил стандартную норму как который имеет простую функциональную форму и дисперсию



Общее нормальное распределение
[ редактировать ]Каждое нормальное распределение является версией стандартного нормального распределения, область действия которого расширена в раз. (стандартное отклонение), а затем переводится на (среднее значение):

Плотность вероятности должна быть масштабирована по формуле так что интеграл по-прежнему равен 1.

Если является стандартным нормальным отклонением , тогда будет иметь нормальное распределение с ожидаемым значением и стандартное отклонение . Это эквивалентно утверждению, что стандартное нормальное распределение можно масштабировать/растягивать в несколько раз. и сдвинут на чтобы получить другое нормальное распределение, называемое . И наоборот, если это нормальное отклонение от параметров и , тогда это распределение можно масштабировать и сдвигать по формуле чтобы преобразовать его к стандартному нормальному распределению. Эту вариацию также называют стандартизированной формой .




Обозначения
[ редактировать ]Плотность вероятности стандартного распределения Гаусса (стандартное нормальное распределение с нулевым средним и единичной дисперсией) часто обозначается греческой буквой. ( фи ). [8] Альтернативная форма греческой буквы фи. , также используется довольно часто.


Нормальное распределение часто называют или . [9] Таким образом, когда случайная величина обычно распределяется со средним значением и стандартное отклонение , можно написать



Альтернативные параметризации
[ редактировать ]Некоторые авторы выступают за использование точности как параметр, определяющий ширину распределения, вместо стандартного отклонения или дисперсия . Точность обычно определяется как величина, обратная дисперсии, . [10] Тогда формула распределения примет вид



Утверждается, что этот выбор имеет преимущества при численных расчетах, когда очень близко к нулю и упрощает формулы в некоторых контекстах, например, при байесовском выводе переменных с многомерным нормальным распределением .
Альтернативно, величина, обратная стандартному отклонению может быть определена как точность , и в этом случае выражение нормального распределения становится


По мнению Стиглера, эта формулировка выгодна тем, что она гораздо проще и легче запоминается, а также имеет простые приближенные формулы для квантилей распределения.
Нормальные распределения образуют экспоненциальное семейство с натуральными параметрами. и и естественная статистика x и x 2 . Параметрами двойного ожидания для нормального распределения являются η 1 = µ и η 2 = µ. 2 + р 2 .


Кумулятивная функция распределения
[ редактировать ]Кумулятивная функция распределения (CDF) стандартного нормального распределения, обычно обозначаемая заглавной греческой буквой. ( фи ) — интеграл


Функция ошибки
[ редактировать ]Соответствующая функция ошибки дает вероятность случайной величины с нормальным распределением среднего значения 0 и дисперсией 1/2, попадающими в диапазон . То есть:

![{\textstyle [-x,x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4939f2eb7c55ff4e7d13331fc0599a5f2452b479)

Эти интегралы не могут быть выражены через элементарные функции, и их часто называют специальными функциями . Однако известно множество численных приближений; см . ниже подробнее .
Эти две функции тесно связаны, а именно
![{\displaystyle \Phi (x)={\frac {1}{2}}\left[1+\operatorname {erf} \left({\frac {x}{\sqrt {2}}}\right)\ верно]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c7831a9a5f630df7170fa805c186f4c53219ca36)
Для общего нормального распределения с плотностью , иметь в виду и дисперсия кумулятивная функция распределения равна

![{\displaystyle F(x)=\Phi \left({\frac {x-\mu }{\sigma }}\right)={\frac {1}{2}}\left[1+\operatorname {erf } \left({\frac {x-\mu }{\sigma {\sqrt {2}}}}\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/75deccfbc473d782dacb783f1524abb09b8135c0)
Дополнение стандартной нормальной функции кумулятивного распределения, , часто называют Q-функцией , особенно в технических текстах. [11] [12] Он дает вероятность того, что значение стандартной нормальной случайной величины превысит : . Другие определения слова -функции, все из которых являются простыми преобразованиями , также иногда используются. [13]




График распределения стандартной нормальной кумулятивной функции имеет 2-кратную вращательную симметрию вокруг точки (0,1/2); то есть, . Его первообразную (неопределенный интеграл) можно выразить следующим образом:


Кумулятивную функцию распределения стандартного нормального распределения можно расширить путем интегрирования по частям в ряд:
![{\displaystyle \Phi (x)={\frac {1}{2}}+{\frac {1}{\sqrt {2\pi }}}\cdot e^{-x^{2}/2} \left[x+{\frac {x^{3}}{3}}+{\frac {x^{5}}{3\cdot 5}}+\cdots +{\frac {x^{2n+1 }}{(2n+1)!!}}+\cdots \right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/54d12af9a3b12a7f859e4e7be105d172b53bcfb8)
где обозначает двойной факториал .

Асимптотическое разложение кумулятивной функции распределения при больших x также можно получить с помощью интегрирования по частям. Дополнительную информацию см. в разделе Функция ошибки#Асимптотическое расширение . [14]
Быстрое приближение к кумулятивной функции распределения стандартного нормального распределения можно найти с помощью аппроксимации рядом Тейлора:

Рекурсивные вычисления с разложением в ряд Тейлора
[ редактировать ]Рекурсивный характер семейство производных можно использовать для легкого построения быстро сходящегося разложения в ряд Тейлора с использованием рекурсивных записей о любой точке известного значения распределения, :



где:

Использование ряда Тейлора и метода Ньютона для обратной функции
[ редактировать ]Применение вышеприведенного разложения в ряд Тейлора состоит в использовании метода Ньютона для обратного вычисления. То есть, если у нас есть значение кумулятивной функции распределения , , но не знаю, какой x необходим для получения , мы можем использовать метод Ньютона, чтобы найти x, и использовать приведенное выше разложение в ряд Тейлора, чтобы минимизировать количество вычислений. Метод Ньютона идеально подходит для решения этой проблемы, поскольку первая производная , которое является интегралом нормального стандартного распределения, является нормальным стандартным распределением и легко доступно для использования в решении метода Ньютона.

Для решения выберите известное приближенное решение, , к желаемому . может быть значением из таблицы распределения или интеллектуальной оценкой, за которой следует вычисление используя любые необходимые средства для вычислений. Используйте это значение и разложение в ряд Тейлора, приведенное выше, для минимизации вычислений.

Повторяйте следующий процесс до тех пор, пока разница между вычисленными и желаемое , который мы назовем , ниже выбранной приемлемо малой ошибки, например 10 −5 , 10 −15 , и т. д.:



где
- это из решения ряда Тейлора с использованием и


Когда повторные вычисления сходятся к ошибке ниже выбранного приемлемо малого значения, x будет значением, необходимым для получения желаемой стоимости, .
Стандартное отклонение и охват
[ редактировать ]
Около 68% значений, полученных из нормального распределения, находятся в пределах одного стандартного отклонения σ от среднего значения; около 95% значений лежат в пределах двух стандартных отклонений; и около 99,7% находятся в пределах трех стандартных отклонений. [6] Этот факт известен как правило 68–95–99,7 (эмпирическое) , или правило 3-х сигм .
Точнее, вероятность того, что нормальное отклонение лежит в диапазоне между и дается До 12 значащих цифр значения для являются: [ нужна ссылка ]




| ОЭИС | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.682 689 492 137 | 0.317 310 507 863 |
| ОЭИС : A178647 | ||
| 2 | 0.954 499 736 104 | 0.045 500 263 896 |
| ОЭИС : A110894 | ||
| 3 | 0.997 300 203 937 | 0.002 699 796 063 |
| ОЭИС : A270712 | ||
| 4 | 0.999 936 657 516 | 0.000 063 342 484 |
| |||
| 5 | 0.999 999 426 697 | 0.000 000 573 303 |
| |||
| 6 | 0.999 999 998 027 | 0.000 000 001 973 |
|




Для больших , можно использовать приближение .

Квантильная функция
[ редактировать ]Квантильная функция распределения является обратной кумулятивной функции распределения. Квантильная функция стандартного нормального распределения называется пробит-функцией и может быть выражена через обратную функцию ошибки : Для нормальной случайной величины со средним и дисперсия , функция квантиля равна Квантиль стандартного нормального распределения обычно обозначается как . Эти значения используются при проверке гипотез , построении доверительных интервалов и графиков Q–Q . Обычная случайная величина превысит с вероятностью , и будет лежать вне интервала с вероятностью . В частности, квантиль составляет 1,96 ; следовательно, нормальная случайная величина будет лежать вне интервала только в 5% случаев.









В следующей таблице приведены квантиль такой, что будет лежать в диапазоне с заданной вероятностью . Эти значения полезны для определения интервала допуска для выборочных средних и других статистических оценок с нормальным (или асимптотически нормальным) распределением. [15] В следующей таблице показаны , нет как определено выше.


| 0.80 | 1.281 551 565 545 | 0.999 | 3.290 526 731 492 | |
| 0.90 | 1.644 853 626 951 | 0.9999 | 3.890 591 886 413 | |
| 0.95 | 1.959 963 984 540 | 0.99999 | 4.417 173 413 469 | |
| 0.98 | 2.326 347 874 041 | 0.999999 | 4.891 638 475 699 | |
| 0.99 | 2.575 829 303 549 | 0.9999999 | 5.326 723 886 384 | |
| 0.995 | 2.807 033 768 344 | 0.99999999 | 5.730 728 868 236 | |
| 0.998 | 3.090 232 306 168 | 0.999999999 | 6.109 410 204 869 |
Для маленьких , функция квантиля имеет полезное асимптотическое разложение [ нужна ссылка ]

Характеристики
[ редактировать ]Нормальное распределение — единственное распределение, кумулянты которого помимо первых двух (т. е. кроме среднего и дисперсии ) равны нулю. Это также непрерывное распределение с максимальной энтропией для заданного среднего значения и дисперсии. [16] [17] Гири показал, предполагая, что среднее значение и дисперсия конечны, что нормальное распределение является единственным распределением, в котором среднее значение и дисперсия, рассчитанные на основе набора независимых выборок, независимы друг от друга. [18] [19]
Нормальное распределение является подклассом эллиптических распределений . Нормальное распределение симметрично относительно своего среднего значения и не равно нулю на всей реальной линии. По существу, она может оказаться неподходящей моделью для переменных, которые по своей сути являются положительными или сильно искаженными, например, вес человека или цена акции . Такие переменные могут быть лучше описаны другими распределениями, такими как логарифмически нормальное распределение или распределение Парето .
Значение нормального распределения практически равно нулю, когда значение находится более чем на несколько стандартных отклонений от среднего значения (например, разброс в три стандартных отклонения покрывает все, кроме 0,27% общего распределения). Следовательно, это может быть неподходящая модель, когда ожидается значительная доля выбросов (значений, которые отклоняются на много стандартных отклонений от среднего значения), а методы наименьших квадратов и другие методы статистического вывода , которые оптимальны для нормально распределенных переменных, часто становятся крайне ненадежными при их применении. к таким данным. В таких случаях следует предположить более тяжелое распределение и применить соответствующие надежные статистические методы вывода .
Распределение Гаусса принадлежит к семейству стабильных распределений , которые являются аттракторами сумм независимых, одинаково распределенных распределений, независимо от того, конечны ли среднее значение или дисперсия. За исключением гауссова распределения, которое является предельным случаем, все стабильные распределения имеют тяжелые хвосты и бесконечную дисперсию. Это одно из немногих распределений, которые стабильны и имеют функции плотности вероятности, которые могут быть выражены аналитически (остальные распределения — это распределение Коши и распределение Леви) .
Симметрии и производные
[ редактировать ]Нормальное распределение с плотностью (иметь в виду и дисперсия ) имеет следующие свойства:


- Оно симметрично относительно точки которая одновременно является модой , медианой и средним значением распределения. [20]
- Он унимодальный : его первая производная положительна при отрицательный для и ноль только при
- Площадь, ограниченная кривой и -ось равна единице (т.е. равна единице).
- Его первая производная
- Его вторая производная
- Его плотность имеет две точки перегиба (где вторая производная равно нулю и меняет знак), расположенное на одно стандартное отклонение от среднего значения, а именно на и [20]
- Его плотность логарифмически вогнутая . [20]
- Его плотность бесконечно дифференцируема и даже сверхгладкая второго порядка. [21]








Кроме того, плотность стандартного нормального распределения (т.е. и ) также имеет следующие свойства:

- Его первая производная
- Его вторая производная
- В более общем смысле, его n- я производная равна где — n -й (вероятностный) полином Эрмита . [22]
- Вероятность того, что нормально распределенная переменная с известными и находится в определенном наборе, можно вычислить, используя тот факт, что дробь имеет стандартное нормальное распределение.




Моменты
[ редактировать ]Простые и абсолютные моменты переменной ожидаемые значения и , соответственно. Если ожидаемое значение из равен нулю, эти параметры называются центральными моментами; в противном случае эти параметры называются нецентральными моментами. Обычно нас интересуют только моменты целого порядка. .



Если имеет нормальное распределение, нецентральные моменты существуют и конечны для любого действительная часть которого больше −1. Для любого неотрицательного целого числа , простыми центральными моментами являются: [23] Здесь обозначает двойной факториал , то есть произведение всех чисел из до 1, которые имеют ту же четность, что и
![{\displaystyle \operatorname {E} \left[(X-\mu)^{p}\right]={\begin{cases}0 & {\text{if }}p{\text{нечетно,}}\ \\sigma ^{p}(p-1)!!&{\text{if }}p{\text{ четно.}}\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f1d2c92b62ac2bbe07a8e475faac29c8cc5f7755)


Центральные абсолютные моменты совпадают с простыми моментами для всех четных порядков, но отличны от нуля для нечетных порядков. Для любого неотрицательного целого числа

Последняя формула справедлива и для любых нецелых чисел. Когда среднее простой и абсолютный моменты могут быть выражены через вырожденные гипергеометрические функции и [24]
![{\displaystyle {\begin{aligned}\operatorname {E} \left[|X-\mu |^{p}\right]&=\sigma ^{p}(p-1)!!\cdot {\begin {cases}{\sqrt {\frac {2}{\pi }}}&{\text{if }}p{\text{ нечетно}}\\1&{\text{if }}p{\text{ четно}}\end{cases}}\\&=\sigma ^{p}\cdot {\frac {2^{p/2}\Gamma \left({\frac {p+1}{2}} \right)}{\sqrt {\pi }}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3b196371c491676efa7ea7770ef56773db7652cd)




![{\displaystyle {\begin{aligned}\operatorname {E} \left[X^{p}\right]&=\sigma ^{p}\cdot (-i {\sqrt {2}})^{p} U\left(-{\frac {p}{2}},{\frac {1}{2}},-{\frac {1}{2}}\left({\frac {\mu }{\ сигма }}\right)^{2}\right),\\\operatorname {E} \left[|X|^{p}\right]&=\sigma ^{p}\cdot 2^{p/2 }{\frac {\Gamma \left({\frac {1+p}{2}}\right)}{\sqrt {\pi }}}{}_{1}F_{1}\left(-{ \frac {p}{2}},{\frac {1}{2}},-{\frac {1}{2}}\left({\frac {\mu }{\sigma }}\right) ^{2}\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c17bf881593b86e728bf5dfbdb41a4b86da3875)
Эти выражения остаются действительными, даже если не является целым числом. См. также обобщенные полиномы Эрмита .
| Заказ | Нецентральный момент | Центральный момент |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 |











Ожидание при условии, что лежит в интервале дается где и соответственно — плотность и кумулятивная функция распределения . Для это известно как обратное соотношение Миллса . Обратите внимание, что выше плотность из используется вместо стандартной нормальной плотности, как в обратном соотношении Миллса, поэтому здесь мы имеем вместо .
![{\textstyle [а,б]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2c780cbaafb5b1d4a6912aa65d2b0b1982097108)
![{\displaystyle \operatorname {E} \left[X\mid a<X<b\right]=\mu -\sigma ^{2}{\frac {f(b)-f(a)}{F(b )-F(а)}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d82ec10bf31f0b63137699ae6e2b5a346770b097)


Преобразование Фурье и характеристическая функция
[ редактировать ]нормальной Преобразование Фурье плотности со средним и дисперсия является [25]

где это мнимая единица . Если среднее , первый множитель равен 1, а преобразование Фурье, помимо постоянного множителя, представляет собой нормальную плотность в частотной области со средним значением 0 и дисперсией . В частности, стандартное нормальное распределение является собственной функцией преобразования Фурье.

В теории вероятностей преобразование Фурье распределения вероятностей действительной случайной величины. тесно связана с характеристической функцией этой переменной, которая определяется как ожидаемое значение , как функция действительной переменной ( частотный параметр преобразования Фурье). Это определение можно аналитически распространить на переменную с комплексным значением. . [26] Связь между обоими такова:




Функции, генерирующие момент и кумулянт
[ редактировать ]Момент -производящая функция действительной случайной величины ожидаемое значение , как функция действительного параметра . Для нормального распределения с плотностью , иметь в виду и дисперсия , производящая функция момента существует и равна

![{\displaystyle M(t)=\operatorname {E} \left[e^{tX}\right]={\hat {f}}(it)=e^{\mu t}e^{\sigma ^{ 2}т^{2}/2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/935bdfb329038ee45bf7cc94d83f68b66a5c74c5)
Кумулянтная производящая функция представляет собой логарифм производящей функции момента, а именно

Поскольку это квадратичный полином от отличны от нуля только первые два кумулянта , а именно среднее и дисперсия .
Некоторые авторы предпочитают вместо этого работать с E[ e ИТХ ] = и яцт - п 2 т 2 /2 и ln E[ e ИТХ ] = iμt - 1 / 2 σ 2 т 2 .
Оператор и класс Штейна
[ редактировать ]В методе Штейна оператор Штейна и класс случайной величины являются и класс всех абсолютно непрерывных функций .



![{\textstyle f:\mathbb {R} \to \mathbb {R} {\mbox{ такой, что }}\mathbb {E} [|f'(X)|]<\infty }](https://wikimedia.org/api/rest_v1/media/math/render/svg/533b737bedccd7496f904d18a4fd39fade40b282)
Предел нулевой дисперсии
[ редактировать ]В пределе , когда стремится к нулю, плотность вероятности в конце концов стремится к нулю при любом , но растет неограниченно, если , а его интеграл остается равным 1. Следовательно, нормальное распределение нельзя определить как обычную функцию, когда .



Однако можно определить нормальное распределение с нулевой дисперсией как обобщенную функцию ; в частности, как дельта-функция Дирака переведено в смысле , то есть Его кумулятивная функция распределения тогда представляет собой ступенчатую функцию Хевисайда, переведенную через среднее значение , а именно



Максимальная энтропия
[ редактировать ]Из всех распределений вероятностей по действительным числам с заданным конечным средним значением и конечная дисперсия , нормальное распределение тот, у которого максимальная энтропия . [27] Чтобы увидеть это, позвольте быть непрерывной случайной величиной с плотностью вероятности . Энтропия определяется как [28] [29] [30]

где считается равным нулю всякий раз, когда . Этот функционал можно максимизировать при условии, что распределение правильно нормализовано и имеет заданное среднее значение и дисперсию, с помощью вариационного исчисления . функция с тремя множителями Лагранжа Определена :



При максимальной энтропии небольшое изменение о создам вариацию о что равно 0:




Поскольку это должно выполняться для любых малых , множитель должно быть равно нулю, и решение для дает:

Ограничения Лагранжа, которые правильно нормализован и имеет указанное среднее значение, а дисперсия удовлетворяется тогда и только тогда, когда , , и выбираются так, что Энтропия нормального распределения равно который не зависит от среднего .






Другие объекты недвижимости
[ редактировать ]- Если характеристическая функция какой-то случайной величины имеет форму в окрестности нуля, где является многочленом , то теорема Марцинкевича (названная в честь Юзефа Марцинкевича ) утверждает, что может быть не более чем квадратичным многочленом, и, следовательно, является нормальной случайной величиной. [31] Следствием этого результата является то, что нормальное распределение является единственным распределением с конечным числом (двумя) ненулевых кумулянтов .
- Если и если они совместно нормальны и некоррелированы , то они независимы . Требование, чтобы и должно быть совместно нормальным, это важно; без этого имущество не сохраняется. [32] [33] [доказательство] Для ненормальных случайных величин некоррелированность не означает независимости.
- Расхождение Кульбака – Лейблера одного нормального распределения из другого дается: [34] Расстояние Хеллингера между одинаковыми распределениями равно
- Информационная матрица Фишера для нормального распределения относительно и диагональна и имеет вид
- Сопряженное априорное значение нормального распределения является еще одним нормальным распределением. [35] В частности, если являются идентификаторами и предшествующий , то апостериорное распределение для оценки будет
- Семейство нормальных распределений не только образует экспоненциальное семейство (EF), но фактически образует естественное экспоненциальное семейство (NEF) с квадратичной функцией дисперсии ( NEF-QVF ). Многие свойства нормальных распределений обобщаются на свойства распределений NEF-QVF, распределений NEF или распределений EF в целом. Распределения NEF-QVF включают 6 семейств, включая распределения Пуассона, гамма, биномиальные и отрицательные биномиальные, в то время как многие из распространенных семейств, изучаемых в области вероятности и статистики, представляют собой NEF или EF.
- В информационной геометрии семейство нормальных распределений образует статистическое многообразие с постоянной кривизной. . Это же семейство плоско относительно (±1)-связностей и . [36]
- Если распределяются по , затем . Обратите внимание, что здесь не предполагается независимость. [37]


















![{\textstyle E[\max _{i}X_{i}]\leq \sigma {\sqrt {2\ln n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0dfb87c9b047ccf23ace2139d97810dff1ed6670)
Связанные дистрибутивы
[ редактировать ]Центральная предельная теорема
[ редактировать ]



Центральная предельная теорема утверждает, что при определенных (довольно распространенных) условиях сумма многих случайных величин будет иметь примерно нормальное распределение. Точнее, где являются независимыми и одинаково распределенными случайными величинами с одинаковым произвольным распределением, нулевым средним значением и дисперсией. и это ихсреднее масштабирование по Тогда, как увеличивается, распределение вероятностей будет стремиться к нормальному распределению с нулевым средним и дисперсией .



Теорему можно распространить на переменные которые не являются независимыми и/или неодинаково распределенными, если на степень зависимости и моменты распределений наложены определенные ограничения.

Многие тестовые статистики , баллы и оценки, встречающиеся на практике, содержат в себе суммы определенных случайных величин, и еще больше оценок можно представить в виде сумм случайных величин за счет использования функций влияния . Центральная предельная теорема подразумевает, что эти статистические параметры будут иметь асимптотически нормальное распределение.
Центральная предельная теорема также подразумевает, что некоторые распределения могут быть аппроксимированы нормальным распределением, например:
- Биномиальное распределение примерно нормально со средним значением и дисперсия для больших и для не слишком близко к 0 или 1.
- Распределение Пуассона с параметром примерно нормально со средним значением и дисперсия , для больших значений . [38]
- Распределение хи -квадрат примерно нормально со средним значением и дисперсия , для большого .
- Стьюдента t-распределение примерно нормально со средним значением 0 и дисперсией 1, когда большой.









Достаточно ли точны эти приближения, зависит от цели, для которой они необходимы, и скорости сходимости к нормальному распределению. Обычно такие аппроксимации менее точны в хвостах распределения.
Общая верхняя оценка погрешности аппроксимации в центральной предельной теореме дается теоремой Берри–Эссеена , улучшения аппроксимации даются разложениями Эджворта .
Эту теорему можно также использовать для обоснования моделирования суммы многих источников однородного шума как гауссова шума . См . AWGN .
Операции и функции обычных переменных
[ редактировать ]
















Плотность вероятности , кумулятивное распределение и обратное кумулятивное распределение любой функции одной или нескольких независимых или коррелированных нормальных переменных можно вычислить с помощью численного метода трассировки лучей. [39] ( код Матлаба ). В следующих разделах мы рассмотрим некоторые особые случаи.
Операции с одной нормальной переменной
[ редактировать ]Если распределяется нормально со средним значением и дисперсия , затем
- , для любых действительных чисел и , также имеет нормальное распределение со средним значением и дисперсия . То есть семейство нормальных распределений замкнуто относительно линейных преобразований .
- Экспонента распространяется логарифмически : .
- Стандартная сигмовидная распределено по логит-нормальному закону : .
- Абсолютное значение свернул нормальное распределение : . Если это известно как полунормальное распределение .
- Абсолютное значение нормализованных остатков, , имеет распределение хи с одной степенью свободы: .
- Площадь имеет нецентральное распределение хи-квадрат с одной степенью свободы: . Если , распределение называется просто хи-квадрат .
- Логарифмическое правдоподобие нормальной переменной это просто журнал его функции плотности вероятности : Поскольку это масштабированный и сдвинутый квадрат стандартной нормальной переменной, он распределяется как масштабированная и сдвинутая переменная хи-квадрат .
- Распределение переменной ограничен интервалом называется усеченным нормальным распределением .
- имеет распределение Леви с местоположением 0 и масштабом .















Операции над двумя независимыми нормальными переменными
[ редактировать ]- Если и две независимые нормальные случайные величины со средними значениями , и отклонения , , то их сумма также будут нормально распределены, [доказательство] со средним и дисперсия .
- В частности, если и являются независимыми нормальными отклонениями с нулевым средним значением и дисперсией , затем и также независимы и нормально распределены, с нулевым средним значением и дисперсией . Это частный случай поляризационного тождества . [40]
- Если , представляют собой два независимых нормальных отклонения со средним значением и дисперсия , и , — произвольные действительные числа, то переменная также обычно распределяется со средним значением и дисперсия . Отсюда следует, что нормальное распределение устойчиво (с показателем ).
- Если , являются нормальными распределениями, то их нормализованное среднее геометрическое это нормальное распределение с и (см. здесь визуализацию).




















Операции над двумя независимыми стандартными нормальными переменными
[ редактировать ]Если и две независимые стандартные нормальные случайные величины со средним значением 0 и дисперсией 1, тогда
- Их сумма и разность распределяются нормально со средним нулевым значением и дисперсией два: .
- Их продукт следит за распространением продукции [41] с функцией плотности где — модифицированная функция Бесселя второго рода . Это распределение симметрично относительно нуля, неограничено в точке , и имеет характеристическую функцию .
- Их соотношение соответствует стандартному распределению Коши : .
- Их евклидова норма имеет распределение Рэлея .







Операции с несколькими независимыми нормальными переменными
[ редактировать ]- Любая линейная комбинация независимых нормальных отклонений является нормальным отклонением.
- Если являются независимыми стандартными нормальными случайными величинами, то сумма их квадратов имеет распределение хи-квадрат с степени свободы
- Если являются независимыми нормально распределенными случайными величинами со средними значениями и отклонения , то их выборочное среднее не зависит от выборочного стандартного отклонения , [42] что можно продемонстрировать с помощью теоремы Басу или теоремы Кокрена . [43] Отношение этих двух величин будет иметь t-распределение Стьюдента с степени свободы:
- Если , являются независимыми стандартными нормальными случайными величинами, то отношение их нормированных сумм квадратов будет иметь F-распределение с ( n , m ) степенями свободы: [44]



![{\displaystyle t={\frac {{\overline {X}}-\mu }{S/{\sqrt {n}}}}={\frac {{\frac {1}{n}}(X_{ 1}+\cdots +X_{n})-\mu }{\sqrt {{\frac {1}{n(n-1)}}\left[(X_{1}-{\overline {X}} )^{2}+\cdots +(X_{n}-{\overline {X}})^{2}\right]}}}\sim t_{n-1}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/36ff0d3c79a0504e8f259ef99192b825357914d7)


Операции с несколькими коррелирующими нормальными переменными
[ редактировать ]- Квадратичная форма нормального вектора, т.е. квадратичная функция из нескольких независимых или коррелирующих нормальных переменных, является обобщенной переменной хи-квадрат .

Действия над функцией плотности
[ редактировать ]Расщепленное нормальное распределение наиболее четко определяется с точки зрения объединения масштабированных участков функций плотности различных нормальных распределений и изменения масштаба плотности для интегрирования в одну. Усеченное нормальное распределение получается в результате изменения масштаба части одной функции плотности.
Бесконечная делимость и теорема Крамера
[ редактировать ]Для любого положительного целого числа , любое нормальное распределение со средним и дисперсия это распределение суммы независимые нормальные отклонения, каждое со средним значением и дисперсия . Это свойство называется бесконечной делимостью . [45]



И наоборот, если и являются независимыми случайными величинами и их сумма имеет нормальное распределение, то оба и должны быть нормальные отклонения. [46]
Этот результат известен как теорема Крамера о разложении и эквивалентен утверждению, что свертка двух распределений является нормальной тогда и только тогда, когда оба распределения нормальны. Теорема Крамера подразумевает, что линейная комбинация независимых негауссовских переменных никогда не будет иметь точно нормальное распределение, хотя и может приближаться к нему сколь угодно близко. [31]
Теорема Бернштейна
[ редактировать ]Теорема Бернштейна утверждает, что если и независимы и и также независимы, то и X , и Y обязательно должны иметь нормальное распределение. [47] [48]
В более общем смысле, если являются независимыми случайными величинами, то две различные линейные комбинации и будет независимым тогда и только тогда, когда все нормальные и , где обозначает дисперсию . [47]





Расширения
[ редактировать ]Понятие нормального распределения, являющегося одним из наиболее важных распределений в теории вероятностей, вышло далеко за рамки стандартных рамок одномерного (то есть одномерного) случая (случай 1). Все эти расширения также называются нормальными или гауссовскими законами, поэтому существует определенная двусмысленность в названиях.
- Многомерное нормальное распределение описывает закон Гаусса в k -мерном евклидовом пространстве . Вектор X ∈ R к является многомерно-нормально распределенным, если любая линейная комбинация его компонент Σ к
j =1 a j X j имеет (одномерное) нормальное распределение. Дисперсия X представляет собой k×k положительно определенную матрицу V. симметричную Многомерное нормальное распределение является частным случаем эллиптических распределений . Таким образом, его локусы изоплотности в случае k = 2 представляют собой эллипсы , а в случае произвольного k — эллипсоиды . - Выпрямленное распределение Гаусса - исправленная версия нормального распределения, в которой все отрицательные элементы сброшены до 0.
- Комплексное нормальное распределение имеет дело с комплексными нормальными векторами. Комплексный вектор X ∈ C к называется нормальным, если его действительная и мнимая компоненты совместно обладают 2k - мерным многомерным нормальным распределением. Ковариационно-дисперсионная структура X описывается двумя матрицами: матрицей дисперсии Γ и отношений матрицей C .
- Нормальное распределение матриц описывает случай нормально распределенных матриц.
- Гауссовы процессы — это нормально распределенные случайные процессы . Их можно рассматривать как элементы некоторого бесконечномерного гильбертова пространства H и, таким образом, они являются аналогами многомерных нормальных векторов для случая k = ∞ . Случайный элемент h ∈ H называется нормальным, если для любой константы a ∈ H скалярное произведение ( a , h ) имеет (одномерное) нормальное распределение. Дисперсионную структуру такого гауссовского случайного элемента можно описать с помощью линейного ковариационного оператора K: H → H. Некоторые гауссовские процессы стали достаточно популярными, чтобы иметь собственные названия:
- Гауссово q-распределение — это абстрактная математическая конструкция, представляющая собой q-аналог нормального распределения.
- является q-гауссиан аналогом распределения Тсаллиса в том смысле, что он максимизирует энтропию Тсаллиса , и является одним из типов распределения Тсаллиса . Это распределение отличается от приведенного выше гауссова q-распределения .
- Распределение Каниадакиса κ -Гаусса является обобщением распределения Гаусса, которое возникает из статистики Каниадакиса , являющейся одним из распределений Каниадакиса .
Случайная величина X имеет нормальное распределение, состоящее из двух частей, если она имеет распределение


где µ — среднее значение, а σ 1 2 и σ 2 2 — это дисперсии распределения слева и справа от среднего значения соответственно.
Были определены среднее значение, дисперсия и третий центральный момент этого распределения. [49]


![{\displaystyle \operatorname {T} (X)={\sqrt {\frac {2}{\pi }}}(\sigma _{2}-\sigma _{1})\left[\left({\ frac {4}{\pi }}-1\right)(\sigma _{2}-\sigma _{1})^{2}+\sigma _{1}\sigma _{2}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9959f2c5186e2ed76884054edaf837a602ac6fac)
где E( X ), V( X ) и T( X ) — среднее значение, дисперсия и третий центральный момент соответственно.
Одним из основных практических применений закона Гаусса является моделирование эмпирических распределений множества различных случайных величин, встречающихся на практике. В таком случае возможным расширением будет более богатое семейство распределений, имеющее более двух параметров и, следовательно, способное более точно соответствовать эмпирическому распределению. Примеры таких расширений:
- Распределение Пирсона — семейство вероятностных распределений с четырьмя параметрами, которые расширяют нормальный закон, включив в него различные значения асимметрии и эксцесса.
- Обобщенное нормальное распределение , также известное как экспоненциальное степенное распределение, допускает хвосты распределения с более толстыми или более тонкими асимптотическим поведением.
Статистический вывод
[ редактировать ]Оценка параметров
[ редактировать ]Часто мы не знаем параметров нормального распределения, но вместо этого хотим их оценить . То есть иметь образец от нормального населения, мы хотели бы узнать примерные значения параметров и . Стандартным подходом к этой проблеме является метод максимального правдоподобия , который требует максимизации логарифмической функции правдоподобия : Взяв производные по и и решение полученной системы условий первого порядка дает оценки максимального правдоподобия :



Затем заключается в следующем:

![{\displaystyle \ln {\mathcal {L}}({\hat {\mu }},{\hat {\sigma }}^{2})=(-n/2)[\ln(2\pi {\hat {\sigma }}^{2})+1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/561353e6bc80d226fddd9510be61d21bc67b3aee)
Выборочное среднее
[ редактировать ]Оценщик называется выборочным средним , поскольку оно является средним арифметическим всех наблюдений. Статистика является полным и достаточным для , и, следовательно, по теореме Лемана–Шеффе , — это несмещенная оценка равномерно минимальной дисперсии (UMVU). [50] В конечных выборках оно распределяется нормально: Дисперсия этой оценки равна µμ -элементу обратной информационной матрицы Фишера . Это означает, что оценка эффективна для конечной выборки . Практическое значение имеет тот факт, что ошибка стандартная пропорционально , то есть, если кто-то хочет уменьшить стандартную ошибку в 10 раз, необходимо увеличить количество точек в выборке в 100 раз. Этот факт широко используется при определении размеров выборки для опросов общественного мнения и числа испытания в моделировании Монте-Карло .





С точки зрения асимптотической теории , является непротиворечивым , то есть сходится по вероятности к как . Оценка также асимптотически нормальна , что является простым следствием того факта, что она нормальна в конечных выборках:


Выборочная дисперсия
[ редактировать ]Оценщик называется выборочной дисперсией , поскольку это дисперсия выборки ( ). На практике вместо . Эта другая оценка обозначается , а также называется выборочной дисперсией , что представляет собой определенную неоднозначность в терминологии; его квадратный корень называется выборочным стандартным отклонением . Оценщик отличается от имея ( n − 1) вместо n в знаменателе (так называемая поправка Бесселя ): Разница между и становится пренебрежимо малым для n больших . Однако в конечных выборках мотивация использования заключается в том, что это несмещенная оценка основного параметра , тогда как является предвзятым. Кроме того, по теореме Лемана–Шеффе оценка является равномерно несмещенной минимальной дисперсией ( UMVU ), [50] что делает его «лучшим» оценщиком среди всех несмещенных. Однако можно показать, что смещенная оценка лучше, чем с точки зрения критерия среднеквадратической ошибки (MSE). В конечных выборках оба и имеют масштабированное распределение хи-квадрат с ( n - 1) степенями свободы: Первое из этих выражений показывает, что дисперсия равно , что немного больше, чем σσ -элемент обратной информационной матрицы Фишера . Таким образом, не является эффективной оценкой , и более того, поскольку является UMVU, мы можем заключить, что эффективная оценка конечной выборки для не существует.






Применяя асимптотическую теорию, обе оценки и непротиворечивы, то есть сходятся по вероятности к как размер выборки . Обе оценки также асимптотически нормальны: В частности, обе оценки асимптотически эффективны для .

Доверительные интервалы
[ редактировать ]По теореме Кокрена для нормальных распределений выборочное среднее и выборочная дисперсия s 2 независимы , а это означает , не дает никакой выгоды что рассмотрение их совместного распределения . Существует также обратная теорема: если в выборке выборочное среднее и выборочная дисперсия независимы, то выборка должна иметь нормальное распределение. Независимость между и s можно использовать для построения так называемой t-статистики : Эта величина t имеет t-распределение Стьюдента с ( n − 1) степенями свободы и является вспомогательной статистикой (независимой от значения параметров). Инвертирование распределения этой t -статистики позволит нам построить доверительный интервал для μ ; [51] аналогично, инвертируя χ 2 распределение статистики s 2 даст нам доверительный интервал для σ 2 : [52] где t k,p и χ 2
k,p квантили p ые - t- — и χ 2 -распределения соответственно. Эти доверительные интервалы имеют доверительный уровень 1 − α , что означает, что истинные значения μ и σ 2 выходят за пределы этих интервалов с вероятностью (или уровнем значимости ) α . На практике люди обычно принимают α = 5% , что приводит к доверительным интервалам 95%.

![{\displaystyle \mu \in \left[{\hat {\mu }}-t_{n-1,1-\alpha /2}{\frac {1}{\sqrt {n}}}s,{\ шляпа {\mu }}+t_{n-1,1-\alpha /2}{\frac {1}{\sqrt {n}}}s\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6e3068587bfbaf61a549a39b518757119bfb846)
![{\displaystyle \sigma ^{2}\in \left[{\frac {(n-1)s^{2}}{\chi _{n-1,1-\alpha /2}^{2}} },{\frac {(n-1)s^{2}}{\chi _{n-1,\alpha /2}^{2}}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3549a31cb861d9e479c232271cb88b019cfa9fd5)
Приближенные формулы можно вывести из асимптотических распределений и с 2 : Приближенные формулы становятся справедливыми при больших значениях n более удобны для ручного расчета, поскольку стандартные нормальные квантили zα и /2 не зависят от n . В частности, наиболее популярное значение α = 5% приводит к | г 0,025 | = 1,96 .
![{\displaystyle \mu \in \left[{\hat {\mu }}-|z_{\alpha /2}|{\frac {1}{\sqrt {n}}}s,{\hat {\mu }}+|z_{\alpha /2}|{\frac {1}{\sqrt {n}}}s\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e13883f93c0a1405e71bd105685ecac6b4c84089)
![{\displaystyle \sigma ^{2}\in \left[s^{2}-|z_{\alpha /2}|{\frac {\sqrt {2}}{\sqrt {n}}}s^{ 2},s^{2}+|z_{\alpha /2}|{\frac {\sqrt {2}}{\sqrt {n}}}s^{2}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e3e7c940eb3f6f50af62200ae75e10435ef8dfe6)
Тесты на нормальность
[ редактировать ]Критерии нормальности оценивают вероятность того, что данный набор данных { x 1 , ..., x n } имеет нормальное распределение. Обычно нулевая гипотеза H 0 заключается в том, что наблюдения распределяются нормально с неопределенным средним значением µ и дисперсией σ. 2 , по сравнению с альтернативой H a , что распределение является произвольным. Для решения этой проблемы было разработано множество тестов (более 40). Наиболее известные из них представлены ниже:
Диагностические графики более интуитивно привлекательны, но в то же время субъективны, поскольку они полагаются на неформальное человеческое суждение при принятии или отклонении нулевой гипотезы.
- График Q–Q , также известный как график нормальной вероятности или график ранки , представляет собой график отсортированных значений из набора данных в сравнении с ожидаемыми значениями соответствующих квантилей из стандартного нормального распределения. То есть это график точки вида (Φ −1 ( p k ), x ( k ) ), где точки построения p k равны p k = ( k − α )/( n + 1 − 2 α ), а α — константа корректировки, которая может принимать любое значение от 0 до 1. Если нулевая гипотеза верна, нанесенные точки должны примерно лежать на прямой линии.
- График P-P - аналогичен графику Q-Q, но используется гораздо реже. Этот метод заключается в нанесении точек (Φ( z ( k ) ), p k ), где . Для нормально распределенных данных этот график должен лежать на линии под углом 45° между (0, 0) и (1, 1).

Тесты на соответствие :
Моментные тесты :
- Критерий К-квадрата Д'Агостино
- Тест Жарка-Бера
- Критерий Шапиро-Уилка : основан на том факте, что линия на графике Q-Q имеет наклон σ . Тест сравнивает оценку этого наклона методом наименьших квадратов со значением выборочной дисперсии и отклоняет нулевую гипотезу, если эти две величины значительно различаются.
Тесты, основанные на эмпирической функции распределения :
Байесовский анализ нормального распределения
[ редактировать ]Байесовский анализ нормально распределенных данных осложняется множеством различных возможностей, которые можно учитывать:
- Фиксированной величиной можно считать либо среднее значение, либо дисперсию, либо ни то, ни другое.
- Когда дисперсия неизвестна, анализ можно проводить непосредственно с точки зрения дисперсии или с точки зрения точности , обратной дисперсии. Причина выражения формул с точки зрения точности состоит в том, что анализ большинства случаев упрощается.
- как одномерные, так и многомерные случаи. Необходимо учитывать
- как сопряженные , так и неправильные априорные распределения . Неизвестным переменным могут быть присвоены
- Дополнительный набор случаев возникает в байесовской линейной регрессии , где в базовой модели предполагается нормальное распределение данных, а к коэффициентам регрессии ставятся нормальные априорные значения . Итоговый анализ аналогичен базовым случаям независимых одинаково распределенных данных.
Формулы для случаев нелинейной регрессии обобщены в сопряженной предыдущей статье.
Сумма двух квадратичных дробей
[ редактировать ]Скалярная форма
[ редактировать ]Следующая вспомогательная формула полезна для упрощения уравнений апостериорного обновления, которые в противном случае становятся довольно утомительными.

Это уравнение переписывает сумму двух квадратичных дробей по x, расширяя квадраты, группируя члены по x и дополняя квадрат . Обратите внимание на следующие сложные постоянные коэффициенты, связанные с некоторыми терминами:
- Фактор имеет форму средневзвешенного значения y и z .
- Это показывает, что этот фактор можно рассматривать как результат ситуации, когда обратные величины a и b складываются напрямую, поэтому, чтобы объединить сами a и b , необходимо совершать возвратно-поступательные движения, складывать и снова возвращать результат, чтобы вернуться в оригинальные агрегаты. Именно такую операцию выполняет среднее гармоническое , поэтому неудивительно, что составляет половину среднего значений a b и . гармонического



Векторная форма
[ редактировать ]Аналогичную формулу можно записать для суммы двух векторных квадратиков: Если x , y , z — векторы длины k , а A и B — симметричные , обратимые матрицы размера , затем


где

Форма x ′ A x называется квадратичной формой и является скаляром : Другими словами, он суммирует все возможные комбинации произведений пар элементов из x с отдельным коэффициентом для каждой. Кроме того, поскольку , только сумма имеет значение для любых недиагональных элементов A , и нет потери общности, если предположить, A симметричен что . Более того, если A симметричен, то форма




Сумма отличий от среднего
[ редактировать ]Еще одна полезная формула выглядит следующим образом: где


С известной дисперсией
[ редактировать ]Для набора iid нормально распределенных точек данных X размера n , где каждая отдельная точка x следует с известной дисперсией σ 2 , сопряженное априорное распределение также имеет нормальное распределение.

Это можно показать проще, переписав дисперсию как точность , т. е. используя τ = 1/σ. 2 . Тогда, если и мы действуем следующим образом.


Во-первых, функция правдоподобия (используя приведенную выше формулу для суммы отличий от среднего):
![{\displaystyle {\begin{aligned}p(\mathbf {X} \mid \mu ,\tau )&=\prod _{i=1}^{n}{\sqrt {\frac {\tau }{2 \pi }}}\exp \left(-{\frac {1}{2}}\tau (x_{i}-\mu )^{2}\right)\\&=\left({\frac { \tau }{2\pi }}\right)^{n/2}\exp \left(-{\frac {1}{2}}\tau \sum _{i=1}^{n}(x_ {i}-\mu )^{2}\right)\\&=\left({\frac {\tau }{2\pi }}\right)^{n/2}\exp \left[-{ \frac {1}{2}}\tau \left(\sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2}+n({\bar {x}}-\mu )^{2}\right)\right].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c2bcd1c34520a24e29b758a0f7427e79e9d8a414)
Далее действуем следующим образом:
![{\displaystyle {\begin{aligned}p(\mu \mid \mathbf {X}) &\propto p(\mathbf {X} \mid \mu )p(\mu )\\&=\left({\ frac {\tau }{2\pi }}\right)^{n/2}\exp \left[-{\frac {1}{2}}\tau \left(\sum _{i=1}^ {n}(x_{i}-{\bar {x}})^{2}+n({\bar {x}}-\mu )^{2}\right)\right]{\sqrt {\ frac {\tau _{0}}{2\pi }}}\exp \left(-{\frac {1}{2}}\tau _{0}(\mu -\mu _{0})^ {2}\right)\\&\propto \exp \left(-{\frac {1}{2}}\left(\tau \left(\sum _{i=1}^{n}(x_{ i}-{\bar {x}})^{2}+n({\bar {x}}-\mu )^{2}\right)+\tau _{0}(\mu -\mu _ {0})^{2}\right)\right)\\&\propto \exp \left(-{\frac {1}{2}}\left(n\tau ({\bar {x}}- \mu )^{2}+\tau _{0}(\mu -\mu _{0})^{2}\right)\right)\\&=\exp \left(-{\frac {1 }{2}}(n\people +\people _{0})\left(\mu -{\dfrac {n\people {\bar {x}}+\people _{0}\mu _{0} }{n\people +\people _{0}}}\right)^{2}+{\frac {n\people \people _{0}}}{n\people +\people _{0}}} ( {\bar {x}}-\mu _{0})^{2}\right)\\&\propto \exp \left(-{\frac {1}{2}}(n\tau +\ tau _{0})\left(\mu -{\dfrac {n\human {\bar {x}}+\human _{0}\mu _{0}}{n\human +\human _{0 } }}\right)^{2}\right)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/96e309ead00fbc8603eced5342aa5df534522d6a)
В приведенном выше выводе мы использовали приведенную выше формулу для суммы двух квадратичных дробей и исключили все постоянные факторы, не включающие µ . Результатом является ядро нормального распределения со средним значением и точность , то есть



Это можно записать как набор байесовских уравнений обновления апостериорных параметров с точки зрения априорных параметров:
![{\displaystyle {\begin{aligned}\tau _{0}'&=\tau _{0}+n\tau \\[5pt]\mu _{0}'&={\frac {n\tau { \bar {x}}+\tau _{0}\mu _{0}}{n\tau +\tau _{0}}}\\[5pt]{\bar {x}}&={\frac {1}{n}}\sum _{i=1}^{n}x_{i}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a6cfbdf504b1a9ce4cbe79561b4ae983fdf7271d)
То есть объединить n точек данных с общей точностью nτ (или, что то же самое, с общей дисперсией n / σ 2 ) и среднее значение значений , получить новую общую точность, просто добавив общую точность данных к предыдущей общей точности, и сформировать новое среднее значение через взвешенное по точности среднее значение , т.е. средневзвешенное среднее значение данных и априорное среднее значение, каждое из которых взвешено по соответствующая общая точность. Это имеет логический смысл, если рассматривать точность как показатель достоверности наблюдений: в распределении апостериорного среднего каждый из входных компонентов взвешивается по его достоверности, а достоверность этого распределения представляет собой сумму отдельных достоверностей. . (Для интуитивного понимания этого сравните выражение «целое больше суммы своих частей». Кроме того, учтите, что знание апостериорного происходит из комбинации знаний априорного и правдоподобия. , поэтому вполне логично, что мы более уверены в нем, чем в любом из его компонентов.)

удобнее проводить байесовский анализ сопряженных априорных значений Приведенная выше формула показывает, почему с точки зрения точности для нормального распределения. Апостериорная точность представляет собой просто сумму априорной точности и точности правдоподобия, а апостериорное среднее вычисляется посредством взвешенного по точности среднего значения, как описано выше. Те же самые формулы можно записать с точки зрения дисперсии, выполняя возвратно-поступательные движения со всеми точностью, что приводит к более уродливым формулам.
![{\displaystyle {\begin{aligned}{\sigma _{0}^{2}}'&={\frac {1}{{\frac {n}{\sigma ^{2}}}+{\frac {1}{\sigma _{0}^{2}}}}}\\[5pt]\mu _{0}'&={\frac {{\frac {n{\bar {x}}}{ \sigma ^{2}}}+{\frac {\mu _{0}}{\sigma _{0}^{2}}}}{{\frac {n}{\sigma ^{2}}} +{\frac {1}{\sigma _{0}^{2}}}}\\[5pt]{\bar {x}}&={\frac {1}{n}}\sum _{ я=1}^{n}x_{i}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ea454c8840683777ce8192d9ae63068c63962858)
С известным средним значением
[ редактировать ]Для набора iid нормально распределенных точек данных X размера n , где каждая отдельная точка x следует с известным средним значением ц сопряженное априорное значение имеет дисперсии обратное гамма-распределение или масштабированное обратное распределение хи-квадрат . Они эквивалентны, за исключением того, что имеют разные параметризации . Хотя обратная гамма используется чаще, для удобства мы используем масштабированный обратный хи-квадрат. Приор для σ 2 заключается в следующем:
![{\displaystyle p(\sigma ^{2}\mid \nu _{0},\sigma _{0}^{2}) = {\frac {(\sigma _{0}^{2}{\frac {\nu _{0}}{2}})^{\nu _{0}/2}}{\Gamma \left({\frac {\nu _{0}}{2}}\right)} }~{\frac {\exp \left[{\frac {-\nu _{0}\sigma _{0}^{2}}{2\sigma ^{2}}}\right]}{(\ сигма ^{2})^{1+{\frac {\nu _{0}}{2}}}}}\propto {\frac {\exp \left[{\frac {-\nu _{0} \sigma _{0}^{2}}{2\sigma ^{2}}}\right]}{(\sigma ^{2})^{1+{\frac {\nu _{0}}{ 2}}}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef2528fe4774a93087d4adae570ef9ab84707f52)
Функция правдоподобия , приведенная выше, записанная через дисперсию, равна:
![{\displaystyle {\begin{aligned}p(\mathbf {X} \mid \mu ,\sigma ^{2}) &=\left({\frac {1}{2\pi \sigma ^{2}} }\right)^{n/2}\exp \left[-{\frac {1}{2\sigma ^{2}}}\sum _{i=1}^{n}(x_{i}- \mu )^{2}\right]\\&=\left({\frac {1}{2\pi \sigma ^{2}}}\right)^{n/2}\exp \left[- {\frac {S}{2\sigma ^{2}}}\right]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc06aa31588bba03e4748f8f345f0638a75dc156)
где

Затем:
![{\displaystyle {\begin{aligned}p(\sigma ^{2}\mid \mathbf {X}) &\propto p(\mathbf {X} \mid \sigma ^{2})p(\sigma ^{ 2})\\&=\left({\frac {1}{2\pi \sigma ^{2}}}\right)^{n/2}\exp \left[-{\frac {S}{ 2\sigma ^{2}}}\right]{\frac {(\sigma _{0}^{2}{\frac {\nu _{0}}{2}})^{\frac {\nu _{0}}{2}}}{\Gamma \left({\frac {\nu _{0}}{2}}\right)}}~{\frac {\exp \left[{\frac { -\nu _{0}\sigma _{0}^{2}}{2\sigma ^{2}}}\right]}{(\sigma ^{2})^{1+{\frac {\ nu _{0}}{2}}}}}\\&\propto \left({\frac {1}{\sigma ^{2}}}\right)^{n/2}{\frac {1 }{(\sigma ^{2})^{1+{\frac {\nu _{0}}{2}}}}}\exp \left[-{\frac {S}{2\sigma ^{ 2}}}+{\frac {-\nu _{0}\sigma _{0}^{2}}{2\sigma ^{2}}}\right]\\&={\frac {1} {(\sigma ^{2})^{1+{\frac {\nu _{0}+n}{2}}}}}\exp \left[-{\frac {\nu _{0}\ сигма _{0}^{2}+S}{2\sigma ^{2}}}\right]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/381c1b93f6dc76e2cdca9f3f1f77132dd51dc55f)
Вышеупомянутое также представляет собой масштабированное обратное распределение хи-квадрат, где

или эквивалентно

Если провести повторную параметризацию с точки зрения обратного гамма-распределения , результат будет следующим:

С неизвестным средним значением и неизвестной дисперсией
[ редактировать ]Для набора iid нормально распределенных точек данных X размера n , где каждая отдельная точка x следует с неизвестным средним значением µ и неизвестной дисперсией σ 2 , комбинированное (многомерное) сопряженное априорное значение помещается над средним значением и дисперсией, состоящее из нормального обратного гамма-распределения .Логически это происходит следующим образом:
- Из анализа случая с неизвестным средним значением, но известной дисперсией, мы видим, что уравнения обновления включают в себя достаточную статистику, рассчитанную на основе данных, состоящих из среднего значения точек данных и общей дисперсии точек данных, вычисленных, в свою очередь, на основе известной дисперсии. разделить на количество точек данных.
- Из анализа случая с неизвестной дисперсией, но известным средним значением, мы видим, что уравнения обновления включают достаточную статистику по данным, состоящую из количества точек данных и суммы квадратичных отклонений .
- Имейте в виду, что значения апостериорного обновления служат априорным распределением при обработке дальнейших данных. Таким образом, мы должны логически думать о наших априорных значениях с точки зрения только что описанной достаточной статистики, сохраняя при этом в максимально возможной степени ту же семантику.
- Чтобы справиться со случаем, когда и среднее значение, и дисперсия неизвестны, мы могли бы разместить независимые априорные значения над средним значением и дисперсией с фиксированными оценками среднего среднего значения, общей дисперсии, количества точек данных, используемых для вычисления априорной дисперсии, и суммы квадратичных отклонений. . Однако обратите внимание, что в действительности общая дисперсия среднего значения зависит от неизвестной дисперсии, а сумма квадратов отклонений, которая входит в априорную дисперсию (по-видимому), зависит от неизвестного среднего значения. На практике последняя зависимость относительно не важна: сдвиг фактического среднего значения смещает сгенерированные точки на равную величину, и в среднем квадраты отклонений останутся прежними. Однако это не относится к общей дисперсии среднего значения: по мере увеличения неизвестной дисперсии общая дисперсия среднего будет пропорционально увеличиваться, и мы хотели бы уловить эту зависимость.
- Это предполагает, что мы создаем условное априорное значение среднего значения для неизвестной дисперсии с гиперпараметром, указывающим среднее значение псевдонаблюдений , связанных с априорным значением, и другим параметром, указывающим количество псевдонаблюдений. Это число служит параметром масштабирования дисперсии, позволяя контролировать общую дисперсию среднего значения относительно фактического параметра дисперсии. Априорное значение дисперсии также имеет два гиперпараметра: один определяет сумму квадратов отклонений псевдонаблюдений, связанных с априорным, а другой еще раз указывает количество псевдонаблюдений. Каждый из априорных значений имеет гиперпараметр, определяющий количество псевдонаблюдений, и в каждом случае он контролирует относительную дисперсию этого априорного значения. Они задаются как два отдельных гиперпараметра, так что дисперсию (т. е. достоверность) двух априорных значений можно контролировать отдельно.
- Это немедленно приводит к нормальному обратному гамма-распределению , которое является продуктом двух только что определенных распределений с использованием сопряженных априорных значений ( обратное гамма-распределение по дисперсии и нормальное распределение по среднему значению, зависящее от дисперсии) и с теми же четырьмя только что определенными параметрами.
Априоры обычно определяются следующим образом:

Уравнения обновления могут быть выведены и выглядят следующим образом:

К соответствующему количеству псевдонаблюдений добавляется количество реальных наблюдений. Новый средний гиперпараметр снова представляет собой средневзвешенное значение, на этот раз взвешенное по относительному количеству наблюдений. Наконец, обновление для аналогичен случаю с известным средним значением, но в этом случае сумма квадратов отклонений берется относительно среднего значения наблюдаемых данных, а не истинного среднего значения, и в результате необходимо добавить новый член взаимодействия, чтобы позаботиться о дополнительный источник ошибок, возникающий из-за отклонения между априорным и средним значением данных.

Предыдущие распределения
![{\displaystyle {\begin{aligned}p(\mu \mid \sigma ^{2};\mu _{0},n_{0}) &\sim {\mathcal {N}}(\mu _{0) },\sigma ^{2}/n_{0})={\frac {1}{\sqrt {2\pi {\frac {\sigma^{2}}{n_{0}}}}}}\ exp \left(-{\frac {n_{0}}{2\sigma^{2}}}(\mu -\mu _{0})^{2}\right)\\&\propto(\sigma ^{2})^{-1/2}\exp \left(-{\frac {n_{0}}{2\sigma ^{2}}}(\mu -\mu _{0})^{ 2}\right)\\p(\sigma ^{2};\nu _{0},\sigma _{0}^{2}) &\sim I\chi ^{2}(\nu _{0 },\sigma _{0}^{2})=IG(\nu _{0}/2,\nu _{0}\sigma _{0}^{2}/2)\\&={\ frac {(\sigma_{0}^{2}\nu_{0}/2)^{\nu_{0}/2}}{\gamma(\nu_{0}/2)}}~ {\frac { \exp \left[{\frac {-\nu _{0}\sigma_{0}^{2}}{2\sigma^{2}}}\right]}{(\sigma^ {2})^ {1+\nu_{0}/2}}}\\&\propto {(\sigma^{2})^{-(1+\nu_{0}/2)}} \exp \left[{\ frac {-\nu _{0}\sigma_{0}^{2}}{2\sigma^{2}}}\right].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf7afb8e3b63fb1526171840344b32458e55cf8b)
Таким образом, совместным приором является
![{\displaystyle {\begin{aligned}p(\mu ,\sigma ^{2};\mu _{0},n_{0},\nu _{0},\sigma _{0}^{2} )&=p(\mu \mid \sigma ^{2};\mu _{0},n_{0})\,p(\sigma ^{2};\nu _{0},\sigma _{ 0}^{2})\\&\propto(\sigma^{2})^{-(\nu_{0}+3)/2}\exp \left[-{\frac {1}{2 \ сигма ^{2}}}\left(\nu_{0}\sigma_{0}^{2}+n_{0}(\mu -\mu _{0})^{2}\right) \right] .\end{выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b6f808161077baef3854dbfd90b870698d721090)
Функция правдоподобия из приведенного выше раздела с известной дисперсией:
![{\displaystyle {\begin{aligned}p(\mathbf {X} \mid \mu ,\sigma ^{2}) &=\left({\frac {1}{2\pi \sigma ^{2}} }\right)^{n/2}\exp \left[-{\frac {1}{2\sigma ^{2}}}\left(\sum _{i=1}^{n}(x_{ i}-\mu )^{2}\right)\right]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3d77342aadcb34c5d84418cecaefdb52842b6b7)
Записав это в терминах дисперсии, а не точности, мы получаем: где
![{\displaystyle {\begin{aligned}p(\mathbf {X} \mid \mu ,\sigma ^{2}) &=\left({\frac {1}{2\pi \sigma ^{2}} }\right)^{n/2}\exp \left[-{\frac {1}{2\sigma ^{2}}}\left(\sum _{i=1}^{n}(x_{ i}-{\bar {x}})^{2}+n({\bar {x}}-\mu )^{2}\right)\right]\\&\propto {\sigma ^{2 }}^{-n/2}\exp \left[-{\frac {1}{2\sigma ^{2}}}\left(S+n({\bar {x}}-\mu )^ {2}\right)\right]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/29b915f070b522a1e9f419be05624c86c854ca14)

Следовательно, апостериорное (опуская гиперпараметры как обуславливающие факторы):
![{\displaystyle {\begin{aligned}p(\mu,\sigma ^{2}\mid \mathbf {X}) &\propto p(\mu,\sigma ^{2})\,p(\mathbf { X} \mid \mu ,\sigma ^{2})\\&\propto (\sigma ^{2})^{-(\nu _{0}+3)/2}\exp \left[-{ \frac {1}{2\sigma ^{2}}}\left(\nu _{0}\sigma _{0}^{2}+n_{0}(\mu -\mu _{0}) ^{2}\right)\right]{\sigma ^{2}}^{-n/2}\exp \left[-{\frac {1}{2\sigma ^{2}}}\left( S+n({\bar {x}}-\mu )^{2}\right)\right]\\&=(\sigma ^{2})^{-(\nu _{0}+n+ 3)/2}\exp \left[-{\frac {1}{2\sigma ^{2}}}\left(\nu _{0}\sigma _{0}^{2}+S+n_ {0}(\mu -\mu _{0})^{2}+n({\bar {x}}-\mu )^{2}\right)\right]\\&=(\sigma ^ {2})^{-(\nu _{0}+n+3)/2}\exp \left[-{\frac {1}{2\sigma ^{2}}}\left(\nu _ {0}\sigma _{0}^{2}+S+{\frac {n_{0}n}{n_{0}+n}}(\mu _{0}-{\bar {x}}) ^{2}+(n_{0}+n)\left(\mu -{\frac {n_{0}\mu _{0}+n{\bar {x}}}{n_{0}+n }}\right)^{2}\right)\right]\\&\propto (\sigma ^{2})^{-1/2}\exp \left[-{\frac {n_{0}+ n}{2\sigma ^{2}}}\left(\mu -{\frac {n_{0}\mu _{0}+n{\bar {x}}}{n_{0}+n} }\right)^{2}\right]\\&\quad \times (\sigma ^{2})^{-(\nu _{0}/2+n/2+1)}\exp \left [-{\frac {1}{2\sigma ^{2}}}\left(\nu _{0}\sigma _{0}^{2}+S+{\frac {n_{0}n}{ n_{0}+n}}(\mu _{0}-{\bar {x}})^{2}\right)\right]\\&={\mathcal {N}}_{\mu \ Mid \sigma ^{2}}\left({\frac {n_{0}\mu _{0}+n{\bar {x}}}{n_{0}+n}},{\frac {\ сигма ^{2}}{n_{0}+n}}\right)\cdot {\rm {IG}}_{\sigma ^{2}}\left({\frac {1}{2}}( \nu _{0}+n),{\frac {1}{2}}\left(\nu _{0}\sigma _{0}^{2}+S+{\frac {n_{0}n }{n_{0}+n}}(\mu _{0}-{\bar {x}})^{2}\right)\right).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cad9489034d77d53c12c7ee6044f712cfdb77831)
Другими словами, апостериорное распределение имеет вид произведения нормального распределения по раз обратное гамма-распределение по , с параметрами, такими же, как приведенные выше уравнения обновления.


Возникновение и применение
[ редактировать ]Возникновение нормального распределения в практических задачах можно условно разделить на четыре категории:
- Точно нормальные распределения;
- Приблизительно нормальные законы, например, когда такое приближение оправдано центральной предельной теоремой ; и
- Распределения моделируются как нормальные: нормальное распределение представляет собой распределение с максимальной энтропией для заданного среднего значения и дисперсии.
- Проблемы регрессии – нормальное распределение обнаруживается после того, как систематические эффекты были достаточно хорошо смоделированы.
Точная нормальность
[ редактировать ]
Некоторые величины в физике распределяются нормально, как это впервые продемонстрировал Джеймс Клерк Максвелл . Примеры таких величин:
- Функция плотности вероятности основного состояния квантового гармонического осциллятора .
- Положение частицы, испытывающей диффузию . Если изначально частица находится в конкретной точке (то есть ее распределение вероятностей — дельта-функция Дирака ), то по истечении времени t ее местоположение описывается нормальным распределением с дисперсией t , которое удовлетворяет уравнению диффузии . Если начальное местоположение задано некоторой функцией плотности то плотность в момент времени t представляет собой свертку g , и нормальной функции плотности вероятности.


Приблизительная нормальность
[ редактировать ]Приблизительно нормальное распределение встречается во многих ситуациях, как это объясняется центральной предельной теоремой . Когда результат создается множеством небольших эффектов, действующих аддитивно и независимо , его распределение будет близко к нормальному. Нормальное приближение не будет действительным, если эффекты действуют мультипликативно (а не аддитивно) или если существует одно внешнее влияние, которое имеет значительно большую величину, чем остальные эффекты.
- В задачах счета, где центральная предельная теорема включает приближение от дискретного к континуальному и где бесконечно делимые и разложимые задействованы распределения, такие как
- Биномиальные случайные величины , связанные с бинарными переменными отклика;
- Случайные величины Пуассона , связанные с редкими событиями;
- Тепловое излучение имеет распределение Бозе-Эйнштейна на очень коротких временных масштабах и нормальное распределение на более длительных временных масштабах из-за центральной предельной теоремы.
Предполагаемая нормальность
[ редактировать ]
Я могу лишь признать появление нормальной кривой – лапласовой кривой ошибок – весьма ненормальным явлением. В некоторых дистрибутивах он примерно приближается к ; по этой причине, а также ввиду его прекрасной простоты, мы, возможно, можем использовать его в качестве первого приближения, особенно в теоретических исследованиях.
Существуют статистические методы эмпирической проверки этого предположения; см. выше раздел «Тестирование нормальности» .
- В биологии логарифмы (после разделения на мужские различных переменных имеют тенденцию иметь нормальное распределение, то есть они имеют тенденцию иметь логарифмически нормальное распределение и женские субпопуляции), в том числе примеры:
- Меры размера живой ткани (длина, высота, площадь кожи, вес); [53]
- Длина в придатков инертных (волос, когтей, ногтей, зубов) биологических особей направлении роста ; предположительно, под эту категорию подпадает и толщина древесной коры;
- Определенные физиологические измерения, такие как артериальное давление взрослых людей.
- В финансах, в частности в модели Блэка-Шоулза , изменения логарифма обменных курсов, индексов цен и индексов фондового рынка считаются нормальными (эти переменные ведут себя как сложные проценты , а не как простые проценты, и поэтому являются мультипликативными). Некоторые математики, такие как Бенуа Мандельброт, утверждали, что лог-распределения Леви с тяжелыми хвостами были бы более подходящей моделью, в частности, для анализа обвалов фондового рынка . Использование предположения о нормальном распределении в финансовых моделях также подвергалось критике со стороны Нассима Николаса Талеба в его работах.
- Ошибки измерений в физических экспериментах часто моделируются нормальным распределением. Такое использование нормального распределения не означает, что предполагается, что ошибки измерения имеют нормальное распределение; скорее, использование нормального распределения дает наиболее консервативные прогнозы, возможные при условии знания только среднего значения и дисперсии ошибок. [54]
- При стандартизированном тестировании результаты могут иметь нормальное распределение, выбирая количество и сложность вопросов (как в тесте IQ ) или преобразуя необработанные результаты теста в выходные баллы, подгоняя их к нормальному распределению. Например, традиционный диапазон SAT 200–800 основан на нормальном распределении со средним значением 500 и стандартным отклонением 100.

- Многие оценки получены на основе нормального распределения, включая процентильные ранги (процентили или квантили), эквиваленты нормальной кривой , станины , z-показатели и T-показатели. Кроме того, некоторые поведенческие статистические процедуры предполагают, что баллы распределяются нормально; например, t-тесты и ANOVA . Оценивание по кривой колокола присваивает относительные оценки на основе нормального распределения баллов.
- В гидрологии распределение долговременного речного стока или осадков, например, месячных и годовых сумм, часто считается практически нормальным в соответствии с центральной предельной теоремой . [55] Синее изображение, сделанное с помощью CumFreq , иллюстрирует пример подбора нормального распределения к ранжированным октябрьским осадкам, показывающим 90% доверительный интервал на основе биномиального распределения . Данные об осадках представлены в виде координат на графике в рамках кумулятивного частотного анализа .
Методологические проблемы и экспертная оценка
[ редактировать ]Джон Иоаннидис утверждал , что использование нормально распределенных стандартных отклонений в качестве стандартов для проверки результатов исследований оставляет непроверенными фальсифицируемые предсказания о явлениях, которые обычно не распределяются. Сюда относятся, например, явления, которые возникают только при наличии всех необходимых условий и одно не может быть заменено другим путем сложения, и явления, которые не распределены случайным образом. Иоаннидис утверждает, что проверка, ориентированная на стандартное отклонение, создает ложную видимость достоверности гипотез и теорий, в которых некоторые, но не все фальсифицируемые прогнозы нормально распределены, поскольку часть фальсифицируемых прогнозов, против которых имеются доказательства, может, а в некоторых случаях, находится в ненормально распределенные части диапазона фальсифицируемых предсказаний, а также безосновательное отклонение гипотез, для которых ни одно из фальсифицируемых предсказаний обычно не распределяется так, как если бы они были нефальсифицируемы, тогда как на самом деле они делают фальсифицируемые предсказания. Иоаннидис утверждает, что многие случаи принятия взаимоисключающих теорий как подтвержденные исследовательскими журналами вызваны неспособностью журналов принять эмпирические фальсификации предсказаний с ненормально распределенным распределением, а не потому, что взаимоисключающие теории верны, чего они не могут сделать. быть, хотя две взаимоисключающие теории могут быть как неправильными, так и третья правильной. [56]
Вычислительные методы
[ редактировать ]Генерация значений из нормального распределения
[ редактировать ]
В компьютерном моделировании, особенно в приложениях метода Монте-Карло , часто желательно генерировать значения, которые имеют нормальное распределение. Все перечисленные ниже алгоритмы генерируют стандартные нормальные отклонения, поскольку N ( µ , σ 2 ) может быть сгенерирован как X = µ + σZ , где Z — стандартная нормаль. Все эти алгоритмы полагаются на наличие генератора случайных чисел U, способного генерировать однородные случайные величины.
- Самый простой метод основан на свойстве преобразования интеграла вероятности : если U распределено равномерно на (0,1), то Φ −1 ( U ) будет иметь стандартное нормальное распределение. Недостатком этого метода является то, что он основан на вычислении пробит-функции Φ −1 , что невозможно сделать аналитически. Некоторые приближенные методы описаны у Харта (1968) и в статье erf . Вичура предлагает быстрый алгоритм вычисления этой функции с точностью до 16 знаков после запятой. [57] который используется R для вычисления случайных величин нормального распределения.
- Простой в программировании приближенный подход , основанный на центральной предельной теореме, заключается в следующем: сгенерируйте 12 равномерных отклонений U (0,1), сложите их все и вычтите 6 – полученная случайная величина будет иметь примерно стандартное нормальное распределение. По правде говоря, распределение будет Ирвина-Холла , которое представляет собой 12-секционное полиномиальное приближение одиннадцатого порядка к нормальному распределению. Это случайное отклонение будет иметь ограниченный диапазон (-6, 6). [58] Обратите внимание, что при истинно нормальном распределении только 0,00034% всех выборок выходят за пределы ±6σ.
- Метод Бокса – Мюллера использует два независимых случайных числа U и V распределенных , равномерно по (0,1). Тогда две случайные величины X и Y оба будут иметь стандартное нормальное распределение и будут независимыми . Эта формулировка возникает потому, что для двумерного нормального случайного вектора ( X , Y ) квадрат нормы X 2 + И 2 будет иметь распределение хи-квадрат с двумя степенями свободы, которое представляет собой легко генерируемую экспоненциальную случайную величину, соответствующую величине −2 ln( U ) в этих уравнениях; и угол равномерно распределен по кругу, выбранному случайной величиной V .
- представляет Полярный метод Марсальи собой модификацию метода Бокса – Мюллера, которая не требует вычисления функций синуса и косинуса. В этом методе U и V извлекаются из равномерного (−1,1) распределения, а затем S = U 2 + V 2 вычисляется. Если S больше или равно 1, метод начинается заново, в противном случае две величины возвращаются. Опять же, X и Y — независимые стандартные нормальные случайные величины.
- Метод отношений [59] это метод отказа. Алгоритм действует следующим образом:
- Сгенерируйте два независимых равномерных отклонения U и V ;
- Вычислить X = √ 8/ e ( V - 0,5)/ U ;
- Необязательно: если X 2 ≤ 5 − 4 е 1/4 Затем вы принимаете X и завершаете алгоритм;
- Необязательно: если X 2 ≥ 4 е −1.35 / U + 1,4, затем отклоняем X и начинаем заново с шага 1;
- Если Х 2 ≤ −4 ln U, тогда примите X , иначе начните алгоритм заново.
- Два дополнительных шага позволяют в большинстве случаев избежать вычисления логарифма на последнем шаге. Эти шаги можно значительно улучшить [60] так что логарифм вычисляется редко.
- Алгоритм зиккурата [61] быстрее, чем преобразование Бокса-Мюллера, но при этом является точным. Примерно в 97% всех случаев он использует только два случайных числа: одно случайное целое и одно случайное равномерное, одно умножение и проверку if. Лишь в 3% случаев, когда комбинация этих двух факторов выходит за рамки «ядра зиккурата» (своего рода отбраковочная выборка с использованием логарифмов), приходится использовать экспоненту и более однородные случайные числа.
- Целочисленную арифметику можно использовать для выборки из стандартного нормального распределения. [62] Этот метод точен в том смысле, что он удовлетворяет условиям идеального приближения ; [63] т. е. это эквивалентно выборке действительного числа из стандартного нормального распределения и округлению его до ближайшего представимого числа с плавающей запятой.
- Также есть расследование [64] в связь между быстрым преобразованием Адамара и нормальным распределением, поскольку преобразование использует только сложение и вычитание, и согласно центральной предельной теореме случайные числа практически из любого распределения будут преобразованы в нормальное распределение. В этом отношении серию преобразований Адамара можно комбинировать со случайными перестановками, чтобы превратить произвольные наборы данных в нормально распределенные данные.


Численные аппроксимации нормальной кумулятивной функции распределения и нормальной функции квантиля
[ редактировать ]Стандартная функция нормального кумулятивного распределения широко используется в научных и статистических вычислениях.
Значения Φ( x ) могут быть очень точно аппроксимированы различными методами, такими как численное интегрирование , ряд Тейлора , асимптотический ряд и цепные дроби . В зависимости от желаемого уровня точности используются различные приближения.
- Зелен и Северо (1964) дают аппроксимацию Φ( x ) для x > 0 с абсолютной ошибкой | ε ( Икс ) | < 7,5·10 −8 (алгоритм 26.2.17 ): где φ ( x ) — стандартная нормальная функция плотности вероятности, а b 0 = 0,2316419, b 1 = 0,319381530, b 2 = -0,356563782, b 3 = 1,781477937, b 4 = -1,821255978, b 5 = 1,330274429.
- Харт (1968) перечисляет несколько десятков аппроксимаций – с помощью рациональных функций, с экспонентами или без них – для функция erfc() . Его алгоритмы различаются по степени сложности и получаемой точности: максимальная абсолютная точность составляет 24 цифры. Алгоритм Уэста (2009) сочетает в себе алгоритм Харта 5666 с аппроксимацией цепной дроби в хвосте, чтобы обеспечить быстрый алгоритм вычислений с точностью до 16 цифр.
- Коди (1969), вспомнив, что решение Hart68 не подходит для erf, дает решение как для erf, так и для erfc с максимальной границей относительной ошибки с помощью рационального приближения Чебышева .
- Марсалья (2004) предложил простой алгоритм. [примечание 1] на основе разложения в ряд Тейлора для вычисления Φ( x ) с произвольной точностью. Недостатком этого алгоритма является сравнительно медленное время расчета (например, для вычисления функции с точностью до 16 знаков при x = 10 требуется более 300 итераций ).
- Научная библиотека GNU вычисляет значения стандартной нормальной кумулятивной функции распределения, используя алгоритмы Харта и аппроксимации с помощью полиномов Чебышева .
- Диа (2023) предлагает следующее приближение с максимальной относительной погрешностью менее по абсолютной величине: за и для ,









Шор (1982) представил простые аппроксимации, которые могут быть включены в модели стохастической оптимизации инженерных и эксплуатационных исследований, такие как проектирование надежности и анализ запасов. Обозначая p = Φ( z ) , простейшим приближением для функции квантиля является:
![{\displaystyle z=\Phi ^{-1}(p)=5,5556\left[1-\left({\frac {1-p}{p}}\right)^{0,1186}\right],\qquad p\geq 1/2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f2df7f1427d0c90d075faef38f4f5ab7acce5c9)
Это приближение дает для z максимальную абсолютную ошибку 0,026 (для 0,5 ≤ p ≤ 0,9999 , что соответствует 0 ≤ z ≤ 3,719 ). Для p < 1/2 замените p на 1 − p и поменяйте знак. Другое приближение, несколько менее точное, — это однопараметрическое приближение:
![{\displaystyle z=-0,4115\left\{{\frac {1-p}{p}}+\log \left[{\frac {1-p}{p}}\right]-1\right\} ,\qquad p\geq 1/2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e1edea9f990058f741db6735799c8b40999b833b)
Последнее послужило для получения простой аппроксимации интеграла потерь нормального распределения, определяемого формулой
![{\displaystyle {\begin{aligned}L(z)&=\int _{z}^{\infty }(uz)\varphi (u)\,du=\int _{z}^{\infty }[ 1-\Phi (u)]\,du\\[5pt]L(z)&\approx {\begin{cases}0.4115\left({\dfrac {p}{1-p}}\right)-z ,&p<1/2,\\\\0.4115\left({\dfrac {1-p}{p}}\right),&p\geq 1/2.\end{cases}}\\[5pt]{ \text{или, что то же самое,}}\\L(z)&\approx {\begin{cases}0.4115\left\{1-\log \left[{\frac {p}{1-p}}\right ]\right\},&p<1/2,\\\\0.4115{\dfrac {1-p}{p}},&p\geq 1/2.\end{cases}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e4b69fa586cffdfbbd40a94c65629726e4ae78bf)
Это приближение особенно точно для правого дальнего хвоста (максимальная ошибка 10 −3 для z≥1,4). Высокоточные аппроксимации кумулятивной функции распределения, основанные на методологии моделирования отклика (RMM, Shore, 2011, 2012), показаны в Shore (2005).
Еще несколько приближений можно найти по адресу: Функция ошибки#Приближение элементарными функциями . В частности, небольшая относительная ошибка во всей области для кумулятивной функции распределения и функция квантиля также достигается с помощью явно обратимой формулы Сергея Виницкого в 2008 году.

История
[ редактировать ]Разработка
[ редактировать ]Некоторые авторы [65] [66] приписывают заслугу открытия нормального распределения де Муавра , который в 1738 г. [примечание 2] опубликовал во втором издании своей «Доктрины шансов» исследование коэффициентов разложения биномиального ( a + b ) н . Де Муавр доказал, что средний член этого расширения имеет приблизительную величину , и что «Если m или 1 / 2 n — бесконечно большая Величина, то логарифм отношения, которое Член, отстоящий от середины на Интервал ℓ , имеет к среднему Члену, равен ." [67] Хотя эту теорему можно интерпретировать как первое неясное выражение нормального закона вероятности, Стиглер указывает, что сам де Муавр не интерпретировал свои результаты как нечто большее, чем приближенное правило для биномиальных коэффициентов, и, в частности, у де Муавра не было концепции функция плотности вероятности. [68]



В 1823 году Гаусс опубликовал свою монографию « Theoria Combinis Observeum erroribus minimis obnoxiae », где, среди прочего, он вводит несколько важных статистических понятий, таких как метод наименьших квадратов , метод максимального правдоподобия и нормальное распределение . Гаусс использовал M , M ′ , M ", ... для обозначения измерений некоторой неизвестной величины V и искал наиболее вероятную оценку этой величины: ту, которая максимизирует вероятность φ ( M − V ) · φ ( M ′ − V ) · φ ( M » − V ) · ... получения наблюдаемых экспериментальных результатов. В его обозначениях φΔ — функция плотности вероятности ошибок измерения величины Δ. Не зная, что представляет собой функция φ , Гаусс требует, чтобы его метод сводился к известному ответу: среднему арифметическому измеренных величин. [примечание 3] Исходя из этих принципов, Гаусс показывает, что единственным законом, который рационализирует выбор среднего арифметического в качестве оценки параметра местоположения, является нормальный закон ошибок: [69] где h - «мера точности наблюдений». Используя этот нормальный закон в качестве общей модели ошибок в экспериментах, Гаусс формулирует то, что сейчас известно как нелинейный взвешенный метод наименьших квадратов . [70]


Хотя Гаусс был первым, кто предложил закон нормального распределения, Лаплас внес значительный вклад. [примечание 4] Именно Лаплас впервые поставил задачу объединения нескольких наблюдений в 1774 году. [71] хотя его собственное решение привело к распределению Лапласа . Именно Лаплас первым вычислил значение интеграла ∫ e − т 2 dt = √ π в 1782 году, что обеспечивает константу нормализации нормального распределения. [72] Наконец, именно Лаплас в 1810 году доказал и представил академии фундаментальную центральную предельную теорему , подчеркивавшую теоретическую важность нормального распределения. [73]
Интересно отметить, что в 1809 году американский математик ирландского происхождения Роберт Адрейн опубликовал два проницательных, но ошибочных вывода нормального закона вероятности, одновременно и независимо от Гаусса. [74] Его работы оставались по большей части незамеченными научным сообществом, пока в 1871 году их не эксгумировал Аббе . [75]
В середине XIX века Максвелл продемонстрировал, что нормальное распределение является не только удобным математическим инструментом, но может встречаться и в природных явлениях: [76] Число частиц, скорость которых, разрешенная в определенном направлении, лежит между x и x + dx, равна

Мы
[ редактировать ]Сегодня эта концепция обычно известна на английском языке как нормальное распределение или распределение Гаусса . Другие менее распространенные названия включают распределение Гаусса, распределение Лапласа-Гаусса, закон ошибок, закон возможности ошибок, второй закон Лапласа и закон Гаусса.
Сам Гаусс, по-видимому, придумал этот термин в отношении «нормальных уравнений», используемых в его приложениях, причем «нормальный» имеет техническое значение «ортогональный», а не «обычный». [77] Однако к концу XIX века некоторые авторы [примечание 5] начал использовать название «нормальное распределение », где слово «нормальный» использовалось как прилагательное – этот термин теперь рассматривается как отражение того факта, что это распределение считалось типичным, распространенным – и, следовательно, нормальным. Пирс (один из этих авторов) однажды определил понятие «нормальности» следующим образом: «...«норма» — это не среднее (или какое-либо другое среднее значение) того, что происходит на самом деле, а то, что произойдет в долгосрочной перспективе. при определенных обстоятельствах». [78] Примерно на рубеже 20-го века Пирсон популяризировал термин «нормальный» для обозначения этого распределения. [79]
Много лет назад я назвал кривую Лапласа-Гаусса нормальной кривой, это название, хотя оно и избегает международного вопроса о приоритете, имеет тот недостаток, что заставляет людей поверить, что все другие распределения частот в том или ином смысле являются «ненормальными».
Кроме того, именно Пирсон первым записал распределение в терминах стандартного отклонения σ в современных обозначениях. Вскоре после этого, в 1915 году, Фишер добавил в формулу нормального распределения параметр местоположения, выразив его так, как он пишется сейчас:

Термин «стандартное нормальное», обозначающий нормальное распределение с нулевым средним значением и единичной дисперсией, стал широко использоваться примерно в 1950-х годах, появившись в популярных учебниках П. Г. Хоэля (1947) « Введение в математическую статистику» и А. М. Муда (1950) « Введение в математическую статистику ». Теория статистики . [80]
См. также
[ редактировать ]- Распределение Бейтса - аналогично распределению Ирвина – Холла, но масштабировано обратно в диапазон от 0 до 1.
- Проблема Беренса-Фишера - давняя проблема проверки того, имеют ли две нормальные выборки с разными дисперсиями одинаковые средние значения;
- Расстояние Бхаттачарьи - метод, используемый для разделения смесей нормальных распределений.
- Теорема Эрдеша – Каца - о возникновении нормального распределения в теории чисел.
- Полная ширина на половине максимума
- Размытие по Гауссу — свертка , использующая в качестве ядра нормальное распределение.
- Модифицированное полунормальное распределение [81] с PDF-файлом на дается как , где обозначает Пси-функцию Фокса–Райта .
- Нормально распределенные и некоррелированные не подразумевают независимость.
- Отношение нормального распределения
- Взаимное нормальное распределение
- Стандартный обычный стол
- Лемма Штейна
- Субгауссово распределение
- Сумма нормально распределенных случайных величин
- Распределение Твиди . Нормальное распределение является членом семейства моделей экспоненциальной дисперсии Твиди .
- Обернутое нормальное распределение - нормальное распределение, применяемое к круговой области.
- Z-тест – использование нормального распределения



Примечания
[ редактировать ]- ^ Например, этот алгоритм приведен в статье Язык программирования Bc .
- ^ Де Муавр впервые опубликовал эти результаты в 1733 году в брошюре «Приближение суммы биномиальных членов ( a + b )». n в Seriem Expansi , предназначенный только для частного обращения. Но только в 1738 году он обнародовал свои результаты. Оригинальная брошюра переиздавалась несколько раз, см., например, Walker (1985) .
- ^ «Было принято считать аксиомой гипотезу о том, что если какая-либо величина была определена путем нескольких прямых наблюдений, выполненных при одинаковых обстоятельствах и с одинаковой тщательностью, то среднее арифметическое наблюдаемых значений дает наиболее вероятное значение, если не строго, но, по крайней мере, почти так, чтобы всегда было безопаснее придерживаться его». — Гаусс (1809 , раздел 177)
- ^ «Мой обычай называть кривую кривой Гаусса-Лапласа или нормальной кривой спасает нас от пропорционального распределения заслуг открытия между двумя великими астрономами-математиками». цитата Пирсона (1905 , стр. 189)
- ^ Помимо тех, которые здесь специально упомянуты, такое использование встречается в работах Пирса , Гальтона ( Galton (1889 , глава V)) и Lexis ( Lexis (1878) , Rohrbasser & Véron (2003) ) c. 1875. [ нужна ссылка ]
Ссылки
[ редактировать ]Цитаты
[ редактировать ]- ^ Нортон, Мэтью; Хохлов, Валентин; Урясев, Стэн (2019). «Расчет CVaR и bPOE для распространенных распределений вероятностей с применением для оптимизации портфеля и оценки плотности» (PDF) . Анналы исследования операций . 299 (1–2). Спрингер: 1281–1315. arXiv : 1811.11301 . дои : 10.1007/s10479-019-03373-1 . S2CID 254231768 . Проверено 27 февраля 2023 г.
- ^ Нормальное распределение , Энциклопедия психологии Гейла
- ^ Казелла и Бергер (2001 , стр. 102)
- ^ Лион, А. (2014). Почему нормальные распределения нормальны? , Британский журнал философии науки.
- ^ Хорхе, Носедаль; Стефан, Дж. Райт (2006). Численная оптимизация (2-е изд.). Спрингер. п. 249. ИСБН 978-0387-30303-1 .
- ^ Jump up to: а б «Нормальное распределение» . www.mathsisfun.com . Проверено 15 августа 2020 г.
- ^ Стиглер (1982)
- ^ Гальперин, Хартли и Хоэл (1965 , пункт 7)
- ^ Макферсон (1990 , стр. 110)
- ^ Бернардо и Смит (2000 , стр. 121)
- ^ Скотт, Клейтон; Новак, Роберт (7 августа 2003 г.). «Q-функция» . Связи .
- ^ Барак, Охад (6 апреля 2006 г.). «Функция Q и функция ошибки» (PDF) . Тель-Авивский университет. Архивировано из оригинала (PDF) 25 марта 2009 г.
- ^ Вайсштейн, Эрик В. «Функция нормального распределения» . Математический мир .
- ^ Абрамовиц, Милтон ; Стегун, Ирен Энн , ред. (1983) [июнь 1964 г.]. «Глава 26, уравнение 26.2.12» . Справочник по математическим функциям с формулами, графиками и математическими таблицами . Серия «Прикладная математика». Том. 55 (Девятое переиздание с дополнительными исправлениями десятого оригинального издания с исправлениями (декабрь 1972 г.); первое изд.). Вашингтон, округ Колумбия; Нью-Йорк: Министерство торговли США, Национальное бюро стандартов; Дуврские публикации. п. 932. ИСБН 978-0-486-61272-0 . LCCN 64-60036 . МР 0167642 . LCCN 65-12253 .
- ^ Ваарт, А.В. ван дер (13 октября 1998 г.). Асимптотическая статистика . Издательство Кембриджского университета. дои : 10.1017/cbo9780511802256 . ISBN 978-0-511-80225-6 .
- ^ Обложка, Томас М.; Томас, Джой А. (2006). Элементы теории информации . Джон Уайли и сыновья. п. 254 . ISBN 9780471748816 .
- ^ Пак, Сон Ю.; Бера, Анил К. (2009). «Модель условной гетероскедастичности с максимальной энтропией авторегрессии» (PDF) . Журнал эконометрики . 150 (2): 219–230. CiteSeerX 10.1.1.511.9750 . doi : 10.1016/j.jeconom.2008.12.014 . Архивировано из оригинала (PDF) 7 марта 2016 года . Проверено 2 июня 2011 г.
- ^ Гири RC (1936) Распределение «коэффициента Стьюдента для ненормальных выборок». Приложение к журналу Королевского статистического общества 3 (2): 178–184.
- ^ Лукач, Евгений (март 1942 г.). «Характеристика нормального распределения». Анналы математической статистики . 13 (1): 91–93. дои : 10.1214/AOMS/1177731647 . ISSN 0003-4851 . JSTOR 2236166 . МР 0006626 . Збл 0060.28509 . Викиданные Q55897617 .
- ^ Jump up to: а б с Патель и Рид (1996 , [2.1.4])
- ^ Из (1991 , стр. 1258)
- ^ Патель и Рид (1996 , [2.1.8])
- ^ Папулис, Афанасий. Вероятность, случайные величины и случайные процессы (4-е изд.). п. 148.
- ^ Винкельбауэр, Андреас (2012). «Моменты и абсолютные моменты нормального распределения». arXiv : 1209.4340 [ math.ST ].
- ^ Брик (1995 , стр. 23)
- ^ Брик (1995 , стр. 24)
- ^ Обложка и Томас (2006 , стр. 254)
- ^ Уильямс, Дэвид (2001). Взвешивание шансов: курс вероятности и статистики (перепечатано под ред.). Кембридж [ua]: Cambridge Univ. Нажимать. стр. 197–199 . ISBN 978-0-521-00618-7 .
- ^ Смит, Хосе М. Бернардо; Адриан Ф.М. (2000). Байесовская теория (Переиздание). Чичестер [ua]: Уайли. стр. 209 , 366. ISBN. 978-0-471-49464-5 .
{{cite book}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ О'Хаган, А. (1994) Продвинутая теория статистики Кендалла, Том 2B, Байесовский вывод , Эдвард Арнольд. ISBN 0-340-52922-9 (раздел 5.40)
- ^ Jump up to: а б Брык (1995 , стр. 35)
- ^ UIUC, Лекция 21. Многомерное нормальное распределение , 21.6: «Индивидуально гауссово против совместно гауссово».
- ^ Эдвард Л. Мельник и Аарон Тененбейн, «Неверные спецификации нормального распределения», The American Statistician , том 36, номер 4, ноябрь 1982 г., страницы 372–373
- ^ «Кульбак Лейблер (KL) Расстояние двух нормальных (гауссовских) распределений вероятностей» . Allisons.org . 5 декабря 2007 года . Проверено 3 марта 2017 г.
- ^ Джордан, Майкл И. (8 февраля 2010 г.). «Stat260: Байесовское моделирование и вывод: сопряженный априор для нормального распределения» (PDF) .
- ^ Амари и Нагаока (2000)
- ^ «Ожидание максимума гауссовских случайных величин» . Математический обмен стеками . Проверено 7 апреля 2024 г.
- ^ «Нормальное приближение к распределению Пуассона» . Stat.ucla.edu . Проверено 3 марта 2017 г.
- ^ Jump up to: а б Дас, Абхранил (2021). «Метод интеграции и классификации нормальных распределений» . Журнал видения . 21 (10): 1. arXiv : 2012.14331 . дои : 10.1167/jov.21.10.1 . ПМЦ 8419883 . ПМИД 34468706 .
- ^ Брик (1995 , стр. 27)
- ^ Вайсштейн, Эрик В. «Нормальное распределение продукции» . Математический мир . wolfram.com.
- ^ Лукач, Евгений (1942). «Характеристика нормального распределения» . Анналы математической статистики . 13 (1): 91–3. дои : 10.1214/aoms/1177731647 . ISSN 0003-4851 . JSTOR 2236166 .
- ^ Басу, Д.; Лаха, Р.Г. (1954). «О некоторых характеристиках нормального распределения». Санкхья . 13 (4): 359–62. ISSN 0036-4452 . JSTOR 25048183 .
- ^ Леманн, Э.Л. (1997). Проверка статистических гипотез (2-е изд.). Спрингер. п. 199. ИСБН 978-0-387-94919-2 .
- ^ Патель и Рид (1996 , [2.3.6])
- ^ Галамбос и Симонелли (2004 , Теорема 3.5)
- ^ Jump up to: а б Лукач и Кинг (1954)
- ^ Куайн, член парламента (1993). «О трёх характеристиках нормального распределения» . Вероятность и математическая статистика . 14 (2): 257–263.
- ^ Джон, С. (1982). «Трехпараметрическое двухчастное нормальное семейство распределений и его аппроксимация». Коммуникации в статистике – теория и методы . 11 (8): 879–885. дои : 10.1080/03610928208828279 .
- ^ Jump up to: а б Кришнамурти (2006 , стр. 127)
- ^ Кришнамурти (2006 , стр. 130)
- ^ Кришнамурти (2006 , стр. 133)
- ^ Хаксли (1932)
- ^ Джейнс, Эдвин Т. (2003). Теория вероятностей: логика науки . Издательство Кембриджского университета. стр. 592–593. ISBN 9780521592710 .
- ^ Остербан, Роланд Дж. (1994). «Глава 6: Частотный и регрессионный анализ гидрологических данных» (PDF) . В Ритземе, Хенк П. (ред.). Принципы и применение дренажа, Публикация 16 (второе исправленное издание). Вагенинген, Нидерланды: Международный институт мелиорации и улучшения земель (ILRI). стр. 175–224. ISBN 978-90-70754-33-4 .
- ^ Почему большинство опубликованных результатов исследований ложны, Джон П.А. Иоаннидис, 2005 г.
- ^ Вичура, Майкл Дж. (1988). «Алгоритм AS241: Процентные точки нормального распределения». Прикладная статистика . 37 (3): 477–84. дои : 10.2307/2347330 . JSTOR 2347330 .
- ^ Джонсон, Коц и Балакришнан (1995 , уравнение (26.48))
- ^ Киндерман и Монахан (1977)
- ^ Лева (1992)
- ^ Марсалья и Цанг (2000)
- ^ Карни (2016)
- ^ Монахан (1985 , раздел 2)
- ^ Уоллес (1996)
- ^ Джонсон, Коц и Балакришнан (1994 , стр. 85)
- ^ Ле Кам и Ло Ян (2000 , стр. 74)
- ^ Де Муавр, Авраам (1733), Следствие I - см. Уокер (1985 , стр. 77).
- ^ Стиглер (1986 , стр. 76)
- ^ Гаусс (1809 , раздел 177)
- ^ Гаусс (1809 , раздел 179)
- ^ Лаплас (1774 , Задача III)
- ^ Пирсон (1905 , стр. 189)
- ^ Стиглер (1986 , стр. 144)
- ^ Стиглер (1978 , стр. 243)
- ^ Стиглер (1978 , стр. 244)
- ^ Максвелл (1860 , стр. 23)
- ^ Джейнс, Эдвин Дж.; Теория вероятностей: Логика науки , Гл. 7 .
- ^ Пирс, Чарльз С. (ок. 1909 г.), Сборник статей, т. 6, параграф 327.
- ^ Краскал и Стиглер (1997) .
- ^ «Самое раннее использование... (Входная стандартная нормальная кривая)» .
- ^ Сунь, Цзинчао; Конг, Майинг; Пал, Субхадип (22 июня 2021 г.). «Модифицированное полунормальное распределение: свойства и эффективная схема выборки» . Коммуникации в статистике – теория и методы . 52 (5): 1591–1613. дои : 10.1080/03610926.2021.1934700 . ISSN 0361-0926 . S2CID 237919587 .
Источники
[ редактировать ]- Олдрич, Джон; Миллер, Джефф. «Самые ранние использования символов в теории вероятности и статистике» .
- Олдрич, Джон; Миллер, Джефф. «Самые ранние известные варианты использования некоторых математических слов» . В частности, записи «Колоколообразная и колоколообразная кривая» , «Нормальное (распределение)» , «Гауссово» и «Ошибка, закон ошибок, теория ошибок и т. д.» .
- Амари, Сюн-ичи; Нагаока, Хироши (2000). Методы информационной геометрии . Издательство Оксфордского университета. ISBN 978-0-8218-0531-2 .
- Бернардо, Хосе М.; Смит, Адриан FM (2000). Байесовская теория . Уайли. ISBN 978-0-471-49464-5 .
- Брик, Влодзимеж (1995). Нормальное распределение: характеристики с приложениями . Спрингер-Верлаг. ISBN 978-0-387-97990-8 .
- Казелла, Джордж; Бергер, Роджер Л. (2001). Статистический вывод (2-е изд.). Даксбери. ISBN 978-0-534-24312-8 .
- Коди, Уильям Дж. (1969). «Рациональные чебышевские аппроксимации функции ошибки» . Математика вычислений . 23 (107): 631–638. дои : 10.1090/S0025-5718-1969-0247736-4 .
- Обложка, Томас М.; Томас, Джой А. (2006). Элементы теории информации . Джон Уайли и сыновья.
- Диа, Яя Д. (2023). «Приближенные неполные интегралы, приложение к дополнительной функции ошибки» . ССРН . дои : 10.2139/ssrn.4487559 . S2CID 259689086 .
- де Муавр, Авраам (1738). Доктрина шансов . Американское математическое общество. ISBN 978-0-8218-2103-9 .
- Фань, Цзяньцин (1991). «Об оптимальных скоростях сходимости для непараметрических задач деконволюции» . Анналы статистики . 19 (3): 1257–1272. дои : 10.1214/aos/1176348248 . JSTOR 2241949 .
- Гальтон, Фрэнсис (1889). Естественное наследование (PDF) . Лондон, Великобритания: Ричард Клей и сыновья.
- Галамбос, Янош; Симонелли, Итало (2004). Произведения случайных величин: приложения к задачам физики и арифметическим функциям . Марсель Деккер, Inc. ISBN 978-0-8247-5402-0 .
- Гаусс, Кароло Фридерико (1809). Theoria motvs corporvm coelestivm insectionibvs conicis Solemambiivm [ Теория движения небесных тел, движущихся вокруг Солнца в конических сечениях ] (на латыни). Хамбврги, Свмтибс Ф. Пертес и И.Х. Бессер. Английский перевод .
- Гулд, Стивен Джей (1981). Неизмерение человека (первое изд.). WW Нортон. ISBN 978-0-393-01489-1 .
- Гальперин, Макс; Хартли, Герман О.; Хоэл, Пол Г. (1965). «Рекомендуемые стандарты статистических символов и обозначений. Комитет COPSS по символам и обозначениям». Американский статистик . 19 (3): 12–14. дои : 10.2307/2681417 . JSTOR 2681417 .
- Харт, Джон Ф.; и др. (1968). Компьютерные приближения . Нью-Йорк, штат Нью-Йорк: ISBN John Wiley & Sons, Inc. 978-0-88275-642-4 .
- «Нормальное распределение» , Математическая энциклопедия , EMS Press , 2001 [1994]
- Хернштейн, Ричард Дж.; Мюррей, Чарльз (1994). Колоколообразная кривая: интеллект и классовая структура в американской жизни . Свободная пресса . ISBN 978-0-02-914673-6 .
- Хаксли, Джулиан С. (1932). Проблемы относительного роста . Лондон. ISBN 978-0-486-61114-3 . OCLC 476909537 .
- Джонсон, Норман Л.; Коц, Сэмюэл; Балакришнан, Нараянасвами (1994). Непрерывные одномерные распределения, Том 1 . Уайли. ISBN 978-0-471-58495-7 .
- Джонсон, Норман Л.; Коц, Сэмюэл; Балакришнан, Нараянасвами (1995). Непрерывные одномерные распределения, Том 2 . Уайли. ISBN 978-0-471-58494-0 .
- Карни, CFF (2016). «Выборка точно из нормального распределения». Транзакции ACM в математическом программном обеспечении . 42 (1): 3:1–14. arXiv : 1303.6257 . дои : 10.1145/2710016 . S2CID 14252035 .
- Киндерман, Альберт Дж.; Монахан, Джон Ф. (1977). «Компьютерная генерация случайных величин с использованием соотношения равномерных отклонений» . Транзакции ACM в математическом программном обеспечении . 3 (3): 257–260. дои : 10.1145/355744.355750 . S2CID 12884505 .
- Кришнамурти, Калимуту (2006). Справочник по статистическим распределениям с приложениями . Чепмен и Холл/CRC. ISBN 978-1-58488-635-8 .
- Краскал, Уильям Х.; Стиглер, Стивен М. (1997). Спенсер, Брюс Д. (ред.). Нормативная терминология: «нормальный» в статистике и других источниках . Статистика и государственная политика. Издательство Оксфордского университета. ISBN 978-0-19-852341-3 .
- Лаплас, Пьер-Симон де (1774). «Память о вероятности причин по событиям» . Мемуары Парижской королевской академии наук (иностранные ученые), том 6 : 621–656. Перевод Стивена М. Стиглера в журнале Statistical Science 1 (3), 1986: JSTOR 2245476 .
- Лаплас, Пьер-Симон (1812). вероятностей Аналитическая теория . Париж, пятница. Курьер.
- Ле Кам, Люсьен; Ло Ян, Грейс (2000). Асимптотика в статистике: некоторые основные понятия (второе изд.). Спрингер. ISBN 978-0-387-95036-5 .
- Лева, Джозеф Л. (1992). «Быстрый нормальный генератор случайных чисел» (PDF) . Транзакции ACM в математическом программном обеспечении . 18 (4): 449–453. CiteSeerX 10.1.1.544.5806 . дои : 10.1145/138351.138364 . S2CID 15802663 . Архивировано из оригинала (PDF) 16 июля 2010 г.
- Лексис, Вильгельм (1878). «О нормальной продолжительности жизни человека и о теории устойчивости статистических связей». Анналы международной демографии . II . Париж: 447–462.
- Лукач, Евгений; Кинг, Эдгар П. (1954). «Свойство нормального распределения» . Анналы математической статистики . 25 (2): 389–394. дои : 10.1214/aoms/1177728796 . JSTOR 2236741 .
- Макферсон, Глен (1990). Статистика в научных исследованиях: ее основы, применение и интерпретация . Спрингер-Верлаг. ISBN 978-0-387-97137-7 .
- Марсалья, Джордж ; Цанг, Вай Ван (2000). «Метод Зиккурата для генерации случайных величин» . Журнал статистического программного обеспечения . 5 (8). дои : 10.18637/jss.v005.i08 .
- Марсалья, Джордж (2004). «Оценка нормального распределения» . Журнал статистического программного обеспечения . 11 (4). дои : 10.18637/jss.v011.i04 .
- Максвелл, Джеймс Клерк (1860). «V. Иллюстрации динамической теории газов. — Часть I: О движении и столкновениях совершенно упругих сфер». Философский журнал . Ряд 4. 19 (124): 19–32. дои : 10.1080/14786446008642818 .
- Монахан, Дж. Ф. (1985). «Точность генерации случайных чисел» . Математика вычислений . 45 (172): 559–568. doi : 10.1090/S0025-5718-1985-0804945-X .
- Патель, Джагдиш К.; Прочтите, Кэмпбелл Б. (1996). Справочник по нормальному распределению (2-е изд.). ЦРК Пресс. ISBN 978-0-8247-9342-5 .
- Пирсон, Карл (1901). «О линиях и плоскостях, наиболее близких к системам точек в пространстве» (PDF) . Философский журнал . 6. 2 (11): 559–572. дои : 10.1080/14786440109462720 . S2CID 125037489 .
- Пирсон, Карл (1905). « Закон ошибок и его обобщения Фехнера и Пирсона». Возражение» . Биометрия . 4 (1): 169–212. дои : 10.2307/2331536 . JSTOR 2331536 .
- Пирсон, Карл (1920). «Заметки по истории корреляции» . Биометрика . 13 (1): 25–45. дои : 10.1093/biomet/13.1.25 . JSTOR 2331722 .
- Рорбассер, Жан-Марк; Верон, Жак (2003). «Лексика Вильгельма: Нормальная продолжительность жизни как выражение «природы вещей» » . Население . 58 (3): 303–322. дои : 10.3917/папа.303.0303 .
- Шор, Х. (1982). «Простые приближения для обратной кумулятивной функции, функции плотности и интеграла потерь нормального распределения». Журнал Королевского статистического общества. Серия C (Прикладная статистика) . 31 (2): 108–114. дои : 10.2307/2347972 . JSTOR 2347972 .
- Шор, Х. (2005). «Точные аппроксимации на основе RMM для CDF нормального распределения». Коммуникации в статистике – теория и методы . 34 (3): 507–513. дои : 10.1081/sta-200052102 . S2CID 122148043 .
- Шор, Х (2011). «Методология моделирования реагирования». ПРОВОДА Вычисление Стат . 3 (4): 357–372. дои : 10.1002/wics.151 . S2CID 62021374 .
- Шор, Х (2012). «Модели методологии моделирования реакции». ПРОВОДА Вычисление Стат . 4 (3): 323–333. дои : 10.1002/wics.1199 . S2CID 122366147 .
- Стиглер, Стивен М. (1978). «Математическая статистика в ранних государствах» . Анналы статистики . 6 (2): 239–265. дои : 10.1214/aos/1176344123 . JSTOR 2958876 .
- Стиглер, Стивен М. (1982). «Скромное предложение: новый стандарт нормальности». Американский статистик . 36 (2): 137–138. дои : 10.2307/2684031 . JSTOR 2684031 .
- Стиглер, Стивен М. (1986). История статистики: измерение неопределенности до 1900 года . Издательство Гарвардского университета. ISBN 978-0-674-40340-6 .
- Стиглер, Стивен М. (1999). Статистика в таблице . Издательство Гарвардского университета. ISBN 978-0-674-83601-3 .
- Уокер, Хелен М. (1985). «Де Муавр о законе нормальной вероятности» (PDF) . В Смите, Дэвид Юджин (ред.). Справочник по математике . Дувр. ISBN 978-0-486-64690-9 .
- Уоллес, CS (1996). «Быстрые псевдослучайные генераторы для нормальных и экспоненциальных переменных» . Транзакции ACM в математическом программном обеспечении . 22 (1): 119–127. дои : 10.1145/225545.225554 . S2CID 18514848 .
- Вайсштейн, Эрик В. «Нормальное распределение» . Математический мир .
- Уэст, Грэм (2009). «Лучшие приближения кумулятивных нормальных функций» (PDF) . Журнал Уилмотт : 70–76. Архивировано из оригинала (PDF) 29 февраля 2012 г.
- Зелен, Марвин; Северо, Норман К. (1964). Функции вероятности (глава 26) . Справочник по математическим функциям с формулами, графиками и математическими таблицами , автор: Абрамовиц М .; и Стегун, Айова : Национальное бюро стандартов. Нью-Йорк, штат Нью-Йорк: Дувр. ISBN 978-0-486-61272-0 .
Внешние ссылки
[ редактировать ]- «Нормальное распределение» , Энциклопедия математики , EMS Press , 2001 [1994]
- Калькулятор нормального распределения