t-распределение Стьюдента
|
Функция плотности вероятности 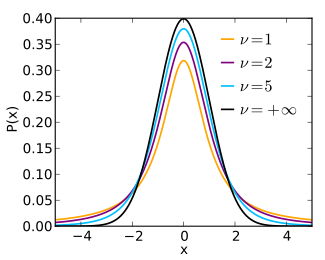 | |||
|
Кумулятивная функция распределения 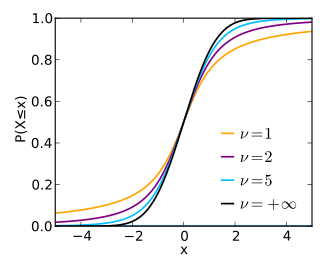 | |||
| Параметры | степени свободы ( действительные , почти всегда положительное целое число ) | ||
|---|---|---|---|
| Поддерживать | |||
| CDF |
| ||
| Иметь в виду | для в противном случае не определено | ||
| медиана | |||
| Режим | |||
| Дисперсия |
для ∞ для в противном случае не определено | ||
| асимметрия | для в противном случае не определено | ||
| Избыточный эксцесс |
для ∞ для в противном случае не определено | ||
| Энтропия |
| ||
| МГФ | неопределенный | ||
| CF |
для | ||
| Ожидаемый дефицит |
Где является обратным стандартизированным Стьюдентом t CDF и представляет собой стандартизированный студенческий PDF-файл . [2] | ||



![{\displaystyle {\begin{matrix}\ {\frac {\ 1\ }{2}}+x\ \Gamma \left({\frac {\ \nu +1\ }{2}}\right)\times \\[0.5em]{\frac {\ {{}_{2}F_{1}}\!\left(\ {\frac {\ 1\ }{2}},\ {\frac {\ \nu +1\ }{2}};\ {\frac {3}{\ 2\ }};\ -{\frac {~x^{2}\ }{\nu }}\ \right)\ }{\ {\sqrt {\pi \nu }}\ \Gamma \left({\frac {\ \nu \ }{2}}\right)\ }}\ ,\end{matrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/32b4a3af11d075b054f564e60b7aea14bf2a95f3)










![{\displaystyle \ {\begin{matrix}{\frac {\ \nu +1\ }{2}}\left[\ \psi \left({\frac {\ \nu +1\ }{2}}\ right)-\psi \left({\frac {\ \nu \ }{2}}\right)\ \right]\\[0.5em]+\ln \left[{\sqrt {\nu \ }}\ {\mathrm {B} }\left(\ {\frac {\ \nu \ }{2}},\ {\frac {\ 1\ }{2}}\ \right)\right]\ {\scriptstyle { \text{(nats)}}}\ \end{matrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f248820e946d0f06d1d132fb0d1473d3bed1736c)







В вероятности и статистике распределение ( t- Стьюдента или просто t- распределение ) является непрерывное распределение вероятностей , которое обобщает стандартное нормальное распределение . Как и последний, он симметричен вокруг нуля и имеет колоколообразную форму.

Однако, имеет более тяжелые хвосты , а количество вероятностной массы в хвостах контролируется параметром Для Стьюдента распределение становится стандартным распределением Коши , имеющим очень «толстые» хвосты ; тогда как для оно становится стандартным нормальным распределением у которого очень «тонкие» хвосты.





Стьюдента Распределение играет роль в ряде широко используемых статистических анализов, включая Стьюдента критерий регрессии для оценки статистической значимости разницы между двумя выборочными средними, построения доверительных интервалов для разницы между двумя генеральными средними и в линейной . анализ .
В виде в масштабе местоположения t распределения оно обобщает нормальное распределение , а также возникает при байесовском анализе данных нормального семейства как составного распределения при маргинализации по параметру дисперсии.

История и этимология
[ редактировать ]
В статистике t- распределение было впервые получено как апостериорное распределение в 1876 году Гельмертом. [3] [4] [5] и Люрот . [6] [7] [8] Таким образом, t-распределение Стьюдента является примером закона эпонимии Стиглера . Распределение t также появилось в более общей форме как распределение Пирсона типа IV в статье Карла Пирсона 1895 года. [9]
В англоязычной литературе распространение получило свое название от статьи Уильяма Сили Госсета 1908 года в журнале «Биометрика» под псевдонимом «Студент». [10] Одна из версий происхождения псевдонима заключается в том, что работодатель Госсета предпочитал, чтобы сотрудники при публикации научных статей использовали псевдонимы вместо своего настоящего имени, поэтому он использовал имя «Студент», чтобы скрыть свою личность. Другая версия заключается в том, что компания Guinness не хотела, чтобы конкуренты знали, что они используют t- тест для определения качества сырья. [11] [12]
Госсет работал на пивоварне Guinness Brewery в Дублине, Ирландия , и интересовался проблемами небольших образцов – например, химическими свойствами ячменя, где размеры выборок могли составлять всего 3. В статье Госсета это распределение называется «частотным распределением». стандартных отклонений выборок, взятых из нормальной популяции». Оно стало широко известно благодаря работе Рональда Фишера , который назвал распределение «распределением Стьюдента» и обозначил проверочное значение буквой t . [13] [14]
Определение
[ редактировать ]Функция плотности вероятности
[ редактировать ]Стьюдента Распределение (PDF) , имеет функцию плотности вероятности определяемую выражением

где число степеней свободы и это гамма-функция . Это также можно записать как



где это бета-функция . В частности, для целочисленных степеней свободы. у нас есть:

Для и даже,


Для и странно,

Функция плотности вероятности симметрична , и ее общая форма напоминает колоколообразную форму нормально распределенной переменной со средним значением 0 и дисперсией 1, за исключением того, что она немного ниже и шире. По мере роста числа степеней свободы распределение t приближается к нормальному распределению со средним значением 0 и дисперсией 1. По этой причине также известен как параметр нормальности. [15]

На следующих изображениях показана плотность распределения t для возрастающих значений Нормальное распределение показано для сравнения синей линией. Обратите внимание, что распределение t (красная линия) становится ближе к нормальному распределению по мере того, как увеличивается.

Предыдущие графики показаны зеленым цветом.





Кумулятивная функция распределения
[ редактировать ]Кумулятивную функцию распределения (CDF) можно записать через I , регуляризованную неполная бета-функция . Для t > 0 ,

где

Другие значения будут получены путем симметрии. Альтернативная формула, справедливая для является


где является частным примером гипергеометрической функции .

Информацию об обратной кумулятивной функции распределения см. в разделе « Функция квантиля § t-распределение Стьюдента» .
Особые случаи
[ редактировать ]Определенные значения приведите простую форму t-распределения Стьюдента.
| CDF | примечания | ||
|---|---|---|---|
| 1 | См. Распределение Коши. | ||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| См. Нормальное распределение , Функция ошибки. |





![{\displaystyle \ {\frac {\ 1\ }{2}}+{\frac {\ 1\ }{\pi }}\ \left[{\frac {\left(\ {\frac {t}{\ {\sqrt {3\ }}\ }}\ \right)}{\left(\ 1+{\frac {~t^{2}\ }{3}}\ \right)}}+\arctan \left (\ {\frac {t}{\ {\sqrt {3\ }}\ }}\ \right)\ \right]\ }](https://wikimedia.org/api/rest_v1/media/math/render/svg/8354c1a9905eca443735c8edd6f2ff7e30338284)

![{\displaystyle \ {\frac {\ 1\ }{2}}+{\frac {\ 3\ }{8}}\left[\ {\frac {t}{\ {\sqrt {1+{\frac {~t^{2}\ }{4}}~}}\ }}\right]\left[\ 1- {\frac {~t^{2}\ }{\ 12\ \left(\ 1+ {\frac {~t^{2}\ }{4}}\ \right)\ }}\ \right]\ }](https://wikimedia.org/api/rest_v1/media/math/render/svg/593d1fbbf85d9c6eca1216081674478751fb9474)

![{\displaystyle \ {\frac {\ 1\ }{2}}+{\frac {\ 1\ }{\pi }}{\left[{\frac {t}{\ {\sqrt {5\ }} \left(1+{\frac {\ t^{2}\ }{5}}\right)\ }}\left(1+{\frac {2}{\ 3\left(1+{\frac { \ t^{2}\ }{5}}\right)\ }}\right)+\arctan \left({\frac {t}{\ {\sqrt {\ 5\ }}\ }}\right) \верно]}\ }](https://wikimedia.org/api/rest_v1/media/math/render/svg/e4b4a5988d5b6d89997077e3ef32bda4bdf6ba5e)


![{\displaystyle \ {\frac {\ 1\ }{2}}\ {\left[1+\operatorname {erf} \left({\frac {t}{\ {\sqrt {2\ }}\ }} \вправо)\вправо]}\ }](https://wikimedia.org/api/rest_v1/media/math/render/svg/a55ea64b38c1617eea3674d914c315fdb9fab27c)
Моменты
[ редактировать ]Для необработанные моменты распределения t равны

![{\displaystyle \operatorname {\mathbb {E} } \left\{\ T^{k}\ \right\}= {\begin{cases}\quad 0&k {\text{odd }},\quad 0<k <\nu \ ,\\{}\\{\frac {1}{\ {\sqrt {\pi \ }}\ \Gamma \left({\frac {\ \nu \ }{2}}\right) }}\ \left[\ \Gamma \!\left({\frac {\ k+1\ }{2}}\right)\ \Gamma \!\left({\frac {\ \nu -k\ } {2}}\right)\ \nu ^{\frac {\ k\ }{2}}\ \right]&k{\text{even }},\quad 0<k<\nu ~.\\\end {случаи}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bede1b3de92cfea26b16817b52f40f76d35d1ceb)
Моменты заказа и выше не существует. [16]
Срок для даже k , можно упростить, используя свойства гамма-функции :


Для распределения t с степеней свободы, ожидаемое значение равно если его дисперсия и если Асимметрия равна 0 , если и эксцесс избыточный если





в масштабе местоположения t Распределение
[ редактировать ]Преобразование в масштабе местоположения
[ редактировать ]Распределение Стьюдента t обобщает трехпараметрическое в масштабе местоположения . распределение путем введения параметра местоположения и параметр масштаба С




и семьи в масштабе локации трансформация

мы получаем

Полученное распределение также называют нестандартизованным t- распределением Стьюдента .
Плотность и первые два момента
[ редактировать ]в масштабе местоположения Распределение t имеет плотность, определяемую следующим образом: [17]

Эквивалентно плотность можно записать через :


Другие свойства этой версии дистрибутива: [17]

Особые случаи
[ редактировать ]- Если в масштабе местоположения следует t - распределению тогда для нормально распределяется со средним и дисперсия
- в масштабе местоположения t Распределение со степенью свободы эквивалентно распределению Коши
- в масштабе местоположения t Распределение с и Стьюдента сводится к t- распределению












Как возникает распределение t (характеристика)
[ редактировать ]Как распределение тестовой статистики
[ редактировать ]-распределение Стьюдента t с степени свободы можно определить как распределение случайной величины T с [18] [19]


где
- Z — стандартная норма с ожидаемым значением 0 и дисперсией 1;
- V имеет распределение хи-квадрат ( χ 2 -распределение ) с степени свободы ;
- Z и V независимы ;
Другое распределение определяется как распределение случайной величины, определяемой для данной константы µ формулой

Эта случайная величина имеет нецентральное t -распределение с параметром нецентральности μ . Это распределение важно при изучении силы t критерия Стьюдента - .
Вывод
[ редактировать ]Предположим, что X 1 , ..., X n являются независимыми реализациями нормально распределенной случайной величины X , которая имеет ожидаемое значение µ и дисперсию σ. 2 . Позволять

быть выборочным средним, и

быть несмещенной оценкой отклонения от выборки. Можно показать, что случайная величина

имеет распределение хи-квадрат с степени свободы (по теореме Кокрена ). [20] Легко показать, что величина


обычно распределяется со средним значением 0 и дисперсией 1, поскольку выборочное среднее нормально распределяется со средним значением µ и дисперсией σ 2 / н . Более того, можно показать, что эти две случайные величины (нормально распределенная Z и распределенная по хи-квадрату V ) независимы. Следовательно [ нужны разъяснения ] ключевое количество


которое отличается от Z тем, что точное стандартное отклонение σ заменяется случайной величиной S n -распределение Стьюдента , имеет t , определенное выше. Обратите внимание, что неизвестная дисперсия совокупности σ 2 не появляется в T , поскольку он был и в числителе, и в знаменателе, поэтому он отменяется. Госсет интуитивно получил указанную выше функцию плотности вероятности: равен n − 1, и Фишер доказал это в 1925 году. [13]
Распределение тестовой статистики T зависит от , но не µ или σ ; Отсутствие зависимости от µ и σ делает t -распределение важным как в теории, так и на практике.
Выборочное распределение t-статистики
[ редактировать ]Распределение t возникает как выборочное распределение статистики t- . статистика для одной выборки t- Ниже обсуждается , соответствующую t- статистику для двух выборок см. в t-критерии Стьюдента .
Несмещенная оценка дисперсии
[ редактировать ]Позволять быть независимыми и одинаково распределенными выборками из нормального распределения со средним значением и дисперсия Выборочное среднее и несмещенная выборочная дисперсия определяются по формуле:


![{\displaystyle {\begin{aligned}{\bar {x}}&={\frac {\ x_{1}+\cdots +x_{n}\ }{n}}\ ,\\[5pt]s^ {2}&={\frac {1}{\ n-1\ }}\ \sum _{i=1}^{n}(x_{i}-{\bar {x}})^{2} ~.\end{выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d888648788b273c89dbb57cb5a936e7824fa31d2)
Результирующая (одна выборка) t- статистика определяется выражением

распределению Стьюдента и распределяется согласно t- с степени свободы.

Таким образом, для целей вывода t- статистика является полезной « ключевой величиной » в случае, когда среднее значение и дисперсия являются неизвестными параметрами совокупности в том смысле, что t- статистика имеет распределение вероятностей, которое не зависит ни от ни

Оценка отклонения ML
[ редактировать ]Вместо несмещенной оценки мы также можем использовать оценку максимального правдоподобия


получение статистики

Оно распределяется в соответствии с распределением t в масштабе местоположения :

Сложное распределение нормального с обратным гамма-распределением
[ редактировать ]в масштабе местоположения Распределение t получается в результате объединения ( распределения Гаусса нормального распределения) со средним значением . и неизвестная дисперсия с обратным гамма-распределением, помещенным поверх дисперсии с параметрами и Другими словами, случайная величина X предполагается, что имеет гауссово распределение с неизвестной дисперсией, распределенной как обратная гамма, а затем дисперсия исключается (интегрируется).


Эквивалентно, это распределение является результатом объединения распределения Гаусса с масштабированным распределением обратного хи-квадрата с параметрами и Масштабированное обратное распределение хи-квадрат представляет собой точно такое же распределение, как и обратное гамма-распределение, но с другой параметризацией, т.е.

Причина полезности этой характеристики заключается в том, что в байесовской статистике обратное гамма-распределение представляет собой сопряженное априорное распределение дисперсии гауссовского распределения. В результате распределение t в масштабе местоположения естественным образом возникает во многих задачах байесовского вывода. [21]
Максимальное распределение энтропии
[ редактировать ]Стьюдента Распределение — это распределение вероятностей максимальной энтропии для случайной величины X , для которого фиксировано. [22] [ нужны разъяснения ] [ нужен лучший источник ]

Дополнительные свойства
[ редактировать ]Выборка Монте-Карло
[ редактировать ]распределения Стьюдента Существуют различные подходы к построению случайных выборок на основе t- . Вопрос зависит от того, требуются ли выборки на отдельной основе или они должны быть построены путем применения функции квантиля к однородным выборкам; например, в многомерных приложениях, основанных на зависимости от копулы . [ нужна ссылка ] В случае автономной выборки расширение метода Бокса-Мюллера и его полярную форму . легко применить [23] Его достоинство заключается в том, что он одинаково хорошо применим ко всем реальным положительным степеням свободы ν ν , в то время как многие другие методы-кандидаты терпят неудачу, если близка к нулю. [23]
Интеграл от функции плотности вероятности Стьюдента и p значения
[ редактировать ]Функция A ( t | ν ) является интегралом функции плотности вероятности Стьюдента f ( t ) между -t и t , для t ≥ 0 . Таким образом, это дает вероятность того, что значение t меньше, чем рассчитанное на основе наблюдаемых данных, возникнет случайно. Следовательно, функцию A ( t | ν ) можно использовать при проверке того, является ли разница между средними значениями двух наборов данных статистически значимой, путем расчета соответствующего значения t и вероятности его возникновения, если два набора данных были взятые из того же населения. Это используется в различных ситуациях, особенно в t- тестах . Для статистики t с ν степенями свободы A ( t | ν ) — это вероятность того, что t будет меньше наблюдаемого значения, если бы два средних были одинаковыми (при условии, что меньшее среднее вычитается из большего, так что т ≥ 0 ). Его можно легко вычислить из кумулятивной функции распределения F ν ( t ) -распределения t :

где Ix функция ( a , b ) — регуляризованная неполная бета- .
Для проверки статистических гипотез эта функция используется для построения p значения .
Связанные дистрибутивы
[ редактировать ]- Нецентральное , t распределение обобщает распределение t включив в него параметр нецентральности. В отличие от нестандартизованных t- распределений, нецентральные распределения не симметричны (медиана не совпадает с модой).
- Дискретное Стьюдента t- распределение определяется его функцией массы вероятности при r, пропорциональной: [24] Здесь a , b и k — параметры. Это распределение возникает в результате построения системы дискретных распределений, аналогичной системе распределений Пирсона для непрерывных распределений. [25]
- Можно сгенерировать выборки Стьюдента A ( t | ν ), взяв соотношение переменных из нормального распределения и квадратный корень χ² распределения из . Если мы используем вместо нормального распределения, например, распределение Ирвина-Холла , мы получаем в целом симметричное распределение с четырьмя параметрами, которое включает нормальное, равномерное , треугольное Стьюдента и Коши , распределение . Это также более гибко, чем некоторые другие симметричные обобщения нормального распределения.
- Распределение t является примером распределения соотношений .

Использование
[ редактировать ]В частотном статистическом выводе
[ редактировать ]Распределение Стьюдента аддитивными возникает в различных задачах статистического оценивания, цель которых состоит в том, чтобы оценить неизвестный параметр, например среднее значение, в условиях, когда данные наблюдаются с ошибками . Если (как почти во всех практических статистических работах) стандартное отклонение генеральной совокупности этих ошибок неизвестно и должно быть оценено на основе данных, t- распределение часто используется для учета дополнительной неопределенности, возникающей в результате этой оценки. В большинстве таких задач, если бы было известно стандартное отклонение ошибок, вместо t- распределения использовалось бы нормальное распределение.
Доверительные интервалы и проверка гипотез — это две статистические процедуры, в которых квантили выборочного распределения конкретной статистики (например, стандартного балла требуются ). В любой ситуации, когда эта статистика является линейной функцией данных t , разделенной на обычную оценку стандартного отклонения, полученную величину можно масштабировать и центрировать, чтобы она соответствовала - распределению Стьюдента. Статистический анализ, включающий средние, взвешенные средние и коэффициенты регрессии, приводит к тому, что статистика имеет такую форму.
распределения Стьюдента Довольно часто в задачах учебников стандартное отклонение генеральной совокупности рассматривается так, как если бы оно было известно, и тем самым устраняется необходимость использования t- . Эти проблемы обычно бывают двух видов: (1) те, в которых размер выборки настолько велик, что можно рассматривать основанную на данных оценку дисперсии, как если бы она была достоверной, и (2) те, которые иллюстрируют математические рассуждения, в которых проблема оценки стандартного отклонения временно игнорируется, потому что это не тот момент, который затем объясняет автор или преподаватель.
Проверка гипотез
[ редактировать ]Можно показать, что ряд статистических данных имеют распределения t для выборок среднего размера при нулевых гипотезах , которые представляют интерес, так что распределение t формирует основу для тестов значимости. Например, распределение коэффициента ранговой корреляции Спирмена ρ в нулевом случае (нулевая корреляция) хорошо аппроксимируется распределением t для размеров выборки выше примерно 20. [ нужна ссылка ]
Доверительные интервалы
[ редактировать ]Предположим, что число A выбрано так, что

когда T имеет распределение t с n - 1 степенями свободы. По симметрии это то же самое, что сказать, что A удовлетворяет

поэтому A — это «95-й процентиль» этого распределения вероятностей, или Затем


и это эквивалентно

Следовательно, интервал, конечные точки которого

представляет собой 90% доверительный интервал для μ. Следовательно, если мы найдем среднее значение набора наблюдений, которые, как мы можем разумно ожидать, будут иметь нормальное распределение, мы можем использовать t- распределение, чтобы проверить, включают ли доверительные пределы этого среднего значения какое-либо теоретически предсказанное значение - например, значение, предсказанное на гипотеза нулевая .
Именно этот результат используется в Стьюдента t- тестах : поскольку разница между средними значениями выборок из двух нормальных распределений сама по себе распределяется нормально, t- распределение можно использовать для проверки того, можно ли разумно предположить, что эта разница равна нулю.
Если данные нормально распределены, односторонний (1 − α ) верхний доверительный предел (UCL) среднего значения можно рассчитать с помощью следующего уравнения:

Результирующий UCL будет наибольшим средним значением, которое может возникнуть для данного доверительного интервала и размера популяции. Другими словами, будучи средним значением набора наблюдений, вероятность того, что среднее значение распределения ниже UCL 1 − α, равна уровню достоверности 1 − α .
Интервалы прогнозирования
[ редактировать ]Распределение t можно использовать для построения интервала прогнозирования для ненаблюдаемой выборки на основе нормального распределения с неизвестным средним значением и дисперсией.
В байесовской статистике
[ редактировать ]Стьюдента Распределение , особенно в его трехпараметрической (шкале местоположения) версии, часто возникает в байесовской статистике в результате его связи с нормальным распределением. Всякий раз, когда дисперсия нормально распределенной случайной величины неизвестна и над ней помещается сопряженная априорная величина , следующая обратному гамма-распределению , результирующее предельное распределение переменной будет следовать t -распределению Стьюдента. Эквивалентные конструкции с одинаковыми результатами включают сопряженное масштабированное распределение обратного хи-квадрата по дисперсии или сопряженное гамма-распределение по точности . Если неправильный априор пропорционален 1 / σ ² помещается над дисперсией, также возникает t- распределение. Это имеет место независимо от того, известно ли среднее значение нормально распределенной переменной, неизвестно, распределено ли в соответствии с сопряженной, нормально распределенной априорной величиной, или неизвестно, распределенной в соответствии с неправильной априорной константой.
Связанные ситуации, которые также приводят к t- распределению:
- Маргинальное неизвестного среднего значения нормально апостериорное распределение распределенной переменной с неизвестным априорным средним значением и дисперсией в соответствии с вышеуказанной моделью.
- Априорное прогнозируемое распределение и апостериорное прогнозируемое распределение серия независимых одинаково распределенных нормально распределенных точек данных с априорным средним значением и дисперсией, как в приведенной выше модели. новой точки данных с нормальным распределением, когда наблюдалась
Надежное параметрическое моделирование
[ редактировать ]Распределение t часто используется в качестве альтернативы нормальному распределению в качестве модели данных, которые часто имеют более тяжелые хвосты, чем допускает нормальное распределение; см., например, Lange et al. [26] Классический подход заключался в выявлении выбросов (например, с помощью критерия Граббса ) и их исключении или понижении их веса каким-либо образом. Однако не всегда легко выявить выбросы (особенно в больших размерностях ), а распределение t является естественным выбором модели для таких данных и обеспечивает параметрический подход к надежной статистике .
Байесовский подход можно найти у Gelman et al. [27] Параметр степеней свободы контролирует эксцесс распределения и коррелирует с параметром масштаба. Вероятность может иметь несколько локальных максимумов, и поэтому часто необходимо зафиксировать достаточно низкое значение степеней свободы и оценить другие параметры, принимая это как заданное. Некоторые авторы [ нужна ссылка ] сообщают, что значения от 3 до 9 часто являются хорошим выбором. Венейблс и Рипли [ нужна ссылка ] предполагают, что значение 5 часто является хорошим выбором.
Студенческий процесс
[ редактировать ]Для практических нужд регрессии и прогнозирования процессы Стьюдента были введены t- , которые являются обобщением t- распределений Стьюдента для функций. процесс Стьюдента t- строится на основе t- распределений Стьюдента, так же как гауссов процесс строится на основе гауссовских распределений . Для гауссовского процесса все наборы значений имеют многомерное гауссово распределение. Аналогично, является процессом Стьюдента на интервале если соответствующие значения процесса ( ) имеют совместное многомерное Стьюдента распределение . [28] Эти процессы используются для регрессии, прогнозирования, байесовской оптимизации и связанных с ними задач. многомерные t- процессы Стьюдента. Для многомерной регрессии и прогнозирования с несколькими выходами вводятся и используются [29]

![{\displaystyle I=[a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d6214bb3ce7f00e496c0706edd1464ac60b73b5)


Таблица выбранных значений
[ редактировать ]В следующей таблице перечислены значения t- распределений со степенями свободы ν для диапазона односторонних или двусторонних критических областей. Первый столбец — ν , проценты вверху — уровни уверенности. а цифры в основной части таблицы — это факторы, описанные в разделе доверительных интервалов .


Последняя строка с бесконечным ν дает критические точки для нормального распределения, поскольку распределение t с бесконечным числом степеней свободы является нормальным распределением. (См. Связанные дистрибутивы выше).
| Односторонний | 75% | 80% | 85% | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Двусторонний | 50% | 60% | 70% | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
| 1 | 1.000 | 1.376 | 1.963 | 3.078 | 6.314 | 12.706 | 31.821 | 63.657 | 127.321 | 318.309 | 636.619 |
| 2 | 0.816 | 1.061 | 1.386 | 1.886 | 2.920 | 4.303 | 6.965 | 9.925 | 14.089 | 22.327 | 31.599 |
| 3 | 0.765 | 0.978 | 1.250 | 1.638 | 2.353 | 3.182 | 4.541 | 5.841 | 7.453 | 10.215 | 12.924 |
| 4 | 0.741 | 0.941 | 1.190 | 1.533 | 2.132 | 2.776 | 3.747 | 4.604 | 5.598 | 7.173 | 8.610 |
| 5 | 0.727 | 0.920 | 1.156 | 1.476 | 2.015 | 2.571 | 3.365 | 4.032 | 4.773 | 5.893 | 6.869 |
| 6 | 0.718 | 0.906 | 1.134 | 1.440 | 1.943 | 2.447 | 3.143 | 3.707 | 4.317 | 5.208 | 5.959 |
| 7 | 0.711 | 0.896 | 1.119 | 1.415 | 1.895 | 2.365 | 2.998 | 3.499 | 4.029 | 4.785 | 5.408 |
| 8 | 0.706 | 0.889 | 1.108 | 1.397 | 1.860 | 2.306 | 2.896 | 3.355 | 3.833 | 4.501 | 5.041 |
| 9 | 0.703 | 0.883 | 1.100 | 1.383 | 1.833 | 2.262 | 2.821 | 3.250 | 3.690 | 4.297 | 4.781 |
| 10 | 0.700 | 0.879 | 1.093 | 1.372 | 1.812 | 2.228 | 2.764 | 3.169 | 3.581 | 4.144 | 4.587 |
| 11 | 0.697 | 0.876 | 1.088 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 | 4.025 | 4.437 |
| 12 | 0.695 | 0.873 | 1.083 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 | 3.930 | 4.318 |
| 13 | 0.694 | 0.870 | 1.079 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3.372 | 3.852 | 4.221 |
| 14 | 0.692 | 0.868 | 1.076 | 1.345 | 1.761 | 2.145 | 2.624 | 2.977 | 3.326 | 3.787 | 4.140 |
| 15 | 0.691 | 0.866 | 1.074 | 1.341 | 1.753 | 2.131 | 2.602 | 2.947 | 3.286 | 3.733 | 4.073 |
| 16 | 0.690 | 0.865 | 1.071 | 1.337 | 1.746 | 2.120 | 2.583 | 2.921 | 3.252 | 3.686 | 4.015 |
| 17 | 0.689 | 0.863 | 1.069 | 1.333 | 1.740 | 2.110 | 2.567 | 2.898 | 3.222 | 3.646 | 3.965 |
| 18 | 0.688 | 0.862 | 1.067 | 1.330 | 1.734 | 2.101 | 2.552 | 2.878 | 3.197 | 3.610 | 3.922 |
| 19 | 0.688 | 0.861 | 1.066 | 1.328 | 1.729 | 2.093 | 2.539 | 2.861 | 3.174 | 3.579 | 3.883 |
| 20 | 0.687 | 0.860 | 1.064 | 1.325 | 1.725 | 2.086 | 2.528 | 2.845 | 3.153 | 3.552 | 3.850 |
| 21 | 0.686 | 0.859 | 1.063 | 1.323 | 1.721 | 2.080 | 2.518 | 2.831 | 3.135 | 3.527 | 3.819 |
| 22 | 0.686 | 0.858 | 1.061 | 1.321 | 1.717 | 2.074 | 2.508 | 2.819 | 3.119 | 3.505 | 3.792 |
| 23 | 0.685 | 0.858 | 1.060 | 1.319 | 1.714 | 2.069 | 2.500 | 2.807 | 3.104 | 3.485 | 3.767 |
| 24 | 0.685 | 0.857 | 1.059 | 1.318 | 1.711 | 2.064 | 2.492 | 2.797 | 3.091 | 3.467 | 3.745 |
| 25 | 0.684 | 0.856 | 1.058 | 1.316 | 1.708 | 2.060 | 2.485 | 2.787 | 3.078 | 3.450 | 3.725 |
| 26 | 0.684 | 0.856 | 1.058 | 1.315 | 1.706 | 2.056 | 2.479 | 2.779 | 3.067 | 3.435 | 3.707 |
| 27 | 0.684 | 0.855 | 1.057 | 1.314 | 1.703 | 2.052 | 2.473 | 2.771 | 3.057 | 3.421 | 3.690 |
| 28 | 0.683 | 0.855 | 1.056 | 1.313 | 1.701 | 2.048 | 2.467 | 2.763 | 3.047 | 3.408 | 3.674 |
| 29 | 0.683 | 0.854 | 1.055 | 1.311 | 1.699 | 2.045 | 2.462 | 2.756 | 3.038 | 3.396 | 3.659 |
| 30 | 0.683 | 0.854 | 1.055 | 1.310 | 1.697 | 2.042 | 2.457 | 2.750 | 3.030 | 3.385 | 3.646 |
| 40 | 0.681 | 0.851 | 1.050 | 1.303 | 1.684 | 2.021 | 2.423 | 2.704 | 2.971 | 3.307 | 3.551 |
| 50 | 0.679 | 0.849 | 1.047 | 1.299 | 1.676 | 2.009 | 2.403 | 2.678 | 2.937 | 3.261 | 3.496 |
| 60 | 0.679 | 0.848 | 1.045 | 1.296 | 1.671 | 2.000 | 2.390 | 2.660 | 2.915 | 3.232 | 3.460 |
| 80 | 0.678 | 0.846 | 1.043 | 1.292 | 1.664 | 1.990 | 2.374 | 2.639 | 2.887 | 3.195 | 3.416 |
| 100 | 0.677 | 0.845 | 1.042 | 1.290 | 1.660 | 1.984 | 2.364 | 2.626 | 2.871 | 3.174 | 3.390 |
| 120 | 0.677 | 0.845 | 1.041 | 1.289 | 1.658 | 1.980 | 2.358 | 2.617 | 2.860 | 3.160 | 3.373 |
| ∞ | 0.674 | 0.842 | 1.036 | 1.282 | 1.645 | 1.960 | 2.326 | 2.576 | 2.807 | 3.090 | 3.291 |
| Односторонний | 75% | 80% | 85% | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
| Двусторонний | 50% | 60% | 70% | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
- Расчет доверительного интервала
Допустим, у нас есть выборка размером 11, средним значением выборки 10 и дисперсией выборки 2. Для 90% уверенности с 10 степенями свободы одностороннее значение t из таблицы равно 1,372. Затем с доверительным интервалом, рассчитанным по формуле

мы определяем, что с 90% уверенностью имеем истинное среднее значение, лежащее ниже

Другими словами, в 90% случаев, когда верхний порог рассчитывается этим методом на основе конкретных образцов, этот верхний порог превышает истинное среднее значение.
И с уверенностью 90% мы имеем истинное среднее значение, лежащее выше

Другими словами, в 90% случаев, когда нижний порог рассчитывается этим методом на основе конкретных образцов, этот нижний порог лежит ниже истинного среднего значения.
Таким образом, при доверительной вероятности 80 % (рассчитанной по формуле 100 % – 2 × (1 – 90 %) = 80 %) мы имеем истинное среднее значение, лежащее в пределах интервала

Сказать, что в 80% случаев, когда верхний и нижний пороговые значения рассчитываются с помощью этого метода на основе данной выборки, истинное среднее значение находится как ниже верхнего порога, так и выше нижнего порога, это не то же самое, что сказать, что существует 80% вероятность того, что истинное среднее находится между определенной парой верхних и нижних порогов, рассчитанных с помощью этого метода; см. доверительный интервал и ошибку прокурора .
В настоящее время статистическое программное обеспечение, такое как язык программирования R , и функции, доступные во многих программах для работы с электронными таблицами, вычисляют значения распределения t и обратного ему без таблиц.
См. также
[ редактировать ]- F -распределение
- сложенных t и половинных t Распределения
- Хотеллинга T² Распределение
- Многомерное распределение студентов
- Стандартная нормальная таблица ( Z -распределения) таблица
- статистика
- Распределение Тау для внутренне стьюдентизированных остатков
- Лямбда-распределение Уилкса
- Распределение желаний
- Модифицированное полунормальное распределение [30] с PDF-файлом на дается как где обозначает Пси-функцию Фокса–Райта .



Примечания
[ редактировать ]- ^ Херст, Саймон. «Характеристическая функция распределения Стьюдента » . Отчет об исследовании финансовой математики. Отчет о статистических исследованиях № SRR044-95. Архивировано из оригинала 18 февраля 2010 года.
- ^ Нортон, Мэтью; Хохлов, Валентин; Урясев, Стэн (2019). «Расчет CVaR и bPOE для распространенных распределений вероятностей с применением для оптимизации портфеля и оценки плотности» (PDF) . Анналы исследования операций . 299 (1–2). Спрингер: 1281–1315. arXiv : 1811.11301 . дои : 10.1007/s10479-019-03373-1 . S2CID 254231768 . Проверено 27 февраля 2023 г.
- ^ Гельмерт Ф.Р. (1875 г.). «О вычислении вероятной ошибки по конечному числу истинных ошибок наблюдения». Журнал прикладной математики и физики (на немецком языке). 20 :300-303.
- ^ Гельмерт Ф.Р. (1876 г.). «О вероятности степенных сумм ошибок наблюдения и о некоторых связанных с этим вопросах». Журнал прикладной математики и физики (на немецком языке). 21 : 192–218.
- ^ Гельмерт Ф.Р. (1876 г.). «Точность формулы Петерса для расчета вероятной ошибки наблюдения прямых наблюдений той же точности » . Астрономические новости (на немецком языке). 88 (8–9): 113–132. Бибкод : 1876AN.....88..113H . дои : 10.1002/asna.18760880802 .
- ^ Люрот Дж (1876). «Сравнение двух значений вероятной ошибки» . Астрономические новости (на немецком языке). 87 (14): 209–220. Бибкод : 1876AN.....87..209L . дои : 10.1002/asna.18760871402 .
- ^ Пфанзагль Дж., Шейнин О. (1996). «Исследования по истории вероятности и статистики. XLIV. Предшественник t- распределения». Биометрика . 83 (4): 891–898. дои : 10.1093/biomet/83.4.891 . МР 1766040 .
- ^ Шейнин О. (1995). «Работа Гельмерта по теории ошибок». Архив истории точных наук . 49 (1): 73–104. дои : 10.1007/BF00374700 . S2CID 121241599 .
- ^ Пирсон, К. (1895). «Вклад в математическую теорию эволюции. II. Косые изменения в однородном материале» (PDF) . Философские труды Королевского общества A : Математические, физические и технические науки . 186 (374): 343–414. Бибкод : 1895RSPTA.186..343P . дои : 10.1098/rsta.1895.0010 . ISSN 1364-503X .
- ^ «Студент» [ псев. Уильям Сили Госсет ] (1908). «Вероятная ошибка среднего» (PDF) . Биометрика . 6 (1): 1–25. дои : 10.1093/биомет/6.1.1 . hdl : 10338.dmlcz/143545 . JSTOR 2331554 .
{{cite journal}}: CS1 maint: числовые имена: список авторов ( ссылка ) - ^ Вендл MC (2016). «Псевдонимная слава». Наука . 351 (6280): 1406. Бибкод : 2016Sci...351.1406W . дои : 10.1126/science.351.6280.1406 . ПМИД 27013722 .
- ^ Мортимер Р.Г. (2005). Математика для физической химии (3-е изд.). Берлингтон, Массачусетс: Elsevier. стр. 326 . ISBN 9780080492889 . OCLC 156200058 .
- ^ Перейти обратно: а б Фишер Р.А. (1925). «Приложения «Студенческой» раздачи» (PDF) . Метрон . 5 : 90–104. Архивировано из оригинала (PDF) 5 марта 2016 года.
- ^ Уолпол Р.Э., Майерс Р., Майерс С., Й.К. (2006). Вероятность и статистика для инженеров и ученых (7-е изд.). Нью-Дели, Индиана: Пирсон. п. 237. ИСБН 9788177584042 . OCLC 818811849 .
- ^ Крушке, Дж. К. (2015). Выполнение байесовского анализа данных (2-е изд.). Академическая пресса. ISBN 9780124058880 . OCLC 959632184 .
- ^ Казелла Дж., Бергер Р.Л. (1990). Статистический вывод . Ресурсный центр Даксбери. п. 56. ИСБН 9780534119584 .
- ^ Перейти обратно: а б Джекман, С. (2009). Байесовский анализ для социальных наук . Ряд Уайли по вероятности и статистике. Уайли. п. 507 . дои : 10.1002/9780470686621 . ISBN 9780470011546 .
- ^ Джонсон Н.Л., Коц С., Балакришнан Н. (1995). «Глава 28». Непрерывные одномерные распределения . Том. 2 (2-е изд.). Уайли. ISBN 9780471584940 .
- ^ Хогг Р.В. , Крейг А.Т. (1978). Введение в математическую статистику (4-е изд.). Нью-Йорк: Макмиллан. ASIN B010WFO0SA . Разделы 4.4 и 4.8
{{cite book}}: CS1 maint: постскриптум ( ссылка ) - ^ Кокран В.Г. (1934). «Распределение квадратичных форм в нормальной системе с приложениями к ковариационному анализу». Математика. Учеб. Кэмб. Филос. Соц. 30 (2): 178–191. Бибкод : 1934PCPS...30..178C . дои : 10.1017/S0305004100016595 . S2CID 122547084 .
- ^ Гельман А.Б., Карлин Дж.С., Рубин Д.Б., Стерн Х.С. (1997). Байесовский анализ данных (2-е изд.). Бока-Ратон, Флорида: Chapman & Hal lp 68. ISBN 9780412039911 .
- ^ Пак С.Ю., Бера АК (2009). «Модель условной гетероскедастичности авторегрессии с максимальной энтропией». Дж. Экономик. 150 (2): 219–230. doi : 10.1016/j.jeconom.2008.12.014 .
- ^ Перейти обратно: а б Бэйли Р.В. (1994). «Полярная генерация случайных величин с t- распределением». Математика вычислений . 62 (206): 779–781. Бибкод : 1994MaCom..62..779B . дои : 10.2307/2153537 . JSTOR 2153537 . S2CID 120459654 .
- ^ Орд Дж. К. (1972). Семейства частотных распределений . Лондон, Великобритания: Гриффин. Таблица 5.1. ISBN 9780852641378 .
- ^ Орд Дж. К. (1972). Семейства частотных распределений . Лондон, Великобритания: Гриффин. Глава 5. ISBN 9780852641378 .
- ^ Ланге К.Л., Литтл Р.Дж., Тейлор Дж.М. (1989). «Надежное статистическое моделирование с использованием t- распределения» (PDF) . Дж. Ам. Стат. доц. 84 (408): 881–896. дои : 10.1080/01621459.1989.10478852 . JSTOR 2290063 .
- ^ Гельман А.Б., Карлин Дж.Б., Стерн Х.С. и др. (2014). «Вычислительно эффективное моделирование цепи Маркова». Байесовский анализ данных . Бока-Ратон, Флорида: CRC Press. п. 293. ИСБН 9781439898208 .
- ^ Шах, Амар; Уилсон, Эндрю Гордон; Гахрамани, Зубин (2014). «Процессы Стьюдента как альтернатива гауссовским процессам» (PDF) . JMLR . 33 (Материалы 17-й Международной конференции по искусственному интеллекту и статистике (AISTATS), 2014 г., Рейкьявик, Исландия): 877–885. arXiv : 1402.4306 .
- ^ Чен, Цзэсюнь; Ван, Бо; Горбань, Александр Н. (2019). «Многомерная регрессия процессов Гаусса и Стьюдента для прогнозирования с несколькими выходами» . Нейронные вычисления и их приложения . 32 (8): 3005–3028. arXiv : 1703.04455 . дои : 10.1007/s00521-019-04687-8 .
- ^ Сунь, Цзинчао; Конг, Майинг; Пал, Субхадип (22 июня 2021 г.). «Модифицированное полунормальное распределение: свойства и эффективная схема выборки» . Коммуникации в статистике - теория и методы . 52 (5): 1591–1613. дои : 10.1080/03610926.2021.1934700 . ISSN 0361-0926 . S2CID 237919587 .
Ссылки
[ редактировать ]- Сенн, С.; Ричардсон, В. (1994). «Первый т- тест». Статистика в медицине . 13 (8): 785–803. дои : 10.1002/сим.4780130802 . ПМИД 8047737 .
- Хогг Р.В. , Крейг А.Т. (1978). Введение в математическую статистику (4-е изд.). Нью-Йорк: Макмиллан. ASIN B010WFO0SA .
- Венейблс, Западная Нью-Йорк; Рипли, Б.Д. (2002). Современная прикладная статистика с S (Четвертое изд.). Спрингер.
- Гельман, Эндрю; Джон Б. Карлин; Хэл С. Стерн; Дональд Б. Рубин (2003). Байесовский анализ данных (второе изд.). CRC/Чепмен и Холл. ISBN 1-58488-388-Х .
Внешние ссылки
[ редактировать ]- «Распределение студентов» , Математическая энциклопедия , EMS Press , 2001 [1994]
- Самые ранние известные варианты использования некоторых математических слов (S) (Замечания об истории термина «Распределение Стьюдента»)
- Руо, М. (2013), Вероятность, статистика и оценка (PDF) (краткая редакция), Первые студенты, стр. 112.
- t-распределение студента , архивировано 10 апреля 2021 г. в Wayback Machine.