Tamil script
| Tamil தமிழ் | |
|---|---|
 | |
| Script type | |
Time period | c. 400 CE – present[1][2] |
| Direction | Left-to-right |
| Languages | Tamil Kanikkaran Badaga Irula Paniya Saurashtra |
| Related scripts | |
Parent systems | |
Sister systems | Grantha, Old Mon, Khmer, Cham, Kawi |
| ISO 15924 | |
| ISO 15924 | Taml (346), Tamil |
| Unicode | |
Unicode alias | Tamil |
| |
| Brahmic scripts |
|---|
| The Brahmi script and its descendants |
The Tamil script (தமிழ் அரிச்சுவடி Tamiḻ ariccuvaṭi [tamiɻ ˈaɾitːɕuʋaɽi]) is an abugida script that is used by Tamils and Tamil speakers in India, Sri Lanka, Malaysia, Singapore, Indonesia and elsewhere to write the Tamil language.[5] It is one of the official scripts of the Indian Republic. Certain minority languages such as Saurashtra, Badaga, Irula and Paniya are also written in the Tamil script.[6]
Characteristics
[edit]
The Tamil script has 12 vowels (உயிரெழுத்து, uyireḻuttu, "soul-letters"), 18 consonants (மெய்யெழுத்து, meyyeḻuttu, "body-letters") and one special character, the ஃ (ஆய்த எழுத்து, āytha eḻuttu). ஃ is called "அக்கு", akku and is classified in Tamil orthography as being neither a consonant nor a vowel.[7] However, it is listed at the end of the vowel set. The script is syllabic, not alphabetic. It is written from left to right.
History
[edit]

The Tamil script, like the other Brahmic scripts, is thought to have evolved from the original Brahmi script.[8] The earliest inscriptions which are accepted examples of Tamil writing date to the Ashokan period. The script used by such inscriptions is commonly known as the Tamil-Brahmi or "Tamili script" and differs in many ways from standard Ashokan Brahmi. For example, early Tamil-Brahmi, unlike Ashokan Brahmi, had a system to distinguish between pure consonants (m, in this example) and consonants with an inherent vowel (ma, in this example). In addition, according to Iravatham Mahadevan, early Tamil Brahmi used slightly different vowel markers, had extra characters to represent letters not found in Sanskrit and omitted letters for sounds not present in Tamil such as voiced consonants and aspirates.[8] Inscriptions from the 2nd century use a later form of Tamil-Brahmi, which is substantially similar to the writing system described in the Tolkāppiyam, an ancient Tamil grammar. Most notably, they used the puḷḷi to suppress the inherent vowel.[9] The Tamil letters thereafter evolved towards a more rounded form and by the 5th or 6th century, they had reached a form called the early vaṭṭeḻuttu.[10]
The modern Tamil script does not, however, descend from that script.[11] In the 4th century,[12] the Pallava dynasty created a new script called Pallava script for Tamil and the Grantha alphabet evolved from it, adding the Vaṭṭeḻuttu alphabet for sounds not found to write Sanskrit.[4] Parallel to Grantha alphabet a new script (Chola-Pallava script, which evolved to modern Tamil script) again emerged in Pallava and Chola territories resembling the same glyph development like Grantha, however, heavily reduced in its shapes and not overtaking non-native Tamil sounds. By the 8th century, the new scripts supplanted Vaṭṭeḻuttu in the Pallava and Chola kingdoms which lay in the north portion of the Tamil-speaking region. However, Vaṭṭeḻuttu continued to be used in the southern portion of the Tamil-speaking region, in the Chera and Pandyan kingdoms until the 11th century, when the Pandyan kingdom was conquered by the Cholas who inherited while being feudatory of Pallavas for a short time.[3][4]
With the fall of Pallava kingdom, the Chola dynasty pushed the Chola-Pallava script as the de facto script. Over the next few centuries, the Chola-Pallava script evolved into the modern Tamil script. The Grantha and its parent script influenced the Tamil script notably. The use of palm leaves as the primary medium for writing led to changes in the script. The scribe had to be careful not to pierce the leaves with the stylus while writing because a leaf with a hole was more likely to tear and decay faster. As a result, the use of the puḷḷi to distinguish pure consonants became rare, with pure consonants usually being written as if the inherent vowel were present. Similarly, the vowel marker (ஃ) called: Tamil: குற்றியலுகரம், romanized: kuṟṟiyal-ukaram, lit. 'short 'u'-sound', a half-rounded u which occurs at the end of some words and in the medial position in certain compound words, marking a shortened u sound, also fell out of use and was replaced by the marker for the simple u (ு). The puḷḷi (ஂ) did not fully reappear until the introduction of printing, but the marker kuṟṟiyal-ukaram (ஃ) never came back for this purpose into use although its usage is retained in certain grammatical conceptual words whereas the sound itself still exists and plays an important role in Tamil prosody.
The forms of some of the letters were simplified in the 19th century to make the script easier to typeset. In the 20th century, the script was simplified even further in a series of reforms, which regularised the vowel markers used with consonants by eliminating special markers and most irregular forms.
Relationship with other Indic scripts
[edit]The Tamil script differs from other Brahmi-derived scripts in a number of ways. Unlike every other Brahmic script, it does not regularly represent voiced or aspirated stop consonants as these are not phonemes of the Tamil language even though voiced and fricative allophones of stops do appear in spoken Tamil. Thus the character க் k, for example, represents /k/ but can also be pronounced [g] or [x] based on the rules of Tamil phonology. A separate set of characters appears for these sounds when the Tamil script is used to write Sanskrit or other languages.
Also unlike other Brahmi scripts, the Tamil script rarely uses typographic ligatures to represent conjunct consonants, which are far less frequent in Tamil than in other Indian languages. Where they occur, conjunct consonants are written by writing the character for the first consonant, adding the puḷḷi to suppress its inherent vowel, and then writing the character for the second consonant. There are a few exceptions, namely க்ஷ kṣa and ஶ்ரீ śrī.
ISO 15919 is an international standard for the transliteration of Tamil and other Indic scripts into Latin characters. It uses diacritics to map the much larger set of Brahmic consonants and vowels to the Latin script.
Letters
[edit]



Basic consonants
[edit]Consonants are called the "body" (mei) letters. The consonants are classified into three categories: vallinam (hard consonants), mellinam (soft consonants, including all nasals), and itayinam (medium consonants).
There are some lexical rules for the formation of words. The Tolkāppiyam describes such rules. Some examples: a word cannot end in certain consonants, and cannot begin with some consonants including r-, l- and ḻ-; there are six nasal consonants in Tamil: a velar nasal ங், a palatal nasal ஞ், a retroflex nasal ண், a dental nasal ந், a bilabial nasal ம், and an alveolar nasal ன்.
The order of the alphabet (strictly abugida) in Tamil closely matches that of the nearby languages both in location and linguistics, reflecting the common origin of their scripts from Brahmi.
Tamil language has 18 consonants - mey eluttukkal. Traditional grammarians have classified these 18 into three groups of 6 letters each. This classification is done based on the method of articulation and hence the nature of these letters. Vallinam (hard group,) Mellinam (soft group) and idaiyinam (medium group). All consonants are pronounced for a half unit (māttirai) time length when isolated (consonants combined with vowels will be pronounced with the time length of the vowel).[13]
| Consonant | ISO 15919 | Category | IPA |
|---|---|---|---|
| க் | k | vallinam | /k/ |
| ங் | ṅ | mellinam | /ŋ/ |
| ச் | c | vallinam | /t͡ʃ, s/ |
| ஞ் | ñ | mellinam | /ɲ/ |
| ட் | ṭ | vallinam | /ʈ/ |
| ண் | ṇ | mellinam | /ɳ/ |
| த் | t | vallinam | /t̪/ |
| ந் | n | mellinam | /n̪/ |
| ப் | p | vallinam | /p/ |
| ம் | m | mellinam | /m/ |
| ய் | y | idaiyinam | /j/ |
| ர் | r | idaiyinam | /ɾ/ |
| ல் | l | idaiyinam | /l/ |
| வ் | v | idaiyinam | /ʋ/ |
| ழ் | ḻ | idaiyinam | /ɻ/ |
| ள் | ḷ | idaiyinam | /ɭ/ |
| ற் | ṟ | vallinam | /r/ |
| ன் | ṉ | mellinam | [n] |
Extra consonants used in Tamil
[edit]The Tamil speech has incorporated many phonemes that were not part of the Tolkāppiyam classification. The letters used to write these sounds, known as Grantha, are used as part of Tamil. These are taught from elementary school and incorporated in Tamil All Character Encoding (TACE16).
| Consonant | ISO 15919 | IPA |
|---|---|---|
| ஜ் | j | /d͡ʒ/ |
| ஶ் | ś | /ʃ/ |
| ஷ் | ṣ | /ʂ/ |
| ஸ் | s | /s/ |
| ஹ் | h | /h/ |
| க்ஷ் | kṣ | /kʂ/ |
There is also the compound ஶ்ரீ (śrī), equivalent to श्री in Devanagari.
Combinations of consonants with ஃ (ஆய்த எழுத்து, āyda eḻuttu, equivalent to nuqta) are occasionally used to represent phonemes of foreign languages, especially to write Islamic and Christian texts. For example: asif = அசிஃப், azārutīn̠ = அஃஜாருதீன், Genghis Khan = கெங்கிஸ் ஃகான்.[citation needed]
A nuqta-like diacritic is used while writing the Badaga language and double dot nuqta for the Irula language to transcribe its sounds.[15]
There has also been effort to differentiate voiced and voiceless consonants through subscripted numbers – two, three, and four which stand for the unvoiced aspirated, voiced, voiced aspirated respectively. This was used to transcribe Sanskrit words in Sanskrit–Tamil books, as shown in the table below.[16][17]
| க ka | க₂ kha | க₃ ga | க₄ gha |
| ச ca | ச₂ cha | ஜ ja | ஜ₂ jha |
| ட ṭa | ட₂ ṭha | ட₃ ḍa | ட₄ ḍha |
| த ta | த₂ tha | த₃ da | த₄ dha |
| ப pa | ப₂ pha | ப₃ ba | ப₄ bha |
The Unicode Standard uses superscripted digits for the same purpose, as in ப² pha, ப³ ba, and ப⁴ bha.[18]
Vowels
[edit]Vowels are also called the 'life' (uyir) or 'soul' letters. Together with the consonants (mei, which are called 'body' letters), they form compound, syllabic (abugida) letters that are called 'living' or 'embodied' letters (uyir mei, i.e. letters that have both 'body' and 'soul').
Tamil language has 12 vowels which are divided into short and long (five of each type) and two diphthongs.
| Independent | Vowel sign | ISO 15919 | IPA |
|---|---|---|---|
| அ | — | a | /ɐ/ |
| ஆ | ா | ā | /aː/ |
| இ | ி | i | /i/ |
| ஈ | ீ | ī | /iː/ |
| உ | ு | u | /u/ |
| ஊ | ூ | ū | /uː/ |
| எ | ெ | e | /e/ |
| ஏ | ே | ē | /eː/ |
| ஐ | ை | ai | /ɐi̯/ |
| ஒ | ொ | o | /o/ |
| ஓ | ோ | ō | /oː/ |
| ஔ | ௌ | au | /ɐu̯/ |
Compound form
[edit]Using the consonant 'k' as an example:
| Formation | Compound form | ISO 15919 | IPA |
|---|---|---|---|
| க் + அ | க | ka | /kɐ/ |
| க் + ஆ | கா | kā | /kaː/ |
| க் + இ | கி | ki | /ki/ |
| க் + ஈ | கீ | kī | /kiː/ |
| க் + உ | கு | ku | /ku/ |
| க் + ஊ | கூ | kū | /kuː/ |
| க் + எ | கெ | ke | /ke/ |
| க் + ஏ | கே | kē | /keː/ |
| க் + ஐ | கை | kai | /kɐi̯/ |
| க் + ஒ | கொ | ko | /ko/ |
| க் + ஓ | கோ | kō | /koː/ |
| க் + ஔ | கௌ | kau | /kɐu̯/ |
The special letter ஃ, represented by three dots, is called āyta eḻuttu or aḵ. It originally represented an archaic Tamil retention of the Dravidian sound ḥ, which has been lost in almost all modern Dravidian languages, and in Tamil traditionally serves a purely grammatical function, but in modern times it has come to be used as a diacritic to represent foreign sounds. For example, ஃப is used for the English sound f, not found in Tamil. It also served before palm leaves became the primary writing medium for words ending with an inherent consonsant-vowel u as a pronouncing rule for a short u, called – Tamil: குற்றியலுகரம், romanized: kuṟṟiyal-ukaram, lit. 'short 'u'-sound'. Following consonants rendered this behaviour: கு, சு, டு, து, பு, று. Instead of writing like in modern days without any markers, for example (Tamil: அது, romanized: Atu), it was written with a preceding ஃ, like – Tamil: அஃது, romanized: Aḥtu.
Another archaic Tamil letter ஂ, represented by a small hollow circle and called Aṉuvara, is the Anusvara. It was traditionally used as a homorganic nasal when in front of a consonant, and either as a bilabial nasal (m) or alveolar nasal (n) at the end of a word, depending on the context.
The long (nedil) vowels are about twice as long as the short (kuṟil) vowels. The diphthongs are usually pronounced about one and a half times as long as the short vowels, though some grammatical texts place them with the long (nedil) vowels.
As can be seen in the compound form, the vowel sign can be added to the right, left or both sides of the consonants. It can also form a ligature. These rules are evolving and older use has more ligatures than modern use. What you actually see on this page depends on your font selection; for example, Code2000 will show more ligatures than Latha.
There are proponents of script reform who want to eliminate all ligatures and let all vowel signs appear on the right side.
Unicode encodes the character in logical order (always the consonant first), whereas legacy 8-bit encodings (such as TSCII) prefer the written order. This makes it necessary to reorder when converting from one encoding to another; it is not sufficient simply to map one set of code points to the other.
Compound table of Tamil letters
[edit]The following table lists vowel (uyir or life) letters across the top and consonant (mei or body) letters along the side, the combination of which gives all Tamil compound (uyirmei) letters.
| Tolkāppiyam consonants | Vowels | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ∅ a | ா ā | ி i | ீ ī | ு u | ூ ū | ெ e | ே ē | ை ai | ொ o | ோ ō | ௌ au | ||
| ∅ (Independent) | அ | ஆ | இ | ஈ | உ | ஊ | எ | ஏ | ஐ | ஒ | ஓ | ஔ | |
| க் | k | க | கா | கி | கீ | கு | கூ | கெ | கே | கை | கொ | கோ | கௌ |
| ங் | ṅ | ங | ஙா | ஙி | ஙீ | ஙு | ஙூ | ஙெ | ஙே | ஙை | ஙொ | ஙோ | ஙௌ |
| ச் | c | ச | சா | சி | சீ | சு | சூ | செ | சே | சை | சொ | சோ | சௌ |
| ஞ் | ñ | ஞ | ஞா | ஞி | ஞீ | ஞு | ஞூ | ஞெ | ஞே | ஞை | ஞொ | ஞோ | ஞௌ |
| ட் | ṭ | ட | டா | டி | டீ | டு | டூ | டெ | டே | டை | டொ | டோ | டௌ |
| ண் | ṇ | ண | ணா | ணி | ணீ | ணு | ணூ | ணெ | ணே | ணை | ணொ | ணோ | ணௌ |
| த் | t | த | தா | தி | தீ | து | தூ | தெ | தே | தை | தொ | தோ | தௌ |
| ந் | n | ந | நா | நி | நீ | நு | நூ | நெ | நே | நை | நொ | நோ | நௌ |
| ப் | p | ப | பா | பி | பீ | பு | பூ | பெ | பே | பை | பொ | போ | பௌ |
| ம் | m | ம | மா | மி | மீ | மு | மூ | மெ | மே | மை | மொ | மோ | மௌ |
| ய் | y | ய | யா | யி | யீ | யு | யூ | யெ | யே | யை | யொ | யோ | யௌ |
| ர் | r | ர | ரா | ரி | ரீ | ரு | ரூ | ரெ | ரே | ரை | ரொ | ரோ | ரௌ |
| ல் | l | ல | லா | லி | லீ | லு | லூ | லெ | லே | லை | லொ | லோ | லௌ |
| வ் | v | வ | வா | வி | வீ | வு | வூ | வெ | வே | வை | வொ | வோ | வௌ |
| ழ் | ḻ | ழ | ழா | ழி | ழீ | ழு | ழூ | ழெ | ழே | ழை | ழொ | ழோ | ழௌ |
| ள் | ḷ | ள | ளா | ளி | ளீ | ளு | ளூ | ளெ | ளே | ளை | ளொ | ளோ | ளௌ |
| ற் | ṟ | ற | றா | றி | றீ | று | றூ | றெ | றே | றை | றொ | றோ | றௌ |
| ன் | ṉ | ன | னா | னி | னீ | னு | னூ | னெ | னே | னை | னொ | னோ | னௌ |
| Grantha consonants | Vowels | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ∅ a | ா ā | ி i | ீ ī | ு u | ூ ū | ெ e | ே ē | ை ai | ொ o | ோ ō | ௌ au | ||
| ஶ் | ś | ஶ | ஶா | ஶி | ஶீ | ஶு | ஶூ | ஶெ | ஶே | ஶை | ஶொ | ஶோ | ஶௌ |
| ஜ் | j | ஜ | ஜா | ஜி | ஜீ | ஜு | ஜூ | ஜெ | ஜே | ஜை | ஜொ | ஜோ | ஜௌ |
| ஷ் | ṣ | ஷ | ஷா | ஷி | ஷீ | ஷு | ஷூ | ஷெ | ஷே | ஷை | ஷொ | ஷோ | ஷௌ |
| ஸ் | s | ஸ | ஸா | ஸி | ஸீ | ஸு | ஸூ | ஸெ | ஸே | ஸை | ஸொ | ஸோ | ஸௌ |
| ஹ் | h | ஹ | ஹா | ஹி | ஹீ | ஹு | ஹூ | ஹெ | ஹே | ஹை | ஹொ | ஹோ | ஹௌ |
| க்ஷ் | kṣ | க்ஷ | க்ஷா | க்ஷி | க்ஷீ | க்ஷு | க்ஷூ | க்ஷெ | க்ஷே | க்ஷை | க்ஷொ | க்ஷோ | க்ஷௌ |
Writing order
[edit]
















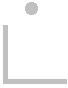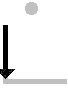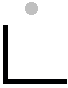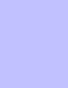













Numerals and symbols
[edit]Apart from the usual numerals (from 0 to 9), Tamil also has numerals for 10, 100 and 1000. Symbols for fraction and other number-based concepts can also be found.[19]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 100 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ௦ | ௧ | ௨ | ௩ | ௪ | ௫ | ௬ | ௭ | ௮ | ௯ | ௰ | ௱ | ௲ |
| day | month | year | debit | credit | as above | rupee | numeral | time | quantity |
|---|---|---|---|---|---|---|---|---|---|
| ௳ | ௴ | ௵ | ௶ | ௷ | ௸ | ௹ | ௺ | ள | வ |
Unicode
[edit]Tamil script was added to the Unicode Standard in October 1991 with the release of version 1.0.0. The Unicode block for Tamil is U+0B80–U+0BFF. Grey areas indicate non-assigned code points. Most of the non-assigned code points are designated reserved because they are in the same relative position as characters assigned in other South Asian script blocks that correspond to phonemes that don't exist in the Tamil script.
Efforts to unify the Grantha script with Tamil have been made;[16][20] however the proposals triggered discontent by some.[21][22] Eventually, considering the sensitivity involved, it was determined that the two scripts should be encoded independently, except for the numerals.[23]
| Tamil[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+0B8x | ஂ | ஃ | அ | ஆ | இ | ஈ | உ | ஊ | எ | ஏ | ||||||
| U+0B9x | ஐ | ஒ | ஓ | ஔ | க | ங | ச | ஜ | ஞ | ட | ||||||
| U+0BAx | ண | த | ந | ன | ப | ம | ய | |||||||||
| U+0BBx | ர | ற | ல | ள | ழ | வ | ஶ | ஷ | ஸ | ஹ | ா | ி | ||||
| U+0BCx | ீ | ு | ூ | ெ | ே | ை | ொ | ோ | ௌ | ் | ||||||
| U+0BDx | ௐ | ௗ | ||||||||||||||
| U+0BEx | ௦ | ௧ | ௨ | ௩ | ௪ | ௫ | ௬ | ௭ | ௮ | ௯ | ||||||
| U+0BFx | ௰ | ௱ | ௲ | ௳ | ௴ | ௵ | ௶ | ௷ | ௸ | ௹ | ௺ | |||||
| Notes | ||||||||||||||||
Proposals to encode characters used for fractional values in traditional accounting practices were submitted.[24] Although discouraged by the ICTA of Sri Lanka,[25] the proposal was recognized by the Government of Tamil Nadu[26] and were added to the Unicode Standard in March 2019 with the release of version 12.0. The Unicode block for Tamil Supplement is U+11FC0–U+11FFF:
| Tamil Supplement[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+11FCx | 𑿀 | 𑿁 | 𑿂 | 𑿃 | 𑿄 | 𑿅 | 𑿆 | 𑿇 | 𑿈 | 𑿉 | 𑿊 | 𑿋 | 𑿌 | 𑿍 | 𑿎 | 𑿏 |
| U+11FDx | 𑿐 | 𑿑 | 𑿒 | 𑿓 | 𑿔 | 𑿕 | 𑿖 | 𑿗 | 𑿘 | 𑿙 | 𑿚 | 𑿛 | 𑿜 | 𑿝 | 𑿞 | 𑿟 |
| U+11FEx | 𑿠 | 𑿡 | 𑿢 | 𑿣 | 𑿤 | 𑿥 | 𑿦 | 𑿧 | 𑿨 | 𑿩 | 𑿪 | 𑿫 | 𑿬 | 𑿭 | 𑿮 | 𑿯 |
| U+11FFx | 𑿰 | 𑿱 | 𑿿 | |||||||||||||
| Notes | ||||||||||||||||
Syllabary
[edit]Like other South Asian scripts in Unicode, the Tamil encoding was originally derived from the ISCII standard. Both ISCII and Unicode encode Tamil as an abugida. In an abugida, each basic character represents a consonant and default vowel. Consonants with a different vowel or bare consonants are represented by adding a modifier character to a base character. Each code point representing a similar phoneme is encoded in the same relative position in each South Asian script block in Unicode, including Tamil. Because Unicode represents Tamil as an abugida all the pure consonants (consonants with no associated vowel) and syllables in Tamil can be represented by combining multiple Unicode code points, as can be seen in the Unicode Tamil Syllabary below. In Unicode 5.1, named sequences were added for all Tamil consonants and syllables.
Unicode 5.1 also has a named sequence for the Tamil ligature SRI (śrī), ஶ்ரீ, written using ஶ (śa). The name of this sequence is TAMIL SYLLABLE SHRII and is composed of the Unicode sequence U+0BB6 U+0BCD U+0BB0 U+0BC0. The ligature can also be written using ஸ (sa) to create an identical ligature ஸ்ரீ composed of the Unicode sequence U+0BB8 U+0BCD U+0BB0 U+0BC0; but this is discouraged by the Unicode standard.[27]
| Consonants | Vowels | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| அ 0B85 | ஆ 0B86 | இ 0B87 | ஈ 0B88 | உ 0B89 | ஊ 0B8A | எ 0B8E | ஏ 0B8F | ஐ 0B90 | ஒ 0B92 | ஓ 0B93 | ஔ 0B94 | |
| க் 0B95 0BCD | க 0B95 | கா 0B95 0BBE | கி 0B95 0BBF | கீ 0B95 0BC0 | கு 0B95 0BC1 | கூ 0B95 0BC2 | கெ 0B95 0BC6 | கே 0B95 0BC7 | கை 0B95 0BC8 | கொ 0B95 0BCA | கோ 0B95 0BCB | கௌ 0B95 0BCC |
| ங் 0B99 0BCD | ங 0B99 | ஙா 0B99 0BBE | ஙி 0B99 0BBF | ஙீ 0B99 0BC0 | ஙு 0B99 0BC1 | ஙூ 0B99 0BC2 | ஙெ 0B99 0BC6 | ஙே 0B99 0BC7 | ஙை 0B99 0BC8 | ஙொ 0B99 0BCA | ஙோ 0B99 0BCB | ஙௌ 0B99 0BCC |
| ச் 0B9A 0BCD | ச 0B9A | சா 0B9A 0BBE | சி 0B9A 0BBF | சீ 0B9A 0BC0 | சு 0B9A 0BC1 | சூ 0B9A 0BC2 | செ 0B9A 0BC6 | சே 0B9A 0BC7 | சை 0B9A 0BC8 | சொ 0B9A 0BCA | சோ 0B9A 0BCB | சௌ 0B9A 0BCC |
| ஞ் 0B9E 0BCD | ஞ 0B9E | ஞா 0B9E 0BBE | ஞி 0B9E 0BBF | ஞீ 0B9E 0BC0 | ஞு 0B9E 0BC1 | ஞூ 0B9E 0BC2 | ஞெ 0B9E 0BC6 | ஞே 0B9E 0BC7 | ஞை 0B9E 0BC8 | ஞொ 0B9E 0BCA | ஞோ 0B9E 0BCB | ஞௌ 0B9E 0BCC |
| ட் 0B9F 0BCD | ட 0B9F | டா 0B9F 0BBE | டி 0B9F 0BBF | டீ 0B9F 0BC0 | டு 0B9F 0BC1 | டூ 0B9F 0BC2 | டெ 0B9F 0BC6 | டே 0B9F 0BC7 | டை 0B9F 0BC8 | டொ 0B9F 0BCA | டோ 0B9F 0BCB | டௌ 0B9F 0BCC |
| ண் 0BA3 0BCD | ண 0BA3 | ணா 0BA3 0BBE | ணி 0BA3 0BBF | ணீ 0BA3 0BC0 | ணு 0BA3 0BC1 | ணூ 0BA3 0BC2 | ணெ 0BA3 0BC6 | ணே 0BA3 0BC7 | ணை 0BA3 0BC8 | ணொ 0BA3 0BCA | ணோ 0BA3 0BCB | ணௌ 0BA3 0BCC |
| த் 0BA4 0BCD | த 0BA4 | தா 0BA4 0BBE | தி 0BA4 0BBF | தீ 0BA4 0BC0 | து 0BA4 0BC1 | தூ 0BA4 0BC2 | தெ 0BA4 0BC6 | தே 0BA4 0BC7 | தை 0BA4 0BC8 | தொ 0BA4 0BCA | தோ 0BA4 0BCB | தௌ 0BA4 0BCC |
| ந் 0BA8 0BCD | ந 0BA8 | நா 0BA8 0BBE | நி 0BA8 0BBF | நீ 0BA8 0BC0 | நு 0BA8 0BC1 | நூ 0BA8 0BC2 | நெ 0BA8 0BC6 | நே 0BA8 0BC7 | நை 0BA8 0BC8 | நொ 0BA8 0BCA | நோ 0BA8 0BCB | நௌ 0BA8 0BCC |
| ப் 0BAA 0BCD | ப 0BAA | பா 0BAA 0BBE | பி 0BAA 0BBF | பீ 0BAA 0BC0 | பு 0BAA 0BC1 | பூ 0BAA 0BC2 | பெ 0BAA 0BC6 | பே 0BAA 0BC7 | பை 0BAA 0BC8 | பொ 0BAA 0BCA | போ 0BAA 0BCB | பௌ 0BAA 0BCC |
| ம் 0BAE 0BCD | ம 0BAE | மா 0BAE 0BBE | மி 0BAE 0BBF | மீ 0BAE 0BC0 | மு 0BAE 0BC1 | மூ 0BAE 0BC2 | மெ 0BAE 0BC6 | மே 0BAE 0BC7 | மை 0BAE 0BC8 | மொ 0BAE 0BCA | மோ 0BAE 0BCB | மௌ 0BAE 0BCC |
| ய் 0BAF 0BCD | ய 0BAF | யா 0BAF 0BBE | யி 0BAF 0BBF | யீ 0BAF 0BC0 | யு 0BAF 0BC1 | யூ 0BAF 0BC2 | யெ 0BAF 0BC6 | யே 0BAF 0BC7 | யை 0BAF 0BC8 | யொ 0BAF 0BCA | யோ 0BAF 0BCB | யௌ 0BAF 0BCC |
| ர் 0BB0 0BCD | ர 0BB0 | ரா 0BB0 0BBE | ரி 0BB0 0BBF | ரீ 0BB0 0BC0 | ரு 0BB0 0BC1 | ரூ 0BB0 0BC2 | ரெ 0BB0 0BC6 | ரே 0BB0 0BC7 | ரை 0BB0 0BC8 | ரொ 0BB0 0BCA | ரோ 0BB0 0BCB | ரௌ 0BB0 0BCC |
| ல் 0BB2 0BCD | ல 0BB2 | லா 0BB2 0BBE | லி 0BB2 0BBF | லீ 0BB2 0BC0 | லு 0BB2 0BC1 | லூ 0BB2 0BC2 | லெ 0BB2 0BC6 | லே 0BB2 0BC7 | லை 0BB2 0BC8 | லொ 0BB2 0BCA | லோ 0BB2 0BCB | லௌ 0BB2 0BCC |
| வ் 0BB5 0BCD | வ 0BB5 | வா 0BB5 0BBE | வி 0BB5 0BBF | வீ 0BB5 0BC0 | வு 0BB5 0BC1 | வூ 0BB5 0BC2 | வெ 0BB5 0BC6 | வே 0BB5 0BC7 | வை 0BB5 0BC8 | வொ 0BB5 0BCA | வோ 0BB5 0BCB | வௌ 0BB5 0BCC |
| ழ் 0BB4 0BCD | ழ 0BB4 | ழா 0BB4 0BBE | ழி 0BB4 0BBF | ழீ 0BB4 0BC0 | ழு 0BB4 0BC1 | ழூ 0BB4 0BC2 | ழெ 0BB4 0BC6 | ழே 0BB4 0BC7 | ழை 0BB4 0BC8 | ழொ 0BB4 0BCA | ழோ 0BB4 0BCB | ழௌ 0BB4 0BCC |
| ள் 0BB3 0BCD | ள 0BB3 | ளா 0BB3 0BBE | ளி 0BB3 0BBF | ளீ 0BB3 0BC0 | ளு 0BB3 0BC1 | ளூ 0BB3 0BC2 | ளெ 0BB3 0BC6 | ளே 0BB3 0BC7 | ளை 0BB3 0BC8 | ளொ 0BB3 0BCA | ளோ 0BB3 0BCB | ளௌ 0BB3 0BCC |
| ற் 0BB1 0BCD | ற 0BB1 | றா 0BB1 0BBE | றி 0BB1 0BBF | றீ 0BB1 0BC0 | று 0BB1 0BC1 | றூ 0BB1 0BC2 | றெ 0BB1 0BC6 | றே 0BB1 0BC7 | றை 0BB1 0BC8 | றொ 0BB1 0BCA | றோ 0BB1 0BCB | றௌ 0BB1 0BCC |
| ன் 0BA9 0BCD | ன 0BA9 | னா 0BA9 0BBE | னி 0BA9 0BBF | னீ 0BA9 0BC0 | னு 0BA9 0BC1 | னூ 0BA9 0BC2 | னெ 0BA9 0BC6 | னே 0BA9 0BC7 | னை 0BA9 0BC8 | னொ 0BA9 0BCA | னோ 0BA9 0BCB | னௌ 0BA9 0BCC |
| ஶ் 0BB6 0BCD | ஶ 0BB6 | ஶா 0BB6 0BBE | ஶி 0BB6 0BBF | ஶீ 0BB6 0BC0 | ஶு 0BB6 0BC1 | ஶூ 0BB6 0BC2 | ஶெ 0BB6 0BC6 | ஶே 0BB6 0BC7 | ஶை 0BB6 0BC8 | ஶொ 0BB6 0BCA | ஶோ 0BB6 0BCB | ஶௌ 0BB6 0BCC |
| ஜ் 0B9C 0BCD | ஜ 0B9C | ஜா 0B9C 0BBE | ஜி 0B9C 0BBF | ஜீ 0B9C 0BC0 | ஜு 0B9C 0BC1 | ஜூ 0B9C 0BC2 | ஜெ 0B9C 0BC6 | ஜே 0B9C 0BC7 | ஜை 0B9C 0BC8 | ஜொ 0B9C 0BCA | ஜோ 0B9C 0BCB | ஜௌ 0B9C 0BCC |
| ஷ் 0BB7 0BCD | ஷ 0BB7 | ஷா 0BB7 0BBE | ஷி 0BB7 0BBF | ஷீ 0BB7 0BC0 | ஷு 0BB7 0BC1 | ஷூ 0BB7 0BC2 | ஷெ 0BB7 0BC6 | ஷே 0BB7 0BC7 | ஷை 0BB7 0BC8 | ஷொ 0BB7 0BCA | ஷோ 0BB7 0BCB | ஷௌ 0BB7 0BCC |
| ஸ் 0BB8 0BCD | ஸ 0BB8 | ஸா 0BB8 0BBE | ஸி 0BB8 0BBF | ஸீ 0BB8 0BC0 | ஸு 0BB8 0BC1 | ஸூ 0BB8 0BC2 | ஸெ 0BB8 0BC6 | ஸே 0BB8 0BC7 | ஸை 0BB8 0BC8 | ஸொ 0BB8 0BCA | ஸோ 0BB8 0BCB | ஸௌ 0BB8 0BCC |
| ஹ் 0BB9 0BCD | ஹ 0BB9 | ஹா 0BB9 0BBE | ஹி 0BB9 0BBF | ஹீ 0BB9 0BC0 | ஹு 0BB9 0BC1 | ஹூ 0BB9 0BC2 | ஹெ 0BB9 0BC6 | ஹே 0BB9 0BC7 | ஹை 0BB9 0BC8 | ஹொ 0BB9 0BCA | ஹோ 0BB9 0BCB | ஹௌ 0BB9 0BCC |
| க்ஷ் 0B95 0BCD 0BB7 0BCD | க்ஷ 0B95 0BCD 0BB7 | க்ஷா 0B95 0BCD 0BB7 0BBE | க்ஷி 0B95 0BCD 0BB7 0BBF | க்ஷீ 0B95 0BCD 0BB7 0BC0 | க்ஷு 0B95 0BCD 0BB7 0BC1 | க்ஷூ 0B95 0BCD 0BB7 0BC2 | க்ஷெ 0B95 0BCD 0BB7 0BC6 | க்ஷே 0B95 0BCD 0BB7 0BC7 | க்ஷை 0B95 0BCD 0BB7 0BC8 | க்ஷொ 0B95 0BCD 0BB7 0BCA | க்ஷோ 0B95 0BCD 0BB7 0BCB | க்ஷெள 0B95 0BCD 0BB7 0BCC |
Programmatic access
[edit]- Tamil script can be manipulated using the Python library called open-Tamil.[28]
- There is a Windows open source application available called AnyTaFont2UTF8 using C#.
See also
[edit]Explanatory notes
[edit]Notes
[edit]- ^ Rajan, K. (December 2001). "Territorial Division as Gleaned from Memorial Stones". East and West. 51 (3/4). Istituto Italiano per l'Africa e l'Oriente (IsIAO): 363. JSTOR 29757518. (table showing Tamil in row for the 601–800 period)
- ^ Diringer, David (1948). Alphabet a key to the history of mankind. p. 385.
- ^ Jump up to: a b Mahadevan 2003, p. 212.
- ^ Jump up to: a b c Mahadevan 2003, p. 213.
- ^ Allen, Julie (2006), The Unicode 5.0 Standard (5 ed.), Upper Saddle River, NJ: Addison-Wesley, ISBN 0-321-48091-0 at p. 324
- ^ Lewis, M. Paul, ed. (2009), Ethnologue: Languages of the World (16th ed.), Dallas, Tex.: SIL International, retrieved 28 August 2009
- ^ University of Madras Tamil Lexicon, page 148: "அலியெழுத்து [ aliyeḻuttu n ali-y-eḻuttu . < அலி¹ +. 1. The letter ஃ, as being regarded as neither a vowel nor a consonant; ஆய்தம். (வெண்பாப். முதன்மொ. 6, உரை.) 2. Consonants; மெய்யெ ழுத்து. (பிங்.)."]
- ^ Jump up to: a b Mahadevan 2003, p. 173.
- ^ Mahadevan 2003, p. 230.
- ^ Mahadevan 2003, p. 211.
- ^ Mahadevan 2003, p. 209.
- ^ Griffiths, Arlo (2014). "Early Indic Inscriptions of Southeast Asia".
- ^
 Learning materials related to Tamil Language/Letters at Wikiversity
Learning materials related to Tamil Language/Letters at Wikiversity - ^ Jump up to: a b c Steever 1996, p. 426-430.
- ^ The Unicode Standard Version 13.0 – Core Specification, South and Central Asia-I, Official Scripts of India pg. 498
- ^ Jump up to: a b Sharma, Shriramana. (2010a). Proposal to encode characters for Extended Tamil.
- ^ Sharma, Shriramana. (2010c). Follow-up #2 to Extended Tamil proposal.
- ^ Unicode Consortium (2019). Tamil. In The Unicode Standard Version 12.0 (pp. 489–498).
- ^ Selvakumar, V. (2016). History of Numbers and Fractions and Arithmetic Calculations in the Tamil Region: Some Observations. HuSS: International Journal of Research in Humanities and Social Sciences, 3(1), 27–35. https://doi.org/10.15613/HIJRH/2016/V3I1/111730
- ^ Sharma, Shriramana. (2010b). Follow-up to Extended Tamil proposal L2/10-256R.
- ^ Eraiyarasan, B. Dr. B. Eraiyarasan's comments on Tamil Unicode And Grantham proposals.
- ^ Nalankilli, Thanjai. (2018). Attempts to "Pollute" Tamil Unicode with Grantha Characters. Tamil Tribune. Retrieved 12 March 2019 from http://www.tamiltribune.com/18/1201.html
- ^ Government of India. (2010). Unicode Standard for Grantha Script.
- ^ Sharma, Shriramana. (2012). Proposal to encode Tamil fractions and symbols.
- ^ ICTA of Sri Lanka. (2014). Comments on the Proposals to Encode Tamil Symbols and Fractions.
- ^ Government of Tamil Nadu. (2017). Finalized proposal to encode Tamil fractions and symbols.
- ^ Pournader, Roozbeh (24 January 2018). "The two ways to represent Tamil Shri". Unicode. Archived from the original on 4 April 2023.
- ^ "Open-Tamil 0.65 : Python Package Index".
References
[edit]- Mahadevan, Iravatham (2003), Early Tamil Epigraphy from the Earliest Times to the Sixth Century A.D., Harvard Oriental Series, Volume 62, Cambridge: Harvard University Press, ISBN 0-674-01227-5
- Steever, Sanford B. (1996), "Tamil Writing", in Bright, William; Daniels, Peter T. (eds.), The World's Writing Systems, New York: Oxford University Press, pp. 426–430, ISBN 0-19-507993-0
External links
[edit]![]() Media related to Tamil script at Wikimedia Commons
Media related to Tamil script at Wikimedia Commons
- Findings at Keeladi Site dates back to 6th Century BCE
- Tamil Alphabet & Basics(PDF) Archived 8 August 2014 at the Wayback Machine
- Phonetics of spoken Tamil
- Unicode Chart – For Tamil (PDF)
- TACE 16 (PDF)
- Learn Tamil
- Tamil Letters
- Tamil Unicode Keyboard